
原文地址:http://blog.csdn.net/historyasamirror/article/details/5778378
当你发现自己最受欢迎的一篇blog其实大错特错时,这绝对不是一件让人愉悦的事。
《 IO - 同步,异步,阻塞,非阻塞 》是我在开始学习epoll和libevent的时候写的,主要的思路来自于文中的那篇link 。写完之后发现很多人都很喜欢,我还是非常开心的,也说明这个问题确实困扰了很多人。随着学习的深入,渐渐的感觉原来的理解有些偏差,但是还是没引起自己的重视,觉着都是一些小错误,无伤大雅。直到有位博友问了一个问题,我重新查阅了一些更权威的资料,才发现原来的文章中有很大的理论错误。我不知道有多少人已经看过这篇blog并受到了我的误导,鄙人在此表示抱歉。俺以后写技术blog会更加严谨的。
一度想把原文删了,最后还是没舍得。毕竟每篇blog都花费了不少心血,另外放在那里也可以引以为戒。所以这里新补一篇。算是亡羊补牢吧。
言归正传。
同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别?这个问题其实不同的人给出的答案都可能不同,比如wiki,就认为asynchronous IO和non-blocking IO是一个东西。这其实是因为不同的人的知识背景不同,并且在讨论这个问题的时候上下文(context)也不相同。所以,为了更好的回答这个问题,我先限定一下本文的上下文。
本文讨论的背景是Linux环境下的network IO。
本文最重要的参考文献是Richard Stevens的“UNIX® Network Programming Volume 1, Third Edition: The Sockets Networking ”,6.2节“I/O Models ”,Stevens在这节中详细说明了各种IO的特点和区别,如果英文够好的话,推荐直接阅读。Stevens的文风是有名的深入浅出,所以不用担心看不懂。本文中的流程图也是截取自参考文献。
Stevens在文章中一共比较了五种IO Model:
blocking IO
nonblocking IO
IO multiplexing
signal driven IO
asynchronous IO
由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。
再说一下IO发生时涉及的对象和步骤。
对于一个network IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
1 等待数据准备 (Waiting for the data to be ready)
2 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
记住这两点很重要,因为这些IO Model的区别就是在两个阶段上各有不同的情况。
blocking IO
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
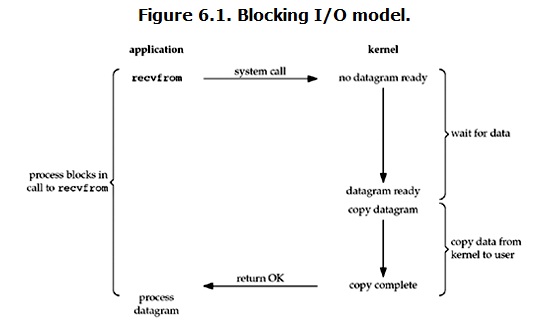
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
non-blocking IO
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
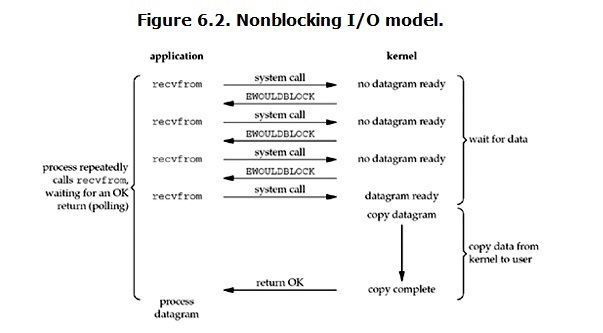
从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,用户进程其实是需要不断的主动询问kernel数据好了没有。
IO multiplexing
IO multiplexing这个词可能有点陌生,但是如果我说select,epoll,大概就都能明白了。有些地方也称这种IO方式为event driven IO。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
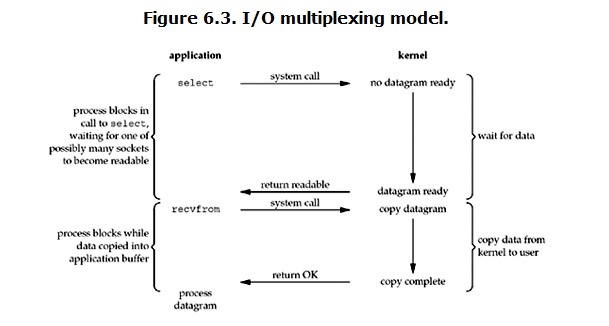
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上,还更差一些。因为这里需要使用两个system call (select 和 recvfrom),而blocking IO只调用了一个system call (recvfrom)。但是,用select的优势在于它可以同时处理多个connection。(多说一句。所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)
在IO multiplexing Model中,实际中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
Asynchronous I/O
linux下的asynchronous IO其实用得很少。先看一下它的流程:
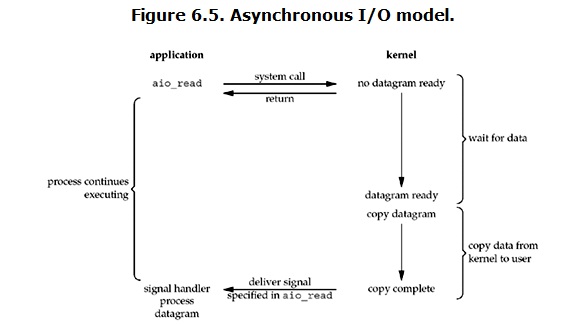
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
到目前为止,已经将四个IO Model都介绍完了。现在回过头来回答最初的那几个问题:blocking和non-blocking的区别在哪,synchronous IO和asynchronous IO的区别在哪。
先回答最简单的这个:blocking vs non-blocking。前面的介绍中其实已经很明确的说明了这两者的区别。调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。Stevens给出的定义(其实是POSIX的定义)是这样子的:
A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
An asynchronous I/O operation does not cause the requesting process to be blocked;
两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。有人可能会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。non-blocking IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。但是,当kernel中数据准备好的时候,recvfrom会将数据从kernel拷贝到用户内存中,这个时候进程是被block了,在这段时间内,进程是被block的。而asynchronous IO则不一样,当进程发起IO 操作之后,就直接返回再也不理睬了,直到kernel发送一个信号,告诉进程说IO完成。在这整个过程中,进程完全没有被block。
各个IO Model的比较如图所示:

经过上面的介绍,会发现non-blocking IO和asynchronous IO的区别还是很明显的。在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
最后,再举几个不是很恰当的例子来说明这四个IO Model:
有A,B,C,D四个人在钓鱼:
A用的是最老式的鱼竿,所以呢,得一直守着,等到鱼上钩了再拉杆;
B的鱼竿有个功能,能够显示是否有鱼上钩,所以呢,B就和旁边的MM聊天,隔会再看看有没有鱼上钩,有的话就迅速拉杆;
C用的鱼竿和B差不多,但他想了一个好办法,就是同时放好几根鱼竿,然后守在旁边,一旦有显示说鱼上钩了,它就将对应的鱼竿拉起来;
D是个有钱人,干脆雇了一个人帮他钓鱼,一旦那个人把鱼钓上来了,就给D发个短信。



相关推荐
同步异步阻塞非阻塞 IO 模型 在 Linux 环境下的网络 IO 中,有五种基本的 IO 模型:阻塞 IO、非阻塞 IO、IO 多路复用、信号驱动 IO 和异步 IO。其中,信号驱动 IO 不常用,因此主要介绍其余四种 IO 模型。 1. 阻塞...
在软件开发领域,尤其是在涉及输入输出(IO)操作时,理解同步与异步、阻塞与非阻塞的概念是非常重要的。这些概念对于设计和实现高效的程序至关重要,尤其是在高并发和分布式系统中。 一、同步与异步 同步和异步是...
根据I/O操作的不同特性,可以将其分为四大类:同步阻塞IO、同步非阻塞IO、异步阻塞IO以及异步非阻塞IO。本文将详细介绍这四种不同的I/O模型,帮助读者理解它们之间的差异及应用场景。 #### 二、同步阻塞IO 同步阻塞...
这里我们将深入探讨同步IO、异步IO、阻塞IO和非阻塞IO的概念,理解它们的工作原理以及在实际应用中的差异。 1. 同步IO与异步IO: - **同步IO**:在同步模式下,应用程序执行I/O操作时会等待操作完成。这意味着程序...
同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别?这个问题其实不同的人给出的答案都可能不同,比如wiki,就认为asynchronous IO和non...
### 同步、异步、阻塞、非阻塞的区别详解 #### 一、同步与异步 **同步**和**异步**是计算机编程中非常重要的概念,尤其是在多线程编程、网络通信以及操作系统中有着广泛的应用。这两个概念主要涉及的是**消息的...
在本文中,我们将讨论基于系统底层通信技术Socket 的JAVA IO同步和异步操作,包括阻塞(Blocking)和非阻塞(Non-Blocking)IO 操作。 同步(Synchronous)IO 同步IO 是指应用程序在执行IO 操作时,需要等待IO ...
在IT领域,特别是网络编程中,我们经常遇到“同步”、“异步”、“阻塞”和“非阻塞”这些概念。这些术语是理解和优化应用程序性能的关键,特别是涉及到客户端(C端)与服务器(S端)之间的通信时。 首先,让我们...
Java阻塞IO与非阻塞IO - OPEN 开发经验库
commons-io-1.1.jarcommons-io-1.1.jarcommons-io-1.1.jarcommons-io-1.1.jarcommons-io-1.1.jarcommons-io-1.1.jar
同步异步,阻塞非阻塞,I/O学习总结的思维导图,需要结合Richard Stevens的书来学习
Socket编程中的阻塞与非阻塞、同步与异步是两个独立的概念,它们涉及的是不同层面的操作机制。这里我们将详细探讨这两个概念以及I/O模型。 首先,同步与异步是客户端(C端)调用服务端(S端)时的行为模式。同步...
-下载后解压zip包,将commons-fileupload-1.1.1.jar,和commons-io-1.2.jar(这里我们用的是更新的版本,但是用法是一样的)复制到tomcat的webapps\你的webapp\WEB-INF\lib\下,如果目录不存在请自建目录。 新建一个...
jar包分享,你懂的 com.springsource.org.apache.commons.io-1.4.0.jar
Boost 库中的 ASIO 模块(异步输入/输出)可能被用来处理网络通信,包括非阻塞的 I/O 操作和事件驱动的编程模型,这对于构建高性能的服务器非常重要。 在这个压缩包中,"socket.io-server-cpp" 可能包含以下部分: ...
draw.io 是一个强大简洁的在线的绘图网站,支持流程图,UML图,架构图,...支持Github,Google Drive, One drive等网盘同步,并且永久免费。如果觉得使用Web版不方便,draw.io 也提供了多平台的离线桌面版可供下载。
commons-io-1.3.1.jar
基于java的开发源码-异步IO框架 Cindy.zip 基于java的开发源码-异步IO框架 Cindy.zip 基于java的开发源码-异步IO框架 Cindy.zip 基于java的开发源码-异步IO框架 Cindy.zip 基于java的开发源码-异步IO框架 Cindy.zip ...
commons-io-2.5.jar 是ava IO的增强版,功能很强大。里面封装了很多实用方便的函数,文件操作、目录操作的。
JAVA连接FTP服务器,并上传/下载文件的,使用commons-net包实现ftp服务器的访问,commons-net包封装了一些常见的网络包:ftp,smtp,pop3等..相关包:commons-net-1.4.1.jar ; commons-io-1.4.jar;jakarta-oro-2.0.8.jar