
Hashи®ҫи®Ўзҡ„еҺҹеҲҷжҳҜе°ҪйҮҸдҪҝе…ғзҙ еқҮеҢҖеҲҶеёғпјҢд»ҺиҖҢжңҖеӨ§еӨ„еҲ©з”ЁеҶ…еӯҳгҖӮ
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•жқҘжәҗдәҺ P2P зҪ‘з»ңзҡ„и·Ҝз”ұз®—жі•пјҢзӣ®еүҚдё»жөҒзҡ„ P2P иҪҜ件е°ұжҳҜеҲ©з”ЁжҲ‘们жүҖзҶҹзҹҘзҡ„ DHT (Distributed Hash TableпјҢеҲҶеёғејҸе“ҲеёҢиЎЁ) жқҘе®ҡдҪҚж•ҙдёӘеҲҶеёғејҸзҪ‘з»ңзҡ„дҝЎжҒҜпјҢеҸҰеӨ–жӯӨз®—жі•еңЁзӣ®еүҚзҒ«зғӯзҡ„дә‘и®Ўз®—йўҶеҹҹд№ҹе°ҶеҚ жңүжһҒе…¶йҮҚиҰҒзҡ„дҪҚзҪ®гҖӮеҸҜд»ҘиҜҙж•ЈеҲ—еҮҪж•°еңЁеҪ“д»Ји®Ўз®—жңәе’ҢзҪ‘з»ңзі»з»ҹдёӯжүҖиө·зҡ„йҮҚиҰҒдҪңз”ЁеӨ§е®¶еә”иҜҘ йғҪжңүзӣ®е…ұзқ№дәҶпјҢзү№еҲ«жҳҜеңЁзӣ®еүҚиҝҷдёӘеҲҶеёғејҸеә”з”ЁзҲҶзӮёзҡ„ж—¶д»ЈпјҢиҝҷдёӘж–№йқўзҡ„зҹҘиҜҶеҸӘдјҡи¶ҠжқҘи¶Ҡеј•иө·дәә们зҡ„йҮҚи§ҶпјҢжң¬ж–ҮйҮҚеңЁд»Һ Memcached иҝҷдёӘжөҒиЎҢзҡ„еҲҶеёғејҸеә”з”Ёзҡ„еңәжҷҜдёӯжқҘеҜ№дёҖиҮҙжҖ§е“ҲеёҢж•ЈеҲ—зҡ„еҮ дёӘдё»жөҒз®—жі•еҒҡдёҖдәӣжҜ”иҫғе’ҢеҲҶжһҗгҖӮ
В
[иғҢжҷҜдҝЎжҒҜ]
В
еҜ№дәҺ Memcached жқҘиҜҙпјҢжң¬иә«жҳҜйӣҶдёӯејҸзҡ„зј“еӯҳзі»з»ҹпјҢиҰҒжҗһеӨҡиҠӮзӮ№еҲҶеёғпјҢеҸӘиғҪйҖҡиҝҮе®ўжҲ·з«Ҝе®һзҺ°гҖӮMemcached зҡ„еҲҶеёғз®—жі•дёҖиҲ¬жңүдёӨз§ҚйҖүжӢ©пјҡ
В
1гҖҒж №жҚ® hash(key) зҡ„з»“жһңпјҢжЁЎиҝһжҺҘж•°зҡ„дҪҷж•°еҶіе®ҡеӯҳеӮЁеҲ°е“ӘдёӘиҠӮзӮ№пјҢд№ҹе°ұжҳҜ hash(key) % sessions.size()пјҢиҝҷдёӘз®—жі•з®ҖеҚ•еҝ«йҖҹпјҢиЎЁзҺ°иүҜеҘҪгҖӮ然иҖҢиҝҷдёӘз®—жі•жңүдёӘзјәзӮ№пјҢе°ұжҳҜеңЁmemcachedиҠӮзӮ№еўһеҠ жҲ–иҖ…еҲ йҷӨзҡ„ж—¶еҖҷпјҢеҺҹжңүзҡ„зј“еӯҳж•°жҚ® е°ҶеӨ§и§„жЁЎеӨұж•ҲпјҢе‘ҪдёӯзҺҮеӨ§еҸ—еҪұе“ҚпјҢеҰӮжһңиҠӮзӮ№ж•°еӨҡпјҢзј“еӯҳж•°жҚ®еӨҡпјҢйҮҚе»әзј“еӯҳзҡ„д»Јд»·еӨӘй«ҳпјҢеӣ жӯӨжңүдәҶ第дәҢдёӘз®—жі•гҖӮ
В
2гҖҒConsistent HashingпјҢдёҖиҮҙжҖ§е“ҲеёҢз®—жі•пјҢд»–зҡ„жҹҘжүҫиҠӮзӮ№иҝҮзЁӢеҰӮдёӢпјҡйҰ–е…ҲжұӮеҮә Memcached жңҚеҠЎеҷЁпјҲиҠӮзӮ№пјүзҡ„е“ҲеёҢеҖјпјҢ并е°Ҷе…¶й…ҚзҪ®еҲ° 0пҪһ232 зҡ„еңҶпјҲcontinuumпјүдёҠгҖӮ然еҗҺз”ЁеҗҢж ·зҡ„ж–№жі•жұӮеҮәеӯҳеӮЁж•°жҚ®зҡ„й”®зҡ„е“ҲеёҢеҖјпјҢ并жҳ е°„еҲ°еңҶдёҠгҖӮ然еҗҺд»Һж•°жҚ®жҳ е°„еҲ°зҡ„дҪҚзҪ®ејҖе§ӢйЎәж—¶й’ҲжҹҘжүҫпјҢе°Ҷж•°жҚ®дҝқеӯҳеҲ°жүҫеҲ°зҡ„第 дёҖдёӘжңҚеҠЎеҷЁдёҠгҖӮеҰӮжһңи¶…иҝҮ 232 д»Қ然жүҫдёҚеҲ°жңҚеҠЎеҷЁпјҢе°ұдјҡдҝқеӯҳеҲ°з¬¬дёҖеҸ° Memcached жңҚеҠЎеҷЁдёҠгҖӮ
В
дёӢеӣҫе°ұжҳҜдёҖиҮҙжҖ§е“ҲеёҢз®—жі•з®—жі•зҡ„зӨәж„ҸеӣҫпјҢжҜ”еҰӮжҲ‘们зҺ°еңЁжңү 4 еҸ°жңҚеҠЎеҷЁпјҢжҲ‘们жҠҠ他们зҡ„ hash еҖјеҪ“дҪң node иҠӮзӮ№жҢүз…§жҹҗз§Қе№іеқҮеҲҶеёғз®—жі•иў«еҲҶй…ҚеҲ°иҝҷдёӘзҺҜдёҠйқўпјҢжҲ‘们жҢүйЎәж—¶й’Ҳж–№еҗ‘ жҠҠ Key зҡ„е“ҲеёҢеҖјдёҺ node иҠӮзӮ№зҡ„ hash еҖјжҜ”иҫғпјҢжҖ»жҳҜжҠҠ Key иҠӮзӮ№дҝқеӯҳеҲ°жүҫеҲ°зҡ„第дёҖдёӘ hash еҖјеӨ§дәҺ Key иҠӮзӮ№зҡ„йӮЈдёӘ node иҠӮзӮ№жңҚеҠЎеҷЁдёҠпјҡ

В
зҺ°еңЁеҒҮеҰӮжҲ‘们жңүдёҖеҸ°ж–°зҡ„жңҚеҠЎеҷЁеҠ е…ҘиҝӣжқҘпјҲеҮҸе°‘дёҖдёӘжңҚеҠЎеҷЁеҗҢзҗҶпјүпјҢйӮЈд№ҲжҢүз…§жӯӨеүҚзҡ„з®—жі•пјҢеҸ—еҪұе“Қзҡ„ Key еҖјеҸӘжңүдёӢеӣҫй»„иүІйӮЈйғЁеҲҶзҡ„ж•°жҚ®пјҢд»Һжҹҗз§Қж„Ҹд№үдёҠз”ҡиҮіиҝҷж ·еҸҜд»ҘиҜҙпјҢеҠ е…Ҙзҡ„жңҚеҠЎеҷЁ node иҠӮзӮ№и¶ҠеӨҡпјҢеҸ—еҪұе“Қзҡ„ж•°жҚ®е°ұи¶Ҡе°‘ пјҢд»ҺиҖҢдҪҝиҝҷдёӘеҠЁжҖҒзҡ„еҲҶеёғејҸзі»з»ҹдёӯзҡ„ж•°жҚ®зЁіе®ҡжҖ§иҫҫеҲ°жңҖеӨ§пјҢиҖҢиҝҷе°ұжҳҜдёҖиҮҙжҖ§е“ҲеёҢз®—жі•зҡ„зІҫй«“жүҖеңЁдәҶпјҡ

В
Spymemcached е’Ң Xmemcached йғҪе®һзҺ°дәҶдёҖиҮҙжҖ§з®—жі•пјҢиҝҷйҮҢиҰҒжөӢиҜ•дёӢеңЁдҪҝз”ЁдёҖиҮҙжҖ§е“ҲеёҢзҡ„жғ…еҶөдёӢпјҢеўһеҠ иҠӮзӮ№пјҢзңӢдёҚеҗҢж•ЈеҲ—еҮҪж•°дёӢе‘ҪдёӯзҺҮе’Ңж•°жҚ®еҲҶеёғзҡ„еҸҳеҢ–жғ…еҶөпјҢиҝҷдёӘжөӢиҜ•з»“жһңеҜ№дәҺ Spymemcached е’Ң Xmemcached жҳҜдёҖж ·зҡ„пјҢжөӢиҜ•еңәжҷҜпјҡ
В
д»ҺдёҖзҜҮиӢұж–Үе°ҸиҜҙпјҲгҖҠй»„йҮ‘зҪ—зӣҳгҖӢеүҚдёүз« пјүиҝӣиЎҢеҚ•иҜҚз»ҹи®ЎпјҢ并е°ҶжңҖеҗҺзҡ„з»ҹи®Ўз»“жһңеӯҳеӮЁеҲ° MemcachedпјҢд»ҘеҚ•иҜҚдёә KeyпјҢд»Ҙж¬Ўж•°дёә ValueгҖӮеҚ•иҜҚдёӘж•°дёә 3061пјҢMemcached еҺҹжқҘиҠӮзӮ№ж•°дёә10пјҢиҝҗиЎҢеңЁеұҖеҹҹзҪ‘еҶ…еҗҢдёҖеҸ°жңҚеҠЎеҷЁдёҠзҡ„дёҚеҗҢз«ҜеҸЈпјҢеңЁеӯҳеӮЁз»ҹи®Ўз»“жһңеҗҺпјҢеўһеҠ дёӨдёӘ Memcached иҠӮзӮ№пјҲд№ҹе°ұжҳҜд»Һ 10дёӘиҠӮзӮ№еўһеҠ еҲ°12дёӘиҠӮзӮ№пјүпјҢз»ҹи®ЎжӯӨж—¶зҡ„зј“еӯҳе‘ҪдёӯзҺҮ并жҹҘзңӢж•°жҚ®зҡ„еҲҶеёғжғ…еҶөгҖӮ
В
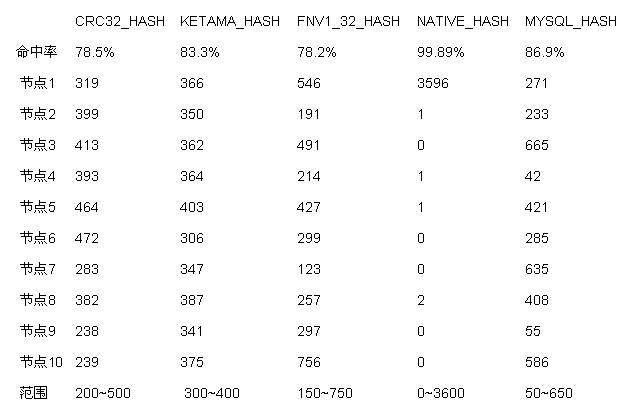
з»“жһңеҰӮдёӢиЎЁж јпјҢе‘ҪдёӯзҺҮдёҖиЎҢиЎЁзӨәеўһеҠ иҠӮзӮ№еҗҺзҡ„е‘ҪдёӯзҺҮжғ…еҶөпјҲеўһеҠ еүҚдёә100%пјүпјҢеҗҺз»ӯзҡ„иЎҢиЎЁзӨәеҗ„дёӘиҠӮзӮ№еӯҳеӮЁзҡ„еҚ•иҜҚж•°,CRC32_HASH иЎЁзӨәйҮҮз”Ё CRC32 ж•ЈеҲ—еҮҪж•°пјҢKETAMA_HASH жҳҜеҹәдәҺ md5 зҡ„ж•ЈеҲ—еҮҪж•°д№ҹжҳҜй»ҳи®Өжғ…еҶөдёӢдёҖиҮҙжҖ§е“ҲеёҢзҡ„жҺЁиҚҗз®—жі•пјҢFNV1_32_HASH е°ұжҳҜ FNV 32 дҪҚж•ЈеҲ—еҮҪж•°пјҢNATIVE_HASH е°ұжҳҜ java.lang.String.hashCode() ж–№жі•иҝ”еӣһзҡ„ long еҸ– 32 дҪҚзҡ„з»“жһңпјҢMYSQL_HASH жҳҜ Xmemcached ж·»еҠ зҡ„дј иҜҙжқҘиҮӘдәҺ mysql жәҗз Ғдёӯзҡ„е“ҲеёҢеҮҪж•°гҖӮ
В
В
[з»“жһңеҲҶжһҗ]
В
1гҖҒе‘ҪдёӯзҺҮжңҖй«ҳзңӢиө·жқҘжҳҜNATIVE_HASHпјҢ然иҖҢNATIVE_HASHжғ…еҶөдёӢж•°жҚ®йӣҶдёӯеӯҳеӮЁеңЁз¬¬дёҖдёӘиҠӮзӮ№пјҢжҳҫ然没жңүе®һйҷ…дҪҝз”Ёд»·еҖјгҖӮдёәд»Җд№ҲдјҡйӣҶдёӯ еӯҳеӮЁеңЁз¬¬дёҖдёӘиҠӮзӮ№е‘ўпјҹиҝҷжҳҜз”ұдәҺеңЁжҹҘжүҫеӯҳеӮЁзҡ„иҠӮзӮ№зҡ„иҝҮзЁӢдёӯпјҢдјҡжҜ”иҫғhash(key)е’Ңhash(иҠӮзӮ№IPең°еқҖ)пјҢиҖҢеңЁйҮҮз”ЁдәҶNATIVE_HASHзҡ„жғ…еҶө дёӢпјҢжүҖжңүиҝһжҺҘзҡ„hashеҖјдјҡе‘ҲзҺ°дёҖдёӘйҖ’еўһзҠ¶еҶөпјҲеӣ дёәString.hashCodeжҳҜд№ҳжі•ж•ЈеҲ—еҮҪж•°пјүпјҢеҰӮпјҡ
192.168.0.100:12000 736402923
192.168.0.100:12001 736402924
192.168.0.100:12002 736402925
192.168.0.100:12003 736402926
еҰӮжһңиҝҷдәӣеҖјеҫҲеӨ§зҡ„дјҡпјҢйӮЈд№ҲеҚ•иҜҚзҡ„hashCode()дјҡйҖҡеёёе°ҸдәҺиҝҷдәӣеҖјзҡ„第дёҖдёӘпјҢйӮЈд№ҲжҹҘжүҫе°ұз»ҸеёёеҸӘжүҫеҲ°з¬¬дёҖдёӘиҠӮзӮ№е№¶еӯҳеӮЁж•°жҚ®пјҢеҪ“然пјҢиҝҷйҮҢжңүжөӢиҜ•зҡ„еұҖ йҷҗжҖ§пјҢеӣ дёәmemcachedйғҪи·‘еңЁдёҖдёӘеҸ°жңәеҷЁдёҠеҸӘжҳҜз«ҜеҸЈдёҚеҗҢйҖ жҲҗдәҶhash(иҠӮзӮ№IPең°еқҖ)зҡ„иҝһз»ӯйҖ’еўһпјҢе°ҶеҲҶеёғдёҚеқҮеҢҖзҡ„й—®йўҳж”ҫеӨ§дәҶгҖӮ
В
2гҖҒд»Һз»“жһңдёҠзңӢпјҢKETAMA_HASH з»ҙжҢҒдәҶдёҖдёӘжңҖдҪіе№іиЎЎпјҢеңЁеўһеҠ дёӨдёӘиҠӮзӮ№еҗҺиҝҳиғҪи®ҝй—®еҲ°83.3%зҡ„еҚ•иҜҚпјҢ并且数жҚ®еҲҶеёғеңЁеҗ„дёӘиҠӮзӮ№дёҠзҡ„ж•°зӣ®д№ҹзӣёеҜ№е№іеқҮпјҢйҡҫжҖӘдҪңдёәй»ҳи®Өж•ЈеҲ—з®—жі•гҖӮ
В
3гҖҒжңҖеҗҺпјҢеҚ•зәҜжҜ”иҫғдёӢж•ЈеҲ—еҮҪж•°зҡ„и®Ўз®—ж•ҲзҺҮпјҡ
CRC32_HASH:3266
KETAMA_HASH:7500
FNV1_32_HASH:375
NATIVE_HASH:187
MYSQL_HASH:500
з®ҖеҚ•зңӢд»ҘдёҠз®—жі•зҡ„ж•ҲзҺҮжҺ’еәҸеҰӮдёӢпјҡ
NATIVE_HASH > FNV1_32_HASH > MYSQL_HASH > CRC32_HASH > KETAMA_HASH
В
з»јдёҠжүҖиҝ°пјҢеӨ§е®¶еҸҜд»ҘжҜ”иҫғжё…жҘҡзҡ„зңӢеҮәе“Әз§Қ hash з®—жі•йҖӮеҗҲдҪ жүҖеңЁзҡ„еңәжҷҜпјҢеҜ№дәҺеҲҶеёғејҸеә”з”ЁпјҢжң¬дәәжҜ”иҫғжҺЁиҚҗеңЁ CRC32_HASHгҖҒFNV1_32_HASHгҖҒKETAMA_HASH иҝҷдёүз§Қз®—жі•дёӯйҖүжӢ©пјҢиҮідәҺдҪ жҳҜжіЁйҮҚз®—жі•ж•ҲзҺҮиҝҳжҳҜе‘ҪдёӯзҺҮпјҢиҝҷе°ұйңҖиҰҒж №жҚ®е…·дҪ“зҡ„еңәжҷҜжқҘйҖүжӢ©дәҶгҖӮеҸҰеӨ–пјҢеҜ№дәҺ PHP е®ўжҲ·з«ҜеҸҜд»ҘйҖҡиҝҮ Memcache жү©еұ•еҰӮдёӢй…ҚзҪ®пјҲеңЁ php.ini дёӯпјүжқҘйҖүжӢ©пјҡ
memcache.hash_function={crc32(default),fnv}
memcache.hash_strategy={consistent(default),standard}
然еҗҺйҖҡиҝҮ Memcache::addServer еҮҪж•°еҚіеҸҜж·»еҠ жңҚеҠЎеҷЁиҠӮзӮ№дәҶпјҢзӣёеҪ“ж–№дҫҝе“Ұ~



зӣёе…іжҺЁиҚҗ
memcachedзҡ„еҲҶеёғејҸзү№жҖ§дҪҝе…¶иғҪеӨҹеңЁеӨҡеҸ°жңҚеҠЎеҷЁдёҠеҲҶеёғзј“еӯҳпјҢйҖҡиҝҮдёҖиҮҙжҖ§е“ҲеёҢз®—жі•е®һзҺ°ж•°жҚ®зҡ„еқҮеҢҖеҲҶеёғпјҢеҪ“йӣҶзҫӨдёӯзҡ„жҹҗдёӘиҠӮзӮ№еҮәзҺ°й—®йўҳж—¶пјҢеҸҜд»ҘйҖҡиҝҮе…¶д»–иҠӮзӮ№з»§з»ӯжҸҗдҫӣжңҚеҠЎпјҢдҝқиҜҒзі»з»ҹзҡ„й«ҳеҸҜз”ЁжҖ§гҖӮжӯӨеӨ–пјҢmemcachedж”ҜжҢҒеӨҡз§Қж•°жҚ®...
1. **иҙҹиҪҪеқҮиЎЎ**пјҡзЎ®дҝқж•°жҚ®еқҮеҢҖеҲҶеёғеҲ°еҗ„дёӘиҠӮзӮ№пјҢйҒҝе…ҚжҹҗдәӣиҠӮзӮ№иҝҮиҪҪпјҢеҸҜд»ҘдҪҝз”ЁдёҖиҮҙжҖ§е“ҲеёҢз®—жі•жқҘеҲҶй…Қй”®еҖјеҜ№гҖӮ 2. **ж•…йҡңжҒўеӨҚ**пјҡеҪ“жҹҗдёӘиҠӮзӮ№еҮәзҺ°ж•…йҡңж—¶пјҢйңҖиҰҒжңүжңәеҲ¶иҮӘеҠЁе°Ҷж•°жҚ®йҮҚж–°еҲҶй…ҚеҲ°е…¶д»–еҒҘеә·иҠӮзӮ№пјҢдҝқиҜҒжңҚеҠЎиҝһз»ӯжҖ§гҖӮ...
жҖ»з»“жқҘиҜҙпјҢMemcachedзҡ„еҲҶеёғејҸзј“еӯҳе®һзҺ°дё»иҰҒдҫқиө–дәҺе®ўжҲ·з«Ҝзҡ„е“ҲеёҢз®—жі•пјҢеҢ…жӢ¬дҪҷж•°и®Ўз®—еҲҶж•Јжі•е’ҢдёҖиҮҙжҖ§е“ҲеёҢгҖӮиҝҷдәӣзӯ–з•ҘзЎ®дҝқдәҶж•°жҚ®еңЁеӨҡеҸ°жңҚеҠЎеҷЁй—ҙзҡ„жңүж•ҲеҲҶеёғпјҢеҮҸе°‘дәҶж•°жҚ®еә“зҡ„еҺӢеҠӣпјҢжҸҗй«ҳдәҶзі»з»ҹзҡ„е“Қеә”йҖҹеәҰе’ҢеҸҜжү©еұ•жҖ§гҖӮеңЁе®һйҷ…...
еңЁеҲҶеёғејҸзј“еӯҳзі»з»ҹеҰӮMemcachedжҲ–RedisдёӯпјҢдёҖиҮҙжҖ§е“ҲеёҢз®—жі•иў«е№ҝжіӣдҪҝз”ЁгҖӮеҪ“з”ЁжҲ·иҜ·жұӮж•°жҚ®ж—¶пјҢж №жҚ®ж•°жҚ®зҡ„й”®иҝӣиЎҢе“ҲеёҢиҝҗз®—пјҢ然еҗҺеңЁе“ҲеёҢзҺҜдёҠжүҫеҲ°жңҖиҝ‘зҡ„жңҚеҠЎеҷЁиҠӮзӮ№жқҘеӯҳеӮЁжҲ–жЈҖзҙўж•°жҚ®гҖӮиҝҷз§Қж–№ејҸзЎ®дҝқдәҶж•°жҚ®дёҺжңҚеҠЎеҷЁд№Ӣй—ҙзҡ„з»‘е®ҡе…ізі»...
1. **еҲҶеёғејҸ**: Memcachedе°Ҷж•°жҚ®еҲҶж•ЈеӯҳеӮЁеңЁеӨҡеҸ°жңҚеҠЎеҷЁдёҠпјҢйҖҡиҝҮдёҖиҮҙжҖ§е“ҲеёҢз®—жі•е®һзҺ°ж•°жҚ®зҡ„еҲҶеёғејҸеӯҳеӮЁпјҢзЎ®дҝқж•°жҚ®зҡ„жӯЈзЎ®еҲҶеёғе’ҢиҙҹиҪҪеқҮиЎЎгҖӮ 2. **еҶ…еӯҳеӯҳеӮЁ**: з”ұдәҺMemcachedдё»иҰҒеҲ©з”ЁеҶ…еӯҳиҝӣиЎҢж•°жҚ®еӯҳеӮЁпјҢеӣ жӯӨе…¶иҜ»еҸ–йҖҹеәҰжһҒеҝ«...
2. **еҲҶеёғејҸзӯ–з•Ҙ**пјҡйҖҡиҝҮдёҖиҮҙжҖ§е“ҲеёҢжҲ–е…¶д»–з®—жі•е®һзҺ°ж•°жҚ®еңЁеӨҡеҸ°MemcachedжңҚеҠЎеҷЁй—ҙзҡ„еқҮеҢҖеҲҶеёғгҖӮ 3. **жҖ§иғҪзӣ‘жҺ§**пјҡе®ҡжңҹжЈҖжҹҘMemcachedзҡ„е‘ҪдёӯзҺҮгҖҒеҶ…еӯҳдҪҝз”Ёжғ…еҶөзӯүжҢҮж ҮпјҢеҸҠж—¶и°ғж•ҙзӯ–з•ҘгҖӮ **е…ӯгҖҒMemcachedдёҺж•°жҚ®еә“зҡ„еҚҸеҗҢ...
7. **ж•…йҡңиҪ¬з§»дёҺеҲҶеёғејҸдёҖиҮҙжҖ§**пјҡеҰӮдҪ•еӨ„зҗҶиҠӮзӮ№ж•…йҡңпјҢд»ҘеҸҠMemcachedзҡ„еҲҶеёғејҸдёҖиҮҙжҖ§е“ҲеёҢз®—жі•гҖӮ 8. **жҖ§иғҪдјҳеҢ–**пјҡзј“еӯҳе‘ҪдёӯзҺҮжҸҗеҚҮжҠҖе·§пјҢйҒҝе…Қзј“еӯҳеҮ»з©ҝгҖҒйӣӘеҙ©зӯүй—®йўҳзҡ„ж–№жі•гҖӮ 9. **жәҗз ҒеҲҶжһҗ**пјҡеҰӮжһңеҢ…еҗ«жәҗз ҒпјҢеҸҜиғҪж¶үеҸҠе…·дҪ“...
C#е®һзҺ°дёҖиҮҙжҖ§е“ҲеёҢзҡ„е…ій”®еңЁдәҺйҖүжӢ©еҗҲйҖӮзҡ„е“ҲеёҢеҮҪж•°е’ҢиҠӮзӮ№еҲҶеёғзӯ–з•ҘгҖӮKetamaHash-codeиҝҷдёӘеҗҚеӯ—еҸҜиғҪжҢҮзҡ„жҳҜдҪҝз”ЁдәҶKetamaдёҖиҮҙжҖ§е“ҲеёҢзҡ„е®һзҺ°гҖӮKetamaжҳҜMemcachedзҡ„дёҖдёӘжү©еұ•пјҢе®ғеј•е…ҘдәҶиҷҡжӢҹиҠӮзӮ№зҡ„жҰӮеҝөпјҢйҖҡиҝҮдёәжҜҸдёӘе®һйҷ…иҠӮзӮ№з”ҹжҲҗеӨҡ...
е®ўжҲ·з«ҜдҪҝз”Ёзү№е®ҡзҡ„еҲҶеёғејҸз®—жі•пјҲдҫӢеҰӮдёҖиҮҙжҖ§е“ҲеёҢпјүжқҘеҶіе®ҡж•°жҚ®еә”еӯҳеӮЁеңЁе“ӘдёӘжңҚеҠЎеҷЁдёҠгҖӮиҝҷз§Қи®ҫи®Ўе…Ғи®ёMemcachedеңЁеӨҡеҸ°жңҚеҠЎеҷЁдёҠеҲҶж•ЈеӨ§йҮҸж•°жҚ®пјҢеҮҸиҪ»еҚ•дёҖжңҚеҠЎеҷЁзҡ„еҺӢеҠӣпјҢ并且иғҪе®һзҺ°зј“еӯҳзҡ„жү©еұ•жҖ§гҖӮ Memcachedзҡ„и®ҫи®Ўзү№еҫҒеҢ…жӢ¬пјҡ 1...
4. **еҲҶеёғејҸзј“еӯҳеҺҹзҗҶ**пјҡзҗҶи§ЈеҲҶеёғејҸзј“еӯҳзҡ„е·ҘдҪңж–№ејҸпјҢеҰӮй”®еҖјеӯҳеӮЁгҖҒж•°жҚ®еҲҶзүҮгҖҒдёҖиҮҙжҖ§е“ҲеёҢгҖҒиҝҮжңҹзӯ–з•ҘзӯүгҖӮ 5. **SQLж•°жҚ®еә“дәӨдә’**пјҡжҺҢжҸЎеҰӮдҪ•е°ҶMemcachedдёҺSQLж•°жҚ®еә“з»“еҗҲдҪҝз”ЁпјҢдјҳеҢ–иҜ»еҶҷж“ҚдҪңпјҢе®һзҺ°иҜ»еҶҷеҲҶзҰ»е’ҢиҙҹиҪҪеқҮиЎЎгҖӮ 6. ...
- **ж”ҜжҢҒConsistentHashingзҡ„еҮҪж•°еә“**пјҡеҰӮKetamaзӯүеә“жҸҗдҫӣдәҶе®һзҺ°дёҖиҮҙжҖ§е“ҲеёҢеҠҹиғҪзҡ„ж”ҜжҢҒгҖӮ #### дә”гҖҒMemcachedзҡ„еә”з”Ёе’Ңе…је®№зЁӢеәҸ **5.1 mixiжЎҲдҫӢз ”з©¶** - **жңҚеҠЎеҷЁй…ҚзҪ®е’Ңж•°йҮҸ**пјҡmixiдҪҝз”ЁеӨ§йҮҸзҡ„memcachedжңҚеҠЎеҷЁйӣҶзҫӨжқҘ...
дёҖиҮҙжҖ§е“ҲеёҢпјҲConsistent HashingпјүжҳҜдёҖз§ҚеҲҶеёғејҸе“ҲеёҢз®—жі•пјҢдё»иҰҒеә”з”ЁдәҺеҲҶеёғејҸзј“еӯҳгҖҒиҙҹиҪҪеқҮиЎЎзӯүйўҶеҹҹпјҢдҫӢеҰӮMemcachedе’ҢRedisзӯүзі»з»ҹгҖӮе®ғи§ЈеҶідәҶеңЁеҲҶеёғејҸзҺҜеўғдёӯж•°жҚ®еҲҶзүҮдёҺиҠӮзӮ№еҠЁжҖҒеўһеҮҸж—¶пјҢе°ҪйҮҸеҮҸе°‘ж•°жҚ®иҝҒ移зҡ„й—®йўҳгҖӮеёҰиҷҡжӢҹ...
жӯӨеӨ–пјҢдёҖиҮҙжҖ§е“ҲеёҢз®—жі•еңЁеҲҶеёғејҸзј“еӯҳеҰӮMemcachedгҖҒRedisдёӯд№ҹеҫ—еҲ°дәҶе№ҝжіӣеә”з”ЁгҖӮе®ғдёҚд»…з®ҖеҢ–дәҶж•°жҚ®еҲҶеёғзҡ„йҖ»иҫ‘пјҢиҝҳе…Ғи®ёеҠЁжҖҒжү©еұ•е’Ң收缩йӣҶзҫӨ规模пјҢж— йңҖеӨ§и§„жЁЎзҡ„ж•°жҚ®иҝҒ移гҖӮ еңЁж–Ү件еҗҚдёәвҖңdistribute-mysqlвҖқзҡ„еҺӢзј©еҢ…дёӯпјҢеҸҜиғҪ...
е®ўжҲ·з«Ҝж №жҚ®дёҖиҮҙжҖ§е“ҲеёҢзӯ–з•ҘйҖүжӢ©еҗҲйҖӮзҡ„жңҚеҠЎеҷЁиҝӣиЎҢж“ҚдҪңгҖӮеҰӮжһңжҹҗдёӘжңҚеҠЎеҷЁж•…йҡңпјҢе®ўжҲ·з«ҜдјҡиҮӘеҠЁе°ҶиҜ·жұӮи·Ҝз”ұеҲ°е…¶д»–жңҚеҠЎеҷЁпјҢдҝқиҜҒжңҚеҠЎзҡ„еҸҜз”ЁжҖ§гҖӮ 然иҖҢпјҢиҝҷз§ҚеҲҶеёғејҸзӯ–з•Ҙд№ҹжңүдёҖдәӣеұҖйҷҗжҖ§гҖӮдҫӢеҰӮпјҢе®ғж— жі•е®һзҺ°ж•°жҚ®зҡ„и·ЁжңҚеҠЎеҷЁеӨҚеҲ¶пјҢ...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•жҳҜдёҖз§ҚеҲҶеёғејҸе“ҲеёҢпјҲDistributed Hash Table, DHTпјүжҠҖжңҜпјҢж—ЁеңЁи§ЈеҶіеңЁеҲҶеёғејҸзҺҜеўғдёӯж•°жҚ®еҲҶеёғдёҚеқҮеҢҖзҡ„й—®йўҳгҖӮKetamaз®—жі•жҳҜеҹәдәҺдёҖиҮҙжҖ§е“ҲеёҢзҡ„дёҖз§ҚдјҳеҢ–е®һзҺ°пјҢз”ұLast.fmе…¬еҸёзҡ„Simon WillisonжҸҗеҮәпјҢе…¶зӣ®ж ҮжҳҜеңЁ...
- **дёҖиҮҙжҖ§е“ҲеёҢ**: дёәи§ЈеҶіжңҚеҠЎеҷЁж·»еҠ жҲ–еҲ йҷӨж—¶еҜјиҮҙзҡ„ж•°жҚ®йҮҚж–°еҲҶеёғй—®йўҳпјҢеҸҜд»ҘйҮҮз”ЁдёҖиҮҙжҖ§е“ҲеёҢз®—жі•гҖӮ - **еҲҶзүҮзӯ–з•Ҙ**: йҖҡиҝҮж•°жҚ®еҲҶзүҮпјҢе°ҶеӨ§еһӢж•°жҚ®йӣҶеҲҶж•ЈеҲ°еӨҡдёӘзј“еӯҳе®һдҫӢпјҢе№іиЎЎеҗ„дёӘиҠӮзӮ№зҡ„иҙҹиҪҪгҖӮ з»јдёҠжүҖиҝ°пјҢMemcached жҳҜ...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•еә”з”ЁеҸҠдјҳеҢ–жҳҜITйўҶеҹҹдёӯеҲҶеёғејҸзі»з»ҹи®ҫи®Ўзҡ„ж ёеҝғжҠҖжңҜд№ӢдёҖпјҢзү№еҲ«жҳҜеңЁеӨ„зҗҶеӨ§и§„жЁЎж•°жҚ®еҲҶеёғдёҺзј“еӯҳзі»з»ҹдёӯпјҢе…¶йҮҚиҰҒжҖ§дёҚиЁҖиҖҢе–»гҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁдёҖиҮҙжҖ§е“ҲеёҢз®—жі•зҡ„еҹәжң¬жҰӮеҝөгҖҒе·ҘдҪңеҺҹзҗҶд»ҘеҸҠеңЁе®һйҷ…еңәжҷҜдёӯзҡ„еә”з”Ёе’ҢдјҳеҢ–...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•жҳҜдёҖз§ҚеңЁеҲҶеёғејҸзі»з»ҹдёӯи§ЈеҶіиҙҹиҪҪеқҮиЎЎе’Ңж•°жҚ®еҲҶеёғй—®йўҳзҡ„жңүж•Ҳж–№жі•гҖӮеңЁдј з»ҹзҡ„е“ҲеёҢз®—жі•дёӯпјҢеҪ“ж·»еҠ жҲ–移йҷӨжңҚеҠЎеҷЁиҠӮзӮ№ж—¶пјҢеӨ§йғЁеҲҶж•°жҚ®йңҖиҰҒйҮҚж–°жҳ е°„пјҢеҜјиҮҙеӨ§и§„жЁЎзҡ„ж•°жҚ®иҝҒ移гҖӮиҖҢдёҖиҮҙжҖ§е“ҲеёҢз®—жі•йҖҡиҝҮзү№е®ҡзҡ„и®ҫи®ЎпјҢиғҪеӨҹ...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•пјҲConsistent HashingпјүжҳҜдёҖз§ҚеңЁеҲҶеёғејҸзі»з»ҹдёӯе®һзҺ°иҙҹиҪҪеқҮиЎЎзҡ„з®—жі•...еңЁзҗҶи§Је’Ңеә”з”ЁдёҖиҮҙжҖ§е“ҲеёҢж—¶пјҢйңҖиҰҒиҖғиҷ‘еҰӮдҪ•еҗҲзҗҶи®ҫзҪ®иҷҡжӢҹиҠӮзӮ№ж•°йҮҸгҖҒйҖүжӢ©еҗҲйҖӮзҡ„е“ҲеёҢеҮҪж•°д»ҘеҸҠдјҳеҢ–ж•°жҚ®еҲҶеёғзӯ–з•ҘпјҢд»ҘйҖӮеә”дёҚеҗҢеә”з”ЁеңәжҷҜзҡ„йңҖжұӮгҖӮ
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•(Consistent Hashing)жҳҜдёҖз§ҚеңЁеҲҶеёғејҸзі»з»ҹдёӯе№іиЎЎж•°жҚ®еҲҶеёғзҡ„зӯ–з•ҘпјҢе°Өе…¶йҖӮз”ЁдәҺзј“еӯҳжңҚеҠЎеҰӮMemcachedжҲ–RedisгҖӮе®ғзҡ„ж ёеҝғжҖқжғіжҳҜйҖҡиҝҮе“ҲеёҢеҮҪж•°е°ҶеҜ№иұЎжҳ е°„еҲ°дёҖдёӘеӣәе®ҡеӨ§е°Ҹзҡ„зҺҜеҪўз©әй—ҙдёӯпјҢ然еҗҺе°ҶжңҚеҠЎеҷЁд№ҹжҳ е°„еҲ°иҝҷдёӘ...