
иљђиЗ™¬†http://jolestar.com/parallel-programming-model-thread-goroutine-actor/
 
жЬђжЦЗеЯЇдЇОжИСеЬ®2жЬИ27жЧ•GopherеМЧдЇђиБЪдЉЪжЉФиЃ≤жХізРЖиАМжИРпЉМињЫи°МдЇЖдЄАдЇЫи°•еЕЕдї•еПКи∞ГжХігАВжКХз®њзїЩгАКйЂШеПѓзФ®жЮґжЮДгАЛеЕђдЉЧеПЈй¶ЦеПСгАВ
иБКињЩдЄ™иѓЭйҐШдєЛеЙНпЉМеЕИжҐ≥зРЖдЄЛдЄ§дЄ™ж¶ВењµпЉМеЗ†дєОжЙАжЬЙиЃ≤еєґеПСзЪДжЦЗзЂ†йГљи¶БеЕИиЃ≤ињЩдЄ§дЄ™ж¶ВењµпЉЪ
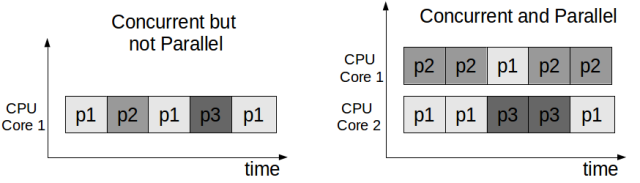
- еєґеПСпЉИconcurrencyпЉЙ¬†еєґеПСзЪДеЕ≥ж≥®зВєеЬ®дЇОдїїеК°еИЗеИЖгАВдЄЊдЊЛжЭ•иѓіпЉМдљ†жШѓдЄАдЄ™еИЫдЄЪеЕђеПЄзЪДCEOпЉМеЉАеІЛеП™жЬЙдљ†дЄАдЄ™дЇЇпЉМдљ†дЄАдЇЇеИЖй•∞е§ЪиІТпЉМдЄАдЉЪеБЪдЇІеУБиІДеИТпЉМдЄАдЉЪеЖЩдї£з†БпЉМдЄАдЉЪиІБеЃҐжИЈпЉМиЩљзДґдљ†дЄНиГљиІБеЃҐжИЈзЪДеРМжЧґеЖЩдї£з†БпЉМдљЖзФ±дЇОдљ†еИЗеИЖдЇЖдїїеК°пЉМеИЖйЕНдЇЖжЧґйЧізЙЗпЉМи°®зО∞еЗЇжЭ•е•љеГПжШѓе§ЪдЄ™дїїеК°дЄАиµЈеЬ®жЙІи°МгАВ
- еєґи°МпЉИparallelismпЉЙ¬†еєґи°МзЪДеЕ≥ж≥®зВєеЬ®дЇОеРМжЧґжЙІи°МгАВињШжШѓдЄКйЭҐзЪДдЊЛе≠РпЉМдљ†еПСзО∞дљ†иǙ壱姙ењЩдЇЖпЉМжЧґйЧіеИЖйЕНдЄНињЗжЭ•пЉМдЇОжШѓиѓЈдЇЖеЈ•з®ЛеЄИпЉМдЇІеУБзїПзРЖпЉМеЄВеЬЇжАїзЫСпЉМеРДеПЄдЄАиБМпЉМињЩжЧґеАЩе§ЪдЄ™дїїеК°еПѓдї•еРМжЧґжЙІи°МдЇЖгАВ
жЙАдї•жАїзїУдЄЛпЉМеєґеПСеєґдЄНи¶Бж±ВењЕй°їеєґи°МпЉМеПѓдї•зФ®жЧґйЧізЙЗеИЗеИЖзЪДжЦєеЉПж®°жЛЯпЉМжѓФе¶ВеНХж†ЄcpuдЄКзЪДе§ЪдїїеК°з≥їзїЯпЉМеєґеПСзЪДи¶Бж±ВжШѓдїїеК°иГљеИЗеИЖжИРзЛђзЂЛжЙІи°МзЪДзЙЗжЃµгАВиАМеєґи°МеЕ≥ж≥®зЪДжШѓеРМжЧґжЙІи°МпЉМењЕй°їжШѓе§ЪпЉИж†ЄпЉЙcpuпЉМи¶БиГљеєґи°МзЪДз®ЛеЇПењЕй°їжШѓжФѓжМБеєґеПСзЪДгАВжЬђжЦЗе§Іе§ЪжХ∞жГЕеЖµдЄЛдЄНдЉЪдЄ•ж†ЉеМЇеИЖињЩдЄ§дЄ™ж¶ВењµпЉМйїШиЃ§еєґеПСе∞±жШѓжМЗеєґи°МжЬЇеИґдЄЛзЪДеєґеПСгАВ
дЄЇдїАдєИеєґеПСз®ЛеЇПињЩдєИйЪЊ?
We believe that writing correct¬†concurrent,¬†fault-tolerant¬†and¬†scalable¬†applications is too hard. Most of the time itвАЩs because we are using the wrong tools and the wrong level of abstraction. вАФвАФ Akka
AkkaеЃШжЦєжЦЗж°£еЉАзѓЗињЩеП•иѓЭиѓізЪДе•љпЉМдєЛжЙАдї•еЖЩж≠£з°ЃзЪДеєґеПСпЉМеЃєйФЩпЉМеПѓжЙ©е±ХзЪДз®ЛеЇПе¶Вж≠§дєЛйЪЊпЉМжШѓеЫ†дЄЇжИСдїђзФ®дЇЖйФЩиѓѓзЪДеЈ•еЕЈеТМйФЩиѓѓзЪДжКљи±°гАВпЉИељУзДґиѓ•жЦЗж°£жЬђжЭ•зЪДжДПжАЭжШѓAkkaжШѓж≠£з°ЃзЪДеЈ•еЕЈпЉМдљЖжИСдїђеПѓдї•зЛђзЂЛзЪДзЬЛеЊЕињЩеП•иѓЭпЉЙгАВ
йВ£жИСдїђдїОжЬАеЉАеІЛжҐ≥зРЖдЄЛз®ЛеЇПзЪДжКљи±°гАВеЉАеІЛжИСдїђзЪДз®ЛеЇПжШѓйЭҐеРСињЗз®ЛзЪДпЉМжХ∞жНЃзїУжЮД+funcгАВеРОжЭ•жЬЙдЇЖйЭҐеРСеѓєи±°пЉМеѓєи±°зїДеРИдЇЖжХ∞зїУжЮДеТМfuncпЉМжИСдїђжГ≥зФ®ж®°жЛЯзО∞еЃЮдЄЦзХМзЪДжЦєеЉПпЉМжКљи±°еЗЇеѓєи±°пЉМжЬЙзКґжАБеТМи°МдЄЇгАВдљЖжЧ†иЃЇжШѓйЭҐеРСињЗз®ЛзЪДfuncињШжШѓйЭҐеРСеѓєи±°зЪДfuncпЉМжЬђиі®дЄКйГљжШѓдї£з†БеЭЧзЪДзїДзїЗеНХеЕГпЉМжЬђиЇЂеєґж≤°жЬЙеМЕеРЂдї£з†БеЭЧзЪДеєґеПСз≠ЦзХ•зЪДеЃЪдєЙгАВдЇОжШѓдЄЇдЇЖиІ£еЖ≥еєґеПСзЪДйЬАж±ВпЉМеЉХеЕ•дЇЖThreadпЉИзЇњз®ЛпЉЙзЪДж¶ВењµгАВ
зЇњз®ЛпЉИThreadпЉЙ
- з≥їзїЯеЖЕж†ЄжАБпЉМжЫіиљїйЗПзЪДињЫз®Л
- зФ±з≥їзїЯеЖЕж†ЄињЫи°Ми∞ГеЇ¶
- еРМдЄАињЫз®ЛзЪДе§ЪдЄ™зЇњз®ЛеПѓеЕ±дЇЂиµДжЇР
зЇњз®ЛзЪДеЗЇзО∞иІ£еЖ≥дЇЖдЄ§дЄ™йЧЃйҐШпЉМдЄАдЄ™жШѓGUIеЗЇзО∞еРОжА•еИЗйЬАи¶БеєґеПСжЬЇеИґжЭ•дњЭиѓБзФ®жИЈзХМйЭҐзЪДеУНеЇФгАВзђђдЇМжШѓдЇТиБФзљСеПСе±ХеРОеЄ¶жЭ•зЪДе§ЪзФ®жИЈйЧЃйҐШгАВжЬАжЧ©зЪДCGIз®ЛеЇПеЊИзЃАеНХпЉМе∞ЖйАЪињЗиДЪжЬђе∞ЖеОЯжЭ•еНХжЬЇзЙИзЪДз®ЛеЇПеМЕи£ЕеЬ®дЄАдЄ™ињЫз®ЛйЗМпЉМжЭ•дЄАдЄ™зФ®жИЈе∞±еРѓеК®дЄАдЄ™ињЫз®ЛгАВдљЖжШОжШЊињЩж†ЈжЙњиљљдЄНдЇЖе§Ъе∞СзФ®жИЈпЉМеєґдЄФе¶ВжЮЬињЫз®ЛйЧійЬАи¶БеЕ±дЇЂиµДжЇРињШеЊЧйАЪињЗињЫз®ЛйЧізЪДйАЪдњ°жЬЇеИґпЉМзЇњз®ЛзЪДеЗЇзО∞зЉУиІ£дЇЖињЩдЄ™йЧЃйҐШгАВ
зЇњз®ЛзЪДдљњзФ®жѓФиЊГзЃАеНХпЉМе¶ВжЮЬдљ†иІЙеЊЧињЩеЭЧдї£з†БйЬАи¶БеєґеПСпЉМе∞±жККеЃГжФЊеЬ®еНХзЛђзЪДзЇњз®ЛйЗМжЙІи°МпЉМзФ±з≥їзїЯиіЯиі£и∞ГеЇ¶пЉМеЕЈдљУдїАдєИжЧґеАЩдљњзФ®зЇњз®ЛпЉМи¶БзФ®е§Ъе∞СдЄ™зЇњз®ЛпЉМзФ±и∞ГзФ®жЦєеЖ≥еЃЪпЉМдљЖеЃЪдєЙжЦєеєґдЄНжЄЕж•Ъи∞ГзФ®жЦєдЉЪе¶ВдљХдљњзФ®иЗ™еЈ±зЪДдї£з†БпЉМеЊИе§ЪеєґеПСйЧЃйҐШйГљжШѓеЫ†дЄЇиѓѓзФ®еѓЉиЗізЪДпЉМжѓФе¶ВGoдЄ≠зЪДmapдї•еПКJavaзЪДHashMapйГљдЄНжШѓеєґеПСеЃЙеЕ®зЪДпЉМиѓѓзФ®еЬ®е§ЪзЇњз®ЛзОѓеҐГе∞±дЉЪеѓЉиЗійЧЃйҐШгАВеП¶е§ЦдєЯеЄ¶жЭ•е§НжЭВеЇ¶пЉЪ
- зЂЮжАБжЭ°дїґпЉИrace conditionsпЉЙ¬†е¶ВжЮЬжѓПдЄ™дїїеК°йГљжШѓзЛђзЂЛзЪДпЉМдЄНйЬАи¶БеЕ±дЇЂдїїдљХиµДжЇРпЉМйВ£зЇњз®ЛдєЯе∞±йЭЮеЄЄзЃАеНХгАВдљЖдЄЦзХМеЊАеЊАжШѓе§НжЭВзЪДпЉМжАїжЬЙдЄАдЇЫиµДжЇРйЬАи¶БеЕ±дЇЂпЉМжѓФе¶ВеЙНйЭҐзЪДдЊЛе≠РпЉМеЉАеПСдЇЇеСШеТМеЄВеЬЇдЇЇеСШеРМжЧґйЬАи¶БеТМCEOеХЖйЗПдЄАдЄ™жЦєж°ИпЉМињЩжЧґеАЩCEOе∞±жИРдЇЖзЂЮжАБжЭ°дїґгАВ
- дЊЭиµЦеЕ≥з≥їдї•еПКжЙІи°Мй°ЇеЇП¬†е¶ВжЮЬзЇњз®ЛдєЛйЧізЪДдїїеК°жЬЙдЊЭиµЦеЕ≥з≥їпЉМйЬАи¶Бз≠ЙеЊЕдї•еПКйАЪзЯ•жЬЇеИґжЭ•ињЫи°МеНПи∞ГгАВжѓФе¶ВеЙНйЭҐзЪДдЊЛе≠РпЉМе¶ВжЮЬдЇІеУБеТМCEOиЃ®иЃЇзЪДжЦєж°ИдЊЭиµЦдЇОеЄВеЬЇеТМCEOиЃ®иЃЇзЪДжЦєж°ИпЉМињЩжЧґеАЩе∞±йЬАи¶БеНПи∞ГжЬЇеИґдњЭиѓБй°ЇеЇПгАВ
дЄЇдЇЖиІ£еЖ≥дЄКињ∞йЧЃйҐШпЉМжИСдїђеЉХеЕ•дЇЖиЃЄе§Ъе§НжЭВжЬЇеИґжЭ•дњЭиѓБпЉЪ
- Mutex(Lock) пЉИGoйЗМзЪДsyncеМЕ, JavaзЪДconcurrentеМЕпЉЙйАЪињЗдЇТжЦ•йЗПжЭ•дњЭжК§жХ∞жНЃпЉМдљЖжЬЙдЇЖйФБпЉМжШОжШЊе∞±йЩНдљОдЇЖеєґеПСеЇ¶гАВ
- semaphore йАЪињЗдњ°еПЈйЗПжЭ•жОІеИґеєґеПСеЇ¶жИЦиАЕдљЬдЄЇзЇњз®ЛйЧідњ°еПЈпЉИsignalпЉЙйАЪзЯ•гАВ
- volatile JavaдЄУйЧ®еЉХеЕ•дЇЖvolatileеЕ≥йФЃиѓНжЭ•пЉМжЭ•йЩНдљОеП™иѓїжГЕеЖµдЄЛзЪДйФБзЪДдљњзФ®гАВ
- compare-and-swap йАЪињЗз°ђдїґжПРдЊЫзЪДCASжЬЇеИґдњЭиѓБеОЯе≠РжАІпЉИatomicпЉЙпЉМдєЯжШѓйЩНдљОйФБзЪДжИРжЬђзЪДжЬЇеИґгАВ
е¶ВжЮЬиѓідЄКйЭҐдЄ§дЄ™йЧЃйҐШеП™жШѓеҐЮеК†дЇЖе§НжЭВеЇ¶пЉМжИСдїђйАЪињЗжЈ±еЕ•е≠¶дє†пЉМдЄ•и∞®зЪДCodeReviewпЉМеЕ®йЭҐзЪДеєґеПСжµЛиѓХпЉИжѓФе¶ВGoиѓ≠и®АдЄ≠еНХеЕГжµЛиѓХзЪДжЧґеАЩеК†дЄК-raceеПВжХ∞пЉЙпЉМдЄАеЃЪз®ЛеЇ¶дЄКиГљиІ£еЖ≥пЉИељУзДґињЩдЄ™дєЯжШѓжЬЙдЇЙиЃЃзЪДпЉМжЬЙиЃЇжЦЗиЃ§дЄЇељУеЙНзЪДе§Іе§ЪжХ∞еєґеПСз®ЛеЇПж≤°еЗЇйЧЃйҐШеП™жШѓеєґеПСеЇ¶дЄНе§ЯпЉМе¶ВжЮЬCPUж†ЄжХ∞зїІзї≠еҐЮеК†пЉМз®ЛеЇПињРи°МзЪДжЧґйЧіжЫійХњпЉМеЊИйЪЊдњЭиѓБдЄНеЗЇйЧЃйҐШпЉЙгАВдљЖжЬАиЃ©дЇЇе§ізЧЫзЪДињШжШѓдЄЛйЭҐињЩдЄ™йЧЃйҐШпЉЪ
з≥їзїЯйЗМеИ∞еЇХйЬАи¶Бе§Ъе∞СзЇњз®ЛпЉЯ
ињЩдЄ™йЧЃйҐШжИСдїђеЕИдїОз°ђдїґиµДжЇРеЕ•жЙЛпЉМиАГиЩСдЄЛзЇњз®ЛзЪДжИРжЬђпЉЪ
- еЖЕе≠ШпЉИзЇњз®ЛзЪДж†Из©ЇйЧіпЉЙ
жѓПдЄ™зЇњз®ЛйГљйЬАи¶БдЄАдЄ™ж†ИпЉИStackпЉЙз©ЇйЧіжЭ•дњЭе≠ШжМВиµЈпЉИsuspendingпЉЙжЧґзЪДзКґжАБгАВJavaзЪДж†Из©ЇйЧіпЉИ64дљНVMпЉЙйїШиЃ§жШѓ1024kпЉМдЄНзЃЧеИЂзЪДеЖЕе≠ШпЉМеП™жШѓж†Из©ЇйЧіпЉМеРѓеК®1024дЄ™зЇњз®Ле∞±и¶Б1GеЖЕе≠ШгАВиЩљзДґеПѓдї•зФ®-XssеПВжХ∞жОІеИґпЉМдљЖзФ±дЇОзЇњз®ЛжШѓжЬђиі®дЄКдєЯжШѓињЫз®ЛпЉМз≥їзїЯеБЗеЃЪжШѓи¶БйХњжЬЯињРи°МзЪДпЉМж†Из©Їй׳姙е∞ПдЉЪеѓЉиЗіз®Не§НжЭВзЪДйАТељТи∞ГзФ®пЉИжѓФе¶Ве§НжЭВзВєзЪДж≠£еИЩи°®иЊЊеЉПеМєйЕНпЉЙеѓЉиЗіж†ИжЇҐеЗЇгАВжЙАдї•и∞ГжХіеПВжХ∞ж≤їж†ЗдЄНж≤їжЬђгАВ -
и∞ГеЇ¶жИРжЬђпЉИcontext-switchпЉЙ
жИСеЬ®дЄ™дЇЇзФµиДСдЄКеБЪзЪДдЄАдЄ™йЭЮдЄ•ж†ЉжµЛиѓХпЉМж®°жЛЯдЄ§дЄ™зЇњз®ЛдЇТзЫЄеФ§йЖТиљЃжµБжМВиµЈпЉМзЇњз®ЛеИЗжНҐжИРжЬђе§ІзЇ¶6000зЇ≥зІТ/жђ°гАВињЩдЄ™ињШж≤°иАГиЩСж†Из©ЇйЧіе§Іе∞ПзЪДељ±еУНгАВеЫље§ЦдЄАзѓЗиЃЇжЦЗдЄУйЧ®еИЖжЮРзЇњз®ЛеИЗжНҐзЪДжИРжЬђпЉМеЯЇжЬђдЄКеЊЧеЗЇзЪДзїУиЃЇжШѓеИЗжНҐжИРжЬђеТМж†Из©ЇйЧідљњзФ®е§Іе∞ПзЫіжО•зЫЄеЕ≥гАВ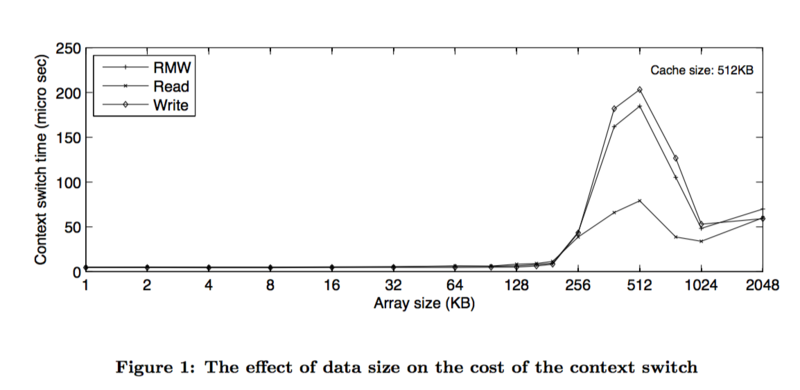
-
CPUдљњзФ®зОЗ
жИСдїђжРЮеєґеПСжЬАдЄїи¶БзЪДдЄАдЄ™зЫЃж†Зе∞±жШѓжИСдїђжЬЙдЇЖе§Ъж†ЄпЉМжГ≥жПРйЂШCPUеИ©зФ®зОЗпЉМжЬАе§ІйЩРеЇ¶зЪДеОЛ涮簐俴иµДжЇРпЉМдїОињЩдЄ™иІТеЇ¶иАГиЩСпЉМжИСдїђеЇФиѓ•зФ®е§Ъе∞СзЇњз®ЛеСҐпЉЯ
ињЩдЄ™жИСдїђеПѓдї•йАЪињЗдЄАдЄ™еЕђеЉПиЃ°зЃЧеЗЇжЭ•пЉМ100/(15+5)*4=20пЉМзФ®20дЄ™зЇњз®ЛжЬАеРИйАВгАВдљЖдЄАжЦєйЭҐзљСзїЬзЪДжЧґйЧідЄНжШѓеЫЇеЃЪзЪДпЉМеП¶е§ЦдЄАжЦєйЭҐпЉМе¶ВжЮЬиАГиЩСеИ∞еЕґдїЦзУґйҐИиµДжЇРеСҐпЉЯжѓФе¶ВйФБпЉМжѓФе¶ВжХ∞жНЃеЇУињЮжΕ汆пЉМе∞±дЉЪжЫіе§НжЭВгАВ
дљЬдЄЇдЄАдЄ™1е≤Бе§Ъе≠©е≠РзЪДзИґдЇ≤пЉМиЃ§дЄЇињЩдЄ™йЧЃйҐШзЪДйЪЊеЇ¶е•љжѓФдљ†и¶БеЖЩдЄ™зїЩе≠©е≠РеЦВй•≠зЪДз®ЛеЇПпЉМйЬАи¶БиАГиЩСгАОзїЩе≠©е≠РеЦВе§Ъе∞Сй•≠еРИйАВпЉЯгАПпЉМињЩдЄ™йЧЃйҐШжЬЙдї•дЄЛеЫЮз≠Фдї•еПКз≠ЦзХ•пЉЪ
- е≠©е≠РдЄНеРГдЇЖе∞±е•љдЇЖпЉИдљЖе≠©е≠Риі™зО©пЉМдЄНеРГдЇЖеПѓиГљжШѓжГ≥еОїзО©дЇЖпЉЙ
- е≠©е≠РеРГй•±дЇЖе∞±е•љдЇЖпЉИеЇЯиѓЭпЉМдљ†жАОдєИзЯ•йБУе≠©е≠РеРГй•±дЇЖпЉЯе≠©е≠РеПИдЄНдЉЪиѓіиѓЭпЉЙ
- йАРжЄРеҐЮйЗПпЉМйХњжЬЯиІВеѓЯпЉМзДґеРОиЃ°зЃЧдЄАдЄ™еє≥еЭЗеАЉпЉИињЩеПѓиГљжШѓжИСдїђи∞ГжХізЇњз®ЛеЄЄзФ®зЪДз≠ЦзХ•пЉМдљЖеҐЮйЗПеҐЮеК†еИ∞е§Ъе∞СеРИйАВеСҐпЉЯпЉЙ
- е≠©е≠РеРГеРРдЇЖе∞±еИЂеЦВдЇЖпЉИе¶ВжЮЬзФ®йАРжЄРеҐЮйЗПзЪДж®°еЉПпЉМйАЪињЗе§ЦйГ®иІВеѓЯпЉМеПѓиГљдЉЪеИ∞иЊЊињЩдЄ™иЊєзХМжЭ°дїґгАВз≥їзїЯжАІиГље¶ВжЮЬеЫ†дЄЇзЇњз®ЛзЪДеҐЮеК†еАТйААдЇЖпЉМе∞±еИЂеҐЮеК†зЇњз®ЛдЇЖпЉЙ
- ж≤°жОІеИґе•љиЊєзХМпЉМжККе≠©е≠РзїЩзїЩжТСеЭПдЇЖ пЉИињЩзЖКзИЄзИЄдєЯ姙жБРжАЦдЇЖгАВдљЖи∞ГжХізЇњз®ЛзЪДжЧґеАЩеЊАеЊАдЄНе∞ПењГеПѓиГље∞±жККз≥їзїЯжРЮжМВдЇЖпЉЙ
йАЪињЗињЩдЄ™дЊЛе≠РжИСдїђеПѓдї•зЬЛеЗЇпЉМдїОе§ЦйГ®з≥їзїЯжЭ•иІВеѓЯпЉМжИЦиАЕдї•зїПй™МзЪДжЦєеЉПињЫи°МиЃ°зЃЧпЉМйГљжШѓйЭЮеЄЄеЫ∞йЪЊзЪДгАВдЇОжШѓзїУиЃЇжШѓпЉЪ
иЃ©е≠©е≠РдЉЪиѓіиѓЭпЉМеРГй•±дЇЖиЗ™еЈ±иѓіпЉМиЗ™еЈ±е≠¶дЉЪеРГй•≠пЉМиЗ™зЃ°зРЖжШѓжЬАдљ≥жЦєж°ИгАВ
зДґеєґеНµпЉМиЃ°зЃЧжЬЇдЄНдЉЪиЗ™еЈ±иѓіиѓЭпЉМе¶ВдљХиЗ™зЃ°зРЖпЉЯ
дљЖжИСдїђдїОдї•дЄКзЪДиЃ®иЃЇеПѓдї•еЊЧеЗЇдЄАдЄ™зїУиЃЇпЉЪ
- зЇњз®ЛзЪДжИРжЬђиЊГйЂШпЉИеЖЕе≠ШпЉМи∞ГеЇ¶пЉЙдЄНеПѓиГље§ІиІДж®°еИЫеїЇ
- еЇФиѓ•зФ±иѓ≠и®АжИЦиАЕж°ЖжЮґеК®жАБиІ£еЖ≥ињЩдЄ™йЧЃйҐШ
зЇњз®Л汆жЦєж°И
Java1.5еРОпЉМDoug LeaзЪДExecutorз≥їеИЧ襀еМЕеРЂеЬ®йїШиЃ§зЪДJDKеЖЕпЉМжШѓеЕЄеЮЛзЪДзЇњз®Л汆жЦєж°ИгАВ
зЇњз®Л汆дЄАеЃЪз®ЛеЇ¶дЄКжОІеИґдЇЖзЇњз®ЛзЪДжХ∞йЗПпЉМеЃЮзО∞дЇЖзЇњз®Ле§НзФ®пЉМйЩНдљОдЇЖзЇњз®ЛзЪДдљњзФ®жИРжЬђгАВдљЖињШжШѓж≤°жЬЙиІ£еЖ≥жХ∞йЗПзЪДйЧЃйҐШпЉМзЇњз®Л汆еИЭеІЛеМЦзЪДжЧґеАЩињШжШѓи¶БиЃЊзљЃдЄАдЄ™жЬАе∞ПеТМжЬАе§ІзЇњз®ЛжХ∞пЉМдї•еПКдїїеК°йШЯеИЧзЪДйХњеЇ¶пЉМиЗ™зЃ°зРЖеП™жШѓеЬ®иЃЊеЃЪиМГеЫіеЖЕзЪДеК®жАБи∞ГжХігАВеП¶е§ЦдЄНеРМзЪДдїїеК°еПѓиГљжЬЙдЄНеРМзЪДеєґеПСйЬАж±ВпЉМдЄЇдЇЖйБњеЕНдЇТзЫЄељ±еУНеПѓиГљйЬАи¶Бе§ЪдЄ™зЇњз®Л汆пЉМжЬАеРОеѓЉиЗізЪДзїУжЮЬе∞±жШѓJavaзЪДз≥їзїЯйЗМеЕЕжЦ•дЇЖе§ІйЗПзЪДзЇњз®Л汆гАВ
жЦ∞зЪДжАЭиЈѓ
дїОеЙНйЭҐзЪДеИЖжЮРжИСдїђеПѓдї•зЬЛеЗЇпЉМе¶ВжЮЬзЇњз®ЛжШѓдЄАзЫіе§ДдЇОињРи°МзКґжАБпЉМжИСдїђеП™йЬАиЃЊзљЃеТМCPUж†ЄжХ∞зЫЄз≠ЙзЪДзЇњз®ЛжХ∞еН≥еПѓпЉМињЩж†Је∞±еПѓдї•жЬАе§ІеМЦзЪДеИ©зФ®CPUпЉМеєґдЄФйЩНдљОеИЗжНҐжИРжЬђдї•еПКеЖЕе≠ШдљњзФ®гАВдљЖе¶ВдљХеБЪеИ∞ињЩдЄАзВєеСҐпЉЯ
йЩИеКЫе∞±еИЧпЉМдЄНиГљиАЕж≠Ґ
ињЩеП•иѓЭжШѓиѓіпЉМиГљеє≤жіїзЪДдї£з†БзЙЗжЃµе∞±жФЊеЬ®зЇњз®ЛйЗМпЉМе¶ВжЮЬеє≤дЄНдЇЖжіїпЉИйЬАи¶Бз≠ЙеЊЕпЉМ襀йШїе°Юз≠ЙпЉЙпЉМе∞±жСШдЄЛжЭ•гАВйАЪдњЧзЪДиѓіе∞±жШѓдЄНи¶БеН†зЭАиМЕеЭСдЄНжЛЙе±ОпЉМе¶ВжЮЬжЛЙдЄНеЗЇжЭ•пЉМйЬАи¶БйЕЭйЕњдЄЛпЉМеЕИжККиМЕеЭСиЃ©еЗЇжЭ•пЉМеЫ†дЄЇиМЕеЭСжШѓз®АзЉЇиµДжЇРгАВ
и¶БеБЪеИ∞ињЩзВєдЄАиИђжЬЙдЄ§зІНжЦєж°ИпЉЪ
-
еЉВж≠•еЫЮи∞ГжЦєж°И¬†еЕЄеЮЛе¶ВNodeJSпЉМйБЗеИ∞йШїе°ЮзЪДжГЕеЖµпЉМжѓФе¶ВзљСзїЬи∞ГзФ®пЉМеИЩж≥®еЖМдЄАдЄ™еЫЮи∞ГжЦєж≥ХпЉИеЕґеЃЮињШеМЕжЛђдЇЖдЄАдЇЫдЄКдЄЛжЦЗжХ∞жНЃеѓєи±°пЉЙзїЩIOи∞ГеЇ¶еЩ®пЉИlinuxдЄЛжШѓlibevпЉМи∞ГеЇ¶еЩ®еЬ®еП¶е§ЦзЪДзЇњз®ЛйЗМпЉЙпЉМељУеЙНзЇњз®Ле∞±иҐЂйЗКжФЊдЇЖпЉМеОїеє≤еИЂзЪДдЇЛжГЕдЇЖгАВз≠ЙжХ∞жНЃеЗЖе§Зе•љпЉМи∞ГеЇ¶еЩ®дЉЪе∞ЖзїУжЮЬдЉ†йАТзїЩеЫЮи∞ГжЦєж≥ХзДґеРОжЙІи°МпЉМжЙІи°МеЕґеЃЮдЄНеЬ®еОЯжЭ•еПСиµЈиѓЈж±ВзЪДзЇњз®ЛйЗМдЇЖпЉМдљЖеѓєзФ®жИЈжЭ•иѓіжЧ†жДЯзЯ•гАВдљЖињЩзІНжЦєеЉПзЪДйЧЃйҐШе∞±жШѓеЊИеЃєжШУйБЗеИ∞callback hellпЉМеЫ†дЄЇжЙАжЬЙзЪДйШїе°ЮжУНдљЬйГљењЕй°їеЉВж≠•пЉМеР¶еИЩз≥їзїЯе∞±еН°ж≠їдЇЖгАВињШжЬЙе∞±жШѓеЉВж≠•зЪДжЦєеЉПжЬЙзВєињЭеПНдЇЇз±їжАЭзїідє†жГѓпЉМдЇЇз±їињШжШѓдє†жГѓеРМж≠•зЪДжЦєеЉПгАВ
-
GreenThread/Coroutine/FiberжЦєж°И¬†ињЩзІНжЦєж°ИеЕґеЃЮеТМдЄКйЭҐзЪДжЦєж°ИжЬђиі®дЄКеМЇеИЂдЄНе§ІпЉМеЕ≥йФЃеЬ®дЇОеЫЮи∞ГдЄКдЄЛжЦЗзЪДдњЭе≠Шдї•еПКжЙІи°МжЬЇеИґгАВдЄЇдЇЖиІ£еЖ≥еЫЮи∞ГжЦєж≥ХеЄ¶жЭ•зЪДйЪЊйҐШпЉМињЩзІНжЦєж°ИзЪДжАЭиЈѓжШѓеЖЩдї£з†БзЪДжЧґеАЩињШжШѓжМЙй°ЇеЇПеЖЩпЉМдљЖйБЗеИ∞IOз≠ЙйШїе°Юи∞ГзФ®жЧґпЉМе∞ЖељУеЙНзЪДдї£з†БзЙЗжЃµжЪВеБЬпЉМдњЭе≠ШдЄКдЄЛжЦЗпЉМиЃ©еЗЇељУеЙНзЇњз®ЛгАВз≠ЙIOдЇЛдїґеЫЮжЭ•пЉМзДґеРОеЖНжЙЊдЄ™зЇњз®ЛиЃ©ељУеЙНдї£з†БзЙЗжЃµжБҐе§НдЄКдЄЛжЦЗзїІзї≠жЙІи°МпЉМеЖЩдї£з†БзЪДжЧґеАЩжДЯиІЙе•љеГПжШѓеРМж≠•зЪДпЉМдїњдљЫеЬ®еРМдЄАдЄ™зЇњз®ЛеЃМжИРзЪДпЉМдљЖеЃЮйЩЕдЄКз≥їзїЯеПѓиГљеИЗжНҐдЇЖзЇњз®ЛпЉМдљЖеѓєз®ЛеЇПжЧ†жДЯгАВ
GreenThread
- зФ®жИЈз©ЇйЧі й¶ЦеЕИжШѓеЬ®зФ®жИЈз©ЇйЧіпЉМйБњеЕНеЖЕж†ЄжАБеТМзФ®жИЈжАБзЪДеИЗжНҐеѓЉиЗізЪДжИРжЬђгАВ
- зФ±иѓ≠и®АжИЦиАЕж°ЖжЮґе±Ви∞ГеЇ¶
- жЫіе∞ПзЪДж†Из©ЇйЧіеЕБиЃЄеИЫеїЇе§ІйЗПеЃЮдЊЛпЉИзЩЊдЄЗзЇІеИЂпЉЙ
еЗ†дЄ™ж¶Вењµ
- Continuation ињЩдЄ™ж¶ВењµдЄНзЖЯжВЙFPзЉЦз®ЛзЪДдЇЇеПѓиГљдЄН姙зЖЯжВЙпЉМдЄНињЗињЩйЗМеПѓдї•зЃАеНХзЪДй°ЊеРНжАЭдєЙпЉМеПѓдї•зРЖиІ£дЄЇиЃ©жИСдїђзЪДз®ЛеЇПеПѓдї•жЪВеБЬпЉМзДґеРОдЄЛжђ°и∞ГзФ®зїІзї≠пЉИcontineпЉЙдїОдЄКжђ°жЪВеБЬзЪДеЬ∞жЦєеЉАеІЛзЪДдЄАзІНжЬЇеИґгАВзЫЄељУдЇОз®ЛеЇПи∞ГзФ®е§ЪдЇЖдЄАзІНеЕ•еП£гАВ
- Coroutine жШѓContinuationзЪДдЄАзІНеЃЮзО∞пЉМдЄАиИђи°®зО∞дЄЇиѓ≠и®Ае±ВйЭҐзЪДзїДдїґжИЦиАЕз±їеЇУгАВдЄїи¶БжПРдЊЫyieldпЉМresumeжЬЇеИґгАВ
- Fiber еТМCoroutineеЕґеЃЮжШѓдЄАдљУдЄ§йЭҐзЪДпЉМдЄїи¶БжШѓдїОз≥їзїЯе±ВйЭҐжППињ∞пЉМеПѓдї•зРЖиІ£жИРCoroutineињРи°МдєЛеРОзЪДдЄЬи•ње∞±жШѓFiberгАВ
Goroutine
GoroutineеЕґеЃЮе∞±жШѓеЙНйЭҐGreenThreadз≥їеИЧиІ£еЖ≥жЦєж°ИзЪДдЄАзІНжЉФињЫеТМеЃЮзО∞гАВ
- й¶ЦеЕИпЉМеЃГеЖЕзљЃдЇЖCoroutineжЬЇеИґгАВеЫ†дЄЇи¶БзФ®жИЈжАБзЪДи∞ГеЇ¶пЉМењЕй°їжЬЙеПѓдї•иЃ©дї£з†БзЙЗжЃµеПѓдї•жЪВеБЬ/зїІзї≠зЪДжЬЇеИґгАВ
- еЕґжђ°пЉМеЃГеЖЕзљЃдЇЖдЄАдЄ™и∞ГеЇ¶еЩ®пЉМеЃЮзО∞дЇЖCoroutineзЪДе§ЪзЇњз®Леєґи°Ми∞ГеЇ¶пЉМеРМжЧґйАЪињЗеѓєзљСзїЬз≠ЙеЇУзЪДе∞Би£ЕпЉМеѓєзФ®жИЈе±ПиФљдЇЖи∞ГеЇ¶зїЖиКВгАВ
- жЬАеРОпЉМжПРдЊЫдЇЖChannelжЬЇеИґпЉМзФ®дЇОGoroutineдєЛйЧійАЪдњ°пЉМеЃЮзО∞CSPеєґеПСж®°еЮЛпЉИCommunicating Sequential ProcessesпЉЙгАВеЫ†дЄЇGoзЪДChannelжШѓйАЪињЗиѓ≠ж≥ХеЕ≥йФЃиѓНжПРдЊЫзЪДпЉМеѓєзФ®жИЈе±ПиФљдЇЖиЃЄе§ЪзїЖиКВгАВеЕґеЃЮGoзЪДChannelеТМJavaдЄ≠зЪДSynchronousQueueжШѓдЄАж†ЈзЪДжЬЇеИґпЉМе¶ВжЮЬжЬЙbufferеЕґеЃЮе∞±жШѓArrayBlockQueueгАВ
Goroutineи∞ГеЇ¶еЩ®
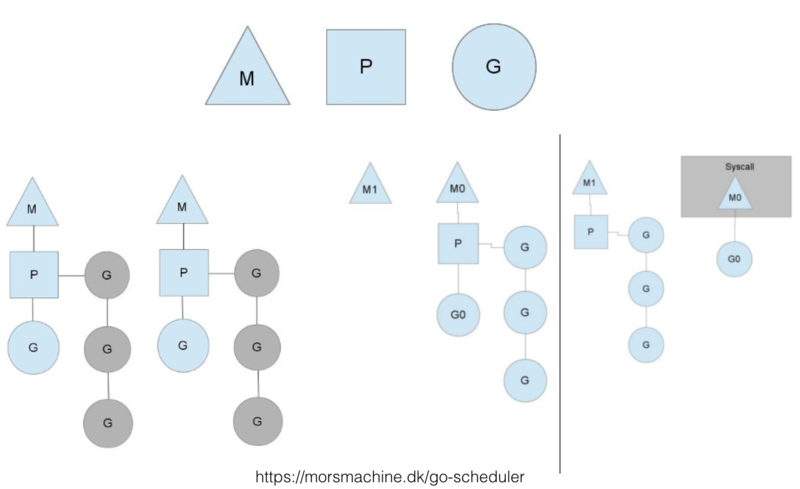
ињЩдЄ™еЫЊдЄАиИђиЃ≤Goroutineи∞ГеЇ¶еЩ®зЪДеЬ∞жЦєйГљдЉЪеЉХзФ®пЉМжГ≥и¶БдїФзїЖдЇЖиІ£зЪДеПѓдї•зЬЛзЬЛеОЯеНЪеЃҐгАВињЩйЗМеП™иѓіжШОеЗ†зВєпЉЪ
- Mдї£и°®з≥їзїЯзЇњз®ЛпЉМPдї£и°®е§ДзРЖеЩ®пЉИж†ЄпЉЙпЉМGдї£и°®GoroutineгАВGoеЃЮзО∞дЇЖM:NзЪДи∞ГеЇ¶пЉМдєЯе∞±жШѓиѓізЇњз®ЛеТМGoroutineдєЛйЧіжШѓе§Ъеѓєе§ЪзЪДеЕ≥з≥їгАВињЩзВєеЬ®иЃЄе§ЪGreenThread/CoroutineзЪДи∞ГеЇ¶еЩ®еєґж≤°жЬЙеЃЮзО∞гАВжѓФе¶ВJava1.1зЙИжЬђдєЛеЙНзЪДзЇњз®ЛеЕґеЃЮжШѓGreenThreadпЉИињЩдЄ™иѓНе∞±жЭ•жЇРдЇОJavaпЉЙпЉМдљЖзФ±дЇОж≤°еЃЮзО∞е§Ъеѓєе§ЪзЪДи∞ГеЇ¶пЉМдєЯе∞±жШѓж≤°жЬЙзЬЯж≠£еЃЮзО∞еєґи°МпЉМеПСжМ•дЄНдЇЖе§Ъж†ЄзЪДдЉШеКњпЉМжЙАдї•еРОжЭ•жФєжИРеЯЇдЇОз≥їзїЯеЖЕж†ЄзЪДThreadеЃЮзО∞дЇЖгАВ
- жЯРдЄ™з≥їзїЯзЇњз®Ле¶ВжЮЬ襀йШїе°ЮпЉМжОТеИЧеЬ®иѓ•зЇњз®ЛдЄКзЪДGoroutineдЉЪ襀ињБзІїгАВељУзДґињШжЬЙеЕґдїЦжЬЇеИґпЉМжѓФе¶ВMз©ЇйЧ≤дЇЖпЉМе¶ВжЮЬеЕ®е±АйШЯеИЧж≤°жЬЙдїїеК°пЉМеПѓиГљдЉЪдїОеЕґдїЦMеБЈдїїеК°жЙІи°МпЉМзЫЄељУдЇОдЄАзІНrebalanceжЬЇеИґгАВињЩйЗМдЄНеЖНзїЖиѓіпЉМжЬЙйЬАи¶БзЬЛдЄУйЧ®зЪДеИЖжЮРжЦЗзЂ†гАВ
- еЕЈдљУзЪДеЃЮзО∞з≠ЦзХ•еТМжИСдїђеЙНйЭҐеИЖжЮРзЪДжЬЇеИґз±їдЉЉгАВз≥їзїЯеРѓеК®жЧґпЉМдЉЪеРѓеК®дЄАдЄ™зЛђзЂЛзЪДеРОеП∞зЇњз®ЛпЉИдЄНеЬ®GoroutineзЪДи∞ГеЇ¶зЇњз®Л汆йЗМпЉЙпЉМеРѓеК®netpollзЪД蚁胥гАВељУжЬЙGoroutineеПСиµЈзљСзїЬиѓЈж±ВжЧґпЉМзљСзїЬеЇУдЉЪе∞ЖfdпЉИжЦЗдїґжППињ∞зђ¶пЉЙеТМpollDescпЉИзФ®дЇОжППињ∞netpollзЪДзїУжЮДдљУпЉМеМЕеРЂеЫ†дЄЇиѓї/еЖЩињЩдЄ™fdиАМйШїе°ЮзЪДGoroutineпЉЙеЕ≥иБФиµЈжЭ•пЉМзДґеРОи∞ГзФ®runtime.goparkжЦєж≥ХпЉМжМВиµЈељУеЙНзЪДGoroutineгАВељУеРОеП∞зЪДnetpoll蚁胥иОЈеПЦеИ∞epollпЉИlinuxзОѓеҐГдЄЛпЉЙзЪДeventпЉМдЉЪе∞ЖeventдЄ≠зЪДpollDescеПЦеЗЇжЭ•пЉМжЙЊеИ∞еЕ≥иБФзЪДйШїе°ЮGoroutineпЉМеєґињЫи°МжБҐе§НгАВ
GoroutineжШѓйУґеЉєдєИпЉЯ
GoroutineеЊИе§Із®ЛеЇ¶дЄКйЩНдљОдЇЖеєґеПСзЪДеЉАеПСжИРжЬђпЉМжШѓдЄНжШѓжИСдїђжЙАжЬЙйЬАи¶БеєґеПСзЪДеЬ∞жЦєзЫіжО•go funcе∞±жРЮеЃЪдЇЖеСҐпЉЯ
GoйАЪињЗGoroutineзЪДи∞ГеЇ¶иІ£еЖ≥дЇЖCPUеИ©зФ®зОЗзЪДйЧЃйҐШгАВдљЖйБЗеИ∞еЕґдїЦзЪДзУґйҐИиµДжЇРе¶ВдљХе§ДзРЖпЉЯжѓФе¶ВеЄ¶йФБзЪДеЕ±дЇЂиµДжЇРпЉМжѓФе¶ВжХ∞жНЃеЇУињЮжО•з≠ЙгАВдЇТиБФзљСеЬ®зЇњеЇФзФ®еЬЇжЩѓдЄЛпЉМе¶ВжЮЬжѓПдЄ™иѓЈж±ВйГљжЙФеИ∞дЄАдЄ™GoroutineйЗМпЉМељУиµДжЇРеЗЇзО∞зУґйҐИзЪДжЧґеАЩпЉМдЉЪеѓЉиЗіе§ІйЗПзЪДGoroutineйШїе°ЮпЉМжЬАеРОзФ®жИЈиѓЈж±ВиґЕжЧґгАВињЩжЧґеАЩе∞±йЬАи¶БзФ®Goroutine汆жЭ•ињЫи°МжОІжµБпЉМеРМжЧґйЧЃйҐШеПИжЭ•дЇЖпЉЪ汆е≠РйЗМиЃЊзљЃе§Ъе∞СдЄ™GoroutineеРИйАВпЉЯ
жЙАдї•ињЩдЄ™йЧЃйҐШињШжШѓж≤°жЬЙдїОжЫіжЬђдЄКиІ£еЖ≥гАВ
Actorж®°еЮЛ
Actorеѓєж≤°жО•иІ¶ињЗињЩдЄ™ж¶ВењµзЪДдЇЇеПѓиГљдЄН姙啚зРЖиІ£пЉМActorзЪДж¶ВењµеЕґеЃЮеТМOOйЗМзЪДеѓєи±°з±їдЉЉпЉМжШѓдЄАзІНжКљи±°гАВйЭҐеѓєеѓєи±°зЉЦз®ЛеѓєзО∞еЃЮзЪДжКљи±°жШѓеѓєи±°=е±ЮжАІ+и°МдЄЇпЉИmethodпЉЙпЉМдљЖељУдљњзФ®жЦєи∞ГзФ®еѓєи±°и°МдЄЇпЉИmethodпЉЙзЪДжЧґеАЩпЉМеЕґеЃЮеН†зФ®зЪДжШѓи∞ГзФ®жЦєзЪДCPUжЧґйЧізЙЗпЉМжШѓеР¶еєґеПСдєЯжШѓзФ±и∞ГзФ®жЦєеЖ≥еЃЪзЪДгАВињЩдЄ™жКљи±°еЕґеЃЮеТМзО∞еЃЮдЄЦзХМжШѓжЬЙеЈЃеЉВзЪДгАВзО∞еЃЮдЄЦзХМжЫіеГПActorзЪДжКљи±°пЉМдЇТзЫЄйГљжШѓйАЪињЗеЉВж≠•жґИжБѓйАЪдњ°зЪДгАВжѓФе¶Вдљ†еѓєдЄАдЄ™зЊОе•≥say hiпЉМзЊОе•≥жШѓеР¶еЫЮеЇФпЉМе¶ВдљХеЫЮеЇФжШѓзФ±зЊОе•≥иЗ™еЈ±еЖ≥еЃЪзЪДпЉМињРи°МеЬ®зЊОе•≥иЗ™еЈ±зЪДе§ІиДСйЗМпЉМеєґдЄНдЉЪеН†зФ®еПСйАБиАЕзЪДе§ІиДСгАВ
жЙАдї•ActorжЬЙдї•дЄЛзЙєеЊБпЉЪ
- Processing вАУ actorеПѓдї•еБЪиЃ°зЃЧзЪДпЉМдЄНйЬАи¶БеН†зФ®и∞ГзФ®жЦєзЪДCPUжЧґйЧізЙЗпЉМеєґеПСз≠ЦзХ•дєЯжШѓзФ±иЗ™еЈ±еЖ≥еЃЪгАВ
- Storage вАУ actorеПѓдї•дњЭе≠ШзКґжАБ
- Communication вАУ actorдєЛйЧіеПѓдї•йАЪињЗеПСйАБжґИжБѓйАЪиЃѓ
ActorйБµеЊ™дї•дЄЛиІДеИЩпЉЪ
- еПСйАБжґИжБѓзїЩеЕґдїЦзЪДActor
- еИЫеїЇеЕґдїЦзЪДActor
- жО•еПЧеєґе§ДзРЖжґИжБѓпЉМдњЃжФєиЗ™еЈ±зЪДзКґжАБ
ActorзЪДзЫЃж†ЗпЉЪ
- ActorеПѓзЛђзЂЛжЫіжЦ∞пЉМеЃЮзО∞зГ≠еНЗзЇІгАВеЫ†дЄЇActorдЇТзЫЄдєЛйЧіж≤°жЬЙзЫіжО•зЪДиА¶еРИпЉМжШѓзЫЄеѓєзЛђзЂЛзЪДеЃЮдљУпЉМеПѓиГљеЃЮзО∞зГ≠еНЗзЇІгАВ
- жЧ†зЉЭеЉ•еРИжЬђеЬ∞еТМињЬз®Ли∞ГзФ® еЫ†дЄЇActorдљњзФ®еЯЇдЇОжґИжБѓзЪДйАЪиЃѓжЬЇеИґпЉМжЧ†иЃЇжШѓеТМжЬђеЬ∞зЪДActorпЉМињШжШѓињЬз®ЛActorдЇ§дЇТпЉМйГљжШѓйАЪињЗжґИжБѓпЉМињЩж†Је∞±еЉ•еРИдЇЖжЬђеЬ∞еТМињЬз®ЛзЪДеЈЃеЉВгАВ
- еЃєйФЩ ActorдєЛйЧізЪДйАЪдњ°жШѓеЉВж≠•зЪДпЉМеПСйАБжЦєеП™зЃ°еПСйАБпЉМдЄНеЕ≥ењГиґЕжЧґдї•еПКйФЩиѓѓпЉМињЩдЇЫйГљзФ±ж°ЖжЮґе±ВеТМзЛђзЂЛзЪДйФЩиѓѓе§ДзРЖжЬЇеИґжО•зЃ°гАВ
- жШУжЙ©е±ХпЉМ姩зДґеИЖеЄГеЉП еЫ†дЄЇActorзЪДйАЪдњ°жЬЇеИґеЉ•еРИдЇЖжЬђеЬ∞еТМињЬз®Ли∞ГзФ®пЉМжЬђеЬ∞Actorе§ДзРЖдЄНињЗжЭ•зЪДжЧґеАЩпЉМеПѓдї•еЬ®ињЬз®ЛиКВзВєдЄКеРѓеК®ActorзДґеРОиљђеПСжґИжБѓињЗеОїгАВ
ActorзЪДеЃЮзО∞пЉЪ
- Erlang/OTP Actorж®°еЮЛзЪДж†ЗжЭЖпЉМеЕґдїЦзЪДеЃЮзО∞еЯЇжЬђдЄКйГљдЄАеЃЪз®ЛеЇ¶еПВзЕІдЇЖErlangзЪДж®°еЉПгАВеЃЮзО∞дЇЖзГ≠еНЗзЇІдї•еПКеИЖеЄГеЉПгАВ
- AkkaпЉИScala,JavaпЉЙеЯЇдЇОзЇњз®ЛеТМеЉВж≠•еЫЮи∞Гж®°еЉПеЃЮзО∞гАВзФ±дЇОJavaдЄ≠ж≤°жЬЙFiberпЉМжЙАдї•жШѓеЯЇдЇОзЇњз®ЛзЪДгАВдЄЇдЇЖйБњеЕНзЇњз®Л襀йШїе°ЮпЉМAkkaдЄ≠жЙАжЬЙзЪДйШїе°ЮжУНдљЬйГљйЬАи¶БеЉВж≠•еМЦгАВи¶БдєИжШѓAkkaжПРдЊЫзЪДеЉВж≠•ж°ЖжЮґпЉМи¶БдєИйАЪињЗFuture-callbackжЬЇеИґпЉМиљђжНҐжИРеЫЮи∞Гж®°еЉПгАВеЃЮзО∞дЇЖеИЖеЄГеЉПпЉМдљЖињШдЄНжФѓжМБзГ≠еНЗзЇІгАВ
- Quasar (Java) дЄЇдЇЖиІ£еЖ≥AkkaзЪДйШїе°ЮеЫЮи∞ГйЧЃйҐШпЉМQuasarйАЪињЗе≠ЧиКВз†БеҐЮеЉЇзЪДжЦєеЉПпЉМеЬ®JavaдЄ≠еЃЮзО∞дЇЖCoroutine/FiberгАВеРМжЧґйАЪињЗClassLoaderзЪДжЬЇеИґеЃЮзО∞дЇЖзГ≠еНЗзЇІгАВзЉЇзВєжШѓз≥їзїЯеРѓеК®зЪДжЧґеАЩи¶БйАЪињЗjavaagentжЬЇеИґињЫи°Ме≠ЧиКВз†БеҐЮеЉЇгАВ
Golang CSP VS Actor
дЇМиАЕзЪДж†Љи®АйГљжШѓпЉЪ
DonвАЩt communicate by sharing memory, share memory by communicating
йАЪињЗжґИжБѓйАЪдњ°зЪДжЬЇеИґжЭ•йБњеЕНзЂЮжАБжЭ°дїґпЉМдљЖеЕЈдљУзЪДжКљи±°еТМеЃЮзО∞дЄКжЬЙдЇЫеЈЃеЉВгАВ
- CSPж®°еЮЛйЗМжґИжБѓеТМChannelжШѓдЄїдљУпЉМе§ДзРЖеЩ®жШѓеМњеРНзЪДгАВ
дєЯе∞±жШѓиѓіеПСйАБжЦєйЬАи¶БеЕ≥ењГиЗ™еЈ±зЪДжґИжБѓз±їеЮЛдї•еПКеЇФиѓ•еЖЩеИ∞еУ™дЄ™ChannelпЉМдљЖдЄНйЬАи¶БеЕ≥ењГи∞БжґИиієдЇЖеЃГпЉМдї•еПКжЬЙе§Ъе∞СдЄ™жґИиієиАЕгАВChannelдЄАиИђйГљжШѓз±їеЮЛзїСеЃЪзЪДпЉМдЄАдЄ™ChannelеП™еЖЩеРМдЄАзІНз±їеЮЛзЪДжґИжБѓпЉМжЙАдї•CSPйЬАи¶БжФѓжМБalt/selectжЬЇеИґпЉМеРМжЧґзЫСеРђе§ЪдЄ™ChannelгАВChannelжШѓеРМж≠•зЪДж®°еЉПпЉИGolangзЪДChannelжФѓжМБbufferпЉМжФѓжМБдЄАеЃЪжХ∞йЗПзЪДеЉВж≠•пЉЙпЉМиГМеРОзЪДйАїиЊСжШѓеПСйАБжЦєйЭЮеЄЄеЕ≥ењГжґИжБѓжШѓеж襀е§ДзРЖпЉМCSPи¶БдњЭиѓБжѓПдЄ™жґИжБѓйÚ襀ж≠£еЄЄе§ДзРЖдЇЖпЉМж≤°иҐЂе§ДзРЖе∞±йШїе°ЮзЭАгАВ - Actorж®°еЮЛйЗМActorжШѓдЄїдљУпЉМMailboxпЉИз±їдЉЉдЇОCSPзЪДChannelпЉЙжШѓйАПжШОзЪДгАВ
дєЯе∞±жШѓиѓіеЃГеБЗеЃЪеПСйАБжЦєдЉЪеЕ≥ењГжґИжБѓеПСзїЩи∞БжґИиієдЇЖпЉМдљЖдЄНеЕ≥ењГжґИжБѓз±їеЮЛдї•еПКйАЪйБУгАВжЙАдї•MailboxжШѓеЉВж≠•ж®°еЉПпЉМеПСйАБиАЕдЄНиГљеБЗеЃЪеПСйАБзЪДжґИжБѓдЄАеЃЪ襀жФґеИ∞еТМе§ДзРЖгАВActorж®°еЮЛењЕй°їжФѓжМБеЉЇе§ІзЪДж®°еЉПеМєйЕНжЬЇеИґпЉМеЫ†дЄЇжЧ†иЃЇдїАдєИз±їеЮЛзЪДжґИжБѓйГљдЉЪйАЪињЗеРМдЄАдЄ™йАЪйБУеПСйАБињЗжЭ•пЉМйЬАи¶БйАЪињЗж®°еЉПеМєйЕНжЬЇеИґеБЪеИЖеПСгАВеЃГиГМеРОзЪДйАїиЊСжШѓзО∞еЃЮдЄЦзХМжЬђжЭ•е∞±жШѓеЉВж≠•зЪДпЉМдЄНз°ЃеЃЪпЉИnon-deterministicпЉЙзЪДпЉМжЙАдї•з®ЛеЇПдєЯи¶БйАВеЇФйЭҐеѓєдЄНз°ЃеЃЪзЪДжЬЇеИґзЉЦз®ЛгАВиЗ™дїОжЬЙдЇЖеєґи°МдєЛеРОпЉМеОЯжЭ•зЪДз°ЃеЃЪзЉЦз®ЛжАЭзїіж®°еЉПеЈ≤зїПеПЧеИ∞дЇЖжМСжИШпЉМиАМActorзЫіжО•еЬ®ж®°еЉПдЄ≠иХіеРЂдЇЖињЩзВєгАВ
дїОињЩж†ЈзЬЛжЭ•пЉМCSPзЪДж®°еЉПжѓФиЊГйАВеРИBoss-Workerж®°еЉПзЪДдїїеК°еИЖеПСжЬЇеИґпЉМеЃГзЪДдЊµеЕ•жАІж≤°йВ£дєИеЉЇпЉМеПѓдї•еЬ®зО∞жЬЙзЪДз≥їзїЯдЄ≠йАЪињЗCSPиІ£еЖ≥жЯРдЄ™еЕЈдљУзЪДйЧЃйҐШгАВеЃГеєґдЄНиѓХеЫЊиІ£еЖ≥йАЪдњ°зЪДиґЕжЧґеЃєйФЩйЧЃйҐШпЉМињЩдЄ™ињШжШѓйЬАи¶БеПСиµЈжЦєињЫи°Ме§ДзРЖгАВеРМжЧґзФ±дЇОChannelжШѓжШЊеЉПзЪДпЉМиЩљзДґеПѓдї•йАЪињЗnetchanпЉИеОЯжЭ•GoжПРдЊЫзЪДnetchanжЬЇеИґзФ±дЇОињЗдЇОе§НжЭВпЉМ襀еЇЯеЉГпЉМеЬ®иЃ®иЃЇжЦ∞зЪДnetchanпЉЙеЃЮзО∞ињЬз®ЛChannelпЉМдљЖеЊИйЪЊеБЪеИ∞еѓєдљњзФ®жЦєйАПжШОгАВиАМActorеИЩжШѓдЄАзІНеЕ®жЦ∞зЪДжКљи±°пЉМдљњзФ®Actorи¶БйЭҐдЄіжХідЄ™еЇФзФ®жЮґжЮДжЬЇеИґеТМжАЭзїіжЦєеЉПзЪДеПШжЫігАВеЃГиѓХеЫЊи¶БиІ£еЖ≥зЪДйЧЃйҐШи¶БжЫіеєњдЄАдЇЫпЉМжѓФе¶ВеЃєйФЩпЉМжѓФе¶ВеИЖеЄГеЉПгАВдљЖActorзЪДйЧЃйҐШеЬ®дЇОдї•ељУеЙНзЪДи∞ГеЇ¶жХИзОЗпЉМеУ™жАХжШѓзФ®GoroutineињЩж†ЈзЪДжЬЇеИґпЉМдєЯеЊИйЪЊиЊЊеИ∞зЫіжО•жЦєж≥Хи∞ГзФ®зЪДжХИзОЗгАВељУеЙНи¶БеГПOOзЪДгАОдЄАеИЗзЪЖеѓєи±°гАПдЄАж†ЈеЃЮзО∞дЄАдЄ™гАОдЄАеИЗзЪЖActorгАПзЪДиѓ≠и®АпЉМжХИзОЗдЄКиВѓеЃЪжЬЙйЧЃйҐШгАВжЙАдї•жКШдЄ≠зЪДжЦєеЉПжШѓеЬ®OOзЪДеЯЇз°АдЄКпЉМе∞Жз≥їзїЯзЪДжЯРдЄ™е±ВйЭҐзЪДзїДдїґжКљи±°дЄЇActorгАВ
еЖНжЙѓдЄАдЄЛRust
RustиІ£еЖ≥еєґеПСйЧЃйҐШзЪДжАЭиЈѓжШѓй¶ЦеЕИжЙњиЃ§зО∞еЃЮдЄЦзХМзЪДиµДжЇРжАїжШѓжЬЙйЩРзЪДпЉМжГ≥ељїеЇХйБњеЕНиµДжЇРеЕ±дЇЂжШѓеЊИйЪЊзЪДпЉМдЄНиѓХеЫЊеЃМеЕ®йБњеЕНиµДжЇРеЕ±дЇЂпЉМеЃГиЃ§дЄЇеєґеПСзЪДйЧЃйҐШдЄНеЬ®дЇОиµДжЇРеЕ±дЇЂпЉМиАМеЬ®дЇОйФЩиѓѓзЪДдљњзФ®иµДжЇРеЕ±дЇЂгАВжѓФе¶ВжИСдїђеЙНйЭҐжПРеИ∞зЪДпЉМе§Іе§ЪжХ∞иѓ≠и®АеЃЪдєЙз±їеЮЛзЪДжЧґеАЩпЉМеєґдЄНиГљйЩРеИґи∞ГзФ®жЦєе¶ВдљХдљњзФ®пЉМеП™иГљйАЪињЗжЦЗж°£жИЦиАЕж†ЗиЃ∞зЪДжЦєеЉПпЉИжѓФе¶ВJavaдЄ≠зЪД@ThreadSafe ,@NotThreadSafe annotationпЉЙиѓіжШОжШѓеР¶еєґеПСеЃЙеЕ®пЉМдљЖдєЯеП™иГљдїЕдїЕеБЪеИ∞жПРз§ЇзЪДдљЬзФ®пЉМдЄНиГљйШїж≠Ґи∞ГзФ®жЦєиѓѓзФ®гАВиЩљзДґGoжПРдЊЫдЇЖ-raceжЬЇеИґпЉМеПѓдї•йАЪињЗињРи°МеНХеЕГжµЛиѓХзЪДжЧґеАЩеЄ¶дЄКињЩдЄ™еПВжХ∞жЭ•ж£АжµЛзЂЮжАБжЭ°дїґпЉМдљЖе¶ВжЮЬдљ†зЪДеНХеЕГжµЛиѓХеєґеПСеЇ¶дЄНе§ЯпЉМи¶ЖзЫЦйЭҐдЄНеИ∞дєЯж£АжµЛдЄНеЗЇжЭ•гАВжЙАдї•RustзЪДиІ£еЖ≥жЦєж°Ие∞±жШѓпЉЪ
- еЃЪдєЙз±їеЮЛзЪДжЧґеАЩи¶БжШОз°ЃжМЗеЃЪиѓ•з±їеЮЛжШѓеР¶жШѓеєґеПСеЃЙеЕ®зЪД
- еЉХеЕ•дЇЖеПШйЗПзЪДжЙАжЬЙжЭГпЉИOwnershipпЉЙж¶Вењµ йЭЮеєґеПСеЃЙеЕ®зЪДжХ∞жНЃзїУжЮДеЬ®е§ЪдЄ™зЇњз®ЛйЧіиљђзІїпЉМдєЯдЄНдЄАеЃЪе∞±дЉЪеѓЉиЗійЧЃйҐШпЉМеѓЉиЗійЧЃйҐШзЪДжШѓе§ЪдЄ™зЇњз®ЛеРМжЧґжУНдљЬпЉМдєЯе∞±жШѓиѓіжШѓеЫ†дЄЇињЩдЄ™еПШйЗПзЪДжЙАжЬЙжЭГдЄНжШОз°ЃеѓЉиЗізЪДгАВжЬЙдЇЖжЙАжЬЙжЭГзЪДж¶ВењµеРОпЉМеПШйЗПеП™иГљзФ±жЛ•жЬЙжЙАжЬЙжЭГзЪДдљЬзФ®еЯЯдї£з†БжУНдљЬпЉМиАМеПШйЗПдЉ†йАТдЉЪеѓЉиЗіжЙАжЬЙжЭГеПШжЫіпЉМдїОиѓ≠и®Ае±ВйЭҐйЩРеИґдЇЖзЂЮжАБжЭ°дїґеЗЇзО∞зЪДжГЕеЖµгАВ
жЬЙдЇЖињЩжЬЇеИґпЉМRustеПѓдї•еЬ®зЉЦиѓСжЬЯиАМдЄНжШѓињРи°МжЬЯеѓєзЂЮжАБжЭ°дїґеБЪж£АжЯ•еТМйЩРеИґгАВиЩљзДґеЉАеПСзЪДжЧґеАЩеҐЮеК†дЇЖењГжЩЇжИРжЬђпЉМдљЖйЩНдљОдЇЖи∞ГзФ®жЦєдї•еПКжОТжЯ•еєґеПСйЧЃйҐШзЪДењГжЩЇжИРжЬђпЉМдєЯжШѓдЄАзІНжЬЙзЙєиЙ≤зЪДиІ£еЖ≥жЦєж°ИгАВ
зїУиЃЇ
йЭ©еСље∞ЪжЬ™жИРеКЯ еРМењЧдїїйЬАеК™еКЫ
жЬђжЦЗеЄ¶е§ІеЃґдЄАиµЈеЫЮй°ЊдЇЖеєґеПСзЪДйЧЃйҐШпЉМеТМеРДзІНиІ£еЖ≥жЦєж°ИгАВиЩљзДґеРДеЃґжЬЙеРДеЃґзЪДдЉШеКњдї•еПКдљњзФ®еЬЇжЩѓпЉМдљЖеєґеПСеЄ¶жЭ•зЪДйЧЃйҐШињШињЬињЬж≤°еИ∞иІ£еЖ≥зЪДз®ЛеЇ¶гАВжЙАдї•ињШйЬАеК™еКЫпЉМе§ІеЃґдєЯжЬЙжЬЇдЉЪеХКгАВ
жЬАеРОжКЫдЄ™з†Ц жЮДжГ≥:еЬ®GoroutineдЄКеЃЮзО∞ActorпЉЯ
- еИЖеЄГеЉП иІ£еЖ≥дЇЖеНХжЬЇжХИзОЗйЧЃйҐШпЉМжШѓдЄНжШѓеПѓдї•е∞ЭиѓХиІ£еЖ≥дЄЛеИЖеЄГеЉПжХИзОЗйЧЃйҐШпЉЯ
- еТМеЃєеЩ®йЫЖзЊ§иЮНеРИ ељУеЙНзЪДиЗ™еК®дЉЄзЉ©жЦєж°ИеЯЇжЬђдЄКйГљжШѓйАЪињЗзЫСжОІжЬНеК°еЩ®жИЦиАЕLoadBalancerпЉМиЃЊзљЃдЄАдЄ™йШАеАЉжЭ•еЃЮзО∞зЪДгАВз±їдЉЉдЇОжИСеЙНйЭҐжПРеИ∞зЪДеЦВй•≠зЪДдЊЛе≠РпЉМжШѓеЯЇдЇОзїПй™МзЪДжЦєж°ИпЉМдљЖе¶ВжЮЬз≥їзїЯеЖЕеТМе§ЦйГ®йЫЖзЊ§зїУеРИпЉМињЩдЄ™дЇЛжГЕе∞±еПѓдї•еБЪзЪДжЫізїЖиЗіеТМжЩЇиГљгАВ
- иЗ™зЃ°зРЖ еЙНйЭҐзЪДдЄ§зВєжЬАзїИзЪДзЫЃж†ЗйГљжШѓеЃЮзО∞дЄАдЄ™еПѓдї•иЗ™зЃ°зРЖзЪДз≥їзїЯгАВеБЪињЗз≥їзїЯињРзїізЪДеРМе≠¶йГљзЯ•йБУпЉМжИСдїђзЕІй°Њз≥їзїЯе∞±еГПзЕІй°Ње≠©е≠РдЄАж†ЈпЉМжЧґеИїи¶БзЫСжОІз≥їзїЯзЪДеРДзІНзКґжАБпЉМжО•еПЧз≥їзїЯзЪДеРДзІНжК•и≠¶пЉМзДґеРОжОТжЯ•йЧЃйҐШпЉМињЫи°МзіІжА•е§ДзРЖгАВе≠©е≠РжЬЙйХње§ІзЪДдЄА姩пЉМйВ£иГљдЄНиГљиЃ©з≥їзїЯдєЯиЗ™еЈ±жИРйХњпЉМеБЪеИ∞иЗ™зЃ°зРЖеСҐпЉЯиЩљзДґињЩдЄ™зЫЃж†ЗзО∞еЬ®зЬЛжЭ•ињШжѓФиЊГињЬпЉМдљЖжИСиІЙеЊЧжШѓеПѓдї•жЬЯеЊЕзЪДгАВ



зЫЄеЕ≥жО®иНР
Go-gaserverеИ©зФ®GoзЪДgoroutineеТМchannelжЭ•еЃЮзО∞ActorдєЛйЧізЪДеЉВж≠•йАЪдњ°пЉМз°ЃдњЭдЇЖжЄЄжИПжЬНеК°еЩ®зЪДйЂШеРЮеРРйЗПеТМдљОеїґињЯгАВ Go-gaserverзЪДиЃЊиЃ°зЫЃж†ЗжШѓжПРдЊЫдЄАдЄ™еПѓжЙ©е±ХзЪДжЄЄжИПжЬНеК°еЩ®еЯЇз°АжЮґжЮДпЉМеЃГиГље§ЯиљїжЭЊеЬ∞е§ДзРЖе§ІйЗПзЪДеєґеПСињЮжО•еТМе§НжЭВзЪД...
C++ Actor FrameworkпЉИCAFпЉЙжШѓдЄАзІНеЉАжЇРзЪДгАБиЈ®еє≥еП∞зЪДеЇУпЉМзФ®дЇОжЮДеїЇеєґеПСеТМеИЖеЄГеЉПз≥їзїЯпЉМеЕґж†ЄењГиЃЊиЃ°жАЭжГ≥жШѓactorж®°еЮЛгАВеЬ®actorж®°еЮЛдЄ≠пЉМжѓПдЄ™actorйГљжШѓдЄАдЄ™зЛђзЂЛзЪДеЃЮдљУпЉМжЛ•жЬЙиЗ™еЈ±зЪДзКґжАБеєґиГљеЉВж≠•жО•жФґеТМе§ДзРЖжґИжБѓгАВCAFжПРдЊЫдЇЖдЄАзІН...
еЬ®еєґеПСзЉЦз®ЛйҐЖеЯЯпЉМSwiftжПРдЊЫдЇЖдЄАзІНеРНдЄЇActorж®°еЮЛзЪДжЬЇеИґпЉМжЧ®еЬ®иІ£еЖ≥е§ЪзЇњз®ЛзОѓеҐГдЄ≠зЪДжХ∞жНЃзЂЮдЇЙйЧЃйҐШпЉМжПРйЂШз®ЛеЇПзЪДеєґеПСжАІиГљеТМеЃЙеЕ®жАІгАВиАМ"Aerojet"ж≠£жШѓдЄАдЄ™йТИеѓєSwiftзЪДActorж®°еЮЛеЃЮзО∞пЉМеЃГдЄЇеЉАеПСиАЕжПРдЊЫдЇЖжЫійЂШзЇІеИЂзЪДжКљи±°жЭ•е§ДзРЖ...
SkynetжШѓдЄАдЄ™еЉАжЇРеєґеПСж°ЖжЮґпЉМеЃГдЄЇдЇЖзЃАжВ¶зЪДзђђдЄАдЄ™MMORPGжЬНеК°еЩ®жЙАзЉЦеЖЩпЉМдљЖеЇФзФ®йҐЖеЯЯдЄНйЩРдЇОзљСзїЬжЄЄжИПгАВSkynetзЪДж†ЄењГйГ®еИЖдЄНеИ∞3000и°МCдї£з†БпЉМеИ©зФ®actorж®°еЉПеЕЕеИЖеИ©зФ®еНХжЬЇе§Ъж†ЄзЪДдЉШеКњпЉМе∞љйЗПе∞ЖдЄЪеК°йАїиЊСињЫи°Меєґи°Ме§ДзРЖгАВзЫЄеѓєдЇОErlang...
еЬ®ITи°МдЄЪдЄ≠пЉМActorж®°еЮЛжШѓдЄАзІНеєґеПСиЃ°зЃЧзЪДж®°еЮЛпЉМеЃГжЇРиЗ™дЇОеЗљжХ∞еЉПзЉЦз®ЛйҐЖеЯЯпЉМзФ±иЛ±еЫљиЃ°зЃЧжЬЇзІСе≠¶еЃґC.A.R. HoareжПРеЗЇгАВActorж®°еЮЛзЪДж†ЄењГжАЭжГ≥жШѓе∞ЖеєґеПСе§ДзРЖдЄ≠зЪДеЃЮдљУвАФвАФдєЯе∞±жШѓжЙІи°МеНХеЕГвАФвАФжКљи±°дЄЇвАЬActorвАЭпЉМжѓПдЄ™ActorйГљжЬЙиЗ™еЈ±зЪД...
ClooneyжШѓдЄАдЄ™дЄУдЄЇWebеЇФзФ®з®ЛеЇПиЃЊиЃ°зЪДActorеЇУпЉМеЃГеЯЇдЇОJavaScriptеЉАеПСпЉМдЄїи¶БеЇФзФ®дЇОе§ДзРЖеєґеПСеТМеИЖеЄГеЉПз≥їзїЯдЄ≠зЪДе§НжЭВйЧЃйҐШгАВеЬ®WebеЉАеПСдЄ≠пЉМйЭҐеѓєйЂШеєґеПСгАБеЃЮжЧґдЇ§дЇТдї•еПКжХ∞жНЃе§ДзРЖзЪДйЬАж±ВпЉМClooneyжПРдЊЫдЇЖдЄАзІНжЦ∞йҐЦдЄФеЉЇе§ІзЪДиІ£еЖ≥жЦєж°И...
еЬ®ITйҐЖеЯЯпЉМзЙєеИЂжШѓзљСзїЬзЉЦз®ЛеТМеєґеПСе§ДзРЖдЄ≠пЉМ`Actor`еТМ`Proactor`ж®°еЉПжШѓдЄ§зІНйЗНи¶БзЪДиЃЊиЃ°ж®°еЉПпЉМеЃГдїђдЄїи¶БзФ®дЇОйЂШжХИеЬ∞е§ДзРЖI/OжУНдљЬгАВињЩдЄ§зІНж®°еЉПйГљжґЙеПКеИ∞е¶ВдљХжЬЙжХИеЬ∞зЃ°зРЖе§ЪдЄ™еєґеПСзЪДI/OиѓЈж±ВпЉМдї•жПРйЂШз≥їзїЯжАІиГљеТМеУНеЇФйАЯеЇ¶гАВ й¶ЦеЕИпЉМ...
LabVIEW Actor Framework жШѓдЄАзІНеЉЇе§ІзЪДзЉЦз®Лж®°еЮЛпЉМдЄУдЄЇиІ£еЖ≥е§НжЭВзЪДеєґеПСеТМеЃЮжЧґйЧЃйҐШиАМиЃЊиЃ°гАВињЩдЄ™ж°ЖжЮґжЇРиЗ™дЇОеєґи°МиЃ°зЃЧеТМдЇЛдїґй©±еК®зЉЦз®ЛзЪДзРЖењµпЉМеЕБиЃЄеЉАеПСиАЕе∞ЖеЇФзФ®з®ЛеЇПеИЖиІ£дЄЇдЄАз≥їеИЧзЛђзЂЛеЈ•дљЬзЪДвАЬactorвАЭпЉИжЉФеСШпЉЙпЉМжѓПдЄ™actorйГљжЬЙ...
гАКAkka Actor 1.1.2пЉЪжЮДеїЇйЂШжХИеєґеПСеЇФзФ®зЪДж†ЄењГзїДдїґгАЛ еЬ®зО∞дї£иљѓдїґеЉАеПСдЄ≠пЉМе§ДзРЖеєґеПСеТМеИЖеЄГеЉПиЃ°зЃЧеЈ≤зїПжИРдЄЇдЄАдЄ™йЗНи¶БзЪДжМСжИШгАВAkkaпЉМдЄАдЄ™зФ±LightbendеЕђеПЄзїіжК§зЪДеЉАжЇРж°ЖжЮґпЉМжПРдЊЫдЇЖеЉЇе§ІзЪДеЈ•еЕЈжЭ•иІ£еЖ≥ињЩдЇЫйЧЃйҐШгАВе∞§еЕґеАЉеЊЧдЄАжПРзЪД...
AkkaжШѓиљїйЗПзЇІгАБеЯЇдЇОactorж®°еЮЛзЪДж°ЖжЮґпЉМеЃГзФ®дЇОжЮДеїЇйЂШеЇ¶еєґеПСгАБеИЖеЄГеЉПеТМеЃєйФЩзЪДеЇФзФ®з®ЛеЇПгАВScalaжШѓе§ЪиМГеЉПзЉЦз®Лиѓ≠и®АпЉМжФѓжМБеЗљжХ∞еЉПеТМйЭҐеРСеѓєи±°зЉЦз®ЛпЉМдЄОAkkaзЪДйЫЖжИРйЭЮеЄЄзіІеѓЖгАВ Akka ActorжШѓAkkaзЪДж†ЄењГзїДдїґпЉМеЃГжШѓдЄАзІНеєґеПСеОЯиѓ≠пЉМ...
Actorж®°еЮЛжШѓдЄАзІНеєґеПСиЃ°зЃЧж®°еЮЛпЉМзФ±Carl HewittжПРеЗЇгАВжѓПдЄ™ActorйГљжШѓзЛђзЂЛзЪДеЃЮдљУпЉМжЛ•жЬЙиЗ™еЈ±зЪДзКґжАБеТМйВЃзЃ±пЉМйАЪињЗеЉВж≠•жґИжБѓдЉ†йАТињЫи°МйАЪдњ°гАВActorдєЛйЧізЪДйАЪдњ°дЄНдЉЪйШїе°ЮеПСйАБиАЕпЉМдїОиАМжПРйЂШдЇЖз≥їзїЯзЪДеєґеПСжАІгАВActorж®°еЮЛ襀зФ®дЇОErlangеТМ...
еЃГеЯЇдЇОActorж®°еЮЛпЉМињЩжШѓдЄАзІНеєґеПСиЃ°зЃЧзЪДж¶ВењµпЉМе∞ЖиЃ°зЃЧињЗз®ЛжКљи±°дЄЇељЉж≠§зЛђзЂЛзЪДеЃЮдљУвАФвАФActorпЉМињЩдЇЫеЃЮдљУйАЪињЗдЉ†йАТжґИжБѓињЫи°МйАЪдњ°пЉМиАМдЄНжШѓеЕ±дЇЂзКґжАБпЉМдїОиАМеЗПе∞СдЇЖзЂЮжАБжЭ°дїґеТМж≠їйФБзЪДеПѓиГљжАІгАВ еЬ®AkkaдЄ≠пЉМжѓПдЄ™ActorйГљжЬЙиЗ™еЈ±зЪДйВЃзЃ±пЉМ...
"Actor-CriticеОЯзРЖ+PPOзЃЧж≥ХжО®еѓЉ" Actor-Critic еОЯзРЖжШѓеЉЇеМЦе≠¶дє†дЄ≠зЪДдЄАзІНйЗНи¶БжЦєж≥ХпЉМдЄїи¶БзФ®дЇОиІ£еЖ≥ Sequential Decision Making йЧЃйҐШгАВиѓ•жЦєж≥ХзїУеРИдЇЖ Actor зљСзїЬеТМ Critic зљСзїЬпЉМActor зљСзїЬиіЯиі£йАЙжЛ©еК®дљЬпЉМиАМ Critic зљСзїЬ...
AkkaзЪДж†ЄењГзїДдїґдєЛдЄАе∞±жШѓActorз≥їзїЯпЉМињЩжШѓдЄАдЄ™иЃЊиЃ°ж®°еЉПпЉМзФ®дЇОе§ДзРЖеєґеПСеТМеєґи°МиЃ°зЃЧгАВеЬ®AkkaдЄ≠пЉМActorsйАЪињЗжґИжБѓдЉ†йАТињЫи°МйАЪдњ°пЉМиАМйЭЮеЕ±дЇЂзКґжАБпЉМињЩзІНж®°еЮЛжЮБе§ІеЬ∞зЃАеМЦдЇЖе§ЪзЇњз®ЛзЉЦз®ЛдЄ≠зЪДеРМж≠•йЧЃйҐШгАВ`akka-actor-1.0-RC2.jar`жШѓињЩ...
9. **C++зЪДеєґеПСжФѓжМБ**пЉЪC++11еПКдї•еРОзЪДзЙИжЬђжПРдЊЫдЇЖзЇњз®ЛеЇУ `<thread>`пЉМеМЕжЛђstd::threadгАБstd::mutexгАБstd::condition_variableз≠ЙпЉМдљњеЊЧC++з®ЛеЇПеСШдєЯиГљжЦєдЊњеЬ∞ињЫи°МеєґеПСзЉЦз®ЛгАВ 10. **еєґи°МзЃЧж≥Х**пЉЪеЬ®еєґеПСзЉЦз®ЛдЄ≠пЉМеИ©зФ®еєґи°М...
Goиѓ≠и®АдљЬдЄЇдЄАйЧ®зО∞дї£зЉЦз®Лиѓ≠и®АпЉМеЕґиЃЊиЃ°дєЛеИЭе∞±иАГиЩСеИ∞дЇЖеєґеПСжАІгАВGoзЪДеєґеПСж®°еЮЛйЭЮеЄЄзЛђзЙєпЉМеЃГеЯЇдЇОдЄАзІНзІ∞дЄЇвАЬgoroutineвАЭзЪДиљїйЗПзЇІзЇњз®ЛгАВ GoroutineжШѓGoиѓ≠и®АзЪДеєґеПСж†ЄењГпЉМз±їдЉЉдЇОз≥їзїЯзЇњз®ЛпЉМдљЖжШѓеЕґеРѓеК®еТМи∞ГеЇ¶зЪДжИРжЬђжЫідљОгАВжѓПдЄ™...