
一、代码
package com.sgcc.hj
import java.sql.DriverManager
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
object JdbcTest {
def main(args: Array[String]) {
val conf = new SparkConf()
val sc = new SparkContext(conf)
val rdd = new JdbcRDD(
sc,
() => {
Class.forName("oracle.jdbc.driver.OracleDriver").newInstance()
DriverManager.getConnection("jdbc:oracle:thin:@172.16.222.112:1521:pms", "scyw", "scyw")
},
"SELECT * FROM MW_APP.CMST_AIRPRESSURE WHERE 1 = ? AND rownum < ?",
1, 10, 1,
r => (r.getString(1),r.getString(2),r.getString(5)))
rdd.collect().foreach(println)
sc.stop()
}
}
二、运行截图
命令:spark-submit --master yarn --jars /opt/test/data/oracle.jdbc_10.2.0.jar --name OracleRead --class com.sgcc.hj.JdbcTest--executor-memory 1G /opt/test/data/sparktest.jar(注意这里依赖了oracle的jar包要在加上)
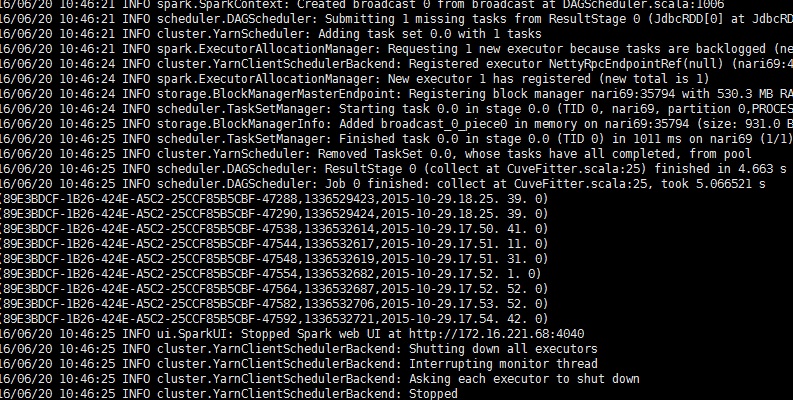
三、答疑
1、官方文档地址:
https://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.rdd.JdbcRDD
2、JdbcRdd中的构造参数:
前面三个就不解释了,一眼就可以看懂,后面三个数字,前两个表示SQL中的参数,必须是LONG型,而且必须有,这个是Spark源码要求的,如果没有LONG型的条件,可以使用1=1这种参数(第三个参数要为1);第三个参数表示分区查询,例如给定前两个参数为1和20,第三个参数为2,那么SQL就会执行两次,第一次参数为(1, 10),第二次为(11, 20);最后一个参数是函数,这里表示把一条记录里的第1、2、5个字段组成三元组,当然也可以变成别的形式。



相关推荐
本教程将探讨如何使用 Scala 语言来操作 Spark,并介绍如何与 MySQL 数据库和 HDFS(Hadoop 分布式文件系统)进行交互。以下是相关知识点的详细说明: **1. Scala 语言基础** Scala 是一种多范式编程语言,融合了...
Oracle数据库是目前广泛使用的大型关系型数据库管理系统之一。在日常的数据库维护和管理过程中,经常会用到各种操作指令来完成特定的任务。针对Oracle数据库,常用的操作指令可以分为数据控制语句(DML)、数据定义...
在大数据处理领域,Spark...通过这个项目,学习者可以深入理解Spark在大数据处理中的实际应用,掌握Scala和Java混合编程,以及如何利用Maven管理项目,同时了解实时处理和批处理的结合,从而提升大数据处理的实战技能。
Scala和Spark是大数据分析领域中的两个重要工具,它们在处理大规模数据时表现出强大的性能和灵活性。Scala是一种静态类型的函数式编程语言,而Spark是一个分布式计算框架,尤其适合于大数据处理和分析。本教程将深入...
通过以上步骤,我们可以高效地利用Scala和MyBatis实现数据库查询。这种结合不仅保持了Scala的优雅和强大,还充分利用了MyBatis的便利性。在实际项目中,这种集成方式能够帮助开发者快速开发出稳定、高性能的数据访问...
在这部分文件内容中,我们首先看到了对Spark解析CSV文件并存入数据库的一个简单介绍。接下来,会逐步展开几个重要知识点,包括Spark框架的基础、如何使用Spark读取和解析CSV文件、数据处理的相关操作以及如何将处理...
在本集成示例中,我们将探讨如何将Spring Boot与Apache Spark 2.4.4以及Scala 2.12版本相结合,实现一个简单的"Hello World"应用。Spring Boot以其便捷的微服务开发能力,而Apache Spark是大数据处理领域中的一员...
在Scala中使用Spark,可以通过DataFrame或RDD API处理大量时间序列数据,并利用Spark的并行计算能力加速模型训练和预测过程。 四、Spark ARIMA实现 在Spark上实现ARIMA模型,通常需要借助专门的库,如`sparkts`库,...
1. **兼容性**:Spark SQL支持通过Hive的元数据、SQL语法和Hive SerDes与Hive集成,使得在Spark上可以无缝地运行Hive的工作负载。 2. **DataFrame API**:DataFrame API提供了强类型和静态类型的API,支持Scala、...
在技术细节上,`greenplum-connector-apache-spark-scala_2.11-2.2.0.jar`是连接器的核心库文件,它包含了所有必要的类和方法,使得Spark应用程序能够识别和连接Greenplum。开发者在构建Spark应用时,需要将这个JAR...
同时,这也是学习Spark和Scala语言实际应用的好教材,通过阅读和实践,可以加深对大数据处理流程和工具的理解。 总之,这个项目展示了如何在Spark中运用Scala和IKAnalyzer进行中文分词统计,帮助我们探索和理解古代...
5. 编写和运行代码:使用Scala编写Spark程序,然后通过ECLIPSE的运行配置来启动Spark集群并提交作业。 总之,Spark Scala开发依赖包对于在ECLIPSE中进行大数据处理项目至关重要。正确配置这些依赖将使开发者能够在...
在Spark的世界里,Scala语言扮演着至关重要的角色。Spark框架由Scala编写,这使得它具有高效、可扩展...通过阅读《Spark实战高手之路》的三个部分,相信你将在Scala和Spark的世界中渐行渐远,成为一名真正的技术专家。
本设计源码提供了一个基于Scala的Spark模型转换为PMML格式。项目包含21个文件,主要使用Scala编程语言,并包含了Java。文件类型包括9个XML配置文件、2个CRC文件、2个Scala源代码文件、1个名称文件、1个Markdown文档...
Spark Scala API 是一个用于大数据处理的强大工具,它结合了Apache Spark的高性能计算框架与Scala编程语言的简洁性和表达力。这个zip压缩包很可能是包含了Spark的Scala开发接口及相关示例,便于开发者在Scala环境中...
综上所述,这个项目展示了如何构建一个现代化的大数据处理系统,该系统使用Spring Boot提供易于使用的HTTP接口,通过Scala编写Spark作业,实现高效的数据计算。这样的架构有助于简化开发过程,同时保持了高性能的...
基于Spark1.6,使用Spark SQL框架和sqlite数据库,把唐诗三百首,宋诗三百首和元明清诗精选导入数据库,可以按来源,体裁及作者,方便地查出诗句或试题中包含某个关键字的作品,还可以在选中作品后,进行五绝,七绝...
对于想学习 Spark 的人而言,如何构建 Spark 集群是其最大的难点之一, 为了解决大家构建 Spark 集群的一切困难,Spark 集群的构建分为了五个步骤,从 零起步,不需要任何前置知识,涵盖操作的每一个细节,构建完整...
在Spark中,Scala用于定义数据处理逻辑,通过RDD(弹性分布式数据集)或者DataFrame/Dataset API进行操作,这些API提供了丰富的转换和行动操作,如map、filter、reduce等,支持并行计算,极大地提高了处理速度。...
最新版本的scala-2.11.8与Spark2.1.0环境搭建