
еҺҹж–Үй“ҫжҺҘВ http://www.cnblogs.com/xinzhao/p/5644175.htmlВ
В
HashMapе’ҢHashTableжңүд»Җд№ҲдёҚеҗҢпјҹеңЁйқўиҜ•е’Ңиў«йқўиҜ•зҡ„иҝҮзЁӢдёӯпјҢжҲ‘й—®иҝҮд№ҹиў«й—®иҝҮиҝҷдёӘй—®йўҳпјҢд№ҹи§ҒиҝҮдәҶдёҚе°‘еӣһзӯ”пјҢд»ҠеӨ©еҶіе®ҡеҶҷдёҖеҶҷиҮӘе·ұеҝғзӣ®дёӯзҡ„зҗҶжғізӯ”жЎҲгҖӮ
д»Јз ҒзүҲжң¬
JDKжҜҸдёҖзүҲжң¬йғҪеңЁж”№иҝӣгҖӮжң¬ж–Үи®Ёи®әзҡ„HashMapе’ҢHashTableеҹәдәҺJDK 1.7.0_67гҖӮжәҗз Ғи§ҒиҝҷйҮҢ
1. ж—¶й—ҙ
HashTableдә§з”ҹдәҺJDK 1.1пјҢиҖҢHashMapдә§з”ҹдәҺJDK 1.2гҖӮд»Һж—¶й—ҙзҡ„з»ҙеәҰдёҠжқҘзңӢпјҢHashMapиҰҒжҜ”HashTableеҮәзҺ°еҫ—жҷҡдёҖдәӣгҖӮ
2. дҪңиҖ…
д»ҘдёӢжҳҜHashTableзҡ„дҪңиҖ…пјҡ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTable
* @author Arthur van Hoff
* @author Josh Bloch
* @author Neal Gafterд»ҘдёӢжҳҜHashMapзҡ„дҪңиҖ…пјҡ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashMap
* @author Doug Lea
* @author Josh Bloch
* @author Arthur van Hoff
* @author Neal GafterеҸҜд»ҘзңӢеҲ°HashMapзҡ„дҪңиҖ…еӨҡдәҶеӨ§зҘһDoug LeaгҖӮдёҚдәҶи§ЈDoug Leaзҡ„пјҢеҸҜд»ҘзңӢиҝҷйҮҢгҖӮ
3. еҜ№еӨ–зҡ„жҺҘеҸЈпјҲAPIпјү
HashMapе’ҢHashTableйғҪжҳҜеҹәдәҺе“ҲеёҢиЎЁжқҘе®һзҺ°й”®еҖјжҳ е°„зҡ„е·Ҙе…·зұ»гҖӮи®Ёи®ә他们зҡ„дёҚеҗҢпјҢжҲ‘们йҰ–е…ҲжқҘзңӢдёҖдёӢ他们жҡҙйңІеңЁеӨ–зҡ„APIжңүд»Җд№ҲдёҚеҗҢгҖӮ
3.1 Public Method
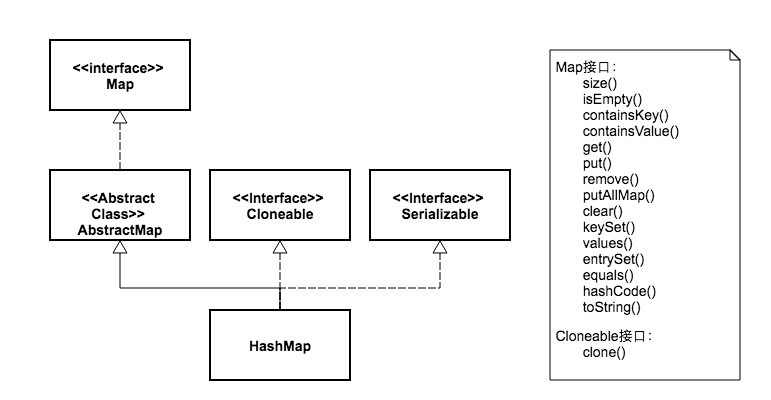
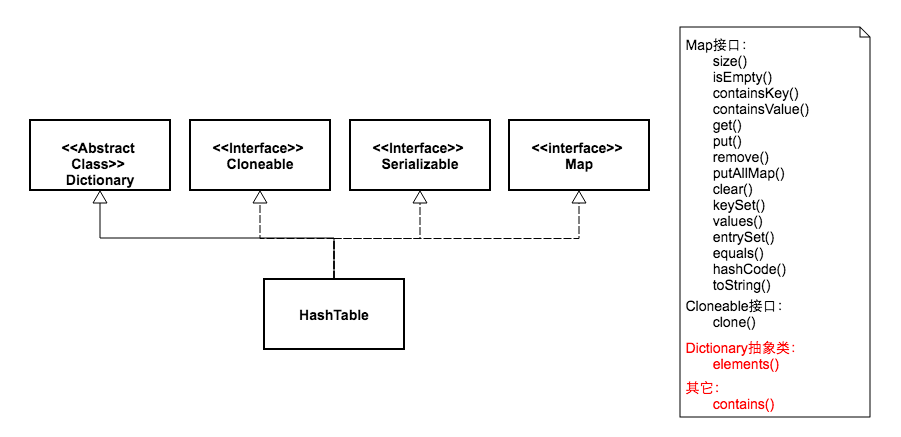
дёӢйқўдёӨеј еӣҫпјҢжҲ‘з”»еҮәдәҶHashMapе’ҢHashTableзҡ„зұ»з»§жүҝдҪ“зі»пјҢ并еҲ—еҮәдәҶиҝҷдёӨдёӘзұ»зҡ„еҸҜдҫӣеӨ–йғЁи°ғз”Ёзҡ„е…¬ејҖж–№жі•гҖӮ
В
В
д»ҺеӣҫдёӯеҸҜд»ҘзңӢеҮәпјҢдёӨдёӘзұ»зҡ„继жүҝдҪ“зі»жңүдәӣдёҚеҗҢгҖӮиҷҪ然йғҪе®һзҺ°дәҶMapгҖҒCloneableгҖҒSerializableдёүдёӘжҺҘеҸЈгҖӮдҪҶжҳҜHashMap继жүҝиҮӘжҠҪиұЎзұ»AbstractMapпјҢиҖҢHashTable继жүҝиҮӘжҠҪиұЎзұ»DictionaryгҖӮе…¶дёӯDictionaryзұ»жҳҜдёҖдёӘе·Із»Ҹиў«еәҹејғзҡ„зұ»пјҢиҝҷдёҖзӮ№жҲ‘们еҸҜд»Ҙд»Һе®ғд»Јз Ғзҡ„жіЁйҮҠдёӯзңӢеҲ°пјҡ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.Dictionary
* <strong>NOTE: This class is obsolete. New implementations should
* implement the Map interface, rather than extending thisclass.</strong>еҗҢж—¶жҲ‘们зңӢеҲ°HashTableжҜ”HashMapеӨҡдәҶдёӨдёӘе…¬ејҖж–№жі•гҖӮдёҖдёӘжҳҜelementsпјҢиҝҷжқҘиҮӘдәҺжҠҪиұЎзұ»DictionaryпјҢйүҙдәҺиҜҘзұ»е·Із»ҸеәҹејғпјҢжүҖд»ҘиҝҷдёӘж–№жі•д№ҹе°ұжІЎд»Җд№Ҳз”ЁеӨ„дәҶгҖӮеҸҰдёҖдёӘеӨҡеҮәжқҘзҡ„ж–№жі•жҳҜcontainsпјҢиҝҷдёӘеӨҡеҮәжқҘзҡ„ж–№жі•д№ҹжІЎд»Җд№Ҳз”ЁпјҢеӣ дёәе®ғи·ҹcontainsValueж–№жі•еҠҹиғҪжҳҜдёҖж ·зҡ„гҖӮд»Јз ҒдёәиҜҒпјҡ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTablepublicsynchronizedbooleancontains(Object value) {
if (value == null) {
throw new NullPointerException();
}
Entry tab[] = table;
for (int i = tab.length ; i-- > 0 ;) {
for (Entry<K,V> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}
publicbooleancontainsValue(Object value) {
return contains(value);
}жүҖд»Ҙд»Һе…¬ејҖзҡ„ж–№жі•дёҠжқҘзңӢпјҢиҝҷдёӨдёӘзұ»жҸҗдҫӣзҡ„пјҢжҳҜдёҖж ·зҡ„еҠҹиғҪгҖӮйғҪжҸҗдҫӣй”®еҖјжҳ е°„зҡ„жңҚеҠЎпјҢеҸҜд»ҘеўһгҖҒеҲ гҖҒжҹҘгҖҒж”№й”®еҖјеҜ№пјҢеҸҜд»ҘеҜ№е»әгҖҒеҖјгҖҒй”®еҖјеҜ№жҸҗдҫӣйҒҚеҺҶи§ҶеӣҫгҖӮж”ҜжҢҒжө…жӢ·иҙқпјҢж”ҜжҢҒеәҸеҲ—еҢ–гҖӮ
3.2 Null Key & Null Value
HashMapжҳҜж”ҜжҢҒnullй”®е’ҢnullеҖјзҡ„пјҢиҖҢHashTableеңЁйҒҮеҲ°nullж—¶пјҢдјҡжҠӣеҮәNullPointerExceptionејӮеёёгҖӮиҝҷ并дёҚжҳҜеӣ дёәHashTableжңүд»Җд№Ҳзү№ж®Ҡзҡ„е®һзҺ°еұӮйқўзҡ„еҺҹеӣ еҜјиҮҙдёҚиғҪж”ҜжҢҒnullй”®е’ҢnullеҖјпјҢиҝҷд»…д»…жҳҜеӣ дёәHashMapеңЁе®һзҺ°ж—¶еҜ№nullеҒҡдәҶзү№ж®ҠеӨ„зҗҶпјҢе°Ҷnullзҡ„hashCodeеҖје®ҡдёәдәҶ0пјҢд»ҺиҖҢе°Ҷе…¶еӯҳж”ҫеңЁе“ҲеёҢиЎЁзҡ„第0дёӘbucketдёӯгҖӮжҲ‘们дёҖputж–№жі•дёәдҫӢпјҢзңӢдёҖзңӢд»Јз Ғзҡ„з»ҶиҠӮпјҡ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTablepublicsynchronized V put(K key, V value) {
// еҰӮжһңvalueдёәnullпјҢжҠӣеҮәNullPointerException
if (value == null) {
throw new NullPointerException();
}
// еҰӮжһңkeyдёәnullпјҢеңЁи°ғз”Ёkey.hashCode()ж—¶жҠӣеҮәNullPointerException
// ...
}
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HasMappublic V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// еҪ“keyдёәnullж—¶пјҢи°ғз”ЁputForNullKeyзү№ж®ҠеӨ„зҗҶ
if (key == null)
return putForNullKey(value);
// ...
}
private V putForNullKey(V value) {
// keyдёәnullж—¶пјҢж”ҫеҲ°table[0]д№ҹе°ұжҳҜ第0дёӘbucketдёӯ
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}4. е®һзҺ°еҺҹзҗҶ
жң¬иҠӮи®Ёи®әHashMapе’ҢHashTableеңЁж•°жҚ®з»“жһ„е’Ңз®—жі•еұӮйқўпјҢжңүд»Җд№ҲдёҚеҗҢгҖӮ
4.1 ж•°жҚ®з»“жһ„
HashMapе’ҢHashTableйғҪдҪҝз”Ёе“ҲеёҢиЎЁжқҘеӯҳеӮЁй”®еҖјеҜ№гҖӮеңЁж•°жҚ®з»“жһ„дёҠжҳҜеҹәжң¬зӣёеҗҢзҡ„пјҢйғҪеҲӣе»әдәҶдёҖдёӘ继жүҝиҮӘMap.Entryзҡ„з§Ғжңүзҡ„еҶ…йғЁзұ»EntryпјҢжҜҸдёҖдёӘEntryеҜ№иұЎиЎЁзӨәеӯҳеӮЁеңЁе“ҲеёҢиЎЁдёӯзҡ„дёҖдёӘй”®еҖјеҜ№гҖӮ
EntryеҜ№иұЎе”ҜдёҖиЎЁзӨәдёҖдёӘй”®еҖјеҜ№пјҢжңүеӣӣдёӘеұһжҖ§пјҡ
-K key й”®еҜ№иұЎ
-V value еҖјеҜ№иұЎ
-int hash й”®еҜ№иұЎзҡ„hashеҖј
-Entry<k, v="" style="margin: 0px; padding: 0px;">В entry жҢҮеҗ‘й“ҫиЎЁдёӯдёӢдёҖдёӘEntryеҜ№иұЎпјҢеҸҜдёәnullпјҢиЎЁзӨәеҪ“еүҚEntryеҜ№иұЎеңЁй“ҫиЎЁе°ҫйғЁ
еҸҜд»ҘиҜҙпјҢжңүеӨҡе°‘дёӘй”®еҖјеҜ№пјҢе°ұжңүеӨҡе°‘дёӘEntryеҜ№иұЎпјҢйӮЈд№ҲеңЁHashMapе’ҢHashTableдёӯжҳҜжҖҺд№ҲеӯҳеӮЁиҝҷдәӣEntryеҜ№иұЎпјҢд»Ҙж–№дҫҝжҲ‘们еҝ«йҖҹжҹҘжүҫе’Ңдҝ®ж”№зҡ„е‘ўпјҹиҜ·зңӢдёӢеӣҫгҖӮ
В

дёҠеӣҫз”»еҮәзҡ„жҳҜдёҖдёӘжЎ¶ж•°йҮҸдёә8пјҢеӯҳжңү5дёӘй”®еҖјеҜ№зҡ„HashMap/HashTableзҡ„еҶ…еӯҳеёғеұҖжғ…еҶөгҖӮеҸҜд»ҘзңӢеҲ°HashMap/HashTableеҶ…йғЁеҲӣе»әжңүдёҖдёӘEntryзұ»еһӢзҡ„еј•з”Ёж•°з»„пјҢз”ЁжқҘиЎЁзӨәе“ҲеёҢиЎЁпјҢж•°з»„зҡ„й•ҝеәҰпјҢеҚіжҳҜе“ҲеёҢжЎ¶зҡ„ж•°йҮҸгҖӮиҖҢж•°з»„зҡ„жҜҸдёҖдёӘе…ғзҙ йғҪжҳҜдёҖдёӘEntryеј•з”ЁпјҢд»ҺEntryеҜ№иұЎзҡ„еұһжҖ§йҮҢпјҢд№ҹеҸҜд»ҘзңӢеҮәе…¶жҳҜй“ҫиЎЁзҡ„иҠӮзӮ№пјҢжҜҸдёҖдёӘEntryеҜ№иұЎеҶ…йғЁеҸҲеҗ«жңүеҸҰдёҖдёӘEntryеҜ№иұЎзҡ„еј•з”ЁгҖӮ
иҝҷж ·е°ұеҸҜд»Ҙеҫ—еҮәз»“и®әпјҢHashMap/HashTableеҶ…йғЁз”ЁEntryж•°з»„е®һзҺ°е“ҲеёҢиЎЁпјҢиҖҢеҜ№дәҺжҳ е°„еҲ°еҗҢдёҖдёӘе“ҲеёҢжЎ¶пјҲж•°з»„зҡ„еҗҢдёҖдёӘдҪҚзҪ®пјүзҡ„й”®еҖјеҜ№пјҢдҪҝз”ЁEntryй“ҫиЎЁжқҘеӯҳеӮЁ(и§ЈеҶіhashеҶІзӘҒ)гҖӮ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTable
/** * The hash table data. */
private transient Entry<K,V>[] table;
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashMap
/** * The table, resized as necessary. Length MUST Always be a power of two. */
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;д»Һд»Јз ҒеҸҜд»ҘзңӢеҲ°пјҢеҜ№дәҺе“ҲеёҢжЎ¶зҡ„еҶ…йғЁиЎЁзӨәпјҢдёӨдёӘзұ»зҡ„е®һзҺ°жҳҜдёҖиҮҙзҡ„гҖӮ
4.2 з®—жі•
дёҠдёҖе°ҸиҠӮе·Із»ҸиҜҙдәҶз”ЁжқҘиЎЁзӨәе“ҲеёҢиЎЁзҡ„еҶ…йғЁж•°жҚ®з»“жһ„гҖӮHashMap/HashTableиҝҳйңҖиҰҒжңүз®—жі•жқҘе°Ҷз»ҷе®ҡзҡ„й”®keyпјҢжҳ е°„еҲ°зЎ®е®ҡзҡ„hashжЎ¶пјҲж•°з»„дҪҚзҪ®пјүгҖӮйңҖиҰҒжңүз®—жі•еңЁе“ҲеёҢжЎ¶еҶ…зҡ„й”®еҖјеҜ№еӨҡеҲ°дёҖе®ҡзЁӢеәҰж—¶пјҢжү©е……е“ҲеёҢиЎЁзҡ„еӨ§е°ҸпјҲж•°з»„зҡ„еӨ§е°ҸпјүгҖӮжң¬е°ҸиҠӮжҜ”иҫғиҝҷдёӨдёӘзұ»еңЁз®—жі•еұӮйқўжңүе“ӘдәӣдёҚеҗҢгҖӮ
еҲқе§Ӣе®№йҮҸеӨ§е°Ҹе’ҢжҜҸж¬Ўжү©е……е®№йҮҸеӨ§е°Ҹзҡ„дёҚеҗҢгҖӮе…ҲзңӢд»Јз Ғпјҡ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTable
// е“ҲеёҢиЎЁй»ҳи®ӨеҲқе§ӢеӨ§е°Ҹдёә11
public Hashtable() {
this(11, 0.75f);
}
protectedvoidrehash() {
int oldCapacity = table.length;
Entry<K,V>[] oldMap = table;
// жҜҸж¬Ўжү©е®№дёәеҺҹжқҘзҡ„2n+1
int newCapacity = (oldCapacity << 1) + 1;
// ...
}
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashMap
// е“ҲеёҢиЎЁй»ҳи®ӨеҲқе§ӢеӨ§е°Ҹдёә2^4=16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
voidaddEntry(int hash, K key, V value, int bucketIndex) {
// жҜҸж¬Ўжү©е……дёәеҺҹжқҘзҡ„2n
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
}еҸҜд»ҘзңӢеҲ°HashTableй»ҳи®Өзҡ„еҲқе§ӢеӨ§е°Ҹдёә11пјҢд№ӢеҗҺжҜҸж¬Ўжү©е……дёәеҺҹжқҘзҡ„2n+1гҖӮHashMapй»ҳи®Өзҡ„еҲқе§ӢеҢ–еӨ§е°Ҹдёә16пјҢд№ӢеҗҺжҜҸж¬Ўжү©е……дёәеҺҹжқҘзҡ„2еҖҚгҖӮиҝҳжңүжҲ‘жІЎеҲ—еҮәд»Јз Ғзҡ„дёҖзӮ№пјҢе°ұжҳҜеҰӮжһңеңЁеҲӣе»әж—¶з»ҷе®ҡдәҶеҲқе§ӢеҢ–еӨ§е°ҸпјҢйӮЈд№ҲHashTableдјҡзӣҙжҺҘдҪҝз”ЁдҪ з»ҷе®ҡзҡ„еӨ§е°ҸпјҢиҖҢHashMapдјҡе°Ҷе…¶жү©е……дёә2зҡ„е№Ӯж¬Ўж–№еӨ§е°ҸгҖӮ
д№ҹе°ұжҳҜиҜҙHashTableдјҡе°ҪйҮҸдҪҝз”Ёзҙ ж•°гҖҒеҘҮж•°гҖӮиҖҢHashMapеҲҷжҖ»жҳҜдҪҝз”Ё2зҡ„е№ӮдҪңдёәе“ҲеёҢиЎЁзҡ„еӨ§е°ҸгҖӮжҲ‘们зҹҘйҒ“еҪ“е“ҲеёҢиЎЁзҡ„еӨ§е°Ҹдёәзҙ ж•°ж—¶пјҢз®ҖеҚ•зҡ„еҸ–жЁЎе“ҲеёҢзҡ„з»“жһңдјҡжӣҙеҠ еқҮеҢҖпјҲе…·дҪ“иҜҒжҳҺпјҢи§ҒиҝҷзҜҮж–Үз« пјүпјҢжүҖд»ҘеҚ•д»ҺиҝҷдёҖзӮ№дёҠзңӢпјҢHashTableзҡ„е“ҲеёҢиЎЁеӨ§е°ҸйҖүжӢ©пјҢдјјд№Һжӣҙй«ҳжҳҺдәӣгҖӮдҪҶеҸҰдёҖж–№йқўжҲ‘们еҸҲзҹҘйҒ“пјҢеңЁеҸ–жЁЎи®Ўз®—ж—¶пјҢеҰӮжһңжЁЎж•°жҳҜ2зҡ„е№ӮпјҢйӮЈд№ҲжҲ‘们еҸҜд»ҘзӣҙжҺҘдҪҝз”ЁдҪҚиҝҗз®—жқҘеҫ—еҲ°з»“жһңпјҢж•ҲзҺҮиҰҒеӨ§еӨ§й«ҳдәҺеҒҡйҷӨжі•гҖӮжүҖд»Ҙд»Һhashи®Ўз®—зҡ„ж•ҲзҺҮдёҠпјҢеҸҲжҳҜHashMapжӣҙиғңдёҖзӯ№гҖӮ
жүҖд»ҘпјҢдәӢе®һе°ұжҳҜHashMapдёәдәҶеҠ еҝ«hashзҡ„йҖҹеәҰпјҢе°Ҷе“ҲеёҢиЎЁзҡ„еӨ§е°Ҹеӣәе®ҡдёәдәҶ2зҡ„е№ӮгҖӮеҪ“然иҝҷеј•е…ҘдәҶе“ҲеёҢеҲҶеёғдёҚеқҮеҢҖзҡ„й—®йўҳпјҢжүҖд»ҘHashMapдёәи§ЈеҶіиҝҷй—®йўҳпјҢеҸҲеҜ№hashз®—жі•еҒҡдәҶдёҖдәӣж”№еҠЁгҖӮе…·дҪ“жҲ‘们жқҘзңӢзңӢпјҢеңЁиҺ·еҸ–дәҶkeyеҜ№иұЎзҡ„hashCodeд№ӢеҗҺпјҢHashTableе’ҢHashMapеҲҶеҲ«жҳҜжҖҺж ·е°Ҷ他们hashеҲ°зЎ®е®ҡзҡ„е“ҲеёҢжЎ¶пјҲEntryж•°з»„дҪҚзҪ®пјүдёӯзҡ„гҖӮ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTable
// hash дёҚиғҪи¶…иҝҮInteger.MAX_VALUE жүҖд»ҘиҰҒеҸ–е…¶жңҖе°Ҹзҡ„31дёӘbit
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
// зӣҙжҺҘи®Ўз®—key.hashCode()
privateinthash(Object k) {
// hashSeed will be zero if alternative hashing is disabled.
return hashSeed ^ k.hashCode();
}
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashMap
int hash = hash(key);
int i = indexFor(hash, table.length);
// еңЁи®Ўз®—дәҶkey.hashCode()д№ӢеҗҺпјҢеҒҡдәҶдёҖдәӣдҪҚиҝҗз®—жқҘеҮҸе°‘е“ҲеёҢеҶІзӘҒ
finalinthash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// еҸ–жЁЎдёҚеҶҚйңҖиҰҒеҒҡйҷӨжі•
staticintindexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}жӯЈеҰӮжҲ‘们жүҖиЁҖпјҢHashMapз”ұдәҺдҪҝз”ЁдәҶ2зҡ„е№Ӯж¬Ўж–№пјҢжүҖд»ҘеңЁеҸ–жЁЎиҝҗз®—ж—¶дёҚйңҖиҰҒеҒҡйҷӨжі•пјҢеҸӘйңҖиҰҒдҪҚзҡ„дёҺиҝҗз®—е°ұеҸҜд»ҘдәҶгҖӮдҪҶжҳҜз”ұдәҺеј•е…Ҙзҡ„hashеҶІзӘҒеҠ еү§й—®йўҳпјҢHashMapеңЁи°ғз”ЁдәҶеҜ№иұЎзҡ„hashCodeж–№жі•д№ӢеҗҺпјҢеҸҲеҒҡдәҶдёҖдәӣдҪҚиҝҗз®—еңЁжү“ж•Јж•°жҚ®гҖӮе…ідәҺиҝҷдәӣдҪҚи®Ўз®—дёәд»Җд№ҲеҸҜд»Ҙжү“ж•Јж•°жҚ®зҡ„й—®йўҳпјҢжң¬ж–ҮдёҚеҶҚеұ•ејҖдәҶгҖӮж„ҹе…ҙи¶Јзҡ„еҸҜд»ҘзңӢиҝҷйҮҢгҖӮ
еҰӮжһңдҪ жңүз»ҶеҝғиҜ»д»Јз ҒпјҢиҝҳеҸҜд»ҘеҸ‘зҺ°дёҖзӮ№пјҢе°ұжҳҜHashMapе’ҢHashTableеңЁи®Ўз®—hashж—¶йғҪз”ЁеҲ°дәҶдёҖдёӘеҸ«hashSeedзҡ„еҸҳйҮҸгҖӮиҝҷжҳҜеӣ дёәжҳ е°„еҲ°еҗҢдёҖдёӘhashжЎ¶еҶ…зҡ„EntryеҜ№иұЎпјҢжҳҜд»Ҙй“ҫиЎЁзҡ„еҪўејҸеӯҳеңЁзҡ„пјҢиҖҢй“ҫиЎЁзҡ„жҹҘиҜўж•ҲзҺҮжҜ”иҫғдҪҺпјҢжүҖд»ҘHashMap/HashTableзҡ„ж•ҲзҺҮеҜ№е“ҲеёҢеҶІзӘҒйқһеёёж•Ҹж„ҹпјҢжүҖд»ҘеҸҜд»ҘйўқеӨ–ејҖеҗҜдёҖдёӘеҸҜйҖүhashпјҲhashSeedпјүпјҢд»ҺиҖҢеҮҸе°‘е“ҲеёҢеҶІзӘҒгҖӮеӣ дёәиҝҷжҳҜдёӨдёӘзұ»зӣёеҗҢзҡ„дёҖзӮ№пјҢжүҖд»Ҙжң¬ж–ҮдёҚеҶҚеұ•ејҖдәҶпјҢж„ҹе…ҙи¶Јзҡ„зңӢиҝҷйҮҢгҖӮдәӢе®һдёҠпјҢиҝҷдёӘдјҳеҢ–еңЁJDK 1.8дёӯе·Із»ҸеҺ»жҺүдәҶпјҢеӣ дёәJDK 1.8дёӯпјҢжҳ е°„еҲ°еҗҢдёҖдёӘе“ҲеёҢжЎ¶пјҲж•°з»„дҪҚзҪ®пјүзҡ„EntryеҜ№иұЎпјҢдҪҝз”ЁдәҶзәўй»‘ж ‘жқҘеӯҳеӮЁпјҢд»ҺиҖҢеӨ§еӨ§еҠ йҖҹдәҶе…¶жҹҘжүҫж•ҲзҺҮгҖӮ
5. зәҝзЁӢе®үе…Ё
жҲ‘们иҜҙHashTableжҳҜеҗҢжӯҘзҡ„пјҢHashMapдёҚжҳҜпјҢд№ҹе°ұжҳҜиҜҙHashTableеңЁеӨҡзәҝзЁӢдҪҝз”Ёзҡ„жғ…еҶөдёӢпјҢдёҚйңҖиҰҒеҒҡйўқеӨ–зҡ„еҗҢжӯҘпјҢиҖҢHashMapеҲҷдёҚиЎҢгҖӮйӮЈд№ҲHashTableжҳҜжҖҺд№ҲеҒҡеҲ°зҡ„е‘ўпјҹ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTablepublicsynchronized V get(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
public Set<K> keySet() {
if (keySet == null)
keySet = Collections.synchronizedSet(new KeySet(), this);
return keySet;
}еҸҜд»ҘзңӢеҲ°пјҢд№ҹжҜ”иҫғз®ҖеҚ•пјҢе°ұжҳҜе…¬ејҖзҡ„ж–№жі•жҜ”еҰӮgetйғҪдҪҝз”ЁдәҶsynchronizedжҸҸиҝ°з¬ҰгҖӮиҖҢйҒҚеҺҶи§ҶеӣҫжҜ”еҰӮkeySetйғҪдҪҝз”ЁдәҶCollections.synchronizedXXXиҝӣиЎҢдәҶеҗҢжӯҘеҢ…иЈ…гҖӮ
6. д»Јз ҒйЈҺж ј
д»ҺжҲ‘зҡ„е“ҒдҪҚжқҘзңӢпјҢHashMapзҡ„д»Јз ҒиҰҒжҜ”HashTableж•ҙжҙҒеҫҲеӨҡгҖӮдёӢйқўиҝҷж®өHashTableзҡ„д»Јз ҒпјҢжҲ‘е°ұи§үзқҖжңүзӮ№ж··д№ұпјҢдёҚеӨӘиғҪжҺҘеҸ—иҝҷз§Қд»Јз ҒеӨҚз”Ёзҡ„ж–№ејҸгҖӮ
д»ҘдёӢд»Јз ҒеҸҠжіЁйҮҠжқҘиҮӘjava.util.HashTable
/** * A hashtable enumerator class. This class implements both the * Enumeration and Iterator interfaces, but individual instances * can be created with the Iterator methods disabled. This is necessary * to avoid unintentionally increasing the capabilities granted a user * by passing an Enumeration. */
private class Enumerator<T> implements Enumeration<T>, Iterator<T> {
Entry[] table = Hashtable.this.table;
int index = table.length;
Entry<K,V> entry = null;
Entry<K,V> lastReturned = null;
int type;
/** * Indicates whether this Enumerator is serving as an Iterator * or an Enumeration. (true -> Iterator). */
boolean iterator;
/** * The modCount value that the iterator believes that the backing * Hashtable should have. If this expectation is violated, the iterator * has detected concurrent modification. */
protected int expectedModCount = modCount;
Enumerator(int type, boolean iterator) {
this.type = type;
this.iterator = iterator;
}
//...
}7. HashTableе·Із»Ҹиў«ж·ҳжұ°дәҶпјҢдёҚиҰҒеңЁд»Јз ҒдёӯеҶҚдҪҝз”Ёе®ғгҖӮ
д»ҘдёӢжҸҸиҝ°жқҘиҮӘдәҺHashTableзҡ„зұ»жіЁйҮҠпјҡ
If a thread-safe implementation is not needed, it is recommended to use HashMap in place of Hashtable. If a thread-safe highly-concurrent implementation is desired, then it is recommended to use java.util.concurrent.ConcurrentHashMap in place of Hashtable.
з®ҖеҚ•жқҘиҜҙе°ұжҳҜпјҢеҰӮжһңдҪ дёҚйңҖиҰҒзәҝзЁӢе®үе…ЁпјҢйӮЈд№ҲдҪҝз”ЁHashMapпјҢеҰӮжһңйңҖиҰҒзәҝзЁӢе®үе…ЁпјҢйӮЈд№ҲдҪҝз”ЁConcurrentHashMapгҖӮHashTableе·Із»Ҹиў«ж·ҳжұ°дәҶпјҢдёҚиҰҒеңЁж–°зҡ„д»Јз ҒдёӯеҶҚдҪҝз”Ёе®ғгҖӮ
8. жҢҒз»ӯдјҳеҢ–
иҷҪ然HashMapе’ҢHashTableзҡ„е…¬ејҖжҺҘеҸЈеә”иҜҘдёҚдјҡж”№еҸҳпјҢжҲ–иҖ…иҜҙж”№еҸҳдёҚйў‘з№ҒгҖӮдҪҶжҜҸдёҖзүҲжң¬зҡ„JDKпјҢйғҪдјҡеҜ№HashMapе’ҢHashTableзҡ„еҶ…йғЁе®һзҺ°еҒҡдјҳеҢ–пјҢжҜ”еҰӮдёҠж–ҮжӣҫжҸҗеҲ°зҡ„JDK 1.8зҡ„зәўй»‘ж ‘дјҳеҢ–гҖӮжүҖд»ҘпјҢе°ҪеҸҜиғҪзҡ„дҪҝз”Ёж–°зүҲжң¬зҡ„JDKеҗ§пјҢйҷӨдәҶйӮЈдәӣзӮ«й…·зҡ„ж–°еҠҹиғҪпјҢжҷ®йҖҡзҡ„APIд№ҹдјҡжңүжҖ§иғҪдёҠжңүжҸҗеҚҮгҖӮ
дёәд»Җд№ҲHashTableе·Із»Ҹж·ҳжұ°дәҶпјҢиҝҳиҰҒдјҳеҢ–е®ғпјҹеӣ дёәжңүиҖҒзҡ„д»Јз ҒиҝҳеңЁдҪҝз”Ёе®ғпјҢжүҖд»ҘдјҳеҢ–дәҶе®ғд№ӢеҗҺпјҢиҝҷдәӣиҖҒзҡ„д»Јз Ғд№ҹиғҪиҺ·еҫ—жҖ§иғҪжҸҗеҚҮгҖӮ



зӣёе…іжҺЁиҚҗ
еҹәдәҺMaxwellи®ҫи®Ўзҡ„з»Ҹе…ё280W 4025RPMй«ҳж•ҲзҺҮз§‘е°”ж‘©ж №12жһҒ39ж§ҪTBMж— жЎҶеҠӣзҹ©з”өжңәпјҡз”ҹдә§дёҺеӯҰд№ еҸҢйҮҚеә”з”ЁжЎҲдҫӢ,еҹәдәҺMaxwellи®ҫи®Ўзҡ„з»Ҹе…ё280Wй«ҳиҪ¬йҖҹз§‘е°”ж‘©ж №TBMж— жЎҶеҠӣзҹ©з”өжңәпјҡ7615зі»еҲ—жЎҲдҫӢи§ЈжһҗдёҺеә”з”Ёе®һи·ө,еҹәдәҺmaxwwellи®ҫи®Ўзҡ„з»Ҹе…ё280WпјҢ4025RPM еҶ…иҪ¬еӯҗ з§‘е°”ж‘©ж № 12жһҒ39ж§Ҫ TBMж— жЎҶеҠӣзҹ©з”өжңәпјҢ7615зі»еҲ—гҖӮ иҜҘжЎҲдҫӢеҸҜз”ЁдәҺз”ҹдә§пјҢжҲ–иҖ…еӯҰд№ з”ЁпјҢпјҲ157пјү ,maxwellи®ҫи®Ў; 280W; 4025RPMеҶ…иҪ¬еӯҗ; з§‘е°”ж‘©ж №; 12жһҒ39ж§ҪTBMж— жЎҶеҠӣзҹ©з”өжңә; 7615зі»еҲ—; з”ҹдә§/еӯҰд№ з”ЁгҖӮ,еҹәдәҺMaxwellи®ҫи®ЎпјҢй«ҳеҠҹзҺҮ280W 12жһҒ39ж§ҪTBMж— жЎҶеҠӣзҹ©з”өжңәпјҡз”ҹдә§дёҺеӯҰд№ еҸҢз”ЁйҖ”жЎҲдҫӢ
еҹәдәҺзўідәӨжҳ“зҡ„еҫ®зҪ‘дјҳеҢ–жЁЎеһӢзҡ„Matlabи®ҫи®ЎдёҺе®һзҺ°зӯ–з•ҘеҲҶжһҗ,еҹәдәҺзўідәӨжҳ“зҡ„еҫ®зҪ‘дјҳеҢ–жЁЎеһӢзҡ„Matlabи®ҫи®ЎдёҺе®һзҺ°жҺўи®Ё,иҖғиҷ‘зўідәӨжҳ“зҡ„еҫ®зҪ‘дјҳеҢ–жЁЎеһӢmatlab ,иҖғиҷ‘зўідәӨжҳ“; еҫ®зҪ‘дјҳеҢ–жЁЎеһӢ; MATLAB;,еҹәдәҺMatlabзҡ„зўідәӨжҳ“еҫ®зҪ‘дјҳеҢ–жЁЎеһӢз ”з©¶
дәҢзә§2025жЁЎжӢҹиҜ•йўҳпјҲзӯ”жЎҲзүҲпјү
OpenCVжҳҜдёҖдёӘеҠҹиғҪејәеӨ§зҡ„и®Ўз®—жңәи§Ҷи§үеә“пјҢе®ғжҸҗдҫӣдәҶеӨҡз§Қе·Ҙе…·е’Ңз®—жі•жқҘеӨ„зҗҶеӣҫеғҸе’Ңи§Ҷйў‘ж•°жҚ®гҖӮеңЁC++дёӯпјҢOpenCVеҸҜд»Ҙз”ЁдәҺе®һзҺ°еҹәзЎҖзҡ„дәәи„ёиҜҶеҲ«еҠҹиғҪпјҢеҢ…жӢ¬д»Һж‘„еғҸеӨҙгҖҒеӣҫзүҮе’Ңи§Ҷйў‘дёӯиҜҶеҲ«дәәи„ёпјҢд»ҘеҸҠйҖҡиҝҮPCAпјҲдё»жҲҗеҲҶеҲҶжһҗпјүжҸҗеҸ–еӣҫеғҸиҪ®е»“гҖӮд»ҘдёӢжҳҜеҜ№жң¬иө„жәҗеӨ§дҪ“зҡ„д»Ӣз»Қпјҡ 1. д»Һж‘„еғҸеӨҙдёӯиҜҶеҲ«дәәи„ёпјҡйҖҡиҝҮдҪҝз”ЁOpenCVзҡ„Haarзү№еҫҒеҲҶзұ»еҷЁпјҢжҲ‘们еҸҜд»Ҙе®һж—¶д»Һж‘„еғҸеӨҙжҚ•иҺ·зҡ„и§Ҷйў‘жөҒдёӯжЈҖжөӢдәәи„ёгҖӮиҝҷдёӘиҝҮзЁӢж¶үеҸҠеҲ°е°Ҷи§Ҷйў‘её§иҪ¬жҚўдёәзҒ°еәҰеӣҫеғҸпјҢ然еҗҺдҪҝз”Ёйў„и®ӯз»ғзҡ„Haarзә§иҒ”еҲҶзұ»еҷЁжқҘиҜҶеҲ«дәәи„ёеҢәеҹҹгҖӮ 2. д»Һи§Ҷйў‘дёӯиҜҶеҲ«еҮәжүҖжңүдәәи„ёе’ҢдәәзңјпјҡеңЁи§Ҷйў‘жөҒдёӯпјҢйҷӨдәҶжЈҖжөӢдәәи„ёпјҢжҲ‘们иҝҳеҸҜд»ҘиҝӣдёҖжӯҘиҜҶеҲ«дәәзңјгҖӮиҝҷйҖҡеёёж¶үеҸҠеҲ°дҪҝз”ЁйўқеӨ–зҡ„Haarзә§иҒ”еҲҶзұ»еҷЁжқҘе®ҡдҪҚдәәзңјеҢәеҹҹпјҢд»ҺиҖҢе®һзҺ°еҜ№дәәи„ёзү№еҫҒзҡ„жӣҙз»ҶиҮҙеҲҶжһҗгҖӮ 3. д»ҺеӣҫзүҮдёӯжЈҖжөӢеҮәдәәи„ёпјҡеҜ№дәҺйқҷжҖҒеӣҫзүҮпјҢOpenCVеҗҢж ·иғҪеӨҹжЈҖжөӢдәәи„ёгҖӮйҖҡиҝҮеҠ иҪҪеӣҫзүҮпјҢиҪ¬жҚўдёәзҒ°еәҰеӣҫпјҢ然еҗҺеә”з”ЁHaarзә§иҒ”еҲҶзұ»еҷЁпјҢжҲ‘们еҸҜд»ҘеңЁеӣҫзүҮдёӯж Үи®°еҮәдәәи„ёзҡ„дҪҚзҪ®гҖӮ 4. PCAжҸҗеҸ–еӣҫеғҸиҪ®е»“пјҡPCAжҳҜдёҖз§Қз»ҹи®Ўж–№жі•пјҢз”ЁдәҺеҲҶжһҗе’Ңи§ЈйҮҠж•°жҚ®дёӯзҡ„жЁЎејҸгҖӮеңЁеӣҫеғҸеӨ„зҗҶдёӯпјҢPCAеҸҜд»Ҙз”ЁжқҘжҸҗеҸ–еӣҫеғҸзҡ„дё»иҰҒиҪ®е»“зү№еҫҒпјҢиҝҷеҜ№дәҺдәәи„ёиҜҶеҲ«жҠҖжңҜдёӯзҡ„йқўйғЁзү№еҫҒжҸҗеҸ–е°Ө
йә»йӣҖжҗңзҙўз®—жі•пјҲSSAпјүиҮӘйҖӮеә”tеҲҶеёғж”№иҝӣзүҲпјҡеҚ“и¶ҠжҖ§иғҪдёҺдјҳеҢ–д»Јз ҒжіЁйҮҠпјҢйҖӮеҗҲж·ұеәҰеӯҰд№ гҖӮ,иҮӘйҖӮеә”tеҲҶеёғж”№иҝӣйә»йӣҖжҗңзҙўз®—жі•пјҲTSSAпјүвҖ”вҖ”еҚ“и¶Ҡзҡ„еӯҰд№ ж ·жң¬пјҢдјҳеҢ–ж•ҲжһңеҮәдј—,йә»йӣҖжҗңзҙўз®—жі•(SSA)ж”№иҝӣвҖ”вҖ”йҮҮз”ЁиҮӘйҖӮеә”tеҲҶеёғж”№иҝӣйә»йӣҖдҪҚзҪ®пјҲTSSAпјүпјҢдјҳеҢ–еҗҺжҳҺжҳҫиҰҒдјҳдәҺеҹәзЎҖSSAпјҲд»Јз Ғеҹәжң¬жҜҸдёҖжӯҘйғҪжңүжіЁйҮҠпјҢд»Јз ҒиҙЁйҮҸжһҒй«ҳпјҢйқһеёёйҖӮеҗҲеӯҰд№ пјү ,TSSAпјҲиҮӘйҖӮеә”tеҲҶеёғйә»йӣҖдҪҚзҪ®з®—жі•пјүпјӣжіЁйҮҠиҜҰе°Ҫпјӣй«ҳиҙЁйҮҸд»Јз ҒпјӣйҖӮеҗҲеӯҰд№ пјӣз®—жі•ж”№иҝӣз»“жһңдјҳејӮпјӣTSSAзӣёжҜ”еҹәзЎҖSSAгҖӮ,иҮӘйҖӮеә”TеҲҶеёғдјҳеҢ–йә»йӣҖжҗңзҙўз®—жі•пјҡд»Јз ҒиҜҰи§ЈдёҺеӯҰд№ йҰ–йҖүпјҲTSSAж”№иҝӣзүҲпјү
й”Ӯз”өжұ дё»еҠЁеқҮиЎЎSimulinkд»ҝзңҹз ”з©¶пјҡеӨҡз§ҚеқҮиЎЎзӯ–з•ҘдёҺз”өи·Ҝжһ¶жһ„зҡ„ж·ұеәҰжҺўи®Ё,й”Ӯз”өжұ дё»еҠЁеқҮиЎЎдёҺеӨҡз§ҚеқҮиЎЎзӯ–з•Ҙзҡ„Simulinkд»ҝзңҹз ”з©¶пјҡbuckboostжӢ“жү‘еҸҠеӨҡеұӮж¬Ўз”өи·ҜеҲҶжһҗ,й”Ӯз”өжұ дё»еҠЁеқҮиЎЎsimulinkд»ҝзңҹ еӣӣиҠӮз”өжұ еҹәдәҺbuckboost(еҚҮйҷҚеҺӢ)жӢ“жү‘ пјҲиҝҳжңүдј з»ҹз”өж„ҹеқҮиЎЎ+ејҖе…із”өе®№еқҮиЎЎ+еҸҢеҗ‘еҸҚжҝҖеқҮиЎЎ+еҸҢеұӮеҮҶи°җжҢҜеқҮиЎЎ+зҺҜеҪўеқҮиЎЎеҷЁ+cuk+иҖҰеҗҲз”өж„ҹпјүиў«еҠЁеқҮиЎЎз”өйҳ»ејҸеқҮиЎЎ гҖҒеҲҶеұӮжһ¶жһ„ејҸеқҮиЎЎд»ҘеҸҠеҲҶеұӮејҸз”өи·ҜеқҮиЎЎпјҢеӨҡеұӮж¬Ўз”өи·ҜпјҢе……ж”ҫз”өгҖӮ ,ж ёеҝғе…ій”®иҜҚпјҡ й”Ӯз”өжұ ; дё»еҠЁеқҮиЎЎ; Simulinkд»ҝзңҹ; еӣӣиҠӮз”өжұ ; BuckBoostжӢ“жү‘; дј з»ҹз”өж„ҹеқҮиЎЎ; ејҖе…із”өе®№еқҮиЎЎ; еҸҢеҗ‘еҸҚжҝҖеқҮиЎЎ; еҸҢеұӮеҮҶи°җжҢҜеқҮиЎЎ; зҺҜеҪўеқҮиЎЎеҷЁ; CUKеқҮиЎЎ; иҖҰеҗҲз”өж„ҹеқҮиЎЎ; иў«еҠЁеқҮиЎЎ; з”өйҳ»ејҸеқҮиЎЎ; еҲҶеұӮжһ¶жһ„ејҸеқҮиЎЎ; еӨҡеұӮж¬Ўз”өи·Ҝ; е……ж”ҫз”өгҖӮ,й”Ӯз”өжұ еқҮиЎЎзӯ–з•Ҙз ”з©¶пјҡSimulinkд»ҝзңҹдёӢзҡ„еӨҡжӢ“жү‘дё»еҠЁдёҺиў«еҠЁеқҮиЎЎжҠҖжңҜ
S7-1500е’ҢеҲҶеёғејҸеӨ–еӣҙзі»з»ҹET200MPжЁЎеқ—ж•°жҚ®
еҶ…зҪ®ејҸж°ёзЈҒеҗҢжӯҘз”өжңәж— дҪҚзҪ®дј ж„ҹеҷЁжЁЎеһӢпјҡеҹәдәҺж»‘иҶңи§ӮжөӢеҷЁе’ҢMTPAжҠҖжңҜзҡ„ж·ұеәҰжҺўз©¶,еҶ…зҪ®ејҸж°ёзЈҒеҗҢжӯҘз”өжңәеҹәдәҺж»‘иҶңи§ӮжөӢеҷЁе’ҢMTPAзҡ„ж— дҪҚзҪ®дј ж„ҹеҷЁжЁЎеһӢз ”з©¶,еҹәдәҺж»‘иҶңи§ӮжөӢеҷЁе’ҢMTPAзҡ„еҶ…зҪ®ејҸж°ёзЈҒеҗҢжӯҘз”өжңәж— дҪҚзҪ®дј ж„ҹеҷЁжЁЎеһӢ ,еҹәдәҺж»‘иҶңи§ӮжөӢеҷЁ;MTPA;еҶ…зҪ®ејҸж°ёзЈҒеҗҢжӯҘз”өжңә;ж— дҪҚзҪ®дј ж„ҹеҷЁжЁЎеһӢ,еҹәдәҺж»‘иҶңи§ӮжөӢдёҺMTPAз®—жі•зҡ„ж°ёзЈҒеҗҢжӯҘз”өжңәж— дҪҚзҪ®дј ж„ҹеҷЁжЁЎеһӢ
centos7ж“ҚдҪңзі»з»ҹдёӢе®үиЈ…dockerпјҢеҸҠdockerеёёз”Ёе‘Ҫд»ӨгҖҒеңЁdockerдёӯиҝҗиЎҢnginxзӨәдҫӢпјҢеҢ…жӢ¬ 1.и®ҫзҪ®yumзҡ„д»“еә“ 2.е®үиЈ… Docker Engine-Community 3.dockerдҪҝз”Ё 4.жҹҘзңӢdockerиҝӣзЁӢжҳҜеҗҰеҗҜеҠЁжҲҗеҠҹ 5.dockerеёёз”Ёе‘Ҫд»ӨеҸҠnginxзӨәдҫӢ 6.еёёи§Ғй—®йўҳ
з»ҷжӣҷе…үжңҚеҠЎеҷЁе®үиЈ…windows2012r2ж—¶еҖҷжүҫдёҚеҲ°зЈҒзӣҳпјҢй—®еҺӮ家е·ҘзЁӢеёҲиҰҒзҡ„raidеҚЎй©ұеҠЁпјҢеҶ…еҗ«дё»жөҒеӨ§еӨҡж•°е“ҒзүҢraidеҚЎй©ұеҠЁ
ж•°еӯҰе»әжЁЎзӣёе…ідё»йўҳиө„жәҗ2
иҘҝй—ЁеӯҗеӣӣиҪҙеҚ§ејҸеҠ е·ҘдёӯеҝғеҗҺеӨ„зҗҶзі»з»ҹпјҡ828DиҮі840Dж”ҜжҢҒпјҢеӣӣиҪҙиҒ”еҠЁеҲ¶йҖ и§ЈеҶіж–№жЎҲпјҢеӣҫжЎЈеӨ„зҗҶдёҺиҜ•зңӢзЁӢеәҸдёҖеә”дҝұе…ЁгҖӮ,иҘҝй—ЁеӯҗеӣӣиҪҙеҚ§еҠ еҗҺеӨ„зҗҶзі»з»ҹпјҡж”ҜжҢҒ828DиҮі840Dзі»з»ҹпјҢеӣӣиҪҙиҒ”еҠЁй«ҳзІҫеәҰеҲ¶йҖ и§ЈеҶіж–№жЎҲ,иҘҝй—ЁеӯҗеӣӣиҪҙеҚ§еҠ еҗҺеӨ„зҗҶпјҢж”ҜжҢҒ828D~840Dзі»з»ҹпјҢж”ҜжҢҒеӣӣиҪҙиҒ”еҠЁпјҢеҸҜеҲ¶еҲ¶пјҢзңӢжё…жҘҡиҒ”зі»пјҢеҸҜжҸҗдҫӣеӣҫжЎЈеӨ„зҗҶиҜ•зңӢзЁӢеәҸ ,ж ёеҝғе…ій”®иҜҚпјҡиҘҝй—ЁеӯҗеӣӣиҪҙеҚ§еҠ еҗҺеӨ„зҗҶ; 828D~840Dзі»з»ҹж”ҜжҢҒ; еӣӣиҪҙиҒ”еҠЁ; еҲ¶зЁӢ; иҒ”зі»; еӣҫжЎЈеӨ„зҗҶиҜ•зңӢзЁӢеәҸгҖӮ,иҘҝй—ЁеӯҗеӣӣиҪҙеҚ§еҠ еҗҺеӨ„зҗҶзЁӢеәҸпјҢж”ҜжҢҒеӨҡз§Қзі»з»ҹдёҺеӣӣиҪҙиҒ”еҠЁ
MATLABдёӢеҹәдәҺеҲ—зәҰжқҹз”ҹжҲҗжі•CCGзҡ„дёӨйҳ¶ж®өйІҒжЈ’дјҳеҢ–й—®йўҳжұӮи§Је…Ҙй—ЁжҢҮеҚ—пјҡз®—жі•йӘҢиҜҒдёҺз»Ҹе…ёж–ҮзҢ®еҸӮиҖғ,MATLABдёӢеҹәдәҺеҲ—зәҰжқҹз”ҹжҲҗжі•CCGзҡ„дёӨйҳ¶ж®өйІҒжЈ’дјҳеҢ–й—®йўҳжұӮи§Је…Ҙй—ЁжҢҮеҚ—пјҡз®—жі•йӘҢиҜҒдёҺж–ҮзҢ®еҸӮиҖғ,MATLABд»Јз ҒпјҡеҹәдәҺеҲ—зәҰжқҹз”ҹжҲҗжі•CCGзҡ„дёӨйҳ¶ж®өй—®йўҳжұӮи§Ј е…ій”®иҜҚпјҡдёӨйҳ¶ж®өйІҒжЈ’ еҲ—зәҰжқҹз”ҹжҲҗжі• CCGз®—жі• еҸӮиҖғж–ҮжЎЈпјҡгҖҠSolving two-stage robust optimization problems using a column-and-constraint generation methodгҖӢ д»ҝзңҹе№іеҸ°пјҡMATLAB YALMIP+CPLEX дё»иҰҒеҶ…е®№пјҡд»Јз Ғжһ„е»әдәҶдёӨйҳ¶ж®өйІҒжЈ’дјҳеҢ–жЁЎеһӢпјҢ并用ж–ҮжЎЈдёӯзҡ„зӣёеҜ№з®ҖеҚ•зҡ„з®—дҫӢпјҢиҝӣиЎҢCCGз®—жі•зҡ„йӘҢиҜҒпјҢжӯӨзҜҮж–ҮзҢ®жҳҜCCGз®—жі•жҲ–иҖ…еҲ—зәҰжқҹз”ҹжҲҗз®—жі•зҡ„е…Ҙй—Ёзә§ж–ҮзҢ®пјҢе…¶з»Ҹе…ёзЁӢеәҰдёҚиЁҖиҖҢе–»пјҢеҮ д№ҺжҜҸдёӘжҗһCCGзҡ„дёӨйҳ¶ж®өйІҒжЈ’зҡ„дәәйғҪз»•дёҚиҝҮжӯӨзҜҮж–ҮзҢ® ,дёӨйҳ¶ж®өйІҒжЈ’;еҲ—зәҰжқҹз”ҹжҲҗжі•;CCGз®—жі•;MATLAB;YALMIP+CPLEX;е…Ҙй—Ёзә§ж–ҮзҢ®гҖӮ,MATLABд»Јз Ғе®һзҺ°пјҡеҹәдәҺдёӨйҳ¶ж®өйІҒжЈ’дёҺеҲ—зәҰжқҹз”ҹжҲҗжі•CCGзҡ„з®—жі•йӘҢиҜҒз ”з©¶
вҖңз”ҹзғӯз ”з©¶зҡ„е…Ёйқўи§ЈиҜ»пјҡжҺўз©¶еҸӮж•°е·Ій…ҚзҪ®зҡ„ComsolжЁЎеһӢдёӯзҡ„18650еңҶжҹұй”Ӯз”өжұ иЎЁзҺ°вҖқ,жҺўз©¶е·Ій…ҚзҪ®еҸӮж•°зҡ„COMSOLжЁЎеһӢдёӢзҡ„й”Ӯз”өжұ з”ҹзғӯзҺ°иұЎпјҡ18650еңҶжҹұй”Ӯз”өжұ жЁЎжӢҹеҲҶжһҗ,еҮәдёҖдёӘ18650еңҶжҹұй”Ӯз”өжұ comsolжЁЎеһӢ еҸӮж•°е·Ій…ҚзҪ®пјҢз”ҹзғӯз ”з©¶ ,еҮәжЁЎеһӢ; 18650еңҶжҹұй”Ӯз”өжұ ; comsolжЁЎеһӢ; еҸӮж•°й…ҚзҪ®; з”ҹзғӯз ”з©¶,жһ„е»ә18650з”өжұ зҡ„COMSOLзғӯз ”з©¶жЁЎеһӢ
移еҠЁз«ҜеӨҡз«ҜиҝҗиЎҢзҡ„зҹҘиҜҶд»ҳиҙ№з®ЎзҗҶзі»з»ҹжәҗз ҒпјҢTP6+Layui+MySQLеҗҺз«Ҝж”ҜжҢҒпјҢеҠҹиғҪдё°еҜҢпјҢж¶өзӣ–зӣҙж’ӯгҖҒзӮ№ж’ӯгҖҒз®ЎзҗҶе…ЁеҠҹиғҪеҸҠзӨјзү©дә’еҠЁ,еҹәдәҺUniAppи·Ёе№іеҸ°ејҖеҸ‘зҡ„移еҠЁз«ҜзҹҘиҜҶд»ҳиҙ№з®ЎзҗҶзі»з»ҹжәҗз ҒпјҡеӨҡз«Ҝдә’йҖҡгҖҒе…ЁеҠҹиғҪйҪҗеӨҮгҖҒеҗҺз«ҜйҮҮз”ЁTP6дёҺPHPеҸҠLayuiеүҚз«ҜпјҢжҗӯиҪҪMySQLж•°жҚ®еә“дёҺзӣҙж’ӯгҖҒзӮ№ж’ӯгҖҒз®ЎзҗҶгҖҒзӨјзү©зӯүеҠҹиғҪзҡ„ејәеӨ§ж•ҙеҗҲгҖӮ,зҹҘиҜҶд»ҳиҙ№з®ЎзҗҶзі»з»ҹжәҗз ҒпјҢ移еҠЁз«ҜuniAppејҖеҸ‘пјҢapp h5 е°ҸзЁӢеәҸдёҖеҘ—д»Јз ҒеӨҡз«ҜиҝҗиЎҢпјҢеҗҺз«ҜphpпјҲtp6пјү+layui+MySQLпјҢеҠҹиғҪйҪҗе…ЁпјҢзӣҙж’ӯпјҢзӮ№ж’ӯпјҢз®ЎзҗҶпјҢзӨјзү©зӯүзӯүеҠҹиғҪеә”жңүе°Ҫжңү ,зҹҘиҜҶд»ҳиҙ№;з®ЎзҗҶзі»з»ҹжәҗз Ғ;移еҠЁз«ҜuniAppејҖеҸ‘;еӨҡз«ҜиҝҗиЎҢ;еҗҺз«Ҝphp(tp6);layui;MySQL;зӣҙж’ӯзӮ№ж’ӯ;з®ЎзҗҶеҠҹиғҪ;зӨјзү©еҠҹиғҪ,зҹҘиҜҶд»ҳиҙ№з®ЎзҗҶе№іеҸ°пјҡе…ЁеҠҹиғҪеӨҡз«ҜиҝҗиЎҢзі»з»ҹжәҗз ҒпјҲPHP+Layui+MySQLпјү
еҹәдәҺPython+Django+MySQLзҡ„дёӘжҖ§еҢ–еӣҫд№ҰжҺЁиҚҗзі»з»ҹпјҡеҚҸеҗҢиҝҮж»ӨжҺЁиҚҗпјҢжҷәиғҪйғЁзҪІпјҢз”ЁжҲ·е®ҡеҲ¶еҠҹиғҪ,еҹәдәҺPython+Django+MySQLзҡ„дёӘжҖ§еҢ–еӣҫд№ҰжҺЁиҚҗзі»з»ҹпјҡеҚҸеҗҢиҝҮж»ӨжҺЁиҚҗпјҢжҷәиғҪйғЁзҪІпјҢз”ЁжҲ·е®ҡеҲ¶еҠҹиғҪ,Python+Django+MysqlдёӘжҖ§еҢ–еӣҫд№ҰжҺЁиҚҗзі»з»ҹ еӣҫд№ҰеңЁзәҝжҺЁиҚҗзі»з»ҹ еҹәдәҺз”ЁжҲ·гҖҒйЎ№зӣ®гҖҒеҶ…е®№зҡ„еҚҸеҗҢиҝҮж»ӨжҺЁиҚҗз®—жі•гҖӮ её®иҝңзЁӢе®үиЈ…йғЁзҪІ дёҖгҖҒйЎ№зӣ®з®Җд»Ӣ 1гҖҒејҖеҸ‘е·Ҙе…·е’Ңе®һзҺ°жҠҖжңҜ Python3.8пјҢDjango4пјҢmysql8пјҢnavicatж•°жҚ®еә“з®ЎзҗҶе·Ҙе…·пјҢhtmlйЎөйқўпјҢjavascriptи„ҡжң¬пјҢjqueryи„ҡжң¬пјҢbootstrapеүҚз«ҜжЎҶжһ¶пјҢlayerеј№зӘ—组件гҖҒwebuploaderж–Ү件дёҠдј з»„д»¶зӯүгҖӮ 2гҖҒйЎ№зӣ®еҠҹиғҪ еүҚеҸ°з”ЁжҲ·еҢ…еҗ«пјҡжіЁеҶҢгҖҒзҷ»еҪ•гҖҒжіЁй”ҖгҖҒжөҸи§Ҳеӣҫд№ҰгҖҒжҗңзҙўеӣҫд№ҰгҖҒдҝЎжҒҜдҝ®ж”№гҖҒеҜҶз Ғдҝ®ж”№гҖҒе…ҙи¶Је–ңеҘҪж ҮзӯҫгҖҒеӣҫд№ҰиҜ„еҲҶгҖҒеӣҫд№Ұ收и—ҸгҖҒеӣҫд№ҰиҜ„и®әгҖҒзғӯзӮ№жҺЁиҚҗгҖҒдёӘжҖ§еҢ–жҺЁиҚҗеӣҫд№ҰзӯүеҠҹиғҪпјӣ еҗҺеҸ°з®ЎзҗҶе‘ҳеҢ…еҗ«пјҡз”ЁжҲ·з®ЎзҗҶгҖҒеӣҫд№Ұз®ЎзҗҶгҖҒеӣҫд№Ұзұ»еһӢз®ЎзҗҶгҖҒиҜ„еҲҶз®ЎзҗҶгҖҒ收и—Ҹз®ЎзҗҶгҖҒиҜ„и®әз®ЎзҗҶгҖҒе…ҙи¶Је–ңеҘҪж Үзӯҫз®ЎзҗҶгҖҒжқғйҷҗз®ЎзҗҶзӯүгҖӮ дёӘжҖ§еҢ–жҺЁиҚҗеҠҹиғҪпјҡ ж— и®әжҳҜеҗҰзҷ»еҪ•пјҢеңЁеүҚеҸ°йҰ–йЎөеұ•зӨәзғӯзӮ№жҺЁиҚҗпјҲж №жҚ®еӣҫд№Ұ被收и—Ҹж•°йҮҸйҷҚеәҸжҺЁиҚҗпјүгҖӮ зҷ»еҪ•з”ЁжҲ·пјҢеңЁеүҚеҸ°йҰ–йЎөеұ•зӨәдёӘжҖ§еҢ–жҺЁиҚҗ
STM32дјҒдёҡзә§й”…зӮүжҺ§еҲ¶еҷЁжәҗз ҒеҲҶдә«пјҡзңҹе®һйЎ№зӣ®з»ҸйӘҢпјҢеёҰжіЁйҮҠе®Ңж•ҙжәҗз ҒеҠ©дҪ еҝ«йҖҹжҺҢжҸЎе®һжҲҳз»ҸйӘҢ,STM32дјҒдёҡзә§й”…зӮүжҺ§еҲ¶еҷЁжәҗз Ғпјҡзңҹе®һйЎ№зӣ®з»ҸйӘҢпјҢе®Ңж•ҙжіЁйҮҠпјҢеҠ©еҠӣеҲқеӯҰиҖ…еҝ«йҖҹдёҠжүӢ,stm32зңҹе®һдјҒдёҡйЎ№зӣ®жәҗз Ғ йЎ№зӣ®иҰҒжұӮдёҺзҪ‘дёҠжҗңзҡ„йӮЈдәӣејҖеҸ‘жқҝзҡ„дҫӢзЁӢе®Ңе…ЁдёҚеңЁдёҖдёӘзә§еҲ«пјҢд№ҹдёҚжҳҜйӮЈдәӣеҮ‘еҗҲжҖ§иҙЁзҡ„йЎ№зӣ®еҸҜд»ҘжҜ”жӢҹзҡ„гҖӮ йЎ№зӣ®жҳҜдјҒдёҡзә§дә§е“Ғзҡ„иҰҒжұӮејҖеҸ‘зҡ„пјҢиғҪеӨҹи®©еҲқеӯҰиҖ…дәҶи§Јзңҹе®һзҡ„дјҒдёҡйЎ№зӣ®жҳҜжҖҺд№Ҳж ·зҡ„пјҢеўһеҠ е·ҘдҪңз»ҸйӘҢ дјҒдёҡзңҹе®һйЎ№зӣ®зҪ‘дёҠзЁҖзјәпјҢе®Ңж•ҙжәҗз ҒеёҰжіЁйҮҠпјҢйҖӮеҗҲжІЎжңүеҸӮдёҺе·ҘдҪңжҲ–иҖ…еҲҡеӯҰstm32зҡ„еўһеҠ е·ҘдҪңз»ҸйӘҢпјҢ иҝҷжҳҜдёҖдёӘй”…зӮүзҡ„жҺ§еҲ¶еҷЁпјҢжңүжөҒзЁӢеӣҫе’ҢзЁӢеәҸеҚҸи®®зҡ„д»Ӣз»ҚгҖӮ ,stm32жәҗз Ғ;дјҒдёҡзә§йЎ№зӣ®;е·ҘдҪңз»ҸйӘҢ;й”…зӮүжҺ§еҲ¶еҷЁ;жөҒзЁӢеӣҫ;зЁӢеәҸеҚҸи®®,еҹәдәҺSTM32зҡ„зңҹе®һдјҒдёҡзә§й”…зӮүжҺ§еҲ¶еҷЁйЎ№зӣ®жәҗз Ғ
ж•ҙиҪҰжҖ§иғҪзӣ®ж Үд№Ұпјҡж¶өзӣ–зҮғжІ№иҪҰгҖҒж··еҠЁиҪҰеҸҠзәҜз”өеҠЁиҪҰеһӢзҡ„еҚҒе…ӯдёӘжҖ§иғҪжЁЎеқ—зӣ®ж Үе®ҡд№үжЁЎжқҝдёҺйӣҶжҲҗејҖеҸ‘жҢҮеҚ—,ж•ҙиҪҰжҖ§иғҪзӣ®ж Үд№Ұпјҡж¶өзӣ–зҮғжІ№иҪҰгҖҒж··еҠЁиҪҰеҸҠзәҜз”өеҠЁиҪҰеһӢзҡ„еҚҒе…ӯдёӘжҖ§иғҪжЁЎеқ—зӣ®ж Үе®ҡд№үжЁЎжқҝдёҺйӣҶжҲҗејҖеҸ‘жҢҮеҚ—,ж•ҙиҪҰжҖ§иғҪзӣ®ж Үд№ҰпјҢжұҪиҪҰжҖ§иғҪзӣ®ж Үд№ҰпјҢеҚҒе…ӯдёӘжҖ§иғҪжЁЎеқ—зӣ®ж Үе®ҡд№үжЁЎжқҝпјҢеҢ…еҗ«зҮғжІ№иҪҰгҖҒж··еҠЁиҪҰеһӢеҸҠзәҜз”өеҠЁиҪҰеһӢгҖӮ еҜ№дәҺж•ҙиҪҰжҖ§иғҪзҡ„йӣҶжҲҗејҖеҸ‘е…·жңүиҫғй«ҳзҡ„еҸӮиҖғд»·еҖј ,ж•ҙиҪҰжҖ§иғҪзӣ®ж Үд№Ұ;жұҪиҪҰжҖ§иғҪзӣ®ж Үд№Ұ;жҖ§иғҪжЁЎеқ—зӣ®ж Үе®ҡд№үжЁЎжқҝ;зҮғжІ№иҪҰ;ж··еҠЁиҪҰеһӢ;зәҜз”өеҠЁиҪҰеһӢ;йӣҶжҲҗејҖеҸ‘;еҸӮиҖғд»·еҖј,гҖҠжұҪиҪҰжҖ§иғҪжЁЎеқ—еҢ–зӣ®ж Үд№ҰпјҡзҮғжІ№иҪҰгҖҒж··еҠЁиҪҰеҸҠзәҜз”өеҠЁиҪҰзҡ„йӣҶжҲҗејҖеҸ‘еҸӮиҖғгҖӢ
SNMPеҚҸи®®жөӢиҜ•е·Ҙе…·пјҢи§ЈеҺӢпјҡ000000
еҹәдәҺMATLABдёҺYALMIPзҡ„еҗ«еҲҶеёғејҸдёҺеӮЁиғҪзҡ„еҫ®зҪ‘дјҳеҢ–и°ғеәҰжЁЎеһӢпјҡзІҫеҮҶйҮҮйӣҶдёҺй«ҳж•ҲжұӮи§Ј,еҲ©з”ЁMATLABе’ҢYALMIPжһ„е»әеҗ«еҲҶеёғејҸдёҺеӮЁиғҪзҡ„еҫ®зҪ‘дјҳеҢ–жЁЎеһӢпјҢе®һзҺ°зІҫеҮҶи°ғеәҰдёҺзәҰжқҹз®ЎзҗҶ,еҫ®зҪ‘дјҳеҢ–и°ғеәҰmatlab йҮҮз”Ёmatlab+yalmipзј–еҲ¶еҗ«еҲҶеёғејҸе’ҢеӮЁиғҪзҡ„еҫ®зҪ‘дјҳеҢ–жЁЎеһӢпјҢзЁӢеәҸйҮҮз”Ё15еҲҶй’ҹдёәйҮҮйӣҶиҠӮзӮ№пјҢеҲ©з”ЁcplexжұӮи§ЈпјҢзЁӢеәҸиҖғиҷ‘еҸ‘з”өжңәзҡ„еҗҜеҒңзәҰжқҹпјҢзЁӢеәҸиҝҗиЎҢеҸҜйқ ,еҫ®зҪ‘дјҳеҢ–и°ғеәҰ; MATLABзј–зЁӢ; YALMIP; еҲҶеёғејҸеӮЁиғҪ; дјҳеҢ–жЁЎеһӢ; CPLXжұӮи§Ј; иҠӮзӮ№йҮҮйӣҶ; еҸ‘з”өжңәзәҰжқҹгҖӮ,MatlabдёӢзҡ„еҫ®зҪ‘дјҳеҢ–и°ғеәҰжЁЎеһӢпјҡеҲҶеёғејҸеӮЁиғҪеҚҸеҗҢCplexжұӮи§ЈзЁӢеәҸ