- 浏览: 59575 次
- 性别:

- 来自: 广州
-

最新评论
-
Joson_Coney:
11.
while( (*strDest++ = *strSr ...
c++笔试题汇总 -
Joson_Coney:
③ 1.
int func(x)
{
int countx = ...
c++笔试题汇总 -
Joson_Coney:
链表反向1:
#include <cstdlib&g ...
c++笔试题汇总
(From:http://www.theserverside.com/news/1321219/Why-Should-You-Care-About-MapReduce)
Why Should You Care About MapReduce?
By Eugene Ciurana
01 Feb 2008 | TheServerSide.com
What is MapReduce?
MapReduce is a distributed programming model intended for processing massive amounts of data in large clusters, developed by Jeffrey Dean and Sanjay Ghemawat at Google. MapReduce is implemented as two functions, Map which applies a function to all the members of a collection and returns a list of results based on that processing, and Reduce, which collates and resolves the results from two or more Maps executed in parallel by multiple threads, processors, or stand-alone systems. Both Map() and Reduce() may run in parallel, though not necessarily in the same system at the same time.
Google uses MapReduce for indexing every Web page they crawl. It replaced the original indexing algorithms and heuristics in 2004, given its proven efficiency in processing very large, unstructured datasets. Several implementations of MapReduce are available in a variety of programming languages, including Java, C++, Python, Perl, Ruby, and C, among others. In some cases, like in Lisp or Python, Map() and Reduce() have been integrated into the fabric of the language itself. In general, these functions could be defined as:
List2 map(Functor1, List1); Object reduce(Functor2, List2);
The map() function operates on large datasets split into two or more smaller buckets. A bucket then contains a collection of loosely delimited logical records or lines of text. Each thread, processor, or system executes the map() function on a separate bucket to calculate a set of intermediate values based on the processing of each logical records. The combined results from all of these should be identical as having been executed as a single bucket by a single map() function. The general form of the map() function is:
map(function, list) {
foreach element in list {
v = function(element)
intermediateResult.add(v)
}
} // map
The reduce() function operates on one or more lists of intermediate results by fetching the each from memory, disk, or a network transfer and performing a function on each element of each list. The final result of the complete operation is performed by collating and interpreting the results from all processes running the reduce() operations. The general form of the reduce() function is:
reduce(function, list, init) {
result = init
foreach value in list {
result = function(result, value)
}
outputResult.add(result)
}
The implementation of MapReduce separates the business logic from the multi-processing logic. The map() and reduce() functions across multiple systems, synchronized over shared pools and communicating with one another over some form of RPC. The business logic is implemented in user-definable functors that only work on logical record processing and aren’t concerned with multiprocessing issues. This enables quick turnaround of parallelized processing applications across massive numbers of processors once the MapReduce framework is in place because developers focus their effort on writing the functors. MapReduce clusters are reused by replacing the functors and providing new data sources without having to build, test, and deploy a complete application every time.
Implementation of MapReduce
MapReduce is intended for large clusters of systems that can work in parallel on a large dataset. Figure 1 shows a main program, running on a master system, coordinating other instances of itself that either execute map() or reduce(), and collates the results from each reduce operation.
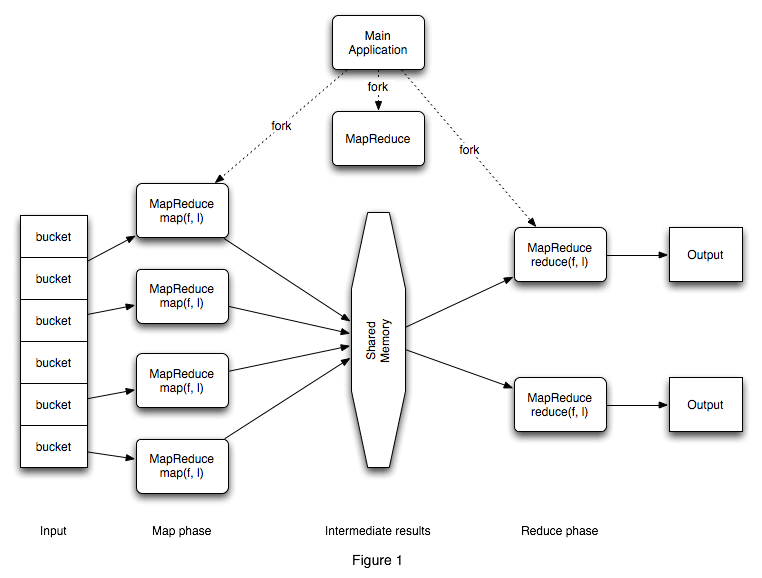
The main application is responsible for splitting the basic dataset into buckets. The optimal bucket size depends on the application, the number of nodes, and the I/O bandwidth available. These buckets are normally saved to disk, but could be split in main memory if appropriate, depending on the application. The buckets will become the input into the map() functions.
The main application is also responsible for launching or forking several copies of the MapReduce core, all of which are identical except for a controller that assigns and coordinates map() or reduce() tasks to idle processes or threads. The controller keeps track of each map() and reduce() tasks state (waiting, running, complete) and may act as a conduit for routing the intermediate results between map() and reduce() tasks.
Each map() task processes an assigned bucket through and produces a list of intermediate results that are stored into a shared memory area. The shared memory can be designed in the form of a distributed cache, disk, or other. The task notifies the controller when a new intermediate result has been written and provides a handle to its shared memory location.
The controller assigns reduce() tasks as new intermediate results are available. The task sorts the results by application-dependent intermediate keys implemented through comparators so that identical data are grouped together for faster retrieval. Very large results may be externally sorted. The task iterates over the sorted data and passes each unique key and collated results to the users’s reduce() functor for processing.
Processing by map() and reduce() instances ends when all buckets are exhausted and all reduce() tasks notify the controller that their output has been generated. The controller signals the main application to retrieve its results. The main application may then operate on these results directly, or re-assign them to a different MapReduce controller and tasks for further processing.
Real world implementations of MapReduce would normally assign controllers, map(), and reduce() tasks to a single system. The Google operational model is based on deploying MapReduce applications across large clusters of commodity systems, or white boxes. Each white box has its own local storage required for processing of its bucket, a reasonable amount of primary memory (2 to 4 GB RAM), and at least two processing cores. White boxes are interchangeable, and the main application may assign any machine in the cluster as the controller, and this one in turn assigns map() or reduce() tasks to other connected white boxes.
Java-based MapReduce Implementation
The Google environment is customized for their needs and to fit their operational model. For example, Google uses a proprietary file system for storing files that’s optimized for the type of operations that their MapReduce implementations are likely to perform. Enterprise applications, on the other hand, are built on top of Java or similar technologies, and rely on existing file systems, communication protocols, and application stacks.
A Java-based implementation of MapReduce should take into account existing data storage facilities, which protocols are supported by the organization where it will be deployed, the internal APIs at hand, and the availability of third-party products (open-source or commercial) that will support deployment. Figure 2 shows how the general architecture could be mapped to robust, existing Java open-source infrastructure for this implementation.
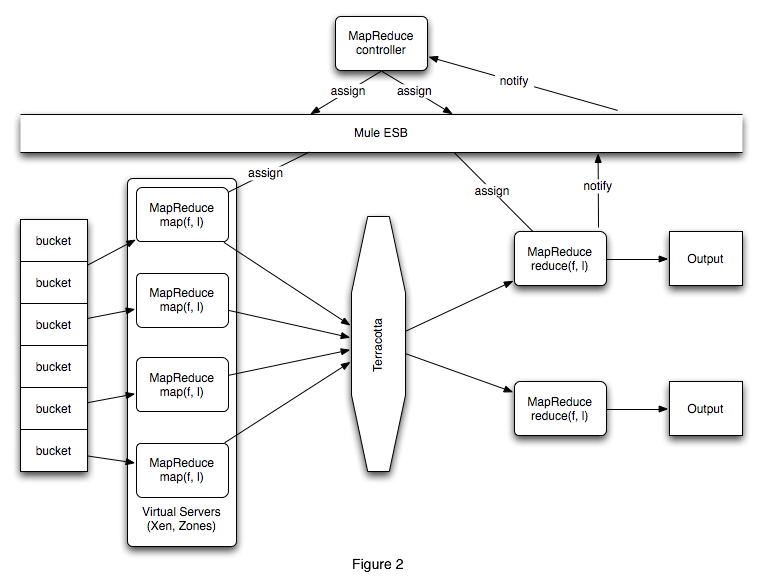
This architecture assumes the presence of tools such as Terracotta or Mule that are common in many enterprise setups, and the availability of white boxes in the form of physical or virtual systems that can be designated as part of the MapReduce cluster through simple configuration and deployment. A large system may be partitioned into several virtual machines for efficiency, and assign more or fewer nodes as needed. Capacity issues and processor availability can help determine whether to use physical white boxes, virtual machines, or a combination of both in the cluster.
The Terracotta clustering technology is a great choice for sharing data between the map() and reduce() tasks because it abstracts all the communications overhead involved in sharing files or using RPC calls to initiate processing of the results. The map() and reduce() tasks are implemented in the same application core, as described in the previous section. The data structures for sharing intermediate result sets could be kept in memory data structures that are in turn shared transparently by Terracotta. Interprocess communication issues disappear to the MapReduce implementers since the Terracotta runtime is in charge of sharing those data structures across the cluster with MapReduce that uses its runtime. Instead of implementing a complex signaling system, all the map() tasks need to do is flag intermediate result sets in memory and the reduce() tasks will fetch them directly.
Both the controller and the main application are likely to be in a wait state for a while even with the massive parallelization available through the MapReduce cluster. Signaling between these two components, and between the reduce() tasks and the controller when reduction is complete, is done over the Mule ESB. In this manner, results output could be queued up for processing by other applications, or a Mule service object (or UMO) can take these output results and split them into buckets for another MapReduce pass, as described in the previous section. Mule supports synchronous and asynchronous data transfers in memory, across all major enterprise protocols, or over raw TCP/IP sockets. Mule can be used to move results output between applications executing in the same machine, across the data center, or in a different location entirely with little programmer participation beyond identifying a local endpoint and letting Mule move and transform the data toward its destination.
Another Java-based implementation could be through Hadoop, a Lucene-derived framework for deploying distributed applications running on large clusters of commodity computers. Hadoop is an open-source, end-to-end, general-purpose implementation of MapReduce.
Conclusion
Indexing large amounts of unstructured data is a difficult task regardless of the technologies involved. Traditional methods of applying dedicated algorithms and heuristics result in hard to maintain, unwieldy systems with performance degradation over time. RDBMSs are optimized for indexing and searching of large structured data sets but they are inadequate for unstructured data. MapReduce provides a simple, elegant solution for data processing in parallelized systems with these advantages:
- Reduced Cost
- High programmer productivity since the business logic is implemented independently of the parallelization code
- Overall better performance and results than using traditional RDBMS techniques or custom algorithms/heuristics
- Ease of deployment using known techniques and existing tools that are familiar to enterprise Java architects and developers
Google has an impressive track record with MapReduce, and more tools appear every day that can ease its adoption for mainstream, enterprise-class applications. If you’re ready to give it a shot, start with a simple task like analyzing the traffic patterns into your Web cluster based on the IP address of the requesters, or something similar. An exercise like this will be a great way of familiarizing yourself with the issues and opportunities of MapReduce in preparation to use it for your mission-critical applications.
About the Author
Eugene Ciurana is the Director of Systems Infrastructure at LeapFrog Enterprises, an open-source software evangelist, and a contributing editor to TheServerSide.com. He can be found in several places across the IRC universe (##java, #awk, #esb, #iphone) under the /nick pr3d4t0r.


发表评论

-
【转】Lucene:基于Java的全文检索引擎简介
2012-04-19 16:15 708(转自:http://www.chedon ... -
Lucene:基于Java的全文检索引擎简介
2012-04-19 16:12 0<p>(转自:http://www.chedong ... -
spring源码阅读
2012-04-18 12:15 0框架包:struts2.3.1+spring 3.1.1+hi ... -
【转】SQL 2008 R2 problems on a Windows 2008 R2 Enterprise server
2012-03-30 15:15 1144(From: http://social.msdn.micro ... -
oracle管理
2012-03-06 10:21 0(转自:http://www.examw.co ... -
敏捷开发Scrum
2012-02-10 09:45 619http://baike.baidu.com/view/152 ... -
Hadoop0.20.203初试手记
2012-01-26 08:01 849OS: Debian 6.03 Hadoop: 0.20.2 ... -
mongodb BinData
2011-10-15 06:06 2445[mongodb-dev] BinData ... -
MongoDB : Using a Large Number of Collections
2011-10-11 12:19 830( From: http://api.mongodb.or ...
相关推荐
Hadoop介绍,HDFS和MapReduce工作原理
MapReduce是一种分布式计算模型,由Google开发,用于处理和生成大量数据。这个模型主要由两个主要阶段组成:Map(映射)和Reduce(规约)。MapReduce的核心思想是将复杂的大规模数据处理任务分解成一系列可并行执行...
实验项目“MapReduce 编程”旨在让学生深入理解并熟练运用MapReduce编程模型,这是大数据处理领域中的核心技术之一。实验内容涵盖了从启动全分布模式的Hadoop集群到编写、运行和分析MapReduce应用程序的全过程。 ...
基于MapReduce实现决策树算法的知识点 基于MapReduce实现决策树算法是一种使用MapReduce框架来实现决策树算法的方法。在这个方法中,主要使用Mapper和Reducer来实现决策树算法的计算。下面是基于MapReduce实现决策...
### MapReduce基础知识详解 #### 一、MapReduce概述 **MapReduce** 是一种编程模型,最初由Google提出并在Hadoop中实现,用于处理大规模数据集的分布式计算问题。该模型的核心思想是将复杂的大型计算任务分解成较...
【标题】Hadoop MapReduce 实现 WordCount MapReduce 是 Apache Hadoop 的核心组件之一,它为大数据处理提供了一个分布式计算框架。WordCount 是 MapReduce 框架中经典的入门示例,它统计文本文件中每个单词出现的...
This book also provides a complete overview of MapReduce that explains its origins and implementations, and why design patterns are so important. All code examples are written for Hadoop....
Hadoop MapReduce 编程实战 Hadoop MapReduce 是大数据处理的核心组件之一,它提供了一个编程模型和软件框架,用于大规模数据处理。下面是 Hadoop MapReduce 编程实战的知识点总结: MapReduce 编程基础 ...
### MapReduce:大规模数据处理的简化利器 #### 引言:MapReduce的诞生与使命 在MapReduce问世之前,Google的工程师们,包括其发明者Jeffrey Dean和Sanjay Ghemawat,面临着一个共同的挑战:如何高效地处理海量...
MapReduce是一种分布式计算模型,由Google在2004年提出,主要用于处理和生成大规模数据集。这个模型将复杂的计算任务分解成两个主要阶段:Map(映射)和Reduce(化简),使得在大规模分布式环境下处理大数据变得可能...
MapReduce是一种编程模型,用于大规模数据集的并行运算。它最初由Google提出,其后发展为Apache Hadoop项目中的一个核心组件。在这一框架下,开发者可以创建Map函数和Reduce函数来处理数据。MapReduce设计模式是对...
MapReduce是一种分布式计算模型,由Google在2004年提出,主要用于处理和生成大规模数据集。它将复杂的并行计算任务分解成两个主要阶段:Map(映射)和Reduce(化简)。在这个"MapReduce项目 数据清洗"中,我们将探讨...
MapReduce是一种由谷歌实验室提出的大规模数据处理模型及其相关实现方案。这篇论文详细介绍了MapReduce的概念、工作机制以及在实际中的应用。MapReduce模型通过两个主要函数——Map函数和Reduce函数来处理数据,使得...
基于MapReduce的Apriori算法代码 基于MapReduce的Apriori算法代码是一个使用Hadoop MapReduce框架实现的关联规则挖掘算法,称为Apriori算法。Apriori算法是一种经典的关联规则挖掘算法,用于发现事务数据库中频繁...
### MapReduce的实现细节 #### 一、MapReduce框架概述 MapReduce是一种广泛应用于大数据处理领域的分布式编程模型,最初由Google提出并在其内部系统中得到广泛应用。随着开源社区的发展,尤其是Apache Hadoop项目...
图解MapReduce,系统介绍Hadoop MapReduce工作过程原理
简单的在MapReduce中实现两个表的join连接简单的在MapReduce中实现两个表的join连接简单的在MapReduce中实现两个表的join连接
If Spark is a better version of MapReduce, why are we even talking about it? Good question! Corporations, being slow-moving entities, are often still using Hadoop due to historical reasons. Just ...