
0. TPC-H是啥
TPC-H是TPC提供的一个benchmark,用来模拟一个现实中的商业应用,可以生成一堆虚构的数据,且自带一些查询,可以导入到各种数据库中来模拟现实需求,检查性能。
具体是怎样的数据见:http://www.tpc.org/tpch/spec/tpch2.16.0.pdf
1. 获取文件
首先到官网 http://www.tpc.org/tpch/ 在右边的 DBGEN & Reference Data Set 下载到下面那个.zip,然后自己选一个路径解压过去。
2. 修改 makefile
在解压的文件夹下面cd到dbgen下,找到makefile.suite。
~/tpch_2_16_1$ cd dbgen
~/tpch_2_16_1/dbgen$ vim makefile.suite
把103~112行左右改成这个样子

CC = gcc # Current values for DATABASE are: INFORMIX, DB2, TDAT (Teradata) # SQLSERVER, SYBASE, ORACLE, VECTORWISE # Current values for MACHINE are: ATT, DOS, HP, IBM, ICL, MVS, # SGI, SUN, U2200, VMS, LINUX, WIN32 # Current values for WORKLOAD are: TPCH DATABASE = MYSQL MACHINE = LINUX WORKLOAD = TPCH #
改动的地方分别是:
- 设定C语言编译器为gcc(如果你用的是其他的编译器就改成其他对应名字)
- DATABASE设为MYSQL(注意注释里写的提供的数据库格式没有mysql,所以等一下要自己写一个格式,见步骤3)
- MACHINE = LINUX 和 WORKLOAD = TPCH 就不用说啥意思了……
改好之后保存为makefile,这样才好用make命令。
3. 修改tpcd.h
// 其实这一步好像没什么用 = = // 不过你上面把DATABASE设成了MYSQL的话就不要跳过这一步,不然编译不了。 // 或者上面那步也可以设成SQLSERVER这步就不用管了
之前说了官方的生成程序没有mysql的格式,所以我们要自己写一个,打开tpcd.h,找一个空白的地方写上
#ifdef MYSQL #define GEN_QUERY_PLAN "" #define START_TRAN "START TRANSACTION" #define END_TRAN "COMMIT" #define SET_OUTPUT "" #define SET_ROWCOUNT "limit %d;\n" #define SET_DBASE "use %s;\n" #endif
这样就定义了一个MYSQL的脚本格式可以用了。
4. 生成dbgen
接下来make,生成数据生成脚本dbgen.
~/tpch_2_16_1/dbgen$ make
这个过程中会有一些关于数据类型的警告,一般可以无视。
make完dbgen目录下之后就会多出很多.o(等到你所有事都干完确定这些没有用了不想留着就make clean,或者直接整个文件夹删掉……)和一个叫dbgen的文件
5. 生成tbl数据文件
接下来要用dbgen生成数据,一共会生成8个表(.tbl)。
查看README里面有命令行参数解说,这里我们在dbgen目录下用
./dbgen -s 1
-s 1 表示生成1G的数据 (如果你之前曾经尝试过生成数据,最好先make clean,再重新make,接着到这步加上-f覆盖掉)
生成之后可以用head命令检查一下tbl们,会看到每一行都有一些用“|”隔开的字段。
6. 修改初始化脚本使mySQL可用
压缩包里自带两个脚本:
- dss.ddl:用来建表
- dss.ri:关联表中primary key和foreign key。
不过这些脚本不能直接在mySQL里用(看README就知道人家根本没考虑过mySQL……),要修改。
dss.ddl的开头需要加上一些给MySQL建立数据库连接用的指令。改完之后是这样:
https://gist.github.com/joyeec9h3/9617329
dss.ri 的情况复杂一些,因为MySQL里添加外键要指明键的名字,所以每个加外键的指令都需要改。前面也有几行MySQL不兼容的东西,改完之后是这样:
https://gist.github.com/joyeec9h3/9617302
如果要直接用这两个脚本请注意:
- dss.ddl开头的tpch是数据库的名字,你也可以换成其他名字,但如果改了,dss.ri里凡是提到“tpch”的地方也要改成对应的数据库名字。
- 这两个脚本用的表名和field名均和tpch文档一致,但tpch自带的测试貌似用了另外的表名。
以下可选,但本教程后面的步骤没有考虑这步
鉴于tpch自带的测试用的表名是小写的,而dss.ddl里面的表名是大写的,我们最好也改成小写……
用vim打开dss.ddl,执行
:%s/TABLE\(.*\)/TABLE\L\1
就可以了。
如果你要事后改,就进到mySQL里,USE tpch,然后用类似于
alter table CUSTOMER rename to customer;
这样的语句改就行了。嫌一个个打麻烦的话就写脚本吧~
7. 建表
打开mysql,执行
mysql> \. ~/tpch_2_16_1/dbgen/dss.ddl
后面那部分是dss.ddl的路径,要按照你的实际存放地址修改
然后可以用
mysql> SHOW DATABASES;
看到有一个叫tpch的数据库,像这样:
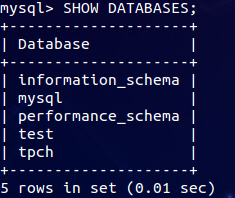
就说明建库成功了。(记得打分号,我老是忘记打分号……)
再执行
mysql> USE tpch; mysql> SHOW TABLES;
可以看到生成的8个表就说明建表成功,像这样

下一步需要添加外键和主键,执行
mysql> \. ~/tpch_2_16_1/dbgen/dss.ri
同样记得dss.ri的路径要改成你的实际存放路径。
如果想看看外键和主键是否添加成功,有没有添加对,可以执行 SHOW CREATE TABLE 表名(觉得默认格式很碍眼可以试试看加上\G垂直打印),像这样:
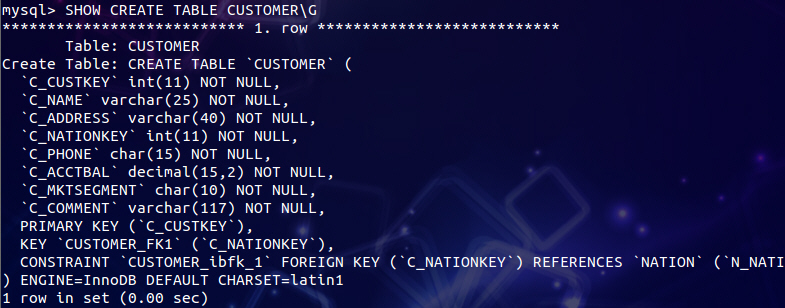
可以看到有哪些限制加进去了。
做完以上步骤之后光有一堆表和限制,里面是没有数据的,需要从之前生成的.tbl里将实际的数据导入进来。
8. 写个导入tbl文件的脚本
你也可以进到mysql然后写一堆类似于
LOAD DATA LOCAL INFILE '/home/joyeecheung/tpch_2_16_1/dbgen/supplier.tbl' INTO TABLE SUPPLIER FIELDS TERMINATED BY '|' LINES TERMINATED BY '|\n';
的东西,不过实在太龟毛了……所以还是写一个bash脚本自动生成这些语句好了。
// 懒得运行脚本生成指令or需要添加外键主键的请往后跳一点直接看成品……
// 不懂bash的人可以看下面,懂的大牛看了这么弱的脚本请别来pia我……
在dbgen目录下新建一个load.sh(或者随便什么名字),把这些东西复制进去
https://gist.github.com/joyeec9h3/9619766
以load.sh为名保存到dbgen目录下,然后执行
sh load.sh
同目录下就会生成一个loaddata.sql,里面是从8个tbl里导入数据的sql指令。
注意如果需要导入外键和主键,要根据各个表的依赖关系调整一下导入各个文件的顺序。(其实就是拓扑排序口桀口桀……不过也就是把八个代码块调整一下顺序而已,这么点工作量就不写代码了)
成品看这里,可以直接复制保存到dbgen目录下进行下一步(要直接用记得替换成你的保存路径):
https://gist.github.com/joyeec9h3/9619336
9. 执行脚本导入数据
在dbgen目录下运行
mysql --local-infile -u root -p < loaddata.sql
记得要加那个 --local-infile,因为MySQL为了安全默认是把从外部文件导入数据的功能关掉的,要导入的话就必须在启动MySQL的时候打开这个功能。
接下来可以喝杯茶等导入。如果你觉得它好像死在那里了,可以再开一个终端,登陆MySQL,用SHOW processlist;看看它在干嘛。
如果你好奇导入多少了,可以用SHOW TABLE STATUS FROM tpch; 看看目前每个表都导入了多少行,对照一下文档里写的1G数据量每个表总共会有几行数据,心里就有谱了。
10. 检查导入结果
按照前面的步骤,如果你不加foreign key和primary key关联的话,导入还是挺快的……
我的本本CPU是i7-2670QM@2.20GHz,虚拟机分配了2个核和2G内存,日立的硬盘分了20G给它(现在一看貌似不够用啊囧),大概7分钟左右就能导入完的样子。如果加了外键和主键速度会显著降低,大约是60多分钟,而且貌似越到后面速度越慢。
导入完了之后可以用
SHOW TABLE STATUS FROM tpch;
看看是不是都导入进去了,对照一下文档的13页,看看每个表行数有没有差太远,我测试是都导进去了,查询结果如下:
mysql> SHOW TABLE STATUS FROM tpch\G;
*************************** 1. row ***************************
Name: CUSTOMER
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 149842
Avg_row_length: 192
Data_length: 28884992
Max_data_length: 0
Index_length: 3686400
Data_free: 130023424
Auto_increment: NULL
Create_time: 2014-03-18 18:43:43
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
*************************** 2. row ***************************
Name: LINEITEM
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 6009452
Avg_row_length: 147
Data_length: 883949568
Max_data_length: 0
Index_length: 218103808
Data_free: 130023424
Auto_increment: NULL
Create_time: 2014-03-18 18:43:43
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
*************************** 3. row ***************************
Name: NATION
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 25
Avg_row_length: 655
Data_length: 16384
Max_data_length: 0
Index_length: 16384
Data_free: 130023424
Auto_increment: NULL
Create_time: 2014-03-18 18:43:43
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
*************************** 4. row ***************************
Name: ORDERS
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 1491770
Avg_row_length: 131
Data_length: 196804608
Max_data_length: 0
Index_length: 39403520
Data_free: 130023424
Auto_increment: NULL
Create_time: 2014-03-18 18:43:43
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
*************************** 5. row ***************************
Name: PART
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 200806
Avg_row_length: 164
Data_length: 33095680
Max_data_length: 0
Index_length: 0
Data_free: 130023424
Auto_increment: NULL
Create_time: 2014-03-18 18:43:43
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
*************************** 6. row ***************************
Name: PARTSUPP
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 778800
Avg_row_length: 267
Data_length: 208388096
Max_data_length: 0
Index_length: 20496384
Data_free: 130023424
Auto_increment: NULL
Create_time: 2014-03-18 18:43:43
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
*************************** 7. row ***************************
Name: REGION
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 5
Avg_row_length: 3276
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 130023424
Auto_increment: NULL
Create_time: 2014-03-18 18:43:43
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
*************************** 8. row ***************************
Name: SUPPLIER
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 9594
Avg_row_length: 274
Data_length: 2637824
Max_data_length: 0
Index_length: 278528
Data_free: 130023424
Auto_increment: NULL
Create_time: 2014-03-18 18:43:43
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
8 rows in set (0.81 sec)
还可以用 SELECT * FROM 表名 LIMIT 数量; 来从表抓几个数据看:
本文转载:
https://www.cnblogs.com/joyeecheung/p/3599698.html
参考链接
http://www.pilhokim.com/index.php?title=Project/EFIM/TPC-H&oldid=90509#Setup_MySQL
http://imysql.cn/2012/12/21/tpch-for-mysql-manual.html
http://my2iu.blogspot.com/2009/01/running-tpc-h-queries-on-mysql.html



相关推荐
在1G的TPC-H数据集中,由于规模较小,可以直接通过SQL命令行或ETL工具快速导入。 5. **性能测试**:一旦数据成功导入,就可以运行TPC-H的22个标准查询来测试数据库的性能。这些查询涵盖各种复杂度,从简单的聚合到...
4. **生成数据**: 使用编译后的`dbgen`工具,指定数据规模(如1GB、10GB等),生成TPC-H测试数据并导入到MySQL数据库。 5. **创建表结构**: 在MySQL中,运行`dbgen`生成的SQL脚本来创建符合TPC-H规范的表结构。 6. *...
在实际操作中,你需要将这些 CSV 文件导入到你的数据库管理系统(如 MySQL, PostgreSQL, 或者大数据处理平台如 Hadoop HDFS)中,以便执行 TPC-H 查询。 对于 BI 开发者和数据库管理员,了解如何高效地加载和查询 ...
1. **TPC-H数据生成器**:这个工具负责生成符合TPC-H规范的测试数据集,数据规模可按需调整,从小到几百MB,大到几十TB不等。 2. **SQL脚本**:预定义的一系列SQL查询,这些查询涵盖了TPC-H的22个标准查询,涵盖了...
TPCC-MYSQL提供了一个tpcc_load工具,用于将数据导入到数据库中。可以使用以下命令导入数据: ```sql ./tpcc_load -h 192.168.65.3 -P 3306 -d tpcc -u root -p 123 -w 2 ``` 其中,-h指定了服务器主机,-P指定了...
使用`gen_data`命令行工具生成TPC-H数据集。这通常涉及指定规模因子,数据将被写入到预先创建的数据库表中。例如,`gen_data -sf 1`将生成1GB的数据。 5. **加载数据** 生成的数据需要导入到MySQL服务器。可以...
其中,“TPCH.dmp”文件很可能是用于实验的数据导入文件,它可能包含了标准的TPC-H基准测试数据集,这种数据集广泛用于衡量数据库在处理复杂商业智能查询时的性能。而“readme.txt”通常是提供指南或说明的文本文件...
3. 数据迁移:测试数据从旧版本迁移到新版本的过程,包括数据导入导出、数据类型兼容性和事务一致性。 4. 安全性:验证新版本的安全特性,如加密、访问控制和审计日志,确保数据安全。 5. 稳定性与可靠性:通过长...
此外,这里还提到了一些与数据导入相关的其他文章,它们可能涵盖了一些实际操作中遇到的问题和解决办法,例如如何从SQLite导入到MySQL,如何使用PHP处理CSV数据,以及在MySQL中使用`LOAD DATA INFILE`的技巧,还有...
5. 数据导入:Doris支持多种数据导入方式,包括HTTP方式的本地数据导入,Kafka流式数据导入,以及HDFS文件的批量导入。 6. 数据模型和查询处理:Doris的数据模型以Key列和Value列为主,支持对Key列进行快速查询定位...
完成上述两项改动之后,TiDB 在 OLAP 场景下的性能有了大幅的质的提升,从 TPC-H 的对比结果来看,所有的 Query 在 2.0 中都运行得更快,一些 Query 大多数都有几倍甚至数量级的提升,特别是一些 1.0 中跑不出结果的...