
ŔŻČŔç¬┬áhttp://www.cnblogs.com/LBSer/p/4715395.html
 
ňëŹÚśÁňşÉń╗ÄŠö»ń╗śň«ŁŔŻČŔ┤Ž1ńŞçňŁŚÚĺ▒ňł░ńŻÖÚóŁň«Ł´╝îŔ┐ÖŠś»ŠŚąňŞŞšöčŠ┤╗šÜäńŞÇń╗Š֫ÚÇÜň░Ćń║ő´╝îńŻćńŻťńŞ║ń║ĺŔüöšŻĹšáöňĆĹń║║ňĹśšÜäŔüîńŞÜšŚů´╝Ĺň░▒ŠÇŁŔÇâŠö»ń╗śň«ŁŠëúÚÖĄ1ńŞçń╣őňÉÄ´╝îňŽéŠ×ťš│╗š╗čŠîéŠÄëŠÇÄń╣łňŐ×´╝îŔ┐ÖŠŚÂńŻÖÚóŁň«ŁŔ┤ŽŠłĚň╣Š▓튝ëňó×ňŐá1ńŞç´╝░ŠŹ«ň░▒ń╝Üňç║šÄ░ńŞŹńŞÇŔç┤šŐÂňćÁń║ćŃÇé
ŃÇÇŃÇÇńŞŐŔ┐░ňť║ŠÖ»ňťĘňÉäńެš▒╗ň×őšÜäš│╗š╗čńŞşÚâŻŔ⯊ëżňł░šŤŞń╝╝ňŻ▒ňşÉ´╝öňŽéňťĘšöÁňĽćš│╗š╗čńŞş´╝îňŻôŠťëšöĘŠłĚńŞőňŹĽňÉÄ´╝îÚÖĄń║ćňťĘŔ«óňŹĽŔíĘŠĆĺňůąńŞÇŠŁíŔ«░ňŻĽňĄľ´╝îň»╣ň║öňĽćňôüŔíĘšÜäŔ┐ÖńެňĽćňôüŠĽ░ÚçĆň┐ůÚí╗ňçĆ1ňÉž´╝îŠÇÄń╣łń┐ŁŔ»ü´╝č´╝üňťĘŠÉťš┤óň╣┐ňĹŐš│╗š╗čńŞş´╝îňŻôšöĘŠłĚšé╣ňç╗ŠčÉň╣┐ňĹŐňÉÄ´╝îÚÖĄń║ćňťĘšé╣ňç╗ń║őń╗ÂŔíĘńŞşňó×ňŐáńŞÇŠŁíŔ«░ňŻĽňĄľ´╝îŔ┐śňżŚňÄ╗ňĽćň«ÂŔ┤ŽŠłĚŔíĘńŞşŠëżňł░Ŕ┐ÖńެňĽćň«Âň╣ŠëúÚÖĄň╣┐ňĹŐŔ┤╣ňÉž´╝îŠÇÄń╣łń┐ŁŔ»ü´╝č´╝üšşëšşë´╝Şń┐íňĄžň«ÂŠłľňĄÜŠłľňĄÜň░ĹÚâŻŔ⯚ó░ňł░šŤŞń╝╝ŠâůŠÖ»ŃÇé
ŃÇÇŃÇÇŔ┐Öń║ŤÚŚ«Ú󜊝ČŔ┤ĘńŞŐÚâŻňĆ»ń╗ąŠŐŻŔ▒íńŞ║´╝ÜňŻôńŞÇńެŔíĘŠĽ░ŠŹ«ŠŤ┤Šľ░ňÉÄ´╝îŠÇÄń╣łń┐ŁŔ»üňĆŽńŞÇńެŔíĘšÜ䊼░ŠŹ«ń╣čň┐ůÚí╗ŔŽüŠŤ┤Šľ░ŠłÉňŐčŃÇé
1 ŠťČňť░ń║őňŐí
ŃÇÇŃÇÇŔ┐śŠś»ń╗ąŠö»ń╗śň«ŁŔŻČŔ┤ŽńŻÖÚóŁň«ŁńŞ║ńżő´╝îňüçŔ«żŠťë
ŃÇÇŃÇÇŠö»ń╗śň«ŁŔ┤ŽŠłĚŔíĘ´╝ÜA´╝łid´╝îuserId´╝îamount´╝ëŃÇÇŃÇÇ
ŃÇÇŃÇÇńŻÖÚóŁň«ŁŔ┤ŽŠłĚŔíĘ´╝ÜB´╝łid´╝îuserId´╝îamount´╝ë
ŃÇÇŃÇÇšöĘŠłĚšÜäuserId=1´╝Ť
ŃÇÇŃÇÇń╗ÄŠö»ń╗śň«ŁŔŻČŔ┤Ž1ńŞçňŁŚÚĺ▒ňł░ńŻÖÚóŁň«ŁšÜäňŐĘńŻťňłćńŞ║ńŞĄŠşą´╝Ü
ŃÇÇŃÇÇ1´╝ëŠö»ń╗śň«ŁŔíĘŠëúÚÖĄ1ńŞç´╝Üupdate A set amount=amount-10000 where userId=1;
ŃÇÇŃÇÇ2´╝ëńŻÖÚóŁň«ŁŔíĘňó×ňŐá1ńŞç´╝Üupdate B set amount=amount+10000 where userId=1;
ŃÇÇŃÇÇňŽéńŻĽší«ń┐ŁŠö»ń╗śň«ŁńŻÖÚóŁň«ŁŠöŠö»ň╣│ŔííňĹó´╝芝ëń║║Ŕ»┤Ŕ┐Öńެňżłš«ÇňŹĽňśŤ´╝îňĆ»ń╗ąšöĘń║őňŐíŔžúňć│ŃÇé
|
1
2
3
4
5
|
Begin transaction
         update A set amount=amount-10000 where userId=1;
         update B set amount=amount+10000 where userId=1;
End transaction
commit;
|
ŃÇÇŃÇÇÚŁ×ňŞŞŠşúší«´╝üňŽéŠ×ťńŻáńŻ┐šöĘspringšÜäŔ»ŁńŞÇńެŠ│ĘŔžúň░▒Ŕ⯊É×ň«ÜńŞŐŔ┐░ń║őňŐíňŐčŔâŻŃÇé
|
1
2
3
4
5
|
@Transactional(rollbackFor=Exception.class)
    public void update() {
┬á┬á┬á┬á┬á┬á┬á┬áupdateATable();┬á//ŠŤ┤Šľ░AŔíĘ
┬á┬á┬á┬á┬á┬á┬á┬áupdateBTable();┬á//ŠŤ┤Šľ░BŔíĘ
    }
|
ŃÇÇŃÇÇňŽéŠ×ťš│╗š╗čŔžäŠĘíŔżâň░Ć´╝░ŠŹ«ŔíĘÚâŻňťĘńŞÇńެŠĽ░ŠŹ«ň║ôň«×ńżőńŞŐ´╝îńŞŐŔ┐░ŠťČňť░ń║őňŐ튾╣ň╝ĆňĆ»ń╗ąňżłňąŻňť░Ŕ┐ÉŔíî´╝îńŻćŠś»ňŽéŠ×ťš│╗š╗čŔžäŠĘíŔżâňĄž´╝öňŽéŠö»ń╗śň«ŁŔ┤ŽŠłĚŔíĘňĺîńŻÖÚóŁň«ŁŔ┤ŽŠłĚŔíĘŠśżšäÂńŞŹń╝ÜňťĘňÉîńŞÇńެŠĽ░ŠŹ«ň║ôň«×ńżőńŞŐ´╝îń╗ľń╗ČňżÇňżÇňłćňŞâňťĘńŞŹňÉîšÜäšëęšÉćŔŐéšé╣ńŞŐ´╝îŔ┐ÖŠŚÂŠťČňť░ń║őňŐíňĚ▓š╗ĆňĄ▒ňÄ╗šöĘŠşŽń╣őňť░ŃÇé
ŃÇÇŃÇÇŠŚóšäŠťČňť░ń║őňŐíňĄ▒ŠĽł´╝îňłćňŞâň╝Ćń║őňŐíŔ笚äÂň░▒šÖ╗ńŞŐŔł×ňĆ░ŃÇé
2 ňłćňŞâň╝Ćń║őňŐíÔÇöńŞĄÚśÂŠ«ÁŠĆÉń║ĄňŹĆŔ««
ŃÇÇŃÇÇńŞĄÚśÂŠ«ÁŠĆÉń║ĄňŹĆŔ««´╝łTwo-phase Commit´╝î2PC´╝ëš╗ĆňŞŞŔóźšöĘŠŁąň«×šÄ░ňłćňŞâň╝Ćń║őňŐíŃÇéńŞÇŔłČňłćńŞ║ňŹĆŔ░âňÖĘCňĺîŔőąň╣▓ń║őňŐíŠëžŔíîŔÇůSińŞĄšžŹŔžĺŔë▓´╝îŔ┐ÖÚçîšÜäń║őňŐíŠëžŔíîŔÇůň░▒Šś»ňůĚńŻôšÜ䊼░ŠŹ«ň║ô´╝îňŹĆŔ░âňÖĘňĆ»ń╗ąňĺîń║őňŐíŠëžŔíîňÖĘňťĘńŞÇňĆ░Šť║ňÖĘńŞŐŃÇé
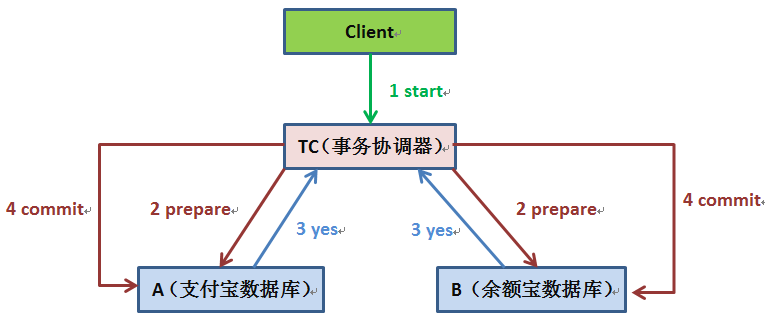
ŃÇÇŃÇÇ1´╝ë ŠłĹń╗ČšÜäň║öšöĘšĘőň║Ć´╝łclient´╝ëňĆĹŔÁĚńŞÇńެň╝ÇňžőŔ»ĚŠ▒éňł░TC´╝Ť
ŃÇÇŃÇÇ2´╝ë TCňůłň░ć<prepare>ŠÂłŠü»ňćÖňł░ŠťČňť░ŠŚąň┐Ś´╝îń╣őňÉÄňÉĹŠëÇŠťëšÜäSiňĆĹŔÁĚ<prepare>ŠÂłŠü»ŃÇéń╗ąŠö»ń╗śň«ŁŔŻČŔ┤Žňł░ńŻÖÚóŁň«ŁńŞ║ńżő´╝îTCš╗ÖAšÜäprepareŠÂłŠü»Šś»ÚÇܚ蹊ö»ń╗śň«ŁŠĽ░ŠŹ«ň║ôšŤŞň║öŔ┤ŽšŤ«ŠëúŠČż1ńŞç´╝îTCš╗ÖBšÜäprepareŠÂłŠü»Šś»ÚÇÜščąńŻÖÚóŁň«ŁŠĽ░ŠŹ«ň║ôšŤŞň║öŔ┤ŽšŤ«ňó×ňŐá1wŃÇéńŞ║ń╗Çń╣łňťĘŠëžŔíîń╗╗ňŐíňëŹÚťÇŔŽüňůłňćÖŠťČňť░ŠŚąň┐Ś´╝îńŞ╗ŔŽüŠś»ńŞ║ń║押ůÚÜťňÉÄŠüóňĄŹšöĘ´╝Čňť░ŠŚąň┐ŚŔÁĚňł░šÄ░ň«×šöčŠ┤╗ńŞşňçşŔ»ü šÜ䊼łŠ×ť´╝îňŽéŠ×ťŠ▓튝늝Čňť░ŠŚąň┐Ś´╝łňçşŔ»ü´╝ë´╝îň«╣ŠśôŠş╗ŠŚáň»╣Ŕ»ü´╝Ť
ŃÇÇŃÇÇ3´╝ë SiŠöÂňł░<prepare>ŠÂłŠü»ňÉÄ´╝îŠëžŔíîňůĚńŻôŠťČŠť║ń║őňŐí´╝îńŻćńŞŹń╝ÜŔ┐ŤŔíîcommit´╝îňŽéŠ×ťŠłÉňŐčŔ┐öňŤ×<yes>´╝îńŞŹŠłÉňŐčŔ┐öňŤ×<no>ŃÇéňÉîšÉć´╝îŔ┐öňŤ×ňëŹÚâŻň║öŠŐŐŔŽüŔ┐öňŤ×šÜäŠÂłŠü»ňćÖňł░ŠŚąň┐ŚÚçî´╝îňŻôńŻťňçşŔ»üŃÇé
ŃÇÇŃÇÇ4´╝ë TCŠöÂÚŤćŠëÇŠťëŠëžŔíîňÖĘŔ┐öňŤ×šÜäŠÂłŠü»´╝îňŽéŠ×ťŠëÇŠťëŠëžŔíîňÖĘÚâŻŔ┐öňŤ×yes´╝îÚéúń╣łš╗ÖŠëÇŠťëŠëžŔíîňÖĘňĆĹšöčÚÇücommitŠÂłŠü»´╝îŠëžŔíîňÖĘŠöÂňł░commitňÉÄŠëžŔíČňť░ń║őňŐíšÜäcommitŠôŹńŻť´╝ŤňŽéŠ×ťŠťëń╗╗ńŞÇńެŠëžŔíîňÖĘŔ┐öňŤ×no´╝îÚéúń╣łš╗ÖŠëÇŠťëŠëžŔíîňÖĘňĆĹÚÇüabortŠÂłŠü»´╝îŠëžŔíîňÖĘŠöÂňł░abortŠÂłŠü»ňÉÄŠëžŔíîń║őňŐíabortŠôŹńŻťŃÇé
ŃÇÇŃÇÇŠ│Ę´╝ÜTCŠłľSiŠŐŐňĆĹÚÇüŠłľŠÄąŠöÂňł░šÜäŠÂłŠü»ňůłňćÖňł░ŠŚąň┐ŚÚçî´╝îńŞ╗ŔŽüŠś»ńŞ║ń║押ůÚÜťňÉÄŠüóňĄŹšöĘŃÇéňŽéŠčÉńŞÇSiń╗ÄŠĽůÚÜťńŞşŠüóňĄŹňÉÄ´╝îňůłŠúNJ蹊ťČŠť║šÜ䊌ąň┐Ś´╝îňŽéŠ×ťňĚ▓ŠöÂňł░<commit >´╝îňłÖŠĆÉń║Ą´╝îňŽéŠ×ť<abort >ňłÖňŤ×Š╗ÜŃÇéňŽéŠ×ťŠś»<yes>´╝îňłÖňćŹňÉĹTCŔ»óÚŚ«ńŞÇńŞő´╝îší«ň«ÜńŞőńŞÇŠşąŃÇéňŽéŠ×ťń╗Çń╣łÚ⯊▓튝ë´╝îňłÖňżłňĆ»ŔâŻňťĘ<prepare>ڜŠ«ÁSiň░▒ň┤ęŠ║âń║ć´╝îňŤáŠşĄÚťÇŔŽüňŤ×Š╗ÜŃÇé
ŃÇÇŃÇÇšÄ░ňŽéń╗Őň«×šÄ░ňč║ń║ÄńŞĄÚśÂŠ«ÁŠĆÉń║ĄšÜäňłćňŞâň╝Ćń║őňŐíń╣čŠ▓íÚéúń╣łňŤ░ÚÜżń║ć´╝îňŽéŠ×ťńŻ┐šöĘjava´╝îÚéúń╣łňĆ»ń╗ąńŻ┐šöĘň╝ÇŠ║ÉŔŻ»ń╗Âatomikos(http://www.atomikos.com/)ŠŁąň┐źÚÇčň«×šÄ░ŃÇé
ŃÇÇŃÇÇńŞŹŔ┐çńŻćňçíńŻ┐šöĘŔ┐çšÜäńŞŐŔ┐░ńŞĄÚśÂŠ«ÁŠĆÉń║ĄšÜäňÉîňşŽÚâŻňĆ»ń╗ąňĆĹšÄ░ŠÇžŔâŻň«×ňťĘŠś»ňĄ¬ňĚ«´╝îŠá╣ŠťČńŞŹÚÇéňÉłÚźśň╣ÂňĆĹšÜäš│╗š╗čŃÇéńŞ║ń╗Çń╣ł´╝č
ŃÇÇŃÇÇ1´╝ëńŞĄÚśÂŠ«ÁŠĆÉń║ĄŠÂëňĆŐňĄÜŠČíŔŐéšé╣ÚŚ┤šÜ䚯Ś╗ťÚÇÜń┐í´╝îÚÇÜń┐튌ÂÚŚ┤ňĄ¬ÚĽ┐´╝ü
ŃÇÇŃÇÇ2´╝ëń║őňŐ튌ÂÚŚ┤šŤŞň»╣ń║ÄňĆśÚĽ┐ń║ć´╝îÚöüň«ÜšÜäŔÁäŠ║ÉšÜ䊌ÂÚŚ┤ń╣čňĆśÚĽ┐ń║ć´╝îÚÇኳÉŔÁäŠ║ÉšşëňżůŠŚÂÚŚ┤ń╣čňó×ňŐáňąŻňĄÜ´╝ü
ŃÇÇŃÇÇŠşúŠś»šö▒ń║ÄňłćňŞâň╝Ćń║őňŐíňşśňťĘňżłńŞąÚ珚ÜäŠÇžŔâŻÚŚ«Úóś´╝îňĄžÚâĘňłćÚźśň╣ÂňĆĹŠťŹňŐíÚâŻňťĘÚü┐ňůŹńŻ┐šöĘ´╝îňżÇňżÇÚÇÜŔ┐çňůÂń╗ľÚÇöňżäŠŁąŔžúňć│ŠĽ░ŠŹ«ńŞÇŔç┤ŠÇžÚŚ«ÚóśŃÇé
3 ńŻ┐šöĘŠÂłŠü»ÚśčňłŚŠŁąÚü┐ňůŹňłćňŞâň╝Ćń║őňŐí
ŃÇÇŃÇÇňŽéŠ×ťń╗öš╗ćŔžéň»čšöčŠ┤╗šÜäŔ»Ł´╝îšöčŠ┤╗šÜäňżłňĄÜňť║ŠÖ»ňĚ▓š╗Ćš╗Öń║抳Ĺń╗ČŠĆÉšĄ║ŃÇé
ŃÇÇŃÇÇŠ»öňŽéňťĘňîŚń║ČňżłŠťëňÉŹšÜäňžÜŔ«░šéĺŔ飚é╣ń║ćšéĺŔéŁň╣Âń╗śń║ćÚĺ▒ňÉÄ´╝îń╗ľń╗Čň╣ÂńŞŹń╝ÜšŤ┤ŠÄąŠŐŐńŻášé╣šÜäšéĺŔ飚╗ÖńŻá´╝îňżÇňżÇŠś»š╗ÖńŻáńŞÇň╝áň░ĆšąĘ´╝îšäÂňÉÄŔ«ęńŻáŠő┐šŁÇň░ĆšąĘňł░ňç║Ŕ┤žňî║ŠÄĺÚśčňÄ╗ňĆľŃÇéńŞ║ń╗Çń╣łń╗ľń╗ČŔŽüň░ćń╗śÚĺ▒ňĺîňĆľŔ┤žńŞĄńެňŐĘńŻťňłćň╝ÇňĹó´╝čňÄčňŤáňżłňĄÜ´╝îňůÂńŞşńŞÇńެňżłÚçŹŔŽüšÜäňÄčňŤáŠś»ńŞ║ń║ćńŻ┐ń╗ľń╗ČŠÄąňżůŔâŻňŐŤňó×ň╝║´╝łň╣ÂňĆĹÚçĆŠŤ┤Úźś´╝ëŃÇé
ŃÇÇŃÇÇŔ┐śŠś»ňŤ×ňł░ŠłĹń╗ČšÜäÚŚ«Úóś´╝îňƬŔŽüŔ┐Öň╝áň░ĆšąĘňťĘ´╝îńŻáŠťÇš╗łŠś»Ŕ⯊ő┐ňł░šéĺŔ飚ÜäŃÇéňÉîšÉćŔŻČŔ┤ŽŠťŹňŐíń╣芜»ňŽéŠşĄ´╝îňŻôŠö»ń╗śň«ŁŔ┤ŽŠłĚŠëúÚÖĄ1ńŞçňÉÄ´╝Ĺń╗ČňƬŔŽüšö芳ÉńŞÇńެňçşŔ»ü´╝łŠÂłŠü»´╝ëňŹ│ňĆ»´╝îŔ┐ÖńެňçşŔ»ü´╝łŠÂłŠü»´╝ëńŞŐňćÖšŁÇÔÇťŔ«ęńŻÖÚóŁň«ŁŔ┤ŽŠłĚňó×ňŐá 1ńŞçÔÇŁ´╝îňƬŔŽüŔ┐ÖńެňçşŔ»ü´╝łŠÂłŠü»´╝ëŔâŻňƻڣáń┐Łňşś´╝Ĺń╗ČŠťÇš╗łŠś»ňĆ»ń╗ąŠő┐šŁÇŔ┐ÖńެňçşŔ»ü´╝łŠÂłŠü»´╝ëŔ«ęńŻÖÚóŁň«ŁŔ┤ŽŠłĚňó×ňŐá1ńŞçšÜä´╝îňŹ│ŠłĹń╗ČŔâŻńżŁÚŁáŔ┐ÖńެňçşŔ»ü´╝łŠÂłŠü»´╝ëň«îŠłÉŠťÇš╗łńŞÇŔç┤ŠÇžŃÇé
3.1 ňŽéńŻĽňƻڣáń┐ŁňşśňçşŔ»ü´╝łŠÂłŠü»´╝ë
ŃÇÇŃÇÇŠťëńŞĄšžŹŠľ╣Š│Ľ´╝Ü
3.1.1 ńŞÜňŐíńŞÄŠÂłŠü»ŔÇŽňÉłšÜ䊾╣ň╝Ć
ŃÇÇŃÇÇŠö»ń╗śň«ŁňťĘň«îŠłÉŠëúŠČżšÜäňÉ´╝îňÉÂŔ«░ňŻĽŠÂłŠü»ŠĽ░ŠŹ«´╝îŔ┐ÖńެŠÂłŠü»ŠĽ░ŠŹ«ńŞÄńŞÜňŐ튼░ŠŹ«ń┐ŁňşśňťĘňÉîńŞÇŠĽ░ŠŹ«ň║ôň«×ńżőÚçî´╝łŠÂłŠü»Ŕ«░ňŻĽŔíĘŔíĘňÉŹńŞ║message´╝ë´╝Ť
|
1
2
3
4
5
|
Begin transaction
         update A set amount=amount-10000 where userId=1;
         insert into message(userId, amount,status) values(1, 10000, 1);
End transaction
commit;
|
ŃÇÇŃÇÇńŞŐŔ┐░ń║őňŐíŔâŻń┐ŁŔ»üňƬŔŽüŠö»ń╗śň«ŁŔ┤ŽŠłĚÚçîŔóźŠëúń║ćÚĺ▒´╝îŠÂłŠü»ńŞÇň«ÜŔâŻń┐ŁňşśńŞőŠŁąŃÇé
ŃÇÇŃÇÇňŻôńŞŐŔ┐░ń║őňŐíŠĆÉń║ĄŠłÉňŐčňÉÄ´╝Ĺń╗ČÚÇÜŔ┐çň«×ŠŚÂŠÂłŠü»ŠťŹňŐíň░抺ĄŠÂłŠü»ÚÇÜščąńŻÖÚóŁň«Ł´╝îńŻÖÚóŁň«ŁňĄäšÉ抳ÉňŐčňÉÄňĆĹÚÇüňŤ×ňĄŹŠłÉňŐčŠÂłŠü»´╝îŠö»ń╗śň«ŁŠöÂňł░ňŤ×ňĄŹňÉÄňłáÚÖĄŔ»ąŠŁíŠÂłŠü»ŠĽ░ŠŹ«ŃÇé
3.1.2 ńŞÜňŐíńŞÄŠÂłŠü»ŔžúŔÇŽŠľ╣ň╝Ć
ŃÇÇŃÇÇńŞŐŔ┐░ń┐ŁňşśŠÂłŠü»šÜ䊾╣ň╝ĆńŻ┐ňżŚŠÂłŠü»ŠĽ░ŠŹ«ňĺîńŞÜňŐ튼░ŠŹ«š┤žŔÇŽňÉłňťĘńŞÇŔÁĚ´╝îń╗Ċ׊×äńŞŐšťőńŞŹňĄčń╝śÚŤů´╝îŔÇîńŞöň«╣ŠśôŔ»▒ňĆĹňůÂń╗ľÚŚ«ÚóśŃÇéńŞ║ń║ćŔžúŔÇŽ´╝îňĆ»ń╗ąÚççšöĘń╗ąńŞőŠľ╣ň╝ĆŃÇé
ŃÇÇŃÇÇ1´╝ëŠö»ń╗śň«ŁňťĘŠëúŠČżń║őňŐíŠĆÉń║Ąń╣őň돴╝îňÉĹň«×ŠŚÂŠÂłŠü»ŠťŹňŐíŔ»ĚŠ▒éňĆĹÚÇüŠÂłŠü»´╝îň«×ŠŚÂŠÂłŠü»ŠťŹňŐíňƬŔ«░ňŻĽŠÂłŠü»ŠĽ░ŠŹ«´╝îŔÇîńŞŹšťčŠşúňĆĹÚÇü´╝îňƬŠťëŠÂłŠü»ňĆĹÚÇüŠłÉňŐčňÉÄŠëŹń╝ÜŠĆÉń║Ąń║őňŐí´╝Ť
ŃÇÇŃÇÇ2´╝ëňŻôŠö»ń╗śň«ŁŠëúŠČżń║őňŐíŔóźŠĆÉń║ĄŠłÉňŐčňÉÄ´╝îňÉĹň«×ŠŚÂŠÂłŠü»ŠťŹňŐíší«Ŕ«ĄňĆĹÚÇüŃÇéňƬŠťëňťĘňżŚňł░ší«Ŕ«ĄňĆĹÚÇüŠîçń╗ĄňÉÄ´╝îň«×ŠŚÂŠÂłŠü»ŠťŹňŐíŠëŹšťčŠşúňĆĹÚÇüŔ»ąŠÂłŠü»´╝Ť
ŃÇÇŃÇÇ3´╝ëňŻôŠö»ń╗śň«ŁŠëúŠČżń║őňŐíŠĆÉń║ĄňĄ▒Ŕ┤ąňŤ×Š╗ÜňÉÄ´╝îňÉĹň«×ŠŚÂŠÂłŠü»ŠťŹňŐíňĆľŠÂłňĆĹÚÇüŃÇéňťĘňżŚňł░ňĆľŠÂłňĆĹÚÇüŠîçń╗ĄňÉÄ´╝îŔ»ąŠÂłŠü»ň░ćńŞŹń╝ÜŔóźňĆĹÚÇü´╝Ť
ŃÇÇŃÇÇ4´╝ëň»╣ń║ÄÚéúń║ŤŠť¬ší«Ŕ«ĄšÜäŠÂłŠü»ŠłľŔÇůňĆľŠÂłšÜäŠÂłŠü»´╝îÚťÇŔŽüŠťëńŞÇńެŠÂłŠü»šŐŠÇüší«Ŕ«Ąš│╗š╗čň«ÜŠŚÂňÄ╗Šö»ń╗śň«Łš│╗š╗čŠčąŔ»óŔ┐ÖńެŠÂłŠü»šÜäšŐŠÇüň╣ÂŔ┐ŤŔí┤Šľ░ŃÇéńŞ║ń╗Çń╣łÚťÇŔŽüŔ┐ÖńŞÇŠşąÚ¬Ą´╝îńŞżńެńżőňşÉ´╝ÜňüçŔ«żňťĘšČČ2ŠşąŠö»ń╗śň«ŁŠëúŠČżń║őňŐíŔ󟊳ÉňŐčŠĆÉń║ĄňÉÄ´╝îš│╗š╗čŠîéń║ć´╝ĄŠŚÂŠÂłŠü»šŐŠÇüň╣Šť¬Ŕ󟊍┤Šľ░ńŞ║ÔÇťší«Ŕ«ĄňĆĹÚÇüÔÇŁ´╝îń╗ÄŔÇîň»╝Ŕç┤ŠÂłŠü»ńŞŹŔâŻŔóźňĆĹÚÇüŃÇé
ŃÇÇŃÇÇń╝śšé╣´╝ÜŠÂłŠü»ŠĽ░ŠŹ«šőČšźőňşśňéĘ´╝îÚÖŹńŻÄńŞÜňŐíš│╗š╗čńŞÄŠÂłŠü»š│╗š╗čÚŚ┤šÜäŔÇŽňÉł´╝Ť
ŃÇÇŃÇÇš╝║šé╣´╝ÜńŞÇŠČíŠÂłŠü»ňĆĹÚÇüÚťÇŔŽüńŞĄŠČíŔ»ĚŠ▒é´╝ŤńŞÜňŐíňĄäšÉ抝ŹňŐíÚťÇŔŽüň«×šÄ░ŠÂłŠü»šŐŠÇüňŤ×ŠčąŠÄąňĆúŃÇé
3.2 ňŽéńŻĽŔžúňć│ŠÂłŠü»ÚçŹňĄŹŠŐĽÚÇĺšÜäÚŚ«Úóś
ŃÇÇŃÇÇŔ┐śŠťëńŞÇńެňżłńŞąÚ珚ÜäÚŚ«Úóśň░▒Šś»ŠÂłŠü»ÚçŹňĄŹŠŐĽÚÇĺ´╝îń╗ąŠłĹń╗ČŠö»ń╗śň«ŁŔŻČŔ┤Žňł░ńŻÖÚóŁň«ŁńŞ║ńżő´╝îňŽéŠ×ťšŤŞňÉîšÜäŠÂłŠü»ŔóźÚçŹňĄŹŠŐĽÚÇĺńŞĄŠČí´╝îÚéúń╣łŠłĹń╗ČńŻÖÚóŁň«ŁŔ┤ŽŠłĚň░ćń╝Üňó×ňŐá2ńŞçŔÇîńŞŹŠś»1ńŞçń║ćŃÇé
ŃÇÇŃÇÇńŞ║ń╗Çń╣łšŤŞňÉîšÜäŠÂłŠü»ń╝ÜŔóźÚçŹňĄŹŠŐĽÚÇĺ´╝芻öňŽéńŻÖÚóŁň«ŁňĄäšÉćň«îŠÂłŠü»msgňÉÄ´╝îňĆĹÚÇüń║ćňĄäšÉ抳ÉňŐčšÜäŠÂłŠü»š╗ÖŠö»ń╗śň«Ł´╝úňŞŞŠâůňćÁńŞőŠö»ń╗śň«Łň║öŔ»ąŔŽüňłáÚÖĄŠÂłŠü»msg´╝îńŻćňŽéŠ×ťŠö»ń╗śň«ŁŔ┐ÖŠŚÂňÇÖŠé▓ňëžšÜäŠîéń║ć´╝îÚçŹňÉ»ňÉÄńŞÇšťőŠÂłŠü»msgŔ┐śňťĘ´╝îň░▒ń╝Üš╗žš╗şňĆĹÚÇüŠÂłŠü»msgŃÇé
ŃÇÇŃÇÇŔžúňć│Šľ╣Š│Ľňżłš«ÇňŹĽ´╝îňťĘńŻÖÚóŁň«ŁŔ┐ÖŔż╣ňó×ňŐáŠÂłŠü»ň║öšöĘšŐŠÇüŔíĘ´╝łmessage_apply´╝ë´╝îÚÇÜń┐ŚŠŁąŔ»┤ň░▒Šś»ńެŔ┤ŽŠťČ´╝îšöĘń║ÄŔ«░ňŻĽŠÂłŠü»šÜäŠÂłŔ┤╣ŠâůňćÁ´╝ƊČ튣ąńŞÇńެŠÂłŠü»´╝îňťĘšťčŠşúŠëžŔíîń╣őň돴╝îňůłňÄ╗ŠÂłŠü»ň║öšöĘšŐŠÇüŔíĘńŞşŠčąŔ»óńŞÇÚüŹ´╝îňŽéŠ×ťŠëżňł░Ŕ»┤ŠśÄŠś»ÚçŹňĄŹŠÂłŠü»´╝îńŞóň╝âňŹ│ňĆ»´╝îňŽéŠ×ťŠ▓íŠëżňł░ŠëŹŠëžŔíî´╝îňÉŠĆĺňůąňł░ŠÂłŠü»ň║öšöĘšŐŠÇüŔíĘ´╝łňÉîńŞÇń║őňŐí´╝ëŃÇé
|
1
2
3
4
5
6
7
8
|
for each msg in queue
  Begin transaction
    select count(*) as cnt from message_apply where msg_id=msg.msg_id;
    if cnt==0 then
      update B set amount=amount+10000 where userId=1;
      insert into message_apply(msg_id) values(msg.msg_id);
  End transaction
  commit;
|
ŃÇÇŃÇÇEbayšÜäšáöňĆĹń║║ňĹśŠŚęňťĘ2008ň╣┤ň░▒ŠĆÉňç║ń║ćň║öšöĘŠÂłŠü»šŐŠÇüší«Ŕ«ĄŔíĘŠŁąŔžúňć│ŠÂłŠü»ÚçŹňĄŹŠŐĽÚÇĺšÜäÚŚ«Úóś´╝Ühttp://queue.acm.org/detail.cfm?id=1394128ŃÇé
ňĆéŔÇ⊾çšî«
Dan Pritchett´╝îBase: An Acid Alternative´╝îhttp://queue.acm.org/detail.cfm?id=1394128
šĘőšźő´╝îňĄžŔžäŠĘíSOAš│╗š╗čńŞşšÜäňłćňŞâň╝Ćń║őňŐíňĄäšÉć
mysqlńŞĄÚśÂŠ«ÁŠĆÉń║Ą´╝îhttp://blog.csdn.net/jesseyoung/article/details/37970271
 
ňÄčňłŤŠľçšźá´╝îÚŁ×ńŻťŔÇůňÉîŠäĆ´╝üŠşóŔŻČŔŻŻ´╝ü



šŤŞňů│ŠÄĘŔŹÉ
ňłćňŞâň╝Ćń║őňŐ튜»ŠîçňťĘňłćňŞâň╝Ćš│╗š╗čńŞş´╝îńŞ║ń║ćší«ń┐ŁŔĚĘňĄÜńެŔŐéšé╣ńŞŐšÜäŠôŹńŻťŔâŻňĄčŠşúší«ňť░ň«îŠłÉŠłľŔÇůňůĘÚâĘňŤ×Š╗Ü´╝îŠëÇÚççňĆľšÜäńŞÇšžŹń║őňŐíňĄäšÉ抝║ňłÂŃÇéňťĘŔ┐ÖŠáĚšÜäňť║ŠÖ»ńŞő´╝îń║őňŐíšÜäňĆéńŞÄŔÇůŃÇüŠö»Šîüń║őňŐíšÜ䊝ŹňŐíňÖĘŃÇüŔÁäŠ║ÉŠťŹňŐíňÖĘń╗ąňĆŐń║őňŐíš«íšÉćňÖĘňłćňłźńŻŹń║ÄńŞŹňÉîšÜä...
4. ň╝銺ąší«ń┐Ł´╝łAsynchronous Ensure´╝ë´╝ÜŠś»ńŞÇšžŹňč║ń║ÄŠÂłŠü»ÚśčňłŚšÜäňłćňŞâň╝Ćń║őňŐíň«×šÄ░ŠŐÇŠť»ŃÇéň«âňĆ»ń╗ąší«ń┐Łń║őňŐíšÜäŠëžŔíîÚí║ň║ĆňĺîňƻڣáŠÇž´╝îÚü┐ňůŹń║ćňłćňŞâň╝Ćń║őňŐíńŞşšÜäšź×ń║ëConditionŃÇé 5. ŠťÇňĄžňŐ¬ňŐŤÚÇÜščą´╝łBest-Effort Notification´╝ë´╝ÜŠś»ńŞÇšžŹ...
ŠťČŠľçň░ćŠĚ▒ňůąŠÄóŔ«ĘÔÇťňłćňŞâň╝Ćń║őňŐí-ňƻڣáŠÂłŠü»šÜ䊝ŹňŐíšÜäŔ«żŔ«íńŞÄň«×šÄ░ÔÇŁŔ┐ÖńŞÇńŞ╗Úóś´╝îńŞ╗ŔŽüňŤ┤š╗ĽŠÂłŠü»ŠťŹňŐíňşÉš│╗š╗č´╝îš╗ôňÉłŠĆÉńżŤšÜäŔÁ䊾ִ╝îňîůŠőČÔÇťňż«ŠťŹňŐíŠ×Š×äšÜäňłćňŞâň╝Ćń║őňŐíŔžúňć│Šľ╣Šíł.pdfÔÇŁŃÇüÔÇťrc_pay_dubbo_message.sqlÔÇŁŠĽ░ŠŹ«ň║ôŔäÜŠťČŃÇüÔǝڿ֊םňşŽÚÖó-...
ňłćňŞâň╝Ćń║őňŐ튜»ńŞ║ń║ćŔžúňć│ňłćňŞâň╝Ćš│╗š╗čńŞşŔĚĘŔÂŐňĄÜńެŔŐéšé╣šÜäŠôŹńŻť´╝îŔŽüŠ▒éŔ┐Öń║ŤŠôŹńŻťŔŽüń╣łňůĘÚâĘŠłÉňŐčŔŽüń╣łňůĘÚâĘňĄ▒Ŕ┤ąšÜäńŞÇšžŹń║őňŐ튝║ňłÂŃÇéň«âŠś»ńŞ║ń║ćń┐ŁŔ»üňťĘńŞŹňÉîŔŐéšé╣ńŞŐšÜ䊼░ŠŹ«ńŞÇŔç┤ŠÇžŔÇîń║žšöčšÜ䊎éň┐ÁŃÇéňłćňŞâň╝Ćń║őňŐíň╣┐Š│Ťň║öšöĘń║Äňż«ŠťŹňŐíŠ×Š×äŃÇüŠĽ░ŠŹ«ň║ôňłćň║ôňłćŔíĘ...
ňłćňŞâň╝Ćń║őňŐ튜»ŠîçňťĘňłćňŞâň╝Ćš│╗š╗čńŞş´╝îńŞ║ń║ćń┐ŁŠîüń║őňŐíšÜäACID´╝łňÄčňşÉŠÇžŃÇüńŞÇŔç┤ŠÇžŃÇüÚÜöšŽ╗ŠÇžŃÇüŠîüń╣ůŠÇž´╝ëšë╣ŠÇž´╝îÚťÇŔŽüŔĚĘŔÂŐňĄÜńެŔÁäŠ║Éš«íšÉćňÖĘ´╝łňŽéŠĽ░ŠŹ«ň║ôŃÇüŠÂłŠü»ÚśčňłŚšşë´╝ëŔ┐ŤŔíîňŹĆŔ░âšÜäńŞÇš│╗ňłŚŠôŹńŻťŃÇéňťĘňłćňŞâň╝Ćš│╗š╗čńŞş´╝îń║őňŐíšÜäŠôŹńŻťňłćňŞâňťĘńŞŹňÉîšÜäŔŐéšé╣ńŞŐ...
ňłćňŞâň╝Ćń║őňŐ튜»ňĄžň×őňłćňŞâň╝Ćš│╗š╗čńŞşň┐ůńŞŹňĆ»ň░ĹšÜäńŞÇńެŠŐÇŠť»šÄ»ŔŐé´╝îň«âŠŚĘňťĘší«ń┐ŁňťĘňĄÜŔŐéšé╣...ÚÇÜŔ┐çňşŽń╣áŔ┐Öń║ŤŔÁ䊾ִ╝îň╝ÇňĆĹŔÇůňĆ»ń╗ąňťĘň«×ÚÖůÚí╣šŤ«ńŞşŠá╣ŠŹ«ńŞÜňŐíڝNJ▒éÚÇëŠőꊝÇÚÇéňÉłšÜäňłćňŞâň╝Ćń║őňŐíšşľšĽą´╝îÚü┐ňůŹŠłľňçĆň░ĹňĆ»ŔâŻňç║šÄ░šÜäňŁĹ´╝îŠĆÉÚźśš│╗š╗čšÜäšĘ│ň«ÜŠÇžňĺîňƻڣáŠÇžŃÇé
ŠÂłŠü»Úę▒ňŐĘšÜäń║őňŐ튝║ňłÂÚÇÜňŞŞńŞÄŔíąňü┐ń║őňŐí(ń╣čšž░ńŞ║ saga ŠĘíň╝Ć)šŤŞš╗ôňÉł´╝îšöĘń╗ąňĄäšÉćňłćňŞâň╝Ćń║őňŐíŃÇéňťĘ saga ŠĘíň╝ĆńŞş´╝îńŞÇš│╗ňłŚŠťČňť░ń║őňŐíÚÇÜŔ┐çŔíąňü┐ŠôŹńŻťŠŁąŔżżňł░ňůĘň▒ÇšÜäń║őňŐíńŞÇŔç┤ŠÇžŃÇé ÚÖĄń║ćń╝áš╗čšÜäňłćňŞâň╝Ćń║őňŐíŔžúňć│Šľ╣ŠíłňĄľ´╝îŔ┐śŠťëńŞÇń║Ťňč║ń║Äšë╣ň«ÜŠĽ░ŠŹ«ň║ô...
ňťĘWebÚí╣šŤ«ńŞşńŻ┐šöĘAtomikosň«×šÄ░ňłćňŞâň╝Ćń║őňŐí´╝îÚÇÜňŞŞňîůŠőČń╗ąńŞőŠşąÚ¬Ą´╝Ü 1. **ڍ抳ÉAtomikos**´╝ÜÚŽľňůł´╝îńŻáÚťÇŔŽüň░ćAtomikosšÜäńżŁŔÁľň║ôŠĚ╗ňŐáňł░ńŻášÜäÚí╣šŤ«ńŞş´╝îŔ┐ÖňĆ»ń╗ąÚÇÜŔ┐çMavenŠłľGradlešÜäńżŁŔÁľš«íšÉ抣ąň«îŠłÉŃÇéší«ń┐Łň╝ĽňůąšÜäšëłŠťČńŞÄńŻášÜäÚí╣šŤ«ŠëÇńŻ┐šöĘ...
ŠťČš»çŠľçšźáň░ćŔ»Žš╗ćŠÄóŔ«ĘňŽéńŻĽńŻ┐šöĘRedissonň«×šÄ░RedisňłćňŞâň╝Ćń║őňŐíÚöü´╝îń╗ąňĆŐňťĘSpring BootšÄ»ňóâńŞşňŽéńŻĽŔ┐ŤŔíîڍ抳ÉŃÇé ÚŽľňůł´╝îRedisńŻťńŞ║ńŞÇńެňćůňşśŠĽ░ŠŹ«ň║ô´╝îňůÂÚźśÚÇčŔ»╗ňćÖŠÇžŔâŻńŻ┐ňůŠłÉńŞ║ň«×šÄ░ňłćňŞâň╝ĆÚöüšÜäšÉćŠâ│ÚÇëŠőęŃÇéňłćňŞâň╝ĆÚöüšÜäńŞ╗ŔŽüńŻťšöĘŠś»ňťĘňĄÜ...
ŃÇÉňłćňŞâň╝Ćń║őňŐ튎éŔ┐░ŃÇĹ ňłćňŞâň╝Ćń║őňŐ튜»ŠîçňťĘňłćňŞâň╝ƚĻňóâńŞő´╝îŔĚĘŔÂŐňĄÜńެŠĽ░ŠŹ«Š║ÉšÜäŠôŹńŻť...šäÂŔÇî´╝îÚťÇŔŽüŠ│ĘŠäĆšÜ䊜»´╝îňłćňŞâň╝Ćń║őňŐíšÜäš«íšÉćňĺîň«×ŠľŻń╝Üňó×ňŐáš│╗š╗čšÜäňĄŹŠŁéŠÇž´╝îň╣ÂňĆ»ŔâŻň»╝Ŕç┤ŠÇžŔâŻńŞőÚÖŹ´╝îňŤáŠşĄňťĘŔ«żŔ«íš│╗š╗芌Âň║öŠŁâŔííń║őňŐíš«íšÉćňĺîŠÇžŔâŻń╣őÚŚ┤šÜäň╣│ŔííŃÇé
ńŻ┐šöĘSpring+JOTMšÜäňłćňŞâň╝Ćń║őňŐí´╝îňĆ»ń╗ąší«ń┐ŁŔ┐ÖńŞĄńެŠôŹńŻťŔŽüń╣łňůĘÚâĘŠłÉňŐč´╝îŔŽüń╣łňůĘÚâĘňŤ×Š╗Ü´╝îÚü┐ňůŹňç║šÄ░ÚâĘňłćň«îŠłÉšÜäń║őňŐíšŐŠÇüŃÇé ŠÇ╗š╗ôŠŁąŔ»┤´╝îSpring+JOTMšÜäš╗äňÉłńŞ║ň╝ÇňĆĹŔÇůŠĆÉńżŤń║ćńŞÇńެň╝║ňĄžšÜäňĚąňůĚ´╝îšöĘń║ÄňĄäšÉćňĄŹŠŁéšÜäňłćňŞâň╝Ćń║őňŐíňť║ŠÖ»ŃÇéÚÇÜŔ┐çňú░ŠśÄ...
Ŕ┐ÖńŞĄńެŠôŹńŻťÚÇÜňŞŞń╝ÜňťĘńŞŹňÉîšÜ䊝ŹňŐ튳ľŠĽ░ŠŹ«ň║ôńŞşŔ┐ŤŔíî´╝îňŤáŠşĄň┐ůÚí╗ÚÇÜŔ┐çňłćňŞâň╝Ćń║őňŐ튝║ňłÂší«ń┐Łň«âń╗ČŔŽüń╣łňÉŠłÉňŐč´╝îŔŽüń╣łňÉÂňĄ▒Ŕ┤ą´╝îń╗ąÚü┐ňůŹŠĽ░ŠŹ«ńŞŹńŞÇŔç┤šÜäÚŚ«ÚóśŃÇé ňťĘňłćňŞâň╝Ćń║őňŐíńŞş´╝îń╝Üňç║šÄ░ňĄÜšžŹň╝éňŞŞŠâůňćÁ´╝îňîůŠőČńŻćńŞŹÚÖÉń║Ä´╝Ü 1. ŠĽ░ŠŹ«ň║ôň╝éňŞŞ´╝Ü...
ňłćňŞâň╝Ćń║őňŐíňťĘšöÁňĽćš│╗š╗čńŞşšÜäÚçŹŔŽüŠÇžńŞŹŔĘÇŔÇîňľ╗´╝îšë╣ňłźŠś»ňťĘňż«ŠťŹňŐíŠ×Š×䚍ŤŔíîšÜäń╗ŐňĄęŃÇéňŻôńŞÇńެŠôŹńŻťŠÂëňĆŐňĄÜńެŠťŹňŐ튳ľŠĽ░ŠŹ«ň║ôŠŚÂ´╝îń╝áš╗čšÜäňŹĽň║ôń║őňŐ튝║ňłÂńŞŹŔÂ│ń╗ąń┐ŁŔ»üŠĽ░ŠŹ«šÜäńŞÇŔç┤ŠÇžŃÇéń╗ąŠľçńŞşŠĆÉňł░šÜäšöÁňĽćš│╗š╗čńŞ║ńżő´╝îšÄęň«ÂŔ┤şń╣░ÚüôňůĚňÉÄ´╝îÚüôňůĚšÜ䊍┤Šľ░ńŞÄ...
ňłćňŞâň╝Ćń║őňŐí-ň╣éšşë ňťĘňłćňŞâň╝Ćš│╗š╗čńŞş´╝îň╣éšşëŠÇž´╝łIdempotence´╝늜»ńŞÇńެÚçŹŔŽüšÜ䊎éň┐Á´╝îň«âší«ń┐Łń║ćňÉîńŞÇńެŠôŹńŻťŠŚáŔ«║ŠëžŔíîňĄÜň░ĹŠČí´╝îš╗ôŠ×ťňžőš╗łšŤŞňÉîŃÇéŔ┐ÖńŞÇšë╣ŠÇžň»╣ń║Äń┐ŁŔ»üŠĽ░ŠŹ«ńŞÇŔç┤ŠÇžŃÇüÚś▓ŠşóÚçŹňĄŹňĄäšÉćń╗ąňĆŐŔžúňć│šŻĹš╗ťň╗ÂŔ┐čšşëÚŚ«ÚóśŔç│ňů│ÚçŹŔŽüŃÇéň░ĄňůŠś»ňťĘ...
ňťĘňĄžŔžäŠĘíšÜäSOA´╝łService-Oriented Architecture´╝îÚŁóňÉĹŠťŹňŐíŠ×Š×ä´╝ëš│╗š╗čńŞş´╝îňłćňŞâň╝Ćń║őňŐíňĄäšÉ抜»ńŞÇÚí╣Ŕç│ňů│ÚçŹŔŽüšÜäŠŐÇŠť»ŃÇ銝Ȋľçň░ćŠĚ▒ňůąŠÄóŔ«ĘŔ┐ÖńŞÇńŞ╗Úóś´╝îňč║ń║ÄšĘőšźőšÜäŔÁ䊾ִ╝îńŞ╗ŔŽüňů│Š│ĘňłćňŞâň╝Ćń║őňŐíňĄäšÉćŠĘíň×őŃÇüXAŔžäŔîâń╗ąňĆŐńŞĄÚśÂŠ«ÁŠĆÉń║ĄňĺîńŞëڜŠ«Á...