
原创整理不易,转载请注明出处:java开源框架SpringSide 3.1.4.3开发Web的demo项目实战
代码下载地址:http://www.zuidaima.com/share/1781596496120832.htm
SpringSide 3.1.4.3是目前SpringSide的最新版本,也是完成度比较高的一个版本,用来做实际项目的开发应该丝毫不成问题。这里写一下使用该版本开发一个简单Web项目的全过程,当然,最重要的是我自己的一些心得体会。我的文章很长,只有耐下性子细看,才能体会个中三味。
第一步、下载SpringSide 3.1.4.3 all-in-one版。这个过程太简单了,SpringSide的官方网站是www.springside.org.cn,去那里就可以下载了,all-in-one版当然是懒人们的不二选择。这里有一点很搞笑,该版本标的是SpringSide 3.1.4.3,但是下载后解压缩,解压缩出来的文件是springside-3.1.4.2,这可能是江南白衣的一点小小的失误,据我猜测,3.1.4.3较3.1.4.1的进步应该是加入了jsp-api.jar这一个库,希望白衣这次不要为了更改这个版本号上的失误而再推出一个新版本,如果真要推出新版本,怎么样也应该把我最近研究出来的多数据库的配置加进去。
第二步、安装SpringSide。如果安装过SpringSide以前的版本,最好把用户目录下的.m2文件夹删掉,这个文件夹是Maven的本地仓库所在地,虽说Maven可以有效保证库文件不会发生版本冲突,但是删除这个文件夹会使安装过程加快,否则,SpringSide的安装过程会不停询问你是否覆盖某某文件。删除.m2文件夹后,运行springside-3.1.4.2目录下的bin目录中的quickstart.bat即可(前提条件是已经安装好了JDK5或以上版本,如果你的电脑中连JDK都没有,就别来趟SpringSide的浑水了)。 等待这个文件运行完,就可以看到SpringSide 3提供的三个示例项目mini-web、mini-service、showcase都运行起来了,这时你可以细细体会一下SpringSide实现的各种特性。
仔细察看SpringSide的bin目录,发现该版本提供的脚本更加明确和有用,如start-db.bat可以用来启动Derby数据库,start-selenium.bat用来启动selenium server,而start-tomcat.bat那就别说了,地球人都知道。
如果要想使用SpringSide来生成项目,还有一点点小工作要做,就是把Maven的bin目录加入到PATH环境变量中,如下图:
第三步,使用SpringSide生成项目。运行bin目录下的new-project.bat即可,如下图: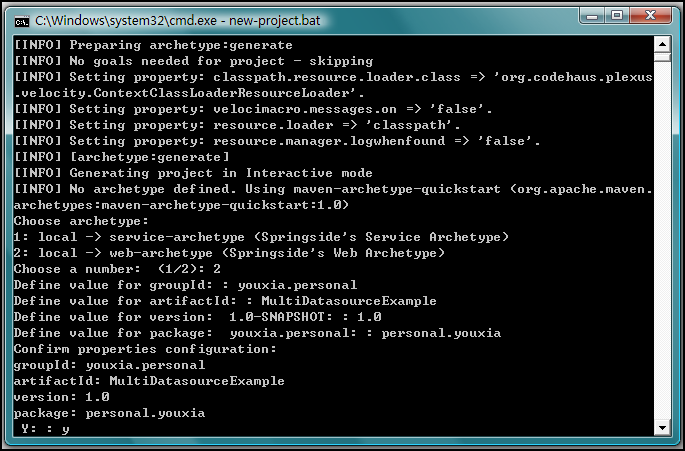
在创建项目的过程中,该脚本会提出一些问题,其中groupId指的是你的组织的名称,由于该项目由我私人贡献,纯属示范用,所以我填了youxia.personal,因此,在第5个问题上,我选择了personal.you作为我项目中的package的名字,这也是符合国际惯例的;artifactId指的是项目的名字,这里为MultiDatasourceExample,名字有点长,从名字就可以看出来我要示范多个数据源的配置。
第四步、启动Eclipse,导入项目。 生成的项目位于SpringSide目录下的tools\generator\generated-project目录下,下面是Eclipse的截图: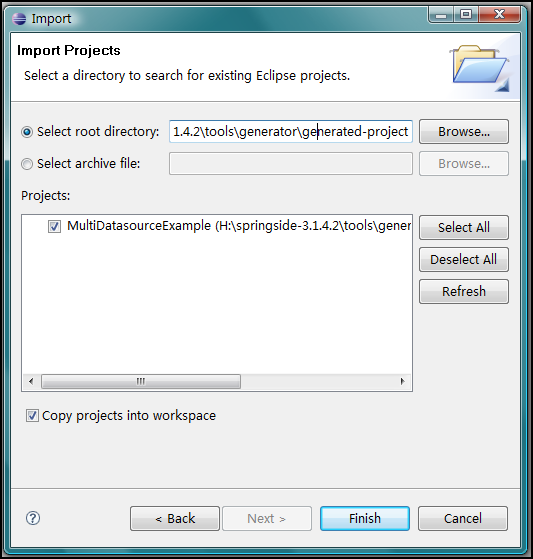
项目导入成功后,Eclispe资源管理器的截图: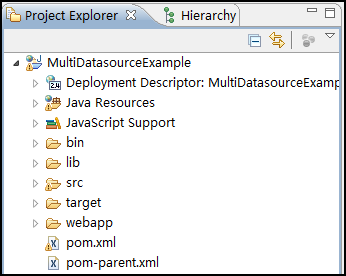
可以看到,该项目一经导入,立即可用,一个烦人的红叉都没有,这也正说明了该版本是SpringSide 3的一个革命性版本,从该版本开始,SpringSide 3的易用性提高了不止一个档次。
Eclipse推荐使用3.4及以上版本,因为在该版本中,对Tomcat服务器的管理更加方便,只需要在项目的快捷菜单中选择Run On Server,即可自动打开Tomcat服务器并部署项目,如下图:
这里有一点一定要注意,由于SpringSide生成的项目默认使用的是Derby数据库,所以要想成功运行项目,必须先启动Derby数据库,还记得前面提到的start-db.bat吗?运行它!然后运行该项目的bin目录下的init-db.jar,在数据库中放入该项目的初始化数据。
然后就可以点Run On Server来启动项目了,让大家见识一下Eclipse的嵌入式浏览器、Tomcat服务器视图、Console视图。真的是太方便了: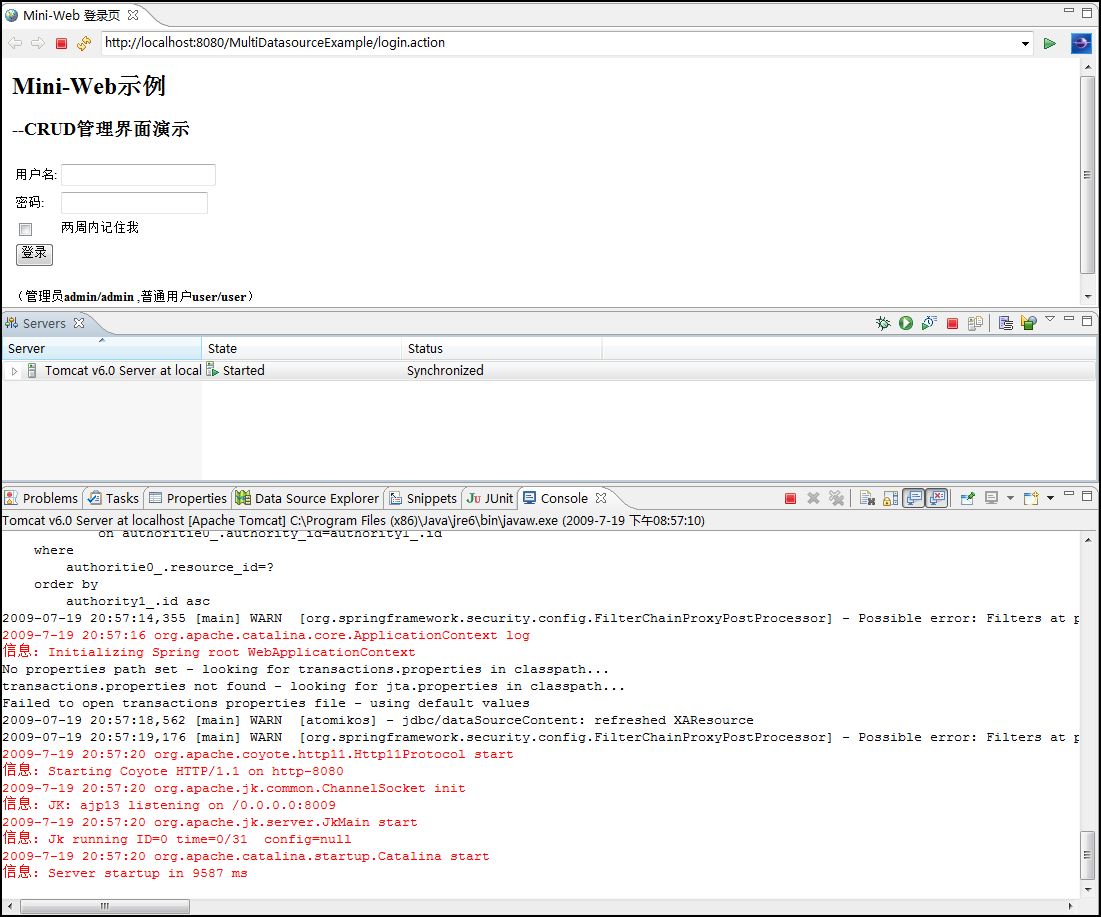
第五步、将数据库迁移到MySQL中。在项目中,创建数据库和初始化数据库的语句都是以SQL文件存在的,如下图: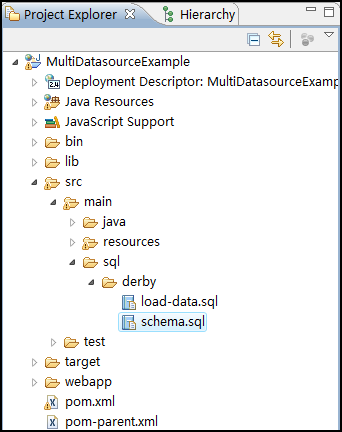
但是该语句都是针对Derby的,如果要应用于MySQL,还必须得要做一些修改才行,先修改schema.sql,如下:
drop table if exists RESOURCES_AUTHORITIES; drop table if exists ROLES_AUTHORITIES; drop table if exists USERS_ROLES; drop table if exists RESOURCES; drop table if exists AUTHORITIES; drop table if exists USERS; drop table if exists ROLES; create table USERS ( ID integer primary key auto_increment, LOGIN_NAME varchar ( 20 ) not null unique , PASSWORD varchar ( 20 ), NAME varchar ( 20 ), EMAIL varchar ( 30 ) ); create unique index USERS_LOGIN_NAME_INDEX on USERS(LOGIN_NAME); create table ROLES ( ID integer primary key auto_increment, NAME varchar ( 20 ) not null unique ); create table USERS_ROLES ( USER_ID integer not null , ROLE_ID integer not null , FOREIGN KEY (ROLE_ID) references ROLES(ID), FOREIGN KEY ( USER_ID ) references USERS(ID) ); CREATE TABLE AUTHORITIES ( ID integer primary key auto_increment, NAME varchar ( 20 ) not null , DISPLAY_NAME varchar ( 20 ) not null ); create table ROLES_AUTHORITIES ( ROLE_ID integer not null , AUTHORITY_ID integer not null , FOREIGN KEY (ROLE_ID) references ROLES(ID), FOREIGN KEY (AUTHORITY_ID) references AUTHORITIES(ID) ); CREATE TABLE RESOURCES ( ID integer primary key auto_increment, RESOURCE_TYPE varchar ( 20 ) not null , VALUE varchar ( 255 ) not null , ORDER_NUM float not null ); create table RESOURCES_AUTHORITIES ( AUTHORITY_ID integer not null , RESOURCE_ID integer not null , FOREIGN KEY (AUTHORITY_ID) references AUTHORITIES(ID), FOREIGN KEY (RESOURCE_ID) references RESOURCES(ID) );
该修改主要包含两个地方,一个是在drop table后面加上了if exists,一个是把GENERATED ALWAYS as IDENTITY修改为auto_increment。而load-data.sql不需要修改。
然后,启动MySQL,在MySQL中使用上面的两个sql文件创建数据库和添加初始化数据,如下图: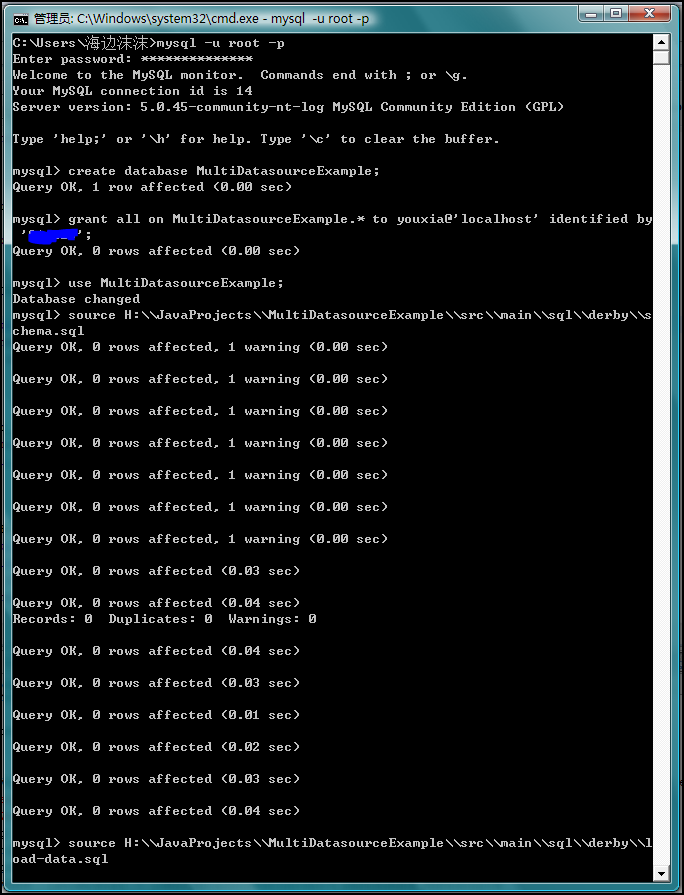
然后更改数据库连接,修改项目的application.properties文件,如下:
#jdbcsettings jdbc.url=jdbc:mysql://localhost: 3306 /MultiDatasourceExample?useUnicode=true&characterEncoding=utf8 jdbc.username=youxia jdbc.password=****** #hibernate settings hibernate.show_sql=false hibernate.format_sql=false hibernate.ehcache_config_file= /ehcache/ehcache-hibernate-local.xml
修改项目的applicationContext.xml文件,这里要修改两个地方,一个为DriverClassName,一个为hibernate.dilect,如下:
<?xml version="1.0"encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jee="http://www.springframework.org/schema/jee" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans-2.5.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd http://www.springframework.org/schema/jee http://www.springframework.org/schema/jee/spring-jee-2.5.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd"
default-lazy-init="true">
<description> Spring公共配置文件 </description>
<!-- 定义受环境影响易变的变量 -->
<bean class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="systemPropertiesModeName" value="SYSTEM_PROPERTIES_MODE_OVERRIDE" />
<property name="ignoreResourceNotFound" value="true" />
<property name="locations">
<list>
<!-- 标准配置 -->
<value> classpath*:/application.properties </value>
<!-- 本地开发环境配置 -->
<value> classpath*:/application.local.properties </value>
<!-- 服务器生产环境配置 -->
<!-- <value>file:/var/myapp/application.server.properties</value> -->
</list>
</property>
</bean>
<!-- 使用annotation 自动注册bean,并保证@Required,@Autowired的属性被注入 -->
<context:component-scan base-package="personal.youxia" />
<!-- 数据源配置,使用应用内的DBCP数据库连接池 -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<!-- Connection Info -->
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<!-- Connection Pooling Info -->
<property name="initialSize" value="5" />
<property name="maxActive" value="100" />
<property name="maxIdle" value="30" />
<property name="maxWait" value="1000" />
<property name="poolPreparedStatements" value="true" />
<property name="defaultAutoCommit" value="false" />
</bean>
<!-- 数据源配置,使用应用服务器的数据库连接池 -->
<!-- <jee:jndi-lookup id="dataSource"jndi-name="java:comp/env/jdbc/ExampleDB"/> -->
<!-- Hibernate配置 -->
<bean id="sessionFactory" class="org.springframework.orm.hibernate3.annotation.AnnotationSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="namingStrategy">
<bean class="org.hibernate.cfg.ImprovedNamingStrategy" />
</property>
<property name="hibernateProperties">
<props>
<prop key="hibernate.dialect">org.hibernate.dialect.MySQL5InnoDBDialect </prop>
<prop key="hibernate.show_sql">${hibernate.show_sql} </prop>
<prop key="hibernate.format_sql">${hibernate.format_sql} </prop>
<prop key="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider
</prop>
<prop key="hibernate.cache.provider_configuration_file_resource_path">${hibernate.ehcache_config_file} </prop>
</props>
</property>
<property name="packagesToScan" value="personal.youxia.entity.*" />
</bean>
<!-- 事务管理器配置,单数据源事务 -->
<bean id="transactionManager" class="org.springframework.orm.hibernate3.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
<!-- 事务管理器配置,多数据源JTA事务 -->
<!--
<bean id="transactionManager"class="org.springframework.transaction.jta.JtaTransactionManageror
WebLogicJtaTransactionManager" />
-->
<!-- 使用annotation定义事务 -->
<tx:annotation-driven transaction-manager="transactionManager" />
</beans>
由于SpringSide不提供Mysql的jdbc驱动,所以需要自己去MySQL的官方网站下载,将下载到的mysql-connector-5.*.jar复制到项目的WEB-INF中的lib目录中。然后运行项目,成功。至此,成功将项目迁移到MySQL中。
第六步、添加数据表、编写Entity类、编写Dao类、Manager类,并进行单元测试。还是以前几篇文章中提到的文章发布系统为例,每一篇文章对应多篇评论,所以说据库中需创建articles和comments两个数据表,如下:
create table articles( id int primary key auto_increment, subject varchar ( 20 ) not null , content text ); create table comments( id int primary key auto_increment, content varchar ( 255 ), article_id int not null , foreign key (article_id) references articles(id) );
在编写Java代码之前,我还要做一点小工作,什么工作呢?那就是要为我自己的项目创建一个单独的源文件夹,因为src\main\java这个文件夹已经被江南白衣放入了太多的package,而且因为涉及到security,所以层次也不明显,操作起来不方便,找起代码来也不够快。下面是我创建了自己的源文件夹后的截图: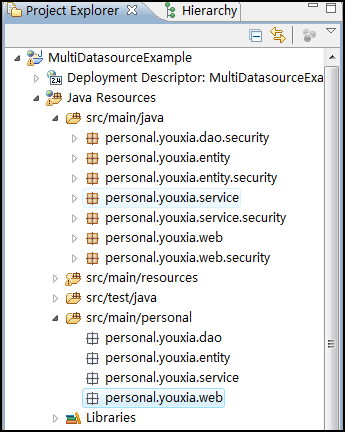
在我自己的源文件夹中,只创建了四个package,刚好代表从底到上的四个层次,这样,找起代码来要方便得多。
先来Entity层,Article.java的代码如下:
package com.zuidaima.entity;
import java.util.LinkedHashSet;
import java.util.Set;
import javax.persistence.CascadeType;
import javax.persistence.Entity;
import javax.persistence.JoinColumn;
import javax.persistence.OneToMany;
import javax.persistence.OrderBy;
import javax.persistence.Table;
import org.hibernate.annotations.Cache;
import org.hibernate.annotations.CacheConcurrencyStrategy;
import org.hibernate.annotations.Fetch;
import org.hibernate.annotations.FetchMode;
@Entity
// 表名与类名不相同时重新定义表名.
@Table(name= " articles " )
// 默认的缓存策略.
@Cache(usage= CacheConcurrencyStrategy.READ_WRITE)
public class Article extends IdEntity {
private String subject;
private String content;
private Set<Comment> comments=new LinkedHashSet<Comment>();
public String getSubject() {
return subject;
}
public void setSubject(String subject) {
this.subject=subject;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content=content;
}
@OneToMany(cascade={ CascadeType.ALL })
@JoinColumn(name="article_id")
// Fecth策略定义
@Fetch(FetchMode.SUBSELECT)
// 集合按id排序.
@OrderBy("id")
// 集合中对象id的缓存.
@Cache(usage=CacheConcurrencyStrategy.READ_WRITE)
public Set<Comment> getComments() {
return comments;
}
public void setComments(Set<Comment> comments) {
this.comments=comments;
}
}
Comment.java如下:
package com.zuidaima.entity.entities;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Table;
import org.hibernate.annotations.Cache;
import org.hibernate.annotations.CacheConcurrencyStrategy;
import com.zuidaima.entity.IdEntity;
@Entity
// 表名与类名不相同时重新定义表名.
@Table(name= " comments " )
// 默认的缓存策略.
@Cache(usage= CacheConcurrencyStrategy.READ_WRITE)
public class Comment extends IdEntity {
private String content;
private Long articleId;
public String getContent() {
return content;
}
public void setContent(String content) {
this .content= content;
}
@Column(name= " article_id " )
public Long getArticleId() {
return articleId;
}
public void setArticleId(Long articleId) {
this .articleId= articleId;
}
}
编写Dao层代码,ArticleDao.java如下:
package com.zuidaima.dao;
import org.springside.modules.orm.hibernate.HibernateDao;
import com.zuidaima.entity.Article;
public class ArticleDao extends HibernateDao <Article, Long> {
}
CommentDao.java如下:
package com.zuidaima.dao;
import org.springside.modules.orm.hibernate.HibernateDao;
import com.zuidaima.entity.Comment;
public class CommentDao extends HibernateDao <Comment, Long> {
}
可以看出,以上代码都从HibernateDao继承,得益于泛型支持,基本不需要编写一行代码。
编写Bussiness层代码,这一层,白衣使用的包名为service,而类名的后缀都是Manager,我就跟他学算了,懒得改了。
ArticleManager.java如下:
package com.zuidaima.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springside.modules.orm.hibernate.HibernateDao;
import com.zuidaima.dao.ArticleDao;
import com.zuidaima.entity.Article;
public class ArticleManager extends EntityManager <Article, Long> {
@Autowired
private ArticleDao articleDao;
public void setArticleDao(ArticleDao articleDao) {
this.articleDao=articleDao;
}
@Override
protected HibernateDao<Article, Long> getEntityDao() {
// TODO Auto-generated method stub
return articleDao;
}
}
CommentManager.java如下:
package com.zuidaima.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springside.modules.orm.hibernate.HibernateDao;
import com.zuidaima.dao.CommentDao;
import com.zuidaima.entity.Comment;
public class CommentManager extends EntityManager <Comment, Long> {
@Autowired
private CommentDao commentDao;
public void setCommentDao(CommentDao commentDao) {
this.commentDao=commentDao;
}
@Override
protected HibernateDao<Comment, Long> getEntityDao() {
// TODO Auto-generated method stub
return commentDao;
}
}
以上代码大同小异,都是从EntityManager继承,并使用Spring的IoC特性,将Dao类注入到Manager类之中,并重载getEntityDao方法来使用该注入的Dao。这个时候,为了验证这些数据访问相关的层能否正常运行,可以编写单元测试。 代码如下:
package com.zuidaima.test;
import org.junit.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springside.modules.test.junit4.SpringTxTestCase;
import com.zuidaima.entity.entities.Article;
import com.zuidaima.entity.entities.Comment;
import com.zuidaima.service.ArticleManager;
import com.zuidaima.service.CommentManager;
public class DataAccessTest extends SpringTxTestCase {
@Autowired
private ArticleManager articleManager;
@Autowired
private CommentManager commentManager;
public void setArticleManager(ArticleManager articleManager) {
this.articleManager=articleManager;
}
@Test
public void addArticle() {
Comment comment=new Comment();
Article article=new Article();
article.setSubject("test");
article.setContent("test");
articleManager.save(article);
comment.setArticleId(article.getId());
commentManager.save(comment);
}
}
单元测试一运行,发现了三个问题,先是出现Manager类没有注入成功的错误,经检查发现 所有的Manager类都应该使用@Service注解,再出现的错误是提示Dao类没有注入成功,经检查发现 所有的Dao类须使用@Repository注解,最后出现的错误是找不到Entity类的错误,经检查发现 Entity类不能位于com.zuidaima.entity包中,必须位于其子包中,这是由applicationContext.xml文件中的配置决定的,更改包名为com.zuidaima.entity.entities后,问题解决。
下一步就应该是编写Action和JSP了,由于文章太长,在Blogjava的编辑器中编辑已经非常缓慢了,所以只有将该文章分为上中下三部分。且看下回分解!
使用SpringSide 3.1.4.3开发Web项目的全过程(中)



相关推荐
内容概要:本文详细介绍了基于MATLAB GUI界面和卷积神经网络(CNN)的模糊车牌识别系统。该系统旨在解决现实中车牌因模糊不清导致识别困难的问题。文中阐述了整个流程的关键步骤,包括图像的模糊还原、灰度化、阈值化、边缘检测、孔洞填充、形态学操作、滤波操作、车牌定位、字符分割以及最终的字符识别。通过使用维纳滤波或最小二乘法约束滤波进行模糊还原,再利用CNN的强大特征提取能力完成字符分类。此外,还特别强调了MATLAB GUI界面的设计,使得用户能直观便捷地操作整个系统。 适合人群:对图像处理和深度学习感兴趣的科研人员、高校学生及从事相关领域的工程师。 使用场景及目标:适用于交通管理、智能停车场等领域,用于提升车牌识别的准确性和效率,特别是在面对模糊车牌时的表现。 其他说明:文中提供了部分关键代码片段作为参考,并对实验结果进行了详细的分析,展示了系统在不同环境下的表现情况及其潜在的应用前景。
嵌入式八股文面试题库资料知识宝典-计算机专业试题.zip
嵌入式八股文面试题库资料知识宝典-C and C++ normal interview_3.zip
内容概要:本文深入探讨了一款额定功率为4kW的开关磁阻电机,详细介绍了其性能参数如额定功率、转速、效率、输出转矩和脉动率等。同时,文章还展示了利用RMxprt、Maxwell 2D和3D模型对该电机进行仿真的方法和技术,通过外电路分析进一步研究其电气性能和动态响应特性。最后,文章提供了基于RMxprt模型的MATLAB仿真代码示例,帮助读者理解电机的工作原理及其性能特点。 适合人群:从事电机设计、工业自动化领域的工程师和技术人员,尤其是对开关磁阻电机感兴趣的科研工作者。 使用场景及目标:适用于希望深入了解开关磁阻电机特性和建模技术的研究人员,在新产品开发或现有产品改进时作为参考资料。 其他说明:文中提供的代码示例仅用于演示目的,实际操作时需根据所用软件的具体情况进行适当修改。
少儿编程scratch项目源代码文件案例素材-剑客冲刺.zip
少儿编程scratch项目源代码文件案例素材-几何冲刺 转瞬即逝.zip
内容概要:本文详细介绍了基于PID控制器的四象限直流电机速度驱动控制系统仿真模型及其永磁直流电机(PMDC)转速控制模型。首先阐述了PID控制器的工作原理,即通过对系统误差的比例、积分和微分运算来调整电机的驱动信号,从而实现转速的精确控制。接着讨论了如何利用PID控制器使有刷PMDC电机在四个象限中精确跟踪参考速度,并展示了仿真模型在应对快速负载扰动时的有效性和稳定性。最后,提供了Simulink仿真模型和详细的Word模型说明文档,帮助读者理解和调整PID控制器参数,以达到最佳控制效果。 适合人群:从事电力电子与电机控制领域的研究人员和技术人员,尤其是对四象限直流电机速度驱动控制系统感兴趣的读者。 使用场景及目标:适用于需要深入了解和掌握四象限直流电机速度驱动控制系统设计与实现的研究人员和技术人员。目标是在实际项目中能够运用PID控制器实现电机转速的精确控制,并提高系统的稳定性和抗干扰能力。 其他说明:文中引用了多篇相关领域的权威文献,确保了理论依据的可靠性和实用性。此外,提供的Simulink模型和Word文档有助于读者更好地理解和实践所介绍的内容。
嵌入式八股文面试题库资料知识宝典-2013年海康威视校园招聘嵌入式开发笔试题.zip
少儿编程scratch项目源代码文件案例素材-驾驶通关.zip
小区开放对周边道路通行能力影响的研究.pdf
内容概要:本文探讨了冷链物流车辆路径优化问题,特别是如何通过NSGA-2遗传算法和软硬时间窗策略来实现高效、环保和高客户满意度的路径规划。文中介绍了冷链物流的特点及其重要性,提出了软时间窗概念,允许一定的配送时间弹性,同时考虑碳排放成本,以达到绿色物流的目的。此外,还讨论了如何将客户满意度作为路径优化的重要评价标准之一。最后,通过一段简化的Python代码展示了遗传算法的应用。 适合人群:从事物流管理、冷链物流运营的专业人士,以及对遗传算法和路径优化感兴趣的科研人员和技术开发者。 使用场景及目标:适用于冷链物流企业,旨在优化配送路线,降低运营成本,减少碳排放,提升客户满意度。目标是帮助企业实现绿色、高效的物流配送系统。 其他说明:文中提供的代码仅为示意,实际应用需根据具体情况调整参数设置和模型构建。
少儿编程scratch项目源代码文件案例素材-恐怖矿井.zip
内容概要:本文详细介绍了基于STM32F030的无刷电机控制方案,重点在于高压FOC(磁场定向控制)技术和滑膜无感FOC的应用。该方案实现了过载、过欠压、堵转等多种保护机制,并提供了完整的源码、原理图和PCB设计。文中展示了关键代码片段,如滑膜观测器和电流环处理,以及保护机制的具体实现方法。此外,还提到了方案的移植要点和实际测试效果,确保系统的稳定性和高效性。 适合人群:嵌入式系统开发者、电机控制系统工程师、硬件工程师。 使用场景及目标:适用于需要高性能无刷电机控制的应用场景,如工业自动化设备、无人机、电动工具等。目标是提供一种成熟的、经过验证的无刷电机控制方案,帮助开发者快速实现并优化电机控制性能。 其他说明:提供的资料包括详细的原理图、PCB设计文件、源码及测试视频,方便开发者进行学习和应用。
基于有限体积法Godunov格式的管道泄漏检测模型研究.pdf
嵌入式八股文面试题库资料知识宝典-CC++笔试题-深圳有为(2019.2.28)1.zip
少儿编程scratch项目源代码文件案例素材-几何冲刺 V1.5.zip
Android系统开发_Linux内核配置_USB-HID设备模拟_通过root权限将Android设备转换为全功能USB键盘的项目实现_该项目需要内核支持configFS文件系统
C# WPF - LiveCharts Project
少儿编程scratch项目源代码文件案例素材-恐怖叉子 动画.zip
嵌入式八股文面试题库资料知识宝典-嵌⼊式⼯程师⾯试⾼频问题.zip