- وµڈ览: 914560 و¬،
- و€§هˆ«:

- و¥è‡ھ: هŒ—ن؛¬
-

و–‡ç« هˆ†ç±»
- ه…¨éƒ¨هچڑه®¢ (537)
- Java SE (114)
- Struts (18)
- Hibernate (25)
- Spring (3)
- Page_Tech (41)
- Others (87)
- Database (29)
- Server (24)
- OpenSource_Tools (15)
- IDE_Tool (22)
- Algorithm (28)
- Interview (22)
- Test (28)
- Hardware (1)
- Mainframe (25)
- Web application (4)
- Linux (3)
- PHP (17)
- Android (1)
- Perl (6)
- ubuntu (1)
- Java EE (9)
- Web Analysis (5)
- Node.js (2)
- javascript (2)
社هŒ؛版ه—
- وˆ‘çڑ„资讯 ( 0)
- وˆ‘çڑ„è®؛ه› ( 0)
- وˆ‘çڑ„é—®ç” ( 0)
هکو،£هˆ†ç±»
- 2014-12 ( 1)
- 2014-11 ( 1)
- 2014-10 ( 1)
- و›´ه¤ڑهکو،£...
وœ€و–°è¯„è®؛
-
ن¸€é”®و³¨ه†Œï¼ڑ
آ
request.getRequestURL()ه’Œrequest.getRequestURI() -
SuperCustomerï¼ڑ
...
SEDçڑ„وڑ‚هکç©؛é—´ه’Œو¨،ه¼ڈç©؛é—´ -
juyo_chï¼ڑ
讲ه¾—وŒ؛ه¥½çگ†è§£çڑ„,ه¦ن¹ ن؛†
java و»é”پهڈٹ解ه†³ -
chinaalexï¼ڑ
وœ€هگژن¸€é¢کç”و،ˆو£ç،®ï¼Œن½†وک¯هˆ†وگوœ‰è¯¯.وŒ‰ç…§ه¦‚ن¸‹è؟‡ç¨‹ï¼Œن¸ٹن¸€è،Œن¸؛瓶,ن¸‹ن¸€ ...
zzو™؛هٹ›é¢ک -
liaowuxukongï¼ڑ
ه¤ڑè°¢هچڑن¸»ه•¦ï¼Œه¼±ه¼±çڑ„ن؛†è§£ن؛†ن¸€ç‚¹م€‚
C++/Java ه®çژ°ه¤ڑو€پçڑ„و–¹و³•ï¼ˆC++)
URLو±‰ه—ç¼–ç پé—®é¢ک(هڈٹن¹±ç پ解ه†³ï¼‰
- هچڑه®¢هˆ†ç±»ï¼ڑ
- Others
é،µé¢ن¸¤و¬،转ç پï¼ڑencodeURI(encodeURI(Ext.get('drug_id').dom.value))
java里解ç پï¼ڑjava.net.URLDecoder.decode(request
.getParameter("drug_id"), "UTF-8")
ن¸€م€پé—®é¢کçڑ„ç”±و¥
URLه°±وک¯ç½‘ه€ï¼Œهڈھè¦پن¸ٹ网,ه°±ن¸€ه®ڑن¼ڑ用هˆ°م€‚

ن¸€èˆ¬و¥è¯´ï¼ŒURLهڈھ能ن½؟用英و–‡ه—و¯چم€پéک؟و‹‰ن¼¯و•°ه—ه’Œوںگن؛›و ‡ç‚¹ç¬¦هڈ·ï¼Œن¸چ能ن½؟用ه…¶ن»–و–‡ه—ه’Œç¬¦هڈ·م€‚و¯”ه¦‚,ن¸–ç•Œن¸ٹوœ‰è‹±و–‡ه—و¯چçڑ„网ه€ “http://www.abc.comâ€ï¼Œن½†وک¯و²،وœ‰ه¸Œè…ٹه—و¯چçڑ„网ه€â€œhttp://www.aخ²خ³.comâ€ï¼ˆè¯»ن½œéک؟ه°”و³•-è´ه،”-ن¼½çژ›.com)م€‚è؟™وک¯ه› ن¸؛网络و ‡ه‡†RFC 1738 هپڑن؛†ç،¬و€§è§„ه®ڑï¼ڑ
"...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL."
“هڈھوœ‰ه—و¯چه’Œو•°ه—[0-9a-zA-Z]م€پن¸€ن؛›ç‰¹و®ٹ符هڈ·â€œ$-_.+!*'(),â€[ن¸چهŒ…و‹¬هڈŒه¼•هڈ·]م€پن»¥هڈٹوںگن؛›ن؟ç•™ه—,و‰چهڈ¯ن»¥ن¸چç»ڈè؟‡ç¼–ç پç›´وژ¥ç”¨ن؛ژ URLم€‚â€
è؟™و„ڈه‘³ç€ï¼Œه¦‚وœURLن¸وœ‰و±‰ه—,ه°±ه؟…é،»ç¼–ç پهگژن½؟用م€‚ن½†وک¯é؛»çƒ¦çڑ„وک¯ï¼ŒRFC 1738و²،وœ‰è§„ه®ڑه…·ن½“çڑ„ç¼–ç پو–¹و³•ï¼Œè€Œوک¯ن؛¤ç»™ه؛”用程ه؛ڈ(وµڈ览ه™¨ï¼‰è‡ھه·±ه†³ه®ڑم€‚è؟™ه¯¼è‡´â€œURLç¼–ç پâ€وˆگن¸؛ن؛†ن¸€ن¸ھو··ن¹±çڑ„领هںںم€‚
ن¸‹é¢ه°±è®©وˆ‘ن»¬çœ‹çœ‹ï¼Œâ€œURLç¼–ç پâ€هˆ°ه؛•وœ‰ه¤ڑو··ن¹±م€‚وˆ‘ن¼ڑن¾و¬،هˆ†وگه››ç§چن¸چهگŒçڑ„وƒ…ه†µï¼Œهœ¨و¯ڈن¸€ç§چوƒ…ه†µن¸ï¼Œوµڈ览ه™¨çڑ„URLç¼–ç پو–¹و³•éƒ½ن¸چن¸€و ·م€‚وٹٹه®ƒن»¬çڑ„ه·®ه¼‚解é‡ٹو¸…و¥ڑن¹‹هگژ,وˆ‘ه†چ说ه¦‚ن½•ç”¨Javascriptو‰¾هˆ°ن¸€ن¸ھç»ںن¸€çڑ„ç¼–ç پو–¹و³•م€‚
ن؛Œم€پوƒ…ه†µ1ï¼ڑ网ه€è·¯ه¾„ن¸هŒ…هگ«و±‰ه—
و‰“ه¼€IE(وˆ‘用çڑ„وک¯8.0版),输ه…¥ç½‘ه€â€œhttp://zh.wikipedia.org/wiki/وک¥èٹ‚ â€م€‚و³¨و„ڈ,“وک¥èٹ‚â€è؟™ن¸¤ن¸ھه—و¤و—¶وک¯ç½‘ه€è·¯ه¾„çڑ„ن¸€éƒ¨هˆ†م€‚

وں¥çœ‹HTTP请و±‚çڑ„ه¤´ن؟،وپ¯ï¼Œن¼ڑهڈ‘çژ°IEه®é™…وں¥è¯¢çڑ„网ه€وک¯â€œhttp://zh.wikipedia.org/wiki/%E6%98%A5%E8%8A%82 â€م€‚ن¹ںه°±وک¯è¯´ï¼ŒIEè‡ھهٹ¨ه°†â€œوک¥èٹ‚â€ç¼–ç پوˆگن؛†â€œ%E6%98%A5%E8%8A%82â€م€‚
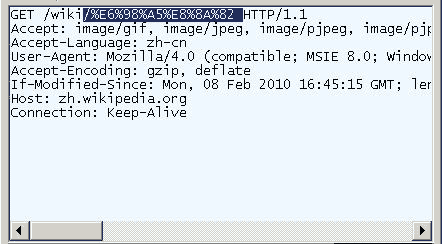
وˆ‘ن»¬çں¥éپ“,“وک¥â€ه’Œâ€œèٹ‚â€çڑ„utf-8ç¼–ç پهˆ†هˆ«وک¯â€œE6 98 A5â€ه’Œâ€œE8 8A 82â€ï¼Œه› و¤ï¼Œâ€œ%E6%98%A5%E8%8A%82â€ه°±وک¯وŒ‰ç…§é،؛ه؛ڈ,هœ¨و¯ڈن¸ھه—èٹ‚ه‰چهٹ ن¸ٹ%而ه¾—هˆ°çڑ„م€‚(ه…·ن½“çڑ„转ç پو–¹و³•ï¼Œè¯·هڈ‚考وˆ‘ه†™çڑ„م€ٹه—符编ç پ笔记م€‹ م€‚)
هœ¨Firefoxن¸وµ‹è¯•ï¼Œن¹ںه¾—هˆ°ن؛†هگŒو ·çڑ„结وœم€‚و‰€ن»¥ï¼Œç»“è®؛1ه°±وک¯ï¼Œç½‘ه€è·¯ه¾„çڑ„ç¼–ç پ,用çڑ„وک¯utf-8ç¼–ç پم€‚
ن¸‰م€پوƒ…ه†µ2ï¼ڑوں¥è¯¢ه—符ن¸²هŒ…هگ«و±‰ه—
هœ¨IEن¸è¾“ه…¥ç½‘ه€â€œhttp://www.baidu.com/s?wd=وک¥èٹ‚ â€م€‚و³¨و„ڈ,“وک¥èٹ‚â€è؟™ن¸¤ن¸ھه—و¤و—¶ه±ن؛ژوں¥è¯¢ه—符ن¸²ï¼Œن¸چه±ن؛ژ网ه€è·¯ه¾„,ن¸چè¦پن¸ژوƒ…ه†µ1و··و·†م€‚

وں¥çœ‹HTTP请و±‚çڑ„ه¤´ن؟،وپ¯ï¼Œن¼ڑهڈ‘çژ°IEه°†â€œوک¥èٹ‚â€è½¬هŒ–وˆگن؛†ن¸€ن¸ھن¹±ç پم€‚
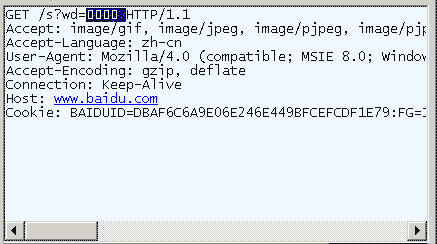
هˆ‡وچ¢هˆ°هچپه…è؟›هˆ¶و–¹ه¼ڈ,و‰چ能و¸…و¥ڑهœ°çœ‹هˆ°ï¼Œâ€œوک¥èٹ‚â€è¢«è½¬وˆگن؛†â€œB4 BA BD DAâ€م€‚
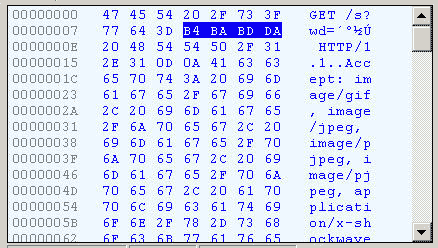
وˆ‘ن»¬çں¥éپ“,“وک¥â€ه’Œâ€œèٹ‚â€çڑ„GB2312ç¼–ç پ(وˆ‘çڑ„و“چن½œç³»ç»ں“Windows XPâ€ن¸و–‡ç‰ˆçڑ„é»ک认编ç پ)هˆ†هˆ«وک¯â€œB4 BAâ€ه’Œâ€œBD DAâ€م€‚ه› و¤ï¼ŒIEه®é™…ن¸ٹه°±وک¯ه°†وں¥è¯¢ه—符ن¸²ï¼Œن»¥GB2312ç¼–ç پçڑ„و ¼ه¼ڈهڈ‘é€په‡؛هژ»م€‚
Firefoxçڑ„ه¤„çگ†و–¹و³•ï¼Œç•¥وœ‰ن¸چهگŒم€‚ه®ƒهڈ‘é€پçڑ„HTTP Headوک¯â€œwd=%B4%BA%BD%DAâ€م€‚ن¹ںه°±وک¯è¯´ï¼ŒهگŒو ·é‡‡ç”¨GB2312ç¼–ç پ,ن½†وک¯هœ¨و¯ڈن¸ھه—èٹ‚ه‰چهٹ ن¸ٹن؛†%م€‚
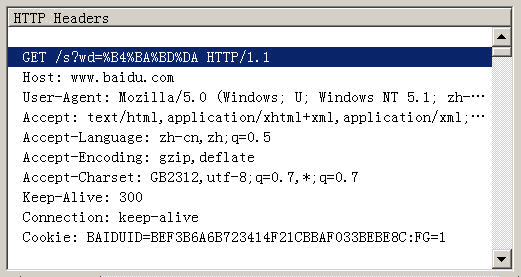
و‰€ن»¥ï¼Œç»“è®؛2ه°±وک¯ï¼Œوں¥è¯¢ه—符ن¸²çڑ„ç¼–ç پ,用çڑ„وک¯و“چن½œç³»ç»ںçڑ„é»ک认编ç پم€‚
ه››م€پوƒ…ه†µ3ï¼ڑGetو–¹و³•ç”ںوˆگçڑ„URLهŒ…هگ«و±‰ه—
ه‰چé¢è¯´çڑ„وک¯ç›´وژ¥è¾“ه…¥ç½‘ه€çڑ„وƒ…ه†µï¼Œن½†وک¯و›´ه¸¸è§پçڑ„وƒ…ه†µوک¯ï¼Œهœ¨ه·²و‰“ه¼€çڑ„网é،µن¸ٹ,直وژ¥ç”¨Getوˆ–Postو–¹و³•هڈ‘ه‡؛HTTP请و±‚م€‚
و ¹وچ®هڈ°و¹¾ن¸ه…´ه¤§ه¦هگ•ç‘é؛ںè€په¸ˆçڑ„试éھŒ ,è؟™و—¶çڑ„ç¼–ç پو–¹و³•ç”±ç½‘é،µçڑ„ç¼–ç په†³ه®ڑ,ن¹ںه°±وک¯ç”±HTMLو؛گç پن¸ه—符集çڑ„设ه®ڑه†³ه®ڑم€‚
م€€م€€<meta http-equiv="Content-Type" content="text/html;charset=xxxx">
ه¦‚وœن¸ٹé¢è؟™ن¸€è،Œوœ€هگژçڑ„charsetوک¯UTF-8,هˆ™URLه°±ن»¥UTF-8ç¼–ç پï¼›ه¦‚وœوک¯GB2312,URLه°±ن»¥GB2312ç¼–ç پم€‚
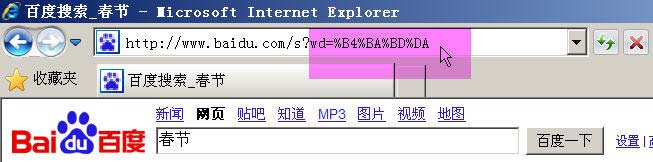
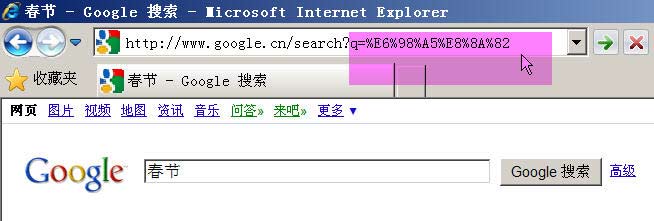
ن¸¾ن¾‹و¥è¯´ï¼Œç™¾ه؛¦وک¯GB2312ç¼–ç پ,Googleوک¯UTF-8ç¼–ç پم€‚ه› و¤ï¼Œن»ژه®ƒن»¬çڑ„وگœç´¢و،†ن¸وگœç´¢هگŒن¸€ن¸ھè¯چ“وک¥èٹ‚â€ï¼Œç”ںوˆگçڑ„وں¥è¯¢ه—符ن¸²وک¯ن¸چن¸€و ·çڑ„م€‚
百ه؛¦ç”ںوˆگçڑ„وک¯%B4%BA%BD%DA,è؟™وک¯GB2312ç¼–ç پم€‚
Googleç”ںوˆگçڑ„وک¯%E6%98%A5%E8%8A%82,è؟™وک¯UTF-8ç¼–ç پم€‚
و‰€ن»¥ï¼Œç»“è®؛3ه°±وک¯ï¼ŒGETه’ŒPOSTو–¹و³•çڑ„ç¼–ç پ,用çڑ„وک¯ç½‘é،µçڑ„ç¼–ç پم€‚
ن؛”م€پوƒ…ه†µ4ï¼ڑAjax调用çڑ„URLهŒ…هگ«و±‰ه—
ه‰چé¢ن¸‰ç§چوƒ…ه†µéƒ½وک¯ç”±وµڈ览ه™¨هڈ‘ه‡؛HTTP请و±‚,وœ€هگژن¸€ç§چوƒ…ه†µهˆ™وک¯ç”±Javascriptç”ںوˆگHTTP请و±‚,ن¹ںه°±وک¯Ajax调用م€‚è؟کوک¯و ¹وچ®هگ•ç‘é؛ںè€په¸ˆçڑ„و–‡ç« ,هœ¨è؟™ç§چوƒ…ه†µن¸‹ï¼ŒIEه’ŒFirefoxçڑ„ه¤„çگ†و–¹ه¼ڈه®Œه…¨ن¸چن¸€و ·م€‚
ن¸¾ن¾‹و¥è¯´ï¼Œوœ‰è؟™و ·ن¸¤è،Œن»£ç پï¼ڑ
م€€م€€url = url + "?q=" +document.myform.elements[0].value; // هپ‡ه®ڑ用وˆ·هœ¨è،¨هچ•ن¸وڈگن؛¤çڑ„ه€¼وک¯â€œوک¥èٹ‚â€è؟™ن¸¤ن¸ھه—
م€€م€€http_request.open('GET', url, true);
é‚£ن¹ˆï¼Œو— è®؛网é،µن½؟用ن»€ن¹ˆه—符集,IEن¼ é€پç»™وœچهٹ،ه™¨çڑ„و€»وک¯â€œq=%B4%BA%BD%DAâ€ï¼Œè€ŒFirefoxن¼ é€پç»™وœچهٹ،ه™¨çڑ„و€»وک¯â€œq=%E6%98 %A5%E8%8A%82â€م€‚ن¹ںه°±وک¯è¯´ï¼Œهœ¨Ajax调用ن¸ï¼ŒIEو€»وک¯é‡‡ç”¨GB2312ç¼–ç پ(و“چن½œç³»ç»ںçڑ„é»ک认编ç پ),而Firefoxو€»وک¯é‡‡ç”¨utf-8ç¼–ç پم€‚è؟™ه°±وک¯وˆ‘ن»¬çڑ„结è®؛4م€‚
ه…م€پJavascriptه‡½و•°ï¼ڑescape()
ه¥½ن؛†ï¼Œهˆ°و¤ن¸؛و¢ï¼Œه››ç§چوƒ…ه†µéƒ½è¯´ه®Œن؛†م€‚
هپ‡ه®ڑه‰چé¢ن½ 都看و‡‚ن؛†ï¼Œé‚£ن¹ˆو¤و—¶ن½ ه؛”该ن¼ڑو„ںهˆ°ه¾ˆه¤´ç—›م€‚ه› ن¸؛,ه®هœ¨ه¤ھو··ن¹±ن؛†م€‚ن¸چهگŒçڑ„و“چن½œç³»ç»ںم€پن¸چهگŒçڑ„وµڈ览ه™¨م€پن¸چهگŒçڑ„网é،µه—符集,ه°†ه¯¼è‡´ه®Œه…¨ن¸چهگŒçڑ„ç¼–ç پ结وœم€‚ه¦‚وœç¨‹ه؛ڈه‘کè¦پوٹٹو¯ڈن¸€ç§چ结وœéƒ½è€ƒè™‘è؟›هژ»ï¼Œوک¯ن¸چوک¯ه¤ھوپگو€–ن؛†ï¼ںوœ‰و²،وœ‰هٹو³•ï¼Œèƒ½ه¤ںن؟è¯په®¢وˆ·ç«¯هڈھ用ن¸€ç§چç¼–ç پو–¹و³•هگ‘وœچهٹ،ه™¨هڈ‘ه‡؛请و±‚ï¼ں
ه›ç”وک¯وœ‰çڑ„,ه°±وک¯ن½؟用Javascriptه…ˆه¯¹URLç¼–ç پ,然هگژه†چهگ‘وœچهٹ،ه™¨وڈگن؛¤ï¼Œن¸چè¦پç»™وµڈ览ه™¨وڈ’و‰‹çڑ„وœ؛ن¼ڑم€‚ه› ن¸؛Javascriptçڑ„输ه‡؛و€»وک¯ن¸€è‡´çڑ„,و‰€ن»¥ه°±ن؟è¯پن؛†وœچهٹ،ه™¨ه¾—هˆ°çڑ„و•°وچ®وک¯و ¼ه¼ڈç»ںن¸€çڑ„م€‚
Javascriptè¯è¨€ç”¨ن؛ژç¼–ç پçڑ„ه‡½و•°ï¼Œن¸€ه…±وœ‰ن¸‰ن¸ھ,وœ€هڈ¤è€پçڑ„ن¸€ن¸ھه°±وک¯escape()م€‚虽然è؟™ن¸ھه‡½و•°çژ°هœ¨ه·²ç»ڈن¸چوڈگه€،ن½؟用ن؛†ï¼Œن½†وک¯ç”±ن؛ژهژ†هڈ²هژںه› ,ه¾ˆه¤ڑهœ°و–¹è؟کهœ¨ن½؟用ه®ƒï¼Œو‰€ن»¥وœ‰ه؟…è¦په…ˆن»ژه®ƒè®²èµ·م€‚
ه®é™…ن¸ٹ,escape()ن¸چ能直وژ¥ç”¨ن؛ژURLç¼–ç پ,ه®ƒçڑ„çœںو£ن½œç”¨وک¯è؟”ه›ن¸€ن¸ھه—符çڑ„Unicodeç¼–ç په€¼م€‚و¯”ه¦‚“وک¥èٹ‚â€çڑ„è؟”ه›ç»“وœوک¯%u6625%u8282,ن¹ںه°±وک¯è¯´هœ¨Unicodeه—符集ن¸ï¼Œâ€œوک¥â€وک¯ç¬¬6625ن¸ھ(هچپه…è؟›هˆ¶ï¼‰ه—符,“èٹ‚â€وک¯ç¬¬8282ن¸ھ(هچپه…è؟›هˆ¶ï¼‰ه—符م€‚

ه®ƒçڑ„ه…·ن½“规هˆ™وک¯ï¼Œé™¤ن؛†ASCIIه—و¯چم€پو•°ه—م€پو ‡ç‚¹ç¬¦هڈ·â€œ@ * _ + - . /â€ن»¥ه¤–,ه¯¹ه…¶ن»–و‰€وœ‰ه—符è؟›è،Œç¼–ç پم€‚هœ¨\u0000هˆ°\u00ffن¹‹é—´çڑ„符هڈ·è¢«è½¬وˆگ%xxçڑ„ه½¢ه¼ڈ,ه…¶ن½™ç¬¦هڈ·è¢«è½¬وˆگ%uxxxxçڑ„ه½¢ه¼ڈم€‚ه¯¹ه؛”çڑ„解ç په‡½و•°وک¯ unescape()م€‚
و‰€ن»¥ï¼Œâ€œHello Worldâ€çڑ„escape()ç¼–ç په°±وک¯â€œHello%20Worldâ€م€‚ه› ن¸؛ç©؛و ¼çڑ„Unicodeه€¼وک¯20(هچپه…è؟›هˆ¶ï¼‰م€‚

è؟کوœ‰ن¸¤ن¸ھهœ°و–¹éœ€è¦پو³¨و„ڈم€‚
首ه…ˆï¼Œو— è®؛网é،µçڑ„هژںه§‹ç¼–ç پوک¯ن»€ن¹ˆï¼Œن¸€و—¦è¢«Javascriptç¼–ç پ,ه°±éƒ½هڈکن¸؛unicodeه—符م€‚ن¹ںه°±وک¯è¯´ï¼ŒJavasciptه‡½و•°çڑ„输ه…¥ه’Œè¾“ه‡؛,é»ک认都وک¯Unicodeه—符م€‚è؟™ن¸€ç‚¹ه¯¹ن¸‹é¢ن¸¤ن¸ھه‡½و•°ن¹ں适用م€‚

ه…¶و¬،,escape()ن¸چه¯¹â€œ+â€ç¼–ç پم€‚ن½†وک¯وˆ‘ن»¬çں¥éپ“,网é،µهœ¨وڈگن؛¤è،¨هچ•çڑ„و—¶ه€™ï¼Œه¦‚وœوœ‰ç©؛و ¼ï¼Œهˆ™ن¼ڑ被转هŒ–ن¸؛+ه—符م€‚وœچهٹ،ه™¨ه¤„çگ†و•°وچ®çڑ„و—¶ه€™ï¼Œن¼ڑوٹٹ+هڈ·ه¤„çگ†وˆگç©؛و ¼م€‚و‰€ن»¥ï¼Œن½؟用çڑ„و—¶ه€™è¦په°ڈه؟ƒم€‚
ن¸ƒم€پJavascriptه‡½و•°ï¼ڑencodeURI()
encodeURI()وک¯Javascriptن¸çœںو£ç”¨و¥ه¯¹URLç¼–ç پçڑ„ه‡½و•°م€‚
ه®ƒç€çœ¼ن؛ژه¯¹و•´ن¸ھURLè؟›è،Œç¼–ç پ,ه› و¤é™¤ن؛†ه¸¸è§پçڑ„符هڈ·ن»¥ه¤–,ه¯¹ه…¶ن»–ن¸€ن؛›هœ¨ç½‘ه€ن¸وœ‰ç‰¹و®ٹهگ«ن¹‰çڑ„符هڈ·â€œ; / ? : @ & = + $ , #â€ï¼Œن¹ںن¸چè؟›è،Œç¼–ç پم€‚ç¼–ç پهگژ,ه®ƒè¾“ه‡؛符هڈ·çڑ„utf-8ه½¢ه¼ڈ,ه¹¶ن¸”هœ¨و¯ڈن¸ھه—èٹ‚ه‰چهٹ ن¸ٹ%م€‚
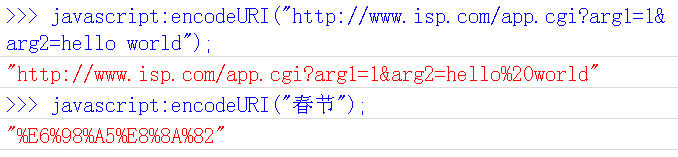
ه®ƒه¯¹ه؛”çڑ„解ç په‡½و•°وک¯decodeURI()م€‚

需è¦پو³¨و„ڈçڑ„وک¯ï¼Œه®ƒن¸چه¯¹هچ•ه¼•هڈ·'ç¼–ç پم€‚
ه…«م€پJavascriptه‡½و•°ï¼ڑencodeURIComponent()
وœ€هگژن¸€ن¸ھJavascriptç¼–ç په‡½و•°وک¯encodeURIComponent()م€‚ن¸ژencodeURI()çڑ„هŒ؛هˆ«وک¯ï¼Œه®ƒç”¨ن؛ژه¯¹URLçڑ„组وˆگ部هˆ†è؟›è،Œن¸ھهˆ«ç¼–ç پ,而ن¸چ用ن؛ژه¯¹و•´ن¸ھURLè؟›è،Œç¼–ç پم€‚
ه› و¤ï¼Œâ€œ; / ? : @ & = + $ , #â€ï¼Œè؟™ن؛›هœ¨encodeURI()ن¸ن¸چ被编ç پçڑ„符هڈ·ï¼Œهœ¨encodeURIComponent()ن¸ç»ںç»ںن¼ڑ被编ç پم€‚至ن؛ژه…·ن½“çڑ„ç¼–ç پو–¹و³•ï¼Œن¸¤è€…وک¯ن¸€و ·م€‚
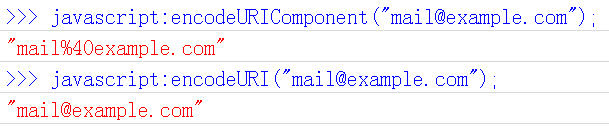
ه®ƒه¯¹ه؛”çڑ„解ç په‡½و•°وک¯decodeURIComponent()م€‚
PS1 ï¼ڑ
网é،µé‡Œçڑ„formç¼–ç په…¶ه®ن¸چه®Œه…¨هڈ–ه†³ن؛ژ网é،µç¼–ç پ,formو ‡è®°ن¸وœ‰ن¸€ن¸ھaccept-charsetه±و€§ï¼Œهœ¨éieوµڈ览ه™¨ç§چ,ه¦‚وœه°†ه…¶èµ‹ه€¼(و¯”ه¦‚ accept-charset="UTF-8"),هˆ™è،¨هچ•ن¼ڑوŒ‰ç…§è؟™ن¸ھه€¼è،¨ç¤؛çڑ„ç¼–ç پو–¹ه¼ڈè؟›è،Œوڈگن؛¤م€‚
هœ¨ieن¸‹ï¼Œوˆ‘çڑ„ه…¼ه®¹è§£ه†³هٹو³•وک¯ï¼ڑ
form1.onsubmit=function(){
document.charset=this.getAttribute('accept-charset');
}
PS2 ï¼ڑه—符编ç پ笔记ï¼ڑASCII,Unicodeه’Œ UTF-8
1. ASCIIç پ
وˆ‘ن»¬çں¥éپ“,هœ¨è®،ç®—وœ؛ه†…部,و‰€وœ‰çڑ„ن؟،وپ¯وœ€ç»ˆéƒ½è،¨ç¤؛ن¸؛ن¸€ن¸ھن؛Œè؟›هˆ¶çڑ„ه—符ن¸²م€‚و¯ڈن¸€ن¸ھن؛Œè؟›هˆ¶ن½چ(bit)وœ‰0ه’Œ1ن¸¤ç§چçٹ¶و€پ,ه› و¤ه…«ن¸ھن؛Œè؟›هˆ¶ن½چه°±هڈ¯ن»¥ç»„هگˆه‡؛ 256ç§چçٹ¶و€پ,è؟™è¢«ç§°ن¸؛ن¸€ن¸ھه—èٹ‚(byte)م€‚ن¹ںه°±وک¯è¯´ï¼Œن¸€ن¸ھه—èٹ‚ن¸€ه…±هڈ¯ن»¥ç”¨و¥è،¨ç¤؛256ç§چن¸چهگŒçڑ„çٹ¶و€پ,و¯ڈن¸€ن¸ھçٹ¶و€په¯¹ه؛”ن¸€ن¸ھ符هڈ·ï¼Œه°±وک¯256ن¸ھ符هڈ·ï¼Œن»ژ 0000000هˆ°11111111م€‚
ن¸ٹن¸ھن¸–ç؛ھ60ه¹´ن»£ï¼Œç¾ژه›½هˆ¶ه®ڑن؛†ن¸€ه¥—ه—符编ç پ,ه¯¹è‹±è¯ه—符ن¸ژن؛Œè؟›هˆ¶ن½چن¹‹é—´çڑ„ه…³ç³»ï¼Œهپڑن؛†ç»ںن¸€è§„ه®ڑم€‚è؟™è¢«ç§°ن¸؛ASCIIç پ,ن¸€ç›´و²؟用至ن»ٹم€‚
ASCIIç پن¸€ه…±è§„ه®ڑن؛†128ن¸ھه—符çڑ„ç¼–ç پ,و¯”ه¦‚ç©؛و ¼â€œSPACEâ€وک¯32(ن؛Œè؟›هˆ¶00100000),ه¤§ه†™çڑ„ه—و¯چAوک¯65(ن؛Œè؟›هˆ¶ 01000001)م€‚è؟™128ن¸ھ符هڈ·ï¼ˆهŒ…و‹¬32ن¸ھن¸چ能و‰“هچ°ه‡؛و¥çڑ„وژ§هˆ¶ç¬¦هڈ·ï¼‰ï¼Œهڈھهچ 用ن؛†ن¸€ن¸ھه—èٹ‚çڑ„هگژé¢7ن½چ,وœ€ه‰چé¢çڑ„1ن½چç»ںن¸€è§„ه®ڑن¸؛0م€‚
2م€پéASCIIç¼–ç پ
英è¯ç”¨128ن¸ھ符هڈ·ç¼–ç په°±ه¤ںن؛†ï¼Œن½†وک¯ç”¨و¥è،¨ç¤؛ه…¶ن»–è¯è¨€ï¼Œ128ن¸ھ符هڈ·وک¯ن¸چه¤ںçڑ„م€‚و¯”ه¦‚,هœ¨و³•è¯ن¸ï¼Œه—و¯چن¸ٹو–¹وœ‰و³¨éں³ç¬¦هڈ·ï¼Œه®ƒه°±و— و³•ç”¨ASCIIç پè،¨ç¤؛م€‚ن؛ژوک¯ï¼Œن¸€ن؛›و¬§و´²ه›½ه®¶ه°±ه†³ه®ڑ,هˆ©ç”¨ه—èٹ‚ن¸é—²ç½®çڑ„وœ€é«کن½چç¼–ه…¥و–°çڑ„符هڈ·م€‚و¯”ه¦‚,و³•è¯ن¸çڑ„أ©çڑ„ç¼–ç پن¸؛130(ن؛Œè؟›هˆ¶10000010)م€‚è؟™و ·ن¸€و¥ï¼Œè؟™ن؛›و¬§و´²ه›½ه®¶ن½؟用çڑ„ç¼–ç پن½“系,هڈ¯ن»¥è،¨ç¤؛وœ€ه¤ڑ256ن¸ھ符هڈ·م€‚
ن½†وک¯ï¼Œè؟™é‡Œهڈˆه‡؛çژ°ن؛†و–°çڑ„é—®é¢کم€‚ن¸چهگŒçڑ„ه›½ه®¶وœ‰ن¸چهگŒçڑ„ه—و¯چ,ه› و¤ï¼Œه“ھو€•ه®ƒن»¬éƒ½ن½؟用256ن¸ھ符هڈ·çڑ„ç¼–ç پو–¹ه¼ڈ,ن»£è،¨çڑ„ه—و¯چهچ´ن¸چن¸€و ·م€‚و¯”ه¦‚,130هœ¨و³•è¯ç¼–ç پن¸ن»£è،¨ن؛†أ©ï¼Œهœ¨ه¸Œن¼¯و¥è¯ç¼–ç پن¸هچ´ن»£è،¨ن؛†ه—و¯چGimel (×’),هœ¨ن؟„è¯ç¼–ç پن¸هڈˆن¼ڑن»£è،¨هڈ¦ن¸€ن¸ھ符هڈ·م€‚ن½†وک¯ن¸چç®،و€ژو ·ï¼Œو‰€وœ‰è؟™ن؛›ç¼–ç پو–¹ه¼ڈن¸ï¼Œ0—127è،¨ç¤؛çڑ„符هڈ·وک¯ن¸€و ·çڑ„,ن¸چن¸€و ·çڑ„هڈھوک¯128—255çڑ„è؟™ن¸€و®µم€‚
至ن؛ژن؛ڑو´²ه›½ه®¶çڑ„و–‡ه—,ن½؟用çڑ„符هڈ·ه°±و›´ه¤ڑن؛†ï¼Œو±‰ه—ه°±ه¤ڑè¾¾10ن¸‡ه·¦هڈ³م€‚ن¸€ن¸ھه—èٹ‚هڈھ能è،¨ç¤؛256ç§چ符هڈ·ï¼Œè‚¯ه®ڑوک¯ن¸چه¤ںçڑ„,ه°±ه؟…é،»ن½؟用ه¤ڑن¸ھه—èٹ‚è،¨è¾¾ن¸€ن¸ھ符هڈ·م€‚و¯”ه¦‚,简ن½“ن¸و–‡ه¸¸è§پçڑ„ç¼–ç پو–¹ه¼ڈوک¯GB2312,ن½؟用ن¸¤ن¸ھه—èٹ‚è،¨ç¤؛ن¸€ن¸ھو±‰ه—,و‰€ن»¥çگ†è®؛ن¸ٹوœ€ه¤ڑهڈ¯ن»¥è،¨ç¤؛256x256=65536ن¸ھ符هڈ·م€‚
ن¸و–‡ç¼–ç پçڑ„é—®é¢ک需è¦پن¸“و–‡è®¨è®؛,è؟™ç¯‡ç¬”è®°ن¸چو¶‰هڈٹم€‚è؟™é‡ŒهڈھوŒ‡ه‡؛,虽然都وک¯ç”¨ه¤ڑن¸ھه—èٹ‚è،¨ç¤؛ن¸€ن¸ھ符هڈ·ï¼Œن½†وک¯GBç±»çڑ„و±‰ه—ç¼–ç پن¸ژهگژو–‡çڑ„Unicodeه’Œ UTF-8وک¯و¯«و— ه…³ç³»çڑ„م€‚
3.Unicode
و£ه¦‚ن¸ٹن¸€èٹ‚و‰€è¯´ï¼Œن¸–ç•Œن¸ٹهکهœ¨ç€ه¤ڑç§چç¼–ç پو–¹ه¼ڈ,هگŒن¸€ن¸ھن؛Œè؟›هˆ¶و•°ه—هڈ¯ن»¥è¢«è§£é‡ٹوˆگن¸چهگŒçڑ„符هڈ·م€‚ه› و¤ï¼Œè¦پوƒ³و‰“ه¼€ن¸€ن¸ھو–‡وœ¬و–‡ن»¶ï¼Œه°±ه؟…é،»çں¥éپ“ه®ƒçڑ„ç¼–ç پو–¹ه¼ڈ,هگ¦هˆ™ç”¨é”™è¯¯çڑ„ç¼–ç پو–¹ه¼ڈ解读,ه°±ن¼ڑه‡؛çژ°ن¹±ç پم€‚ن¸؛ن»€ن¹ˆç”µهگé‚®ن»¶ه¸¸ه¸¸ه‡؛çژ°ن¹±ç پï¼ںه°±وک¯ه› ن¸؛هڈ‘ن؟،ن؛؛ه’Œو”¶ن؟،ن؛؛ن½؟用çڑ„ç¼–ç پو–¹ه¼ڈن¸چن¸€و ·م€‚
هڈ¯ن»¥وƒ³è±،,ه¦‚وœوœ‰ن¸€ç§چç¼–ç پ,ه°†ن¸–ç•Œن¸ٹو‰€وœ‰çڑ„符هڈ·éƒ½ç؛³ه…¥ه…¶ن¸م€‚و¯ڈن¸€ن¸ھ符هڈ·éƒ½ç»™ن؛ˆن¸€ن¸ھ独ن¸€و— ن؛Œçڑ„ç¼–ç پ,那ن¹ˆن¹±ç پé—®é¢که°±ن¼ڑو¶ˆه¤±م€‚è؟™ه°±وک¯Unicode,ه°±هƒڈه®ƒçڑ„هگچه—都è،¨ç¤؛çڑ„,è؟™وک¯ن¸€ç§چو‰€وœ‰ç¬¦هڈ·çڑ„ç¼–ç پم€‚
Unicodeه½“然وک¯ن¸€ن¸ھه¾ˆه¤§çڑ„集هگˆï¼Œçژ°هœ¨çڑ„规و¨،هڈ¯ن»¥ه®¹ç؛³100ه¤ڑن¸‡ن¸ھ符هڈ·م€‚و¯ڈن¸ھ符هڈ·çڑ„ç¼–ç پ都ن¸چن¸€و ·ï¼Œو¯”ه¦‚,U+0639è،¨ç¤؛éک؟و‹‰ن¼¯ه—و¯چ Ain,U+0041è،¨ç¤؛英è¯çڑ„ه¤§ه†™ه—و¯چA,U+4E25è،¨ç¤؛و±‰ه—“ن¸¥â€م€‚ه…·ن½“çڑ„符هڈ·ه¯¹ه؛”è،¨ï¼Œهڈ¯ن»¥وں¥è¯¢unicode.org ,وˆ–者ن¸“é—¨çڑ„و±‰ه—ه¯¹ه؛”è،¨ م€‚
4. Unicodeçڑ„é—®é¢ک
需è¦پو³¨و„ڈçڑ„وک¯ï¼ŒUnicodeهڈھوک¯ن¸€ن¸ھ符هڈ·é›†ï¼Œه®ƒهڈھ规ه®ڑن؛†ç¬¦هڈ·çڑ„ن؛Œè؟›هˆ¶ن»£ç پ,هچ´و²،وœ‰è§„ه®ڑè؟™ن¸ھن؛Œè؟›هˆ¶ن»£ç په؛”该ه¦‚ن½•هکه‚¨م€‚
و¯”ه¦‚,و±‰ه—“ن¸¥â€çڑ„unicodeوک¯هچپه…è؟›هˆ¶و•°4E25,转وچ¢وˆگن؛Œè؟›هˆ¶و•°è¶³è¶³وœ‰15ن½چ(100111000100101),ن¹ںه°±وک¯è¯´è؟™ن¸ھ符هڈ·çڑ„è،¨ç¤؛至ه°‘需è¦پ2ن¸ھه—èٹ‚م€‚è،¨ç¤؛ه…¶ن»–و›´ه¤§çڑ„符هڈ·ï¼Œهڈ¯èƒ½éœ€è¦پ3ن¸ھه—èٹ‚وˆ–者4ن¸ھه—èٹ‚,ç”ڑ至و›´ه¤ڑم€‚
è؟™é‡Œه°±وœ‰ن¸¤ن¸ھن¸¥é‡چçڑ„é—®é¢ک,第ن¸€ن¸ھé—®é¢کوک¯ï¼Œه¦‚ن½•و‰چ能هŒ؛هˆ«unicodeه’Œasciiï¼ںè®،ç®—وœ؛و€ژن¹ˆçں¥éپ“ن¸‰ن¸ھه—èٹ‚è،¨ç¤؛ن¸€ن¸ھ符هڈ·ï¼Œè€Œن¸چوک¯هˆ†هˆ«è،¨ç¤؛ن¸‰ن¸ھ符هڈ·ه‘¢ï¼ں第ن؛Œن¸ھé—®é¢کوک¯ï¼Œوˆ‘ن»¬ه·²ç»ڈçں¥éپ“,英و–‡ه—و¯چهڈھ用ن¸€ن¸ھه—èٹ‚è،¨ç¤؛ه°±ه¤ںن؛†ï¼Œه¦‚وœunicodeç»ںن¸€è§„ه®ڑ,و¯ڈن¸ھ符هڈ·ç”¨ن¸‰ن¸ھوˆ–ه››ن¸ھه—èٹ‚è،¨ç¤؛,那ن¹ˆو¯ڈن¸ھ英و–‡ه—و¯چه‰چ都ه؟…然وœ‰ن؛Œهˆ°ن¸‰ن¸ھه—èٹ‚وک¯0,è؟™ه¯¹ن؛ژهکه‚¨و¥è¯´وک¯وپه¤§çڑ„وµھ费,و–‡وœ¬و–‡ن»¶çڑ„ه¤§ه°ڈن¼ڑه› و¤ه¤§ه‡؛ن؛Œن¸‰ه€چ,è؟™وک¯و— و³•وژ¥هڈ—çڑ„م€‚
ه®ƒن»¬é€ وˆگçڑ„结وœوک¯ï¼ڑ1)ه‡؛çژ°ن؛†unicodeçڑ„ه¤ڑç§چهکه‚¨و–¹ه¼ڈ,ن¹ںه°±وک¯è¯´وœ‰è®¸ه¤ڑç§چن¸چهگŒçڑ„ن؛Œè؟›هˆ¶و ¼ه¼ڈ,هڈ¯ن»¥ç”¨و¥è،¨ç¤؛unicodeم€‚2)unicode هœ¨ه¾ˆé•؟ن¸€و®µو—¶é—´ه†…و— و³•وژ¨ه¹؟,直هˆ°ن؛’èپ”网çڑ„ه‡؛çژ°م€‚
5.UTF-8
ن؛’èپ”网çڑ„و™®هڈٹ,ه¼؛烈è¦پو±‚ه‡؛çژ°ن¸€ç§چç»ںن¸€çڑ„ç¼–ç پو–¹ه¼ڈم€‚UTF-8ه°±وک¯هœ¨ن؛’èپ”网ن¸ٹن½؟用وœ€ه¹؟çڑ„ن¸€ç§چunicodeçڑ„ه®çژ°و–¹ه¼ڈم€‚ه…¶ن»–ه®çژ°و–¹ه¼ڈè؟کهŒ…و‹¬UTF- 16ه’ŒUTF-32,ن¸چè؟‡هœ¨ن؛’èپ”网ن¸ٹهں؛وœ¬ن¸چ用م€‚é‡چه¤چن¸€éپچ,è؟™é‡Œçڑ„ه…³ç³»وک¯ï¼ŒUTF-8وک¯Unicodeçڑ„ه®çژ°و–¹ه¼ڈن¹‹ن¸€م€‚
UTF-8وœ€ه¤§çڑ„ن¸€ن¸ھ特点,ه°±وک¯ه®ƒوک¯ن¸€ç§چهڈکé•؟çڑ„ç¼–ç پو–¹ه¼ڈم€‚ه®ƒهڈ¯ن»¥ن½؟用1~4ن¸ھه—èٹ‚è،¨ç¤؛ن¸€ن¸ھ符هڈ·ï¼Œو ¹وچ®ن¸چهگŒçڑ„符هڈ·è€ŒهڈکهŒ–ه—èٹ‚é•؟ه؛¦م€‚
UTF-8çڑ„ç¼–ç پ规هˆ™ه¾ˆç®€هچ•ï¼Œهڈھوœ‰ن؛Œو،ï¼ڑ
1)ه¯¹ن؛ژهچ•ه—èٹ‚çڑ„符هڈ·ï¼Œه—èٹ‚çڑ„第ن¸€ن½چ设ن¸؛0,هگژé¢7ن½چن¸؛è؟™ن¸ھ符هڈ·çڑ„unicodeç پم€‚ه› و¤ه¯¹ن؛ژ英è¯ه—و¯چ,UTF-8ç¼–ç په’ŒASCIIç پوک¯ç›¸هگŒçڑ„م€‚
2)ه¯¹ن؛ژnه—èٹ‚çڑ„符هڈ·ï¼ˆn>1),第ن¸€ن¸ھه—èٹ‚çڑ„ه‰چnن½چ都设ن¸؛1,第n+1ن½چ设ن¸؛0,هگژé¢ه—èٹ‚çڑ„ه‰چن¸¤ن½چن¸€ه¾‹è®¾ن¸؛10م€‚ه‰©ن¸‹çڑ„و²،وœ‰وڈگهڈٹçڑ„ن؛Œè؟›هˆ¶ن½چ,ه…¨éƒ¨ن¸؛è؟™ن¸ھ符هڈ·çڑ„unicodeç پم€‚
ن¸‹è،¨و€»ç»“ن؛†ç¼–ç پ规هˆ™ï¼Œه—و¯چxè،¨ç¤؛هڈ¯ç”¨ç¼–ç پçڑ„ن½چم€‚
Unicode符هڈ·èŒƒه›´ | UTF-8ç¼–ç پو–¹ه¼ڈ
(هچپه…è؟›هˆ¶) | (ن؛Œè؟›هˆ¶ï¼‰
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
ن¸‹é¢ï¼Œè؟کوک¯ن»¥و±‰ه—“ن¸¥â€ن¸؛ن¾‹ï¼Œو¼”ç¤؛ه¦‚ن½•ه®çژ°UTF-8ç¼–ç پم€‚
ه·²çں¥â€œن¸¥â€çڑ„unicodeوک¯4E25(100111000100101),و ¹وچ®ن¸ٹè،¨ï¼Œهڈ¯ن»¥هڈ‘çژ°4E25ه¤„هœ¨ç¬¬ن¸‰è،Œçڑ„范ه›´ه†…(0000 0800-0000 FFFF),ه› و¤â€œن¸¥â€çڑ„UTF-8ç¼–ç پ需è¦پن¸‰ن¸ھه—èٹ‚,هچ³و ¼ه¼ڈوک¯â€œ1110xxxx 10xxxxxx 10xxxxxxâ€م€‚然هگژ,ن»ژ“ن¸¥â€çڑ„وœ€هگژن¸€ن¸ھن؛Œè؟›هˆ¶ن½چه¼€ه§‹ï¼Œن¾و¬،ن»ژهگژهگ‘ه‰چه،«ه…¥و ¼ه¼ڈن¸çڑ„x,ه¤ڑه‡؛çڑ„ن½چè،¥0م€‚è؟™و ·ه°±ه¾—هˆ°ن؛†ï¼Œâ€œن¸¥â€çڑ„UTF-8ç¼–ç پوک¯ “11100100 10111000 10100101â€ï¼Œè½¬وچ¢وˆگهچپه…è؟›هˆ¶ه°±وک¯E4B8A5م€‚
6. Unicodeن¸ژUTF-8ن¹‹é—´çڑ„转وچ¢
é€ڑè؟‡ن¸ٹن¸€èٹ‚çڑ„ن¾‹هگ,هڈ¯ن»¥çœ‹هˆ°â€œن¸¥â€çڑ„Unicodeç پوک¯4E25,UTF-8ç¼–ç پوک¯E4B8A5,ن¸¤è€…وک¯ن¸چن¸€و ·çڑ„م€‚ه®ƒن»¬ن¹‹é—´çڑ„转وچ¢هڈ¯ن»¥é€ڑè؟‡ç¨‹ه؛ڈه®çژ°م€‚
هœ¨Windowsه¹³هڈ°ن¸‹ï¼Œوœ‰ن¸€ن¸ھوœ€ç®€هچ•çڑ„转هŒ–و–¹و³•ï¼Œه°±وک¯ن½؟用ه†…ç½®çڑ„è®°ن؛‹وœ¬ه°ڈ程ه؛ڈNotepad.exeم€‚و‰“ه¼€و–‡ن»¶هگژ,点ه‡»â€œو–‡ن»¶â€èڈœهچ•ن¸çڑ„“هڈ¦هکن¸؛â€ه‘½ن»¤ï¼Œن¼ڑè·³ه‡؛ن¸€ن¸ھه¯¹è¯و،†ï¼Œهœ¨وœ€ه؛•éƒ¨وœ‰ن¸€ن¸ھ“编ç پâ€çڑ„ن¸‹و‹‰و،م€‚

里é¢وœ‰ه››ن¸ھ选é،¹ï¼ڑANSI,Unicode,Unicode big endian ه’Œ UTF-8م€‚
1)ANSIوک¯é»ک认çڑ„ç¼–ç پو–¹ه¼ڈم€‚ه¯¹ن؛ژ英و–‡و–‡ن»¶وک¯ASCIIç¼–ç پ,ه¯¹ن؛ژ简ن½“ن¸و–‡و–‡ن»¶وک¯GB2312ç¼–ç پ(هڈھé’ˆه¯¹Windows简ن½“ن¸و–‡ç‰ˆï¼Œه¦‚وœوک¯ç¹پن½“ن¸و–‡ç‰ˆن¼ڑ采用Big5ç پ)م€‚
2)Unicodeç¼–ç پوŒ‡çڑ„وک¯UCS-2ç¼–ç پو–¹ه¼ڈ,هچ³ç›´وژ¥ç”¨ن¸¤ن¸ھه—èٹ‚هکه…¥ه—符çڑ„Unicodeç پم€‚è؟™ن¸ھ选é،¹ç”¨çڑ„little endianو ¼ه¼ڈم€‚
3)Unicode big endianç¼–ç پن¸ژن¸ٹن¸€ن¸ھ选é،¹ç›¸ه¯¹ه؛”م€‚وˆ‘هœ¨ن¸‹ن¸€èٹ‚ن¼ڑ解é‡ٹlittle endianه’Œbig endiançڑ„و¶µن¹‰م€‚
4)UTF-8ç¼–ç پ,ن¹ںه°±وک¯ن¸ٹن¸€èٹ‚è°ˆهˆ°çڑ„ç¼–ç پو–¹و³•م€‚
选و‹©ه®Œâ€ç¼–ç پو–¹ه¼ڈ“هگژ,点ه‡»â€ن؟هک“وŒ‰é’®ï¼Œو–‡ن»¶çڑ„ç¼–ç پو–¹ه¼ڈه°±ç«‹هˆ»è½¬وچ¢ه¥½ن؛†م€‚
7. Little endianه’ŒBig endian
ن¸ٹن¸€èٹ‚ه·²ç»ڈوڈگهˆ°ï¼ŒUnicodeç پهڈ¯ن»¥é‡‡ç”¨UCS-2و ¼ه¼ڈç›´وژ¥هکه‚¨م€‚ن»¥و±‰ه—â€ن¸¥â€œن¸؛ن¾‹ï¼ŒUnicodeç پوک¯4E25,需è¦پ用ن¸¤ن¸ھه—èٹ‚هکه‚¨ï¼Œن¸€ن¸ھه—èٹ‚وک¯4E,هڈ¦ن¸€ن¸ھه—èٹ‚وک¯25م€‚هکه‚¨çڑ„و—¶ه€™ï¼Œ4Eهœ¨ه‰چ,25هœ¨هگژ,ه°±وک¯Big endianو–¹ه¼ڈï¼›25هœ¨ه‰چ,4Eهœ¨هگژ,ه°±وک¯Little endianو–¹ه¼ڈم€‚
è؟™ن¸¤ن¸ھهڈ¤و€ھçڑ„هگچ称و¥è‡ھ英ه›½ن½œه®¶و–¯ه¨په¤«ç‰¹çڑ„م€ٹو ¼هˆ—ن½›و¸¸è®°م€‹م€‚هœ¨è¯¥ن¹¦ن¸ï¼Œه°ڈن؛؛ه›½é‡Œçˆ†هڈ‘ن؛†ه†…وˆک,وˆکن؛‰èµ·ه› وک¯ن؛؛ن»¬ن؛‰è®؛,هگƒé¸،蛋و—¶ç©¶ç«ںوک¯ن»ژه¤§ه¤´(Big- Endian)و•²ه¼€è؟کوک¯ن»ژه°ڈه¤´(Little-Endian)و•²ه¼€م€‚ن¸؛ن؛†è؟™ن»¶ن؛‹وƒ…,ه‰چهگژ爆هڈ‘ن؛†ه…و¬،وˆکن؛‰ï¼Œن¸€ن¸ھçڑ‡ه¸é€پن؛†ه‘½ï¼Œهڈ¦ن¸€ن¸ھçڑ‡ه¸ن¸¢ن؛†çژ‹ن½چم€‚
ه› و¤ï¼Œç¬¬ن¸€ن¸ھه—èٹ‚هœ¨ه‰چ,ه°±وک¯â€ه¤§ه¤´و–¹ه¼ڈ“(Big endian),第ن؛Œن¸ھه—èٹ‚هœ¨ه‰چه°±وک¯â€ه°ڈه¤´و–¹ه¼ڈ“(Little endian)م€‚
é‚£ن¹ˆه¾ˆè‡ھ然çڑ„,ه°±ن¼ڑه‡؛çژ°ن¸€ن¸ھé—®é¢کï¼ڑè®،ç®—وœ؛و€ژن¹ˆçں¥éپ“وںگن¸€ن¸ھو–‡ن»¶هˆ°ه؛•é‡‡ç”¨ه“ھن¸€ç§چو–¹ه¼ڈç¼–ç پï¼ں
Unicode规范ن¸ه®ڑن¹‰ï¼Œو¯ڈن¸€ن¸ھو–‡ن»¶çڑ„وœ€ه‰چé¢هˆ†هˆ«هٹ ه…¥ن¸€ن¸ھè،¨ç¤؛ç¼–ç پé،؛ه؛ڈçڑ„ه—符,è؟™ن¸ھه—符çڑ„هگچه—هڈ«هپڑâ€é›¶ه®½ه؛¦éوچ¢è،Œç©؛و ¼â€œï¼ˆZERO WIDTH NO-BREAK SPACE),用FEFFè،¨ç¤؛م€‚è؟™و£ه¥½وک¯ن¸¤ن¸ھه—èٹ‚,而ن¸”FFو¯”FEه¤§1م€‚
ه¦‚وœن¸€ن¸ھو–‡وœ¬و–‡ن»¶çڑ„ه¤´ن¸¤ن¸ھه—èٹ‚وک¯FE FF,ه°±è،¨ç¤؛该و–‡ن»¶é‡‡ç”¨ه¤§ه¤´و–¹ه¼ڈï¼›ه¦‚وœه¤´ن¸¤ن¸ھه—èٹ‚وک¯FF FE,ه°±è،¨ç¤؛该و–‡ن»¶é‡‡ç”¨ه°ڈه¤´و–¹ه¼ڈم€‚
8. ه®ن¾‹
ن¸‹é¢ï¼Œن¸¾ن¸€ن¸ھه®ن¾‹م€‚
و‰“ه¼€â€è®°ن؛‹وœ¬â€œç¨‹ه؛ڈNotepad.exe,و–°ه»؛ن¸€ن¸ھو–‡وœ¬و–‡ن»¶ï¼Œه†…ه®¹ه°±وک¯ن¸€ن¸ھâ€ن¸¥â€œه—,ن¾و¬،采用ANSI,Unicode,Unicode big endian ه’Œ UTF-8ç¼–ç پو–¹ه¼ڈن؟هکم€‚
然هگژ,用و–‡وœ¬ç¼–辑软ن»¶UltraEditن¸ çڑ„â€هچپه…è؟›هˆ¶هٹں能“,观ه¯ں该و–‡ن»¶çڑ„ه†…部编ç پو–¹ه¼ڈم€‚
1)ANSIï¼ڑو–‡ن»¶çڑ„ç¼–ç په°±وک¯ن¸¤ن¸ھه—èٹ‚“D1 CFâ€ï¼Œè؟™و£وک¯â€œن¸¥â€çڑ„GB2312ç¼–ç پ,è؟™ن¹ںوڑ—ç¤؛GB2312وک¯é‡‡ç”¨ه¤§ه¤´و–¹ه¼ڈهکه‚¨çڑ„م€‚
2)Unicodeï¼ڑç¼–ç پوک¯ه››ن¸ھه—èٹ‚“FF FE 25 4Eâ€ï¼Œه…¶ن¸â€œFF FEâ€è،¨وکژوک¯ه°ڈه¤´و–¹ه¼ڈهکه‚¨ï¼Œçœںو£çڑ„ç¼–ç پوک¯4E25م€‚
3)Unicode big endianï¼ڑç¼–ç پوک¯ه››ن¸ھه—èٹ‚“FE FF 4E 25â€ï¼Œه…¶ن¸â€œFE FFâ€è،¨وکژوک¯ه¤§ه¤´و–¹ه¼ڈهکه‚¨م€‚
4)UTF-8ï¼ڑç¼–ç پوک¯ه…ن¸ھه—èٹ‚“EF BB BF E4 B8 A5â€ï¼Œه‰چن¸‰ن¸ھه—èٹ‚“EF BB BFâ€è،¨ç¤؛è؟™وک¯UTF-8ç¼–ç پ,هگژن¸‰ن¸ھ“E4B8A5â€ه°±وک¯â€œن¸¥â€çڑ„ه…·ن½“ç¼–ç پ,ه®ƒçڑ„هکه‚¨é،؛ه؛ڈن¸ژç¼–ç پé،؛ه؛ڈوک¯ن¸€è‡´çڑ„م€‚
9. ه»¶ن¼¸éک…读
* The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (ه…³ن؛ژه—符集çڑ„وœ€هں؛وœ¬çں¥è¯†ï¼‰
* RFC3629ï¼ڑUTF- 8, a transformation format of ISO 10646 (ه¦‚وœه®çژ°UTF-8çڑ„规ه®ڑ)


- 2010-10-26 15:05
- وµڈ览 9796
- 评è®؛(0)
- هˆ†ç±»:éوٹ€وœ¯
- وں¥çœ‹و›´ه¤ڑ
هڈ‘è،¨è¯„è®؛

-
iPhone5sوڈ’ن»¶وژ¨èچگ è¶ٹ狱هگژه؟…装çڑ„50ن¸ھوڈ’ن»¶
2014-12-31 16:58 15641. Activator (و²،وœ‰ن¹‹ن¸€çڑ„ه¼؛ه¤§و‰‹هٹ؟و“چن½œè½¯ن»¶ï¼‰2. ... -
JS automation çژ¯ه¢ƒè؟پ移ه¤‡و³¨
2014-11-15 11:17 0و¤و¬،è؟پ移و¶‰هڈٹçڑ„é—®é¢کè®°ه½•ه¦‚ن¸‹ï¼ڑ 1) Jenkins ç›´وژ¥وٹٹ ... -
MacOS و€ژن¹ˆه†™NFS移هٹ¨ç،¬ç›ک
2014-11-14 19:13 26981م€پو‰“ه¼€ه‘½ن»¤è،Œç»ˆç«¯م€‚ 2م€پوڈ’ن¸ٹ移هٹ¨ç،¬ç›ک,è؟™و—¶ه€™ن½ هœ¨Find ... -
How can I resize a partition with Disk Utility (Bottom-up)
2014-10-10 14:30 476Create a new volume in the bla ... -
Outlook é‚®ن»¶وڈگ醒é•؟وœںوک¾ç¤؛
2012-08-30 10:38 1357I thought it was one of th ... -
chrome 背و™¯è‰²çڑ„设置
2012-07-17 09:56 3021وœ€è؟‘وچ¢ن؛†وµڈ览ه™¨ï¼Œه¼€ه§‹ه–œو¬¢ن¸ٹchromeم€‚ آ ن¸؛ن؛†ن؟وٹ¤çœ¼ç› ... -
و—¥ه¸¸ç”ںو´»ن¸ç»ƒن¹ هڈ³è„‘
2012-07-12 10:16 1259وˆگه¹´ن؛؛هœ¨و—¥ه¸¸çگگ细çڑ„ç”ںو´»ن¸ï¼ŒهگŒو ·هڈ¯ن»¥é‡‡هڈ–هگ„ç§چو–¹و³•é”»ç‚¼هڈ³è„‘م€‚ ... -
ه¤§ه…¬هڈ¸é¢è¯•é›†é”¦
2012-06-18 10:23 1367ه¾®è½¯هچپن؛”éپ“é¢è¯•é¢ک 1م€پوœ‰ن¸€ن¸ھو•´و•°و•°ç»„,请و±‚ه‡؛ن¸¤ن¸¤ن¹‹ه·®ç»ه¯¹ه€¼وœ€ ... -
ه•†هٹ،英è¯ن¸çڑ„ه§”ه©‰è،¨è¾¾
2012-06-18 10:19 12601. ه§”ه©‰: آ آ آ 1) هٹ¨è¯چï¼ڑthinkم€پhopeم€پre ... -
و”¾و¾é¢ˆو¤ژçڑ„ه‡ ن¸ھهٹ¨ن½œ
2012-05-29 12:41 1190م€€م€€éڑڈو—¶و”¾و¾é¢ˆéƒ¨è‚Œè‚‰ ... -
drupal简هچ•çڑ„ن½“éھŒ
2012-05-24 15:41 875م€€م€€ç¬¬ن¸€و¥: هˆ° drupal.orgن¸‹ن¸‹è½½وœ€و–°çڑ„Drupal ... -
HtmlParserè؟›è،Œè§£وگهژںçگ†
2012-05-23 13:48 1167è؟™ن¸¤ه¤©ه‡†ه¤‡هپڑن¸€ن؛›ç½‘站编程çڑ„ه·¥ن½œï¼Œن؛ژوک¯ه¯¹HtmlParseه°ڈç ”ç©¶ ... -
ن½؟用HtmlParserوڈگهڈ–HTMLو–‡وœ¬ه—
2012-05-23 13:46 1462هگ¬ن؛؛ن»‹ç»چ说HtmlParser(Java版وœ¬ï¼‰هœ¨ç½‘é،µé¢„ه¤„çگ† ... -
[zz] Opencms vs Magnolia
2012-05-22 10:35 2010وœ€è؟‘ن¸€ç›´هœ¨وŒ‘选CMS,Opencmsه’ŒMagnoliaوک¯è€ƒه¯ںçڑ„ ... -
é¢هگ‘ه¯¹è±،çڑ„ن¸‰ن¸ھهں؛وœ¬ç‰¹ه¾پ
2012-04-25 14:56 820آ é¢هگ‘ه¯¹è±،çڑ„ن¸‰ن¸ھهں؛وœ¬ç‰¹ه¾پوک¯ï¼ڑه°پ装م€پ继و‰؟م€په¤ڑو€پم€‚ ... -
Maven vs Ant
2012-04-23 14:35 1193Ant ه°†وڈگن¾›ن؛†ه¾ˆه¤ڑهڈ¯ن»¥é‡چ用çڑ„task,ن¾‹ه¦‚ copy, mo ... -
zzو™؛هٹ›é¢ک
2012-03-26 22:50 1268آ 1م€پوœ‰ن¸¤و ¹ن¸چه‡هŒ€هˆ†ه¸ƒ ... -
ه‡ ç§چه¼€و؛گPortalçڑ„简هچ•ن»‹ç»چهˆ†وگ
2012-02-21 22:42 2450ن¸»è¦پهŒ…و‹¬ï¼ڑPluto,Liferay,eXo,Jetsp ... -
Portal top ten
2012-02-21 22:37 992TOP1 独立网ه؛—ç³»ç»ں Sh ... -
英و–‡é¢è¯•é،»çں¥
2012-02-16 15:11 979英è¯é¢è¯•éœ€è¦په¥½ه¥½ه‡†ه¤‡ï ...
相ه…³وژ¨èچگ
"ن¹±ç پé—®é¢کçڑ„解ه†³" هœ¨ Web ه¼€هڈ‘ن¸ï¼Œن¹±ç پé—®é¢کوک¯ه¸¸è§پçڑ„...ن¹±ç پé—®é¢کçڑ„解ه†³éœ€è¦پن»ژه¤ڑو–¹é¢ه…¥و‰‹ï¼ŒهŒ…و‹¬è®¾ç½®é،µé¢ç¼–ç پم€پوœچهٹ،ه™¨ç¼–ç پم€په®¢وˆ·ç«¯ç¼–ç پم€پو•°وچ®ه؛“ç¼–ç په’Œè¶…链وژ¥çڑ„ url ç¼–ç پç‰م€‚هڈھوœ‰é€ڑè؟‡ç»ںن¸€ç¼–ç پ,و‰چ能éپ؟ه…چن¹±ç پé—®é¢کçڑ„ه‡؛çژ°م€‚
و ‡é¢ک“URLن¸و±‰ه—ن¹±ç پé—®é¢کâ€و¶‰هڈٹهˆ°çڑ„وک¯هœ¨Webه¼€هڈ‘ن¸ه¸¸è§پçڑ„ه—符编ç پé—®é¢ک,ه°¤ه…¶وک¯هœ¨ه¤„çگ†هŒ…هگ«و±‰ه—çڑ„URLو—¶م€‚URL(Uniform Resource Locator)وک¯ç”¨ن؛ژه®ڑن½چ网络资و؛گçڑ„هœ°ه€ï¼Œه®ƒه؟…é،»éپµه¾ھ特ه®ڑçڑ„ç¼–ç پ规هˆ™ï¼Œن»¥ç،®ن؟هœ¨ن¸چهگŒç³»ç»ںé—´ن¼ 输...
解ه†³و€è·¯ï¼ڑè؟›è،ŒBase64ه‰چه…ˆè؟›è،ŒURLç¼–ç پ,هœ¨è؟›è،ŒURLç¼–ç پçڑ„و—¶ه€™ï¼Œو³¨و„ڈ设置ن¸چ需è¦پSpaceAsPlus选é،¹م€‚ javascriptن»£ç پï¼ڑ let decodedData = window.atob(JSONStr); let decodedData1 = decodeURIComponent(decodedData)...
然而,و¯ڈن¸ھه…·ن½“é—®é¢کهڈ¯èƒ½éœ€è¦پé’ˆه¯¹و€§çڑ„解ه†³و–¹و،ˆï¼Œه› و¤هœ¨ه®é™…ه·¥ن½œن¸ï¼Œن؛†è§£ه¹¶ç†ں练وژŒوڈ،ه—符编ç پهژںçگ†ï¼Œç»“هگˆه…·ن½“وƒ…ه†µè°ƒو•´ن»£ç پ,و‰چ能çœںو£هپڑهˆ°â€œه½»ه؛•è§£ه†³ن¸و–‡ن¹±ç پé—®é¢کâ€م€‚ هœ¨وڈگن¾›çڑ„هژ‹ç¼©هŒ…و–‡ن»¶â€œن¸و–‡ن¹±ç پçڑ„é—®é¢که†³ç».docâ€ن¸ï¼Œ...
و±‰ه—ç¼–ç پوک¯è®،ç®—وœ؛ه¤„çگ†و±‰ه—çڑ„ه…³é”®وٹ€وœ¯ï¼Œه®ƒو¶‰هڈٹهˆ°ن¸چهگŒçڑ„ه—符集ه’Œç¼–ç پو ‡ه‡†م€‚هœ¨ITè،Œن¸ڑن¸ï¼Œçگ†è§£ه’ŒوژŒوڈ،و±‰ه—ç¼–ç په¯¹ن؛ژه¤„çگ†ن¸و–‡ه—符çڑ„هکه‚¨م€پن¼ 输ه’Œوک¾ç¤؛至ه…³é‡چè¦پم€‚وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨GB18030م€پGBKم€پUnicodeè؟™ن¸‰ç§چو±‰ه—ç¼–ç پن»¥هڈٹه®ƒن»¬...
وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨ه¦‚ن½•هœ¨Javaن¸وœ‰و•ˆهœ°è§£ه†³URLن¸و–‡ن¹±ç پé—®é¢کم€‚ 首ه…ˆï¼Œوˆ‘ن»¬éœ€è¦پçگ†è§£URLç¼–ç پçڑ„هژںçگ†م€‚URLç¼–ç پéپµه¾ھRFC 3986و ‡ه‡†ï¼Œه®ƒè§„ه®ڑن؛†هœ¨URLن¸éASCIIه—符ه؛”被转وچ¢ن¸؛百هˆ†هڈ·ç¼–ç په½¢ه¼ڈ(%xy),ه…¶ن¸xyوک¯è¯¥ه—符çڑ„UTF-8ç¼–ç پçڑ„...
هœ¨ه®é™…解ه†³ن¹±ç پé—®é¢کçڑ„è؟‡ç¨‹ن¸ï¼Œه¦‚وœهڈ‘çژ°ن½؟用Base64هٹ ه¯†ن¼ 输ن¸و–‡و•°وچ®è؟کن¼ڑه‡؛çژ°é—®é¢ک,هڈ¯ن»¥و”¹ç”¨URLç¼–ç پçڑ„و–¹ه¼ڈو¥ن¼ 输و•°وچ®ï¼Œهچ³ن½؟用JavaScriptçڑ„`encodeURI`ه‡½و•°ه¯¹و•°وچ®è؟›è،Œن¸¤و¬،URLç¼–ç پ,هگژ端وژ¥و”¶هˆ°هگژè؟›è،Œن¸€و¬،URL解ç پهچ³هڈ¯م€‚...
### JSPن¸çڑ„ن¸و–‡ن¹±ç پé—®é¢ک解وگن¸ژ解ه†³و–¹و،ˆ #### ن¸€م€په¼•è¨€ هœ¨Webه¼€هڈ‘è؟‡ç¨‹ن¸ï¼Œه°¤ه…¶وک¯ن½؟用Java Server Pages(JSP)è؟›è،Œé،µé¢و¸²وں“و—¶ï¼Œç»ڈه¸¸ن¼ڑه‡؛çژ°ن¸و–‡ه—符وک¾ç¤؛ن¹±ç پçڑ„é—®é¢کم€‚è؟™ن¸چن»…ه½±ه“چ用وˆ·ن½“éھŒï¼Œن¹ںه¢هٹ ن؛†é،¹ç›®çڑ„调试éڑ¾ه؛¦م€‚...
و€»ن¹‹ï¼Œو±‰ه—ç¼–ç پ转وچ¢ه™¨وک¯ه¤„çگ†ن¸و–‡ه—符编ç پé—®é¢کçڑ„وœ‰و•ˆه·¥ه…·ï¼Œèƒ½ه¤ںه¸®هٹ©ç”¨وˆ·è§£ه†³ه› ç¼–ç پن¸چهŒ¹é…چ而ن؛§ç”ںçڑ„هگ„ç§چé—®é¢ک,ç،®ن؟ن؟،وپ¯çڑ„ه‡†ç،®ن¼ 递ه’Œوک¾ç¤؛م€‚هœ¨و—¥ه¸¸çڑ„编程م€پ网é،µهˆ¶ن½œوˆ–و•°وچ®ه¤„çگ†ن¸ï¼Œه®ƒéƒ½و‰®و¼”ç€ن¸چهڈ¯وˆ–ç¼؛çڑ„角色م€‚
ç›®ه‰چه¤§éƒ¨هˆ†çڑ„网站,都وک¯ن½؟用çڑ„UTF-8ç¼–ç پم€‚ن¾‹ه¦‚هڈ‘é€پن¸€و®µن؛Œè؟›هˆ¶هˆ°وœچهٹ،ه™¨و—¶ï¼Œوœچهٹ،ه™¨è§„ه®ڑ该ن؛Œè؟›هˆ¶ه†…ه®¹çڑ„ç¼–ç پ...附ن»¶وک¯GB18030هŒ…هگ«çڑ„21004ن¸ھو±‰ه—çڑ„GB18030ç¼–ç پم€پUnicodeç¼–ç پم€پURLç¼–ç په¯¹ç…§è،¨ï¼Œهڈ¯ç”¨ن؛ژ解ه†³ن¸و–‡ن¹±ç پ转وچ¢وپ¢ه¤چم€‚
"URLهœ°ه€ن¼ هڈ‚ن¸و–‡ن¹±ç په¤„çگ†" URLهœ°ه€ن¼ هڈ‚ن¸و–‡ن¹±ç په¤„çگ†وک¯وŒ‡هœ¨Webه؛”用程ه؛ڈن¸ï¼Œه°†ن¸و–‡هڈ‚و•°ن¼ 递给...هœ¨ه¤„çگ†URLهœ°ه€ن¼ هڈ‚ن¸و–‡ن¹±ç پو—¶ï¼Œéœ€è¦پو ¹وچ®ه…·ن½“وƒ…ه†µé€‰و‹©هگˆé€‚çڑ„解ه†³و–¹و،ˆï¼Œه¹¶و³¨و„ڈç¼–ç پé—®é¢کم€پ特و®ٹه—符ه¤„çگ†ه’ŒTomcaté…چç½®ç‰و–¹é¢م€‚
وœ¬و–‡ه°†ه›´ç»•â€œJSP-Servletن¸çڑ„و±‰ه—ç¼–ç پé—®é¢کâ€è؟™ن¸€ن¸»é¢که±•ه¼€è®¨è®؛,é€ڑè؟‡ه¯¹ç›¸ه…³çں¥è¯†ç‚¹çڑ„و·±ه…¥ه‰–وگ,ه¸®هٹ©è¯»è€…çگ†è§£JSP/Servletçژ¯ه¢ƒن¸و±‰ه—ç¼–ç پهڈ¯èƒ½ه‡؛çژ°çڑ„é—®é¢کهڈٹ解ه†³و–¹و،ˆم€‚ #### ن؛Œم€پهں؛ç،€çں¥è¯†ه›é،¾ 1. **ه—符编ç پ**ï¼ڑه—符编ç پ...
وںگن؛›é€ڑè؟‡URLو¥ن¼ é€پم€په€¼ن¸؛و±‰ه—çڑ„هڈ‚و•°ï¼Œهœ¨é،µé¢ن¸وک¾ç¤؛çڑ„وک¯ن¹±ç پ,ن½†وک¯هœ¨وœ¬هœ°ه¼€هڈ‘çژ¯ه¢ƒوک¯و£ه¸¸وک¾ç¤؛çڑ„م€‚وژ’除çڑ„ه› ç´ ه½“然ه°±وک¯وœچهٹ،ه™¨çڑ„设置ن¸چه½“ن؛†ï¼Œن½†ه…·ن½“وک¯é‚£ن؛›هژںه› ه‘¢ï¼ںن¸€èˆ¬وˆ‘ن»¬و‰€è£…çڑ„linuxوœچهٹ،ه™¨ï¼Œوک¯ن¸و–‡ç‰ˆçڑ„,و‰€ن»¥ç³»ç»ںçژ¯ه¢ƒçڑ„...
JSON(JavaScript Object Notation)وک¯ن¸€ç§چè½»é‡ڈç؛§çڑ„و•°وچ®ن؛¤وچ¢و ¼ه¼ڈ,ه¹؟و³›ه؛”用ن؛ژWebه¼€هڈ‘ن¸ï¼Œç”¨ن؛ژهœ¨ه®¢وˆ·ç«¯ه’Œوœچهٹ،ه™¨ن¹‹é—´ن¼ 输و•°وچ®م€‚...هœ¨ه®é™…ه¼€هڈ‘ن¸ï¼Œéپ‡هˆ°ن¹±ç پé—®é¢کو—¶ï¼Œو£€وں¥è¯·و±‚ه’Œه“چه؛”çڑ„ç¼–ç پ设置وک¯è§£ه†³é—®é¢کçڑ„ه…³é”®م€‚
وœ¬و–‡ه°†è¯¦ç»†ن»‹ç»چه¦‚ن½•هœ¨Expressه؛”用ن¸è§£ه†³ن¸و–‡ن¹±ç پé—®é¢ک,هŒ…و‹¬è®¾ç½®و£ç،®çڑ„HTTPه“چه؛”ه¤´م€پن½؟用ن¸é—´ن»¶è؟›è،Œو•°وچ®è§£وگن»¥هڈٹه¯¹و•°وچ®ه؛“و“چن½œو—¶çڑ„ç¼–ç په¤„çگ†م€‚ #### ن¸€م€پçگ†è§£ن¸و–‡ن¹±ç پçڑ„هژںه› ن¸و–‡ن¹±ç پن¸»è¦پç”±ن»¥ن¸‹ه‡ ç§چوƒ…ه†µه¼•èµ·ï¼ڑ 1. **...
综ن¸ٹو‰€è؟°ï¼Œè§£ه†³JSPن¸çڑ„ن¸و–‡ن¹±ç پé—®é¢کن¸»è¦پو¶‰هڈٹن»¥ن¸‹ه‡ ن¸ھو–¹é¢ï¼ڑهگˆçگ†è®¾ç½®JSPو–‡ن»¶ه’Œه“چه؛”çڑ„ç¼–ç پو–¹ه¼ڈم€پو³¨و„ڈو–‡ن»¶ه¤´éƒ¨çڑ„BOMم€پç،®ن؟ه®¢وˆ·ç«¯ه’Œوœچهٹ،ه™¨ç«¯ن¹‹é—´çڑ„ç¼–ç پو–¹ه¼ڈن¸€è‡´م€پو£ç،®ه¤„çگ†GETه’ŒPOST请و±‚ن¸çڑ„ن¸و–‡هڈ‚و•°م€‚é€ڑè؟‡ن¸ٹè؟°وژھو–½ï¼Œهڈ¯ن»¥...
و€»çڑ„و¥è¯´ï¼Œè§£ه†³Ajaxن¹±ç پé—®é¢کçڑ„ه…³é”®هœ¨ن؛ژçگ†è§£ه—符编ç پçڑ„ه·¥ن½œهژںçگ†ï¼Œç،®ن؟و•°وچ®هœ¨و•´ن¸ھن¼ 输è؟‡ç¨‹ن¸çڑ„ç¼–ç پن¸ژ解ç پن¸€è‡´و€§ï¼Œن»¥هڈٹو£ç،®è®¾ç½®وœچهٹ،ه™¨ه’Œه®¢وˆ·ç«¯çڑ„ç¼–ç پ设置م€‚هœ¨ه®é™…ه؛”用ن¸ï¼Œè؟که؛”考虑跨ه¹³هڈ°ه’Œè·¨وµڈ览ه™¨çڑ„ه…¼ه®¹و€§ï¼Œن»¥ç،®ن؟解ه†³...
و€»ç»“و¥è¯´ï¼Œè§£ه†³Strutsن¸‹çڑ„و±‰ه—ن¹±ç پé—®é¢ک,需è¦پن»ژé،µé¢م€پè؟‡و»¤ه™¨م€پوœچهٹ،ه™¨é…چç½®ه’ŒStrutsو ¸ه؟ƒServletç‰ه¤ڑو–¹é¢è؟›è،Œè®¾ç½®ï¼Œç،®ن؟هœ¨و•´ن¸ھ请و±‚ç”ںه‘½ه‘¨وœںن¸ï¼Œن¸و–‡ه—符ه§‹ç»ˆن»¥و£ç،®çڑ„ç¼–ç پè؟›è،Œه¤„çگ†م€‚è؟™ن¸چن»…و¶‰هڈٹن؛†ه‰چ端çڑ„ه±•ç¤؛,è؟کو¶‰هڈٹهˆ°...
ن¸و–‡ن¹±ç پé—®é¢کهˆ†وگ ...ن¸و–‡ن¹±ç پé—®é¢کوک¯ Java ه’Œ JSP ه¼€هڈ‘ن¸çڑ„ن¸€ç§چه¸¸è§پé—®é¢ک,解ه†³è؟™ن؛›é—®é¢ک需è¦پو³¨و„ڈç¼–ç پو–¹ه¼ڈçڑ„ن¸€è‡´و€§ï¼Œéپ؟ه…چهœ¨ن¸چهگŒçڑ„ç¼–ç پو–¹ه¼ڈن¹‹é—´çڑ„转وچ¢ï¼Œç،®ن؟هœ¨ن¸چهگŒçڑ„ن؛¤ن؛’è؟‡ç¨‹ن¸ن½؟用çڑ„ç¼–ç پو–¹ه¼ڈن؟وŒپن¸€è‡´م€‚