
首先本地将kafka的docker容器镜像下载到本地并运行:
docker search kafka
docker pull spotify/kafka
docker run --name kafka3 spotify/kafka
docker ps命令,查看tcp端口号:

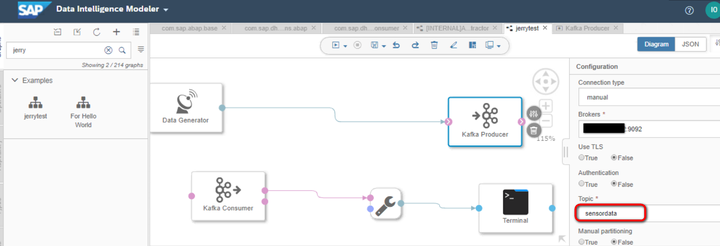
新建一个graph,使用典型的生产者-消费者模型:将Data Generator生成的数据交给kafka Producer operator;
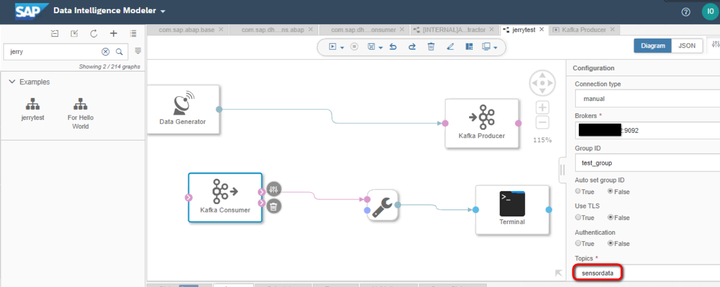
而Kafka Consumer从kafka producer里读取出data Generator生成的数据,通过ToString converter,输出到Terminal Operator上。

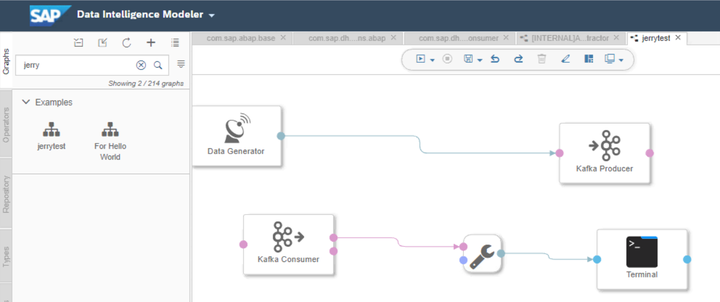
kafka producer和consumer使用的broker和topic必须一致:
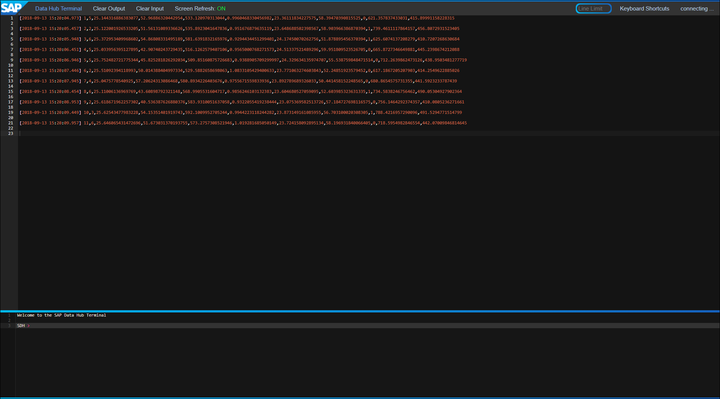
运行graph,可以看到
要获取更多Jerry的原创文章,请关注公众号"汪子熙":



相关推荐
Pentaho Kafka Producer是一款用于Pentaho Data Integration(Kettle)平台的插件,它允许用户在数据集成过程中将数据流发布到Apache Kafka消息队列。Kafka是一个分布式流处理平台,广泛应用于实时数据管道和流应用...
通过对Kafka Producer发送机制进行优化,特别是在面对Broker故障时的消息发送策略调整,可以显著提高系统的稳定性和消息发送的可靠性。通过上述改进方案,即使部分Broker出现故障,也能保证消息能够及时、准确地发送...
consumer = KafkaConsumer('your_topic', bootstrap_servers='localhost:9092', security_protocol='SASL_PLAINTEXT', sasl_mechanism='PLAIN', sasl_plain_username='your_username', sasl_plain_password='your_...
标题中的“spring-kafka-producer-consumer-example”表明这是一个关于Spring Boot应用,它使用了Apache Kafka作为消息中间件,展示了生产者(producer)和消费者(consumer)的实现。描述中的“Simple application ...
总结起来,"pentaho-kafka-consumer.zip"是一个用于Pentaho Kettle的插件,它提供了与Apache Kafka集成的能力,使得用户可以方便地从Kafka中消费数据,并在Pentaho的工作流中进行进一步的数据处理和集成操作。...
Spring Boot 集成 Kafka 可以帮助开发者轻松地在应用程序中实现消息生产和消费功能,利用 Kafka 的高性能和可扩展性。Kafka 是一个分布式流处理平台,它最初由 LinkedIn 开发,后来成为 Apache 软件基金会的顶级项目...
Kafka Producer拦截器和Kafka Streams是Kafka提供的一些强大的工具,可以满足用户对数据处理的需求。但是,在使用这些工具时,需要注意一些重要的细节,如线程安全、错误处理等,以确保系统的稳定运行。
带有Rest URL的Kafka Producer和Consumer API的Spring Boot应用程序 生产者:将数据或消息发送到kafka服务器的应用程序 消息:一小段数据,即kafka的字节数组 使用者:数据的接收者,即从kafka服务器读取数据 Kafka...
在本文中,我们将深入探讨如何使用C++库RdKafka中的`KafkaConsumer`类来消费Apache Kafka消息。RdKafka是一个高效的C/C++ Kafka客户端,它提供了生产者和消费者API,使得与Kafka集群进行交互变得更加简单。在这个...
consumer = KafkaConsumer('my-topic', group_id='my-group', bootstrap_servers=['localhost:9092']) for message in consumer: print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition, ...
标题中的“kettle kafka 消息生产插件”指的是Pentaho Data Integration(通常称为Kettle或PDI)中的一款插件,它允许用户通过Kettle工作流将数据发布到Apache Kafka分布式消息系统。Kafka是一种高效、可扩展且容错...
为了验证和优化Kafka系统的性能,开发者通常需要进行大规模并发数据发送的测试。这时,JMeter,一个开源的性能测试工具,结合其Kafka连接器,就成为了理想的解决方案。本文将详细介绍如何使用JMeter-Kafka连接器来...
通过这个`kafkaConsumerDemo`,你可以了解到Kafka Consumer API的基本使用方式,并且能够根据自己的需求进行定制和扩展。在实际应用中,你可能还需要考虑更多的高级特性,如自动偏移量提交、幂等性消费以及多线程...
在实际操作中,`kafka_hdfs_consumer`可能还会利用Zookeeper进行协调,保证消费的顺序性和一致性,以及使用Hadoop的MapReduce或Spark等框架进行更复杂的批处理和数据分析。整个流程需要考虑到数据量大、实时性高和...
在Kafka中,Producer(生产者)负责将数据流发送到Kafka集群中。生产者的配置参数非常关键,因为它们会直接影响到生产者的行为和性能。以下是根据提供的文件内容整理的Kafka生产者配置参数的知识点: 1. bootstrap....
在这个项目中,`kafka_producer.zip`包含了实现这一功能的所有必要文件:一个配置文件`config.conf`和一个Python脚本`producer.py`。 首先,让我们了解`config.conf`文件的作用。这个配置文件通常包含Kafka生产者...
kafka_client_producer_consumer
kettle7.1版本整合kafka,kafka插件包含生产者、消费者。直接在kettle安装目录plugins下创建steps目录,并解压下载文件到kettle/plugins/steps目录。具体可查看我博文。
KafkaConsumer, String> consumer = new KafkaConsumer(props); consumer.subscribe(Arrays.asList("my-topic")); while (true) { ConsumerRecords, String> records = consumer.poll(Duration.ofMillis(100)); ...