前几篇文章讲述了
HBase的安装、Hbase命令和API的使用、HBase简单的优化技巧,《HBase入门篇4》这篇文章是讲述把HBase的数据放在HDFS上的点滴过程。目前对与HBase我是一个绝对的新手,如果在文章中有任何我理解有错误的地方请各位指正,谢谢。
Ok,进行正题 ………
在HBase中创建的一张表可以分布在多个Hregion,也就说一张表可以被拆分成多块,每一块称我们呼为一个Hregion。每个Hregion会保 存一个表里面某段连续的数据,用户创建的那个大表中的每个Hregion块是由Hregion服务器提供维护,访问Hregion块是要通过 Hregion服务器,而一个Hregion块对应一个Hregion服务器,一张完整的表可以保存在多个Hregion 上。HRegion Server 与Region的对应关系是一对多的关系。每一个HRegion在物理上会被分为三个部分:Hmemcache(缓存)、Hlog(日志)、HStore(持久层)。
上述这些关系在我脑海中的样子,如图所示:
1.HRegionServer、HRegion、Hmemcache、Hlog、HStore之间的关系,如图所示:

2.HBase表中的数据与HRegionServer的分布关系,如图所示:

HBase读数据
HBase读取数据优先读取HMemcache中的内容,如果未取到再去读取Hstore中的数据,提高数据读取的性能。
HBase写数据
HBase写入数据会写到HMemcache和Hlog中,HMemcache建立缓存,Hlog同步Hmemcache和Hstore的事务日志,发起Flush Cache时,数据持久化到Hstore中,并清空HMemecache。
客户端访问这些数据的时候通过Hmaster ,每个 Hregion 服务器都会和Hmaster 服务器保持一个长连接,Hmaster 是HBase分布式系统中的管理者,他的主要任务就是要告诉每个Hregion 服务器它要维护哪些Hregion。用户的这些都数据可以保存在Hadoop 分布式文件系统上。 如果主服务器Hmaster死机,那么整个系统都会无效。下面我会考虑如何解决Hmaster的SPFO的问题,这个问题有点类似Hadoop的SPFO 问题一样只有一个NameNode维护全局的DataNode,HDFS一旦死机全部挂了,也有人说采用Heartbeat来解决这个问题,但我总想找出
其他的解决方案,多点时间,总有办法的。
昨天在hadoop-0.21.0、hbase-0.20.6的环境中折腾了很久,一直报错,错误信息如下:
Exception in thread "main" java.io.IOException: Call to localhost/serv6:9000 failed on local exception: java.io.EOFException
10/11/10 15:34:34 ERROR master.HMaster: Can not start master
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:39)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:27)
at java.lang.reflect.Constructor.newInstance(Constructor.java:513)
at org.apache.hadoop.hbase.master.HMaster.doMain(HMaster.java:1233)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:1274)
死活连接不上HDFS,也无法连接HMaster,郁闷啊。
我想想啊,慢慢想,我眼前一亮 java.io.EOFException 这个异常,是不是有可能是RPC 协定格式不一致导致的?也就是说服务器端和客户端的版本不一致的问题?换了一个HDFS的服务器端以后,一切都好了,果然是版本的问题,最后采用 hadoop-0.20.2 搭配hbase-0.20.6 比较稳当。
最后的效果如图所示:
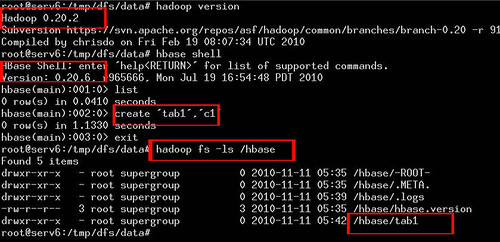
查看大图请点击这里, 上图的一些文字说明:
1.hadoop版本是0.20.2 ,
2.hbase版本是0.20.6,
3.在hbase中创建了一张表 tab1,退出hbase shell环境,
4.用hadoop命令查看,文件系统中的文件果然多了一个刚刚创建的tab1目录,
以上这张图片说明HBase在分布式文件系统Apache HDFS中运行了。
分享到:




相关推荐
《HBase专题配套文件解析》 HBase,全称Apache HBase,是构建在Hadoop分布式文件系统(HDFS)之上、面向列的开源数据库,主要用于处理大规模数据。HBase的设计理念是支持实时读写,适合大数据场景下的快速随机访问...
【标题】:“HBase专题测试文件” 【描述】:这篇内容是与HBase相关的测试资料,配合某博主的博客文章进行深入学习。博客链接指向了CSDN平台的一篇文章,详细介绍了HBase的相关知识和实战操作,这可能是对HBase进行...
本文档概述了广西大数据应用专题开发技术方案的第三个标包,主要介绍了大数据设计架构、分布式模块设计、插件化程序开发、多样化数据采集系统、Docker 容器部署、ArcGIS 二次开发等技术方案。 titre:广西大数据...
本文档是关于智慧城市大数据应用专题开发技术方案的详细技术方案,主要介绍了智慧城市大数据应用的架构设计、技术选型、系统部署、数据处理方式等方面的技术细节。 该方案的主要技术架构基于 Hadoop+Hive+Spark,...
分布式数据库如Cassandra、HBase等,它们解决了单机数据库在容量和性能上的瓶颈。分布式数据库通常采用分片策略,将数据分布在多个节点上,同时提供事务处理和一致性保证。 6. 分布式缓存 分布式缓存如Redis、...
除此之外,数据库知识也是重点,包括关系型数据库MySQL的事务处理、索引优化、查询优化,以及NoSQL数据库如MongoDB和HBase的使用场景和优缺点。数据结构与算法虽然不是Java特定的,但它们是衡量开发者解决问题能力的...
由于应急测绘需要处理大量的地理空间数据,分布式数据库能够帮助实现快速查询和统计周边地物、人口、法人等专题数据,满足不同尺度和不同用户需求的测绘应急专题数据资源服务。 传统的数据库系统在处理大量数据时...
"大数据应用专题开发技术方案" 大数据设计架构 在广东移动大数据关联分析服务项目中,采用了 HADOOP+MPP+RDB+流计算混搭技术架构,满足不同类型数据处理及访问需求。系统架构体系通过使用信令 XDR 数据、MR 数据、...
- HBase的元数据管理:HBase的RegionServer定位依赖Zookeeper。 - Kafka的集群管理:Kafka的Broker选举和消费者分区分配依赖Zookeeper。 - Dubbo的服务注册与发现:Dubbo通过Zookeeper实现服务的注册、查找和监控...
**Zookeeper面试专题及答案** 在Java开发领域,Apache ZooKeeper是一个至关重要的分布式协调服务,它为分布式应用程序提供了高可用性、一致性以及命名服务等关键功能。本篇内容将深入探讨Zookeeper的核心概念、功能...
【Hadoop与大数据技术大会2012PPT】是一个关于Hadoop和大数据技术的专题会议,该会议可能聚集了业界专家和学者,分享了他们在2012年关于这两个领域的最新研究、实践经验和未来发展趋势。这个压缩包包含了多个PDF文件...
【Java与MongoDB面试专题】 在Java开发中,MongoDB是一种广泛应用的NoSQL数据库,尤其在处理非结构化和半结构化数据时表现出色。在面试中,掌握关于MongoDB的基本概念、特性和与传统RDBMS的区别是至关重要的。 1. ...
Java前后开发面试题,大厂进阶之路,基于JavaGuide、Cyc大佬、牛客...包含计算机网络知识、JavaSE、JVM、Spring、Springboot、SpringCloud、Mybatis、多线程并发、netty、MySQL、MongoDB、Elasticsearch、Redis、HBASE
MongoDB面试专题及答案.pdf 本文档总结了 MongoDB 相关的知识点,涵盖了 NoSQL 数据库的定义、类型、特点、优点、应用场景、与 RDBMS 的差别、MongoDB 的特点、优势、限制等。 NoSQL 数据库 NoSQL 数据库是一种非...
HBase 知识体系最强总结 Hadoop知识体系最强宝典 Hadoop企业级调优手册 Flink知识体系保姆级总结 Flink面试八股文 最强最全面数仓建设规范指南(强烈推荐) 最强最全面的大数据SQL面试题和答案 数据结构与算法篇 数据...
### MongoDB面试专题知识点详解 #### 1. NoSQL数据库的概念及其与RDBMS的区别 - **NoSQL**:Non-relational databases(非关系型数据库),通常指那些**不使用传统的关系表格来组织数据**的数据库系统。NoSQL的...
Zookeeper 是一个分布式协调服务,源自 Apache Hadoop 项目,主要设计用于...Zookeeper 在分布式系统中的应用广泛,包括 HBase、Kafka、Hadoop 等项目,理解和掌握其核心概念和机制对于从事分布式开发的人员至关重要。
《Zookeeper面试专题》 Apache ZooKeeper 是一个分布式协调服务,它为分布式应用程序提供一致性服务。在面试中,Zookeeper 是一个经常被提及的话题,因为它在大数据、云计算和分布式系统中的核心作用。以下是对...