在SQLServer 2000环境中,如果要实现交叉表格报表,主要是靠一系列复杂的 SELECT...CASE 语句.
其实现过程请参阅这里T-SQL 交叉报表(行列互换) 交叉查询 旋转查询
在SQLServer 2005中我们可以使用PIVOT关系运算符来实现行列转换.
还是以学生成绩表来举例:
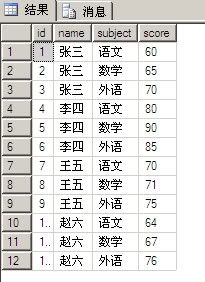
id姓名 科目 成绩
1张三语文60
2张三数学65
3张三外语70
4李四语文80
5李四数学90
6李四外语85
7王五语文70
8王五数学71
9王五外语75
10赵六语文64
11赵六数学67
12赵六外语76
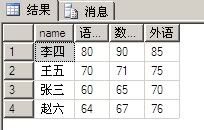
查询后得出:
姓名语文数学外语
李四80 90 85
王五70 71 75
张三60 65 70
赵六64 67 76
--准备数据:
select * from sysobjects where [xtype]='u'
go
if exists(select id from sysobjects where name='studentscore')
drop table studentscore--删除与实验冲突的表
go
create table studentscore--创建实验表
(
[id] int identity(1,1),
[name] nvarchar(20) not null,
subject nvarchar(20) not null,
score int not null
)
go
select * from studentscore
go
--添加实验数据
insert studentscore values ('张三','语文','60');
insert studentscore values ('张三','数学','65');
insert studentscore values ('张三','外语','70');
insert studentscore values ('李四','语文','80');
insert studentscore values ('李四','数学','90');
insert studentscore values ('李四','外语','85');
insert studentscore values ('王五','语文','70');
insert studentscore values ('王五','数学','71');
insert studentscore values ('王五','外语','75');
insert studentscore values ('赵六','语文','64');
insert studentscore values ('赵六','数学','67');
insert studentscore values ('赵六','外语','76');
go
select * from studentscore
go
使用 SELECT...CASE 语句实现代码如下
select [name],
语文=max(case
when subject='语文' then score else 0
end),
数学=max(case
when subject='数学' then score else 0
end),
外语=max(case
when subject='外语' then score else 0
end)
from studentscore
group by [name]
结果:
下面我们使用PIVOT关系运算符来实现行列转换
select [name],[语文] as '语文',[数学] as '数学',[外语] as '外语'
from (select score,subject,[name] from studentscore) as ss
pivot
(
sum(score) for subject in([语文],[数学],[外语])
) as pvt
结果:用较少的代码完成了交叉表格报表
============================
对于这种方法要注意的一点是,我们使用sum()聚合函数,表面上没有指定按什么方式分组,但是自动按照name列分组了.
怎么做到的呢?原来pivot关系运算符会根据前面的对象中的列来自行判断,在这个例子中pivot前面的对象是ss,是个子查询,这个子查询中只有三列,score,subject和[name],但是pivot运算符内部使用了score和subject这两列,那么肯定是对[name]分组.
所以我们得出,pivot运算符的分组规则是,跟随对象中的那些不在pivot运算符内部的列:
为了好理解我们再写一个例子:
--在ss这个子查询中,多加一列id
--那么pivot应该按照name和id进行分组
select[name],[语文]as'语文',[数学]as'数学',[外语]as'外语'
from(selectscore,subject,[name],idfromstudentscore)asss
pivot
(
sum(score)forsubjectin([语文],[数学],[外语])
)aspvt
结果:验证了我们的设想

UNPIVOT关系运算符从字面上来看,就知道它的用途正好和PIVOT相反,下面举例说明:
if exists(select id from sysobjects where name='studentscore')
drop table studentscore--删除与实验冲突的表
go
create table studentscore--创建实验表
(
[id] int identity(1,1),
[name] nvarchar(20) not null,
yuwen int not null,
shuxue int not null,
waiyu int not null
)
go
select * from studentscore
go
--添加实验数据
insert studentscore values ('张三','60','65','70');
insert studentscore values ('李四','80','90','86');
insert studentscore values ('王五','70','71','75');
insert studentscore values ('赵六','64','67','76');
go
select * from studentscore
go
结果:

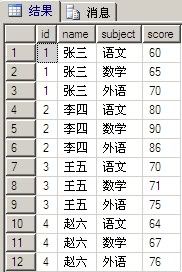
SELECT id, [name],subject, score
FROM
(SELECT id,[name], 语文=yuwen, 数学=shuxue, 外语=waiyu
FROM studentscore) as ss
UNPIVOT
(score FOR subject IN
(语文, 数学, 外语)
)AS unpvt
结果:
分享到:




相关推荐
枢纽表达式PIVOT和UNPIVOT是SQL Server 2005中新增的关系运算符,用于实现行列的旋转。本篇文章将介绍PIVOT和UNPIVOT的简单用法,并提供实例代码。 一、枢纽表达式PIVOT和UNPIVOT的概念 PIVOT和UNPIVOT是SQL ...
Pivot 和 UnPivot 是 SQL Server 2005 中引入的两个语法,用于实现行列转换。 Pivot Pivot 语法的主要作用是将列值旋转为列名,即行转列。其基本语法为: ``` SELECT * FROM table_source PIVOT (聚合函数(value_...
在SQL Server 2005中,...总之,SQL Server 2005引入的PIVOT功能是数据库查询能力的一个显著提升,它使得数据的行列转换更为直观和高效,尤其在处理大量数据的统计分析时,能有效减少编写和维护复杂SQL代码的工作量。
pivot 与 unpivot 函数是SQL05新提供的2个函数 灰常灰常的实用
1. **T-SQL增强**:SQL Server 2005引入了新的T-SQL语言特性,如Cursors的改进、窗口函数、 Common Table Expressions (CTE)、Table Value Parameters 和 PIVOT/UNPIVOT操作等,使得查询编写更为灵活和强大。...
3. **PIVOT和APPLY关系运算符**: PIVOT用于将行转换为列,这对于数据透视和报告非常有用。APPLY运算符则允许将一个表值函数应用到另一个表的每一行,提供了更复杂的联接操作。这些新运算符增加了Transact-SQL的...
本篇文章将深入探讨如何使用聚合函数Pivot和Unpivot来实现这一目标,特别是针对SQL Server数据库。 首先,让我们了解什么是行转列。行转列就是将表格中的某列值变为新的列名,而原本的行数据则对应到这些新列中。举...
《Microsoft SQL Server 2005技术内幕全套(三):T-SQL查询》是一部深入探讨SQL Server 2005数据库管理系统中Transact-SQL(T-SQL)查询技术的专业著作。本部分主要聚焦于如何高效、准确地在SQL Server 2005环境中...
- **日期与时间**: SQL Server 2005引入了`DATE`, `TIME`和`DATETIME2`等数据类型,使得处理日期和时间变得更加精确和高效。 - **可变精度货币**: `MONEY`类型被`DECIMAL`和`NUMERIC`所替代,提供了更高的精度选项。...
SQL Server 2008 中数据透视(PIVOT)和数据逆透视(UNPIVOT)操作是用于转换表数据格式的SQL关系运算符。它们能够将行转换成列或将列转换成行,以便于进行数据分析和报告。 数据透视(PIVOT)操作允许我们把一个表...
除此之外,SQL Server 2005还增强了CTE(公用表表达式)功能,允许使用PIVOT和UNPIVOT运算符,这进一步提升了查询的灵活性和表达能力。CTE提供了一种方式,让开发者能够临时命名一个结果集,并且在查询中引用它。...
SQL Server 2005 支持多种 OLAP 模式,包括 ROLAP(关系型 OLAP)、MOLAP(多维 OLAP)和 HOLAP(混合 OLAP),从而为企业提供了更多的灵活性和选择。 ### 5. KPIs(关键绩效指标)的支持 SQL Server 2005 引入了 ...
总之,SQL Server 2005的`PIVOT`和`UNPIVOT`函数为数据的行列转换提供了强大的工具,使得数据在分析和展示时更具灵活性。在处理聚合记录集时,根据需求选择合适的方法进行旋转,可以有效地满足各种报表和分析场景的...
在SQL Server中,这通常需要使用到PIVOT(行列转换)和UNPIVOT(行列还原)操作来实现。 存储过程允许将创建动态交叉表的逻辑代码集中存储,并可以重复调用,提高了数据操作的灵活性和效率。实现动态交叉表的关键...
在Oracle 11g中引入了两项新功能:`PIVOT` 和 `UNPIVOT`,这两项功能使得在SQL中进行数据的行列转换变得更加简单和直观。这些操作特别适用于报表开发,能够帮助用户快速地将数据按照特定的需求重新组织。 #### 二、...
本文将详细讲解如何在SQL Server 2005中实现这一功能,并提供一个适合初级学者学习的实例。 一、Pivot函数的使用 SQL Server 2005引入了Pivot函数,这是一个强大的工具,专门用于进行行转列的操作。Pivot函数的...
在SQL Server中,可以使用pivot函数或自定义函数来实现交叉查询。 二、交叉查询的实现 在给定的代码中,作者使用了动态SQL语句来实现交叉查询。首先,作者声明了一个变量@sql,并将其设置为一个select语句。然后,...
SQL Server 2005对T-SQL的功能进行了多方面的改进,如优化了TOP子句,引入了CTE(公共表表达式),添加了PIVOT和UNPIVOT操作符,以及新的DDL触发器和TRY-CATCH错误处理结构。 例如,书中可能包含了使用CLR创建存储...
SQL Server 2005是Microsoft推出的一款关系型数据库管理系统,它在数据库管理、数据存储、数据处理等方面具有丰富的功能。对于SQL Server 2005的学习和培训,以下是一些核心知识点: 1. **数据类型增强**: - **...