äļŠäššč§įđïžåĪ§æ°æŪæäŧŽé―įĨéhadoopïžä―åđķäļé―æŊhadoop.æäŧŽčŊĨåĶä―æåŧšåĪ§æ°æŪåšéĄđįŪãåŊđäšįĶŧįšŋåĪįïžhadoopčŋæŊæŊčūéåįïžä―æŊåŊđäšåŪæķæ§æŊčūåžšįïžæ°æŪéæŊčūåĪ§įïžæäŧŽåŊäŧĨéįĻStormïžéĢäđStormåäŧäđææŊæé
ïžæč―åĪåäļäļŠéåčŠå·ąįéĄđįŪãäļéĒįŧåĪ§åŪķåŊäŧĨåčã
åŊäŧĨåļĶįäļéĒéŪéĒæĨé
čŊŧæŽæįŦ ïž
1.äļäļŠåĨ―įéĄđįŪæķæåščŊĨå
·åĪäŧäđįđįđïž
2.æŽéĄđįŪæķææŊåĶä―äŋčŊæ°æŪåįĄŪæ§įïž
3.äŧäđæŊKafkaïž
4.flume+kafkaåĶä―æīåïž
5.ä―ŋįĻäŧäđčæŽåŊäŧĨæĨįflumeææēĄæåūKafkaäž čūæ°æŪ
åč―Ŋäŧķåžåįé―įĨéæĻĄååææģïžčŋæ ·čŪūčŪĄįåå æäļĪæđéĒïž
äļæđéĒæŊåŊäŧĨæĻĄååïžåč―ååæīå æļ
æ°ïžäŧâæ°æŪéé--æ°æŪæĨå
Ĩ--æĩåĪąčŪĄįŪ--æ°æŪčūåš/ååĻâ
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;"> Â
Â
1ïž.æ°æŪéé
čīčīĢäŧåčįđäļåŪæķééæ°æŪïžéįĻclouderaįflumeæĨåŪį°
2ïž.æ°æŪæĨå
Ĩ
įąäšééæ°æŪįéåšĶåæ°æŪåĪįįéåšĶäļäļåŪåæĨïžå æĪæ·ŧå äļäļŠæķæŊäļéīäŧķæĨä―äļšįžåēïžéįĻapacheįkafka
3ïž.æĩåžčŪĄįŪ
åŊđééå°įæ°æŪčŋčĄåŪæķåæïžéįĻapacheįstorm
4ïž.æ°æŪčūåš
åŊđåæåįįŧææäđ
åïžæåŪįĻmysql
åĶäļæđéĒæŊæĻĄååäđåïžååĶå―Stormææäšäđåïžæ°æŪééåæ°æŪæĨå
ĨčŋæŊįŧ§įŧåĻč·įïžæ°æŪäļäžäļĒåĪąïžstormčĩ·æĨäđååŊäŧĨįŧ§įŧčŋčĄæĩåžčŪĄįŪïž
Â
éĢäđæĨäļæĨæäŧŽæĨįäļæīä―įæķæåū
<ignore_js_op style="word-wrap: break-word;">
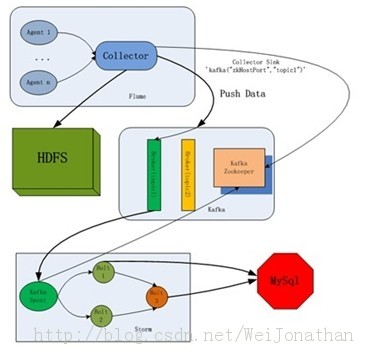
Â
Â
čŊĶįŧäŧįŧåäļŠįŧäŧķååŪčĢ
é
į―Ūïž
æä―įģŧįŧïžubuntu
Â
Flume
FlumeæŊClouderaæäūįäļäļŠååļåžãåŊé ãåéŦåŊįĻįæĩ·éæĨåŋééãčååäž čūįæĨåŋæķéįģŧįŧïžæŊæåĻæĨåŋįģŧįŧäļåŪåķåįąŧæ°æŪåéæđïžįĻäšæķéæ°æŪ;åæķïžFlumeæäūåŊđæ°æŪčŋčĄįŪååĪįïžåđķåå°åį§æ°æŪæĨåæđ(åŊåŪåķ)įč―åã
äļåūäļšflumeå
ļåįä―įģŧįŧæïž
Flumeæ°æŪæšäŧĨåčūåšæđåž:
Flumeæäūäšäŧconsole(æ§åķå°)ãRPC(Thrift-RPC)ãtext(æäŧķ)ãtail(UNIX tail)ãsyslog(syslogæĨåŋįģŧįŧïžæŊæTCPåUDPį2į§æĻĄåž)ïžexec(å―äŧĪæ§čĄ)įæ°æŪæšäļæķéæ°æŪįč―å,åĻæäŧŽįįģŧįŧäļįŪåä―ŋįĻexecæđåžčŋčĄæĨåŋééã
Flumeįæ°æŪæĨåæđïžåŊäŧĨæŊconsole(æ§åķå°)ãtext(æäŧķ)ãdfs(HDFSæäŧķ)ãRPC(Thrift-RPC)åsyslogTCP(TCP syslogæĨåŋįģŧįŧ)įãåĻæäŧŽįģŧįŧäļįąkafkaæĨæĨæķã
Flumeäļč――åææĄĢïž
http://flume.apache.org/
FlumeåŪčĢ
ïž
- $tar zxvf apache-flume-1.4.0-bin.tar.gz/usr/local
FlumeåŊåĻå―äŧĪïž
- $bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name producer -Dflume.root.logger=INFO,console
Kafka
Â
kafkaæŊäļį§éŦååéįååļåžååļčŪĒé
æķæŊįģŧįŧïžåĨđæåĶäļįđæ§ïž
- éčŋO(1)įįĢįæ°æŪįŧææäūæķæŊįæäđ
åïžčŋį§įŧæåŊđäšåģä―ŋæ°äŧĨTBįæķæŊååĻäđč―åĪäŋæéŋæķéīįįĻģåŪæ§č―ã
- éŦååéïžåģä―ŋæŊéåļļæŪéįįĄŽäŧķkafkaäđåŊäŧĨæŊææŊį§æ°åäļįæķæŊã
- æŊæéčŋkafkaæåĄåĻåæķčīđæšéįūĪæĨååšæķæŊã
- æŊæHadoopåđķčĄæ°æŪå č――ã
kafkaįįŪįæŊæäūäļäļŠååļčŪĒé
č§ĢåģæđæĄïžåŪåŊäŧĨåĪįæķčīđč
č§æĻĄįį―įŦäļįææåĻä―æĩæ°æŪã čŋį§åĻä―ïžį―éĄĩæĩč§ïžæįīĒåå
ķäŧįĻæ·įčĄåĻïžæŊåĻį°äŧĢį―įŧäļįčŪļåĪįĪūäžåč―įäļäļŠå
ģéŪå įī ã čŋäšæ°æŪéåļļæŊįąäšååéįčĶæąčéčŋåĪįæĨåŋåæĨåŋčåæĨč§Ģåģã åŊđäšåHadoopįäļæ ·įæĨåŋæ°æŪåįĶŧįšŋåæįģŧįŧïžä―åčĶæąåŪæķåĪįįéåķïžčŋæŊäļäļŠåŊčĄįč§ĢåģæđæĄãkafkaįįŪįæŊéčŋHadoopįåđķčĄå č――æšåķæĨįŧäļįšŋäļåįĶŧįšŋįæķæŊåĪįïžäđæŊäļšäšéčŋéįūĪæšæĨæäūåŪæķįæķčīđã
kafkaååļåžčŪĒé
æķæåĶäļåūïž--åčŠKafkaåŪį―
<ignore_js_op style="word-wrap: break-word;">
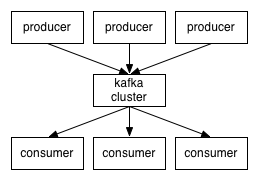
į―åŪå
åžæįŦ äļįæķæåūæŊčŋæ ·į
<ignore_js_op style="word-wrap: break-word;">
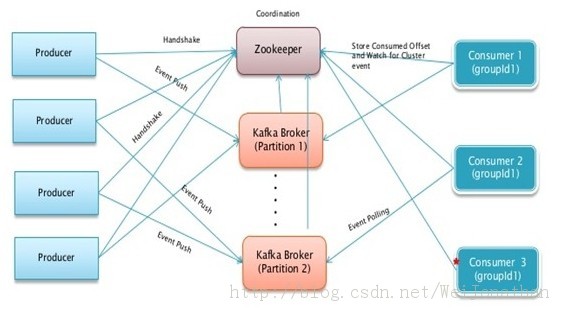
å
ķåŪäļĪč
æēĄæåĪŠåĪ§åšåŦïžåŪį―įæķæåūåŠæŊæKafkaįŪæīįčĄĻįĪšæäļäļŠKafka ClusterïžčäļéĒæķæåūå°ąįļåŊđčŊĶįŧäļäšïž
Â
KafkaįæŽïž0.8.0
KafkaåŪčĢ
ïž
- > tar xzf kafka-<VERSION>.tgz
- > cd kafka-<VERSION>
- > ./sbt update
- > ./sbt package
- > ./sbt assembly-package-dependency
åŊåĻåæĩčŊå―äŧĪïž
ïž1ïž start server
Â
- > bin/zookeeper-server-start.shconfig/zookeeper.properties
- > bin/kafka-server-start.shconfig/server.properties
čŋéæŊåŪį―äļįæįĻïžkafkaæŽčšŦæå
į―Ūzookeeperïžä―æŊæčŠå·ąåĻåŪé
éĻį―ēäļæŊä―ŋįĻåįŽįzookeeperéįūĪïžæäŧĨįŽŽäļčĄå―äŧĪæå°ąæēĄæ§čĄïžčŋéåŠæŊäšåšæĨįŧåĪ§åŪķįäļã
Â
é
į―ŪįŽįŦįzookeeperéįūĪéčĶé
į―Ūserver.propertiesæäŧķïžčŪēzookeeper.connectäŋŪæđäļšįŽįŦéįūĪįIPåįŦŊåĢ
Â
- zookeeper.connect=nutch1:2181
ïž2ïžCreate a topic
Â
- > bin/kafka-create-topic.sh --zookeeper localhost:2181 --replica 1 --partition 1 --topic test
- > bin/kafka-list-topic.sh --zookeeperlocalhost:2181
ïž3ïžSend some messages
Â
- > bin/kafka-console-producer.sh--broker-list localhost:9092 --topic test
ïž4ïžStart a consumer
Â
- > bin/kafka-console-consumer.sh--zookeeper localhost:2181 --topic test --from-beginning
kafka-console-producer.shåkafka-console-cousumer.shåŠæŊįģŧįŧæäūįå―äŧĪčĄå·Ĩå
·ãčŋéåŊåĻæŊäļšäšæĩčŊæŊåĶč―æĢåļļį䚧æķčīđïžéŠčŊæĩįĻæĢįĄŪæ§
åĻåŪé
åžåäļčŋæŊčĶčŠčĄåžåčŠå·ąįį䚧č
äļæķčīđč
ïž
Storm
Twitterå°StormæĢåžåžæšäšïžčŋæŊäļäļŠååļåžįãåŪđéįåŪæķčŪĄįŪįģŧįŧïžåŪčĒŦæįŪĄåĻGitHubäļïžéĩåūŠÂ  Eclipse Public License 1.0ãStormæŊįąBackTypeåžåįåŪæķåĪįįģŧįŧïžBackTypeį°åĻå·ēåĻTwitteréšūäļãGitHubäļįææ°įæŽæŊStorm 0.5.2ïžåšæŽæŊįĻClojureåįã
<ignore_js_op style="word-wrap: break-word;">
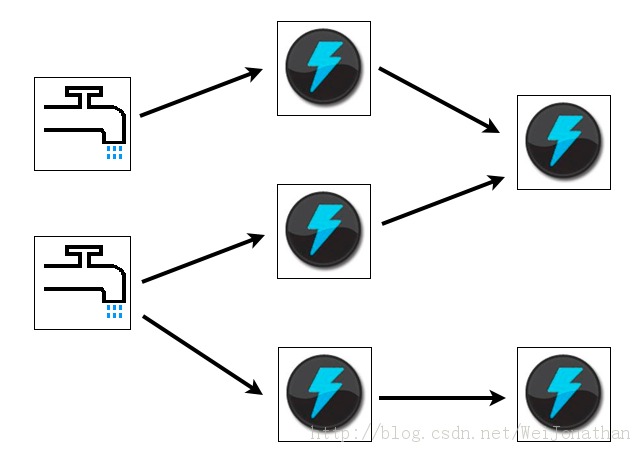
Â
Â
StormįäļŧčĶįđįđåĶäļïž
- įŪåįįžįĻæĻĄåãįąŧäžžäšMapReduceéä―äšåđķčĄæđåĪįåĪææ§ïžStorméä―äščŋčĄåŪæķåĪįįåĪææ§ã
- åŊäŧĨä―ŋįĻåį§įžįĻčŊčĻãä― åŊäŧĨåĻStormäđäļä―ŋįĻåį§įžįĻčŊčĻãéŧčŪĪæŊæClojureãJavaãRubyåPythonãčĶåĒå åŊđå
ķäŧčŊčĻįæŊæïžåŠéåŪį°äļäļŠįŪåįStorméäŋĄåčŪŪåģåŊã
- åŪđéæ§ãStormäžįŪĄįå·Ĩä―čŋįĻåčįđįæ
éã
- æ°īåđģæĐåąãčŪĄįŪæŊåĻåĪäļŠįšŋįĻãčŋįĻåæåĄåĻäđéīåđķčĄčŋčĄįã
- åŊé įæķæŊåĪįãStormäŋčŊæŊäļŠæķæŊčģå°č―åūå°äļæŽĄåŪæīåĪįãäŧŧåĄåĪąčīĨæķïžåŪäžčīčīĢäŧæķæŊæšéčŊæķæŊã
- åŋŦéãįģŧįŧįčŪūčŪĄäŋčŊäšæķæŊč―åūå°åŋŦéįåĪįïžä―ŋįĻÃMQä―äļšå
ķåšåąæķæŊéåãïž0.9.0.1įæŽæŊæÃMQånettyäļĪį§æĻĄåžïž
- æŽå°æĻĄåžãStormæäļäļŠâæŽå°æĻĄåžâïžåŊäŧĨåĻåĪįčŋįĻäļåŪå
ĻæĻĄæStorméįūĪãčŋčŪĐä― åŊäŧĨåŋŦéčŋčĄåžåååå
æĩčŊã
æĨäļæĨéåĪīæåžå§æïžéĢå°ąæŊæĄæķäđéīįæīååĶ
Â
flumeåkafkaæīå
2.æåæäŧķäļįflume-conf.propertiesæäŧķ
äŋŪæđčŊĨæäŧķïž#source section
producer.sources.s.type = exec
producer.sources.s.command = tail -f -n+1 /mnt/hgfs/vmshare/test.log
producer.sources.s.channels = c
äŋŪæđæætopicįåžæđäļštest
å°æđåįé
į―Ūæäŧķæūčŋflume/confįŪå―äļ
åĻčŊĨéĄđįŪäļæåäŧĨäļjarå
æūå
ĨįŊåĒäļflumeįlibäļïž
æģĻïžčŋéįflumeng-kafka-plugin.jarčŋäļŠå
ïžåéĒåĻgithubéĄđįŪäļå·ēįŧį§ŧåĻå°packageįŪå―äšãæūäļå°įįŦĨéåŊäŧĨå°packageįŪå―č·åã
Â
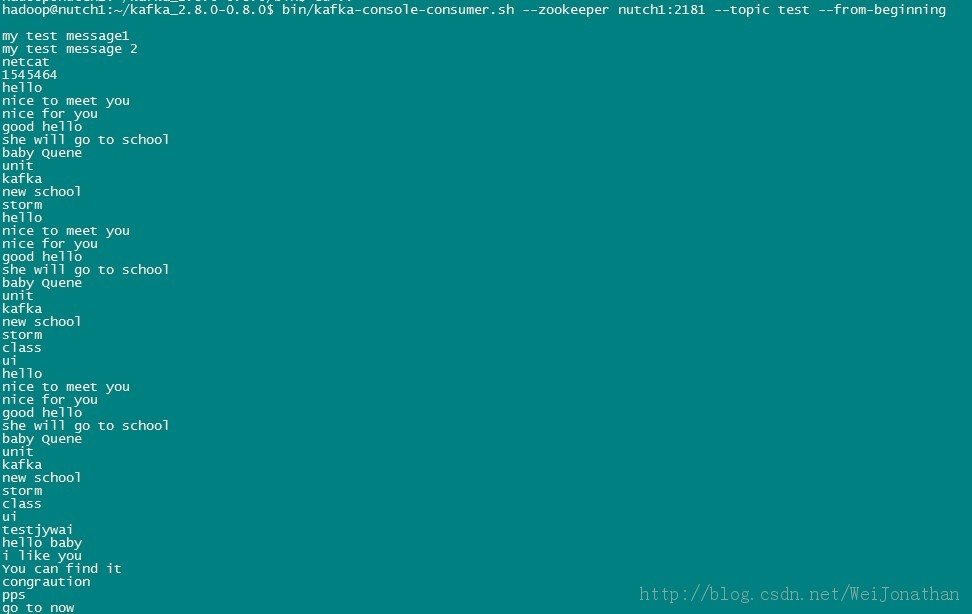
åŪæäļéĒįæĨéŠĪäđåïžæäŧŽæĨæĩčŊäļflume+kafkačŋäļŠæĩįĻææēĄæčĩ°éïž
æäŧŽå
åŊåĻflumeïžįķåååŊåĻkafkaïžåŊåĻæĨéŠĪæäđåįæĨéŠĪæ§čĄïžæĨäļæĨæäŧŽä―ŋįĻkafkaįkafka-console-consumer.shčæŽæĨįæŊåĶæflumeææēĄæåūKafkaäž čūæ°æŪïž
<ignore_js_op style="word-wrap: break-word;">
Â
äŧĨäļčŋäļŠæŊæįtest.logæäŧķéčŋflumeæåäž å°kafkaįæ°æŪïžčŊīææäŧŽįflumeåkafkaæĩįĻčĩ°éäšïž
åĪ§åŪķčŋčŪ°åūååžå§æäŧŽįæĩįĻåūäđïžå
ķäļæäļæĨæŊéčŋflumeå°kafkaïžčŋæäļæĨæŊå°hdfsįïžčæäŧŽčŋčūđčŋæēĄææå°åĶä―åå
ĨkafkaäļåæķååĶhdfsïž
<ignore_js_op style="word-wrap: break-word;">

Â
æäđčŪūį―ŪåæĨåĪåķåĒïžįäļéĒįé
į―Ūïž
Â
- #2äļŠchannelå2äļŠsinkįé
į―ŪæäŧķÂ Â čŋéæäŧŽåŊäŧĨčŪūį―ŪäļĪäļŠsinkïžäļäļŠæŊkafkaįïžäļäļŠæŊhdfsįïž
- a1.sources = r1
- a1.sinks = k1 k2
- a1.channels = c1 c2
å
·ä―é
į―ŪåĪ§äžæ đæŪčŠå·ąįéæąåŧčŪūį―Ūïžčŋéå°ąäļå
·ä―äļūäūäš
Â
kafkaåstormįæīå
Â
2.ä―ŋįĻmaven packagečŋčĄįžčŊïžåūå°storm-kafka-0.8-plus-0.3.0-SNAPSHOT.jarå
  --æč―Žč――įįŦĨéæģĻæäļïžčŋéįå
åäđååéäšïžį°åĻæđæĢįĄŪäšïžäļåĨ―ææïž
3.å°čŊĨjarå
åkafka_2.9.2-0.8.0-beta1.jarãmetrics-core-2.2.0.jarãscala-library-2.9.2.jar (čŋäļäļŠjarå
åĻkafkaéĄđįŪäļč―æūå°)
åĪæģĻïžåĶæåžåįéĄđįŪéčĶå
ķäŧjarïžčŪ°åūäđčĶæūčŋstormįLibäļæŊåĶįĻå°äšmysqlå°ąčĶæ·ŧå mysql-connector-java-5.1.22-bin.jarå°stormįlibäļ
éĢäđæĨäļæĨæäŧŽæstormäđéåŊäļïž
åŪæäŧĨäļæĨéŠĪäđåïžæäŧŽčŋæäļäŧķäšæ
čĶåïžå°ąæŊä―ŋįĻkafka-storm0.8æäŧķïžåäļäļŠčŠå·ąįStormįĻåšïž
å
įĻåūŪįäļįĻåšįååŧšTopologyäŧĢį
<ignore_js_op style="word-wrap: break-word;">

Â
æ°æŪæä―äļŧčĶåĻWordCounterįąŧäļïžčŋéåŠæŊä―ŋįĻįŪåJDBCčŋčĄæå
ĨåĪį
<ignore_js_op style="word-wrap: break-word;">

Â
čŋéåŠéčĶčūå
ĨäļäļŠåæ°ä―äļšTopologyåį§°å°ąåŊäŧĨäšïžæäŧŽčŋéä―ŋįĻæŽå°æĻĄåžïžæäŧĨäļčūå
Ĩåæ°ïžįīæĨįæĩįĻæŊåĶčĩ°éïž
Â
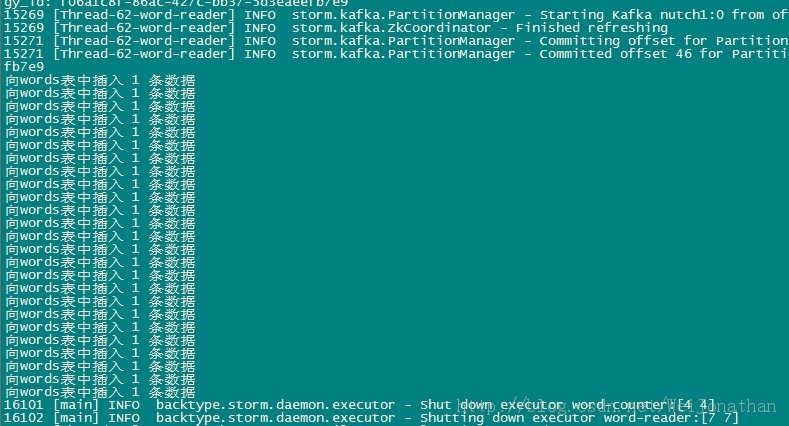
- storm-0.9.0.1/bin/storm jar storm-start-demo-0.0.1-SNAPSHOT.jar com.storm.topology.MyTopology
å
įäļæĨåŋïžčŋéæå°åšæĨäšåūæ°æŪåšééĒæå
Ĩæ°æŪäš
<ignore_js_op style="word-wrap: break-word;">
Â
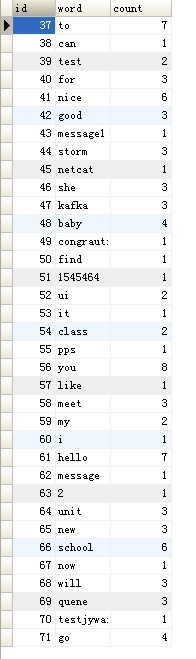
įķåæäŧŽæĨįäļæ°æŪåšïžæå
Ĩæåäšïž
<ignore_js_op style="word-wrap: break-word;">
Â
å°čŋéæäŧŽįæīäļŠæīåå°ąåŪæäšïž
ä―æŊčŋéčŋæäļäļŠéŪéĒïžäļįĨéåĪ§äžææēĄæåį°ã
įąäšæäŧŽä―ŋįĻstormčŋčĄååļåžæĩåžčŪĄįŪïžéĢäđååļåžæéčĶæģĻæįæŊæ°æŪäļčīæ§äŧĨåéŋå
čæ°æŪį䚧įïžæäŧĨææäūįæĩčŊéĄđįŪåŠč―įĻäšæĩčŊïžæĢåžåžåäļč―čŋæ ·åĪįïž
æĻčēæįĐšJ2EEïžäļäļŠį―åïžįŧįåŧščŪŪæŊåŧšįŦäļäļŠzookeeperįååļåžå
ĻåąéïžäŋčŊæ°æŪäļčīæ§ïžéŋå
čæ°æŪå―å
Ĩïž
zookeeperåŪĒæ·įŦŊæĄæķåĪ§äžåŊäŧĨä―ŋįĻNetflix CuratoræĨåŪæïžįąäščŋåæčŋæēĄåŧįïžæäŧĨåŠč―åå°čŋéäšïž
http://blog.csdn.net/weijonathan/article/details/18301321
æĨčŠįūĪįŧ: HadoopææŊįŧ
Â
http://www.aboutyun.com/thread-6855-1-1.html
Â





įļå ģæĻč
åĻčŋäļŠčŋįĻäļïžææĄĢãTwitter Stormįģŧåãflume-ng+Kafka+Storm+HDFS åŪæķįģŧįŧæåŧš.docxåãåŪčĢ æčŪ°.pdfãå°æäūčŊĶįŧįæĨéŠĪæåŊžååļļč§éŪéĒč§ĢåģæđæĄïžåļŪåĐä― éĄšåĐåŪææīäļŠįģŧįŧįæåŧšåäžåã æŧįæĨčŊīïžLNMPäļåŪæķåĪ§...
įīäŧĨæĨé―æģæĨč§ĶStormåŪæķčŪĄįŪčŋåįäļčĨŋïžæčŋåĻįūĪéįå°äļæĩ·äļåĨäŧŽį―åŪåįFlume+Kafka+StormįåŪæķæĨåŋæĩįģŧįŧįæåŧšææĄĢïžčŠå·ąäđč·įæīäšäļéïžäđåį―åŪįæįŦ äļæäļäščĶæģĻæįđæēĄæå°įïžäŧĨåäļäšåéįįđïžåĻčŋčūđ...
åŊåĻFlumeæķïžä―ŋįĻflume-ngå―äŧĪåđķæåŪé į―ŪæäŧķåäŧĢįåį§°ã KafkaįåŪčĢ åé į―ŪčŋįĻå æŽäļč――æšį å ïžæ§čĄsbtæīæ°ãæå ãįŧčĢ å äūčĩïžäŧĨåæ§čĄåŊåĻčæŽãåŊåĻKafkaæåĄéčĶå åŊåĻZookeeperæåĄïžįķååŊåĻKafkaæåĄ...
æ éĒäļįâåĐįĻFlumeå°MySQLčĄĻæ°æŪååŪæķæ―åå°HDFSãMySQLãKafkaâæŊäļéĄđæ°æŪéæäŧŧåĄïžæķåApache FlumeãMySQLæ°æŪåšãHadoop Distributed File System (HDFS) åApache KafkačŋåäļŠå ģéŪææŊãFlumeæŊApacheįäļ...
æŽæå°čŊĶįŧäŧįŧåĶä―åĐįĻKafkaãFlumeNGãStormäļHBaseæåŧšäļåĨéŦæįæ°æŪåĪįįģŧįŧãčŊĨįģŧįŧæĻåĻåŪį°äŧĨäļįŪæ ïž - åŪæķåĪįäŧŧæč§æĻĄįæ°æŪéã - æŊæåĪį§įąŧåįåĪįæä―ã - įŧååĪį§ææŊåå·Ĩå ·ïžæåŧšäļäļŠå Ļæđä―įåĪ§...
åĻåĪ§æ°æŪåĪįéĒåïžFlumeãKafkaåStormæŊäļäļŠčģå ģéčĶįå·Ĩå ·ïžåŪäŧŽååŦåĻæ°æŪééãæ°æŪååååŪæķåĪįæđéĒåæĨįæ ļåŋä―įĻãčŋéæäŧŽå°æ·ąå ĨæĒčŪĻčŋäļäļŠįŧäŧķäŧĨååĶä―æåŧšåŪäŧŽã 1. FlumeïžFlumeæŊApacheč―Ŋäŧķåšéäžį...
åĻåĪ§æ°æŪåĪįéĒåïžFlumeãKafkaåStormæŊäļäļŠéåļļéčĶįå·Ĩå ·ïžåŪäŧŽååŦčīčīĢæ°æŪééãæķæŊäļéīäŧķååŪæķæĩåĪįã"flume-kafka-stormæšįĻåš"čŋäļŠåįžĐå åūåŊč―æŊå åŦčŋäļäļŠįŧäŧķįéæįĪšäūæč æšäŧĢį ïžįĻäšåļŪåĐåžåč ...
åĻåŪé åšįĻäļïžFlume NG 1.6.0-cdh5.14.0 åļļåļļäļå ķäŧåĪ§æ°æŪįŧäŧķåĶ HadoopãKafka å Storm įŧåä―ŋįĻïžæåŧšåĪæįæ°æŪåĪįæĩæ°īįšŋãäūåĶïžåŊäŧĨå ä―ŋįĻ Flume äŧåĪå°æåĄåĻæķéæĨåŋæ°æŪïžįķåéčŋ Kafka čŋčĄæķæŊéå...
- **åŊåĻFlume**ïžæ§čĄ`bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name a1 -Dflume.root.logger=INFO,console`åŊåĻFlume Agentã 2. **KafkaįŊåĒæåŧš**ïž - **åŪčĢ Zookeeper**ïžKafkaäūčĩ...
### åŪæķæĨåŋåæįĨčŊįđčŊĶč§Ģ ...įŧžäļæčŋ°ïžFlume-ng+Kafka+Storm+HDFSææäšäļäļŠåžšåĪ§įåŪæķæĨåŋåæįģŧįŧïžäļäŧ č―åĪæŧĄčķģå―åéĄđįŪįéæąïžčŋå ·åĪčŊåĨ―įæĐåąæ§åįŧīæĪæ§ïžéįĻäšåĪ§č§æĻĄįæĨåŋåĪįåšæŊã
čŋäļŠææĄĢæŊãäščŪĄįŪäđFlume+Kafka+Storm+Redis/Hbase+Hadoop+Hive+Mahout+Spark ææŊææĄĢåäšŦV1.0.0ãįģŧåįäļéĻåïžæķĩįäšåĪį§äščŪĄįŪææŊã éĶå ïžHadoop-2.2.0æŊäļäļŠåžæšįååļåžčŪĄįŪæĄæķïžå ķæ ļåŋįąHDFSïžHadoop ...
æŽæåŊđåšäš Flume įįūåĒæĨåŋæķéįģŧįŧčŋčĄäščŊĶįŧįäŧįŧååæïžå æŽæĨåŋæķéįģŧįŧįæķæčŪūčŪĄãFlume-NG äļ Scribe įæŊčūãįūåĒæĨåŋæķéįģŧįŧįæķæåčŪūčŪĄãįūåĒæĨåŋæķéįģŧįŧįčŪūčŪĄåäžåįæđéĒãåæķïžæŽæčŋåŊđ Flume...
emsiteæĄæķéæäšdubboæåĄåąãåįđįŧå―ãAuth2.0čŪĪčŊãstorm+kafkaæķæŊåĪįįģŧįŧãæĨåŋåæįģŧįŧïžkafka+ flume+storm+hdfs+hadoopïžãé į―ŪäļåŋãååļåžäŧŧåĄč°åšĶįģŧįŧãæåĄåĻåŪæķįæ§įģŧįŧäŧĨåæįīĒåžæįģŧįŧïželastic...
Flume-NGæŊäļäļŠéŦåŊįĻãéŦåŊé įååļåžæĨåŋééįģŧįŧïžįąClouderaåžååđķå·ēįšģå ĨApacheéĄđįŪãäļScribeįļæŊïžFlume-NGåĻåŪđéæ§ååŊæĐåąæ§æđéĒčĄĻį°åščēãåŪäļäŧ åĻAgentåCollectoräđéīïžäđåĻCollectoråStoreäđéīæäūäš...
- emsiteéįĻdubboä―äļšæåĄåąæĄæķïžåå°å°éæåįđįŧå―ãoauth2.0ãstorm+kafkaæķæŊåĪįįģŧįŧãkafka+ flume+storm+hdfs+hadoopä―äļšæĨåŋåæįģŧįŧãé į―ŪäļåŋãååļåžäŧŧåĄč°åšĶįģŧįŧãæåĄåĻåŪæķįæ§įģŧįŧãæįīĒåžæįģŧįŧ...
éįĻdubboä―äļšæåĄåąæĄæķïžåå°å°éæåįđįŧå―ãAuth2.0ãstorm+kafkaæķæŊåĪįįģŧįŧãkafka+ flume+storm+hdfs+hadoopä―äļšæĨåŋåæįģŧįŧãé į―ŪäļåŋãååļåžäŧŧåĄč°åšĶįģŧįŧãæåĄåĻåŪæķįæ§įģŧįŧãæįīĒåžæįģŧįŧ(elastic...
- **Kafka+Flume+Storm åĻįšŋčŪĄįŪïž** éįĻäšåŪæķæ°æŪæĩåĪįã - **Flume+Kafka+HDFS įĻäš MR įĶŧįšŋčŪĄįŪïž** éįĻäšæđåĪįä―äļã - **Kafka+Spark įĻäšæ°æŪææåæšåĻåĶäđ ïž** äļšåĪæįæ°æŪåæäŧŧåĄæäūäšåžšåĪ§įæŊæã...
ãäščŪĄįŪãæĪåĪïžæįĻčŋæķåäšäščŪĄįŪįļå ģįææŊïžåĶKafkaïžååļåžæķæŊįģŧįŧïžãStormïžåŪæķæĩåĪįïžãSparkïžåŋŦéåĪ§æ°æŪåĪįåžæïžäŧĨåOozieïžå·Ĩä―æĩč°åšĶåĻïžãImpalaïžäšĪäšåžæĨčŊĒæåĄïžãSolrïžå ĻææįīĒåžæïžįïž...