- 浏览: 153552 次
- 性别:

- 来自: 郑州
-

文章分类
最新评论
-
loveseaside:
db2v9.1
db2许可证 -
uglypeak:
不对,你这个是哪个版本的??
db2许可证 -
uglypeak:
试过了,不行啊~~
db2许可证 -
yingjun055:
怎么样能修改后,能实时生效呢?
java 读取配置文件的例子
在本文中将介绍 DB2 V9.7 中的新功能 - 分区索引,如何使用和管理分区索引,以及分区索引如何改进大型数据库性能。
简介
分区索引(partitioned index)是 DB2 V9.7 中的新特性,在本文中将介绍什么是分区索引,如何创建和管理分区索引,分区索引如何改进大型数据库性能,读者将获得对分区索引的第一手体验。每个分区索引由多个索引分区(index partition)组成,每个索引分区只对相应的数据分区(data partition)的数据作索引。
开始之前
在开始讨论分区索引之前我们有必要复习一下 DB2 的表分区特性,这一特性是在 DB2 V9 引入的,developerworks 上的这篇文章 “ DB2 9 表分区 - 改进大型数据库的管理” 是一个很好的参考。
表分区是一种数据组织模式,在这种模式中,数据将以一个或多个表列的值为依据,分割到多个称为数据分区(或范围)的存储对象中。每一个数据分区被分别存储。这些存储对象可以位于不同的表空间中,可以位于相同的表空间中,也可能是这两种情况的组合。
表分区特性改进了大型数据库的管理,用户可以灵活的放置索引,在图 1 中,在分区表上建立了两个索引,每个索引分别放置在一个表空间中。但是我们同时也看到,每一个索引中的键值指向了所有数据分区的数据库,在表数据量很大的情况索引也会变得很大。
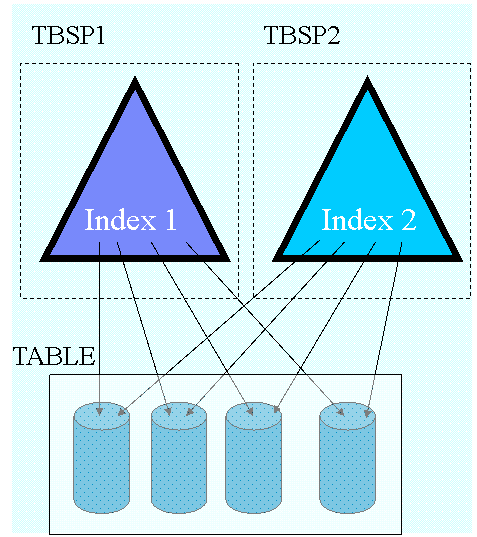 |
图 1. DB2 v9 中表分区特性及其索引
另外,表分区特性使得用户可以使用 ALTER TABLE … ATTACH PARTITION 命令和 DETACH PARTITION 命令轻易的实现表数据的转入( roll-in )和转出( roll-out) ,这两个操作都不需要有任何数据的移动,从而很大的提高性能。同时我们也看到,这两个操作之后需要对索引进行维护,例如 ATTACH 一个新的分区之后需要为这个分区的新数据进行索引, DETACH 一个分区之后需要将索引中相应的键值清除。
分区索引简介
在 DB2 V9.7 之前,分区表上的索引是不能分区的。由于分区表很多情况都是应用在数据仓库环境中,当数据量很大的时候,索引也随之变得很大,从而导致一些的性能上降低。
在 DB2 V9.7 中,索引也可以是分区的,这一特性称之为分区索引(partitioned index)。分区索引由多个索引分区(index partition)组成,每个索引分区中的键值指向相应的唯一一个数据分区(data partition)的数据,系统创建的索引或者用户的创建的索引都可以是分区索引。
在图 2 中,在一个有 4 个数据分区的分区表上建立了三个索引,其中 index1 和 index2 是分区索引,分别由 4 个索引分区组成,index3 是非分区索引(nonpartitioned index),或者称之为全局索引(global index),相对应的,我们可以把分区索引称为本地索引(local index)。
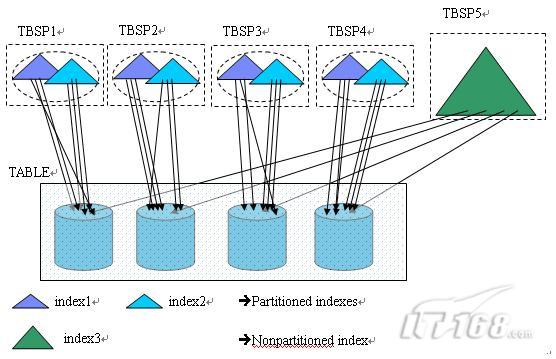 |
图 2. DB2 V9.7 中的分区索引
分区索引带来的一个显著优势在于,在使用 ALTER TABLE ATTACH PARTITION 和 DETAICH PARTITION 命令进行数据的转入( roll-in )和转出( roll-out) 时, 使用分区索引能够很大程度的提高性能。
在 DB2 V9.7 中,以下类型的索引不能是分区索引,只能是非分区索引。
XML 索引
空间数据( spatial data )索引
MDC 块索引( block index ,系统生成索引)
XML path index (系统生成索引)
准备工作
在开始之前,我们先创建一个新的数据库名字叫做 MYDB,如清单 1 所示。当然用已经存在的数据库也可以,但是为了能够简化环境,清楚的、逐步的进行我们接下来的讨论,建议使用一个全新的数据库。
本文中所有操作都是在 LinuxAMD64 平台上的 DB2 V97 版本进行,V97 版本之前的版本都没有分区索引特性。
清单 1. 创建数据库
db2 CREATE DB mydb
创建数据库之后我们创建若干个表空间,如清单 2 所示。
清单 2. 创建表空间
CREATE TABLESPACE TbspT MANAGED BY DATABASE using (FILE 'tspT' 4 M) AUTORESIZE YES;
CREATE TABLESPACE TbspX MANAGED BY DATABASE using (FILE 'tspX' 4 M) AUTORESIZE YES;
CREATE TABLESPACE TbspD MANAGED BY DATABASE using (FILE 'tspD' 4 M) AUTORESIZE YES;
CREATE TABLESPACE TbspY MANAGED BY DATABASE using (FILE 'tspY' 4 M) AUTORESIZE YES;
CREATE TABLESPACE TbspW MANAGED BY DATABASE using (FILE 'tspW' 4 M) AUTORESIZE YES;
创建分区表
首先创建一个分区表,V9.7 中的分区索引特性为 CREATE TABLE 语法引入了新的子句,即分区级的 INDEX IN 子句。在创建分区表时,我们可以通过表级的 INDEX IN <tablespace> 来指定非分区索引的存放位置,同时可以通过分区级的 INDEX IN <tablespace> 为每一个数据分区对应的索引分区指定单独的表空间。如果没有对于某一个或者多个数据分区指定索引分区的存放表空间,默认是将索引分区存放在与数据分区相同的表空间内。
使用如清单 3 所示的语句创建一个分区表 datapartT,包括 5 个分区。
清单 3. 创建分区表
CREATE TABLE datapartT (a int, b int )IN TbspT INDEX IN TbspXPARTITION BY ( a,b )
(
PARTITION Part0 STARTING (0, 0) ENDING (0, 10)IN TbspD,
PARTITION Part1 ENDING (20,20)INDEX IN TbspY,
PARTITION Part2 ENDING (40,40)INDEX IN TbspW,
PARTITION Part3 STARTING (100,100) ENDING (150, 150)
INDEX IN TbspW,PARTITION Part4 ENDING (200, 200) );
创建分区索引
在 DB2 V9.7 中,创建索引的语法增加了两个保留字 PARTITIONED 和 NOT PARTITIONED,分别用来创建分区索引和非分区索引。如果在创建索引时没有指定这两个保留字中任何一个,默认将建立分区索引。这就意味着,当用户在 DB2 V9.7 上使用于之前相同的语句创建索引时,事实上 DB2 数据库管理系统自动的为用户应用了分区索引这一新特性。
我们已经知道,在 DB2 V9.7 之前,在分区表上创建索引(非分区索引)时可以使用“ CREATE INDEX … ON … IN <tablespace> ”语法将索引放到不同的表空间中,如图 1 所示。在 DB2 V9.7 中,我们仍然可以使用类似语句将非分区索引放到不同的表空间中,而对于分区索引,不允许在创建索引时指定“ IN <tablespace> ”子句,这是因为分区索引的特性,每个索引分区的存放位置取决于创建分区表时分区级“ INDEX IN <tablespace> ”子句,如果某个数据分区没有指定该字句,则相应的索引分区将存放在与数据分区相同的表空间中。
创建索引的语句如清单 4 所示,这里创建了两个分区索引 purpleidx 和 greenidx,以及一个非分区的索引 blueidx 。
清单 4. 创建分区索引以及非分区索引
CREATE INDEX purpleidx on datapartT(a,b) PARTITIONED;
CREATE INDEX greenidx on datapartT(b) PARTITIONED;
CREATE INDEX blueidx on datapartT(a) NOT PARTITIONED;
此时分区表 datapartT 中各个数据分区和索引的存放如图 3 所示。
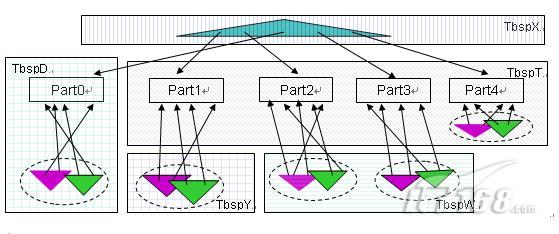 |
图 3. 分区表上分区索引和非分区索引的存放
在图 3 中, 分区 Part0,在创建表时指定了“ IN TbspD ”,没有分区级的 INDEX IN 子句,于是 Part0 的数据分区放在表空间 TbspD 中,相应的索引分区存放在相同的表空间 TbspD 中。
分区 Part1,在创建表时没有指定分区级的 IN 子句,但是由于存在表级的“ IN TbspT ”,于是 Part1 的数据分区放在 TbspT,同时对于 Part1 指定了分区级的“ INDEX IN TbspY ”,于是 Part1 相应的索引分区放在表空间 TbspY 上。
分区 Part2 和 Part3,都没有指定分区级 IN 字句,都有分区级的“ INDEX IN TbspW ”,于是这两个数据分区放在表空间 TbspT,相应的索引分区放在表空间 TbspW 中。
分区 Part4,即没有指定分区级的 IN 子句,也没有指定分区级的 INDEX IN 子句,于是这个数据分区放在表级“ IN TbspT ”所指定的表空间 TbspT 中,索引分区放在与数据分区相同的表空间 TbspT 中。
对于非分区索引 blueidx,在创建索引没有指定 IN 子句,根据规则这个索引将存放在创建表时的表级 INDEX IN 子句所指定的表空间中,即 TbspX 。
分区索引管理
在这里我们来介绍如何维护分区索引,包括
如何判断分区索引
如何取得分区索引的信息
如何把非分区索引移植为分区索引。
如何判断分区索引
对于已经存在的数据库中的索引,我们如何判断是分区索引或非分区索引,可以通过 DB2 提供的命令 DESCRIBE INDEXES 来判断,使用的命令和结果如清单 5 所示。
清单 5. 用 DESCRIBE 命令查看是否为分区索引
db2 describe indexes for table datapartt
Index Index Unique Number of Index Index
schema name rule columns type partitioning
------ ------ ------ ------- --------- --------
TESTUSERS PURPLEIDX D 2 RELATIONAL DATA P
TESTUSERS GREENIDX D 1 RELATIONAL DATA P
TESTUSERS BLUEIDX D 1 RELATIONAL DATA N 3 record(s) selected.
在 DESCRIBE INDEXES 的输出中有一列“ Index partitioning ”,“ P ”表示该索引为分区表上的分区索引,“ N ”表示该索引为分区表上的非分区索引。如果所指定的不是分区表,对于表上的索引 DESCRIBE 将输出“ _ ”。
如何取得分区索引的信息
在故障诊断和数据恢复时,我们需要获得表和索引的一些基本信息,除了表名、索引名之外我们经常需要获得表和索引的对象 ID(object ID),表空间 ID 以及其他的信息,其中对象 ID 和表空间 ID 是两个最重要的信息,可以用来唯一标识数据库中的一个对象。
我们可以通过熟知的 CATALOG 表中获取相应信息,我们已经知道,对于表和索引的基本信息,可以分别查询 SYSCAT.TABLES 和 SYSCAT.INDEXES 。查询语句和输出结果如清单 6 所示。
清单 6. 查询 CATALOG 表获取表和索引信息
select substr(tabname, 1,10) tabname, TABLEID ,TBSPACEID
from syscat.tables where tabname='DATAPARTT'
TABNAME TABLEID TBSPACEID
---------- ------- ---------
DATAPARTT -32768
-6 1 record(s) selected.
select substr(TABNAME, 1,10)TABNAME,SUBSTR(INDNAME, 1, 10)
INDNAME, INDEXTYPE, TBSPACEID, INDEX_OBJECTID
from syscat.indexes where tabname='DATAPARTT'
TABNAME INDNAME INDEXTYPE TBSPACEID INDEX_OBJECTID
---------- ---------- --------- ----------- --------------
DATAPARTT PURPLEIDX REG 65530
32768
DATAPARTT GREENIDX REG 65530
32768
DATAPARTT BLUEIDX REG 10
4 3 record(s) selected.
对于分区表,从 SYSCAT.TABLES 中获取到的对象 ID 和表空间 ID 是逻辑 ID(-32768, -6),并不是表空间存储中真正的 ID,也并不存在这样一个物理的对象,这是因为分区表是由若干个数据分区组成的,每一个分区分别对应一个表空间中的数据对象。
类似的,对于分区索引从 SYSCAT.INDEXES 中获取到的对象 ID 和表空间 ID 也是逻辑 ID(65530, 32768),同样原因是因为分区索引是由若干个索引分区组成,每个索引分区分别对应着一个表空间的索引对象。
我们可以通过查询 SYSCAT.DATAPARTITIONS 来获取每一个数据分区的信息,使用的查询语句和输出的结果如清单 7 所示。
清单 7. 查询 CATALOG 表获取每个数据分区信息
select substr(DATAPARTITIONNAME, 1,10) DATAPARTITIONNAME, PARTITIONOBJECTID,
tbspaceid ,substr(tabname,1,10) tabname
from syscat.datapartitions where tabname='DATAPARTT'
DATAPARTITIONNAME PARTITIONOBJECTID TBSPACEID TABNAME
----------------- ----------------- ----------- ----------
PART0 4 11 DATAPARTT
PART1 4 9 DATAPARTT
PART2 5 9 DATAPARTT
PART3 6 9 DATAPARTT
PART4 7 9 DATAPARTT 5 record(s) selected.
在结果中我们可以看到每一个数据分区都有各自的对象 ID 和表空间 ID,这里的 ID 都是物理 ID,对应一个数据库对象。
对于分区索引的每一个索引分区,在 DB2 V9.7 中有一个新的 CATALOG 表 SYSCAT.INDEXPARTITIONS 来记录其信息,从这个表中我们也可以获取每一个索引分区唯一的对象 ID 和表空间 ID 。使用的查询语句和输出结果如清单 8 所示。
清单 8. 查询 CATALOG 表获取每个索引分区的信息
select substr(TABNAME, 1,10)TABNAME,SUBSTR(INDNAME, 1, 10) INDNAME,
INDPARTITIONTBSPACEID, INDPARTITIONOBJECTID, DATAPARTITIONID
from SYSCAT.INDEXPARTITIONS where tabname='DATAPARTT'
TABNAME INDNAME INDPARTITIONTBSPACEID INDPARTITIONOBJECTID DATAPARTITIONID
------ ----- ------------ ------------ ----------
DATAPARTT PURPLEIDX 11 4 0
DATAPARTT PURPLEIDX 12 4 1
DATAPARTT PURPLEIDX 13 4 2
DATAPARTT PURPLEIDX 13 5 3
DATAPARTT PURPLEIDX 9 7 4
DATAPARTT GREENIDX 11 4 0
DATAPARTT GREENIDX 12 4 1
DATAPARTT GREENIDX 13 4 2
DATAPARTT GREENIDX 13 5 3
DATAPARTT GREENIDX 9 7 4 10 record(s) selected.
在结果中我们发现一个现象,索引 purpleidx 的索引分区 0 对应的对象 ID 和表空间 ID 为(4,11),而索引 greeninx 的索引分区 0 对应的对象 ID 和表空间 ID 也是(4,11),其他的分区也有相同的重复问题,我们在上文也指出每一个对象有唯一的对象 ID 和表空间 ID,这是否矛盾呢?其实,对于每一个数据分区的所有索引分区,都是存放在同一个索引对象中,例如,对于数据分区 Part0,它对应两个索引分区分别是 purpleidx 的分区 0 和 greenidx 的分区 0,这两个索引分区都存放在对象 ID 和表空间 ID 为(4,11)的索引对象里。假如我们继续在这个 datapartT 表上创建更多的分区索引,那数据分区 Part0 相应的所有索引分区都将共享这一个索引对象(4,11)。
<!-- 内容导航 -->
如何把非分区索引移植为分区索引
分区索引是 DB2 V9.7 中的新特性,但是在实际环境中,我们经常需要把数据库从一个之前的 DB2 版本移植到更新的 DB2 版本上来,对于移植到 DB2 V9.7 上的旧数据库来说,其中分区表上的索引都是非分区索引,这种情况下如何将非分区索引移植为分区索引而且要保证索引一直可用?
一个可行的方法是,创建一个分区索引,具有与原有的非分区索引相同的定义,在这个新索引建立的过程中,原有的非分区索引仍然可用,当新索引创建完成之后,删掉原有的非分区索引,最后用命令“ RENAME INDEX … TO … ”把新索引更改为与原有索引相同的名字。这是移植过程全部完成,整个过程中始终有索引可用。提示: DB2 V9.7 中允许在相同的一个或多个列上分别创建一个分区索引和一个非分区索引。
分区索引如何提高性能
之前提到,分区索引带来的一个显著优势在于,在使用 ALTER TABLE ATTACH PARTITION 和 DETAICH PARTITION 命令进行数据的转入( roll-in )和转出( roll-out) 时, 使用分区索引能够很大程度的提高性能。
在使用分区索引特性之前,分区表上的所有索引都是非分区索引,在进行数据的转入( roll-in )和转出( roll-out) 时,需要对索引进行维护,包括在数据的转入时需要在索引中建立新的键值对新数据分区作索引(如图 4 所示),在数据的转出时需要将索引中相应的键值清除(如图 5 所示)。当索引很大的时候,这些维护工作需要非常的代价,将会严重影响数据库系统的性能。
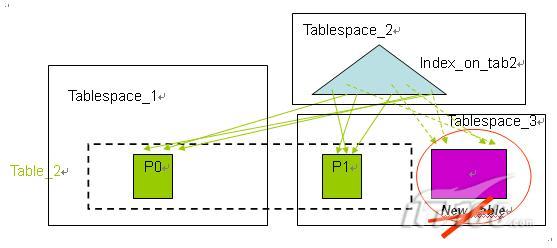 |
图 4. 使用非分区索引时的数据转入
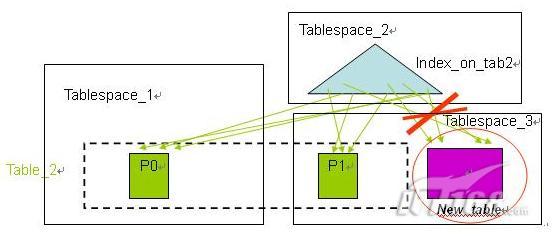 |
图 5. 使用非分区索引时的数据转出
在 DB2 V9.7 上有了分区索引特性,当分区表上只有分区索引时,这时的进行数据的转入和转出变得更加便捷。如图 6 所示,表 SalesTab 有两个数据分区和两个分区索引,表 New_table 是一个相同结构的普通表,并创建了相同定义的两个索引。
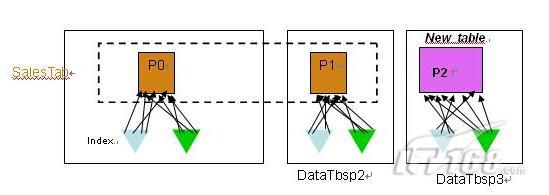 |
图 6. 使用分区索引时的数据转入
当使用数据转入方式把表 New_table 连接(ATTACH)到表 SalesTab 上时,表 New_table 的数据将成为表 SalesTab 的一个数据分区,表 New_table 上的两个索引分别成为表 SalesTab 上分区索引的新的索引分区,然后执行 Set Integrity 命令是所有的数据可用。整个过程不需要任何的数据移动,也不需要大量的索引维护,只需要很少的代价在很短的时间可以完成。类似的,当需要数据转出时,被转出的数据分区成为新表的数据对象,原有的分区索引的索引分区成为新表上的索引。
当然,在实际应用环境中可能遇到一些情况仍然需要对索引进行维护,例如
目标表上的分区索引在源表上没有定义;
源表上的索引与目标表上索引不一致;
目标表上既有分区索引又有非分区索引。
另外, DB2 V9.7 的优化器对分区索引也有相应的处理,能够根据情况选择更加优化的执行计划。限于篇幅以及复杂性,这个主题不在此介绍。
总结
本文可以使读者获得 DB2 V9.7 的分区索引特性的第一手体验,包括什么是分区索引,如何创建和维护分区索引,并且分析了分区索引带来的性能提高。分区索引这一特性,能够给数据仓库、商业智能数据库系统带来性能上的巨大的提高。


发表评论

-
DB2系统命令
2011-08-10 15:11 2645DB2系统命令 1、dasauto在$DB2DIR/da ... -
db2查看当前模式的sql
2011-08-09 15:05 1316通过DB2提供的专用寄存器current sche ... -
db2中会导致表处于reorg pending状态的alter语句
2011-08-09 14:57 5016会导致表处于reorg pending状态的alter tab ... -
db2系统编目表的实践
2011-08-03 15:34 1009一 根据此命令导出全部需要进行统计的表--导出runstats ... -
db2认证
2011-07-19 09:29 1107在这里,我把IBM的认证相关的资料整理下,希望对大家有点帮助。 ... -
db2pd 使用(二)
2011-07-19 09:23 2848分析 DB2 for Linux, UNIX, and ... -
db2pd 使用
2011-07-19 08:53 1437db2pd 工具 用于监控 DB2 实例和数据库的新的 DB ... -
db2的几个有用SQL
2010-11-04 14:47 982--查找函数SELECT * FROM SYSCAT.FUNC ... -
すばらしいnet ---------testpassport問題集のメリット
2010-09-17 14:16 844http://www.testpassport.jp/ ... -
DB2关于查看表空间是否启动了自动存储功能
2010-09-16 11:04 4011可以通过三种方式查看 进入命令行模式 d ... -
DB2约束
2010-09-09 09:53 1184DB2约束 DB2 约束用来对数据实施业务规则,主要 ... -
高级建表SQL
2010-08-16 09:15 890--建表AB 和已知表AA一样create table AB ... -
db2单表优化的命令
2010-08-16 09:04 1038reorg 和runstats 都是单个表优化 ... -
DB2常用语句总结
2010-06-03 16:41 814DB2常用语句 ... -
DB2使用笔记
2010-06-03 15:00 1515DB2使用笔 ... -
db2检索授权的SQL
2010-05-27 10:07 1012--检索具有特权的所有授权名 SELECT DISTINCT ... -
db2许可证
2010-05-27 09:54 1911许可证执行过程 1、windows下启动命令提示符。2、将目 ... -
[转载]DB2表合理映射到表空间
2010-05-26 08:18 1055在DB2数据库中,是� ... -
DB2 DATE 函数的使用一个陷阱
2010-05-19 09:27 4862DB2 DATE 函数的使用一个陷阱 1)DATE 函数正确 ... -
DB2 连接与谓词
2010-05-19 08:37 1125DB2 连接与谓词 ...
相关推荐
目前关于属性操作的创建于编辑主要有新旧两个版本,旧版本主要使用UF_ATTR_assign()函数,新版本主要使用UF_ATTR_set_user_attribute()函数。注意在使用新版本是需要初始化。
编书 机械制图习题集(属性块图框)出版社.dwg
【项目资源】: 物联网项目适用于从基础到高级的各种项目,特别是在性能要求较高的场景中,比如操作系统开发、嵌入式编程和底层系统编程。如果您是初学者,可以从简单的控制台程序开始练习;如果是进阶开发者,可以尝试涉及硬件或网络的项目。 【项目质量】: 所有源码都经过严格测试,可以直接运行。 功能在确认正常工作后才上传。 【适用人群】: 适用于希望学习不同技术领域的小白或进阶学习者。 可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【附加价值】: 项目具有较高的学习借鉴价值,也可直接拿来修改复刻。 对于有一定基础或热衷于研究的人来说,可以在这些基础代码上进行修改和扩展,实现其他功能。 【沟通交流】: 有任何使用上的问题,欢迎随时与博主沟通,博主会及时解答。 鼓励下载和使用,并欢迎大家互相学习,共同进步。 # 注意 1. 本资源仅用于开源学习和技术交流。不可商用等,一切后果由使用者承担。 2. 部分字体以及插图等来自网络,若是侵权请联系删除。
内容概要:本文档提供了三种神经网络控制器(NNPC、MRC和NARMA-L2)在机器人手臂模型上性能比较的MATLAB实现代码及详细解释。首先初始化工作空间并设定仿真参数,包括仿真时间和采样时间等。接着定义了机器人手臂的二阶动力学模型参数,并将其转换为离散时间系统。对于参考信号,可以选择方波或正弦波形式。然后分别实现了三种控制器的具体算法:MRC通过定义参考模型参数并训练神经网络来实现控制;NNPC利用预测模型神经网络并结合优化算法求解控制序列;NARMA-L2则通过两个神经网络分别建模f和g函数,进而实现控制律。最后,对三种控制器进行了性能比较,包括计算均方根误差、最大误差、调节时间等指标,并绘制了响应曲线和跟踪误差曲线。此外,还强调了机器人手臂模型参数的一致性和参考信号设置的规范性,提出了常见问题的解决方案以及性能比较的标准化方法。 适合人群:具备一定编程基础,特别是熟悉MATLAB编程语言的研究人员或工程师,以及对神经网络控制理论有一定了解的技术人员。 使用场景及目标:①理解不同类型的神经网络控制器的工作原理;②掌握在MATLAB中实现这些控制器的方法;③学会如何设置合理的参考信号并保证模型参数的一致性;④能够根据具体的性能指标对比不同控制器的效果,从而选择最适合应用场景的控制器。 其他说明:本文档不仅提供了完整的实验代码,还对每个步骤进行了详细的注释,有助于读者更好地理解每段代码的功能。同时,针对可能出现的问题给出了相应的解决办法,确保实验结果的有效性和可靠性。为了使性能比较更加公平合理,文档还介绍了标准化的测试流程和评估标准,这对于进一步研究和应用具有重要的指导意义。
资源内项目源码是来自个人的毕业设计,代码都测试ok,包含源码、数据集、可视化页面和部署说明,可产生核心指标曲线图、混淆矩阵、F1分数曲线、精确率-召回率曲线、验证集预测结果、标签分布图。都是运行成功后才上传资源,毕设答辩评审绝对信服的保底85分以上,放心下载使用,拿来就能用。包含源码、数据集、可视化页面和部署说明一站式服务,拿来就能用的绝对好资源!!! 项目备注 1、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,请放心下载使用! 2、本项目适合计算机相关专业(如计科、人工智能、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载学习,也适合小白学习进阶,当然也可作为毕设项目、课程设计、大作业、项目初期立项演示等。 3、如果基础还行,也可在此代码基础上进行修改,以实现其他功能,也可用于毕设、课设、作业等。 下载后请首先打开README.txt文件,仅供学习参考, 切勿用于商业用途。
# 基于Python的微信智能聊天机器人 ## 项目简介 本项目是一个基于Python的微信智能聊天机器人框架,旨在通过ChatGPT的强大对话能力,将微信打造成一个智能助手。该机器人支持私聊和群聊的智能回复、语音识别、图片生成、插件扩展等功能,能够与好友进行多轮对话,并提供丰富的交互体验。项目支持多端部署,包括个人微信、微信公众号和企业微信应用。 ## 项目的主要特性和功能 多端部署支持个人微信、微信公众号和企业微信应用等多种部署方式。 智能对话支持私聊和群聊的智能回复,具备多轮会话上下文记忆功能,支持GPT3、GPT3.5、GPT4等模型。 语音识别可识别语音消息并通过文字或语音回复,支持Azure、Baidu、Google、OpenAI等多种语音模型。 图片生成支持图片生成和图生图功能(如照片修复),可选择DALLE、Stable Diffusion、Replicate等模型。
【项目资源】: 适用于从基础到高级的各种项目,特别是在性能要求较高的场景中,比如操作系统开发、嵌入式编程和底层系统编程。如果您是初学者,可以从简单的控制台程序开始练习;如果是进阶开发者,可以尝试涉及硬件或网络的项目。 【项目质量】: 所有源码都经过严格测试,可以直接运行。 功能在确认正常工作后才上传。 【适用人群】: 适用于希望学习不同技术领域的小白或进阶学习者。 可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【附加价值】: 项目具有较高的学习借鉴价值,也可直接拿来修改复刻。 对于有一定基础或热衷于研究的人来说,可以在这些基础代码上进行修改和扩展,实现其他功能。 【沟通交流】: 有任何使用上的问题,欢迎随时与博主沟通,博主会及时解答。 鼓励下载和使用,并欢迎大家互相学习,共同进步。 # 注意 1. 本资源仅用于开源学习和技术交流。不可商用等,一切后果由使用者承担。 2. 部分字体以及插图等来自网络,若是侵权请联系删除。
资源内项目源码是来自个人的毕业设计,代码都测试ok,包含源码、数据集、可视化页面和部署说明,可产生核心指标曲线图、混淆矩阵、F1分数曲线、精确率-召回率曲线、验证集预测结果、标签分布图。都是运行成功后才上传资源,毕设答辩评审绝对信服的保底85分以上,放心下载使用,拿来就能用。包含源码、数据集、可视化页面和部署说明一站式服务,拿来就能用的绝对好资源!!! 项目备注 1、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,请放心下载使用! 2、本项目适合计算机相关专业(如计科、人工智能、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载学习,也适合小白学习进阶,当然也可作为毕设项目、课程设计、大作业、项目初期立项演示等。 3、如果基础还行,也可在此代码基础上进行修改,以实现其他功能,也可用于毕设、课设、作业等。 下载后请首先打开README.txt文件,仅供学习参考, 切勿用于商业用途。
【项目资源】: 物联网项目适用于从基础到高级的各种项目,特别是在性能要求较高的场景中,比如操作系统开发、嵌入式编程和底层系统编程。如果您是初学者,可以从简单的控制台程序开始练习;如果是进阶开发者,可以尝试涉及硬件或网络的项目。 【项目质量】: 所有源码都经过严格测试,可以直接运行。 功能在确认正常工作后才上传。 【适用人群】: 适用于希望学习不同技术领域的小白或进阶学习者。 可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【附加价值】: 项目具有较高的学习借鉴价值,也可直接拿来修改复刻。 对于有一定基础或热衷于研究的人来说,可以在这些基础代码上进行修改和扩展,实现其他功能。 【沟通交流】: 有任何使用上的问题,欢迎随时与博主沟通,博主会及时解答。 鼓励下载和使用,并欢迎大家互相学习,共同进步。 # 注意 1. 本资源仅用于开源学习和技术交流。不可商用等,一切后果由使用者承担。 2. 部分字体以及插图等来自网络,若是侵权请联系删除。
该资源为scipy-0.11.0.tar.gz,欢迎下载使用哦!
内容概要:PT500PLUS平行轴齿轮箱故障测试台是由瓦伦尼安(VALENIAN)Machine Vibration & Gearbox Simulator(机械振动-齿轮箱模拟器)开发的专业机械故障仿真测试设备。该测试台旨在模拟和研究转子、齿轮传动、轴承及电机系统中的多种常见故障,包括但不限于轴不对中、转子不平衡、机械松动、轴承故障、齿轮故障(如点蚀、磨损、断齿等)以及电机故障(如转子不平衡、轴承故障、匝间短路等)。测试台配备有先进的传感器和数据采集系统,能够实时采集并分析振动、噪声、转速、扭矩等参数,提供多通道同步信号采集与频谱分析功能。此外,测试台还配备了10寸触摸屏、PLC智能控制系统和急停按钮,确保操作简便和安全。 适用人群:机械工程专业师生、科研人员以及从事机械故障诊断和维护的技术人员。 使用场景及目标:①用于高校和科研机构的教学和研究,帮助学生和研究人员深入理解机械故障的机理;②为企业提供故障诊断和预防性维护的解决方案,提高设备可靠性和运行效率;③通过模拟真实工况下的故障,进行轴承寿命预测性试验,研究轴承故障机制与轴承载荷、转速、振动、温度之间的关系。 其他说明:测试台结构紧凑,模块化设计,便于移动和维护。它不仅支持多种传感器的安装和数据采集,还提供了丰富的分析软件功能,如FFT频谱分析、轴心轨迹图、小波分析等,支持数据导出和二次开发,适用于各种复杂的研究和应用需求。
内容概要:本文档详细介绍了XXX5G特色商业街的规划设计方案,旨在通过5G技术与物联网等前沿科技的融合,全方位提升游客体验感和街区运营效率。首先,基础信息系统涵盖综合管理智慧平台、统一结算系统、5G视频智慧安防监控系统等多个子系统,实现多系统协同管理和数据安全保障。其次,特色应用方面,推出5G短信服务、5G智慧机器人、5G无人巡逻车、5G+XR时空走廊、5G+元宇宙体验馆等项目,将尖端科技与深厚文化底蕴巧妙结合,创新文旅体验形式。最后,通过5G高清视频直播与分享、5G+高空文旅等举措,进一步提升水街的影响力和吸引力。 适用人群:本方案适用于文旅项目规划者、商业街运营管理者、信息技术从业者以及对智慧城市建设感兴趣的各界人士。 使用场景及目标:①为商业街提供全面的智慧化升级方案,涵盖基础信息系统和特色应用两大部分;②通过5G技术赋能,实现高效运营管理和沉浸式游客体验;③推动文旅产业创新发展,促进地方经济繁荣和社会进步。 其他说明:该方案不仅关注技术实现,更重视用户体验和服务质量,强调文化传承与科技创新的有机结合,致力于打造具有国际影响力的智慧文旅新地标。
【更新至2023年】2000-2023年中国气候政策不确定性指数数据(全国、省、市三个层面) 1.时间:2000-2023年 2.来源:使用人工审计和深度学习算法MacBERT模型,基于中国《人民日报》《光明日报》《经济日报》《环球时报》《科技日报》《中国新闻社》等6家主流报纸中的1,755,826篇文章,构建了2000年1月至2023年12月的中国全国、省份和主要城市层面的CCPU指数。研究框架包括六个部分:数据收集、清洗数据、人工审计、模型构建、指数计算与标准化以及技术验证。 3.范围:中国、省、市三个层次 4.参考文献:Ma, Y. R., Liu, Z., Ma, D., Zhai, P., Guo, K., Zhang, D., & Ji, Q. (2023). A news-based climate policy uncertainty index for China. Scientific Data, 10(1), 881. 5.时间跨度:全国层面:日度、月度、年度;省级层面:月度、年度;地级市层面:月度、年度
【项目资源】: 单片机项目适用于从基础到高级的各种项目,特别是在性能要求较高的场景中,比如操作系统开发、嵌入式编程和底层系统编程。如果您是初学者,可以从简单的控制台程序开始练习;如果是进阶开发者,可以尝试涉及硬件或网络的项目。 【项目质量】: 所有源码都经过严格测试,可以直接运行。 功能在确认正常工作后才上传。 【适用人群】: 适用于希望学习不同技术领域的小白或进阶学习者。 可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【附加价值】: 项目具有较高的学习借鉴价值,也可直接拿来修改复刻。 对于有一定基础或热衷于研究的人来说,可以在这些基础代码上进行修改和扩展,实现其他功能。 【沟通交流】: 有任何使用上的问题,欢迎随时与博主沟通,博主会及时解答。 鼓励下载和使用,并欢迎大家互相学习,共同进步。 # 注意 1. 本资源仅用于开源学习和技术交流。不可商用等,一切后果由使用者承担。 2. 部分字体以及插图等来自网络,若是侵权请联系删除。
内容概要:BTS200轴承寿命预测测试台是一款专为研究轴承寿命预测及加速磨损过程设计的实验设备。该设备结构灵活,支持不同尺寸和类型的轴承测试,最大负载可达15000N。测试台采用先进的伺服电缸加载系统,能够在轴向和径向上精确施加载荷,并配备高精度测力传感器和温度监测系统,确保实验数据的准确性。此外,BTS200还拥有油液循环润滑系统,通过油膜减少摩擦和磨损,保持机械部件在适宜的工作温度范围内,延长轴承寿命。Bearing Prognostics Simulator(实验台可通过触控屏操作,支持多速运行(0-3000RPM),并具备过热保护机制,在温度超过150℃时自动停机。BTS200广泛应用于轴承寿命预测、故障机制研究以及剩余寿命预测模型的开发。 适合人群:轴承设计研发人员、机械工程研究人员、高校实验室师生及相关领域工程师。 使用场景及目标:①研究轴承在不同载荷和转速条件下的磨损特性;②开发和验证轴承剩余寿命预测模型;③探索轴承故障机制及其对系统性能的影响;④评估不同润滑方式对轴承寿命的影响。 其他说明:BTS200测试台不仅提供硬件支持,还配备了完整的软件控制系统,包括PLC闭环控制、温度监测反馈模块等,确保实验过程的稳定性和数据的可靠性。此外,设备支持快速安装和拆卸测试轴承,便于实验操作。
xilinx基于PCIE IP的PCIE Bridge IP操作手册
【项目资源】: 单片机项目适用于从基础到高级的各种项目,特别是在性能要求较高的场景中,比如操作系统开发、嵌入式编程和底层系统编程。如果您是初学者,可以从简单的控制台程序开始练习;如果是进阶开发者,可以尝试涉及硬件或网络的项目。 【项目质量】: 所有源码都经过严格测试,可以直接运行。 功能在确认正常工作后才上传。 【适用人群】: 适用于希望学习不同技术领域的小白或进阶学习者。 可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。 【附加价值】: 项目具有较高的学习借鉴价值,也可直接拿来修改复刻。 对于有一定基础或热衷于研究的人来说,可以在这些基础代码上进行修改和扩展,实现其他功能。 【沟通交流】: 有任何使用上的问题,欢迎随时与博主沟通,博主会及时解答。 鼓励下载和使用,并欢迎大家互相学习,共同进步。 # 注意 1. 本资源仅用于开源学习和技术交流。不可商用等,一切后果由使用者承担。 2. 部分字体以及插图等来自网络,若是侵权请联系删除。
使用教程 (1).mov
# 基于webpack和Vue的前端项目构建方案 ## 项目简介 本项目是基于webpack和Vue构建的前端项目方案,借助webpack强大的打包能力以及Vue的开发特性,可用于快速搭建现代化的前端应用。项目不仅完成了基本的webpack与Vue的集成配置,还在构建速度优化和代码规范性方面做了诸多配置。 ## 项目的主要特性和功能 1. 打包功能运用webpack进行模块打包,支持将scss转换为css,借助babel实现语法转换。 2. Vue开发支持集成Vue框架,能使用Vue单文件组件的开发模式。 3. 构建优化采用threadloader实现多进程打包,cacheloader缓存资源,极大提高构建速度开启热更新功能,开发更高效。 4. 错误处理与优化提供不同环境下的错误映射配置,便于定位错误利用webpackbundleanalyzer分析打包体积。
数据说明: 板球是世界上观看人数第二多的运动。这项运动充满了大量的情绪和戏剧性,直到比赛的最后一球。而且,有板球运动员一次又一次地证明,他们是这项运动的真正大师,改变了输掉比赛到赢得比赛的方程式,并在比赛中用他们的魔法咒语为他们的国家带来了许多胜利。作为板球迷,是时候利用深度学习技能,通过这个数据集获得更多乐趣,并检测/预测有史以来最伟大的板球运动员了。 数据准备: 2019年,BBC邀请观众投票选出“有史以来最伟大的板球运动员”,最终根据收到的最高票数发布了有史以来最伟大的30名板球运动员名单。这个数据集从中提取了30名板球运动员的相关图像6950张