
静态类型是现代语言的发展趋势之一。近年来,不仅有很多静态类型的现代语言兴起,还有不少动态类型语言也在引入静态类型支持。
下面我们就来看下为何静态类型会如此受到现代语言的青睐。
静态类型的优势
与动态类型相比,静态类型有如下优势:
更佳的性能
静态类型有利于编译器优化,生成效率更高的代码。类型信息不仅有助于编译型静态类型语言编译,对于一些具有 JIT 的动态类型语言同样有积极意义,如减少 JIT 开销、提供更多优化信息等。
及早发现错误
在动态类型代码中,类型不匹配的错误需要在运行期才能发现。而在在静态类型代码中,可将这类错误的发现提前至编译期,甚至在 IDE 的辅助下还可以更进一步提前至编码期。
让我们先看一个静态类型语言的例子,这是一段 Kotlin 代码:
val hello = "Hello world"
val result = hello / 2
fun main(args: Array<String>) {
println(result)
}
如果把上面代码粘贴在普通文本编辑器中并保存,然后编译会得到以下错误:

即上述代码中的类型不匹配错误可在编译期发现。 而如果在 IntelliJ IDEA 中手动输入这些代码的话,当输入完第二行的时候,就会得到以下错误提示:
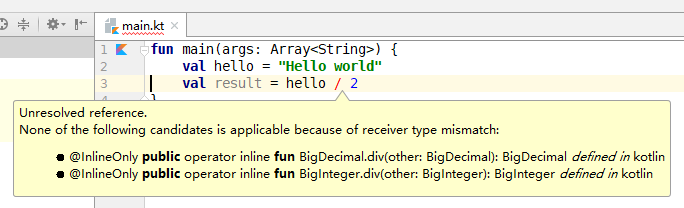
也就是说,通过 IDEA 的辅助,可以在编码期捕获到类型不匹配的错误。
接下来我们再看一个动态类型语言的例子,以 Python 3 为例对比下引入静态类型支持前后的差异:
def plus_five(num):
return num + 5
plus_five("Hello")
在 PyCharm 中,这段代码可以正常键入没有任何错误提示,只是运行时会出现以下报错:
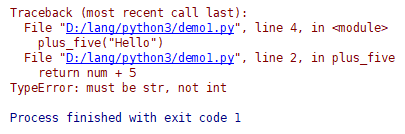
现在,我们加上类型标注再试一次:
def plus_five(num: int) -> int:
return num + 5
plus_five("Hello")
当输入完 plus_five("Hello") 就能在 PyCharm 中得到以下错误提示:
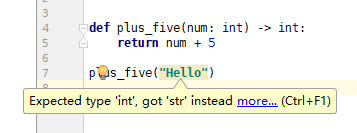
可以看出,即使在 Python 3 这样的动态类型语言中,也能通过静态类型(类型标注)与 IDE 辅助成功地将原本要在运行时才能发现的类型不匹配的错误,提前到编码阶段发现。
更好的工具支持
静态类型能为 IDE 智能补全、重构以及其他静态分析提供良好支持。我们看个 Python 3 代码智能补全的例子:
hello = "Hello world"
def to_constant_name(s):
return s.upper().replace(' ', '_')
print(to_constant_name(hello))
如果顺序键入代码,当写到 return s. 时,即便是 PyCharm 这样智能的 IDE 也无法自动列出类型 str 的成员。但如果加上类型标注,情形就完全不同了:
hello = "Hello world"
def to_constant_name(s: str) -> str:
return s.upper().replace(' ', '_')
print(to_constant_name(hello))
当键入到 s.u 的时候 PyCharm 就会弹出下图的菜单,按 Tab 即可完成补全:
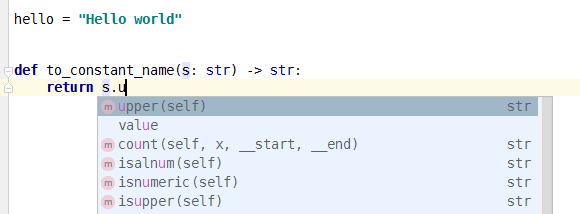
之后的 .replace() 与之类似。
易于理解
代码中有函数参数类型、返回值类型、变量类型以及泛型约束这些类型信息作为辅助,能让生疏的代码更易于理解。这在接手新项目、阅读开源代码以及代码评审实践中都能带来很多便利。
小结
静态类型能够提升程序的性能、健壮性、代码质量与可维护性。因此,很多现代的动态类型语言都引入了对静态类型的支持。
动态类型语言中的静态类型支持
Python 的类型提示
Python 的类型标注称为类型提示(Type hint)。在上文中我们已经看到,借助 IDE,它能够获得静态类型的几点优势。但是这些信息只用于工具检查,Python 运行时自身并不会对类型提示做校验,是名副其实的“提示”。例如下述代码能够正常运行:
def print_int(i: int) -> None:
print(i)
print_int("Hello")
这段代码中声明了一个输出整数的函数 print_int,函数类型提示指出该函数只接受整数,但当我们传给它一个字符串的时候,它一样能够正常输出。
Julia 的类型标注
Julia 是定位于科学计算、数据统计等数值计算领域的现代语言,旨在取代 Matlab、R、Python、Fortran 等在该领域的地位。 与 Python 3 不同,Julia 会针对类型标注做运行时校验,同样以一个只输出整数的函数为例:
function print_int(i::Int)::Void
print(i)
end
如果给该函数传一个整型参数,它能够正常输出。而如果传入其他类型的参数,它会报错:
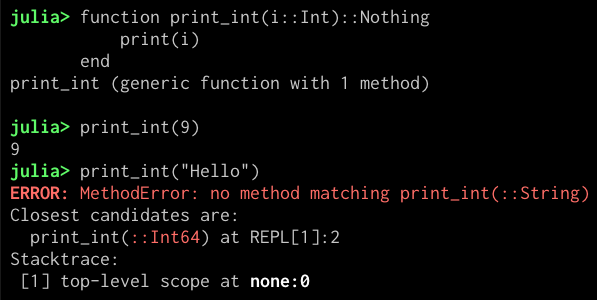
对于解释执行也会得到类似的错误信息。除此之外 Julia 还会(在 JIT 中)利用类型信息进行性能优化以及函数重载,作为专业的数值计算语言,这两点对 Julia 尤为重要。
Hack 的严格模式
Hack 是 Facebook 开源的一门动态语言,保留了对 PHP 的良好兼容性的同时,引入了对静态类型的支持。与 Python 3、Julia 类似,Hack 同样支持类型标注。不同的是 Hack 的运行时 HHVM 对于以 <?hh开头 Hack 语言文件(HHVM 也支持以 <?php 开头的 PHP 语言文件)会要求首先运行类型检查工具,以便在运行前发现问题。继续以输出整数的代码为例,Hack 代码需要用严格模式才能检测出问题。
Hack 语言的严格模式不允许调用传统 PHP 代码或非严格 Hack 代码,要求所有代码进行类型标注,并且除了 require 语句、函数与类声明之外不允许有其他顶层代码。因此输出整数的 Hack 代码需要分成两个文件来写:
a.hh —— 严格模式代码,以 <?hh // strict 开头
<?hh // strict
function print_int(int $i): void {
echo $i;
}
function main(): void {
print_int(5);
print_int("hello");
}
b.hh —— 非严格模式,可以在顶层调用严格模式代码,用于执行 main 函数。
<?hh
main();
上述代码,在运行类型检查工具时,会报以下错误:

当然,检查过后就可以运行相应代码了。虽然检查到了错误,仍然可以忽略之继续任性运行。运行同样会报运行时错误:
sh-4.2$ hhvm b.hh
Catchable fatal error: Hack type error: Invalid argument at /tmp/a.hh line 9
Hack 的检查工具还能做类型检查之外一些其他静态分析。与 Julia 类似,HHVM 也会在 JIT 中利用类型信息来改善性能。
Groovy 的混合类型
Groovy 是同时支持动态类型与静态类型的动态语言。如果说 Hack 相当于在动态类型语言 PHP 的基础上引入了静态类型,那么 Groovy 正好相反,它相当于在静态类型语言 Java 的基础上引入了动态类型。
虽然 Groovy 支持动态类型、在实践中广泛应用并且也带来了很多便利,不过仍然有很多场景它推荐使用静态类型,比如类成员声明等。另外 Groovy 程序也可以编译后运行,并且可以在编译期做类型检查。同样以输出整数的函数为例:
import groovy.transform.TypeChecked
def print_int(int i) {
print i
}
@TypeChecked
def main() {
print_int(5)
print_int("hello")
}
main()
无论编译或者直接运行都会报这个错:
org.codehaus.groovy.control.MultipleCompilationErrorsException: startup failed:
demo1.groovy: 10: [Static type checking] - Cannot find matching method demo1#print_int(java.lang.String). Please check if the declared type is right and if the method exists.
@ line 10, column 5.
print_int("hello")
^
1 error
其他
除此之外,混合类型语言还有 Dart、Perl 6 等;在动态类型语言里基础上引入静态类型的还有著名的 TypeScript 语言,以及一堆带有 Typed 前缀的语言,如 Typed Racket、Typed Clojure、Type Scheme、Typed Lua 等等。可见静态类型对于动态类型语言也是一个重要补充。
动态类型的出发点主要是省却类型声明让代码更简洁、编码更便利,另外还能让同样的代码可适用于多种不同类型(鸭子类型)。相比之下传统的 C、Java 以及传统 C++ 等静态类型语言却很麻烦,需要写不少样板代码。而这些问题在现代静态类型语言中已经有明显改善,它们能够提供近乎动态类型语言的简洁便利性的同时,还能确保性能、类型安全以及良好的工具支持。接下来我们就看下静态语言的改善之处吧。
静态类型的便利性改善
REPL
通常静态类型语言都是编译型语言,编译构建是静态类型语言相对动态类型语言比较麻烦的问题之一,尤其是需要只写几行代码试验效果的时候。现代静态类型语言为这一场景提供了交互式编程环境,即 REPL(Read-Eval-Print Loop),这在小段代码测试或者实验驱动开发中非常有用。下表列举了一些现代静态类型语言的 REPL,其中粗体表示官方提供。
| Kotlin | kotlinc |
| Swift | swift |
| Rust | irust rusti |
| F# | fsi |
| Haskell | ghci |
| Scala | scala |
| 现代 C++ 1 | cling |
类型推断
与 C 语言以及传统的 C++/Java 不同,(包括现代 C++ 在内的)现代的静态类型语言可以在很多地方省却显式类型标注,编译器能够从相应的上下文来推断出变量/表达式的类型,这一机制称为类型推断(type inference)。静态类型语言的这一机制让变量声明像动态类型语言一样简洁,例如:
// Kotlin 或 Scala 代码
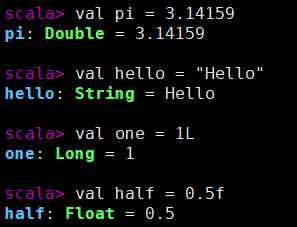
val pi = 3.14159 // 推断为 Double
val hello = "Hello" // 推断为 String
val one = 1L // 推断为 Long
val half = 0.5f // 推断为 Float
在 Scala REPL 中运行的截图如下:
上述变量都是直接以字面值为初值,因此字面值的类型即是变量类型。当然变量的初值还可以是表达式:
// Kotlin 或 Scala 代码
val a = "Hello".length + 1.5 // 推断为 Double
当类型推断结果与预期不符时可以显式标注:
// Kotlin 或 Scala 代码
val a = 97 // 推断为 Int
val b: Byte = 97
val c: Short = 97
上述简单字面值以及表达式的类型推断结果在 Kotlin、Scala、Swift、Rust、F# 以及现代 C++ 中都是具体类型。不过在 Haskell 中会与它们有所不同,我们在 GHCi 中看两个示例:
GHCi, version 8.0.2: http://www.haskell.org/ghc/ :? for help
Prelude> :set +t
Prelude> one = 1
one :: Num t => t
Prelude> half = 0.5
half :: Fractional t => t
上述 one 的类型为 Num t => t,这不是一个具体类型,而是泛型。在 Haskell 中 Num 不是具体类型,而是类型类。Haskell 类型类相当于 Rust 的 Trait 或者 Swift 的协议,也可以近似理解为 Scala 的特质或者 Java 的接口。one 的类型如果要在 Java 中表示,大约是这样的 <t: Num>。在 Haskell 中整数和小数都是 Num 的实例(继续与 Java 类比,可以理解为实现了 Num 接口),而数字字面值 1 在 Haskell 中既可以做整数也可以做小数,因此推断为泛型的数字类型实际上更准确、更智能。
half 与 one 类似,它被推断为一个泛型类型 t,t 是 Fractional 的一个实例。即它被推断为一个小数,在 Haskell 中有理数和浮点数都是小数的实例,而 0.5 即可以作为有理数也可以作为浮点数。
Haskell 不仅对字面值的推断会更智能,对复杂表达式的推断也能更智能一些。例如以下这个除以 5 的函数定义:
Prelude> divBy5 x = x / 5
divBy5 :: Fractional a => a -> a
Haskell 能够根据运算符 / 将参数 x 和 divBy5 的返回值都推断为小数,因为 / 接受的参数和返回值都是小数。
Scala 对一些表达式的类型推断也能够更智能一些,例如:
trait I
class A extends I
class B extends I
val a = true
val v = if (a) new A else new B
上面的变量 v 会被推断为类型 I,这是因为 if 表达式两个分支分别返回类型 A 和类型 B,因此 v 必须既能接受 A 类型也能接受 B 类型,于是 Scala 将其推断为二者的公共超类型 I。
泛型
与动态类型语言相比,静态类型语言通常缺少对鸭子类型的支持。静态类型语言通过泛型来解决这一问题,因此现代静态类型语言都支持泛型。 例如实现一个交换两个可变变量值的通用函数,以 Swift 为例:
func swap<T>(a: inout T, b: inout T) {
let tmp = a
a = b
b = tmp
}
其中 T 为泛型参数,代表任意类型,但 a 与 b 需要是相同类型。这样 swap 就能用于交换任何类型的两个可变变量的值了。
我们再看一个例子,实现一个函数,它接受两个同样类型的参数,返回二者中的最大值(也就是说返回值类型与两个参数类型均相同),以 Rust 为例,代码如下:
fn max2<T: Ord>(a: T, b: T) -> T {
if a < b {
b
} else {
a
}
}
对于任何实现了 Ord 的类型(这样才能比大小)T 都可用使用这个泛型函数 max2 来求两个值中的最大值。Swift、Kotlin 的泛型语法与之相近,只是在 Kotlin 中可以更简洁一些:
fun <T: Comparable<T>> max(a: T, b: T) = if (a > b) a else b
而在 F# 或者 Haskell 中只需这样写即可:
let max' a b = if (a < b) then b else a
与 Rust、Kotlin 等显著不同的是,F#/Haskell 的这段代码并没有显式标注泛型。因为 F#/Haskell 能够通过 < 自动推断出 a、b 以及返回值具有可比较的泛型约束(comparison/Ord)。F#/Haskell 强大的类型推断能力让这段代码看起来如同动态语言一样简洁。
在 F# 中还可以用成员函数/属性作为泛型约束,可以说是类型安全的鸭子类型:
type A() =
member this.info = "I'm A.";;
type B() =
member this.info = "I'm B.";;
let inline printInfo (x: ^T when ^T: (member info: string)) =
(^T: (member info: string) (x));;
A() |> printInfo;;
B() |> printInfo;;
只是其语法上有些啰嗦。
综述
静态类型具有很多优势,对于动态类型语言同样有积极意义。 现代静态类型语言在不断改进其简洁性与便利性,与动态类型语言的差距在缩小,因此更加亲民,近年来有很多现代静态类型语言兴起与流行。 另外由于静态类型的优势,很多动态类型语言也在引入静态类型支持。可见静态类型是现代语言发展的一个趋势。
-
现代 C++,即 C++ 11 及其后版本(如 C++14、C++17 等)的 C++。 ↩






相关推荐
此外,还会涉及类型检查、类型推断以及类型系统的设计原则,这些都是现代编程语言设计中的关键考虑因素。 **内存管理**是编程语言实现中的重要环节。书中会涵盖内存分配、垃圾回收机制、引用计数等概念,这些对于...
C语言于1972年由Dennis Ritchie创造,以其简洁和高效而闻名,成为了现代编程语言的基石。随后,BASIC语言在1964年由John Kemeny和Thomas Kurtz设计,旨在使非专业程序员也能进行编程。Pascal语言则在1971年由Niklaus...
此外,函数式编程语言如Haskell和Scala也在现代编程中占有一席之地。 总结,计算机编程语言的选择取决于具体需求、项目规模、团队技能和开发效率等因素。了解各种语言的特点和适用场景,有助于我们做出明智的选择并...
它还集成了一系列现代编程语言的理念,以及Apple公司工程文化的智慧,并且注重编译器性能和语言开发的优化。 Swift入门基础: 学习Swift编程语言的入门之路通常从打印"Hello, world"开始。在Swift中,这一经典的...
在本课程设计报告中,将详细介绍如何使用MATLAB这一强大的编程语言和工具,实现静态手势的识别以及视频图像中的手势识别。 静态手势识别是通过捕捉单个图像帧来识别人的手势,主要依赖于图像处理技术。报告中将展示...
此外,编译时优化也是现代编程语言的一个重要特性,Scorpion可能包括了丰富的优化选项。 8. **标准库**:Scorpion可能会有一个强大的标准库,包含常用的容器、算法和其他工具,以便于开发者的日常编码工作。 9. **...
适合人群:对现代编程语言特别是并发处理有兴趣的技术爱好者及专业开发者。 使用场景及目标:适用于想要深入了解并考虑采用Go语言作为主要开发工具的个人和技术团队,希望通过学习本篇文章达到评估是否引入Go语言进...
现代编程语言开始借鉴不同范式的优点,静态语言引入动态特性,动态语言添加类型检查,函数式编程的思想渗透到各种语言中,这种跨范式的融合使得编程语言更加多样化,适应不同的应用场景。 在.NET框架的背景下,...
5. 现代Web开发趋势:随着技术的发展,现代Web开发出现了诸如Jamstack(JavaScript、APIs、Markup)的概念,强调预渲染和边缘计算,使得静态页面可以拥有动态功能,同时保持其快速和安全的优势。 6. 静态站点生成器...
Go语言,也被称为Golang,是由Google的Robert Griesemer、Rob Pike和Ken Thompson设计并开发的一种静态强类型、编译型、并行的多平台编程语言。Go语言的开发始于2007年,其设计目标是为了解决大型项目在开发和维护...
在软件开发领域,选择合适的编程语言是至关重要的。软件语言分类是一个广泛的议题,涉及到不同的应用场景、性能需求以及开发效率等因素。以下是对这个主题的详细探讨: 1. **基础分类**: - **编译型语言**:如C、...
D语言是一种高性能、静态类型的编程语言,由Walter Bright设计,并由Digital Mars公司开发。该手册覆盖了从D语言的基础概念到高级特性的广泛内容,为读者提供了一个系统的学习框架。 ### 一、D语言2.0简介 D语言...
Go语言是一种现代化的编程语言,旨在解决传统编程语言中存在的问题,如复杂的并发模型、低效的编译时间和陈旧的设计思想。通过提供简洁的语法、高效的并发机制和强大的标准库,Go语言已经成为服务器端开发、微服务...
书中不仅涵盖了传统编程语言的基础知识,还介绍了现代编程语言的发展趋势和技术革新。 #### 二、作者简介 罗伯特·W·塞贝斯塔教授任职于科罗拉多大学科罗拉多斯普林斯分校,拥有丰富的教学经验和深厚的研究背景。...
C#作为一种现代化的编程语言,支持各种现代软件开发的趋势和技术,比如异步编程模型(async/await)、LINQ(语言集成查询)、泛型编程、多核并行处理等。C#的不断更新和发展也反映了现代软件开发的需求,C#版本的...
Swift语言的设计也充分考虑了现代编程语言的发展趋势,它支持闭包、元编程、泛型等高级编程特性,这些特性让开发者可以在更抽象的层面上进行编程,从而更加专注于解决实际问题,而不是陷入繁琐的代码实现细节。...
C#是一种现代、简单、modern、object-orientedProgramming语言,具有强大的功能和灵活性。以下是对C#语言的详细介绍: C#设计目标: * 忠实于C++ * 简单、可扩展的类型系统 * 组件支持 * 多版本支持 C#类型系统:...
在当今的软件开发领域中,TypeScript作为一种扩展了JavaScript的编程语言,已经成为前端开发中的主流技术之一。TypeScript提供了JavaScript的所有功能,并在此基础上增加了类型系统和对ES6+的新特性的支持。而多语言...