
memcache虽然是分布式的应用服务,但分布的原则是由client端的api来决定的,api根据存储用的key以及已知的服务器列表,根据key的hash计算将指定的key存储到对应的服务器列表上。
通常使用的散列方法是根据 key的hash值%服务器数取余数的方法来决定当前这个key的内容发往哪一个memcache服务器。但这样的算法在服务实例本身发生变动的时候,服务列表的变动会造成几乎大部分数据都会需要迁移到另外的服务实例上。这样在大型服务在线时,瞬时对后端数据库/硬盘照成的压力很可能导致整个服务的crash。
在此可以采用一致性哈希(Consistent Hashing)来解决这个问题,处理服务器的选择不再仅仅依赖key的hash本身而是将服务实例(节点)的配置也进行hash运算。
一致性哈希(Consistent Hashing)算法简述如下:
1. 求出每个服务节点的hash,并将其配置到一个0~2^32的圆环(continuum)区间上。
2. 使用同样的方法求出你所需要存储的key的hash,也将其配置到这个圆环(continuum)上。
3. 从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务节点上。如果超过2^32仍然找不到服务节点,就会保存到第一个服务节点上。
整个数据的图例: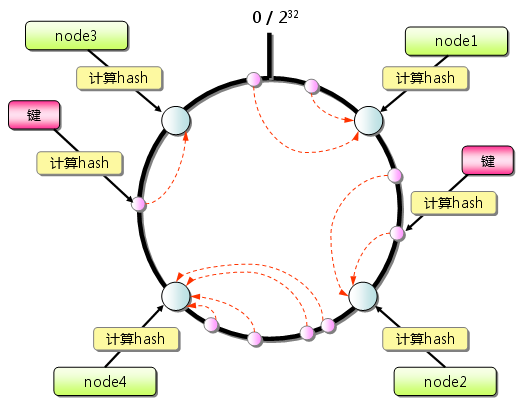
当增加服务器节点时: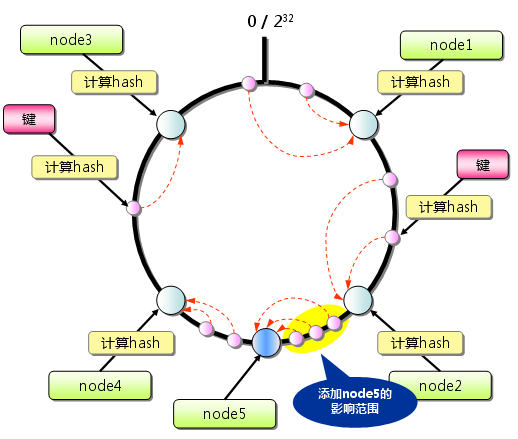
这样做可以最大程度的避免了key在服务节点列表上的重新分布,同时还增加了虚拟服务节点的方法,也就是一个服务节点在环上有多个映射点,这样就能抑制分布不均匀,最大限度地减小服务节点增减时的缓存重新分布。具体来说,只有在圆环上增加服务节点的位置为逆时针方向的第一个服务节点上的键会受到影响。
以下部分为一致性哈希算法的一种PHP实现。
from: http://paul.annesley.cc/
comment: http://blog.csdn.net/mayongzhan/
<?php
/**
* Flexihash - A simple consistent hashing implementation for PHP.
*
* The MIT License
*
* Copyright (c) 2008 Paul Annesley
*
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in
* all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
* THE SOFTWARE.
*
* @author Paul Annesley
* @link http://paul.annesley.cc/
* @copyright Paul Annesley, 2008
* @comment by MyZ (http://blog.csdn.net/mayongzhan/)
*/
/**
* A simple consistent hashing implementation with pluggable hash algorithms.
*
* @author Paul Annesley
* @package Flexihash
* @licence http://www.opensource.org/licenses/mit-license.php
*/
class Flexihash {
/**
* The number of positions to hash each target to.
*
* @var int
* @comment 虚拟节点数,解决节点分布不均的问题
*/
private $_replicas = 64;
/**
* The hash algorithm, encapsulated in a Flexihash_Hasher implementation.
* @var object Flexihash_Hasher
* @comment 使用的hash方法 : md5,crc32
*/
private $_hasher;
/**
* Internal counter for current number of targets.
* @var int
* @comment 节点记数器
*/
private $_targetCount = 0;
/**
* Internal map of positions (hash outputs) to targets
* @var array { position => target, ... }
* @comment 位置对应节点,用于lookup中根据位置确定要访问的节点
*/
private $_positionToTarget = array();
/**
* Internal map of targets to lists of positions that target is hashed to.
* @var array { target => [ position, position, ... ], ... }
* @comment 节点对应位置,用于删除节点
*/
private $_targetToPositions = array();
/**
* Whether the internal map of positions to targets is already sorted.
* @var boolean
* @comment 是否已排序
*/
private $_positionToTargetSorted = false;
/**
* Constructor
* @param object $hasher Flexihash_Hasher
* @param int $replicas Amount of positions to hash each target to.
* @comment 构造函数,确定要使用的hash方法和需拟节点数,虚拟节点数越多,分布越均匀,但程序的分布式运算越慢
*/
public function __construct(Flexihash_Hasher $hasher = null, $replicas = null) {
$this->_hasher = $hasher ? $hasher : new Flexihash_Crc32Hasher();
if (!emptyempty($replicas)) {
$this->_replicas = $replicas;
}
}
/**
* Add a target.
* @param string $target
* @chainable
* @comment 添加节点,根据虚拟节点数,将节点分布到多个虚拟位置上
*/
public function addTarget($target) {
if (isset($this->_targetToPositions[$target])) {
throw new Flexihash_Exception("Target '$target' already exists.");
}
$this->_targetToPositions[$target] = array();
// hash the target into multiple positions
for ($i = 0; $i < $this->_replicas; $i++) {
$position = $this->_hasher->hash($target . $i);
$this->_positionToTarget[$position] = $target; // lookup
$this->_targetToPositions[$target] []= $position; // target removal
}
$this->_positionToTargetSorted = false;
$this->_targetCount++;
return $this;
}
/**
* Add a list of targets.
* @param array $targets
* @chainable
*/
public function addTargets($targets) {
foreach ($targets as $target) {
$this->addTarget($target);
}
return $this;
}
/**
* Remove a target.
* @param string $target
* @chainable
*/
public function removeTarget($target) {
if (!isset($this->_targetToPositions[$target])) {
throw new Flexihash_Exception("Target '$target' does not exist.");
}
foreach ($this->_targetToPositions[$target] as $position) {
unset($this->_positionToTarget[$position]);
}
unset($this->_targetToPositions[$target]);
$this->_targetCount--;
return $this;
}
/**
* A list of all potential targets
* @return array
*/
public function getAllTargets() {
return array_keys($this->_targetToPositions);
}
/**
* Looks up the target for the given resource.
* @param string $resource
* @return string
*/
public function lookup($resource) {
$targets = $this->lookupList($resource, 1);
if (emptyempty($targets)) {
throw new Flexihash_Exception('No targets exist');
}
return $targets[0];
}
/**
* Get a list of targets for the resource, in order of precedence.
* Up to $requestedCount targets are returned, less if there are fewer in total.
*
* @param string $resource
* @param int $requestedCount The length of the list to return
* @return array List of targets
* @comment 查找当前的资源对应的节点,
* 节点为空则返回空,节点只有一个则返回该节点,
* 对当前资源进行hash,对所有的位置进行排序,在有序的位置列上寻找当前资源的位置
* 当全部没有找到的时候,将资源的位置确定为有序位置的第一个(形成一个环)
* 返回所找到的节点
*/
public function lookupList($resource, $requestedCount) {
if (!$requestedCount) {
throw new Flexihash_Exception('Invalid count requested');
}
// handle no targets
if (emptyempty($this->_positionToTarget)) {
return array();
}
// optimize single target
if ($this->_targetCount == 1) {
return array_unique(array_values($this->_positionToTarget));
}
// hash resource to a position
$resourcePosition = $this->_hasher->hash($resource);
$results = array();
$collect = false;
$this->_sortPositionTargets();
// search values above the resourcePosition
foreach ($this->_positionToTarget as $key => $value) {
// start collecting targets after passing resource position
if (!$collect && $key > $resourcePosition) {
$collect = true;
}
// only collect the first instance of any target
if ($collect && !in_array($value, $results)) {
$results []= $value;
}
// return when enough results, or list exhausted
if (count($results) == $requestedCount || count($results) == $this->_targetCount) {
return $results;
}
}
// loop to start - search values below the resourcePosition
foreach ($this->_positionToTarget as $key => $value) {
if (!in_array($value, $results)) {
$results []= $value;
}
// return when enough results, or list exhausted
if (count($results) == $requestedCount || count($results) == $this->_targetCount) {
return $results;
}
}
// return results after iterating through both "parts"
return $results;
}
public function __toString() {
return sprintf(
'%s{targets:[%s]}',
get_class($this),
implode(',', $this->getAllTargets())
);
}
// ----------------------------------------
// private methods
/**
* Sorts the internal mapping (positions to targets) by position
*/
private function _sortPositionTargets() {
// sort by key (position) if not already
if (!$this->_positionToTargetSorted) {
ksort($this->_positionToTarget, SORT_REGULAR);
$this->_positionToTargetSorted = true;
}
}
}
/**
* Hashes given values into a sortable fixed size address space.
*
* @author Paul Annesley
* @package Flexihash
* @licence http://www.opensource.org/licenses/mit-license.php
*/
interface Flexihash_Hasher {
/**
* Hashes the given string into a 32bit address space.
*
* Note that the output may be more than 32bits of raw data, for example
* hexidecimal characters representing a 32bit value.
*
* The data must have 0xFFFFFFFF possible values, and be sortable by
* PHP sort functions using SORT_REGULAR.
*
* @param string
* @return mixed A sortable format with 0xFFFFFFFF possible values
*/
public function hash($string);
}
/**
* Uses CRC32 to hash a value into a signed 32bit int address space.
* Under 32bit PHP this (safely) overflows into negatives ints.
*
* @author Paul Annesley
* @package Flexihash
* @licence http://www.opensource.org/licenses/mit-license.php
*/
class Flexihash_Crc32Hasher
implements Flexihash_Hasher {
/* (non-phpdoc)
* @see Flexihash_Hasher::hash()
*/
public function hash($string) {
return crc32($string);
}
}
/**
* Uses CRC32 to hash a value into a 32bit binary string data address space.
*
* @author Paul Annesley
* @package Flexihash
* @licence http://www.opensource.org/licenses/mit-license.php
*/
class Flexihash_Md5Hasher
implements Flexihash_Hasher {
/* (non-phpdoc)
* @see Flexihash_Hasher::hash()
*/
public function hash($string) {
return substr(md5($string), 0, 8); // 8 hexits = 32bit
// 4 bytes of binary md5 data could also be used, but
// performance seems to be the same.
}
}
/**
* An exception thrown by Flexihash.
*
* @author Paul Annesley
* @package Flexihash
* @licence http://www.opensource.org/licenses/mit-license.php
*/
class Flexihash_Exception extends Exception {
}



相关推荐
在分布式系统中,常常需要使用缓存,而且通常是集群,访问缓存和添加缓存都需要一个 hash 算法来寻找到合适的 Cache 节点。但,通常不是用取余hash,而是使用我们今天的主角—— 一致性 hash 算法。
总之,`ConsistentHashing`是一个用于Python的工具,它实现了高效的一致性哈希算法,有助于构建稳定、可扩展的分布式系统。对于处理大数据量、高并发场景以及需要动态扩展的系统,这个库是十分实用的。
一致性哈希算法(Consistent Hashing)是一种在分布式系统中平衡数据分布的策略,尤其适用于缓存服务如Memcached或Redis。它的核心思想是通过哈希函数将对象映射到一个固定大小的环形空间中,然后将服务器也映射到这个...
一致性哈希算法(Consistent Hashing)是一种在分布式系统中实现负载均衡的算法,尤其在分布式缓存如Memcached和Redis等场景下广泛使用。它解决了传统哈希算法在节点增减时导致的大量数据迁移问题,提高了系统的可用...
一致性哈希(Consistent Hashing)是一种用于分布式系统的哈希算法,主要应用于分布式缓存、分布式数据库等场景,目的是在节点动态增减时保持哈希表的稳定性,从而最小化数据迁移的影响。它解决了传统哈希取模方法在...
一致性哈希算法
一致性哈希(Consistent Hashing)是一种分布式哈希算法,主要应用于分布式缓存、负载均衡等领域,例如Memcached和Redis等系统。它解决了在分布式环境中数据分片与节点动态增减时,尽量减少数据迁移的问题。带虚拟...
一致性哈希(Consistent Hashing)是一种特殊的哈希算法,它在分布式缓存和负载均衡等场景中被广泛应用。它通过将数据和服务器节点映射到一个哈希环上,提供了一种在节点增减时能够最小化数据重新分配的机制。本文将...
一致性哈希算法(Consistent Hashing)是一种常用于分布式系统中的数据分片策略,它有效地解决了数据在多台服务器间均匀分布的问题,同时减少了因节点加入或离开时的数据迁移成本。 首先,一致性哈希的基本原理是将...
“ConsistentHashingandRandomTrees: Distributed Caching Protocols for Relieving Hot Spots on the Worldwide Web”指的是由David Karger等人撰写的关于一致性哈希算法(Consistent Hashing)以及如何运用该算法...
一致性哈希(Consistent Hashing)是一种分布式哈希表(DHT)的算法,它主要应用于分布式缓存、负载均衡等场景,旨在解决在动态扩展或收缩系统规模时,尽量减少数据迁移的问题。在这个简单的实现中,我们将探讨如何...
一致性哈希(Consistent Hashing)是一种分布式哈希算法,主要应用于分布式缓存、负载均衡等领域,例如在Redis、Memcached等系统中广泛使用。它解决了传统哈希算法在节点动态增减时导致的大量数据迁移问题。在Java中...
一致性哈希(Consistent Hashing)是一种分布式哈希算法,主要应用于分布式缓存、负载均衡等领域,以解决在分布式环境中动态添加或删除节点时,尽可能少地改变已有的哈希映射关系。在这个Java实现中,我们看到的是...
跳跃一致哈希计算 甚至服务器之间的数据分布也非常重要:另一个重要方面是能够... 关于一致性哈希,使用的算法是谷歌的论文“A Fast, Minimal Memory, Consistent Hash Algorithm”中提出的Jump Consistent Hashing。
一致性哈希(Consistent Hashing)是一种在分布式系统中解决数据分片问题的算法,它在Go语言中的实现对于构建可扩展且容错的服务至关重要。在Go开发中,尤其是在涉及分布式缓存、负载均衡等场景下,一致性哈希能够...