
function change(num){
var str = num.toString().replace(/(\d)(\d{3})(?=(?:(\d{3}))*(?!\d))/g, function($0, $1 , $2 , $3) {
console.log('$0 = ' + $0);
console.log('$1 = ' + $1);
console.log('$2 = ' + $2);
console.log('$3 = ' + $3);
if($3){
return $1 + "," + $2 +",";
}
return $1 + "," + $2 ;
});
return str;
}
change(1512341234)
"1,512,341,234"
语法:
|
字符 |
描述 |
示例 |
|
(pattern) |
匹配pattern并捕获结果,自动设置组号。 |
(abc)+d 匹配abcd或者abcabcd |
|
(?<name>pattern) 或 (?'name'pattern) |
匹配pattern并捕获结果,设置name为组名。 |
|
|
\num |
对捕获组的反向引用。其中 num 是一个正整数。 |
(\w)(\w)\2\1 匹配abba |
|
\k< name > 或 \k' name ' |
对命名捕获组的反向引用。其中 name 是捕获组名。 |
(?<group>\w)abc\k<group> 匹配xabcx |
例如:
(\d{4})-(\d{2}-(\d{2}))
1 1 2 3 32
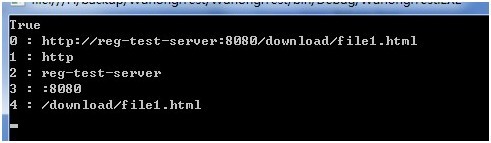
以下是用程序处理捕获组的示例,对一个Url地址进行解析,并显示所有捕获组。
可以看到按顺序设置的捕获组号。
Regex.Match方法
using System.Text.RegularExpressions;
namespace Wuhong.Test
{
class Program
{
static void Main(string[] args)
{
//目标字符串
string source = "http://reg-test-server:8080/download/file1.html# ";
//正则式
string regex = @"(\w+):\/\/([^/:]+)(:\d+)?([^# :]*)";
Regex regUrl = new Regex(regex);
//匹配正则表达式
Match m = regUrl.Match(source);
Console.WriteLine(m.Success);
if (m.Success)
{
//捕获组存放在Match.Groups集合中,索引值从1开始,索引0处为匹配的整个字符串值
//按“组号 : 捕获内容”的格式显示
for (int i = 0; i < m.Groups.Count; i++)
{
Console.WriteLine(string.Format("{0} : {1}", i, m.Groups[i]));
}
}
Console.ReadLine();
}
}
}
例如:
(\d{4})-(?<date>\d{2}-(\d{2}))
1 1 3 2 23
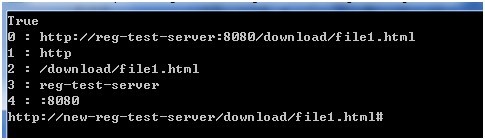
下面在程序中处理命名捕获组,显示混合规则生成的组号,并利用捕获组的内容对源字符串进行替换。
可以看到先对普通捕获组进行编号,再对命名捕获组编号。
Regex.Replace方法
using System.Text.RegularExpressions;
namespace Wuhong.Test
{
class Program
{
static void Main(string[] args)
{
//目标字符串
string source = "http://reg-test-server:8080/download/file1.html# ";
//正则式,对其中两个分组命名
string regex = @"(\w+):\/\/(?<server>[^/:]+)(?<port>:\d+)?([^# :]*)";
Regex regUrl = new Regex(regex);
//匹配正则表达式
Match m = regUrl.Match(source);
Console.WriteLine(m.Success);
if (m.Success)
{
//捕获组存放在Match.Groups集合中,索引值从1开始,索引0处为匹配的整个字符串值
//按“组号 : 捕获内容”的格式显示
for (int i = 0; i < m.Groups.Count; i++)
{
Console.WriteLine(string.Format("{0} : {1}", i, m.Groups[i]));
}
}
//替换字符串
//“$组号”引用捕获组的内容。
//需要特别注意的是“$组号”后不能跟数字形式的字符串,如果出现此情况,需要使用命名捕获组,引用格式“${组名}”
string replacement = string.Format("$1://{0}{1}$2", "new-reg-test-server", "");
string result = regUrl.Replace(source, replacement);
Console.WriteLine(result);
Console.ReadLine();
}
}
}
非捕获组
语法:
|
字符 |
描述 |
示例 |
|
(?:pattern) |
匹配pattern,但不捕获匹配结果。 |
'industr(?:y|ies) 匹配'industry'或'industries'。 |
|
(?=pattern) |
零宽度正向预查,不捕获匹配结果。 |
'Windows (?=95|98|NT|2000)' 匹配 "Windows2000" 中的 "Windows" 不匹配 "Windows3.1" 中的 "Windows"。 |
|
(?!pattern) |
零宽度负向预查,不捕获匹配结果。 |
'Windows (?!95|98|NT|2000)' 匹配 "Windows3.1" 中的 "Windows" 不匹配 "Windows2000" 中的 "Windows"。 |
|
(?<=pattern) |
零宽度正向回查,不捕获匹配结果。 |
'2000 (?<=Office|Word|Excel)' 匹配 " Office2000" 中的 "2000" 不匹配 "Windows2000" 中的 "2000"。 |
|
(?<!pattern) |
零宽度负向回查,不捕获匹配结果。 |
'2000 (?<!Office|Word|Excel)' 匹配 " Windows2000" 中的 "2000" 不匹配 " Office2000" 中的 "2000"。 |
非捕获组只匹配结果,但不捕获结果,也不会分配组号,当然也不能在表达式和程序中做进一步处理。
首先(?:pattern)与(pattern)不同之处只是在于不捕获结果。
接下来的四个非捕获组用于匹配pattern(或者不匹配pattern)位置之前(或之后)的内容。匹配的结果不包括pattern。
例如:
(?<=<(\w+)>).*(?=<\/\1>)匹配不包含属性的简单HTML标签内的内容。如:<div>hello</div>之中的hello,匹配结果不包括前缀<div>和后缀</div>。
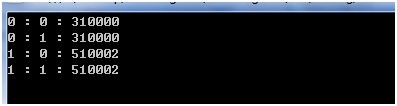
下面是程序中非捕获组的示例,用来提取邮编。
可以看到反向回查和反向预查都没有被捕获。
Regex.Matches方法
using System.Text.RegularExpressions;
namespace Wuhong.Test
{
class Program
{
static void Main(string[] args)
{
//目标字符串
string source = "有6组数字:010001,100,21000,310000,4100011,510002,把邮编挑出来。";
//正则式
string regex = @"(?<!\d)([1-9]\d{5})(?!\d)";
Regex regUrl = new Regex(regex);
//获取所有匹配
MatchCollection mList = regUrl.Matches(source);
for (int j = 0; j < mList.Count; j++)
{
//显示每个分组,可以看到每个分组都只有组号为1的项,反向回查和反向预查没有被捕获
for (int i = 0; i < mList[j].Groups.Count; i++)
{
Console.WriteLine(string.Format("{0} : {1} : {2}", j, i, mList[j].Groups[i]));
}
}
Console.ReadLine();
}
}
}
注释
语法:
|
字符 |
描述 |
示例 |
|
(?#comment) |
comment是注释,不对正则表达式的处理产生任何影响 |
2[0-4]\d(?#200-249)|25[0-5](?#250-255)|1?\d\d?(?#0-199) 匹配0-255的整数 |



相关推荐
感觉JDK这块不好理解,写了几个例子。求拍求回复。
5. **捕获组**:提取匹配的子串,特别是对于包含括号的正则表达式,可以获取多个匹配部分。 6. **修饰符**:如全局匹配(g)使匹配不局限于第一个出现的位置,忽略大小写(i)等。 “pbregexp”组件可能提供了相应...
正则表达式的书写方法有很多技巧,包括使用空白字符忽略和注释、使用非捕获组和命名捕获组以及正则表达式的优化方法。通过这些技巧,可以编写出既高效又准确的正则表达式。 Web开发中,正则表达式被用于验证表单...
在VB.NET中,正则表达式(Regular Expression)是一种强大的文本处理工具,它允许程序员通过模式匹配来处理字符串。这个“vb正则表达式实例”很可能是为了帮助开发者测试和理解正则表达式的工作原理而设计的一个应用...
- **分组与引用**:使用圆括号`()`来定义一个捕获组,并可以通过`\1`、`\2`等引用之前捕获的组。 #### 正则表达式在SQL中的应用 在数据库查询中使用正则表达式可以显著提高查询的灵活性和效率。具体应用场景包括但...
正则表达式(Deelx版)是一种强大的文本处理工具,它允许程序员和用户通过预定义的模式来匹配、查找、替换或者分析字符串。Deelx版是专门为提高正则表达式性能和功能而设计的一个支持库,适用于各种编程语言和应用场景...
001_正则表达式初体验.wmv ...020_正则表达式非捕获分组之零宽断言.wmv 021_正则表达式非捕获分组之零宽断言2.wmv 022_正则表达式非捕获分组之负向零宽断言.wmv 023_正则表达式之贪婪与懒惰.wmv 024_正则表达式实例应用
正则表达式是一种强大的文本处理工具,用于在字符串中进行模式匹配和搜索。在C#编程语言中,正则表达式被广泛应用于数据验证、文本提取、格式转换等多个场景。本项目提供了一个C#编写的正则表达式测试工具,包含完整...
1. **语法兼容性**:如描述所述,PCRE库的正则表达式语法与Perl语言高度兼容,这意味着开发者可以利用Perl中广泛使用的正则表达式语法,如贪婪和非贪婪量词、分支选择、反向引用等。 2. **Unicode支持**:PCRE库...
《Delphi 2010正则表达式插件详解》 在编程世界中,正则表达式(Regular Expression)是一种强大的文本处理工具,能够帮助开发者高效地进行字符串的匹配、查找、替换等操作。在Delphi 2010这个经典的集成开发环境中...
1. **非捕获组**:通过添加问号(?)到分组后,可以使该分组不保存匹配结果,仅用于模式匹配。 2. **条件表达式**:允许根据前面的模式是否匹配来决定是否应用后续的模式。 3. **重复结构**:如“x{m,n}”表示匹配x...
"中级(神奇的咒语)"则引入了更高级的概念,如反向引用(用于匹配与前面捕获组相同的文本)、非捕获组(不影响整体的括号分组)以及正向预查(匹配某个位置后面紧跟的特定模式)。这些技巧能帮助解决更为复杂的数据...
正则表达式是一种强大的文本处理工具,用于在字符串中进行模式匹配和搜索替换操作。C#作为.NET框架的一部分,提供了全面支持正则表达式的类库,使得开发人员能够方便地利用正则表达式进行复杂的文本处理任务。在这个...
### 正则表达式的应用与理解 在计算机编程与数据处理领域中,正则表达式是一种非常强大的文本匹配工具。本文将围绕一个特定的正则表达式 `/^([A-Za-z0-9])+$/` 展开讨论,该表达式主要用于验证输入字符串是否仅包含...
Java正则表达式匹配工具是IT领域中一种强大的文本处理工具,它利用正则表达式(Regular Expression)的规则来查找、替换或者提取文本中的特定模式。正则表达式是一种特殊的字符序列,能够帮助程序员或者用户高效地...
本文将详细介绍"正则表达式调试工具V3.0 绿色免费版"的特点及其在软件开发中的应用。 该调试工具界面简洁,旨在为开发者提供一个友好的环境来调试他们的正则表达式。它的主要功能包括: 1. **模式测试**:用户可以...
6. **取子匹配文本**:除了整个匹配外,正则表达式可能还包含捕获组,这些是用括号定义的子模式。`取子匹配文本`可以获取这些子模式的文本,这对于提取特定部分的文本非常有用。 7. **取子匹配数量**:这个方法返回...
- 利用工具提供的功能,如捕获组、模式修饰符等,优化正则表达式。 - 检查正则表达式的性能,避免过度复杂的模式导致效率降低。 在实际开发中,熟练掌握Qt的QRegExp类和正则表达式语法,能大大提高处理文本数据的...