
问题
有这样一个问题是很常见的:如果我们的Hive使用默认使用Tez作为执行引擎,当我们使用IDE通过Hive JDBC连接时,会出现在一个很“有趣”的想象:即如果我们不断开这个JDBC连接,则在Yarn上会持续有有一个Tez的AM容器持续存在,只有当端开JDBC连接时,这个容器才会被释放。关于Tez在Yarn的资源布局,可参考这篇文章:https://zh.hortonworks.com/blog/introducing-tez-sessions/ ,其中一张直观的图如下:
当团队拥有一个资源较为充裕的集群时,这不会是一个问题,并且维持这样一个Tez的AM容器是有好处的,好处就是:避免每次执行SQL时重新初始化容器。当如果我们的集群资源有限,使用的人又较多时,这个问题就会导致一个很糟糕的状况:那就是每个人连接到Hive时就会有一个Tez的AM容器生成,相应的至少有一个cpu core要分配出去,如果总的核数较小,单JDBC连接就会挤占掉所有的资源。(注:实际上,Yarn并不会等到所有的核都被占用,而是当所有AM容器占用的资源达到一定的比例时,就不会再允许新的应用提交了,这个比例的参数项名为:yarn.scheduler.capacity.maximum-am-resource-percent,默认0.2, 即20%)
解决方案
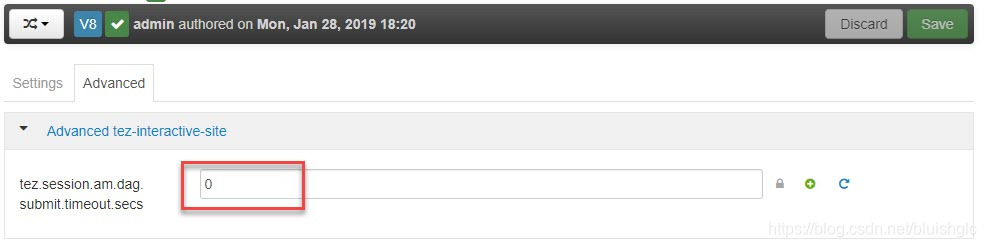
显然,在资源有限的前提下,我们不能让一个session长期存在,只要存在一个session就会有一个core被占用着无法释放,所以我们要让session存在的时间尽可能的短!而控制一个session生命周期长短的参数其实主要是它的超时时间,这个参数是:tez.session.am.dag.submit.timeout.secs, 在Hive和Tez上都有这个配置,默认值是一个比较大的数值,如果我们想尽可能早的释放掉资源,就把这个值设为0,最为了稳妥,最好是在Tez和Hive上都进行设置!
以HDP为例,Tez设置为:

Hive设置为:
————————————————
版权声明:本文为CSDN博主「bluishglc」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/bluishglc/article/details/86703939



相关推荐
Hive JDBC连接是Java应用程序与Hive数据仓库进行交互的一种方式。它允许程序通过标准的JDBC接口查询和操作Hive中的数据。在使用Hive JDBC进行连接时,需要依赖一系列的jar包来确保所有必要的功能得以实现。下面将...
hive-jdbc
本教程将深入讲解如何使用Hive JDBC在Java项目中建立与Hive的连接,并通过Maven来管理依赖。 首先,让我们了解Hive JDBC的基本概念。JDBC是Java中用于数据库访问的标准API,它定义了一组接口和类,使得开发者可以...
apache seatunnel支持hive jdbc
标题中的"jdbc连接hive数据库的驱动jar包"指的是Hive JDBC驱动的Java类库文件,通常是一个.jar文件,包含了所有必要的类和方法,使得Java应用程序能够建立到Hive服务器的连接,执行查询并获取结果。这个“jar包”...
Hive JDBC是Apache Hive项目的一部分,它提供了一个Java数据库连接(JDBC)接口,使得其他应用程序,如Python、Java或任何支持JDBC的环境,能够与Hive进行交互。Hive JDBC驱动程序允许用户通过标准的JDBC API来执行...
首先,Hive JDBC驱动是Java程序连接Hive服务的关键组件,它实现了JDBC接口,使得我们可以在Java应用程序、Web应用或任何支持JDBC的环境中操作Hive。"JDBC驱动"标签明确指出,这个压缩包包含的就是这样的驱动文件。 ...
7. **错误处理和调试**:Hive JDBC提供了详细的错误信息和日志记录,帮助开发者诊断和解决连接、查询或数据加载等问题。 8. **API文档**:Hive-jdbc-3.1.1.zip可能包含了Javadoc文档,这为开发者提供了详细的API...
hive权限,通过自定义jar对hive的10000端口进行权限管控,直接放入到hive所在的lib环境下,然后对xml文件进行相应的配置
Hive JDBC驱动是连接Hadoop生态系统中的Hive数据仓库的重要桥梁,它允许用户通过Java数据库连接(JDBC)标准来访问Hive。在Hive 2.5.15和2.6.1这两个版本中,都包含了对Hive查询语言(HQL)的支持以及对大数据处理的...
这里我们将深入探讨五个在Hive on Tez中常见的报错问题及其解决方案。 1. 错误一:Failing because I am unlikely to write too。 这个问题是由于Hive中的一个已知bug,具体问题可以在Apache JIRA的HIVE-16398中...
在Dbeaver中,为了连接到Hive服务器,用户需要配置Hive的JDBC驱动,而**hive-jdbc-uber-2.6.5.0-292.jar**就是这个配置过程中不可或缺的部分。用户需要将此驱动添加到Dbeaver的驱动定义中,指定正确的URL、用户名和...
- **版本兼容性**:确保JDBC驱动与你的Hive或Impala版本兼容,否则可能会出现连接问题。 总的来说,通过JDBC,开发人员能够方便地在Java应用中集成Hive和Impala,实现对大数据的高效查询和处理。正确配置JDBC驱动...
hive的jdbc连接,亲身试验可以使用,但有时还需要hive其他环境
cloudera.com为我们提供的hiveserver2-JDBC驱动包,不需要把10几个jar找齐就能使用了。
而Hive JDBC(Java Database Connectivity)是Hive与外部应用交互的重要接口,它允许Java应用程序或者其他支持JDBC的工具连接到Hive服务器,执行Hive查询并获取结果。 标题"hive-jdbc所需jar(精简可用)"表明这个...
Hive JDBC 1.1.0-cdh5.12.1 连接库是Apache Hive项目中的一个重要组件,主要用于允许客户端程序通过Java数据库连接(JDBC)接口与Hive服务器进行交互。这个连接库是专为CDH(Cloudera Distribution Including Apache...
HiveJDBC驱动可直接配合DBeaver使用,新建连接 -> Apache Hive ->编辑驱动设置(删除默认地址) ->添加文件 ->选中下载的文件 ->点击找到类 ->确定
6. log4j-1.2.14.jar:日志记录库,用于收集和处理Hive JDBC连接过程中的日志信息,便于调试和问题排查。 7. libfb303-0.9.0.jar:Facebook的Thrift基础服务协议库,提供了Thrift服务的状态管理和监控功能。 8. ql...
Hive JDBC驱动是连接Hadoop Hive数据库的重要组件,它允许用户通过Java编程语言或任何支持JDBC的工具(如SQL客户端)与Hive进行交互。Hive JDBC 1.1.0版本是这个驱动的一个特定迭代,提供了对Hive查询、数据操作和...