
Õłåµ×ÉMapReduceµē¦ĶĪīĶ┐ćń©ŗ
┬Ā┬Ā┬Ā┬ĀMapReduceĶ┐ÉĶĪīńÜ䵌ČÕĆÖ’╝īõ╝ÜķĆÜĶ┐ćMapperĶ┐ÉĶĪīńÜäõ╗╗ÕŖĪĶ»╗ÕÅ¢HDFSõĖŁńÜäµĢ░µŹ«µ¢ćõ╗Č’╝īńäČÕÉÄĶ░āńö©Ķć¬ÕĘ▒ńÜäµ¢╣µ│Ģ’╝īÕżäńÉåµĢ░µŹ«’╝īµ£ĆÕÉÄĶŠōÕć║ŃĆéReducerõ╗╗ÕŖĪõ╝ܵğµöČMapperõ╗╗ÕŖĪĶŠōÕć║ńÜäµĢ░µŹ«’╝īõĮ£õĖ║Ķć¬ÕĘ▒ńÜäĶŠōÕģźµĢ░µŹ«’╝īĶ░āńö©Ķć¬ÕĘ▒ńÜäµ¢╣µ│Ģ’╝īµ£ĆÕÉÄĶŠōÕć║Õł░HDFSńÜäµ¢ćõ╗ČõĖŁŃĆéµĢ┤õĖ¬µĄüń©ŗÕ”éÕøŠ’╝Ü

Mapperõ╗╗ÕŖĪńÜäµē¦ĶĪīĶ┐ćń©ŗĶ»”Ķ¦Ż
µ»ÅõĖ¬Mapperõ╗╗ÕŖĪµś»õĖĆõĖ¬javaĶ┐øń©ŗ’╝īÕ«āõ╝ÜĶ»╗ÕÅ¢HDFSõĖŁńÜäµ¢ćõ╗Č’╝īĶ¦Żµ×ɵłÉÕŠłÕżÜńÜäķö«ÕĆ╝Õ»╣’╝īń╗ÅĶ┐浳æõ╗¼Ķ”åńø¢ńÜämapµ¢╣µ│ĢÕżäńÉåÕÉÄ’╝īĶĮ¼µŹóõĖ║ÕŠłÕżÜńÜäķö«ÕĆ╝Õ»╣ÕåŹĶŠōÕć║ŃĆéµĢ┤õĖ¬Mapperõ╗╗ÕŖĪńÜäÕżäńÉåĶ┐ćń©ŗÕÅłÕÅ»õ╗źÕłåõĖ║õ╗źõĖŗÕćĀõĖ¬ķśČµ«Ą’╝īÕ”éÕøŠµēĆńż║ŃĆé

Õ£©õĖŖÕøŠõĖŁ’╝īµŖŖMapperõ╗╗ÕŖĪńÜäĶ┐ÉĶĪīĶ┐ćń©ŗÕłåõĖ║ÕģŁõĖ¬ķśČµ«ĄŃĆé
-
ń¼¼õĖĆķśČµ«Ąµś»µŖŖĶŠōÕģźµ¢ćõ╗ȵīēńģ¦õĖĆÕ«ÜńÜäµĀćÕćåÕłåńēć(InputSplit)’╝īµ»ÅõĖ¬ĶŠōÕģźńēćńÜäÕż¦Õ░ŵś»Õø║Õ«ÜńÜäŃĆéķ╗śĶ«żµāģÕåĄõĖŗ’╝īĶŠōÕģźńēć(InputSplit)ńÜäÕż¦Õ░ÅõĖĵĢ░µŹ«ÕØŚ(Block)ńÜäÕż¦Õ░ŵś»ńøĖÕÉīńÜäŃĆéÕ”éµ×£µĢ░µŹ«ÕØŚ(Block)ńÜäÕż¦Õ░ŵś»ķ╗śĶ«żÕĆ╝64MB’╝īĶŠōÕģźµ¢ćõ╗ȵ£ēõĖżõĖ¬’╝īõĖĆõĖ¬µś»32MB’╝īõĖĆõĖ¬µś»72MBŃĆéķéŻõ╣łÕ░ÅńÜäµ¢ćõ╗ȵś»õĖĆõĖ¬ĶŠōÕģźńēć’╝īÕż¦µ¢ćõ╗Čõ╝ÜÕłåõĖ║õĖżõĖ¬µĢ░µŹ«ÕØŚ’╝īķéŻõ╣łµś»õĖżõĖ¬ĶŠōÕģźńēćŃĆéõĖĆÕģ▒õ║¦ńö¤õĖēõĖ¬ĶŠōÕģźńēćŃĆéµ»ÅõĖĆõĖ¬ĶŠōÕģźńēćńö▒õĖĆõĖ¬MapperĶ┐øń©ŗÕżäńÉåŃĆéĶ┐ÖķćīńÜäõĖēõĖ¬ĶŠōÕģźńēć’╝īõ╝ܵ£ēõĖēõĖ¬MapperĶ┐øń©ŗÕżäńÉåŃĆé
-
ń¼¼õ║īķśČµ«Ąµś»Õ»╣ĶŠōÕģźńēćõĖŁńÜäĶ«░ÕĮĢµīēńģ¦õĖĆÕ«ÜńÜäĶ¦äÕłÖĶ¦Żµ×ɵłÉķö«ÕĆ╝Õ»╣ŃĆéµ£ēõĖ¬ķ╗śĶ«żĶ¦äÕłÖµś»µŖŖµ»ÅõĖĆĶĪīµ¢ćµ£¼ÕåģÕ«╣Ķ¦Żµ×ɵłÉķö«ÕĆ╝Õ»╣ŃĆéŌĆ£ķö«ŌĆصś»µ»ÅõĖĆĶĪīńÜäĶĄĘÕ¦ŗõĮŹńĮ«(ÕŹĢõĮŹµś»ÕŁŚĶŖé)’╝īŌĆ£ÕĆ╝ŌĆصś»µ£¼ĶĪīńÜäµ¢ćµ£¼ÕåģÕ«╣ŃĆé
-
ń¼¼õĖēķśČµ«Ąµś»Ķ░āńö©Mapperń▒╗õĖŁńÜämapµ¢╣µ│ĢŃĆéń¼¼õ║īķśČµ«ĄõĖŁĶ¦Żµ×ÉÕć║µØźńÜäµ»ÅõĖĆõĖ¬ķö«ÕĆ╝Õ»╣’╝īĶ░āńö©õĖƵ¼Īmapµ¢╣µ│ĢŃĆéÕ”éµ×£µ£ē1000õĖ¬ķö«ÕĆ╝Õ»╣’╝īÕ░▒õ╝ÜĶ░āńö©1000µ¼Īmapµ¢╣µ│ĢŃĆéµ»ÅõĖƵ¼ĪĶ░āńö©mapµ¢╣µ│Ģõ╝ÜĶŠōÕć║ķøČõĖ¬µł¢ĶĆģÕżÜõĖ¬ķö«ÕĆ╝Õ»╣ŃĆé
-
ń¼¼ÕøøķśČµ«Ąµś»µīēńģ¦õĖĆÕ«ÜńÜäĶ¦äÕłÖÕ»╣ń¼¼õĖēķśČµ«ĄĶŠōÕć║ńÜäķö«ÕĆ╝Õ»╣Ķ┐øĶĪīÕłåÕī║ŃĆéµ»öĶŠāµś»Õ¤║õ║Äķö«Ķ┐øĶĪīńÜäŃĆéµ»öÕ”éµłæõ╗¼ńÜäķö«ĶĪ©ńż║ń£üõ╗Į(Õ”éÕīŚõ║¼ŃĆüõĖŖµĄĘŃĆüÕ▒▒õĖ£ńŁē)’╝īķéŻõ╣łÕ░▒ÕÅ»õ╗źµīēńģ¦õĖŹÕÉīń£üõ╗ĮĶ┐øĶĪīÕłåÕī║’╝īÕÉīõĖĆõĖ¬ń£üõ╗ĮńÜäķö«ÕĆ╝Õ»╣ÕłÆÕłåÕł░õĖĆõĖ¬Õī║õĖŁŃĆéķ╗śĶ«żµś»ÕŬµ£ēõĖĆõĖ¬Õī║ŃĆéÕłåÕī║ńÜäµĢ░ķćÅÕ░▒µś»Reducerõ╗╗ÕŖĪĶ┐ÉĶĪīńÜäµĢ░ķćÅŃĆéķ╗śĶ«żÕŬµ£ēõĖĆõĖ¬Reducerõ╗╗ÕŖĪŃĆé
-
ń¼¼õ║öķśČµ«Ąµś»Õ»╣µ»ÅõĖ¬ÕłåÕī║õĖŁńÜäķö«ÕĆ╝Õ»╣Ķ┐øĶĪīµÄÆÕ║ÅŃĆéķ”¢Õģł’╝īµīēńģ¦ķö«Ķ┐øĶĪīµÄÆÕ║Å’╝īÕ»╣õ║Äķö«ńøĖÕÉīńÜäķö«ÕĆ╝Õ»╣’╝īµīēńģ¦ÕĆ╝Ķ┐øĶĪīµÄÆÕ║ÅŃĆéµ»öÕ”éõĖēõĖ¬ķö«ÕĆ╝Õ»╣<2,2>ŃĆü<1,3>ŃĆü<2,1>’╝īķö«ÕÆīÕĆ╝ÕłåÕł½µś»µĢ┤µĢ░ŃĆéķéŻõ╣łµÄÆÕ║ÅÕÉÄńÜäń╗ōµ×£µś»<1,3>ŃĆü<2,1>ŃĆü<2,2>ŃĆéÕ”éµ×£µ£ēń¼¼ÕģŁķśČµ«Ą’╝īķéŻõ╣łĶ┐øÕģźń¼¼ÕģŁķśČµ«Ą’╝øÕ”éµ×£µ▓Īµ£ē’╝īńø┤µÄźĶŠōÕć║Õł░µ£¼Õ£░ńÜälinuxµ¢ćõ╗ČõĖŁŃĆé
-
ń¼¼ÕģŁķśČµ«Ąµś»Õ»╣µĢ░µŹ«Ķ┐øĶĪīÕĮÆń║”ÕżäńÉå’╝īõ╣¤Õ░▒µś»reduceÕżäńÉåŃĆéķö«ńøĖńŁēńÜäķö«ÕĆ╝Õ»╣õ╝ÜĶ░āńö©õĖƵ¼Īreduceµ¢╣µ│ĢŃĆéń╗ÅĶ┐ćĶ┐ÖõĖĆķśČµ«Ą’╝īµĢ░µŹ«ķćÅõ╝ÜÕćÅÕ░æŃĆéÕĮÆń║”ÕÉÄńÜäµĢ░µŹ«ĶŠōÕć║Õł░µ£¼Õ£░ńÜälinxuµ¢ćõ╗ČõĖŁŃĆéµ£¼ķśČµ«Ąķ╗śĶ«żµś»µ▓Īµ£ēńÜä’╝īķ£ĆĶ”üńö©µłĘĶć¬ÕĘ▒Õó×ÕŖĀĶ┐ÖõĖĆķśČµ«ĄńÜäõ╗ŻńĀüŃĆé
Reducerõ╗╗ÕŖĪńÜäµē¦ĶĪīĶ┐ćń©ŗĶ»”Ķ¦Ż
µ»ÅõĖ¬Reducerõ╗╗ÕŖĪµś»õĖĆõĖ¬javaĶ┐øń©ŗŃĆéReducerõ╗╗ÕŖĪµÄźµöČMapperõ╗╗ÕŖĪńÜäĶŠōÕć║’╝īÕĮÆń║”ÕżäńÉåÕÉÄÕåÖÕģźÕł░HDFSõĖŁ’╝īÕÅ»õ╗źÕłåõĖ║Õ”éõĖŗÕøŠµēĆńż║ńÜäÕćĀõĖ¬ķśČµ«ĄŃĆé

-
ń¼¼õĖĆķśČµ«Ąµś»Reducerõ╗╗ÕŖĪõ╝ÜõĖ╗ÕŖ©õ╗ÄMapperõ╗╗ÕŖĪÕżŹÕłČÕģČĶŠōÕć║ńÜäķö«ÕĆ╝Õ»╣ŃĆéMapperõ╗╗ÕŖĪÕÅ»ĶāĮõ╝ܵ£ēÕŠłÕżÜ’╝īÕøĀµŁżReducerõ╝ÜÕżŹÕłČÕżÜõĖ¬MapperńÜäĶŠōÕć║ŃĆé
-
ń¼¼õ║īķśČµ«Ąµś»µŖŖÕżŹÕłČÕł░Reducerµ£¼Õ£░µĢ░µŹ«’╝īÕģ©ķā©Ķ┐øĶĪīÕÉłÕ╣Č’╝īÕŹ│µŖŖÕłåµĢŻńÜäµĢ░µŹ«ÕÉłÕ╣ȵłÉõĖĆõĖ¬Õż¦ńÜäµĢ░µŹ«ŃĆéÕåŹÕ»╣ÕÉłÕ╣ČÕÉÄńÜäµĢ░µŹ«µÄÆÕ║ÅŃĆé
-
ń¼¼õĖēķśČµ«Ąµś»Õ»╣µÄÆÕ║ÅÕÉÄńÜäķö«ÕĆ╝Õ»╣Ķ░āńö©reduceµ¢╣µ│ĢŃĆéķö«ńøĖńŁēńÜäķö«ÕĆ╝Õ»╣Ķ░āńö©õĖƵ¼Īreduceµ¢╣µ│Ģ’╝īµ»Åµ¼ĪĶ░āńö©õ╝Üõ║¦ńö¤ķøČõĖ¬µł¢ĶĆģÕżÜõĖ¬ķö«ÕĆ╝Õ»╣ŃĆéµ£ĆÕÉĵŖŖĶ┐Öõ║øĶŠōÕć║ńÜäķö«ÕĆ╝Õ»╣ÕåÖÕģźÕł░HDFSµ¢ćõ╗ČõĖŁŃĆé
Õ£©µĢ┤õĖ¬MapReduceń©ŗÕ║ÅńÜäÕ╝ĆÕÅæĶ┐ćń©ŗõĖŁ’╝īµłæõ╗¼µ£ĆÕż¦ńÜäÕĘźõĮ£ķćŵś»Ķ”åńø¢mapÕćĮµĢ░ÕÆīĶ”åńø¢reduceÕćĮµĢ░ŃĆé
ķö«ÕĆ╝Õ»╣ńÜäń╝¢ÕÅĘ
Õ£©Õ»╣Mapperõ╗╗ÕŖĪŃĆüReducerõ╗╗ÕŖĪńÜäÕłåµ×ÉĶ┐ćń©ŗõĖŁ’╝īõ╝Üń£ŗÕł░ÕŠłÕżÜķśČµ«ĄķāĮÕć║ńÄ░õ║åķö«ÕĆ╝Õ»╣’╝īĶ»╗ĶĆģÕ«╣µśōµĘʵĘå’╝īµēĆõ╗źĶ┐ÖķćīÕ»╣ķö«ÕĆ╝Õ»╣Ķ┐øĶĪīń╝¢ÕÅĘ’╝īµ¢╣õŠ┐Õż¦Õ«ČńÉåĶ¦Żķö«ÕĆ╝Õ»╣ńÜäÕÅśÕī¢µāģÕåĄ’╝īÕ”éõĖŗÕøŠµēĆńż║ŃĆé

Õ£©õĖŖÕøŠõĖŁ’╝īÕ»╣õ║ÄMapperõ╗╗ÕŖĪĶŠōÕģźńÜäķö«ÕĆ╝Õ»╣’╝īÕ«Üõ╣ēõĖ║key1ÕÆīvalue1ŃĆéÕ£©mapµ¢╣µ│ĢõĖŁÕżäńÉåÕÉÄ’╝īĶŠōÕć║ńÜäķö«ÕĆ╝Õ»╣’╝īÕ«Üõ╣ēõĖ║key2ÕÆīvalue2ŃĆéreduceµ¢╣µ│ĢµÄźµöČkey2ÕÆīvalue2’╝īÕżäńÉåÕÉÄ’╝īĶŠōÕć║key3ÕÆīvalue3ŃĆéÕ£©õĖŗµ¢ćĶ«©Ķ«║ķö«ÕĆ╝Õ»╣µŚČ’╝īÕÅ»ĶāĮµŖŖkey1ÕÆīvalue1ń«ĆÕåÖõĖ║<k1,v1>’╝īkey2ÕÆīvalue2ń«ĆÕåÖõĖ║<k2,v2>’╝īkey3ÕÆīvalue3ń«ĆÕåÖõĖ║<k3,v3>ŃĆé
õ╗źõĖŖÕåģÕ«╣µØźĶ欒╝Ühttp://www.superwu.cn/2013/08/21/530/
┬Ā
-----------------------Õłå------------------Õē▓----------------ń║┐-------------------------
┬Ā
õŠŗÕŁÉ’╝ܵ▒éµ»ÅÕ╣┤µ£Ćķ½śµ░öµĖ®
Õ£©HDFSõĖŁńÜäµĀ╣ńø«ÕĮĢõĖŗµ£ēõ╗źõĖŗµ¢ćõ╗ȵĀ╝Õ╝Å’╝Ü /input.txt
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
2014010114201401021620140103172014010410201401050620120106092012010732201201081220120109192012011023200101011620010102122001010310200101041120010105292013010619201301072220130108122013010929201301102320080101052008010216200801033720080104142008010516200701061920070107122007010812200701099920070110232010010114201001021620100103172010010410201001050620150106492015010722201501081220150109992015011023 |
┬Ā
┬Ā ┬Ā┬Āµ»öÕ”é’╝Ü2010012325ĶĪ©ńż║Õ£©2010Õ╣┤01µ£ł23µŚźńÜäµ░öµĖ®õĖ║25Õ║”ŃĆéńÄ░Õ£©Ķ”üµ▒éõĮ┐ńö©MapReduce’╝īĶ«Īń«Śµ»ÅõĖĆÕ╣┤Õć║ńÄ░Ķ┐ćńÜäµ£ĆÕż¦µ░öµĖ®ŃĆé
┬Ā ┬Ā Õ£©ÕåÖõ╗ŻńĀüõ╣ŗÕēŹ’╝īÕģłńĪ«õ┐صŁŻńĪ«ńÜäÕ»╝Õģźõ║åńøĖÕģ│ńÜäjarÕīģŃĆ鵳æõĮ┐ńö©ńÜ䵜»maven’╝īÕÅ»õ╗źÕł░http://mvnrepository.comÕÄ╗µÉ£ń┤óĶ┐ÖÕćĀõĖ¬artifactIdŃĆé
┬Ā┬Ā┬Ā┬ĀµŁżń©ŗÕ║Åķ£ĆĶ”üõ╗źHadoopµ¢ćõ╗ČõĮ£õĖ║ĶŠōÕģźµ¢ćõ╗Č’╝īõ╗źHadoopµ¢ćõ╗ČõĮ£õĖ║ĶŠōÕć║µ¢ćõ╗Č’╝īÕøĀµŁżķ£ĆĶ”üńö©Õł░µ¢ćõ╗Čń│╗ń╗¤’╝īõ║ĵś»ķ£ĆĶ”üÕ╝ĢÕģźhadoop-hdfsÕīģ’╝øµłæõ╗¼ķ£ĆĶ”üÕÉæMap-ReduceķøåńŠżµÅÉõ║żõ╗╗ÕŖĪ’╝īķ£ĆĶ”üńö©Õł░Map-ReduceńÜäÕ«óµłĘń½»’╝īõ║ĵś»ķ£ĆĶ”üÕ»╝Õģźhadoop-mapreduce-client-jobclientÕīģ’╝øÕÅ”Õż¢’╝īÕ£©ÕżäńÉåµĢ░µŹ«ńÜ䵌ČÕĆÖõ╝Üńö©Õł░õĖĆõ║øhadoopńÜäµĢ░µŹ«ń▒╗Õ×ŗõŠŗÕ”éIntWritableÕÆīTextńŁē’╝īÕøĀµŁżķ£ĆĶ”üÕ»╝Õģźhadoop-commonÕīģŃĆéõ║ĵś»Ķ┐ÉĶĪīµŁżń©ŗÕ║ŵēĆķ£ĆĶ”üńÜäńøĖÕģ│õŠØĶĄ¢µ£ēõ╗źõĖŗÕćĀõĖ¬’╝Ü
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<dependency>
┬Ā┬Ā┬Ā┬Ā<groupId>org.apache.hadoop</groupId>
┬Ā┬Ā┬Ā┬Ā<artifactId>hadoop-hdfs</artifactId>
┬Ā┬Ā┬Ā┬Ā<version>2.4.0</version>
</dependency>
<dependency>
┬Ā┬Ā┬Ā┬Ā<groupId>org.apache.hadoop</groupId>
┬Ā┬Ā┬Ā┬Ā<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
┬Ā┬Ā┬Ā┬Ā<version>2.4.0</version>
</dependency>
<dependency>
┬Ā┬Ā┬Ā┬Ā<groupId>org.apache.hadoop</groupId>
┬Ā┬Ā┬Ā┬Ā<artifactId>hadoop-common</artifactId>
┬Ā┬Ā┬Ā┬Ā<version>2.4.0</version>
</dependency>
|
┬Ā
┬Ā ┬Ā┬ĀÕīģÕ»╝ÕźĮõ║åÕÉÄ’╝ī┬ĀĶ«ŠĶ«Īõ╗ŻńĀüÕ”éõĖŗ’╝Ü
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
|
package┬Ācom.abc.yarn;
┬Ā
import┬Ājava.io.IOException;
┬Ā
import┬Āorg.apache.hadoop.conf.Configuration;
import┬Āorg.apache.hadoop.fs.Path;
import┬Āorg.apache.hadoop.io.IntWritable;
import┬Āorg.apache.hadoop.io.LongWritable;
import┬Āorg.apache.hadoop.io.Text;
import┬Āorg.apache.hadoop.mapreduce.Job;
import┬Āorg.apache.hadoop.mapreduce.Mapper;
import┬Āorg.apache.hadoop.mapreduce.Reducer;
import┬Āorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import┬Āorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
┬Ā
public┬Āclass┬ĀTemperature┬Ā{
┬Ā┬Ā┬Ā┬Ā/**
┬Ā┬Ā┬Ā┬Ā┬Ā*┬ĀÕøøõĖ¬µ│øÕ×ŗń▒╗Õ×ŗÕłåÕł½õ╗ŻĶĪ©’╝Ü
┬Ā┬Ā┬Ā┬Ā┬Ā*┬ĀKeyIn┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀMapperńÜäĶŠōÕģźµĢ░µŹ«ńÜäKey’╝īĶ┐Öķćīµś»µ»ÅĶĪīµ¢ćÕŁŚńÜäĶĄĘÕ¦ŗõĮŹńĮ«’╝ł0,11,...’╝ē
┬Ā┬Ā┬Ā┬Ā┬Ā*┬ĀValueIn┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀMapperńÜäĶŠōÕģźµĢ░µŹ«ńÜäValue’╝īĶ┐Öķćīµś»µ»ÅĶĪīµ¢ćÕŁŚ
┬Ā┬Ā┬Ā┬Ā┬Ā*┬ĀKeyOut┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀMapperńÜäĶŠōÕć║µĢ░µŹ«ńÜäKey’╝īĶ┐Öķćīµś»µ»ÅĶĪīµ¢ćÕŁŚõĖŁńÜäŌĆ£Õ╣┤õ╗ĮŌĆØ
┬Ā┬Ā┬Ā┬Ā┬Ā*┬ĀValueOut┬Ā┬Ā┬Ā┬Ā┬ĀMapperńÜäĶŠōÕć║µĢ░µŹ«ńÜäValue’╝īĶ┐Öķćīµś»µ»ÅĶĪīµ¢ćÕŁŚõĖŁńÜäŌĆ£µ░öµĖ®ŌĆØ
┬Ā┬Ā┬Ā┬Ā┬Ā*/
┬Ā┬Ā┬Ā┬Āstatic┬Āclass┬ĀTempMapper┬Āextends
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀMapper<LongWritable,┬ĀText,┬ĀText,┬ĀIntWritable>┬Ā{
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā@Override
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āpublic┬Āvoid┬Āmap(LongWritable┬Ākey,┬ĀText┬Āvalue,┬ĀContext┬Ācontext)
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āthrows┬ĀIOException,┬ĀInterruptedException┬Ā{
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā//┬ĀµēōÕŹ░µĀʵ£¼:┬ĀBefore┬ĀMapper:┬Ā0,┬Ā2000010115
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSystem.out.print("Before┬ĀMapper:┬Ā"┬Ā+┬Ākey┬Ā+┬Ā",┬Ā"┬Ā+┬Āvalue);
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀString┬Āline┬Ā=┬Āvalue.toString();
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀString┬Āyear┬Ā=┬Āline.substring(0,┬Ā4);
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āint┬Ātemperature┬Ā=┬ĀInteger.parseInt(line.substring(8));
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ācontext.write(new┬ĀText(year),┬Ānew┬ĀIntWritable(temperature));
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā//┬ĀµēōÕŹ░µĀʵ£¼:┬ĀAfter┬ĀMapper:2000,┬Ā15
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSystem.out.println(
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā"======"┬Ā+
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā"After┬ĀMapper:"┬Ā+┬Ānew┬ĀText(year)┬Ā+┬Ā",┬Ā"┬Ā+┬Ānew┬ĀIntWritable(temperature));
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā}
┬Ā┬Ā┬Ā┬Ā}
┬Ā
┬Ā┬Ā┬Ā┬Ā/**
┬Ā┬Ā┬Ā┬Ā┬Ā*┬ĀÕøøõĖ¬µ│øÕ×ŗń▒╗Õ×ŗÕłåÕł½õ╗ŻĶĪ©’╝Ü
┬Ā┬Ā┬Ā┬Ā┬Ā*┬ĀKeyIn┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀReducerńÜäĶŠōÕģźµĢ░µŹ«ńÜäKey’╝īĶ┐Öķćīµś»µ»ÅĶĪīµ¢ćÕŁŚõĖŁńÜäŌĆ£Õ╣┤õ╗ĮŌĆØ
┬Ā┬Ā┬Ā┬Ā┬Ā*┬ĀValueIn┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀReducerńÜäĶŠōÕģźµĢ░µŹ«ńÜäValue’╝īĶ┐Öķćīµś»µ»ÅĶĪīµ¢ćÕŁŚõĖŁńÜäŌĆ£µ░öµĖ®ŌĆØ
┬Ā┬Ā┬Ā┬Ā┬Ā*┬ĀKeyOut┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀReducerńÜäĶŠōÕć║µĢ░µŹ«ńÜäKey’╝īĶ┐Öķćīµś»õĖŹķćŹÕżŹńÜäŌĆ£Õ╣┤õ╗ĮŌĆØ
┬Ā┬Ā┬Ā┬Ā┬Ā*┬ĀValueOut┬Ā┬Ā┬Ā┬Ā┬ĀReducerńÜäĶŠōÕć║µĢ░µŹ«ńÜäValue’╝īĶ┐Öķćīµś»Ķ┐ÖõĖĆÕ╣┤õĖŁńÜäŌĆ£µ£Ćķ½śµ░öµĖ®ŌĆØ
┬Ā┬Ā┬Ā┬Ā┬Ā*/
┬Ā┬Ā┬Ā┬Āstatic┬Āclass┬ĀTempReducer┬Āextends
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀReducer<Text,┬ĀIntWritable,┬ĀText,┬ĀIntWritable>┬Ā{
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā@Override
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āpublic┬Āvoid┬Āreduce(Text┬Ākey,┬ĀIterable<IntWritable>┬Āvalues,
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀContext┬Ācontext)┬Āthrows┬ĀIOException,┬ĀInterruptedException┬Ā{
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āint┬ĀmaxValue┬Ā=┬ĀInteger.MIN_VALUE;
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀStringBuffer┬Āsb┬Ā=┬Ānew┬ĀStringBuffer();
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā//ÕÅ¢valuesńÜäµ£ĆÕż¦ÕĆ╝
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āfor┬Ā(IntWritable┬Āvalue┬Ā:┬Āvalues)┬Ā{
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀmaxValue┬Ā=┬ĀMath.max(maxValue,┬Āvalue.get());
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āsb.append(value).append(",┬Ā");
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā}
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā//┬ĀµēōÕŹ░µĀʵ£¼’╝Ü┬ĀBefore┬ĀReduce:┬Ā2000,┬Ā15,┬Ā23,┬Ā99,┬Ā12,┬Ā22,┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSystem.out.print("Before┬ĀReduce:┬Ā"┬Ā+┬Ākey┬Ā+┬Ā",┬Ā"┬Ā+┬Āsb.toString());
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ācontext.write(key,┬Ānew┬ĀIntWritable(maxValue));
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā//┬ĀµēōÕŹ░µĀʵ£¼’╝Ü┬ĀAfter┬ĀReduce:┬Ā2000,┬Ā99
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSystem.out.println(
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā"======"┬Ā+
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā"After┬ĀReduce:┬Ā"┬Ā+┬Ākey┬Ā+┬Ā",┬Ā"┬Ā+┬ĀmaxValue);
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā}
┬Ā┬Ā┬Ā┬Ā}
┬Ā
┬Ā┬Ā┬Ā┬Āpublic┬Āstatic┬Āvoid┬Āmain(String[]┬Āargs)┬Āthrows┬ĀException┬Ā{
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā//ĶŠōÕģźĶĘ»ÕŠä
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀString┬Ādst┬Ā=┬Ā"hdfs://localhost:9000/intput.txt";
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā//ĶŠōÕć║ĶĘ»ÕŠä’╝īÕ┐ģķĪ╗µś»õĖŹÕŁśÕ£©ńÜä’╝īń®║µ¢ćõ╗ČÕŖĀõ╣¤õĖŹĶĪīŃĆé
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀString┬ĀdstOut┬Ā=┬Ā"hdfs://localhost:9000/output";
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀConfiguration┬ĀhadoopConfig┬Ā=┬Ānew┬ĀConfiguration();
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀhadoopConfig.set("fs.hdfs.impl",┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āorg.apache.hadoop.hdfs.DistributedFileSystem.class.getName()
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā);
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀhadoopConfig.set("fs.file.impl",
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āorg.apache.hadoop.fs.LocalFileSystem.class.getName()
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā);
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀJob┬Ājob┬Ā=┬Ānew┬ĀJob(hadoopConfig);
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā//Õ”éµ×£ķ£ĆĶ”üµēōµłÉjarĶ┐ÉĶĪī’╝īķ£ĆĶ”üõĖŗķØóĶ┐ÖÕÅź
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā//job.setJarByClass(NewMaxTemperature.class);
┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā//jobµē¦ĶĪīõĮ£õĖܵŚČĶŠōÕģźÕÆīĶŠōÕć║µ¢ćõ╗ČńÜäĶĘ»ÕŠä
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀFileInputFormat.addInputPath(job,┬Ānew┬ĀPath(dst));
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀFileOutputFormat.setOutputPath(job,┬Ānew┬ĀPath(dstOut));
┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā//µīćÕ«ÜĶć¬Õ«Üõ╣ēńÜäMapperÕÆīReducerõĮ£õĖ║õĖżõĖ¬ķśČµ«ĄńÜäõ╗╗ÕŖĪÕżäńÉåń▒╗
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ājob.setMapperClass(TempMapper.class);
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ājob.setReducerClass(TempReducer.class);
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā//Ķ«ŠńĮ«µ£ĆÕÉÄĶŠōÕć║ń╗ōµ×£ńÜäKeyÕÆīValueńÜäń▒╗Õ×ŗ
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ājob.setOutputKeyClass(Text.class);
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ājob.setOutputValueClass(IntWritable.class);
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā//µē¦ĶĪījob’╝īńø┤Õł░Õ«īµłÉ
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ājob.waitForCompletion(true);
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSystem.out.println("Finished");
┬Ā┬Ā┬Ā┬Ā}
} |
┬Ā
õĖŖķØóõ╗ŻńĀüõĖŁ’╝īµ│©µäÅMapperń▒╗ńÜäµ│øÕ×ŗõĖŹµś»javańÜäÕ¤║µ£¼ń▒╗Õ×ŗ’╝īĶĆīµś»HadoopńÜäµĢ░µŹ«ń▒╗Õ×ŗTextŃĆüIntWritableŃĆ鵳æõ╗¼ÕÅ»õ╗źń«ĆÕŹĢńÜäńŁēõ╗ĘõĖ║javańÜäń▒╗StringŃĆüintŃĆé
õ╗ŻńĀüõĖŁMapperń▒╗ńÜäµ│øÕ×ŗõŠØµ¼Īµś»<k1,v1,k2,v2>ŃĆémapµ¢╣µ│ĢńÜäń¼¼õ║īõĖ¬ÕĮóÕÅ鵜»ĶĪīµ¢ćµ£¼ÕåģÕ«╣’╝īµś»µłæõ╗¼Õģ│Õ┐āńÜäŃĆéµĀĖÕ┐āõ╗ŻńĀüµś»µŖŖĶĪīµ¢ćµ£¼ÕåģÕ«╣µīēńģ¦ń®║µĀ╝µŗåÕłå’╝īµŖŖµ»ÅĶĪīµĢ░µŹ«õĖŁŌĆ£Õ╣┤ŌĆØÕÆīŌĆ£µ░öµĖ®ŌĆصÅÉÕÅ¢Õć║µØź’╝īÕģČõĖŁŌĆ£Õ╣┤ŌĆØõĮ£õĖ║µ¢░ńÜäķö«’╝īŌĆ£µĖ®Õ║”ŌĆØõĮ£õĖ║µ¢░ńÜäÕĆ╝’╝īÕåÖÕģźÕł░õĖŖõĖŗµ¢ćcontextõĖŁŃĆéÕ£©Ķ┐Öķćī’╝īÕøĀõĖ║µ»ÅõĖĆÕ╣┤µ£ēÕżÜĶĪīµĢ░µŹ«’╝īÕøĀµŁżµ»ÅõĖĆĶĪīķāĮõ╝ÜĶŠōÕć║õĖĆõĖ¬<Õ╣┤õ╗Į, µ░öµĖ®>ķö«ÕĆ╝Õ»╣ŃĆé
õĖŗķØ󵜻µÄ¦ÕłČÕÅ░µēōÕŹ░ń╗ōµ×£’╝Ü
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
Before┬ĀMapper:┬Ā0,┬Ā2014010114======After┬ĀMapper:2014,┬Ā14
Before┬ĀMapper:┬Ā11,┬Ā2014010216======After┬ĀMapper:2014,┬Ā16
Before┬ĀMapper:┬Ā22,┬Ā2014010317======After┬ĀMapper:2014,┬Ā17
Before┬ĀMapper:┬Ā33,┬Ā2014010410======After┬ĀMapper:2014,┬Ā10
Before┬ĀMapper:┬Ā44,┬Ā2014010506======After┬ĀMapper:2014,┬Ā6
Before┬ĀMapper:┬Ā55,┬Ā2012010609======After┬ĀMapper:2012,┬Ā9
Before┬ĀMapper:┬Ā66,┬Ā2012010732======After┬ĀMapper:2012,┬Ā32
Before┬ĀMapper:┬Ā77,┬Ā2012010812======After┬ĀMapper:2012,┬Ā12
Before┬ĀMapper:┬Ā88,┬Ā2012010919======After┬ĀMapper:2012,┬Ā19
Before┬ĀMapper:┬Ā99,┬Ā2012011023======After┬ĀMapper:2012,┬Ā23
Before┬ĀMapper:┬Ā110,┬Ā2001010116======After┬ĀMapper:2001,┬Ā16
Before┬ĀMapper:┬Ā121,┬Ā2001010212======After┬ĀMapper:2001,┬Ā12
Before┬ĀMapper:┬Ā132,┬Ā2001010310======After┬ĀMapper:2001,┬Ā10
Before┬ĀMapper:┬Ā143,┬Ā2001010411======After┬ĀMapper:2001,┬Ā11
Before┬ĀMapper:┬Ā154,┬Ā2001010529======After┬ĀMapper:2001,┬Ā29
Before┬ĀMapper:┬Ā165,┬Ā2013010619======After┬ĀMapper:2013,┬Ā19
Before┬ĀMapper:┬Ā176,┬Ā2013010722======After┬ĀMapper:2013,┬Ā22
Before┬ĀMapper:┬Ā187,┬Ā2013010812======After┬ĀMapper:2013,┬Ā12
Before┬ĀMapper:┬Ā198,┬Ā2013010929======After┬ĀMapper:2013,┬Ā29
Before┬ĀMapper:┬Ā209,┬Ā2013011023======After┬ĀMapper:2013,┬Ā23
Before┬ĀMapper:┬Ā220,┬Ā2008010105======After┬ĀMapper:2008,┬Ā5
Before┬ĀMapper:┬Ā231,┬Ā2008010216======After┬ĀMapper:2008,┬Ā16
Before┬ĀMapper:┬Ā242,┬Ā2008010337======After┬ĀMapper:2008,┬Ā37
Before┬ĀMapper:┬Ā253,┬Ā2008010414======After┬ĀMapper:2008,┬Ā14
Before┬ĀMapper:┬Ā264,┬Ā2008010516======After┬ĀMapper:2008,┬Ā16
Before┬ĀMapper:┬Ā275,┬Ā2007010619======After┬ĀMapper:2007,┬Ā19
Before┬ĀMapper:┬Ā286,┬Ā2007010712======After┬ĀMapper:2007,┬Ā12
Before┬ĀMapper:┬Ā297,┬Ā2007010812======After┬ĀMapper:2007,┬Ā12
Before┬ĀMapper:┬Ā308,┬Ā2007010999======After┬ĀMapper:2007,┬Ā99
Before┬ĀMapper:┬Ā319,┬Ā2007011023======After┬ĀMapper:2007,┬Ā23
Before┬ĀMapper:┬Ā330,┬Ā2010010114======After┬ĀMapper:2010,┬Ā14
Before┬ĀMapper:┬Ā341,┬Ā2010010216======After┬ĀMapper:2010,┬Ā16
Before┬ĀMapper:┬Ā352,┬Ā2010010317======After┬ĀMapper:2010,┬Ā17
Before┬ĀMapper:┬Ā363,┬Ā2010010410======After┬ĀMapper:2010,┬Ā10
Before┬ĀMapper:┬Ā374,┬Ā2010010506======After┬ĀMapper:2010,┬Ā6
Before┬ĀMapper:┬Ā385,┬Ā2015010649======After┬ĀMapper:2015,┬Ā49
Before┬ĀMapper:┬Ā396,┬Ā2015010722======After┬ĀMapper:2015,┬Ā22
Before┬ĀMapper:┬Ā407,┬Ā2015010812======After┬ĀMapper:2015,┬Ā12
Before┬ĀMapper:┬Ā418,┬Ā2015010999======After┬ĀMapper:2015,┬Ā99
Before┬ĀMapper:┬Ā429,┬Ā2015011023======After┬ĀMapper:2015,┬Ā23
Before┬ĀReduce:┬Ā2001,┬Ā12,┬Ā10,┬Ā11,┬Ā29,┬Ā16,┬Ā======After┬ĀReduce:┬Ā2001,┬Ā29
Before┬ĀReduce:┬Ā2007,┬Ā23,┬Ā19,┬Ā12,┬Ā12,┬Ā99,┬Ā======After┬ĀReduce:┬Ā2007,┬Ā99
Before┬ĀReduce:┬Ā2008,┬Ā16,┬Ā14,┬Ā37,┬Ā16,┬Ā5,┬Ā======After┬ĀReduce:┬Ā2008,┬Ā37
Before┬ĀReduce:┬Ā2010,┬Ā10,┬Ā6,┬Ā14,┬Ā16,┬Ā17,┬Ā======After┬ĀReduce:┬Ā2010,┬Ā17
Before┬ĀReduce:┬Ā2012,┬Ā19,┬Ā12,┬Ā32,┬Ā9,┬Ā23,┬Ā======After┬ĀReduce:┬Ā2012,┬Ā32
Before┬ĀReduce:┬Ā2013,┬Ā23,┬Ā29,┬Ā12,┬Ā22,┬Ā19,┬Ā======After┬ĀReduce:┬Ā2013,┬Ā29
Before┬ĀReduce:┬Ā2014,┬Ā14,┬Ā6,┬Ā10,┬Ā17,┬Ā16,┬Ā======After┬ĀReduce:┬Ā2014,┬Ā17
Before┬ĀReduce:┬Ā2015,┬Ā23,┬Ā49,┬Ā22,┬Ā12,┬Ā99,┬Ā======After┬ĀReduce:┬Ā2015,┬Ā99
Finished |
┬Ā
┬Ā┬Ā┬Ā┬Āµē¦ĶĪīń╗ōµ×£’╝Ü
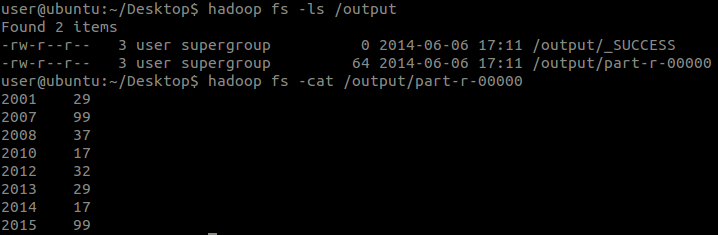
Õ»╣Õłåµ×ÉńÜäķ¬īĶ»ü
┬Ā┬Ā┬Ā┬Āõ╗ĵēōÕŹ░ńÜ䵌źÕ┐ŚõĖŁÕÅ»õ╗źń£ŗÕć║’╝Ü
-
MapperńÜäĶŠōÕģźµĢ░µŹ«(k1,v1)µĀ╝Õ╝ŵś»’╝Üķ╗śĶ«żńÜäµīēĶĪīÕłåńÜäķö«ÕĆ╝Õ»╣<0, 2010012325>’╝ī<11, 2012010123>...
-
ReducerńÜäĶŠōÕģźµĢ░µŹ«µĀ╝Õ╝ŵś»’╝ܵŖŖńøĖÕÉīńÜäķö«ÕÉłÕ╣ČÕÉÄńÜäķö«ÕĆ╝Õ»╣’╝Ü<2001, [12, 32, 25...]>’╝ī<2007, [20, 34, 30...]>...
-
ReducerńÜäĶŠōÕć║µĢ░(k3,v3)µŹ«µĀ╝Õ╝ŵś»’╝Üń╗ÅĶć¬ÕĘ▒Õ£©ReducerõĖŁÕåÖÕć║ńÜäµĀ╝Õ╝Å’╝Ü<2001, 32>’╝ī<2007, 34>...
┬Ā ┬Ā ÕģČõĖŁ’╝īńö▒õ║ÄĶŠōÕģźµĢ░µŹ«Õż¬Õ░Å’╝īMapĶ┐ćń©ŗńÜäń¼¼1ķśČµ«ĄĶ┐ÖķćīõĖŹĶāĮĶ»üµśÄŃĆéõĮåõ║ŗÕ«×õĖŖµś»Ķ┐ÖµĀĘńÜäŃĆé
┬Ā┬Ā┬Ā┬Āń╗ōĶ«║õĖŁń¼¼õĖĆńé╣ķ¬īĶ»üõ║åMapĶ┐ćń©ŗńÜäń¼¼2ķśČµ«Ą’╝ÜŌĆ£ķö«ŌĆصś»µ»ÅõĖĆĶĪīńÜäĶĄĘÕ¦ŗõĮŹńĮ«(ÕŹĢõĮŹµś»ÕŁŚĶŖé)’╝īŌĆ£ÕĆ╝ŌĆصś»µ£¼ĶĪīńÜäµ¢ćµ£¼ÕåģÕ«╣ŃĆé
┬Ā┬Ā┬Ā┬ĀÕÅ”Õż¢’╝īķĆÜĶ┐ćReduceńÜäÕćĀĶĪī
┬Ā
|
1
2
3
4
5
6
7
8
|
Before┬ĀReduce:┬Ā2001,┬Ā12,┬Ā10,┬Ā11,┬Ā29,┬Ā16,┬Ā======After┬ĀReduce:┬Ā2001,┬Ā29
Before┬ĀReduce:┬Ā2007,┬Ā23,┬Ā19,┬Ā12,┬Ā12,┬Ā99,┬Ā======After┬ĀReduce:┬Ā2007,┬Ā99
Before┬ĀReduce:┬Ā2008,┬Ā16,┬Ā14,┬Ā37,┬Ā16,┬Ā5,┬Ā======After┬ĀReduce:┬Ā2008,┬Ā37
Before┬ĀReduce:┬Ā2010,┬Ā10,┬Ā6,┬Ā14,┬Ā16,┬Ā17,┬Ā======After┬ĀReduce:┬Ā2010,┬Ā17
Before┬ĀReduce:┬Ā2012,┬Ā19,┬Ā12,┬Ā32,┬Ā9,┬Ā23,┬Ā======After┬ĀReduce:┬Ā2012,┬Ā32
Before┬ĀReduce:┬Ā2013,┬Ā23,┬Ā29,┬Ā12,┬Ā22,┬Ā19,┬Ā======After┬ĀReduce:┬Ā2013,┬Ā29
Before┬ĀReduce:┬Ā2014,┬Ā14,┬Ā6,┬Ā10,┬Ā17,┬Ā16,┬Ā======After┬ĀReduce:┬Ā2014,┬Ā17
Before┬ĀReduce:┬Ā2015,┬Ā23,┬Ā49,┬Ā22,┬Ā12,┬Ā99,┬Ā======After┬ĀReduce:┬Ā2015,┬Ā99
|
┬Ā
┬Ā┬Ā┬Ā┬ĀÕÅ»õ╗źĶ»üÕ«×MapĶ┐ćń©ŗńÜäń¼¼4ķśČµ«Ą’╝ÜÕģłÕłåÕī║’╝īńäČÕÉÄÕ»╣µ»ÅõĖ¬ÕłåÕī║ķāĮµē¦ĶĪīõĖƵ¼ĪReduce’╝łMapĶ┐ćń©ŗń¼¼6ķśČµ«Ą’╝ēŃĆé
┬Ā┬Ā┬Ā┬ĀÕ»╣õ║ÄMapperńÜäĶŠōÕć║’╝īÕēŹµ¢ćõĖŁµÅÉÕł░’╝ÜÕ”éµ×£µ▓Īµ£ēReduceĶ┐ćń©ŗ’╝īMapperńÜäĶŠōÕć║õ╝Üńø┤µÄźÕåÖÕģźµ¢ćõ╗ČŃĆéõ║ĵś»µłæõ╗¼µŖŖReduceµ¢╣µ│ĢÕÄ╗µÄē’╝łµ│©ķćŖµÄēń¼¼95ĶĪīÕŹ│ÕÅ»’╝ēŃĆé
┬Ā ┬Ā ÕåŹµē¦ĶĪī’╝īõĖŗķØ󵜻µÄ¦ÕłČÕÅ░µēōÕŹ░ń╗ōµ×£’╝Ü┬Ā
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
Before┬ĀMapper:┬Ā0,┬Ā2014010114======After┬ĀMapper:2014,┬Ā14
Before┬ĀMapper:┬Ā11,┬Ā2014010216======After┬ĀMapper:2014,┬Ā16
Before┬ĀMapper:┬Ā22,┬Ā2014010317======After┬ĀMapper:2014,┬Ā17
Before┬ĀMapper:┬Ā33,┬Ā2014010410======After┬ĀMapper:2014,┬Ā10
Before┬ĀMapper:┬Ā44,┬Ā2014010506======After┬ĀMapper:2014,┬Ā6
Before┬ĀMapper:┬Ā55,┬Ā2012010609======After┬ĀMapper:2012,┬Ā9
Before┬ĀMapper:┬Ā66,┬Ā2012010732======After┬ĀMapper:2012,┬Ā32
Before┬ĀMapper:┬Ā77,┬Ā2012010812======After┬ĀMapper:2012,┬Ā12
Before┬ĀMapper:┬Ā88,┬Ā2012010919======After┬ĀMapper:2012,┬Ā19
Before┬ĀMapper:┬Ā99,┬Ā2012011023======After┬ĀMapper:2012,┬Ā23
Before┬ĀMapper:┬Ā110,┬Ā2001010116======After┬ĀMapper:2001,┬Ā16
Before┬ĀMapper:┬Ā121,┬Ā2001010212======After┬ĀMapper:2001,┬Ā12
Before┬ĀMapper:┬Ā132,┬Ā2001010310======After┬ĀMapper:2001,┬Ā10
Before┬ĀMapper:┬Ā143,┬Ā2001010411======After┬ĀMapper:2001,┬Ā11
Before┬ĀMapper:┬Ā154,┬Ā2001010529======After┬ĀMapper:2001,┬Ā29
Before┬ĀMapper:┬Ā165,┬Ā2013010619======After┬ĀMapper:2013,┬Ā19
Before┬ĀMapper:┬Ā176,┬Ā2013010722======After┬ĀMapper:2013,┬Ā22
Before┬ĀMapper:┬Ā187,┬Ā2013010812======After┬ĀMapper:2013,┬Ā12
Before┬ĀMapper:┬Ā198,┬Ā2013010929======After┬ĀMapper:2013,┬Ā29
Before┬ĀMapper:┬Ā209,┬Ā2013011023======After┬ĀMapper:2013,┬Ā23
Before┬ĀMapper:┬Ā220,┬Ā2008010105======After┬ĀMapper:2008,┬Ā5
Before┬ĀMapper:┬Ā231,┬Ā2008010216======After┬ĀMapper:2008,┬Ā16
Before┬ĀMapper:┬Ā242,┬Ā2008010337======After┬ĀMapper:2008,┬Ā37
Before┬ĀMapper:┬Ā253,┬Ā2008010414======After┬ĀMapper:2008,┬Ā14
Before┬ĀMapper:┬Ā264,┬Ā2008010516======After┬ĀMapper:2008,┬Ā16
Before┬ĀMapper:┬Ā275,┬Ā2007010619======After┬ĀMapper:2007,┬Ā19
Before┬ĀMapper:┬Ā286,┬Ā2007010712======After┬ĀMapper:2007,┬Ā12
Before┬ĀMapper:┬Ā297,┬Ā2007010812======After┬ĀMapper:2007,┬Ā12
Before┬ĀMapper:┬Ā308,┬Ā2007010999======After┬ĀMapper:2007,┬Ā99
Before┬ĀMapper:┬Ā319,┬Ā2007011023======After┬ĀMapper:2007,┬Ā23
Before┬ĀMapper:┬Ā330,┬Ā2010010114======After┬ĀMapper:2010,┬Ā14
Before┬ĀMapper:┬Ā341,┬Ā2010010216======After┬ĀMapper:2010,┬Ā16
Before┬ĀMapper:┬Ā352,┬Ā2010010317======After┬ĀMapper:2010,┬Ā17
Before┬ĀMapper:┬Ā363,┬Ā2010010410======After┬ĀMapper:2010,┬Ā10
Before┬ĀMapper:┬Ā374,┬Ā2010010506======After┬ĀMapper:2010,┬Ā6
Before┬ĀMapper:┬Ā385,┬Ā2015010649======After┬ĀMapper:2015,┬Ā49
Before┬ĀMapper:┬Ā396,┬Ā2015010722======After┬ĀMapper:2015,┬Ā22
Before┬ĀMapper:┬Ā407,┬Ā2015010812======After┬ĀMapper:2015,┬Ā12
Before┬ĀMapper:┬Ā418,┬Ā2015010999======After┬ĀMapper:2015,┬Ā99
Before┬ĀMapper:┬Ā429,┬Ā2015011023======After┬ĀMapper:2015,┬Ā23
Finished |
┬Ā
┬Ā┬Ā┬Ā┬ĀÕåŹµØźń£ŗń£ŗµē¦ĶĪīń╗ōµ×£’╝Ü
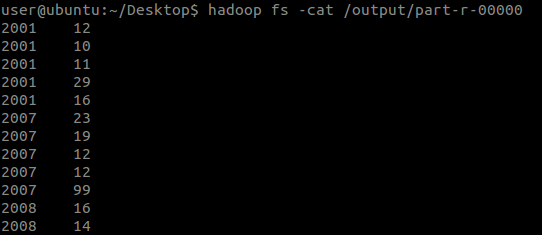
┬Ā┬Ā┬Ā┬Āń╗ōµ×£Ķ┐śµ£ēÕŠłÕżÜĶĪī’╝īµ▓Īµ£ēµł¬ÕøŠõ║åŃĆé
┬Ā┬Ā┬Ā┬Āńö▒õ║ĵ▓Īµ£ēµē¦ĶĪīReduceµōŹõĮ£’╝īÕøĀµŁżĶ┐ÖõĖ¬Õ░▒µś»MapperĶŠōÕć║ńÜäõĖŁķŚ┤µ¢ćõ╗ČńÜäÕåģÕ«╣õ║åŃĆé
┬Ā┬Ā┬Ā┬Āõ╗ĵēōÕŹ░ńÜ䵌źÕ┐ŚÕÅ»õ╗źń£ŗÕć║’╝Ü
┬Ā
-
MapperńÜäĶŠōÕć║µĢ░µŹ«(k2, v2)µĀ╝Õ╝ŵś»’╝Üń╗ÅĶć¬ÕĘ▒Õ£©MapperõĖŁÕåÖÕć║ńÜäµĀ╝Õ╝Å’╝Ü<2010, 25>’╝ī<2012, 23>...
┬Ā┬Ā┬Ā┬Āõ╗ÄĶ┐ÖõĖ¬ń╗ōµ×£õĖŁÕÅ»õ╗źń£ŗÕć║’╝īÕĤµĢ░µŹ«µ¢ćõ╗ČõĖŁńÜäµ»ÅõĖĆĶĪīńĪ«Õ«×ķāĮµ£ēõĖĆĶĪīĶŠōÕć║’╝īķéŻõ╣łMapĶ┐ćń©ŗńÜäń¼¼3ķśČµ«ĄÕ░▒Ķ»üÕ«×õ║åŃĆé
┬Ā
┬Ā┬Ā┬Ā┬Āõ╗ÄĶ┐ÖõĖ¬ń╗ōµ×£õĖŁĶ┐śÕÅ»õ╗źń£ŗÕć║’╝īŌĆ£Õ╣┤õ╗ĮŌĆØÕĘ▓ń╗ÅõĖŹµś»ĶŠōÕģźń╗ÖMapperńÜäķĪ║Õ║Åõ║å’╝īĶ┐Öõ╣¤Ķ»┤µśÄõ║åÕ£©MapĶ┐ćń©ŗõĖŁõ╣¤µīēńģ¦Keyµē¦ĶĪīõ║åµÄÆÕ║ŵōŹõĮ£’╝īÕŹ│MapĶ┐ćń©ŗńÜäń¼¼5ķśČµ«ĄŃĆé



ńøĖÕģ│µÄ©ĶŹÉ
µ£¼µ¢ćÕ░åÕ»╣MapReduceńÜäÕ¤║µ£¼µ”éÕ┐ĄŃĆüń╝¢ń©ŗµ©ĪÕ×ŗŃĆüµĪåµ×ČÕĤńÉåŃĆüńøĖÕģ│ń╗äõ╗Čõ╗źÕÅŖÕģźķŚ©ń╝¢ń©ŗÕ«×õŠŗńŁēĶ┐øĶĪīĶ»”ń╗åõ╗ŗń╗ŹŃĆé MapReduceµś»õĖĆń¦ŹÕłåÕĖāÕ╝ÅĶ«Īń«Śµ©ĪÕ×ŗ’╝īĶāĮÕż¤Õ░åÕżŹµØéńÜäµĢ░µŹ«ÕżäńÉåĶ┐ćń©ŗµŖĮĶ▒ĪõĖ║MapÕÆīReduceõĖżõĖ¬ń«ĆÕŹĢńÜäµōŹõĮ£’╝īõ╗ÄĶĆīń«ĆÕī¢Õ╣ČĶĪīĶ«Īń«ŚńÜä...
ŃĆŖHadoopÕ«×µłś-ķÖåÕśēµüÆ(ķ½śµĖģÕ«īµĢ┤ńēł)ŃĆŗµś»õĖƵ£¼µĘ▒ÕģźµĄģÕć║õ╗ŗń╗ŹHadoopµŖƵ£»ńÜäõ╣”ń▒Ź’╝īÕ░żÕģČķĆéÕÉłÕłØÕŁ”ĶĆģõĮ£õĖ║ÕģźķŚ©µĢÖµØÉŃĆéHadoopõĮ£õĖ║Õż¦µĢ░µŹ«ÕżäńÉåķóåÕ¤¤ńÜäÕ¤║ń¤│’╝īÕģČķćŹĶ”üµĆ¦õĖŹĶ©ĆĶĆīÕ¢╗ŃĆéĶ┐Öµ£¼õ╣”Ķ»”ń╗åĶ«▓Ķ¦Żõ║åHadoopńÜäµĀĖÕ┐āµ”éÕ┐ĄŃĆüµ×ȵ×äõ╗źÕÅŖÕ«×ķÖģÕ║öńö©’╝ī...
### ķ½śń║¦ĶĮ»õ╗Čõ║║µēŹÕ¤╣Ķ«ŁõĖōÕ«Č-HadoopĶ»Šń©ŗĶĄäµ¢Ö-3-ń¼¼õĖēń½Ā - MapReduce & YARNÕģźķŚ© #### ń¤źĶ»åńé╣õĖĆ’╝ÜÕłåÕĖāÕ╝ÅĶ«Īń«Śµ”éĶ┐░ - **Õ«Üõ╣ē**’╝ÜÕłåÕĖāÕ╝ÅĶ«Īń«Śµś»õĖĆń¦ŹĶ«Īń«Śµ©ĪÕ×ŗ’╝īÕ«āķĆÜĶ┐ćńĮæń╗£Õ░åõ╗╗ÕŖĪÕłåķģŹÕł░ÕżÜÕÅ░Ķ«Īń«Śµ£║õĖŖÕ╣ČĶĪīÕżäńÉå’╝īõ╗źµÅÉķ½śĶ«Īń«ŚµĢłńÄć...
ŃĆŖHadoop 2 Õ┐½ķƤÕģźķŚ©µīćÕŹŚŃĆŗµś»õĖƵ£¼ķØ×ÕĖĖķĆéÕÉłÕłØÕŁ”ĶĆģÕÆīµ£ēõĖĆÕ«Üń╗Åķ¬īńÜäńö©µłĘõĮ┐ńö©ńÜäõ╣”ń▒Ź’╝īÕ«āõĖŹõ╗ģµČĄńø¢õ║åHadoop 2.xńÜäµĀĖÕ┐āµŖƵ£»ÕÆīńē╣µĆ¦’╝īĶ┐śµÅÉõŠøõ║åÕż¦ķćÅńÜäÕ«×ĶĘĄµīćÕ»╝ÕÆīµĪłõŠŗÕłåµ×É’╝īµ£ēÕŖ®õ║ÄĶ»╗ĶĆģµø┤Õ┐½Õ£░µÄīµÅĪHadoopńÜäńøĖÕģ│ń¤źĶ»åÕÆīµŖƵ£»ŃĆé
HadoopÕģźķŚ©µēŗÕåīńÜäķ½śµĖģńēłńĪ«õ┐Øõ║åķśģĶ»╗õĮōķ¬ī’╝īµĖģµÖ░ńÜäµ¢ćÕŁŚÕÆīÕøŠĶĪ©µ£ēÕŖ®õ║ÄńÉåĶ¦ŻÕżŹµØéńÜäµ”éÕ┐ĄŃĆéõ╣”ńŁŠńēłÕłÖõĮ┐ÕŠŚÕ£©Õż¦ķćÅÕåģÕ«╣õĖŁÕ┐½ķĆ¤Õ«ÜõĮŹńē╣Õ«Üń½ĀĶŖéÕÅśÕŠŚĶĮ╗µØŠ’╝īĶ┐ÖÕ»╣õ║ĵĘ▒ÕģźÕŁ”õ╣ĀÕÆīµ¤źµēŠńē╣Õ«Üń¤źĶ»åńé╣µ×üÕģČķćŹĶ”üŃĆéõ╗źõĖŗµś»Õ»╣HadoopÕ╝ĆÕÅæĶĆģÕģźķŚ©õĖŁõĖ╗Ķ”üń¤źĶ»å...
"HadoopÕģźķŚ©Õł░ń▓ŠķĆÜ"ńÜäÕŁ”õ╣ĀĶĄäµ¢ÖµŚ©Õ£©ÕĖ«ÕŖ®ÕłØÕŁ”ĶĆģµÄīµÅĪĶ┐ÖõĖĆÕ╝║Õż¦ńÜäµĪåµ×Č’╝īÕ╣ČķĆɵŁźµÖŗÕŹćõĖ║õĖōÕ«ČŃĆéõ╗źõĖŗµś»Õ»╣HadoopÕÅŖÕģČńøĖÕģ│µ”éÕ┐ĄńÜäĶ»”ń╗åĶ¦ŻĶ»╗ŃĆé õĖĆŃĆüHadoopµ”éĶ┐░ Hadoopµś»ńö▒ApacheÕ¤║ķćæõ╝ÜÕ╝ĆÕÅæńÜäõĖĆõĖ¬Õ╝Ƶ║ɵĪåµ×Č’╝īõĖ╗Ķ”üńö©õ║ÄÕżäńÉåÕÆīÕŁśÕé©Õż¦...
ķĆÜĶ┐ćõ╗źõĖŖõ╗ŗń╗ŹÕÅ»õ╗źń£ŗÕć║’╝īŃĆŖHadoopÕģźķŚ©µīćÕŹŚŃĆŗõĖŹõ╗ģµČĄńø¢õ║åHadoopńÜäÕ¤║ńĪƵ”éÕ┐ĄŃĆüÕ«ēĶŻģķģŹńĮ«µĄüń©ŗ’╝īĶ┐śµĘ▒ÕģźĶ«▓Ķ¦Żõ║åHDFSÕÆīMapReduceńÜäÕĘźõĮ£ÕĤńÉåÕÅŖÕ«×ķÖģÕ║öńö©µĪłõŠŗŃĆéĶ┐ÖÕ»╣õ║ÄÕłØÕŁ”ĶĆģµØźĶ»┤µś»ķØ×ÕĖĖÕ«ØĶ┤ĄńÜäĶĄäµ║É’╝īĶāĮÕż¤ÕĖ«ÕŖ®õ╗¢õ╗¼Õ┐½ķƤµÄīµÅĪHadoopńÜä...
Hadoopµś»õĖĆõĖ¬Õ╝Ƶ║ÉńÜäÕłåÕĖāÕ╝ÅĶ«Īń«ŚµĪåµ×Č’╝īÕ«āÕģüĶ«Ėńö©µłĘķĆÜĶ┐ćń«ĆÕŹĢµśōńö©ńÜäń╝¢ń©ŗµ©ĪÕ×ŗÕżäńÉåÕż¦Õ×ŗµĢ░µŹ«ķøå’╝īĶĆīHDFS’╝łHadoop Distributed File System’╝ēµś»ÕģȵĀĖÕ┐āń╗äõ╗Č’╝īńö©õ║ÄÕŁśÕé©ÕÆīÕżäńÉåÕż¦µĢ░µŹ«ŃĆé ķ”¢Õģł’╝īHadoopµś»õĖĆõĖ¬ńö▒ApacheĶĮ»õ╗ČÕ¤║ķćæõ╝ÜÕ╝ĆÕÅæ...
ŃĆŖHadoopÕģźķŚ©Õ«×µłśµēŗÕåīŃĆŗõĖŁÕÅ»ĶāĮÕīģÕÉ½ÕżÜõĖ¬Õ«×ķÖģµĪłõŠŗ’╝īÕ”éµŚźÕ┐ŚÕłåµ×ÉŃĆüµÄ©ĶŹÉń│╗ń╗¤ŃĆüńżŠõ║żńĮæń╗£Õłåµ×ÉńŁē’╝īķĆÜĶ┐ćĶ┐Öõ║øµĪłõŠŗ’╝īĶ»╗ĶĆģÕÅ»õ╗źµø┤ÕźĮÕ£░ńÉåĶ¦ŻHadoopÕ£©Õ«×ķÖģÕĘźõĮ£õĖŁńÜäÕ║öńö©’╝īÕ╣ČķĆɵŁźµÅÉÕŹćĶ¦ŻÕå│ÕżŹµØéķŚ«ķóśńÜäĶāĮÕŖøŃĆé µĆ╗ńÜäµØźĶ»┤’╝īŃĆŖHadoopÕģźķŚ©Õ«×µłś...
µ£¼µĢÖń©ŗŃĆŖHadoopÕģźķŚ©µĢÖń©ŗŃĆŗµŚ©Õ£©õĖ║ÕłØÕŁ”ĶĆģµÅÉõŠøÕģ©ķØóõĖöµĘ▒ÕģźńÜäµīćÕ»╝’╝īÕĖ«ÕŖ®õ╗¢õ╗¼Õ┐½ķƤńÉåĶ¦ŻÕ╣ȵÄīµÅĪHadoopńÜäÕ¤║µ£¼µ”éÕ┐ĄŃĆüµ×ȵ×äÕÅŖÕ║öńö©ŃĆéµĢÖń©ŗńö▒HadoopµŖƵ£»Ķ«║ÕØøÕ£©2010Õ╣┤Õć║ńēł’╝īõĖ║ÕĮōµŚČńÜäÕ╝ĆÕÅæĶĆģµÅÉõŠøõ║åÕ«ØĶ┤ĄńÜäĶĄäµ║ÉŃĆé õĖĆŃĆüHadoopń«Ćõ╗ŗ Hadoop...
µĆ╗õ╣ŗ’╝īHadoopÕģźķŚ©µĢÖń©ŗõĖ║ÕłØÕŁ”ĶĆģµÅÉõŠøõ║åÕ»╣HadoopµĀĖÕ┐āµ”éÕ┐ĄńÜäńÉåĶ¦Ż’╝īÕĖ«ÕŖ®õ╗¢õ╗¼µÄīµÅĪÕ”éõĮĢÕ«ēĶŻģÕÆīõĮ┐ńö©HadoopĶ┐øĶĪīµĢ░µŹ«ÕŁśÕé©õĖÄÕżäńÉå’╝īÕ╣ČńÉåĶ¦ŻHadoopńÜäĶ«ŠĶ«ĪµĆصā│ÕÆīõĮōń│╗µ×ȵ×äŃĆéķĆÜĶ┐ćÕŁ”õ╣ĀHadoop’╝īÕłØÕŁ”ĶĆģÕÅ»õ╗źÕģźķŚ©Õł░Õż¦µĢ░µŹ«ÕżäńÉåńÜäÕ╣┐ķśöÕż®Õ£░õĖŁ’╝ī...
õĖ╗Ķ”üÕłåõĖ║õ╗źõĖŗÕćĀõĖ¬ķā©Õłå’╝ÜHadoopńÄ»ÕóāÕćåÕżćõĖĵ£¼Õ£░µ©ĪÕ╝ÅŃĆüHadoopõ╝¬ÕłåÕĖāÕ╝ÅķøåńŠżµ©ĪÕ╝ÅŃĆüHadoopÕ«īÕģ©ÕłåÕĖāÕ╝ÅķøåńŠżµ©ĪÕ╝ÅŃĆüHDFS ShellÕæĮõ╗żõ╗źÕÅŖMapReduceÕģźķŚ©µĪłõŠŗwordcountŃĆé ### HadoopńÄ»ÕóāÕćåÕżćÕÅŖµ£¼Õ£░µ©ĪÕ╝Å #### Õ«×ķ¬īńø«ńÜä - µÄīµÅĪ...
Õ£©Ķ┐ÖõĖ¬µĪłõŠŗõĖŁ’╝īµłæõ╗¼Õ░åµĘ▒ÕģźµÄóĶ«©Õ”éõĮĢÕ£© Hadoop ńÄ»ÕóāõĖŁõĮ┐ńö© MapReduce Õ«×ńÄ░ WordCountŃĆé ŃĆɵÅÅĶ┐░ŃĆæÕ£© Hadoop ńÄ»ÕóāõĖŁ’╝īWordCount ńÜäÕ«×ńÄ░õĖ╗Ķ”üµČēÕÅŖõĖżõĖ¬Õģ│ķö«ķśČµ«Ą’╝ÜMap ķśČµ«ĄÕÆī Reduce ķśČµ«ĄŃĆéMap ķśČµ«ĄÕ░åÕĤզŗĶŠōÕģźµĢ░µŹ«’╝łķĆÜÕĖĖµś»...
ŃĆÉHadoopÕģźķŚ©µēŗÕåīŃĆæµś»õĖƵ£¼õĖōõĖ║ÕłØÕŁ”ĶĆģĶ«ŠĶ«ĪńÜäµīćÕŹŚ’╝īµŚ©Õ£©ÕĖ«ÕŖ®Ķ»╗ĶĆģÕ┐½ķƤµÄīµÅĪHadoopĶ┐ÖõĖĆÕłåÕĖāÕ╝ÅĶ«Īń«ŚµĪåµ×ČńÜäÕ¤║ńĪĆń¤źĶ»åÕÆīµĀĖÕ┐āµ”éÕ┐ĄŃĆéHadoopµś»ApacheĶĮ»õ╗ČÕ¤║ķćæõ╝ÜńÜäõĖĆõĖ¬Õ╝Ƶ║ÉķĪ╣ńø«’╝īÕ«āńÜäÕć║ńÄ░Ķ¦ŻÕå│õ║åÕż¦µĢ░µŹ«ÕżäńÉåõĖŁńÜäĶ»ĖÕżÜµīæµłś’╝īÕīģµŗ¼µĢ░µŹ«...
ń¼¼Õøøń½Ā HDFSńÜäJavaAPIµōŹõĮ£ÕÆīMapReduceÕģźķŚ© ń¼¼õ║öń½Ā MapReduceńÜäWordCountµĪłõŠŗÕÆīÕłåÕī║ ń¼¼ÕģŁń½Ā MapReduceńÜäµÄÆÕ║ÅÕÆīÕ║ÅÕłŚÕī¢ ń¼¼õĖāń½Ā MapReduceńÜäĶ┐ÉĶĪīµ£║ÕłČÕÆījoinµōŹõĮ£ ń¼¼Õģ½ń½Ā MapReduceńÜäÕģČõ╗¢µōŹõĮ£ÕÆīyarn ń¼¼õ╣Øń½Ā µĢ░õ╗ōHiveÕ¤║µ£¼...
4. MapReduceÕģźķŚ©ń╝¢ń©ŗ’╝ł9ÕŁ”µŚČ’╝ē - MapReduceÕĤńÉå - MapReduceń╝¢ń©ŗķĆ╗ĶŠæ - õĮ┐ńö©EclipseĶ┐øĶĪīMapReduceÕ╝ĆÕÅæ - Ķć¬Õ«Üõ╣ēķö«ÕĆ╝Õ»╣ŃĆüCombinerÕÆīPartitionerńÜäõĮ┐ńö© 5. MapReduceĶ┐øķśČń╝¢ń©ŗ’╝ł12ÕŁ”µŚČ’╝ē - MapReduceńÜäķ½śń║¦Õ║öńö© ...
### ÕłåÕĖāÕ╝ÅĶ«Īń«ŚÕ╝Ƶ║ɵĪåµ×ČHadoopÕģźķŚ©Õ«×ĶĘĄ #### õĖĆŃĆüHadoopń«Ćõ╗ŗ Hadoopµś»õĖĆõĖ¬ńö▒ApacheÕ¤║ķćæõ╝Üń╗┤µŖżńÜäÕ╝Ƶ║ÉÕłåÕĖāÕ╝ÅĶ«Īń«ŚµĪåµ×Č’╝īÕ«āÕ¤║õ║ÄJavaĶ»ŁĶ©Ćń╝¢ÕåÖ’╝īõĖ╗Ķ”üńö▒õĖżÕż¦µĀĖÕ┐āń╗äõ╗ȵ×䵳ɒ╝Ü**HDFS’╝łHadoop Distributed File System’╝ē** ÕÆī...
2. **HadoopÕģźķŚ©**’╝Ü - ÕŁ”õ╣ĀÕ”éõĮĢń╝¢Ķ»æHadoopµ║ÉńĀü’╝īĶ┐ÖÕ»╣õ║ÄńÉåĶ¦ŻÕģČÕåģķā©ÕĘźõĮ£ÕĤńÉåÕÆīĶ┐øĶĪīÕ«ÜÕłČÕī¢Õ╝ĆÕÅæĶć│Õģ│ķćŹĶ”üŃĆé - õĮ┐ńö©Hadoop-Eclipse-PluginµÅÆõ╗Č’╝īÕÅ»õ╗źµ¢╣õŠ┐Õ£░Õ£©EclipseõĖŁĶ┐£ń©ŗĶ░āĶ»ĢHadoopń©ŗÕ║Å’╝īĶ┐ÖÕ»╣õ║ÄÕ£©µ£¼Õ£░Õ╝ĆÕÅæÕ╣ČÕ£©ķøåńŠżõĖŖ...