
转自:https://webtide.com/eat-what-you-kill/
A producer consumer pattern for Jetty HTTP/2 with mechanical sympathy
Developing scalable servers in Java now requires careful consideration of mechanical sympathetic issues to achieve both high throughput and low latency. With the introduction of HTTP/2 multiplexed semantics to Jetty, we have taken the opportunity to introduce a new execution strategy based on the eat what you killhunting ethic, which is providing wins over the following: avoiding dispatch latency; running tasks with hot caches; reducing contention and parallel slowdown; reducing memory footprint and queue depth.
The problem
The problem we are trying to solve is the producer consumer pattern, where one process produces tasks that need to be run to be consumed. This is a common pattern with two key examples in the Jetty Server:
- a NIO
Selectorproduces connection IO events that need to be consumed - a multiplexed HTTP/2 connection produces HTTP requests that need to be consumed by calling the Servlet Container
For the purposes of this blog, we will consider the problem in general, with the producer represented by following interface:
The optimisation task that we trying to solve is how to handle potentially many producers, each producing many tasks to run, and how to run the tasks that they produce so that they are consumed in a timely and efficient manner.
Produce Consume
The simplest solution to this pattern is to iteratively produce and consume as follows:
This strategy iteratively produces and consumes tasks in a single thread per Producer:
 It has the advantage of simplicity, but suffers the fundamental flaw of head-of-line blocking (HOL): If one of the tasks blocks or executes slowly (e.g. task C3 above), then subsequent tasks will be held up. This is actually good for a HTTP/1 connection where responses must be produced in the order of request, but is unacceptable for HTTP/2 connections where responses must be able to return in arbitrary order and one slow request cannot hold up other fast ones. It is also unacceptable for the NIO selection use-case as one slow/busy/blocked connection must not prevent other connections from being produced/consumed.
It has the advantage of simplicity, but suffers the fundamental flaw of head-of-line blocking (HOL): If one of the tasks blocks or executes slowly (e.g. task C3 above), then subsequent tasks will be held up. This is actually good for a HTTP/1 connection where responses must be produced in the order of request, but is unacceptable for HTTP/2 connections where responses must be able to return in arbitrary order and one slow request cannot hold up other fast ones. It is also unacceptable for the NIO selection use-case as one slow/busy/blocked connection must not prevent other connections from being produced/consumed.
Produce Execute Consume
To solve the HOL blocking problem, multiple threads must be used so that produced tasks can be executed in parallel and even if one is slow or blocks, the other threads can progress the other tasks. The simplest application of threading is to place every task that is produced onto a queue to be consumed by an Executor:
This strategy could be considered the canonical solution to the producer consumer problem, where producers are separated from consumers by a queue and is at the heart of architectures such as SEDA. This strategy solves well the head of line blocking issue, since all tasks produced can complete independently in different threads (or cached threads):
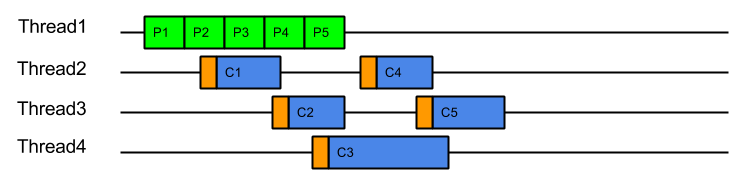
However, while it solves the HOL blocking issue, it introduces a number of other significant issues:
- Tasks are produced by one thread and then consumed by another thread. This means that tasks are consumed on CPU cores with cold caches and that extra CPU time is required (indicated above in orange) while the cache loads the task related data. For example, when producing a HTTP request, the parser will identify the request method, URI and fields, which will be in the CPU’s cache. If the request is consumed by a different thread, then all the request data must be loaded into the new CPU cache. This is an aspect of Parallel Slowdown which Jetty has needed to avoid previously as it can cause a considerable impact on the server throughput.
- Slow consumers may cause an arbitrarily large queue of tasks to build up as the producers may just keep adding to the queue faster than tasks can be consumed. This means that no back pressure is given to the production of tasks and out of memory problems can result. Conversely, if the queue size is limited with a blocking queue, then HOL blocking problems can re-emerge as producers are prevented for queuing tasks that could be executed.
- Every task produced will experience a dispatch latency as it is passed to a new thread to be consumed. While extra latency does not necessarily reduce the throughput of the server, it can represent a reduction in the quality of service. The diagram above shows the total 5 tasks completing sooner than ProduceConsume, but if the server was busy then tasks may need to wait some time in the queue before being allocated a thread.
- Another aspect of parallel slowdown is the contention between related tasks which a single producer may produce. For example a single HTTP/2 connection is likely to produce requests for the same client session, accessing the same user data. If multiple requests from the same connection are executed in parallel on different CPU cores, then they may contend for the same application locks and data and therefore be less efficient. Another way to think about this is that if a 4 core machine is handling 8 connections that each produce 4 requests, then each core will handle 8 requests. If each core can handle 4 requests from each of 2 connections then there will be no contention between cores. However, if each core handles 1 requests from each of 8 connections, then the chances of contention will be high. It is far better for total throughput for a single connections load to not be spread over all the systems cores.
Thus the ProduceExecuteConsume strategy has solved the HOL blocking concern but at the expense of very poor performance on both latency (dispatch times) and execution (cold caches), as well as introducing concerns of contention and back pressure. Many of these additional concerns involve the concept of Mechanical Sympathy, where the underlying mechanical design (i.e. CPU cores and caches) must be considered when designing scalable software.
How Bad Is It?
Pretty Bad! We have written a benchmark project that compares the Produce Consume and Produce Execute Consume strategies (both described above). The Test Connection used simulates a typical HTTP request handling load where the production of the task equates to parsing the request and created the request object and the consumption of the task equates to handling the request and generating a response.
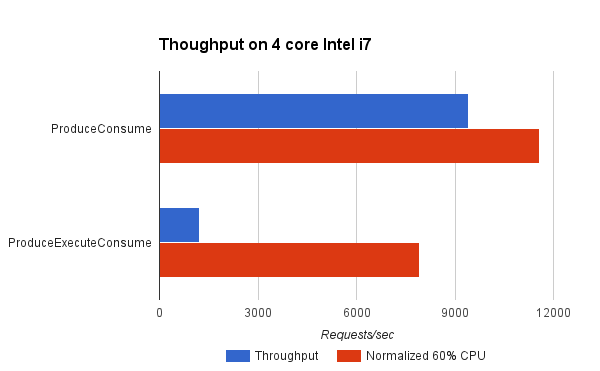
It can be seen that the ProduceConsume strategy achieves almost 8 times the throughput of the ProduceExecuteConsume strategy. However in doing so, the ProduceExecuteConsume strategy is using a lot less CPU (probably because it is idle during the dispatch delays). Yet even when the throughput is normalised to what might be achieved if 60% of the available CPU was used, then this strategy reduces throughput by 30%! This is most probably due to the processing inefficiencies of cold caches and contention between tasks in the ProduceExecuteConsume strategy. This clearly shows that to avoid HOL blocking, the ProduceExecuteConsume strategy is giving up significant throughput when you consider either achieved or theoretical measures.
What Can Be Done?
Disruptor ?
Consideration of the SEDA architecture led to the development of the Disruptor pattern, which self describes as a “High performance alternative to bounded queues for exchanging data between concurrent threads”. This pattern attacks the problem by replacing the queue between producer and consumer with a better data structure that can greatly improve the handing off of tasks between threads by considering the mechanical sympathetic concerns that affect the queue data structure itself.
While replacing the queue with a better mechanism may well greatly improve performance, our analysis was that it in Jetty it was the parallel slowdown of sharing the task data between threads that dominated any issues with the queue mechanism itself. Furthermore, the problem domain of a full SEDA-like architecture, whilst similar to the Jetty use-cases is not similar enough to take advantage of some of the more advanced semantics available with the disruptor.
Even with the most efficient queue replacement, the Jetty use-cases will suffer from some dispatch latency and parallel slow down from cold caches and contending related tasks.
Work Stealing ?
Another technique for avoiding parallel slowdown is a Work Stealing scheduling strategy:
In a work stealing scheduler, each processor in a computer system has a queue of work items to perform…. New items are initially put on the queue of the processor executing the work item. When a processor runs out of work, it looks at the queues of other processors and “steals” their work items.
This concept initially looked very promising as it appear that it would allow related tasks to stay on the same CPU core and avoid the parallel slowdown issues described above.
It would require the single task queue to be broken up in to multiple queues, but there are suitable candidates for finer granularity queues available (e.g. the connection).
Unfortunately, several efforts to implement it within Jetty failed to find an elegant solution because it is not generally possible to stick a queue or thread to a processor and the interaction of task queues vs thread pool queues added an additional level of complexity. More over, because the approach still involves queues it does not solve the back pressure issues and the execution of tasks in a queue may flush the cache between production and consumption.
However consideration of the principles of Work Stealing inspired the creation of a new scheduling strategy that attempt to achieve the same result but without any queues.
Eat What You Kill!
The Eat What You Kill strategy (prosaically named ExecuteProduceConsume for the production version) has been designed to get the best of both worlds of the strategies presented above. It is nick named after the hunting movement that says a hunter should only kill an animal they intend to eat. Applied to the producer consumer problem this policy says that a thread must only produce (kill) a task if it intends to consume (eat) it immediately. However, unlike the ProduceConsume strategy that adheres to this principle, ExecuteProduceConsume still performs dispatches, but only to recruit new threads (hunters) to produce and consume more tasks while the current thread is busy eating !
This strategy can still operate like ProduceConsume using a loop to produce and consume tasks with a hot cache. A dispatch is performed to recruit a new thread to produce and consume, but on a busy server where the delay in dispatching a new thread may be large, the extra thread may arrive after all the work is done. Thus the extreme case on a busy server is that this strategy can behave like ProduceConsume with an extra noop dispatch:

Serial queueless execution like this is optimal for a servers throughput: There is not queue of produced tasks wasting memory, as tasks are only produced when needed; tasks are always consumed with hot caches immediately after production. Ideally each core and/or thread in a server is serially executing related tasks in this pattern… unless of course one tasks takes too long to execute and we need to avoid HOL blocking.
EatWhatYouKill avoids HOL blocking as it is able to recruit additional threads to iterate on production and consumption if the server is less busy and the dispatch delay is less than the time needed to consume a task. In such cases, a new threads will be recruited to assist with producing and consuming, but each thread will consume what they produced using a hot cache and tasks can complete out of order:
 On a mostly idle server, the dispatch delay may always be less than the time to consume a task and thus every task may be produced and consumed in its own dispatched thread:
On a mostly idle server, the dispatch delay may always be less than the time to consume a task and thus every task may be produced and consumed in its own dispatched thread:
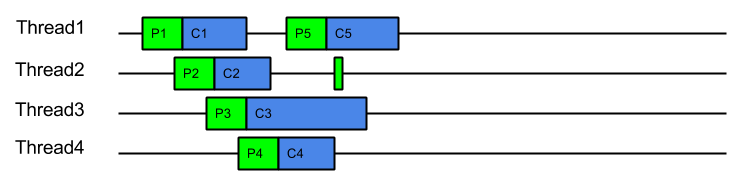 In this idle case there is a dispatch for every task, which is exactly the same dispatch cost of ProduceExecuteConsume. However this is only the worst case dispatch overhead for EatWhatYouKill and only happens on a mostly idle server, which has spare CPU. Even with the worst case dispatch case, EatWahtYouKill still has the advantage of always consuming with a hot cache.
In this idle case there is a dispatch for every task, which is exactly the same dispatch cost of ProduceExecuteConsume. However this is only the worst case dispatch overhead for EatWhatYouKill and only happens on a mostly idle server, which has spare CPU. Even with the worst case dispatch case, EatWahtYouKill still has the advantage of always consuming with a hot cache.
An alternate way to visualise this strategy is to consider it like ProduceConsume, but that it dispatches extra threads to work steal production and consumption. These work stealing threads will only manage to steal work if the server is has spare capacity and the consumption of a task is risking HOL blocking.
This strategy has many benefits:
- A hot cache is always used to consume a produced task.
- Good back pressure is achieved by making production contingent on either another thread being available or prior consumption being completed.
- There will only ever be one outstanding dispatch to the thread pool per producer which reduces contention on the thread pool queue.
- Unlike ProduceExecuteConsume, which always incurs the cost of a dispatch for every task produced, ExecuteProduceConsume will only dispatch additional threads if the time to consume exceeds the time to dispatch.
- On systems where the dispatch delay is of the same order of magnitude as consuming a task (which is likely as the dispatch delay is often comprised of the wait for previous tasks to complete), then this strategy is self balancing and will find an optimal number of threads.
- While contention between related tasks can still occur, it will be less of a problem on busy servers because related task will tend to be consumed iteratively, unless one of them blocks or executes slowly.
How Good Is It ?
Indications from the benchmarks is that it is very good !
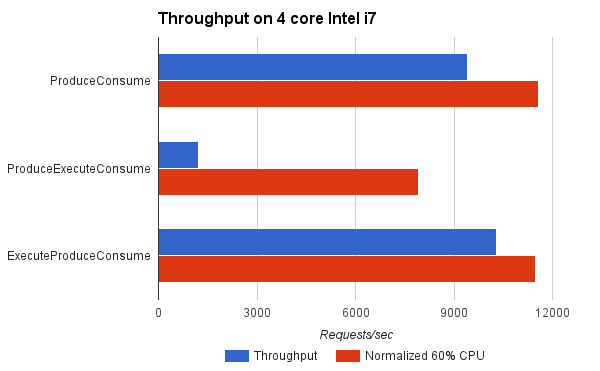
For the benchmark, ExecuteProduceConsume achieved better throughput than ProduceConsume because it was able to use more CPU cores when appropriate. When normalised for CPU load, it achieved near identical results to ProduceConsume, which is to be expected since both consume tasks with hot caches and ExecuteProduceConsume only incurs in dispatch costs when they are productive.
This indicates that you can kill your cake and eat it too! The same efficiency of ProduceConsume can be achieved with the same HOL blocking prevention of ProduceExecuteConsume.
Conclusion
The EatWhatYouKill (aka ExecuteProduceConsume) strategy has been integrated into Jetty-9.3 for both NIO selection and HTTP/2 request handling. This makes it possible for the following sequence of events to occur within a single thread of execution:
- A selector thread T1 wakes up because it has detected IO activity.
- (T1) An ExecuteProduceConsume strategy processes the selected keys set.
- (T1) An EndPoint with input pending is produced from the selected keys set.
- Another thread T2 is dispatched to continue producing from the selected keys set.
- (T1) The EndPoint with input pending is consumed by running the HTTP/2 connection associated with it.
- (T1) An ExecuteProduceConsume strategy processes the I/O for the HTTP/2 connection.
- (T1) A HTTP/2 frame is produced by the HTTP/2 connection.
- Another thread T3 is dispatched to continue producing HTTP/2 frames from the HTTP/2 connection.
- (T1) The frame is consumed by possibly invoking the application to produce a response.
- (T1) The thread returns from the application and attempts to produce more frames from the HTTP/2 connection, if there is I/O left to process.
- (T1) The thread returns from HTTP/2 connection I/O processing and attempts to produce more EndPoints from the selected keys set, if there is any left.
This allows a single thread with hot cache to handle a request from I/O selection, through frame parsing to response generation with no queues or dispatch delays. This offers maximum efficiency of handling while avoiding the unacceptable HOL blocking.
Early indications are that Jetty-9.3 is indeed demonstrating a significant step forward in both low latency and high throughput. This site has been running on EWYK Jetty-9.3 for some months. We are confident that with this new execution strategy, Jetty will provide the most performant and scalable HTTP/2 implementation available in Java.



相关推荐
Lesson 11 What do they eat练习题及答案.doc
这篇文档是关于外研版小学英语六年级下册Module 1 Unit 2 "What do you want to eat"的教案,旨在帮助教师进行有效的课堂教学。教案详细规划了教学目标、教学重点与难点,以及一系列的教学步骤。 一、教学目标 1. ...
这篇课件是针对小学六年级下册外研版英语教材Module 1 Unit 2 "What do you want to eat"的内容,旨在帮助学生学习如何在英语环境中进行简单的餐饮点餐对话。这一单元的核心教学目标是让学生掌握用英语点餐和询问...
- 你应该多吃蔬菜来保持健康:You should eat more vegetables to keep healthy. - 每天做一些运动对你有好处:It's good for you to do some exercise every day. 通过本课的学习,学生们不仅能够掌握新的单词、...
- “What do you want to eat?”(你想吃什么?) - “I want a hamburger, please.”(我想吃一个汉堡包。) - “What do you want to drink?”(你想喝什么?) - 学习并演唱歌曲:“What do you want to eat?...
六年级英语下册 Module 1 Unit 2 What do you want to eat课件2 外研版(一起)
六年级英语下册 Module 1 Unit 2 What do you want to eat课件1 外研版(一起)
本节课的主题是“ What Would You Like to Eat ?”,选自EEC小学英语五年级下册Lesson1,是一堂句型练习课。课程主要围绕如何询问和表达饮食喜好,旨在培养学生的英语口语能力和日常交流能力。 【教材分析】 教材以...
1. "What would you like to eat?" 这句话询问对方想要吃什么,是日常点餐时常见的问句; 2. "What kind of noodles would you like?" 是更具体地询问面条的种类,例如意大利面、拉面等; 3. "We’d like two bowls ...
教师招聘、教师资格证面试小学英语《Whatwouldyouliketoeat?》试讲稿.pdf
解决“不知道吃什么”的问题的软件通常属于生活辅助或健康管理类应用。这类软件通过不同的方式帮助用户决定餐食选择,增加饮食的多样性,同时可能还会提供营养信息,帮助用户做出更健康的饮食决策。...
解决“不知道吃什么”的问题的软件通常属于生活辅助或健康管理类应用。这类软件通过不同的方式帮助用户决定餐食选择,增加饮食的多样性,同时可能还会提供营养信息,帮助用户做出更健康的饮食决策。...
A small program that chooses what to eat today is developed using the development tools of Choujiang.
- **Let’s talk** 包含两个部分,一是Sarah家庭用餐场景,展示了"What would you like to eat?"和"What would you like to drink?"的对话应用;二是Ask and answer环节,让学生实践问答,巩固所学句型。 5. **...
”以及答语“I’m…We are…”本课的知识目标是让学生能听懂、会说、认读单词:we,read,eat,draw,和句型“What are you doing?I’m…We are…”。 二、教学目标 1. 知识目标 * 能听懂、会说、认读单词:we,...
这篇文档是针对小学英语教学的一份练习材料,主要围绕Unit 3 "What would you like?" Part A的第一课时设计,旨在提升学生的听力和语言运用能力。这个单元的主题是关于饮食和点餐,涉及的核心词汇包括食物(如...
这篇文档是关于四年级英语教学的一个教案,主题是"What do they eat?",主要涉及冀教版小学四年级上册Unit4 Lesson30的内容。教案详细规划了教学目标、重点难点、教具学具、教学过程以及课后反思,旨在帮助学生掌握...
1. **日常饮食表达**:在英语中,描述一日三餐的常见表达是"What do you usually have for breakfast/lunch/supper?"。例如,“I usually have milk and bread for breakfast.” 这里,"have" 表示吃或喝的动作。 2...
例如题目中的 "What would you like to eat?" 和 "What would you like to drink?" 这种句型常用于餐厅点餐或提供服务的情景。 2. **What kind of...?**:这个短语用于询问具体的种类,比如在选择水果或食物时,...
【标题】"What2Eat" 是一个以C语言编写的项目,旨在为用户提供饮食推荐服务。这个项目可能是一个简单的命令行应用或者一个基础的图形用户界面(GUI),它利用算法来帮助用户根据他们的口味、饮食偏好和营养需求来...