lzh166
- µÁÅÞºê: 300092 µ¼í
- µÇºÕê½:

- µØÑÞç¬: Õîùõ║¼
-

µûçþ½áÕêåþ▒╗
- Õà¿Úâ¿ÕìÜÕ«ó (101)
- J2SEÕƒ║þíÇ (28)
- µûçþ½áµÄ¿ÞìÉ (4)
- HibernateþƒÑÞ»å (6)
- SpringþƒÑÞ»å (3)
- StrutsþƒÑÞ»å (7)
- ÚØóÞ»òÕçåÕñç (9)
- JavaScriptþƒÑÞ»å (4)
- OracleþƒÑÞ»å (3)
- web Õëìþ½» (5)
- Þ«¥Þ«íµ¿íÕ╝Å (1)
- þ¿ïÕ║ÅÕæÿÕà╗þöƒ (0)
- þ¿ïÕ║Åõ║║þöƒ (4)
- þëøõ║║ÕìÜÕ«ó (1)
- JBPM (1)
- DWR (4)
- FreeMarker (1)
- iBATIS (6)
- ExtJS (7)
- õ╝üõ©ÜÕ║öþö¿ (1)
- linux/unix (1)
þñ¥Õî║þëêÕØù
- µêæþÜäÞÁäÞ«» ( 0)
- µêæþÜäÞ«║ÕØø ( 2)
- µêæþÜäÚù«þ¡ö ( 0)
Õ¡ÿµíúÕêåþ▒╗
- 2013-03 ( 1)
- 2012-05 ( 4)
- 2012-03 ( 1)
- µø┤ÕñÜÕ¡ÿµíú...
µ£Çµû░Þ»äÞ«║
-
ÕêÿþçòÕ«ØÕ«ØÚ▒╝´╝Ü
fengqiyuanluo ÕåÖÚüôq77102902 ÕåÖÚüôDAO ...
springõ║ïÕèíþ«íþÉåÕçáþºìµû╣Õ╝Å´╝êÞ¢¼´╝ë -
zweichxu´╝Ü
q77102902 ÕåÖÚüôDAOÕ▒éµ│¿ÞºúÕèáþÜäµ£ëÚù«Úóÿ´╝îõ©ìÞªüÞ»»Õ»╝µû░õ║║´╝î ...
springõ║ïÕèíþ«íþÉåÕçáþºìµû╣Õ╝Å´╝êÞ¢¼´╝ë -
jsolo´╝Ü
q77102902 ÕåÖÚüôDAOÕ▒éµ│¿ÞºúÕèáþÜäµ£ëÚù«Úóÿ´╝îõ©ìÞªüÞ»»Õ»╝µû░õ║║´╝î ...
springõ║ïÕèíþ«íþÉåÕçáþºìµû╣Õ╝Å´╝êÞ¢¼´╝ë -
fengqiyuanluo´╝Ü
q77102902 ÕåÖÚüôDAOÕ▒éµ│¿ÞºúÕèáþÜäµ£ëÚù«Úóÿ´╝îõ©ìÞªüÞ»»Õ»╝µû░õ║║´╝î ...
springõ║ïÕèíþ«íþÉåÕçáþºìµû╣Õ╝Å´╝êÞ¢¼´╝ë -
q77102902´╝Ü
DAOÕ▒éµ│¿ÞºúÕèáþÜäµ£ëÚù«Úóÿ´╝îõ©ìÞªüÞ»»Õ»╝µû░õ║║´╝îDAOÕ▒éµ│¿ÞºúÕ║ö޻ѵÿ»@Re ...
springõ║ïÕèíþ«íþÉåÕçáþºìµû╣Õ╝Å´╝êÞ¢¼´╝ë
Õ£¿JAVAõ©¡´╝îµ£ëÕà¡õ©¬õ©ìÕÉîþÜäÕ£░µû╣ÕÅ»õ╗ÑÕ¡ÿÕ鿵ò░µì«´╝Ü
1. Õ»äÕ¡ÿÕÖ¿´╝êregister´╝ëÒÇéÞ┐Öµÿ»µ£ÇÕ┐½þÜäÕ¡ÿÕé¿Õî║´╝îÕøáõ©║Õ«âõ¢ìõ║Äõ©ìÕÉîõ║ÄÕàÂõ╗ûÕ¡ÿÕé¿Õî║þÜäÕ£░µû╣ÔÇöÔÇöÕñäþÉåÕÖ¿ÕåàÚâ¿ÒÇéõ¢åµÿ»Õ»äÕ¡ÿÕÖ¿þÜäµò░Úçŵ×üÕൣëÚÖÉ´╝îµëÇõ╗ÑÕ»äÕ¡ÿÕÖ¿þö▒þ╝ûÞ»æÕÖ¿µá╣µì«Ú£Çµ▒éÞ┐øÞíîÕêåÚàìÒÇéõ¢áõ©ìÞâ¢þø┤µÄѵĺÕê´╝îõ╣ƒõ©ìÞâ¢Õ£¿þ¿ïÕ║Åõ©¡µäƒÞºëÕê░Õ»äÕ¡ÿÕÖ¿Õ¡ÿÕ£¿þÜäõ╗╗õ¢òÞ┐╣Þ▒íÒÇé
2. Õáåµáê´╝êstack´╝ëÒÇéõ¢ìõ║ÄÚÇÜþö¿RAMõ©¡´╝îõ¢åÚÇÜÞ┐çÕ«âþÜäÔÇ£ÕáåµáêµîçÚÆêÔÇØÕÅ»õ╗Ñõ╗ÄÕñäþÉåÕÖ¿Õô¬ÚçîÞÄÀÕ¥ùµö»µîüÒÇéÕáåµáêµîçÚÆêÞïÑÕÉæõ©ïþº╗Õè¿´╝îÕêÖÕêåÚàìµû░þÜäÕåàÕ¡ÿ´╝øÞïÑÕÉæõ©èþº╗Õè¿´╝îÕêÖÚçèµö¥Úéúõ║øÕåàÕ¡ÿÒÇéÞ┐Öµÿ»õ©ÇþºìÕ┐½Úǃµ£ëµòêþÜäÕêåÚàìÕ¡ÿÕ鿵û╣µ│ò´╝îõ╗ർíõ║ÄÕ»äÕ¡ÿÕÖ¿ÒÇéÕêøÕ╗║þ¿ïÕ║ŵùÂÕÇÖ´╝îJAVAþ╝ûÞ»æÕÖ¿Õ┐àÚí╗þƒÑÚüôÕ¡ÿÕé¿Õ£¿ÕáåµáêÕåàµëǵ£ëµò░µì«þÜäþí«ÕêçÕñºÕ░ÅÕÆîþöƒÕæ¢Õ濵£ƒ´╝îÕøáõ©║Õ«âÕ┐àÚí╗þöƒµêÉþø©Õ║öþÜäõ╗úþáü´╝îõ╗Ñõ¥┐õ©èõ©ïþº╗Õè¿ÕáåµáêµîçÚÆêÒÇéÞ┐Öõ©Çþ║ªµØƒÚÖÉÕêÂõ║åþ¿ïÕ║ÅþÜäþüÁµ┤╗µÇº´╝îµëÇõ╗ÑÞÖ¢þ䵃Éõ║øJAVAµò░µì«Õ¡ÿÕé¿Õ£¿Õáåµáêõ©¡ÔÇöÔÇöþë╣Õê½µÿ»Õ»╣Þ▒íÕ╝òþö¿´╝îõ¢åµÿ»JAVAÕ»╣Þ▒íõ©ìÕ¡ÿÕé¿ÕàÂõ©¡ÒÇé
3. Õáå´╝êheap´╝ëÒÇéõ©ÇþºìÚÇÜþö¿µÇºþÜäÕåàÕ¡ÿµ▒á´╝êõ╣ƒÕ¡ÿÕ£¿õ║ÄRAMõ©¡´╝ë´╝îþö¿õ║ÄÕ¡ÿµö¥µëÇõ╗ÑþÜäJAVAÕ»╣Þ▒íÒÇéÕáåõ©ìÕÉîõ║ÄÕáåµáêþÜäÕÑ¢Õñäµÿ»´╝Üþ╝ûÞ»æÕÖ¿õ©ìÚ£ÇÞªüþƒÑÚüôÞªüõ╗ÄÕáåÚçîÕêåÚàìÕñÜÕ░æÕ¡ÿÕé¿Õî║Õƒƒ´╝îõ╣ƒõ©ìÕ┐àþƒÑÚüôÕ¡ÿÕé¿þÜäµò░µì«Õ£¿ÕáåÚçîÕ¡ÿµ┤╗ÕñÜÚò┐µùÂÚù┤ÒÇéÕøᵡñ´╝îÕ£¿ÕáåÚçîÕêåÚàìÕ¡ÿÕ鿵£ëÕ¥êÕñºþÜäþüÁµ┤╗µÇºÒÇéÕ¢ôõ¢áÚ£ÇÞªüÕêøÕ╗║õ©Çõ©¬Õ»╣Þ▒íþÜäµùÂÕÇÖ´╝îÕŬڣÇÞªünewÕåÖõ©ÇÞíîþ«ÇÕìòþÜäõ╗úþáü´╝îÕ¢ôµëºÞíîÞ┐ÖÞíîõ╗úþáüµù´╝îõ╝ÜÞç¬Õè¿Õ£¿ÕáåÚçîÞ┐øÞíîÕ¡ÿÕé¿ÕêåÚàìÒÇéÕ¢ôþä´╝îõ©║Þ┐ÖþºìþüÁµ┤╗µÇºÕ┐àÚí╗Þªüõ╗ÿÕç║þø©Õ║öþÜäõ╗úþáüÒÇéþö¿ÕáåÞ┐øÞíîÕ¡ÿÕé¿ÕêåÚàìµ»öþö¿ÕáåµáêÞ┐øÞíîÕ¡ÿÕé¿Õ¡ÿÕé¿Ú£ÇÞªüµø┤ÕñÜþÜäµùÂÚù┤ÒÇé
4. ÚØÖµÇüÕ¡ÿÕé¿´╝êstatic storage´╝ëÒÇéÞ┐ÖÚçîþÜäÔÇ£ÚØÖµÇüÔÇصÿ»µîçÔÇ£Õ£¿Õø║Õ«ÜþÜäõ¢ìþ¢«ÔÇØÒÇéÚØÖµÇüÕ¡ÿÕé¿ÚçîÕ¡ÿµö¥þ¿ïÕ║ÅÞ┐ÉÞíîµùÂõ©Çþø┤Õ¡ÿÕ£¿þÜäµò░µì«ÒÇéõ¢áÕÅ»þö¿Õà│Úö«Õ¡ùstaticµØѵáçÞ»åõ©Çõ©¬Õ»╣Þ▒íþÜäþë╣Õ«ÜÕàâþ┤áµÿ»ÚØÖµÇüþÜä´╝îõ¢åJAVAÕ»╣Þ▒íµ£¼Þ║½õ╗ĵØÑõ©ìõ╝ÜÕ¡ÿµö¥Õ£¿ÚØÖµÇüÕ¡ÿÕé¿þ®║Úù┤ÚçîÒÇé
5. Õ©©ÚçÅÕ¡ÿÕé¿´╝êconstant storage´╝ëÒÇéÕ©©ÚçÅÕÇ╝ÚÇÜÕ©©þø┤µÄÑÕ¡ÿµö¥Õ£¿þ¿ïÕ║Åõ╗úþáüÕåàÚâ¿´╝îÞ┐ÖµáÀÕüܵÿ»Õ«ëÕà¿þÜä´╝îÕøáõ©║Õ«âõ╗¼µ░©Þ┐£õ©ìõ╝ÜÞó½µö╣ÕÅÿÒÇéµ£ëµù´╝îÕ£¿ÕÁîÕàÑÕ╝Åþ│╗þ╗ƒõ©¡´╝îÕ©©Úçŵ£¼Þ║½õ╝ÜÕÆîÕàÂõ╗ûÚâ¿ÕêåÕêåÕë▓þª╗Õ╝Ç´╝îµëÇõ╗ÑÕ£¿Þ┐ÖþºìµâàÕåÁõ©ï´╝îÕÅ»õ╗ÑÚÇëµï®Õ░åÕàµö¥Õ£¿ROMõ©¡
6. ÚØ×RAMÕ¡ÿÕé¿ÒÇéÕªéµ×£µò░µì«Õ«îÕà¿Õ¡ÿµ┤╗õ║Äþ¿ïÕ║Åõ╣ïÕñû´╝îÚéúõ╣êÕ«âÕÅ»õ╗Ñõ©ìÕÅùþ¿ïÕ║ÅþÜäõ╗╗õ¢òµÄºÕê´╝îÕ£¿þ¿ïÕ║ŵ▓íµ£ëÞ┐ÉÞíîµùÂõ╣ƒÕÅ»õ╗ÑÕ¡ÿÕ£¿ÒÇé
 
õ©èÚØóÞ┐Öµ«Á޻صæÿÕÅûõ╣ïÒÇèThinking in JavaÒÇïÒÇÅ
 
---------------------------------------------------------------------
Õáåµÿ»õ©Çõ©¬Þ┐ÉÞíîµùµò░µì«Õî║,þ▒╗þÜäÕ»╣Þ▒íõ╗Äõ©¡ÕêåÚàìþ®║Úù┤ÒÇéÞ┐Öõ║øÕ»╣Þ▒íÚÇÜÞ┐çnewÕ╗║þ½ï´╝îÕ«âõ╗¼õ©ìÚ£ÇÞªüþ¿ïÕ║Åõ╗úþáüµØѵÿ¥Õ╝ÅþÜäÚçèµö¥ÒÇéÕáåµÿ»þö▒Õ×âÕ£¥Õø×µöµØÑÞ┤ƒÞ┤úþÜä´╝îÕáåþÜäõ╝ÿÕè┐µÿ»ÕÅ»õ╗ÑÕ迵ÇüÕ£░ÕêåÚàìÕåàÕ¡ÿÕñºÕ░Å´╝îþöƒÕ¡ÿµ£ƒõ╣ƒõ©ìÕ┐àõ║ïÕàêÕæèÞ»ëþ╝ûÞ»æÕÖ¿´╝îÕøáõ©║Õ«âµÿ»Õ£¿Þ┐ÉÞíîµùÂÕ迵ÇüÕêåÚàìÕåàÕ¡ÿþÜä´╝îJavaþÜäÕ×âÕ£¥µöÂÚøåÕÖ¿õ╝ÜÞç¬Õ迵öÂÞÁ░Þ┐Öõ║øõ©ìÕåìõ¢┐þö¿þÜäµò░µì«ÒÇéõ¢åþ╝║þé╣µÿ»´╝îþö▒õ║ÄÞªüÕ£¿Þ┐ÉÞíîµùÂÕ迵ÇüÕêåÚàìÕåàÕ¡ÿ´╝îÕ¡ÿÕÅûÚǃÕ║ªÞ¥âµàóÒÇéjavaõ©¡þÜäÕ»╣Þ▒íÕÆîµò░þ╗äÚâ¢Õ¡ÿµö¥Õ£¿Õáåõ©¡ÒÇé
µáêþÜäõ╝ÿÕè┐µÿ»´╝îÕ¡ÿÕÅûÚǃÕ║ªµ»öÕáåÞªüÕ┐½´╝îõ╗ർíõ║ÄÕ»äÕ¡ÿÕÖ¿´╝îµáêµò░µì«ÕÅ»õ╗ÑÕà▒õ║½ÒÇéõ¢åþ╝║þé╣µÿ»´╝îÕ¡ÿÕ£¿µáêõ©¡þÜäµò░µì«ÕñºÕ░Åõ©ÄþöƒÕ¡ÿµ£ƒÕ┐àÚí╗µÿ»þí«Õ«ÜþÜä´╝îþ╝║õ╣ÅþüÁµ┤╗µÇºÒÇéµáêõ©¡õ©╗ÞªüÕ¡ÿµö¥õ©Çõ║øÕƒ║µ£¼þ▒╗Õ×ïþÜäÕÅÿÚçÅ´╝ê,int, short, long, byte, float, double, boolean, char´╝ëÕÆîÕ»╣Þ▒íÕ╝òþö¿ÒÇé
µáêµ£ëõ©Çõ©¬Õ¥êÚçìÞªüþÜäþë╣µ«èµÇº´╝îÕ░▒µÿ»Õ¡ÿÕ£¿µáêõ©¡þÜäµò░µì«ÕÅ»õ╗ÑÕà▒õ║½ÒÇéÕüçÞ«¥µêæõ╗¼ÕÉîµùÂÕ«Üõ╣ë´╝Ü
int a = 3;
int b = 3´╝ø
þ╝ûÞ»æÕÖ¿ÕàêÕñäþÉåint a = 3´╝øÚªûÕàêÕ«âõ╝ÜÕ£¿µáêõ©¡ÕêøÕ╗║õ©Çõ©¬ÕÅÿÚçÅõ©║aþÜäÕ╝òþö¿´╝îþäÂÕÉĵƒÑµë¥µáêõ©¡µÿ»Õɪµ£ë3Þ┐Öõ©¬ÕÇ╝´╝îÕªéµ×£µ▓íµë¥Õê░´╝îÕ░▒Õ░å3Õ¡ÿµö¥Þ┐øµØÑ´╝îþäÂÕÉÄÕ░åaµîçÕÉæ3ÒÇéµÄÑþØÇÕñäþÉåint b = 3´╝øÕ£¿ÕêøÕ╗║Õ«îbþÜäÕ╝òþö¿ÕÅÿÚçÅÕÉÄ´╝îÕøáõ©║Õ£¿µáêõ©¡ÕÀ▓þ╗ŵ£ë3Þ┐Öõ©¬ÕÇ╝´╝îõ¥┐Õ░åbþø┤µÄѵîçÕÉæ3ÒÇéÞ┐ÖµáÀ´╝îÕ░▒Õç║þÄ░õ║åaõ©ÄbÕÉîµùÂÕØçµîçÕÉæ3þÜäµâàÕåÁÒÇéÞ┐Öµù´╝îÕªéµ×£Õåìõ╗ña=4´╝øÚéúõ╣êþ╝ûÞ»æÕÖ¿õ╝ÜÚçìµû░µÉ£þ┤óµáêõ©¡µÿ»Õɪµ£ë4ÕÇ╝´╝îÕªéµ×£µ▓íµ£ë´╝îÕêÖÕ░å4Õ¡ÿµö¥Þ┐øµØÑ´╝îÕ╣Âõ╗ñaµîçÕÉæ4´╝øÕªéµ×£ÕÀ▓þ╗ŵ£ëõ║å´╝îÕêÖþø┤µÄÑÕ░åaµîçÕÉæÞ┐Öõ©¬Õ£░ÕØÇÒÇéÕøᵡñaÕÇ╝þÜäµö╣ÕÅÿõ©ìõ╝ÜÕ¢▒ÕôìÕê░bþÜäÕÇ╝ÒÇéÞªüµ│¿µäÅÞ┐Öþºìµò░µì«þÜäÕà▒õ║½õ©Äõ©ñõ©¬Õ»╣Þ▒íþÜäÕ╝òþö¿ÕÉîµùµîçÕÉæõ©Çõ©¬Õ»╣Þ▒íþÜäÞ┐ÖþºìÕà▒õ║½µÿ»õ©ìÕÉîþÜä´╝îÕøáõ©║Þ┐ÖþºìµâàÕåÁaþÜäõ┐«µö╣Õ╣Âõ©ìõ╝ÜÕ¢▒ÕôìÕê░b, Õ«âµÿ»þö▒þ╝ûÞ»æÕÖ¿Õ«îµêÉþÜä´╝îÕ«âµ£ëÕê®õ║ÄÞèéþ£üþ®║Úù┤ÒÇéÞÇîõ©Çõ©¬Õ»╣Þ▒íÕ╝òþö¿ÕÅÿÚçÅõ┐«µö╣õ║åÞ┐Öõ©¬Õ»╣Þ▒íþÜäÕåàÚâ¿þèµÇü´╝îõ╝ÜÕ¢▒ÕôìÕê░ÕŪõ©Çõ©¬Õ»╣Þ▒íÕ╝òþö¿ÕÅÿÚçÅÒÇé
 
õ╗Ñõ©èÕåàÕ«╣õ╣ƒµÿ»µæÿµèäÞç¬þ¢æõ©èÒÇé
 
---------------------------------------------------------------------
õ©ïÚØóµêæÞç¬ÕÀ▒µØÑõ©¥Õçáõ©¬õ¥ïÕ¡É´╝Ü
 [code="java"]
public class TestStr {
  public static void main(String[] args) {
┬á┬á┬á┬á// õ╗Ñõ©ïõ©ñµØíÞ»¡ÕÅÑÕêøÕ╗║õ║å1õ©¬Õ»╣Þ▒íÒÇé"ÕçñÕ▒▒"Õ¡ÿÕé¿Õ£¿Õ¡ùþ¼ªõ©▓Õ©©Úçŵ▒áõ©¡
┬á┬á┬á┬áString str1 = "ÕçñÕ▒▒";
┬á┬á┬á┬áString str2 = "ÕçñÕ▒▒";
    System.out.println(str1==str2);//true
    
┬á┬á┬á┬á//õ╗Ñõ©ïõ©ñµØíÞ»¡ÕÅÑÕêøÕ╗║õ║å3õ©¬Õ»╣Þ▒íÒÇé"Õñ®Õ│¿"´╝îÕ¡ÿÕé¿Õ£¿Õ¡ùþ¼ªõ©▓Õ©©Úçŵ▒áõ©¡´╝îõ©ñõ©¬new String()Õ»╣Þ▒íÕ¡ÿÕé¿Õ£¿ÕáåÕåàÕ¡ÿõ©¡
┬á┬á┬á┬áString str3 = new String("Õñ®Õ│¿");
┬á┬á┬á┬áString str4 = new String("Õñ®Õ│¿");
    System.out.println(str3==str4);//false
    
┬á┬á┬á┬á//õ╗Ñõ©ïõ©ñµØíÞ»¡ÕÅÑÕêøÕ╗║õ║å1õ©¬Õ»╣Þ▒íÒÇé9µÿ»Õ¡ÿÕé¿Õ£¿µáêÕåàÕ¡ÿõ©¡
    int i = 9;
    int j = 9;
    System.out.println(i==j);//true
    
┬á┬á┬á┬á┬á┬á//õ╗Ñõ©ïõ©ñµØíÞ»¡ÕÅÑÕêøÕ╗║õ║å1õ©¬Õ»╣Þ▒íÒÇé1Õ»╣Þ▒íÕ¡ÿÕé¿Õ£¿µáêÕåàÕ¡ÿõ©¡
┬á┬á┬á┬áInteger l = 1;//Þúàþ«▒
┬á┬á┬á┬áInteger k = 1;//Þúàþ«▒
    System.out.println(l==k);//true
    
┬á┬á┬á┬á//þö▒õ║ĵ▓íµ£ëõ║åÞúàþ«▒´╝îõ╗Ñõ©ïõ©ñµØíÞ»¡ÕÅÑÕêøÕ╗║õ║å2õ©¬Õ»╣Þ▒íÒÇéõ©ñõ©¬1Õ»╣Þ▒íÕ¡ÿÕé¿Õ£¿ÕáåÕåàÕ¡ÿõ©¡
    Integer l1 = new Integer(1);
    Integer k1 = new Integer(1);
    System.out.println(l1==k1);//false
    
┬á┬á┬á┬á//õ╗Ñõ©ïõ©ñµØíÞ»¡ÕÅÑÕêøÕ╗║õ║å1õ©¬Õ»╣Þ▒íÒÇéi1,i2ÕÅÿÚçÅÕ¡ÿÕé¿Õ£¿µáêÕåàÕ¡ÿõ©¡´╝îõ©ñõ©¬256Õ»╣Þ▒íÕ¡ÿÕé¿Õ£¿ÕáåÕåàÕ¡ÿõ©¡
         Integer i1 = 256;
                Integer i2 = 256;
         System.out.println(i1==i2);//false
  }
}
[/code]
  public static void main(String[] args) {
┬á┬á┬á┬á// õ╗Ñõ©ïõ©ñµØíÞ»¡ÕÅÑÕêøÕ╗║õ║å1õ©¬Õ»╣Þ▒íÒÇé"ÕçñÕ▒▒"Õ¡ÿÕé¿Õ£¿Õ¡ùþ¼ªõ©▓Õ©©Úçŵ▒áõ©¡
┬á┬á┬á┬áString str1 = "ÕçñÕ▒▒";
┬á┬á┬á┬áString str2 = "ÕçñÕ▒▒";
    System.out.println(str1==str2);//true
    
┬á┬á┬á┬á//õ╗Ñõ©ïõ©ñµØíÞ»¡ÕÅÑÕêøÕ╗║õ║å3õ©¬Õ»╣Þ▒íÒÇé"Õñ®Õ│¿"´╝îÕ¡ÿÕé¿Õ£¿Õ¡ùþ¼ªõ©▓Õ©©Úçŵ▒áõ©¡´╝îõ©ñõ©¬new String()Õ»╣Þ▒íÕ¡ÿÕé¿Õ£¿ÕáåÕåàÕ¡ÿõ©¡
┬á┬á┬á┬áString str3 = new String("Õñ®Õ│¿");
┬á┬á┬á┬áString str4 = new String("Õñ®Õ│¿");
    System.out.println(str3==str4);//false
    
┬á┬á┬á┬á//õ╗Ñõ©ïõ©ñµØíÞ»¡ÕÅÑÕêøÕ╗║õ║å1õ©¬Õ»╣Þ▒íÒÇé9µÿ»Õ¡ÿÕé¿Õ£¿µáêÕåàÕ¡ÿõ©¡
    int i = 9;
    int j = 9;
    System.out.println(i==j);//true
    
┬á┬á┬á┬á┬á┬á//õ╗Ñõ©ïõ©ñµØíÞ»¡ÕÅÑÕêøÕ╗║õ║å1õ©¬Õ»╣Þ▒íÒÇé1Õ»╣Þ▒íÕ¡ÿÕé¿Õ£¿µáêÕåàÕ¡ÿõ©¡
┬á┬á┬á┬áInteger l = 1;//Þúàþ«▒
┬á┬á┬á┬áInteger k = 1;//Þúàþ«▒
    System.out.println(l==k);//true
    
┬á┬á┬á┬á//þö▒õ║ĵ▓íµ£ëõ║åÞúàþ«▒´╝îõ╗Ñõ©ïõ©ñµØíÞ»¡ÕÅÑÕêøÕ╗║õ║å2õ©¬Õ»╣Þ▒íÒÇéõ©ñõ©¬1Õ»╣Þ▒íÕ¡ÿÕé¿Õ£¿ÕáåÕåàÕ¡ÿõ©¡
    Integer l1 = new Integer(1);
    Integer k1 = new Integer(1);
    System.out.println(l1==k1);//false
    
┬á┬á┬á┬á//õ╗Ñõ©ïõ©ñµØíÞ»¡ÕÅÑÕêøÕ╗║õ║å1õ©¬Õ»╣Þ▒íÒÇéi1,i2ÕÅÿÚçÅÕ¡ÿÕé¿Õ£¿µáêÕåàÕ¡ÿõ©¡´╝îõ©ñõ©¬256Õ»╣Þ▒íÕ¡ÿÕé¿Õ£¿ÕáåÕåàÕ¡ÿõ©¡
         Integer i1 = 256;
                Integer i2 = 256;
         System.out.println(i1==i2);//false
  }
}
[/code]
Õ»╣õ║Äõ╗Ñõ©èµ£ÇÕÉÄõ©ñõ©¬Õà│õ║ÄIntegerÕ»╣Þ▒íþÜäõ¥ïÕ¡É´╝îÕ£¿Þç¬Õè¿Þúàþ«▒µùÂÕ»╣õ║ÄÕÇ╝õ╗ÄÔÇô128Õê░127õ╣ïÚù┤þÜäÕÇ╝´╝îõ¢┐þö¿õ©Çõ©¬Õ«×õ¥ïÒÇé
õ©ïÚØóµÿ»Õ»╣Õ¡ùþ¼ªõ©▓Õ©©Úçŵ▒á´╝ê´╝ëþÜäõ©Çõ©¬õ¥ïÕ¡É´╝Ü
String s1 = "aaa" + "bbb"; //õ║ºþöƒõ║å1õ©¬Õ»╣Þ▒íÒÇé
þö▒õ║ÄÕ©©ÚçÅþÜäÕÇ╝Õ£¿þ╝ûÞ»æþÜäµùÂÕÇÖÕ░▒Þó½þí«Õ«Üõ║åÒÇéÕ£¿Þ┐ÖÚçî´╝î"aaa"ÕÆî"bbb"Ú⢵ÿ»Õ©©ÚçÅ´╝îÕøᵡñÕÅÿÚçÅs1 þÜäÕÇ╝Õ£¿þ╝ûÞ»æµùÂÕ░▒ÕÅ»õ╗Ñþí«Õ«ÜÒÇéÞ┐ÖÞíîõ╗úþáüþ╝ûÞ»æÕÉÄþÜäµòêµ×£þ¡ëÕÉîõ║Ä´╝Ü
String s1 ="aaabbb";
ÕøᵡñÞ┐ÖÚçîÕŬÕêøÕ╗║õ║åõ©Çõ©¬Õ»╣Þ▒í"aaabbb"´╝îÕ╣Âõ©öÕ«âÞó½õ┐ØÕ¡ÿÕ£¿Õ¡ùþ¼ªõ©▓µ▒áÚçîõ║åÒÇé
þö▒õ║ÄÕ©©ÚçÅþÜäÕÇ╝Õ£¿þ╝ûÞ»æþÜäµùÂÕÇÖÕ░▒Þó½þí«Õ«Üõ║åÒÇéÕ£¿Þ┐ÖÚçî´╝î"aaa"ÕÆî"bbb"Ú⢵ÿ»Õ©©ÚçÅ´╝îÕøᵡñÕÅÿÚçÅs1 þÜäÕÇ╝Õ£¿þ╝ûÞ»æµùÂÕ░▒ÕÅ»õ╗Ñþí«Õ«ÜÒÇéÞ┐ÖÞíîõ╗úþáüþ╝ûÞ»æÕÉÄþÜäµòêµ×£þ¡ëÕÉîõ║Ä´╝Ü
String s1 ="aaabbb";
ÕøᵡñÞ┐ÖÚçîÕŬÕêøÕ╗║õ║åõ©Çõ©¬Õ»╣Þ▒í"aaabbb"´╝îÕ╣Âõ©öÕ«âÞó½õ┐ØÕ¡ÿÕ£¿Õ¡ùþ¼ªõ©▓µ▒áÚçîõ║åÒÇé
 
String str1 = "ÕçñÕ▒▒";
String str2 = "ÕçñÕ▒▒";
õ╗Ñõ©èõ©ñµØíÞ»¡ÕÅÑÕŬգ¿Õ©©Úçŵ▒áõ©¡õ┐ØÕ¡ÿõ║åõ©Çõ©¬"ÕçñÕ▒▒"Õ»╣Þ▒íÒÇé
 
String str3 = new String("Õñ®Õ│¿");
String str4 = new String("Õñ®Õ│¿");
õ╗Ñõ©èõ©ñµØíÞ»¡ÕÅÑÕêøÕ╗║õ║å3õ©¬Õ»╣Þ▒í´╝îÚªûÕàêÕ£¿Õ¡ùþ¼ªõ©▓Õ©©Úçŵ▒áõ©¡ÕêøÕ╗║õ©Çõ©¬"Õñ®Õ│¿"Õ»╣Þ▒í´╝îµÄÑþØÇÕ£¿ÕáåÕåàÕ¡ÿõ©¡ÕêøÕ╗║õ©ñõ©¬new String()Õ»╣Þ▒í´╝îÚçîÚØóõ┐ØÕ¡ÿþÜäµÿ»µîçÕÉæ"Õñ®Õ│¿"Õ»╣Þ▒íþÜäÕ╝òþö¿ÒÇé
ÕŪ´╝ÜÔÇ£==ÔÇ£Õ£¿Õêñµû¡Õ»╣Þ▒íµù´╝îÕàÂÕ«×µÿ»µá╣µì«Õ»╣Þ▒íÕ£¿Õáåµáêõ©¡þÜäÕ£░ÕØÇÕêñµû¡Õ»╣Þ▒íµÿ»õ©ìµÿ»õ©ÇµáÀ´╝îÞÇîõ©ìµÿ»µá╣µì«hashcode ÕÇ╝ÒÇé
 
 
Õ£¿þ¢æõ©èþ£ïÞºüÞ┐Öµ«ÁÕ»╣Java┬áStringõ©¡þÜäHashCodeÕÆîequalþÜäµÇ╗þ╗ôµ»öÞ¥âÕÑ¢´╝îÞ«░Õ¢òÕªéõ©ï´╝Ü
┬á┬á┬á 1. hashSetõ©¡µ»öÞ¥âµÿ»ÕɪÚçìÕñìþÜäõ¥Øµì«µÿ»a.hasCode´╝ê´╝ë=b.hasCode´╝ê´╝ë && a.equals´╝êb´╝ë
┬á┬á┬á 2. StringþÜähashCodeõ¥Øµì«´╝Ü õ╗Ñõ¥ØÞÁûõ║Ächar[i]þÜäintÕÇ╝õ╗ÑÕÆîchar[i]þÜäµÄÆÕêùÕ║ÅþÜäþ«ùµ│òÞ«íþ«ùÕç║þÜä´╝êÕÅ»õ╗ÑÕÄ╗þ£ïþ£ïµ║Éþáü´╝ëÒÇéõ©ìõ¥ØÞÁûStringþÜäref.
┬á┬á┬á 3. StringþÜäequalsõ¥Øµì«´╝Ü a==b || ´╝ê a.length=b.length && { a[i]=b[i] } ´╝ë
┬á┬á┬á 4. ÕŬµ£ëþö¿a==bµùµ»öµáíþÜäµëìµÿ»µ»öµáíþÜäref´╝îõ╣ƒÕ░▒µÿ»Þ»┤Þ┐Öµùµëìµÿ»µ»öµáíµÿ»aõ©Äbµÿ»õ©ìµÿ»ÕÉîõ©Çõ©¬Õ»╣Þ▒í
┬á┬á┬á 5. þ╗ôÞ«║´╝Ü õ©ñõ©¬õ©ìÕÉîrefþÜäStringÕÅ»Þâ¢õ╝ÜÞó½Þ«ñõ©║µÿ»ÚøåÕÉêõ©¡þÜäÕÉîõ©Çõ©¬Õàâþ┤áÒÇé
 
---------------------------------------------------------------------
õ©ïÚØóÕêåµ×Éõ©Çõ©¬õ╗úþáüþñ║õ¥ï´╝Ü
class BirthDate {
        private int day;
        private int month;
        private int year;        
        public BirthDate(int d, int m, int y) {
                day = d;    
                month = m;    
                year = y;
        }
┬á┬á┬á┬á┬á┬á┬á┬áþ£üþòÑget,setµû╣µ│òÒÇéÒÇéÒÇé
        public void display() {
        System.out.println
                (day + " - " + month + " - " + year);
        }
}
    
public class Test{
        public static void main(String args[]){
                Test test = new Test();
                int date = 9;
                BirthDate d1= new BirthDate(7,7,1970);
                BirthDate d2= new BirthDate(1,1,2000);        
                test.change1(date);
                test.change2(d1);
                test.change3(d2);
                d1.display();
                d2.display();
        }
        
        public void change1(int i){
        i = 1234;
        }
        
        public void change2(BirthDate b) {
        b = new BirthDate(22,2,2004);
        }
        
        public void change3(BirthDate b) {
        b.setDay(22);
        }
}
        private int day;
        private int month;
        private int year;        
        public BirthDate(int d, int m, int y) {
                day = d;    
                month = m;    
                year = y;
        }
┬á┬á┬á┬á┬á┬á┬á┬áþ£üþòÑget,setµû╣µ│òÒÇéÒÇéÒÇé
        public void display() {
        System.out.println
                (day + " - " + month + " - " + year);
        }
}
    
public class Test{
        public static void main(String args[]){
                Test test = new Test();
                int date = 9;
                BirthDate d1= new BirthDate(7,7,1970);
                BirthDate d2= new BirthDate(1,1,2000);        
                test.change1(date);
                test.change2(d1);
                test.change3(d2);
                d1.display();
                d2.display();
        }
        
        public void change1(int i){
        i = 1234;
        }
        
        public void change2(BirthDate b) {
        b = new BirthDate(22,2,2004);
        }
        
        public void change3(BirthDate b) {
        b.setDay(22);
        }
}
õ╗Ñõ©ïõ©║Õ»╣ÕåàÕ¡ÿþÜäÕêåµ×É´╝Ü
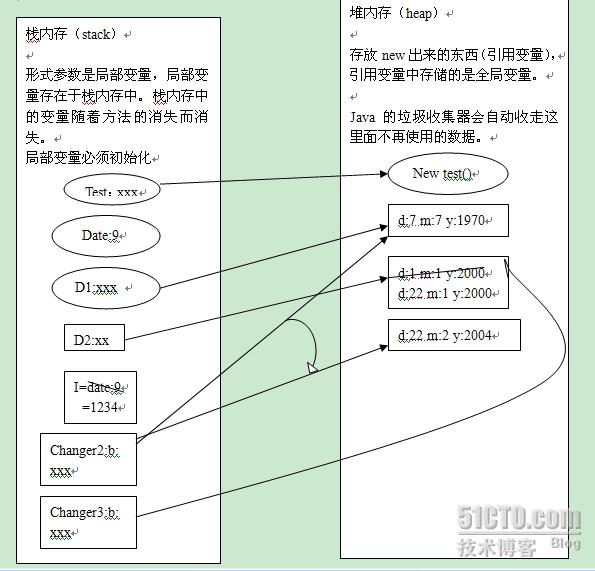
 
 
µêÉÕæÿÕÅÿÚçÅ´╝ܵû╣µ│òÕñûÚâ¿´╝îþ▒╗þÜäÕåàÚâ¿Õ«Üõ╣ëþÜäÕÅÿÚçÅÒÇé
Õ▒ÇÚâ¿ÕÅÿÚçÅ´╝ܵû╣µ│òµêûÞ»¡ÕÅÑÕØùÕåàÚâ¿Õ«Üõ╣ëþÜäÕÅÿÚçÅÒÇé
 
ÕåìÞ┤┤õ©èõ©ÇÕ╝áþ¿ïÕ║ŵëºÞíîÞ┐çþ¿ïþÜäÕø¥þëç´╝êµê¬ÕÅûÞç¬Õ░ÜÕ¡ªÕáé´╝ë´╝Ü
 
µ£¼µûçÕç║Þç¬ ÔÇ£ÚØÆÕ▒▒ÔÇØ ÕìÜÕ«ó´╝îÞ»ÀÕèíÕ┐àõ┐ØþòÖµ¡ñÕç║Õñähttp://java999.blog.51cto.com/259217/134359
µ£¼µûçÕç║Þç¬ 51CTO.COMµèǵ£»ÕìÜÕ«ó

Õêåõ║½Õê░´╝Ü


- 2010-03-28 22:46
- µÁÅÞºê 856
- Þ»äÞ«║(0)
- Õêåþ▒╗:þ╝ûþ¿ïÞ»¡Þ¿Ç
- µƒÑþ£ïµø┤ÕñÜ
ÕÅæÞí¿Þ»äÞ«║

-
Lucene ÕàÑÚù¿
2011-05-29 15:13 0http://blog.csdn.net/wenlin56/c ... -
java Transient
2011-01-08 23:10 1807µêæõ╗¼Úâ¢þƒÑÚüôõ©Çõ©¬Õ»╣Þ▒íÕÅ¬Þ ... -
Þ░êÞ░êjavaõ©Äjsõ©¡þÜä&&ÒÇü& ||ÒÇü|
2010-05-06 23:31 2969javaõ©¡þÜäÚÇ╗Þ¥æÞ┐Éþ«ùþ¼ªõ©╗Þªü ... -
Javaõ©¡µÄÑÕÅúÚçîÕ«Üõ╣ëþÜäµêÉÕæÿÕÅÿÚçÅ
2010-04-18 22:45 2580Õ£¿interfaceÚçîÚØóþÜäÕÅÿÚçÅÚ⢵ ... -
StringÒÇüStringBufferÕÆîStringBuilderõ╣ïÚù┤µ»öÞ¥â
2010-04-17 00:07 1356Þ┐Öµÿ»µêæÕ£¿þ¢æõ©èþ£ïÕê░þÜä´╝îµ ... -
ÕÇ╝Õ¥ùþÉåÞºúþÜäJavaÕñܵÇüµÇº
2010-04-16 22:13 1180Õ£¿þ¢æõ©èµâ│µÉ£õ©Çõ©ïÕà│õ║ÄjavaÕñܵÇüþÜäõ©Çõ║øõ©¬õ║║þÉåÞºú´╝îµ£ÇÕÑ¢µÿ»õ©Çõ║øÚÇÜõ┐ùµÿô ... -
Java 1.5ÕÆî1.6õ©¡µû░þë╣µÇº(Þ¢¼)
2010-04-14 22:43 1139JDK5µû░þë╣µÇº´╝êõ©Ä1.4þø©µ»ö´╝ëÒÇÉÞ¢¼ÒÇæ 1 Õ¥¬þÄ» for ... -
JVMÞ┐ÉÞíîjavaþ¿ïÕ║ÅÕ£¿ÕåàÕ¡ÿõ©¡þÜäÕêåÚàì
2010-04-14 15:59 2192þ¼¼õ©Çõ©¬JVMÞ»×þöƒõ║Ä1995Õ╣┤ÒÇé JVMþÜäõ©╗Þªüõ╗╗Õèíµÿ»´╝ÜÞúàÞ¢¢cla ... -
õ╗úþÉ嵿íÕ╝Åõ©ÄJava Õ迵Çüõ╗úþÉåþ▒╗
2010-04-05 23:09 34411. õ╗úþÉ嵿íÕ╝Å õ╗úþÉ嵿íÕ╝ÅþÜäõ¢£þö¿µÿ»´╝Üõ©║ÕàÂõ╗ûÕ»╣Þ▒íµÅÉõ¥øõ©Çþºìõ╗úþÉåõ╗ѵĺÕê ... -
Õà│õ║Äþ▒╗ÕèáÞ¢¢ÕÖ¿þÜäõ©Çõ©¬Õ║öþö¿µÁïÞ»ò
2010-04-05 22:33 1221µû░Õ╗║õ©Çõ©¬webÚí╣þø«þäÂÕÉĵû░Õ╗║õ©Çõ©¬servlet´╝îÕ£¿servetþÜä ... -
Java þ▒╗ÕèáÞ¢¢ÕÖ¿µûçþ½á
2010-04-05 00:31 996µ£¼µûçµ║Éõ║Ä´╝ܵÀ▒ÕàѵÄóÞ«¿ Jav ... -
java µ│øÕ×ï
2010-04-04 19:34 1767õ©ÇÒÇüµ│øÕ×ïþÜäÕƒ║µ£¼ÕàÑÚù¿ µ│øÕ×ï´╝êGeneric type µêûÞÇàgen ... -
java annotation µ│¿Þºúµò┤þÉå´╝êÚâ¿ÕêåÞ¢¼Þ¢¢´╝ë
2010-04-04 00:05 1520µ£¼µûçÕ░åÕÉæõ¢áõ╗ïþ╗ìJ2SE5.0õ©¡þÜäµû░þë╣µÇºõ╣ïõ©Ç´╝ܵ│¿Úçè´╝êµ│¿Þºú´╝ëÒÇéµ£¼µûç ... -
µ¡úÕêÖÞí¿Þ¥¥Õ╝Å(µöÂÞùÅ)
2010-04-03 23:02 9001ÒÇüÚØ×Þ┤ƒµò┤µò░´╝Ü^\d+$ 2ÒÇüµ ... -
JavaBean þÜäþ«ÇÕìòÕåàþ£ü(Intorspector)µôìõ¢£ÕÅèBeanUtilsÕÀÑÕàÀþ▒╗
2010-04-03 19:45 14821ÒÇüÕ»╣JavabeanþÜäþ«ÇÕìòþÜäÕåàþ£üµôìõ¢£ Úù«Úóÿ ÕÀ▓þƒÑõ©Çõ©¬Refl ... -
JavaÕ╝éÕ©©þÜäµûçþ½á(Þ¢¼Þ¢¢)
2010-04-03 16:12 1177Õà¡þºìÕ╝éÕ©©ÕñäþÉåþÜäÚÖïõ╣á õ¢ ... -
Javaþ╝ûþáüÞºäÞîâ´╝êThe Elements of Java Style´╝ë
2010-04-03 12:28 3615Genaral Principles õ©ÇÞê¼þ║ªÕ«Ü 1.Adher ... -
JavaBeanþÜäÕæ¢ÕÉìÞºäÕêÖ
2010-04-03 12:26 8637Õë쵫ÁµùÂÚù┤´╝îÕåÖþ¿ïÕ║ŵù´╝îÕ ... -
equals()ÕÆîhashCode()Þ»ªþ╗åÕêåµ×É(Þ¢¼Þ¢¢)
2010-03-29 22:25 1083HashCodeµÿ»Õ£░ÕØÇõ©ÄÕôêÞÑ┐þ«ùµ│ ... -
equals()ÕÆîhashCode()Þ»ªþ╗åÕêåµ×É´╝êÞ¢¼Þ¢¢´╝ë
2010-03-29 22:18 1004HashCodeµÿ»Õ£░ÕØÇõ©ÄÕôêÞÑ┐þ«ùµ│ ...
þø©Õà│µÄ¿ÞìÉ
õ╗Ñõ©ïµÿ»Õ»╣Java I/Oµ£║ÕêÂþÜäÞ»ªþ╗åÕêåµ×É´╝Ü 1. **I/O µÁüþÜ䵪éÕ┐Á** Javaõ©¡þÜäI/Oµôìõ¢£Õƒ║õ║ĵÁüþÜ䵪éÕ┐Á´╝îµÁüµÿ»µò░µì«þÜäµ£ëÕ║Åõ╝áÞ¥ôÚÇÜÚüôÒÇéJavaÕ░åµëǵ£ëþÜäI/Oµôìõ¢£µè¢Þ▒íõ©║µÁüÕ»╣Þ▒í´╝îÕêåõ©║Õ¡ùÞèéµÁüÕÆîÕ¡ùþ¼ªµÁüõ©ñÕñºþ▒╗ÒÇéÕ¡ùÞèéµÁüÕñäþÉåÕìòõ©¬Õ¡ùÞèéþÜäµò░µì«´╝îÕªé...
µ¡ñÚí╣þø«þÜäµá©Õ┐âþø«µáçÕ£¿õ║ÄÕêåµ×Éþ│╗þ╗ƒþÜäÕÅ»ÞíîµÇº´╝îµÿÄþí«Õ╝ÇÕÅæµû╣ÕÉæ´╝îþí«õ┐ØÕ╝ÇÕÅæÞ┐çþ¿ïþÜäÕÉêþÉåµÇºÒÇéÕ«âÞªüµ▒éÕ╝ÇÕÅæÞÇàÞâ¢Õñƒþ▓¥þí«Þ»åÕê½þ│╗þ╗ƒµÁüþ¿ï´╝îþåƒþ╗âÞ┐Éþö¿Javaþ╝ûþ¿ïµèǵ£»´╝îÚÇÜÞ┐çõ║ÆÞüöþ¢æÞÁäµ║ÉÕÅèõ©ôõ©Üõ╣ªþ▒ìµÉ£Úøåþø©Õà│õ┐íµü»´╝îµ£Çþ╗êÕ«îµêÉõ©Çõ©¬Õƒ║õ║ÄJavaþÜäÕ║öþö¿þ│╗þ╗ƒ...
5. JavaµÇºÞâ¢Õƒ║ÕçåµÁïÞ»ò´╝Üõ╣ªõ©¡ÕÅ»Þâ¢õ╝ÜÞ«¿Þ«║Õªéõ¢òÞííÚçÅÕÆîÕêåµ×ÉJavaÕ║öþö¿þ¿ïÕ║ÅþÜäµÇºÞ⢴╝îÕîàµï¼õ¢┐þö¿õ©ìÕÉîþÜäÕƒ║ÕçåµÁïÞ»òÕÀÑÕàÀÕÆîµû╣µ│òÒÇé þëêµØâõ┐íµü»µÿ¥þñ║´╝îÞ┐Öµ£¼õ╣ªþÜäþëêµØâÕ¢ÆPackt Publishingµëǵ£ë´╝îÕàÂÕ£¿µ£¬ÞÄÀÕ¥ùÕç║þëêÕòåµÿÄþí«Þ«©ÕÅ»þÜäµâàÕåÁõ©ï´╝îõ©ìÕ¥ùÕñìÕêµêû...
µ¡ñÕñû´╝îõ¢┐þö¿ÕåàÕ¡ÿÕêåµ×ÉÕÀÑÕàÀ´╝êÕªéVisualVMµêûJProfiler´╝ëÕÅ»õ╗ÑÕ©«Õè®Þ»åÕê½ÕåàÕ¡ÿµ│äµ╝ÅþÜäÕàÀõ¢ôÕ»╣Þ▒íÕÆîÕ╝òþö¿Úô¥ÒÇé ÚÖñµ¡ñõ╣ïÕñû´╝îÕàÂõ╗ûÕ©©ÞºüþÜäµÇºÞâ¢Úù«ÚóÿÕîàµï¼þ║┐þ¿ïµ▒áþÜäõ╝ÿÕîûÒÇüµò░µì«Õ║ôÞ┐×µÄѵ▒áþ«íþÉåÒÇüþ╝ôÕ¡ÿþ¡ûþòÑþÜäÞ«¥Õ«ÜÒÇüõ╗úþáüþ║ºÕê½þÜäµòêþÄçÚù«Úóÿ´╝êÕªéÞ┐çÕ║ªþÜä...
ÚÇÜÞ┐çÚÿàÞ»╗ÒÇèJavaÕ©©ÞºüÚØóÞ»òÚóÿ.docÒÇïÒÇüÒÇèJavaÚØóÞ»òÚóÿ1.htmÒÇïÒÇüÒÇè5559.htmÒÇïÒÇüÒÇèJavaÚØóÞ»òÚóÿ2.htmÒÇïÒÇüÒÇèjavaÚØóÞ»òþ¼öÞ»òÚóÿÕñºµ▒çµÇ╗ ÕÅèc-c++ÚØóÞ»òÞ»òÚóÿ(Þ¢¼Þ¢¢ ) - happyfish - BlogJava.mhtÒÇïõ╗ÑÕÅèÒÇèJavaÕ©©ÞºüÚØóÞ»òÚóÿ.txtÒÇïþ¡ëµûçõ╗´╝îµé¿...
HotspotÕ«×þÄ░õ║åJavaÕåàÕ¡ÿµ¿íÕ×ï´╝êJMM´╝ë´╝îþí«õ┐Øõ║åÕñÜþ║┐þ¿ïþÄ»Õóâõ©ïþÜäµò░µì«õ©ÇÞç┤µÇºÒÇéÕ«âÕ«Üõ╣ëõ║åÕÅÿÚçÅÞ«┐Úù«ÞºäÕêÖÒÇüþ║┐þ¿ïõ║ñõ║ÆÞºäÕêÖõ╗ÑÕÅèÕåàÕ¡ÿÕŻ޺üµÇº´╝îþí«õ┐Øõ║åÕ╣ÂÕÅæþ╝ûþ¿ïþÜ䵡úþí«µÇºÒÇé 5. **þ▒╗ÕèáÞ¢¢µ£║ÕêÂ** HotspotÚüÁÕ¥¬ÕÅîõ║▓Õºöµëÿµ¿íÕ×ïÞ┐øÞíîþ▒╗ÕèáÞ¢¢´╝îõ╗Ä...
ÕåàÕ¡ÿµ║óÕç║Õêåµ×ÉÕÀÑÕàÀÒÇüõ©¥õ¥ïÕêåµ×Édumpõ©ïþÜähprofµûçõ╗ Shallow Heap ´╝Üõ©Çõ©¬Õ»╣Þ▒íµëÇÕìáþö¿þÜäÕåàÕ¡ÿ´╝îõ©ìÕîàÕɽջ╣ÕàÂõ╗ûÕ»╣Þ▒íþÜäÕ╝òþö¿ Retained Heap ´╝ܵÿ»shallow HeapþÜäµÇ╗ÕÆî´╝êÕìòõ©¬Õ»╣Þ▒íÕìáþö¿ÕåàÕ¡ÿ*µ¡ñÕ»╣Þ▒íþÜäõ©¬µò░´╝ë´╝îõ╣ƒÕ░▒µÿ»Þ»ÑÕ»╣Þ▒íÞó½GCõ╣ïÕÉĵëÇÞâ¢...
4. **ÕåàÕ¡ÿþ«íþÉå**´╝ÜJNAÞ┤ƒÞ┤úÕåàÕ¡ÿþ«íþÉå´╝îÚü┐Õàìõ║åJNIõ©¡þÜäÕåàÕ¡ÿµ│äµ╝ÅÚù«ÚóÿÒÇé **JNIÞ»ªÞºú** þø©µ»öõ╣ïõ©ï´╝îJNIµÿ»JavaÕ╣│ÕÅ░µáçÕçåþÜäõ©ÇÚâ¿Õêå´╝îµÅÉõ¥øõ║åõ©Äµ£¼Õ£░õ╗úþáüõ║ñõ║ÆþÜäÕ║òÕ▒éµÄÑÕÅúÒÇéÞÖ¢þäÂÕ«âµÅÉõ¥øõ║åµø┤þüÁµ┤╗þÜäµÄºÕê´╝îõ¢åÕ¡ªõ╣áµø▓þ║┐Þ¥âÚÖíÕ│¡´╝îÕøáõ©║Õ╝ÇÕÅæÞÇà...
7. **jvisualvm**´╝ÜÚøåµêÉÕ£¿JDKõ©¡þÜäÕñÜÕÉêõ©ÇJavaÕ║öþö¿µÇºÞâ¢Õêåµ×ÉÕÀÑÕàÀ´╝îµÅÉõ¥øõ©░Õ»îþÜäÕŻ޺åÕîûµò░µì«´╝îÕîàµï¼CPUÒÇüÕåàÕ¡ÿÒÇüþ║┐þ¿ïþ¡ëÒÇé 8. **jmap**´╝Üþö¿õ║ÄþöƒµêÉÕáåÞ¢¼Õ鿵ûçõ╗´╝êheap dump´╝ë´╝îÕ©«Õè®Õêåµ×ÉÕåàÕ¡ÿµ│äµ╝ÅÒÇéõ¥ïÕªé´╝î`jmap -dump:format=b,...
Nginxõ╗ÑÕàÂÚ½ÿµÇºÞâ¢ÕÆîõ¢ÄÕåàÕ¡ÿÕìáþö¿ÞÇîÞæùÕÉì´╝îÚÇéÕÉêÕñäþÉåÚ½ÿÕ╣ÂÕÅæÕ£║µÖ»´╝øÞÇîApacheÕêÖõ╗ÑÕàÂþüÁµ┤╗µÇºÕÆîÕ╣┐µ│øþÜ䵿íÕØùµö»µîüÕÅùÕê░ÚØÆþØÉÒÇé 2. **Õ║öþö¿µ£ìÕèíÕÖ¿**´╝ÜÕ»╣õ║ÄÕ迵ÇüÕåàÕ«╣ÕñäþÉå´╝îÕ║öþö¿µ£ìÕèíÕÖ¿ÕªéTomcat´╝êJava´╝ëµêûPassenger´╝êRuby on Rails´╝ëµÿ»µá©Õ┐â...
Sparkµÿ»Apache HadoopþöƒµÇüþ│╗þ╗ƒõ©¡þÜäõ©Çõ©¬Õ┐½ÚǃÒÇüÚÇÜþö¿õ©öÕÅ»µë®Õ▒òþÜäÕñºµò░µì«ÕñäþÉåµíåµ×´╝îÕ«âõ╗ÑÕàÂÚ½ÿµòêþÜäÕåàÕ¡ÿÞ«íþ«ùÕÆîDAG´╝êµ£ëÕÉæµùáþÄ»Õø¥´╝ëµëºÞííÕ×ïÞÇîÚù╗ÕÉìÒÇéSparkµÅÉõ¥øõ║åÕñÜþºìAPI´╝îÕîàµï¼ScalaÒÇüJavaÒÇüPythonÕÆîR´╝îõ¢┐Õ¥ùÕ╝ÇÕÅæõ║║ÕæÿÕÅ»õ╗ѵû╣õ¥┐Õ£░...
ÕŪõ©Çþºìµø┤þÄ░õ╗úÒÇüµø┤Ú½ÿµòêþÜäµû╣µ│òµÿ»õ¢┐þö¿þ¼¼õ©ëµû╣Õ║ô´╝îÕªéSpire.DocµêûApache POI´╝êÚÆêÕ»╣.NETþÜäJavaÕ║ôþÜäþº╗µñì´╝ëÒÇé "DocMerger.cs"µûçõ╗ÂÕ¥êÕÅ»Þ⢵ÿ»õ©Çõ©¬Þç¬Õ«Üõ╣ëþÜäC#þ▒╗´╝îþö¿õ║ÄÕ«×þÄ░WordµûçµíúþÜäÕÉêÕ╣ÂÕèƒÞâ¢ÒÇéÞ┐Öõ©¬þ▒╗ÕÅ»Þâ¢ÕîàÕɽõ╗Ñõ©ïÕà│Úö«þ╗äõ╗´╝Ü 1. ...
Õ¥êþ«ÇÕìòõ©Çõ©¬µ¿íÕ╝Å,Õ░▒µÿ»Õ£¿ÕåàÕ¡ÿõ©¡õ┐ØþòÖÕăµØѵò░µì«þÜäµïÀÞ┤Ø. Þ«¥Þ«íµ¿íÕ╝Åõ╣ï Interpreter(ÞºúÚçèÕÖ¿) õ©╗Þªüþö¿µØÑÕ»╣Þ»¡Þ¿ÇþÜäÕêåµ×É,Õ║öþö¿µ£║õ╝Üõ©ìÕñÜ. Þ«¥Þ«íµ¿íÕ╝Åõ╣ï Visitor(Þ«┐Úù«ÞÇà) Þ«┐Úù«ÞÇàÕ£¿Þ┐øÞíîÞ«┐Úù«µùÂ,Õ«îµêÉõ©Çþ│╗ÕêùÕ«×Þ┤¿µÇºµôìõ¢£,ÞÇîõ©öÞ┐ÿÕÅ»õ╗ѵë®Õ▒ò. ...
ÚÖñõ║åõ╗Ñõ©èÕåàÕ«╣´╝îµûçµíúÞ┐ÿÕÅ»Þ⢵ÂÁþøûõ║åµø┤ÕñÜõ©╗Úóÿ´╝îÕªéÞ«¥Õñ絿íµïƒÒÇüµëôÕîàõ©ÄÚâ¿þ¢▓ÒÇüµÇºÞâ¢Õêåµ×ÉÒÇüÕåàÕ¡ÿþ«íþÉåõ╗ÑÕÅèEclipse MEþÜäÚ½ÿþ║ºþë╣µÇºþ¡ë´╝îÞ┐Öõ║øÚ⢵ÿ»J2MEÕ╝ÇÕÅæõ©¡þÜäÕà│Úö«þÄ»ÞèéÒÇé µÇ╗þÜäµØÑÞ»┤´╝îÒÇèEclipse ME õ©¡µûçµûçµíúÒÇïµÿ»J2MEÕ╝ÇÕÅæÞÇàþÜäÚçìÞªüÕÅéÞÇâ...
ÕìüÕà¡Þ┐øÕêÂþ╝ûÞ¥æÕÖ¿µÿ»õ©ÇþºìÕàüÞ«©µé¿µƒÑþ£ïÕÆîþ╝ûÞ¥æõ║îÞ┐øÕêµûçõ╗Âõ©¡õ©¬Õê½ Õ¡ùÞèéþÜäþ¿ïÕ║Å´╝îÞÇîÚ½ÿþ║ºþÜäÕìüÕà¡Þ┐øÕêÂþ╝ûÞ¥æÕÖ¿´╝êÕîàµï¼ 010 Editor´╝ëÞ┐ÿÕàüÞ«©µé¿þ╝ûÞ¥æþí¼þøÿÚ®▒Õè¿ÕÖ¿ÒÇüÞ¢»þøÿÚ®▒Õè¿ÕÖ¿ÒÇüÕåàÕ¡ÿÕ»åÚÆÑÒÇüÚù¬Õ¡ÿÚ®▒Õè¿ÕÖ¿ÒÇüÕàëÚ®▒ÕÆîÞ┐øþ¿ïõ©¡þÜäÕ¡ùÞèéÒÇé SweetScape 010 ...