
1.client端指定Job的各种参数配置之后调用job.waitForCompletion(true) 方法提交Job给JobTracker,等待Job 完成。
- public void submit() throws IOException, InterruptedException,
- ClassNotFoundException {
- ensureState(JobState.DEFINE);//检查JobState状态
- setUseNewAPI();//检查及设置是否使用新的MapReduce API
- // Connect to the JobTracker and submit the job
- connect();//链接JobTracker
- info = jobClient.submitJobInternal(conf);//将job信息提交
- super.setJobID(info.getID());
- state = JobState.RUNNING;//更改job状态
- }
以上代码主要有两步骤,连接JobTracker并提交Job信息。connect方法主要是实例化JobClient对象,包括设置JobConf和init工作:
- public void init(JobConf conf) throws IOException {
- String tracker = conf.get("mapred.job.tracker", "local");//读取配置文件信息用于判断该Job是运行于本地单机模式还是分布式模式
- tasklogtimeout = conf.getInt(
- TASKLOG_PULL_TIMEOUT_KEY, DEFAULT_TASKLOG_TIMEOUT);
- this.ugi = UserGroupInformation.getCurrentUser();
- if ("local".equals(tracker)) {//如果是单机模式,new LocalJobRunner
- conf.setNumMapTasks(1);
- this.jobSubmitClient = new LocalJobRunner(conf);
- } else {
- this.jobSubmitClient = createRPCProxy(JobTracker.getAddress(conf), conf);
- }
- }
分布式模式下就会创建一个RPC代理链接:
- public static VersionedProtocol getProxy(
- Class<? extends VersionedProtocol> protocol,
- long clientVersion, InetSocketAddress addr, UserGroupInformation ticket,
- Configuration conf, SocketFactory factory, int rpcTimeout) throws IOException {
- if (UserGroupInformation.isSecurityEnabled()) {
- SaslRpcServer.init(conf);
- }
- VersionedProtocol proxy =
- (VersionedProtocol) Proxy.newProxyInstance(
- protocol.getClassLoader(), new Class[] { protocol },
- new Invoker(protocol, addr, ticket, conf, factory, rpcTimeout));
- long serverVersion = proxy.getProtocolVersion(protocol.getName(),
- clientVersion);
- if (serverVersion == clientVersion) {
- return proxy;
- } else {
- throw new VersionMismatch(protocol.getName(), clientVersion,
- serverVersion);
- }
- }
从上述代码可以看出hadoop实际上使用了Java自带的Proxy API来实现Remote Procedure Call
初始完之后,需要提交job
- info = jobClient.submitJobInternal(conf);//将job信息提交
submit方法做以下几件事情:
1.将conf中目录名字替换成hdfs代理的名字
2.检查output是否合法:比如路径是否已经存在,是否是明确的
3.将数据分成多个split并放到hdfs上面,写入job.xml文件
4.调用JobTracker的submitJob方法
该方法主要新建JobInProgress对象,然后检查访问权限和系统参数是否满足job,最后addJob:
- private synchronized JobStatus addJob(JobID jobId, JobInProgress job)
- throws IOException {
- totalSubmissions++;
- synchronized (jobs) {
- synchronized (taskScheduler) {
- jobs.put(job.getProfile().getJobID(), job);
- for (JobInProgressListener listener : jobInProgressListeners) {
- listener.jobAdded(job);
- }
- }
- }
- myInstrumentation.submitJob(job.getJobConf(), jobId);
- job.getQueueMetrics().submitJob(job.getJobConf(), jobId);
- LOG.info("Job " + jobId + " added successfully for user '"
- + job.getJobConf().getUser() + "' to queue '"
- + job.getJobConf().getQueueName() + "'");
- AuditLogger.logSuccess(job.getUser(),
- Operation.SUBMIT_JOB.name(), jobId.toString());
- return job.getStatus();
- }
totalSubmissions记录client端提交job到JobTracker的次数。而jobs则是JobTracker所有可以管理的job的映射表
Map<JobID, JobInProgress> jobs = Collections.synchronizedMap(new TreeMap<JobID, JobInProgress>());
taskScheduler是用于调度job先后执行策略的,其类图如下所示:
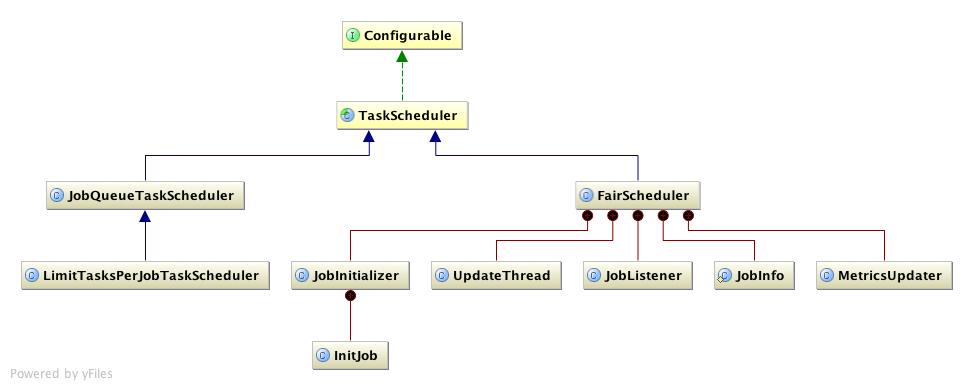
hadoop job调度机制;
public enum SchedulingMode {
FAIR, FIFO
}
1.公平调度FairScheduler
对于每个用户而言,分布式资源是公平分配的,每个用户都有一个job池,假若某个用户目前所占有的资源很多,对于其他用户而言是不公平的,那么调度器就会杀掉占有资源多的用户的一些task,释放资源供他人使用
2.容量调度JobQueueTaskScheduler
在分布式系统上维护多个队列,每个队列都有一定的容量,每个队列中的job按照FIFO的策略进行调度。队列中可以包含队列。
两个Scheduler都要实现TaskScheduler的public synchronized List<Task> assignTasks(TaskTracker tracker)方法,该方法通过具体的计算生成可以分配的task
接下来看看JobTracker的工作:
记录更新JobTracker重试的次数:
- while (true) {
- try {
- recoveryManager.updateRestartCount();
- break;
- } catch (IOException ioe) {
- LOG.warn("Failed to initialize recovery manager. ", ioe);
- // wait for some time
- Thread.sleep(FS_ACCESS_RETRY_PERIOD);
- LOG.warn("Retrying...");
- }
- }
启动Job调度器,默认是FairScheduler:
taskScheduler.start();主要是初始化一些管理对象,比如job pool管理池
- // Initialize other pieces of the scheduler
- jobInitializer = new JobInitializer(conf, taskTrackerManager);
- taskTrackerManager.addJobInProgressListener(jobListener);
- poolMgr = new PoolManager(this);
- poolMgr.initialize();
- loadMgr = (LoadManager) ReflectionUtils.newInstance(
- conf.getClass("mapred.fairscheduler.loadmanager",
- CapBasedLoadManager.class, LoadManager.class), conf);
- loadMgr.setTaskTrackerManager(taskTrackerManager);
- loadMgr.setEventLog(eventLog);
- loadMgr.start();
- taskSelector = (TaskSelector) ReflectionUtils.newInstance(
- conf.getClass("mapred.fairscheduler.taskselector",
- DefaultTaskSelector.class, TaskSelector.class), conf);
- taskSelector.setTaskTrackerManager(taskTrackerManager);
- taskSelector.start();
- JobInitializer有一个确定大小的ExecutorService threadPool,每个thread用于初始化job
- try {
- JobStatus prevStatus = (JobStatus)job.getStatus().clone();
- LOG.info("Initializing " + job.getJobID());
- job.initTasks();
- // Inform the listeners if the job state has changed
- // Note : that the job will be in PREP state.
- JobStatus newStatus = (JobStatus)job.getStatus().clone();
- if (prevStatus.getRunState() != newStatus.getRunState()) {
- JobStatusChangeEvent event =
- new JobStatusChangeEvent(job, EventType.RUN_STATE_CHANGED, prevStatus,
- newStatus);
- synchronized (JobTracker.this) {
- updateJobInProgressListeners(event);
- }
- }
- }
初始化操作主要用于初始化生成tasks然后通知其他的监听者执行其他操作。initTasks主要处理以下工作:
- // 记录用户提交的运行的job信息
- try {
- userUGI.doAs(new PrivilegedExceptionAction<Object>() {
- @Override
- public Object run() throws Exception {
- JobHistory.JobInfo.logSubmitted(getJobID(), conf, jobFile,
- startTimeFinal, hasRestarted());
- return null;
- }
- });
- } catch(InterruptedException ie) {
- throw new IOException(ie);
- }
- // 设置并记录job的优先级
- setPriority(this.priority);
- //
- //生成每个Task需要的密钥
- //
- generateAndStoreTokens();
然后读取JobTracker split的数据的元信息,元信息包括以下属性信息:
- private TaskSplitIndex splitIndex;//洗牌后的索引位置
- private long inputDataLength;//洗牌后数据长度
- private String[] locations;//数据存储位置
然后根据元信息的长度来计算numMapTasks并校验数据存储地址是否可以连接
接下来生成map tasks和reducer tasks:
- maps = new TaskInProgress[numMapTasks];
- for(int i=0; i < numMapTasks; ++i) {
- inputLength += splits[i].getInputDataLength();
- maps[i] = new TaskInProgress(jobId, jobFile,
- splits[i],
- jobtracker, conf, this, i, numSlotsPerMap);
- }
- this.jobFile = jobFile;
- this.splitInfo = split;
- this.jobtracker = jobtracker;
- this.job = job;
- this.conf = conf;
- this.partition = partition;
- this.maxSkipRecords = SkipBadRecords.getMapperMaxSkipRecords(conf);
- this.numSlotsRequired = numSlotsRequired;
- setMaxTaskAttempts();
- init(jobid);
以上除了task对应的jobTracker,split信息和job信息外,还设置了
- maxSkipRecords ---记录task执行的时候最大可以跳过的错误记录数;
- <pre name="code" class="java">setMaxTaskAttempts--设置task最多可以执行的次数。当一个task执行两次都失败了之后,会以skip mode模式再重新执行一次,记录那些bad record,
- 然后第四次再执行的时候,跳过这些bad records</pre><p></p>
- <pre></pre>
- 新建reducer task的过程也很类似。
- <p></p>
- <p><br>
- </p>
- <p><br>
- </p>
- <p><br>
- </p>
- <p><br>
- </p>
- <p></p>



相关推荐
基于Hadoop的成绩分析系统 本文档介绍了基于Hadoop的成绩分析系统的设计和实现。Hadoop是一个分布式开源计算平台,具有高可靠性、高扩展性、高效性和高容错性等特点。该系统使用Hadoop的分布式文件系统HDFS和...
Hive是建立在Hadoop之上的数据仓库工具,它允许用户使用SQL-like语言进行数据查询和分析,简化了大数据分析的过程。Hive将SQL语句转换为MapReduce任务运行在Hadoop集群上,提供了一种更易用的接口来处理Hadoop中的大...
如何使用hadoop进行数据分析.zip 如何使用hadoop进行数据分析.zip 如何使用hadoop进行数据分析.zip 如何使用hadoop进行数据分析.zip 如何使用hadoop进行数据分析.zip 如何使用hadoop进行数据分析.zip 如何使用hadoop...
【基于Hadoop豆瓣电影数据分析实验报告】 在大数据时代,对海量信息进行高效处理和分析是企业决策的关键。Hadoop作为一款强大的分布式计算框架,自2006年诞生以来,已经在多个领域展现了其卓越的数据处理能力。本...
,Hadoop 技术已经在互联网领域得到了广泛的应用。...同样也得到了许多公司的青睐,如百度主要将Hadoop 应用于日志分析和网页数据库的数据 挖掘;阿里巴巴则将Hadoop 用于商业数据的排序和搜索引擎的优化等。
针对本次实验,我们需要用到Hadoop集群作为模拟大数据的分析软件,集群环境必须要包括,hdfs,hbase,hive,flume,sqoop等插件,最后结合分析出来的数据进行可视化展示,需要用到Python(爬取数据集,可视化展示)...
本主题将深入探讨Hadoop在数据分析中的应用及其生态系统的关键技术。 首先,我们需要理解“大数据”的概念。大数据指的是无法用传统数据库软件工具捕获、管理和处理的大规模数据集。这些数据集通常具有三个关键特征...
HDFS 是 Hadoop 的核心组件之一,是一个分布式文件系统。HDFS 的主要功能是提供一个高可靠、高可扩展的文件系统,可以存储大量的数据。HDFS 的架构主要包括以下几个部分: * Namenode:负责管理文件系统的命名空间...
【基于Hadoop的电影影评数据分析】是一项大数据课程的大作业,旨在利用Hadoop的分布式处理能力来分析电影影评数据。Hadoop是一个由Apache软件基金会开发的开源框架,专为处理和存储大规模数据而设计。它由四个核心...
Hadoop源代码分析完整版.pdf
Hadoop豆瓣电影数据分析(Hadoop)操作源码
**基于Hadoop平台的数据仓库可行性分析报告** **1. 引言** 在信息化时代,企业对数据处理的需求日益增长,传统的数据仓库系统由于其规模、性能和灵活性的限制,已经无法满足现代企业对大数据处理的需求。Hadoop作为...
使用hadoop进行数据分析天气数据分析.zip使用hadoop进行数据分析天气数据分析.zip使用hadoop进行数据分析天气数据分析.zip使用hadoop进行数据分析天气数据分析.zip使用hadoop进行数据分析天气数据分析.zip使用hadoop...
《Hadoop源代码分析》是一本深入探讨Hadoop核心组件MapReduce的专著。Hadoop是Apache软件基金会的一个开源项目,旨在提供分布式存储和计算框架,以处理和存储大量数据。MapReduce是Hadoop的核心计算模型,它通过将大...
基于Hadoop网站流量日志数据分析系统 1、典型的离线流数据分析系统 2、技术分析 - Hadoop - nginx - flume - hive - mysql - springboot + mybatisplus+vcharts nginx + lua 日志文件埋点的 基于Hadoop网站流量...
深入云计算:Hadoop源代码分析(修订版)
### 深入云计算 Hadoop源代码分析 #### 一、引言 随着大数据时代的到来,数据处理成为了各个领域中的关键技术之一。Hadoop作为一个开源的大数据处理框架,因其优秀的分布式计算能力,在业界得到了广泛的应用。...
Hadoop源码分析是深入理解Hadoop分布式计算平台原理的起点,通过源码分析,可以更好地掌握Hadoop的工作机制、关键组件的实现方式和内部通信流程。Hadoop项目包括了多个子项目,其中最核心的是HDFS和MapReduce,这两...
本文将深入探讨“Hadoop之外卖订单数据分析系统”,并介绍如何利用Hadoop进行大规模数据处理,以及如何将分析结果通过可视化手段进行展示。 首先,我们需要理解Hadoop的核心组件:HDFS(Hadoop Distributed File ...