
This page is not necessarily kept up to date - for the latest SolrCloud documentation see https://cwiki.apache.org/confluence/display/solr/SolrCloud

Contents
- SolrCloud
- Getting Started
- ZooKeeper
- Managing collections via the Collections API
- Collection Aliases
- Creating cores via CoreAdmin
- Distributed Requests
- Required Config
- Re-sizing a Cluster
- Near Realtime Search
- Parameter Reference
- Getting your Configuration Files into ZooKeeper
- Known Limitations
- Glossary
- FAQ
SolrCloud
SolrCloud is the name of a set of new distributed capabilities in Solr. Passing parameters to enable these capabilities will enable you to set up a highly available, fault tolerant cluster of Solr servers. Use SolrCloud when you want high scale, fault tolerant, distributed indexing and search capabilities.
Look at the following 'Getting Started' section to quickly learn how to start up a cluster. There are 3 quick examples to follow, each showing how to startup a progressively more complicated cluster. After checking out the examples, consult the following sections for more detailed information as needed.
A little about SolrCores and Collections
On a single instance, Solr has something called a SolrCore that is essentially a single index. If you want multiple indexes, you create multiple SolrCores. With SolrCloud, a single index can span multiple Solr instances. This means that a single index can be made up of multiple SolrCore's on different machines. We call all of these SolrCores that make up one logical index a collection. A collection is a essentially a single index that spans many SolrCore's, both for index scaling as well as redundancy. If you wanted to move your 2 SolrCore Solr setup to SolrCloud, you would have 2 collections, each made up of multiple individual SolrCores.
Getting Started
Download Solr 4-Beta or greater: http://lucene.apache.org/solr/downloads.html
If you haven't yet, go through the simple Solr Tutorial to familiarize yourself with Solr. Note: reset all configuration and remove documents from the tutorial before going through the cloud features. Copying the example directories with pre-existing Solr indexes will cause document counts to be off.
Solr embeds and uses Zookeeper as a repository for cluster configuration and coordination - think of it as a distributed filesystem that contains information about all of the Solr servers
If you want to use a port other than 8983 for Solr, see the note about solr.xml under Parameter Reference below.
Example A: Simple two shard cluster

This example simply creates a cluster consisting of two solr servers representing two different shards of a collection.
Since we'll need two solr servers for this example, simply make a copy of the example directory for the second server -- making sure you don't have any data already indexed.
rm -r example/solr/collection1/data/* cp -r example example2
This command starts up a Solr server and bootstraps a new solr cluster.
cd example java -Dbootstrap_confdir=./solr/collection1/conf -Dcollection.configName=myconf -DzkRun -DnumShards=2 -jar start.jar
-
-DzkRun causes an embedded zookeeper server to be run as part of this Solr server.
-
-Dbootstrap_confdir=./solr/collection1/conf Since we don't yet have a config in zookeeper, this parameter causes the local configuration directory ./solr/conf to be uploaded as the "myconf" config. The name "myconf" is taken from the "collection.configName" param below.
-
-Dcollection.configName=myconf sets the config to use for the new collection. Omitting this param will cause the config name to default to "configuration1".
-
-DnumShards=2 the number of logical partitions we plan on splitting the index into.
Browse to http://localhost:8983/solr/#/~cloud to see the state of the cluster (the zookeeper distributed filesystem).
You can see from the zookeeper browser that the Solr configuration files were uploaded under "myconf", and that a new document collection called "collection1" was created. Under collection1 is a list of shards, the pieces that make up the complete collection.
Now we want to start up our second server - it will automatically be assigned to shard2 because we don't explicitly set the shard id.
Then start the second server, pointing it at the cluster:
cd example2 java -Djetty.port=7574 -DzkHost=localhost:9983 -jar start.jar
-
-Djetty.port=7574 is just one way to tell the Jetty servlet container to use a different port.
-
-DzkHost=localhost:9983 points to the Zookeeper ensemble containing the cluster state. In this example we're running a single Zookeeper server embedded in the first Solr server. By default, an embedded Zookeeper server runs at the Solr port plus 1000, so 9983.
If you refresh the zookeeper browser, you should now see both shard1 and shard2 in collection1. View http://localhost:8983/solr/#/~cloud.
Next, index some documents. If you want to whip up some Java you can use the CloudSolrServer solrj impl and simply init it with the address to ZooKeeper. Or simply randomly choose which instance to add documents too - they will be automatically forwarded to where they belong:
cd exampledocs java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar ipod_video.xml java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar monitor.xml java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar mem.xml
And now, a request to either server results in a distributed search that covers the entire collection:
http://localhost:8983/solr/collection1/select?q=*:*
If at any point you wish to start over fresh or experiment with different configurations, you can delete all of the cloud state contained within zookeeper by simply deleting the solr/zoo_data directory after shutting down the servers.
Example B: Simple two shard cluster with shard replicas

This example will simply build off of the previous example by creating another copy of shard1 and shard2. Extra shard copies can be used for high availability and fault tolerance, or simply for increasing the query capacity of the cluster.
First, run through the previous example so we already have two shards and some documents indexed into each. Then simply make a copy of those two servers:
cp -r example exampleB cp -r example2 example2B
Then start the two new servers on different ports, each in its own window:
cd exampleB java -Djetty.port=8900 -DzkHost=localhost:9983 -jar start.jar
cd example2B java -Djetty.port=7500 -DzkHost=localhost:9983 -jar start.jar
Refresh the zookeeper browser page Solr Zookeeper Admin UI and verify that 4 solr nodes are up, and that each shard has two replicas.
Because we have been telling Solr that we want two logical shards, starting instances 3 and 4 are assigned to be additional replicas of those shards automatically.
Now send a query to any of the servers to query the cluster:
http://localhost:7500/solr/collection1/select?q=*:*
Send this query multiple times and observe the logs from the solr servers. You should be able to observe Solr load balancing the requests (done via LBHttpSolrServer ?) across replicas, using different servers to satisfy each request. There will be a log statement for the top-level request in the server the browser sends the request to, and then a log statement for each sub-request that are merged to produce the complete response.
To demonstrate fail-over for high availability, press CTRL-C in the window running any one of the Solr servers except the instance running ZooKeeper. (We'll talk about ZooKeeper redundancy in Example C.) Once that server instance terminates, send another query request to any of the remaining servers that are up. You should continue to see the full results.
SolrCloud can continue to serve results without interruption as long as at least one server hosts every shard. You can demonstrate this by judiciously shutting down various instances and looking for results. If you have killed all of the servers for a particular shard, requests to other servers will result in a 503 error. To return just the documents that are available in the shards that are still alive (and avoid the error), add the following query parameter: shards.tolerant=true
SolrCloud uses leaders and an overseer as an implementation detail. This means that some nodes/replicas will play special roles. You don't need to worry if the instance you kill is a leader or the cluster overseer - if you happen to kill one of these, automatic fail over will choose new leaders or a new overseer transparently to the user and they will seamlessly takeover their respective jobs. Any Solr instance can be promoted to one of these roles.
Example C: Two shard cluster with shard replicas and zookeeper ensemble

The problem with example B is that while there are enough Solr servers to survive any one of them crashing, there is only one zookeeper server that contains the state of the cluster. If that zookeeper server crashes, distributed queries will still work since the solr servers remember the state of the cluster last reported by zookeeper. The problem is that no new servers or clients will be able to discover the cluster state, and no changes to the cluster state will be possible.
Running multiple zookeeper servers in concert (a zookeeper ensemble) allows for high availability of the zookeeper service. Every zookeeper server needs to know about every other zookeeper server in the ensemble, and a majority of servers are needed to provide service. For example, a zookeeper ensemble of 3 servers allows any one to fail with the remaining 2 constituting a majority to continue providing service. 5 zookeeper servers are needed to allow for the failure of up to 2 servers at a time.
For production, it's recommended that you run an external zookeeper ensemble rather than having Solr run embedded zookeeper servers. You can read more about setting up a zookeeper ensemble here. For this example, we'll use the embedded servers for simplicity.
First, stop all 4 servers and then clean up the zookeeper data directories for a fresh start.
rm -r example*/solr/zoo_data
We will be running the servers again at ports 8983,7574,8900,7500. The default is to run an embedded zookeeper server at hostPort+1000, so if we run an embedded zookeeper on the first three servers, the ensemble address will be localhost:9983,localhost:8574,localhost:9900.
As a convenience, we'll have the first server upload the solr config to the cluster. You will notice it block until you have actually started the second server. This is due to zookeeper needing a quorum before it can operate.
cd example java -Dbootstrap_confdir=./solr/collection1/conf -Dcollection.configName=myconf -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -DnumShards=2 -jar start.jar
cd example2 java -Djetty.port=7574 -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
cd exampleB java -Djetty.port=8900 -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
cd example2B java -Djetty.port=7500 -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
Now since we are running three embedded zookeeper servers as an ensemble, everything can keep working even if a server is lost. To demonstrate this, kill the exampleB server by pressing CTRL+C in it's window and then browse to the Solr Zookeeper Admin UI to verify that the zookeeper service still works.
Note that when running on multiple hosts, you will need to set -DzkRun=hostname:port on each host to the exact name and port used in -DzkHost -- the default localhostwill not work.
ZooKeeper
Multiple Zookeeper servers running together for fault tolerance and high availability is called an ensemble. For production, it's recommended that you run an external zookeeper ensemble rather than having Solr run embedded servers. See the Apache ZooKeeper site for more information on downloading and running a zookeeper ensemble. More specifically, try Getting Started and ZooKeeper Admin. It's actually pretty simple to get going. You can stick to having Solr runZooKeeper, but keep in mind that a ZooKeeper cluster is not easily changed dynamically. Until further support is added to ZooKeeper, changes are best done with rolling restarts. Handling this in a separate process from Solr will usually be preferable.
When Solr runs an embedded zookeeper server, it defaults to using the solr port plus 1000 for the zookeeper client port. In addition, it defaults to adding one to the client port for the zookeeper server port, and two for the zookeeper leader election port. So in the first example with Solr running at 8983, the embedded zookeeper server used port 9983 for the client port and 9984,9985 for the server ports.
In terms of trying to make sure ZooKeeper is setup to be very fast, keep a few things in mind: Solr does not use ZooKeeper intensively - optimizations may not be necessary in many cases. Also, while adding more ZooKeeper nodes will help some with read performance, it will slightly hurt write performance. Again, Solr does not really do much with ZooKeeper when your cluster is in a steady state. If you do need to optimize ZooKeeper, here are a few helpful notes:
-
ZooKeeper works best when it has a dedicated machine. ZooKeeper is a timely service and a dedicated machine helps ensure timely responses. A dedicated machine is not required however.
-
ZooKeeper works best when you put its transaction log and snap-shots on different disk drives.
-
If you do colocate ZooKeeper with Solr, using separate disk drives for Solr and ZooKeeper will help with performance.
Managing collections via the Collections API
The collections API let's you manage collections. Under the hood, it generally uses the CoreAdmin API to asynchronously (though Overseer) manage SolrCores on each server - it's essentially sugar for actions that you could handle yourself if you made individual CoreAdmin API calls to each server you wanted an action to take place on.
About the params:
-
name: The name of the collection to be created.
-
numShards: The number of logical shards (sometimes called slices) to be created as part of the collection.
-
replicationFactor: The number of copies of each document (or, the number of physical replicas to be created for each logical shard of the collection.) A replicationFactor of 3 means that there will be 3 replicas (one of which is normally designated to be the leader) for each logical shard. NOTE: in Solr 4.0, replicationFactor was the number of *additional* copies as opposed to the total number of copies.
-
maxShardsPerNode : A create operation will spread numShards*replicationFactor shard-replica across your live Solr nodes - fairly distributed, and never two replica of the same shard on the same Solr node. If a Solr is not live at the point in time where the create operation is carried out, it will not get any parts of the new collection. To prevent too many replica being created on a single Solr node, use maxShardsPerNode to set a limit for how many replicas the create operation is allowed to create on each node - default is 1. If it cannot fit the entire collection numShards*replicationFactor replicas on you live Solrs it will not create anything at all.
-
createNodeSet: If not provided the create operation will create shard-replica spread across all of your live Solr nodes. You can provide the "createNodeSet" parameter to change the set of nodes to spread the shard-replica across. The format of values for this param is "<node-name1>,<node-name2>,...,<node-nameN>" - e.g. "localhost:8983_solr,localhost:8984_solr,localhost:8985_solr"
-
collection.configName: The name of the config (must be already stored in zookeeper) to use for this new collection. If not provided the create operation will default to the collection name as the config name.
About the params:
-
name: The name of the collection alias to be created.
-
collections: A comma-separated list of one or more collections to alias to.
Delete http://localhost:8983/solr/admin/collections?action=DELETE&name=mycollection
About the params:
-
name: The name of the collection to be deleted.
Reload http://localhost:8983/solr/admin/collections?action=RELOAD&name=mycollection
About the params:
-
name: The name of the collection to be reloaded.
Split Shard http://localhost:8983/solr/admin/collections?action=SPLITSHARD&collection=<collection_name>&shard=shardId
About the params:
-
collection: The name of the collection
-
shard: The shard to be split
This command cannot be used by clusters with custom hashing because such clusters do not rely on a hash range. It should only be used by clusters having "plain" or "compositeId" router.
The SPLITSHARD command will create two new shards by splitting the given shard's index into two pieces. The split is performed by dividing the shard's range into two equal partitions and dividing up the documents in the parent shard according to the new sub-ranges. This is a synchronous operation. The new shards will be named by appending _0 and _1 to the parent shard name e.g. if shard=shard1 is to be split, the new shards will be named as shard1_0 and shard1_1. Once the new shards are created, they are set active and the parent shard is set to inactive so that no new requests are routed to the parent shard.
This feature allows for seamless splitting and requires no down-time. The parent shard is not removed and therefore no data is removed. It is up to the user of the command to unload the shard using the new APIs in SOLR-4693 (under construction).
This feature was released with Solr 4.3 however due to bugs found after 4.3 release, it is recommended that you wait for release 4.3.1 before using this feature.
Collection Aliases
Aliasing allows you to create a single 'virtual' collection name that can point to one more real collections. You can update the alias on the fly.
CreateAlias http://localhost:8983/solr/admin/collections?action=CREATEALIAS&name=alias&collections=collection1,collection2,…
Creates or updates a given alias. Aliases that are used to send updates to should only map an alias to a single collection. Read aliases can map an alias to a single collection or multiple collections.
DeleteAlias http://localhost:8983/solr/admin/collections?action=DELETEALIAS&name=alias
Removes an existing alias.
Creating cores via CoreAdmin
New Solr cores may also be created and associated with a collection via CoreAdmin.
Additional cloud related parameters for the CREATE action:
-
collection - the name of the collection this core belongs to. Default is the name of the core.
-
shard - the shard id this core represents (Optional - normally you want to be auto assigned a shard id)
-
numShards - the number of shards you want the collection to have - this is only respected on the first core created for the collection
-
collection.<param>=<value> - causes a property of <param>=<value> to be set if a new collection is being created.
-
Use collection.configName=<configname> to point to the config for a new collection.
-
Example:
curl 'http://localhost:8983/solr/admin/cores?action=CREATE&name=mycore&collection=collection1&shard=shard2'
Distributed Requests
Query all shards of a collection (the collection is implicit in the URL):
http://localhost:8983/solr/collection1/select?
Query all shards of a compatible collection, explicitly specified:
http://localhost:8983/solr/collection1/select?collection=collection1_recent
Query all shards of multiple compatible collections, explicitly specified:
http://localhost:8983/solr/collection1/select?collection=collection1_NY,collection1_NJ,collection1_CT
Query specific shard ids of the (implicit) collection. In this example, the user has partitioned the index by date, creating a new shard every month:
http://localhost:8983/solr/collection1/select?shards=shard_200812,shard_200912,shard_201001
Explicitly specify the addresses of shards you want to query:
http://localhost:8983/solr/collection1/select?shards=localhost:8983/solr,localhost:7574/solr
Explicitly specify the addresses of shards you want to query, giving alternatives (delimited by |) used for load balancing and fail-over:
http://localhost:8983/solr/collection1/select?shards=localhost:8983/solr|localhost:8900/solr,localhost:7574/solr|localhost:7500/solr
Required Config
All of the required config is already setup in the example configs shipped with Solr. The following is what you need to add if you are migrating old config files, or what you should not remove if you are starting with new config files.
schema.xml
You must have a _version_ field defined:
<field name="_version_" type="long" indexed="true" stored="true" multiValued="false"/>
solrconfig.xml
You must have an UpdateLog defined - this should be defined in the updateHandler section.
<!-- Enables a transaction log, currently used for real-time get.
"dir" - the target directory for transaction logs, defaults to the
solr data directory. -->
<updateLog>
<str name="dir">${solr.data.dir:}</str>
<!-- if you want to take control of the synchronization you may specify the syncLevel as one of the
following where ''flush'' is the default. fsync will reduce throughput.
<str name="syncLevel">flush|fsync|none</str>
-->
</updateLog>
You must have a replication handler called /replication defined:
<requestHandler name="/replication" class="solr.ReplicationHandler" startup="lazy" />
You must have a realtime get handler called /get defined:
<requestHandler name="/get" class="solr.RealTimeGetHandler">
<lst name="defaults">
<str name="omitHeader">true</str>
</lst>
</requestHandler>
You must have the admin handlers defined:
<requestHandler name="/admin/" class="solr.admin.AdminHandlers" />
The DistributedUpdateProcessor is part of the default update chain and is automatically injected into any of your custom update chains. You can still explicitly add it yourself as follows:
<updateRequestProcessorChain name="sample">
<processor class="solr.LogUpdateProcessorFactory" />
<processor class="solr.DistributedUpdateProcessorFactory"/>
<processor class="my.package.UpdateFactory"/>
<processor class="solr.RunUpdateProcessorFactory" />
</updateRequestProcessorChain>
If you do not want the DistributedUpdateProcessFactory auto injected into your chain (say you want to use SolrCloud functionality, but you want to distribute updates yourself) then specify the following update processor factory in your chain: NoOpDistributingUpdateProcessorFactory
solr.xml
You must leave the admin path as the default:
<cores adminPath="/admin/cores"
Re-sizing a Cluster
You can control cluster size by passing the numShards when you start up the first SolrCore in a collection. This parameter is used to auto assign which shard each instance should be part of. Any SolrCores that you start after starting numShards instances are evenly added to each shard as replicas (as long as they all belong to the same collection).
To add more SolrCores to your collection, simply keep starting new SolrCores up. You can do this at any time and the new SolrCore will sync up its data with the current replicas in the shard before becoming active.
If you want to start your cluster on fewer machines and then expand over time beyond just adding replicas, you can choose to start by hosting multiple shards per machine (using multiple SolrCores) and then later migrate shards onto new machines by starting up a new replica for a given shard and eventually removing the shard from the original machine.
![]() Solr4.3 The new "SPLITSHARD" collection API can be used to split an existing shard into two shards containing exactly half the range of the parent shard each. More details can be found under the "Managing collections via the Collections API" section.
Solr4.3 The new "SPLITSHARD" collection API can be used to split an existing shard into two shards containing exactly half the range of the parent shard each. More details can be found under the "Managing collections via the Collections API" section.
Near Realtime Search
If you want to use the Near Realtime search support, you will probably want to enable auto soft commits in your solrconfig.xml file before putting it into zookeeper. Otherwise you can send explicit soft commits to the cluster as you desire. See NearRealtimeSearch
Parameter Reference
Cluster Params
|
numShards |
Defaults to 1 |
The number of shards to hash documents to. There will be one leader per shard and each leader can have N replicas. |
SolrCloud Instance Params
These are set in solr.xml, but by default they are setup in solr.xml to also work with system properties. Important note: the hostPort value found here will be used (via zookeeper) to inform the rest of the cluster what port each Solr instance is using. The default port is 8983. The example solr.xml uses the jetty.port system property, so if you want to use a port other than 8983, either you have to set this property when starting Solr, or you have to change solr.xml to fit your particular installation. If you do not do this, the cluster will think all your Solr servers are using port 8983, which may not be what you want.
|
host |
Defaults to the first local host address found |
If the wrong host address is found automatically, you can over ride the host address with this param. |
|
hostPort |
Defaults to the jetty.port system property |
The port that Solr is running on - by default this is found by looking at the jetty.port system property. |
|
hostContext |
Defaults to solr |
The context path for the Solr webapp. (Note: in Solr 4.0, it was mandatory that the hostContext not contain "/" or "_" characters. Begining with Solr 4.1, this limitation was removed, and it is recomended that you specify the begining slash. When running in the example jetty configs, the "hostContext" system property can be used to control both the servlet context used by jetty, and the hostContext used by SolrCloud -- eg: -DhostContext=/solr) |
SolrCloud Instance ZooKeeper Params
|
zkRun |
Defaults to localhost:<solrPort+1001> |
Causes Solr to run an embedded version of ZooKeeper. Set to the address of ZooKeeper on this node - this allows us to know who 'we are' in the list of addresses in the zkHost connect string. Simply using -DzkRun gets you the default value. Note this must be one of the exact strings from zkHost; in particular, the default localhost will not work for a multi-machine ensemble. |
|
zkHost |
No default |
The host address for ZooKeeper - usually this should be a comma separated list of addresses to each node in your ZooKeeperensemble. |
|
zkClientTimeout |
Defaults to 15000 |
The time a client is allowed to not talk to ZooKeeper before having it's session expired. |
zkRun and zkHost are setup using system properties. zkClientTimeout is setup in solr.xml, but default, can also be set using a system property.
SolrCloud Core Params
|
shard |
The shard id. Defaults to being automatically assigned based on numShards |
Allows you to specify the id used to group SolrCores into shards. |
shard can be configured in solr.xml for each core element as an attribute.
Getting your Configuration Files into ZooKeeper
Config Startup Bootstrap Params
There are two different ways you can use system properties to upload your initial configuration files to ZooKeeper the first time you start Solr. Remember that these are meant to be used only on first startup or when overwriting configuration files - everytime you start Solr with these system properties, any current configuration files in ZooKeeper may be overwritten when 'conf set' names match.
1. Look at solr.xml and upload the conf for each SolrCore found. The 'config set' name will be the collection name for that SolrCore, and collections will use the 'config set' that has a matching name.
|
bootstrap_conf |
No default |
If you pass -Dbootstrap_conf=true on startup, each SolrCore you have configured will have it's configuration files automatically uploaded and linked to the collection that SolrCore is part of |
2. Upload the given directory as a 'conf set' with the given name. No linking of collection to 'config set' is done. However, if only one 'conf set' exists, a collection will auto link to it.
|
bootstrap_confdir |
No default |
If you pass -bootstrap_confdir=<directory> on startup, that specific directory of configuration files will be uploaded toZooKeeper with a 'conf set' name defined by the below system property, collection.configName |
|
collection.configName |
Defaults to configuration1 |
Determines the name of the conf set pointed to by bootstrap_confdir |
Command Line Util
The ZkCLI tool (aka zkcli.sh and zkcli.bar) also lets you upload config to ZooKeeper. It allows you to do it the same two ways that you can above. It also provides a few other commands that let you link collection sets to collections, make ZooKeeper paths or clear them, as well as download configs from ZooKeeper to the local filesystem.
Details on using the ZkCLI command line tool and the options it supports can be found in the Solr Ref Guide.
Examples
Scripts
See: https://cwiki.apache.org/confluence/display/solr/Command+Line+Utilities#CommandLineUtilities-Scripts
Zookeeper chroot
If you are already using Zookeeper for other applications and you want to keep the ZNodes organized by application, or if you want to have multiple separated SolrCloud clusters sharing one Zookeeper ensemble you can use Zookeeper's "chroot" option. From Zookeeper's documentation: http://zookeeper.apache.org/doc/r3.3.6/zookeeperProgrammers.html#ch_zkSessions
An optional "chroot" suffix may also be appended to the connection string. This will run the client commands while interpreting all paths relative to this root (similar to the unix chroot command). If used the example would look like: "127.0.0.1:4545/app/a" or "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002/app/a" where the client would be rooted at "/app/a" and all paths would be relative to this root - ie getting/setting/etc... "/foo/bar" would result in operations being run on "/app/a/foo/bar" (from the server perspective).
To use this Zookeeper feature, simply start Solr with the "chroot" suffix in the zkHost parameter. For example:
java -DzkHost=localhost:9983/foo/bar -jar start.jar
or
java -DzkHost=zoo1:9983,zoo2:9983,zoo3:9983/foo/bar -jar start.jar
NOTE: With Solr 4.0 you'll need to create the initial path in Zoookeeper before starting Solr. Since Solr 4.1, the initial path will automatically be created if you are using either bootstrap_conf or boostrap_confdir.
Known Limitations
A small number of Solr search components do not support DistributedSearch. In some cases, a component may never get distributed support, in other cases it may just be a matter of time and effort. All of the search components that do not yet support standard distributed search have the same limitation with SolrCloud. You can pass distrib=false to use these components on a single SolrCore.
The Grouping feature only works if groups are in the same shard. You must use the custom sharding feature to use the Grouping feature.
If upgrading an existing Solr instance instance running with SolrCloud from Solr 4.0 to 4.1, be aware that the way the name_node parameter is defined has changed. This may cause a situation where the name_node uses the IP address of the machine instead of the server name, and thus SolrCloud is not aware of the existing node. If this happens, you can manually edit the host parameter in solr.xml to refer to the server name, or set the host in your system environment variables (since by default solr.xml is configured to inherit the host name from the environment variables). See also the section Core Admin and Configuring solr.xml for more information about the host parameter.
Glossary
|
Collection: |
A single search index. |
|
Shard: |
A logical section of a single collection (also called Slice). Sometimes people will talk about "Shard" in a physical sense (a manifestation of a logical shard) |
|
Replica: |
A physical manifestation of a logical Shard, implemented as a single Lucene index on a SolrCore |
|
Leader: |
One Replica of every Shard will be designated as a Leader to coordinate indexing for that Shard |
|
Encapsulates a single physical index. One or more make up logical shards (or slices) which make up a collection. |
|
|
Node: |
A single instance of Solr. A single Solr instance can have multiple SolrCores that can be part of any number of collections. |
|
Cluster: |
All of the nodes you are using to host SolrCores. |
FAQ
-
Q: I'm seeing lot's of session timeout exceptions - what to do?
-
A: Try raising the ZooKeeper session timeout by editing solr.xml - see the zkClientTimeout attribute. The minimum session timeout is 2 times yourZooKeeper defined tickTime. The maximum is 20 times the tickTime. The default tickTime is 2 seconds. You should avoiding raising this for no good reason, but it should be high enough that you don't see a lot of false session timeouts due to load, network lag, or garbage collection pauses. The default timeout is 15 seconds, but some environments might need to go as high as 30-60 seconds.
-
-
Q: How do I use SolrCloud, but distribute updates myself?
-
A: Add the following UpdateProcessorFactory somewhere in your update chain: NoOpDistributingUpdateProcessorFactory
-
-
Q: What is the difference between a Collection and a SolrCore?
-
A: In classic single node Solr, a SolrCore is basically equivalent to a Collection. It presents one logical index. In SolrCloud, the SolrCore's on multiple nodes form a Collection. This is still just one logical index, but multiple SolrCores host different 'shards' of the full collection. So aSolrCore encapsulates a single physical index on an instance. A Collection is a combination of all of the SolrCores that together provide a logical index that is distributed across many nodes.
-
Solr4.0升级参考
本文永久链接 http://fnil.me/aaaabe
目录
[隐藏]声明
- 本Wiki上的任何文字信息均在GNU自由文档许可证1.3或更高版本下发布,如果用于任何商业用途都需经本人同意。任何转载都请注明出处。
- 本Wiki上的内容来自本人的学习笔记,来源可能包括原创、书籍、网页、链接等,如果侵犯了您的知识产权,请与本人联系,我将及时删除。
- 我的联系方式 killme2008@gmail.com
介绍
最近负责solr集群的升级,从solr 3.x的一个shard集群升级到solr 4.0的cloud集群。
Why
Solr 4.0引入了SolrCloud功能,利用zookeeper做到全自动的分区、负载均衡,无需再人工做痛苦的shard切分,也不需要利用Haproxy或者Nginx做前端的负载均衡。索引添加和更新,会自动路由到正确的shard master做更新,并分布式同步到shard slave。查询会自动地从各个shard(shard内的master/slave也会做负载均衡)做查询并汇集结果。这是我们升级的主要动力。Solr 4.0还有一个NRT,近实时搜索的特性也是我们比较关注的。
整个升级主要参考SolrCloud这篇文档。
配置变更
schema.xml
schema.xml 必须加入_version_字段:
<field name="_version_" type="long" indexed="true" stored="true" multiValued="false"/>
solrconfig.xml
- indexDefaults和mainIndex合并成indexConfig
- 加入
<luceneMatchVersion>LUCENE_CURRENT</luceneMatchVersion>
选择你使用的lucene版本号。
- 找到updateHandler,并加入updateLog,用于生成事务日志
<updateLog> <str name="dir">${solr.data.dir:}</str> </updateLog>- 原来用于复制的replicationHandler可以简化成:
<requestHandler name="/replication" class="solr.ReplicationHandler" startup="lazy" />
- 添加/get handler:
<requestHandler name="/get" class="solr.RealTimeGetHandler"> <lst name="defaults"> <str name="omitHeader">true</str> </lst> </requestHandler>- 如果没有添加admin handler,必须添加:
<requestHandler name="/admin/" class="solr.admin.AdminHandlers" />
solr.xml保持默认:
<cores adminPath="/admin/cores"
- DistributedUpdateProcessor会自动添加到update链里,但是你也可以手动添加:
<updateRequestProcessorChain name="sample"> <processor class="solr.LogUpdateProcessorFactory" /> <processor class="solr.DistributedUpdateProcessorFactory"/> <processor class="my.package.UpdateFactory"/> <processor class="solr.RunUpdateProcessorFactory" /> </updateRequestProcessorChain>- solr.DisMaxRequestHandler相关handler需要删除。
- solr.AnalysisRequestHandler相关handler需要删除。
启动
1. 在第一次创建cloud集群的时候,第一个节点的启动必须特殊处理,启动参数类似(以多个core为例):
#Startup the first node. export BASE_DIR=. export JVM_ARGS="-Xmx16G -Xms16G" export ZK_SERVERS="localhost:2181" export ZK_TIMEOUT=20000 export SHARDS=2 java $JVM_ARGS -Dbootstrap_conf=true -DzkHost=$ZK_SERVERS -DzkClientTimeout=$ZK_TIMEOUT -DnumShards=$SHARDS -Dsolr.solr.home=$BASE_DIR -jar $BASE_DIR/start.jar 2>&1 >> $BASE_DIR/logs/solr.log &
重要参数说明如下:- bootstrap_conf If you pass -Dbootstrap_conf=true on startup, each SolrCore you have configured will have it's configuration files automatically uploaded and linked to the collection that SolrCore is part of
- zkHost 用到zookeeper集群服务器列表,逗号隔开
- zkClientTimeout zookeeper client timeout
- numShards 多少个分片,例如上面设置为两个分片
- solr.solr.home solr目录,该目录下需有solr.xml,设定core(现在称为collection)列表,例如:
<solr sharedLib="lib" persistent="true"> <cores adminPath="/admin/cores" defaultCoreName="test1" host="${host:}" hostPort="${jetty.port:}" > <core default="true" instanceDir="test1" name="test1"></core> <core default="false" instanceDir="test2" name="test2"></core> </cores> </solr>设定了两个collection: test1和test2,他们的配置分别在$solr.solr.home/test1和$solr.solr.home/test2目录下。
2. 当第一次创建集群的时候,第一个节点启动后会等待其他节点启动,因为要组成一个shard集群,必须至少有numShards个节点启动。
3. 其他节点启动无需传入-Dbootstrap_conf=true和-DnumShards:
java $JVM_ARGS -DzkHost=$ZK_SERVERS -DzkClientTimeout=$ZK_TIMEOUT -Dsolr.solr.home=$BASE_DIR -jar $BASE_DIR/start.jar 2>&1 >>$BASE_DIR/logs/solr.log &
只需zookeeper相关参数就够了。
4. 更健壮的启动脚本应该将solr作为daemon service开机启动。
中文分词
我用的是IKAnalyzer这个分词组件,可以参考这篇文档。
注意事项
- 在启动前最好设置集群内所有机器的hostname,并且可根据hostname相互访问,solr cloud会存储所有的集群内的机器hostname到zookeeper。如果hostname变更,该台机器将无法加入集群。
- 监控,如果你使用nagios,可以尝试我的这个插件脚本: https://gist.github.com/4705395 它会做两个事情:查看活跃节点数目是否是你指定的数目,并且尝试查询该节点,是否返回结果不为空。
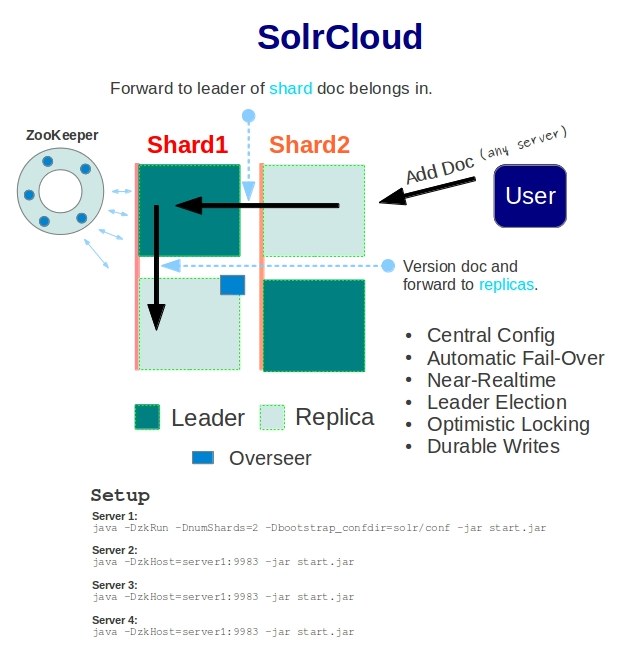
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,是正在开发中的Solr4.0的核心组件之一,它的主要思想是使用Zookeeper作为集群的配置信息中心。它有几个特色功能:1)集中式的配置信息 2)自动容错 3)近实时搜索 4)查询时自动负载均衡

基本可以用上面这幅图来概述,这是一个拥有4个Solr节点的集群,索引分布在两个Shard里面,每个Shard包含两个Solr节点,一个是Leader节点,一个是Replica节点,此外集群中有一个负责维护集群状态信息的Overseer节点,它是一个总控制器。集群的所有状态信息都放在Zookeeper集群中统一维护。从图中还可以看到,任何一个节点都可以接收索引更新的请求,然后再将这个请求转发到文档所应该属于的那个Shard的Leader节点,Leader节点更新结束完成,最后将版本号和文档转发给同属于一个Shard的replicas节点。
下面我们来看一个简单的SolrCloud集群的配置过程。
首先去https://builds.apache.org/job/Solr-trunk/lastSuccessfulBuild/artifact/artifacts/下载Solr4.0的源码和二进制包,注意Solr4.0现在还在开发中,因此这里是Nightly Build版本。
示例1,简单的包含2个Shard的集群
这个示例中,我们把一个collection的索引数据分布到两个shard上去,步骤如下:
为了弄2个solr服务器,我们拷贝一份example目录
cp -r example example2然后启动第一个solr服务器,并初始化一个新的solr集群,
cd example
java -Dbootstrap_confdir=./solr/conf -Dcollection.configName=myconf -DzkRun -DnumShards=2 -jar start.jar-DzkRun参数是启动一个嵌入式的Zookeeper服务器,它会作为solr服务器的一部分,-Dbootstrap_confdir参数是上传本地的配置文件上传到zookeeper中去,作为整个集群共用的配置文件,-DnumShards指定了集群的逻辑分组数目。
然后启动第二个solr服务器,并将其引向集群所在位置
cd example2
java -Djetty.port=7574 -DzkHost=localhost:9983 -jar start.jar-DzkHost=localhost:9983就是指明了Zookeeper集群所在位置
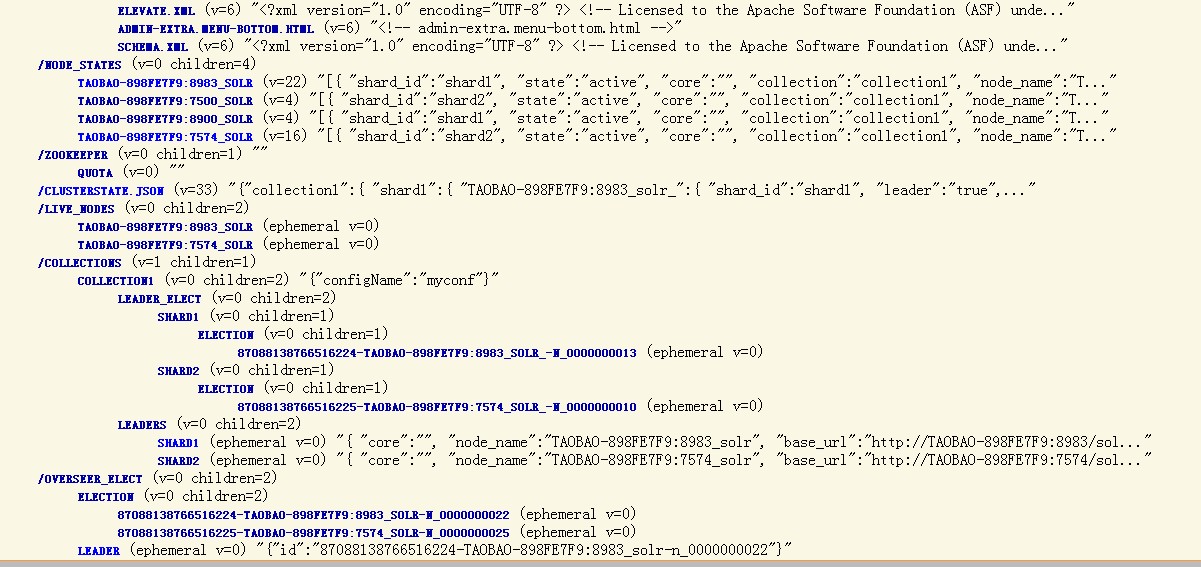
我们可以打开http://localhost:8983/solr/collection1/admin/zookeeper.jsp 或者http://localhost:8983/solr/#/cloud看看目前集群的状态,
现在,我们可以试试索引一些文档,
cd exampledocs
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar ipod_video.xml
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar monitor.xml
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar mem.xml最后,来试试分布式搜索吧:
http://localhost:8983/solr/collection1/select?q
Zookeeper维护的集群状态数据是存放在solr/zoo_data目录下的。
现在我们来剖析下这样一个简单的集群构建的基本流程:
先从第一台solr服务器说起:
1) 它首先启动一个嵌入式的Zookeeper服务器,作为集群状态信息的管理者,
2) 将自己这个节点注册到/node_states/目录下
3) 同时将自己注册到/live_nodes/目录下
4)创建/overseer_elect/leader,为后续Overseer节点的选举做准备,新建一个Overseer,
5) 更新/clusterstate.json目录下json格式的集群状态信息
6) 本机从Zookeeper中更新集群状态信息,维持与Zookeeper上的集群信息一致
7)上传本地配置文件到Zookeeper中,供集群中其他solr节点使用
8) 启动本地的Solr服务器,
9) Solr启动完成后,Overseer会得知shard中有第一个节点进来,更新shard状态信息,并将本机所在节点设置为shard1的leader节点,并向整个集群发布最新的集群状态信息。
10)本机从Zookeeper中再次更新集群状态信息,第一台solr服务器启动完毕。
然后来看第二台solr服务器的启动过程:
1) 本机连接到集群所在的Zookeeper,
2) 将自己这个节点注册到/node_states/目录下
3) 同时将自己注册到/live_nodes/目录下
4) 本机从Zookeeper中更新集群状态信息,维持与Zookeeper上的集群信息一致
5) 从集群中保存的配置文件加载Solr所需要的配置信息
6) 启动本地solr服务器,
7) solr启动完成后,将本节点注册为集群中的shard,并将本机设置为shard2的Leader节点,
8) 本机从Zookeeper中再次更新集群状态信息,第二台solr服务器启动完毕。
示例2,包含2个shard的集群,每个shard中有replica节点
如图所示,集群包含2个shard,每个shard中有两个solr节点,一个是leader,一个是replica节点,
cp -r example exampleB
cp -r example2 example2B
cd exampleB
java -Djetty.port=8900 -DzkHost=localhost:9983 -jar start.jar
cd example2B
java -Djetty.port=7500 -DzkHost=localhost:9983 -jar start.jar我们可以打开http://localhost:8983/solr/collection1/admin/zookeeper.jsp 看看包含4个节点的集群的状态,
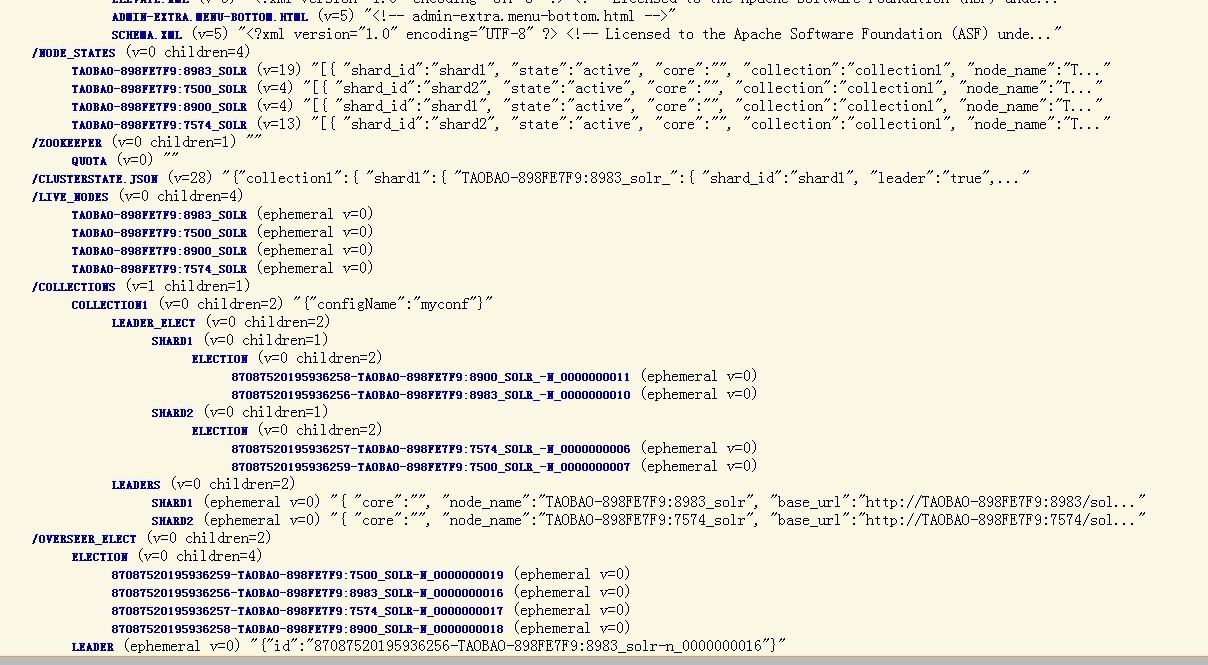
这个集群现在就具备容错性了,你可以试着干掉一个Solr服务器,然后再发送查询请求。背后的实质是集群的ov erseer会监测各个shard的leader节点,如果leader节点挂了,则会启动自动的容错机制,会从同一个shard中的其他replica节点集中重新选举出一个leader节点,甚至如果overseer节点自己也挂了,同样会自动在其他节点上启用新的overseer节点,这样就确保了集群的高可用性。
示例3 包含2个shard的集群,带shard备份和zookeeper集群机制
上一个示例中存在的问题是:尽管solr服务器可以容忍挂掉,但集群中只有一个zookeeper服务器来维护集群的状态信息,单点的存在即是不稳定的根源。如果这个zookeeper服务器挂了,那么分布式查询还是可以工作的,因为每个solr服务器都会在内存中维护最近一次由zookeeper维护的集群状态信息,但新的节点无法加入集群,集群的状态变化也不可知了。因此,为了解决这个问题,需要对Zookeeper服务器也设置一个集群,让其也具备高可用性和容错性。
有两种方式可选,一种是提供一个外部独立的Zookeeper集群,另一种是每个solr服务器都启动一个内嵌的Zookeeper服务器,再将这些Zookeeper服务器组成一个集群。 我们这里用后一种做示例:
 cd example
cd example
java -Dbootstrap_confdir=./solr/conf -Dcollection.configName=myconf -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -DnumShards=2 -jar start.jar
cd example2
java -Djetty.port=7574 -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
cd exampleB
java -Djetty.port=8900 -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
cd example2B
java -Djetty.port=7500 -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar我们可以打开http://localhost:8983/solr/collection1/admin/zookeeper.jsp 看看包含4个节点的集群的状态,可以发现其实和上一个没有任何区别。
后续的文章将从实现层面对SolrCloud这个分布式搜索解决方案进行进一步的深入剖析。
作者:洞庭散人
出处:http://phinecos.cnblogs.com/
本博客遵从Creative Commons Attribution 3.0 License,若用于非商业目的,您可以自由转载,但请保留原作者信息和文章链接URL。上一篇介绍了SolrCloud的基本概念,从这一篇开始我将深入到其实现代码中进行剖析。
SolrCloud最重要的一点就是引入了ZooKeeper来统一管理各种配置和状态信息。zookeeper是一个开源分布式的服务,它提供了分布式协作,分布式同步,配置管理等功能. 其实现的功能与google的chubby基本一致.zookeeper的官方网站已经写了一篇非常经典的概述性文章,请大家参阅:ZooKeeper: A Distributed Coordination Service for Distributed Applications.
上一篇的示例中是在启动每个solr服务器前,内嵌启动了一个Zookeeper服务器,再将这几台Zookeeper服务器组成一个集群,确保Solr集群信息的高可用性和容错性。
构建一个可用的Zookeeper集群,这就是SolrCloud要做的第一件工作。下面来看下SolrCloud是如何实现这一功能的:
1) 首先在web.xml中配置了一个filter
<filter>
<filter-name>SolrRequestFilter</filter-name>
<filter-class>org.apache.solr.servlet.SolrDispatchFilter</filter-class>
</filter>在web容器启动时会去加载并初始化SolrDispatchFilter这个filter,它的init方法会被调用,这个方法中做的最主要的事情是初始化一个Solr核容器。
CoreContainer.Initializer init = createInitializer();
// web.xml configuration
this.pathPrefix = config.getInitParameter( "path-prefix" );
this.cores = init.initialize();2) 初始化Solr核容器时,首先找到solr的根目录,这个目录下最重要的是solr.xml这个配置文件,这个配置文件用于初始化容器中加载的各个solr核,如果没有提供solr.xml,则会启用默认的配置信息:
private static final String DEF_SOLR_XML ="<?xml version=\"1.0\" encoding=\"UTF-8\" ?>\n" +
"<solr persistent=\"false\">\n" +
" <cores adminPath=\"/admin/cores\" defaultCoreName=\"" + DEFAULT_DEFAULT_CORE_NAME + "\">\n" +
" <core name=\""+ DEFAULT_DEFAULT_CORE_NAME + "\" shard=\"${shard:}\" instanceDir=\".\" />\n" +
" </cores>\n" +
"</solr>";3) 初始化过程的其中一步就是初始化Zookeeper服务器,你可以选择单机的Zookeeper服务器,也可以构建Zookeeper集群,下面以集群为例进行代码分析。
if (zkRun != null) {
zkServer = new SolrZkServer(zkRun, zookeeperHost, solrHome, hostPort);
zkServer.parseConfig();
zkServer.start();
// set client from server config if not already set
if (zookeeperHost == null) {
zookeeperHost = zkServer.getClientString();
}
}SolrZkServer类就是伴随solr启动的内嵌的Zookeeper服务器,首先来看parseConfig方法,它负责解析zoo.cfg文件,读取Zookeeper启动时所需要的配置信息,这些配置信息由SolrZkServerProps类表示,
首先设置Zookeeper存储数据的目录
if (zkProps == null) {
zkProps = new SolrZkServerProps();
// set default data dir
// TODO: use something based on IP+port??? support ensemble all from same solr home?
zkProps.setDataDir(solrHome + '/' + "zoo_data");
zkProps.zkRun = zkRun;
zkProps.solrPort = solrPort;
}然后读取zoo.cfg配置文件中的信息,为启动zookeeper服务器提供完整的配置信息,
props = SolrZkServerProps.getProperties(solrHome + '/' + "zoo.cfg");
SolrZkServerProps.injectServers(props, zkRun, zkHost);
zkProps.parseProperties(props);下面是一个示例配置文件:
tickTime=2000
dataDir=/var/zookeeper/
clientPort=2181
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888注意,server.x这些行就指明了zookeeper集群所包含的机器名称,每台Zookeeper服务器会使用3个端口来进行工作,其中第一个端口(端口1)用来做运行期间server间的通信,第二个端口(端口2)用来做leader election,另外还有一个端口(端口0)负责接收客户端请求。那么一台机器怎样确定自己是谁呢?这是通过dataDir目录下的myid文本文件确定。myid文件只包含一个数字,内容就是所在Server的ID:QuorumPeerConfig.myid。
1) 准备好集群所需要的配置信息后,就可以启动Zookeeper集群了。启动时是生成一个Zookeeper服务器线程,根据配置信息来决定是单机还是集群模式,如果是单机模式,则生成ZooKeeperServerMain对象并启动,如果是集群模式,则使用QuorumPeerMain对象启动。最后将服务器线程设置为Daemon模式,就完成了Zookeeper服务器的启动工作了。
public void start() {
zkThread = new Thread() {
@Override
public void run() {
try {
if (zkProps.getServers().size() > 1) {//zk集群
QuorumPeerMain zkServer = new QuorumPeerMain();
zkServer.runFromConfig(zkProps);
if (logger.isInfoEnabled()) {
logger.info("启动zk服务器集群成功");
}
} else {//单机zk
ServerConfig sc = new ServerConfig();
sc.readFrom(zkProps);
ZooKeeperServerMain zkServer = new ZooKeeperServerMain();
zkServer.runFromConfig(sc);
if (logger.isInfoEnabled()) {
logger.info("启动单机zk服务器成功");
}
}
logger.info("ZooKeeper Server exited.");
} catch (Throwable e) {
logger.error("ZooKeeper Server ERROR", e);
throw new SolrException(SolrException.ErrorCode.SERVER_ERROR, e);
}
}
};
if (zkProps.getServers().size() > 1) {
logger.info("STARTING EMBEDDED ENSEMBLE ZOOKEEPER SERVER at port " + zkProps.getClientPortAddress().getPort());
} else {
logger.info("STARTING EMBEDDED STANDALONE ZOOKEEPER SERVER at port " + zkProps.getClientPortAddress().getPort());
}
zkThread.setDaemon(true);
zkThread.start();
try {
Thread.sleep(500); // pause for ZooKeeper to start
} catch (Exception e) {
logger.error("STARTING ZOOKEEPER", e);
}
}为了验证集群是否启动成功,可以使用Zookeeper提供的命令行工具进行验证,进入bin目录下,运行:
zkCli.cmd –server zookeeper服务器地址1:端口这是连接到集群中1台Zookeeper服务器,然后创建一个ZNode,往其中加入一些数据,你再连接到集群中其他的服务器上,查看数据是否一致,即可知道Zookeeper集群是否已经构建成功。
作者:洞庭散人
出处:http://phinecos.cnblogs.com/
在上一篇中介绍了SolrCloud的第一个模块---构建管理solr集群状态信息的zookeeper集群。当我们在solr服务器启动时拥有了这样一个Zookeeper集群后,显然我们需要连接到Zookeeper集群的方便手段,在这一篇中我将对Zookeeper客户端相关的各个封装类进行分析。
SolrZkClient类是Solr服务器用来与Zookeeper集群进行通信的接口类,它包含的主要组件有:
private ConnectionManager connManager;
private volatile SolrZooKeeper keeper;
private ZkCmdExecutor zkCmdExecutor = new ZkCmdExecutor();其中ConnectionManager是Watcher的实现类,主要负责对客户端与Zookeeper集群之间连接的状态变化信息进行响应,关于Watcher的详细介绍,可以参考http://zookeeper.apache.org/doc/trunk/zookeeperProgrammers.html#ch_zkWatches,
SolrZooKeeper类是一个包装类,没有实际意义,ZkCmdExecutor类是负责在连接失败的情况下,重试某种操作特定次数,具体的操作是ZkOperation这个抽象类的具体实现子类,其execute方法中包含了具体操作步骤,这些操作包括新建一个Znode节点,读取Znode节点数据,创建Znode路径,删除Znode节点等Zookeeper操作。
首先来看它的构造函数,先创建ConnectionManager对象来响应两端之间的状态变化信息,然后ZkClientConnectionStrategy类是一个连接策略抽象类,它包含连接和重连两种策略,并且采用模板方法模式,具体的实现是通过静态累不类ZkUpdate来实现的,DefaultConnectionStrategy是它的一个实现子类,它覆写了connect和reconnect两个连接策略方法。
public SolrZkClient(String zkServerAddress, int zkClientTimeout,
ZkClientConnectionStrategy strat, final OnReconnect onReconnect, int clientConnectTimeout) throws InterruptedException,
TimeoutException, IOException {
connManager = new ConnectionManager("ZooKeeperConnection Watcher:"
+ zkServerAddress, this, zkServerAddress, zkClientTimeout, strat, onReconnect);
strat.connect(zkServerAddress, zkClientTimeout, connManager,
new ZkUpdate() {
@Override
public void update(SolrZooKeeper zooKeeper) {
SolrZooKeeper oldKeeper = keeper;
keeper = zooKeeper;
if (oldKeeper != null) {
try {
oldKeeper.close();
} catch (InterruptedException e) {
// Restore the interrupted status
Thread.currentThread().interrupt();
log.error("", e);
throw new ZooKeeperException(SolrException.ErrorCode.SERVER_ERROR,
"", e);
}
}
}
});
connManager.waitForConnected(clientConnectTimeout);
numOpens.incrementAndGet();
}值得注意的是,构造函数中生成的ZkUpdate匿名类对象,它的update方法会被调用,
在这个方法里,会首先将已有的老的SolrZooKeeperg关闭掉,然后放置上一个新的SolrZooKeeper。做好这些准备工作以后,就会去连接Zookeeper服务器集群,
connManager.waitForConnected(clientConnectTimeout);//连接zk服务器集群,默认30秒超时时间
其实具体的连接动作是new SolrZooKeeper(serverAddress, timeout, watcher)引发的,上面那句代码只是在等待指定时间,看是否已经连接上。
如果连接Zookeeper服务器集群成功,那么就可以进行Zookeeper的常规操作了:
1) 是否已经连接
public boolean isConnected() {
return keeper != null && keeper.getState() == ZooKeeper.States.CONNECTED;
}2) 是否存在某个路径的Znode
public Stat exists(final String path, final Watcher watcher, boolean retryOnConnLoss) throws KeeperException, InterruptedException {
if (retryOnConnLoss) {
return zkCmdExecutor.retryOperation(new ZkOperation() {
@Override
public Stat execute() throws KeeperException, InterruptedException {
return keeper.exists(path, watcher);
}
});
} else {
return keeper.exists(path, watcher);
}
}3) 创建一个Znode节点
public String create(final String path, final byte data[], final List<ACL> acl, final CreateMode createMode, boolean retryOnConnLoss) throws KeeperException, InterruptedException {
if (retryOnConnLoss) {
return zkCmdExecutor.retryOperation(new ZkOperation() {
@Override
public String execute() throws KeeperException, InterruptedException {
return keeper.create(path, data, acl, createMode);
}
});
} else {
return keeper.create(path, data, acl, createMode);
}
}4) 获取指定路径下的孩子Znode节点
public List<String> getChildren(final String path, final Watcher watcher, boolean retryOnConnLoss) throws KeeperException, InterruptedException {
if (retryOnConnLoss) {
return zkCmdExecutor.retryOperation(new ZkOperation() {
@Override
public List<String> execute() throws KeeperException, InterruptedException {
return keeper.getChildren(path, watcher);
}
});
} else {
return keeper.getChildren(path, watcher);
}
}5) 获取指定Znode上附加的数据
public byte[] getData(final String path, final Watcher watcher, final Stat stat, boolean retryOnConnLoss) throws KeeperException, InterruptedException {
if (retryOnConnLoss) {
return zkCmdExecutor.retryOperation(new ZkOperation() {
@Override
public byte[] execute() throws KeeperException, InterruptedException {
return keeper.getData(path, watcher, stat);
}
});
} else {
return keeper.getData(path, watcher, stat);
}
}6) 在指定Znode上设置数据
public Stat setData(final String path, final byte data[], final int version, boolean retryOnConnLoss) throws KeeperException, InterruptedException {
if (retryOnConnLoss) {
return zkCmdExecutor.retryOperation(new ZkOperation() {
@Override
public Stat execute() throws KeeperException, InterruptedException {
return keeper.setData(path, data, version);
}
});
} else {
return keeper.setData(path, data, version);
}
}7) 创建路径
public void makePath(String path, byte[] data, CreateMode createMode, Watcher watcher, boolean failOnExists, boolean retryOnConnLoss) throws KeeperException, InterruptedException {
if (log.isInfoEnabled()) {
log.info("makePath: " + path);
}
boolean retry = true;
if (path.startsWith("/")) {
path = path.substring(1, path.length());
}
String[] paths = path.split("/");
StringBuilder sbPath = new StringBuilder();
for (int i = 0; i < paths.length; i++) {
byte[] bytes = null;
String pathPiece = paths[i];
sbPath.append("/" + pathPiece);
final String currentPath = sbPath.toString();
Object exists = exists(currentPath, watcher, retryOnConnLoss);
if (exists == null || ((i == paths.length -1) && failOnExists)) {
CreateMode mode = CreateMode.PERSISTENT;
if (i == paths.length - 1) {
mode = createMode;
bytes = data;
if (!retryOnConnLoss) retry = false;
}
try {
if (retry) {
final CreateMode finalMode = mode;
final byte[] finalBytes = bytes;
zkCmdExecutor.retryOperation(new ZkOperation() {
@Override
public Object execute() throws KeeperException, InterruptedException {
keeper.create(currentPath, finalBytes, ZooDefs.Ids.OPEN_ACL_UNSAFE, finalMode);
return null;
}
});
} else {
keeper.create(currentPath, bytes, ZooDefs.Ids.OPEN_ACL_UNSAFE, mode);
}
} catch (NodeExistsException e) {
if (!failOnExists) {
// TODO: version ? for now, don't worry about race
setData(currentPath, data, -1, retryOnConnLoss);
// set new watch
exists(currentPath, watcher, retryOnConnLoss);
return;
}
// ignore unless it's the last node in the path
if (i == paths.length - 1) {
throw e;
}
}
if(i == paths.length -1) {
// set new watch
exists(currentPath, watcher, retryOnConnLoss);
}
} else if (i == paths.length - 1) {
// TODO: version ? for now, don't worry about race
setData(currentPath, data, -1, retryOnConnLoss);
// set new watch
exists(currentPath, watcher, retryOnConnLoss);
}
}
}8) 删除指定Znode
public void delete(final String path, final int version, boolean retryOnConnLoss) throws InterruptedException, KeeperException {
if (retryOnConnLoss) {
zkCmdExecutor.retryOperation(new ZkOperation() {
@Override
public Stat execute() throws KeeperException, InterruptedException {
keeper.delete(path, version);
return null;
}
});
} else {
keeper.delete(path, version);
}
}我们再回过头来看看ConnectionManager类是如何响应两端的连接状态信息的变化的,它最重要的方法是process方法,当它被触发回调时,会从WatchedEvent参数中得到事件的各种状态信息,比如连接成功,会话过期(此时需要进行重连),连接断开等。
public synchronized void process(WatchedEvent event) {
if (log.isInfoEnabled()) {
log.info("Watcher " + this + " name:" + name + " got event " + event + " path:" + event.getPath() + " type:" + event.getType());
}
state = event.getState();
if (state == KeeperState.SyncConnected) {
connected = true;
clientConnected.countDown();
} else if (state == KeeperState.Expired) {
connected = false;
log.info("Attempting to reconnect to recover relationship with ZooKeeper...");
//尝试重新连接zk服务器
try {
connectionStrategy.reconnect(zkServerAddress, zkClientTimeout, this,
new ZkClientConnectionStrategy.ZkUpdate() {
@Override
public void update(SolrZooKeeper keeper) throws InterruptedException, TimeoutException, IOException {
synchronized (connectionStrategy) {
waitForConnected(SolrZkClient.DEFAULT_CLIENT_CONNECT_TIMEOUT);
client.updateKeeper(keeper);
if (onReconnect != null) {
onReconnect.command();
}
synchronized (ConnectionManager.this) {
ConnectionManager.this.connected = true;
}
}
}
});
} catch (Exception e) {
SolrException.log(log, "", e);
}
log.info("Connected:" + connected);
} else if (state == KeeperState.Disconnected) {
connected = false;
} else {
connected = false;
}
notifyAll();
}在上一篇中介绍了连接Zookeeper集群的方法,这一篇将围绕一个有趣的话题---来展开,这就是Replication(索引复制),关于Solr Replication的详细介绍,可以参考http://wiki.apache.org/solr/SolrReplication。
在开始这个话题之前,先从我最近在应用中引入solr的master/slave架构时,遇到的一个让我困扰的实际问题。
应用场景简单描述如下:
1)首先master节点下载索引分片,然后创建配置文件,加入master节点的replication配置片段,再对索引分片进行合并(关于mergeIndex,可以参考http://wiki.apache.org/solr/MergingSolrIndexes),然后利用上述配置文件和索引数据去创建一个solr核。
2)slave节点创建配置文件,加入slave节点的replication配置片段,创建一个空的solr核,等待从master节点进行索引数据同步
出现的问题:slave节点没有从master节点同步到数据。
问题分析:
1)首先检查master节点,获取最新的可复制索引的版本号,
http://master_host:port/solr/replication?command=indexversion
发现返回的索引版本号是0,这说明mater节点根本没有触发replication动作,
2)为了确认上述判断,在slave节点上进一步查看replication的详细信息
http://slave_host:port/solr/replication?command=details
发现确实如此,尽管master节点的索引版本号和slave节点的索引版本号不一致,但索引却没有同步过来,再分别查看master节点和slave节点的日志,发现索引复制动作确实没有开始。
综上所述,确实是master节点没有触发索引复制动作,那究竟是为何呢?先将原因摆出来,后面会通过源码的分析来加以说明。
原因:solr合并索引时,不管你是通过mergeindexes的http命令,还是调用底层lucene的IndexWriter,记得最后一定要提交一个commit,否则,不仅索引不仅不会对查询可见,更是对于master/slave架构的solr集群来说,master节点的replication动作不会触发,因为indexversion没有感知到变化。
好了,下面开始对Solr的Replication的分析。
Solr容器在加载solr核的时候,会对已经注册的各个实现SolrCoreAware接口的Handler进行回调,调用其inform方法。
对于ReplicationHandler来说,就是在这里对自己是属于master节点还是slave节点进行判断,若是slave节点,则创建一个SnapPuller对象,定时负责从master节点主动拉索引数据下来;若是master节点,则只设置相应的参数。
public void inform(SolrCore core) {
this.core = core;
registerFileStreamResponseWriter();
registerCloseHook();
NamedList slave = (NamedList) initArgs.get("slave");
boolean enableSlave = isEnabled( slave );
if (enableSlave) {
tempSnapPuller = snapPuller = new SnapPuller(slave, this, core);
isSlave = true;
}
NamedList master = (NamedList) initArgs.get("master");
boolean enableMaster = isEnabled( master );
if (!enableSlave && !enableMaster) {
enableMaster = true;
master = new NamedList<Object>();
}
if (enableMaster) {
includeConfFiles = (String) master.get(CONF_FILES);
if (includeConfFiles != null && includeConfFiles.trim().length() > 0) {
List<String> files = Arrays.asList(includeConfFiles.split(","));
for (String file : files) {
if (file.trim().length() == 0) continue;
String[] strs = file.split(":");
// if there is an alias add it or it is null
confFileNameAlias.add(strs[0], strs.length > 1 ? strs[1] : null);
}
LOG.info("Replication enabled for following config files: " + includeConfFiles);
}
List backup = master.getAll("backupAfter");
boolean backupOnCommit = backup.contains("commit");
boolean backupOnOptimize = !backupOnCommit && backup.contains("optimize");
List replicateAfter = master.getAll(REPLICATE_AFTER);
replicateOnCommit = replicateAfter.contains("commit");
replicateOnOptimize = !replicateOnCommit && replicateAfter.contains("optimize");
if (!replicateOnCommit && ! replicateOnOptimize) {
replicateOnCommit = true;
}
// if we only want to replicate on optimize, we need the deletion policy to
// save the last optimized commit point.
if (replicateOnOptimize) {
IndexDeletionPolicyWrapper wrapper = core.getDeletionPolicy();
IndexDeletionPolicy policy = wrapper == null ? null : wrapper.getWrappedDeletionPolicy();
if (policy instanceof SolrDeletionPolicy) {
SolrDeletionPolicy solrPolicy = (SolrDeletionPolicy)policy;
if (solrPolicy.getMaxOptimizedCommitsToKeep() < 1) {
solrPolicy.setMaxOptimizedCommitsToKeep(1);
}
} else {
LOG.warn("Replication can't call setMaxOptimizedCommitsToKeep on " + policy);
}
}
if (replicateOnOptimize || backupOnOptimize) {
core.getUpdateHandler().registerOptimizeCallback(getEventListener(backupOnOptimize, replicateOnOptimize));
}
if (replicateOnCommit || backupOnCommit) {
replicateOnCommit = true;
core.getUpdateHandler().registerCommitCallback(getEventListener(backupOnCommit, replicateOnCommit));
}
if (replicateAfter.contains("startup")) {
replicateOnStart = true;
RefCounted<SolrIndexSearcher> s = core.getNewestSearcher(false);
try {
DirectoryReader reader = s==null ? null : s.get().getIndexReader();
if (reader!=null && reader.getIndexCommit() != null && reader.getIndexCommit().getGeneration() != 1L) {
try {
if(replicateOnOptimize){
Collection<IndexCommit> commits = DirectoryReader.listCommits(reader.directory());
for (IndexCommit ic : commits) {
if(ic.getSegmentCount() == 1){
if(indexCommitPoint == null || indexCommitPoint.getGeneration() < ic.getGeneration()) indexCommitPoint = ic;
}
}
} else{
indexCommitPoint = reader.getIndexCommit();
}
} finally {
// We don't need to save commit points for replication, the SolrDeletionPolicy
// always saves the last commit point (and the last optimized commit point, if needed)
/***
if(indexCommitPoint != null){
core.getDeletionPolicy().saveCommitPoint(indexCommitPoint.getGeneration());
}
***/
}
}
// reboot the writer on the new index
core.getUpdateHandler().newIndexWriter();
} catch (IOException e) {
LOG.warn("Unable to get IndexCommit on startup", e);
} finally {
if (s!=null) s.decref();
}
}
String reserve = (String) master.get(RESERVE);
if (reserve != null && !reserve.trim().equals("")) {
reserveCommitDuration = SnapPuller.readInterval(reserve);
}
LOG.info("Commits will be reserved for " + reserveCommitDuration);
isMaster = true;
}}
ReplicationHandler可以响应多种命令:
1) indexversion。
这里需要了解的第一个概念是索引提交点(IndexCommit),这是底层lucene的东西,可以自行查阅资料。首先获取最新的索引提交点,然后从其中获取索引版本号和索引所属代。
IndexCommit commitPoint = indexCommitPoint; // make a copy so it won't change
if (commitPoint != null && replicationEnabled.get()) {
core.getDeletionPolicy().setReserveDuration(commitPoint.getVersion(), reserveCommitDuration);
rsp.add(CMD_INDEX_VERSION, commitPoint.getVersion());rsp.add(GENERATION, commitPoint.getGeneration());
2)backup。这个命令用来对索引做快照。首先获取最新的索引提交点,然后创建做一个SnapShooter,具体的快照动作由这个对象完成,
private void doSnapShoot(SolrParams params, SolrQueryResponse rsp, SolrQueryRequest req) {try {
int numberToKeep = params.getInt(NUMBER_BACKUPS_TO_KEEP, Integer.MAX_VALUE);
IndexDeletionPolicyWrapper delPolicy = core.getDeletionPolicy();
IndexCommit indexCommit = delPolicy.getLatestCommit();
if(indexCommit == null) {
indexCommit = req.getSearcher().getReader().getIndexCommit();
}
// small race here before the commit point is saved
new SnapShooter(core, params.get("location")).createSnapAsync(indexCommit, numberToKeep, this);
} catch (Exception e) {
LOG.warn("Exception during creating a snapshot", e);
rsp.add("exception", e);
}
}快照对象会启动一个线程去异步地做一个索引备份。
void createSnapAsync(final IndexCommit indexCommit, final int numberToKeep, final ReplicationHandler replicationHandler) {
replicationHandler.core.getDeletionPolicy().saveCommitPoint(indexCommit.getVersion());
new Thread() {
@Override
public void run() {
createSnapshot(indexCommit, numberToKeep, replicationHandler);
}
}.start();
}
void createSnapshot(final IndexCommit indexCommit, int numberToKeep, ReplicationHandler replicationHandler) {
NamedList details = new NamedList();
details.add("startTime", new Date().toString());
File snapShotDir = null;
String directoryName = null;
Lock lock = null;
try {
if(numberToKeep<Integer.MAX_VALUE) {
deleteOldBackups(numberToKeep);
}
SimpleDateFormat fmt = new SimpleDateFormat(DATE_FMT, Locale.US);
directoryName = "snapshot." + fmt.format(new Date());
lock = lockFactory.makeLock(directoryName + ".lock");
if (lock.isLocked()) return;
snapShotDir = new File(snapDir, directoryName);
if (!snapShotDir.mkdir()) {
LOG.warn("Unable to create snapshot directory: " + snapShotDir.getAbsolutePath());
return;
}
Collection<String> files = indexCommit.getFileNames();
FileCopier fileCopier = new FileCopier(solrCore.getDeletionPolicy(), indexCommit);
fileCopier.copyFiles(files, snapShotDir);
details.add("fileCount", files.size());
details.add("status", "success");
details.add("snapshotCompletedAt", new Date().toString());
} catch (Exception e) {
SnapPuller.delTree(snapShotDir);
LOG.error("Exception while creating snapshot", e);
details.add("snapShootException", e.getMessage());
} finally {
replicationHandler.core.getDeletionPolicy().releaseCommitPoint(indexCommit.getVersion());
replicationHandler.snapShootDetails = details;
if (lock != null) {
try {
lock.release();
} catch (IOException e) {
LOG.error("Unable to release snapshoot lock: " + directoryName + ".lock");
}
}
}
}
3)fetchindex。响应来自slave节点的取索引文件的请求,会启动一个线程来实现索引文件的获取。
String masterUrl = solrParams.get(MASTER_URL);
if (!isSlave && masterUrl == null) {
rsp.add(STATUS,ERR_STATUS);
rsp.add("message","No slave configured or no 'masterUrl' Specified");
return;
}
final SolrParams paramsCopy = new ModifiableSolrParams(solrParams);
new Thread() {
@Override
public void run() {
doFetch(paramsCopy);
}
}.start();
rsp.add(STATUS, OK_STATUS);
具体的获取动作是通过SnapPuller对象来实现的,首先尝试获取pull对象锁,如果请求锁失败,则说明还有取索引数据动作未结束,如果请求锁成功,就调用SnapPuller对象的fetchLatestIndex方法来取最新的索引数据。
void doFetch(SolrParams solrParams) {
String masterUrl = solrParams == null ? null : solrParams.get(MASTER_URL);
if (!snapPullLock.tryLock())
return;
try {
tempSnapPuller = snapPuller;
if (masterUrl != null) {
NamedList<Object> nl = solrParams.toNamedList();
nl.remove(SnapPuller.POLL_INTERVAL);
tempSnapPuller = new SnapPuller(nl, this, core);
}
tempSnapPuller.fetchLatestIndex(core);
} catch (Exception e) {
LOG.error("SnapPull failed ", e);
} finally {
tempSnapPuller = snapPuller;
snapPullLock.unlock();
}
}
最后真正的取索引数据过程,首先,若mastet节点的indexversion为0,则说明master节点根本没有提供可供复制的索引数据,若master节点和slave节点的indexversion相同,则说明slave节点目前与master节点索引数据状态保持一致,无需同步。若两者的indexversion不同,则开始索引复制过程,首先从master节点上下载指定索引版本号的索引文件列表,然后创建一个索引文件同步服务线程来完成同并工作。
这里需要区分的是,如果master节点的年代比slave节点要老,那就说明两者已经不相容,此时slave节点需要新建一个索引目录,再从master节点做一次全量索引复制。还需要注意的一点是,索引同步也是可以同步配置文件的,若配置文件发生变化,则需要对solr核进行一次reload操作。最对了,还有,和文章开头一样, slave节点同步完数据后,别忘了做一次commit操作,以便刷新自己的索引提交点到最新的状态。最后,关闭并等待同步服务线程结束。此外,具体的取索引文件是通过FileFetcher对象来完成。
boolean fetchLatestIndex(SolrCore core) throws IOException {
replicationStartTime = System.currentTimeMillis();
try {
//get the current 'replicateable' index version in the master
NamedList response = null;
try {
response = getLatestVersion();
} catch (Exception e) {
LOG.error("Master at: " + masterUrl + " is not available. Index fetch failed. Exception: " + e.getMessage());
return false;
}
long latestVersion = (Long) response.get(CMD_INDEX_VERSION);
long latestGeneration = (Long) response.get(GENERATION);
if (latestVersion == 0L) {
//there is nothing to be replicated
return false;
}
IndexCommit commit;
RefCounted<SolrIndexSearcher> searcherRefCounted = null;
try {
searcherRefCounted = core.getNewestSearcher(false);
commit = searcherRefCounted.get().getReader().getIndexCommit();
} finally {
if (searcherRefCounted != null)
searcherRefCounted.decref();
}
if (commit.getVersion() == latestVersion && commit.getGeneration() == latestGeneration) {
//master and slave are alsready in sync just return
LOG.info("Slave in sync with master.");
return false;
}
LOG.info("Master's version: " + latestVersion + ", generation: " + latestGeneration);
LOG.info("Slave's version: " + commit.getVersion() + ", generation: " + commit.getGeneration());
LOG.info("Starting replication process");
// get the list of files first
fetchFileList(latestVersion);
// this can happen if the commit point is deleted before we fetch the file list.
if(filesToDownload.isEmpty()) return false;
LOG.info("Number of files in latest index in master: " + filesToDownload.size());
// Create the sync service
fsyncService = Executors.newSingleThreadExecutor();
// use a synchronized list because the list is read by other threads (to show details)
filesDownloaded = Collections.synchronizedList(new ArrayList<Map<String, Object>>());
// if the generateion of master is older than that of the slave , it means they are not compatible to be copied
// then a new index direcory to be created and all the files need to be copied
boolean isFullCopyNeeded = commit.getGeneration() >= latestGeneration;
File tmpIndexDir = createTempindexDir(core);
if (isIndexStale())
isFullCopyNeeded = true;
successfulInstall = false;
boolean deleteTmpIdxDir = true;
File indexDir = null ;
try {
indexDir = new File(core.getIndexDir());
downloadIndexFiles(isFullCopyNeeded, tmpIndexDir, latestVersion);
LOG.info("Total time taken for download : " + ((System.currentTimeMillis() - replicationStartTime) / 1000) + " secs");
Collection<Map<String, Object>> modifiedConfFiles = getModifiedConfFiles(confFilesToDownload);
if (!modifiedConfFiles.isEmpty()) {
downloadConfFiles(confFilesToDownload, latestVersion);
if (isFullCopyNeeded) {
successfulInstall = modifyIndexProps(tmpIndexDir.getName());
deleteTmpIdxDir = false;
} else {
successfulInstall = copyIndexFiles(tmpIndexDir, indexDir);
}
if (successfulInstall) {
LOG.info("Configuration files are modified, core will be reloaded");
logReplicationTimeAndConfFiles(modifiedConfFiles, successfulInstall);//write to a file time of replication and conf files.
reloadCore();
}
} else {
terminateAndWaitFsyncService();
if (isFullCopyNeeded) {
successfulInstall = modifyIndexProps(tmpIndexDir.getName());
deleteTmpIdxDir = false;
} else {
successfulInstall = copyIndexFiles(tmpIndexDir, indexDir);
}
if (successfulInstall) {
logReplicationTimeAndConfFiles(modifiedConfFiles, successfulInstall);
doCommit();
}
}
replicationStartTime = 0;
return successfulInstall;
} catch (ReplicationHandlerException e) {
LOG.error("User aborted Replication");
} catch (SolrException e) {
throw e;
} catch (Exception e) {
throw new SolrException(SolrException.ErrorCode.SERVER_ERROR, "Index fetch failed : ", e);
} finally {
if (deleteTmpIdxDir) delTree(tmpIndexDir);
else delTree(indexDir);
}
return successfulInstall;
} finally {
if (!successfulInstall) {
logReplicationTimeAndConfFiles(null, successfulInstall);
}
filesToDownload = filesDownloaded = confFilesDownloaded = confFilesToDownload = null;
replicationStartTime = 0;
fileFetcher = null;
if (fsyncService != null && !fsyncService.isShutdown()) fsyncService.shutdownNow();
fsyncService = null;
stop = false;
fsyncException = null;
}
}




相关推荐
这个“solr7 相关资料包.zip”文件包含了Solr 7.7.3版本的安装包以及一些重要的扩展工具,这对于学习和部署Solr 7.x版本非常有帮助。 首先,Solr 7.7.3是Solr的一个稳定版本,它包含了众多改进和新特性。在这一版本...
在CDH 4的安全指南中,有详细的步骤指导如何配置Kerberos和相关的HDFS安全设置。 在**使用Cloudera Manager**安装Cloudera Search时,整个过程会自动化很多,包括安装、配置和管理。而**不使用Cloudera Manager**...
【大数据分布式全文检索系统设计与实现】 随着信息技术的迅速进步,大数据已经成为各行各业的关键生产要素。...实际论文中,应包含相关领域的学术文献和技术资料,为读者提供深入学习和研究的依据。
3. **分布式搜索**:SOLR云(SolrCloud)提供了分布式部署和自动复制,以实现高可用性和水平扩展。 4. **实时搜索**:SOLR的实时索引功能允许在不重启服务的情况下更新索引,提高用户体验。 5. **优化索引**:定期...
本资料深入讲解了该平台中的关键组件,包括HDFS(Hadoop Distributed File System)、HBase、Spark以及Solr等,同时也涵盖了这些技术的架构原理和二次开发相关内容。 HDFS是Apache Hadoop项目的核心组件之一,是一...
这份压缩包文件包含了一系列关于大数据技术的PPT和PDF文档,主要聚焦于Spark、HBase、HDFS的二次开发以及相关的技术,如Hive、Kafka、Solr和MapReduce等。以下是这些资源中涉及的主要知识点: 1. **Spark二次开发**...
SolrCloud模式下,Zookeeper作为协调节点,负责集群的管理和状态维护。 三、SOLR索引 1. 创建索引:通过索引器将数据导入SOLR,可以是XML、JSON、CSV等格式。 2. 更新索引:支持实时更新,包括添加、删除和修改文档...
### 相关框架: 1.Dubbo:当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用 于提高机器利用率的资源调度和治理中心。 ...
+ 功能模块:待处理中心、采购模块、销售模块、仓库模块、财务模块、报表中心、信息资料、系统。 + 工作职责及技术描述: - 负责客户和供应商的管理模块。 - 对客户、供应商进行划分类别,定期更新管理,进行 ...
标题中的"JAVA+Solr分词项目工程实例Java实用源码整理learns"指的是一个基于Java编程语言并结合Solr搜索引擎...同时,这个实例也提供了扩展学习的机会,通过链接可以获取更多Java相关的学习资料,进一步提升开发技能。
5. **文档和示例**: `docs`目录下包含Solr的用户指南、开发者文档和其他相关参考资料,对于学习和理解Solr的运作机制非常有帮助。同时,`example/exampledocs`目录下的示例数据集可以帮助初学者快速上手。 6. **...
这个“solr项目和相关资源.rar”压缩包显然是针对Solr初学者或开发者准备的一份资料集合,包含了Solr的配置文件、必要的JAR库、资源文件以及一个入门测试项目,帮助用户快速理解和上手Solr。 1. **Solr核心概念**:...
这将启动一个名为 "SolrCloud" 的模式,或者你可以选择单节点模式运行 `bin/solr start -e single`。如果你是初次接触 Solr,单节点模式是个不错的起点。 Solr 的核心概念之一是集合(Collections),类似于数据库...
"solr-4.9.1" 是Solr的一个特定版本,包含了Solr的核心功能和相关的文档资料,以及官方提供的示例(Demo)。 在Solr-4.9.1版本中,你可以找到以下关键知识点: 1. **Solr核心模块**:Solr的核心组件包括索引、查询...
5. 拼写建议与自动补全:Solr内置了拼写检查和自动补全功能,可以帮助用户纠正输入错误并提供相关建议,提升用户体验。 6. 多语言支持:Solr具有内置的多种语言分析器,可以处理不同语言的文本,包括中文、英文、...
本资源包包含了安装Solr单机版和集群版所需的所有相关资料,这将帮助你搭建一个高效、稳定的搜索服务环境。以下是关于Solr安装及使用的详细知识: 1. **Solr单机版安装**:首先,你需要下载最新版本的Solr压缩包,...
全文搜索是Solr的主要应用场景,通过索引文档内容,用户可以输入任意关键词进行搜索,Solr会返回最相关的文档。Solr支持多种查询类型,包括标准查询、范围查询、多字段查询等,同时还可以实现高亮显示搜索结果中的...
这个"Java项目-搜索引擎的设计与实现.zip"文件显然包含了实现一个搜索引擎的相关资料,包括数据库设计和源代码。下面我们将深入探讨Java中搜索引擎设计的关键技术和知识点。 1. **全文检索**:搜索引擎的核心功能是...
《Solr权威指南-下卷》是一本专为Java Web开发人员量身打造的参考资料,旨在帮助他们在开发过程中解决与Solr相关的问题。Solr是Apache Lucene项目的一个子项目,是一个高性能、全文检索服务器,广泛应用于大数据搜索...
1. **全文检索**:Solr的核心功能之一就是全文检索,它能够对输入的查询进行分析,找到相关度最高的文档。Solr支持多种语言的分词器,如英文的StandardAnalyzer和中文的SmartChineseAnalyzer,确保了跨语言的检索...