ķŚ«ķóś
µ¤ÉµĄĘķćÅńö©µłĘńĮæń½Ö’╝īńö©µłĘµŗźµ£ēń¦»Õłå’╝īń¦»ÕłåÕÅ»ĶāĮõ╝ÜÕ£©õĮ┐ńö©Ķ┐ćń©ŗõĖŁķÜŵŚČµø┤µ¢░ŃĆéńÄ░Õ£©Ķ”üõĖ║Ķ»źńĮæń½ÖĶ«ŠĶ«ĪõĖĆń¦Źń«Śµ│Ģ’╝īÕ£©µ»Åµ¼Īńö©µłĘńÖ╗ÕĮĢµŚČµśŠńż║ÕģČÕĮōÕēŹń¦»ÕłåµÄÆÕÉŹŃĆéńö©µłĘµ£ĆÕż¦Ķ¦äµ©ĪõĖ║2õ║┐’╝øń¦»ÕłåõĖ║ķØ×Ķ┤¤µĢ┤µĢ░’╝īõĖöÕ░Åõ║Ä100õĖćŃĆé
PS: µŹ«Ķ»┤Ķ┐Öµś»Ķ┐ģķøĘńÜäõĖĆķüōķØóĶ»Ģķóś’╝īõĖŹĶ┐ćķŚ«ķóśµ£¼Ķ║½Õģʵ£ēÕŠłÕ╝║ńÜäń£¤Õ«×µĆ¦’╝īµēĆõ╗źµ£¼µ¢ćµēōń«Śµīēńģ¦ń£¤Õ«×Õ£║µÖ»µØźĶĆāĶÖæ’╝īĶĆīõĖŹÕ▒ĆķÖÉõ║ÄķØóĶ»ĢķóśńÜäńÉåµā│ńÄ»ÕóāŃĆé
ÕŁśÕé©ń╗ōµ×ä
ķ”¢Õģł’╝īµłæõ╗¼ńö©õĖĆÕ╝Āńö©µłĘń¦»ÕłåĶĪ©user_scoreµØźõ┐ØÕŁśńö©µłĘńÜäń¦»Õłåõ┐Īµü»ŃĆé
ĶĪ©ń╗ōµ×ä’╝Ü
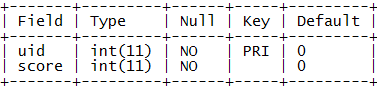
ńż║õŠŗµĢ░µŹ«’╝Ü
õĖŗķØóńÜäń«Śµ│Ģõ╝ÜÕ¤║õ║ÄĶ┐ÖõĖ¬Õ¤║µ£¼ńÜäĶĪ©ń╗ōµ×äµØźĶ┐øĶĪīŃĆé
ń«Śµ│Ģ1’╝Üń«ĆÕŹĢSQLµ¤źĶ»ó
ķ”¢Õģł’╝īµłæõ╗¼ÕŠłÕ«╣µśōµā│Õł░ńö©õĖƵØĪń«ĆÕŹĢńÜäSQLĶ»ŁÕÅźµ¤źĶ»óÕć║ń¦»ÕłåÕż¦õ║ÄĶ»źńö©µłĘń¦»ÕłåńÜäńö©µłĘµĢ░ķćÅ’╝Ü
select 1 + count(t2.uid) as rank from user_score t1, user_score t2 where t1.uid = @uid and t2.score > t1.score
Õ»╣õ║Ä4ÕÅĘńö©µłĘµłæõ╗¼ÕÅ»õ╗źÕŠŚÕł░õĖŗķØóńÜäń╗ōµ×£’╝Ü

ń«Śµ│Ģńē╣ńé╣
õ╝śńé╣’╝Üń«ĆÕŹĢ’╝īÕł®ńö©õ║åSQLńÜäÕŖ¤ĶāĮ’╝īõĖŹķ£ĆĶ”üÕżŹµØéńÜ䵤źĶ»óķĆ╗ĶŠæ’╝īõ╣¤õĖŹÕ╝ĢÕģźķóØÕż¢ńÜäÕŁśÕé©ń╗ōµ×ä’╝īÕ»╣Õ░ÅĶ¦äµ©Īµł¢µĆ¦ĶāĮĶ”üµ▒éõĖŹķ½śńÜäÕ║öńö©õĖŹÕż▒õĖ║õĖĆń¦ŹĶē»ÕźĮńÜäĶ¦ŻÕå│µ¢╣µĪłŃĆé
ń╝║ńé╣’╝Üķ£ĆĶ”üÕ»╣user_scoreĶĪ©Ķ┐øĶĪīÕģ©ĶĪ©µē½µÅÅ’╝īĶ┐śķ£ĆĶ”üĶĆāĶÖæÕł░µ¤źĶ»óńÜäÕÉīµŚČĶŗźµ£ēń¦»Õłåµø┤µ¢░õ╝ÜÕ»╣ĶĪ©ķĆĀµłÉķöüÕ«Ü’╝īÕ£©µĄĘķćŵĢ░µŹ«Ķ¦äµ©ĪÕÆīķ½śÕ╣ČÕÅæńÜäÕ║öńö©õĖŁ’╝īµĆ¦ĶāĮµś»µŚĀµ│ĢµÄźÕÅŚńÜäŃĆé
ń«Śµ│Ģ2’╝ÜÕØćÕīĆÕłåÕī║Ķ«ŠĶ«Ī
Õ£©Ķ«ĖÕżÜÕ║öńö©õĖŁń╝ōÕŁśµś»Ķ¦ŻÕå│µĆ¦ĶāĮķŚ«ķóśńÜäķćŹĶ”üķĆöÕŠä’╝īµłæõ╗¼Ķć¬ńäČõ╝ܵā│ĶāĮõĖŹĶāĮµŖŖńö©µłĘµÄÆÕÉŹńö©Memcachedń╝ōÕŁśõĖŗµØźÕæó’╝¤õĖŹĶ┐ćÕåŹõĖƵā│ÕÅæńÄ░ń╝ōÕŁśõ╝╝õ╣ÄÕĖ«õĖŹõĖŖõ╗Ćõ╣łÕ┐Ö’╝īÕøĀõĖ║ńö©µłĘµÄÆÕÉŹµś»õĖĆõĖ¬Õģ©Õ▒ƵƦńÜäń╗¤Ķ«ĪµĆ¦µīćµĀć’╝īĶĆīÕ╣ČķØ×ńö©µłĘńÜäń¦üµ£ēÕ▒׵Ʀ’╝īÕģČõ╗¢ńö©µłĘńÜäń¦»ÕłåÕÅśÕī¢ÕÅ»ĶāĮõ╝Üķ®¼õĖŖÕĮ▒ÕōŹÕł░µ£¼ńö©µłĘńÜäµÄÆÕÉŹŃĆéńäČĶĆī’╝īń£¤Õ«×ńÜäÕ║öńö©õĖŁń¦»ÕłåńÜäÕÅśÕī¢ÕģČÕ«×õ╣¤µś»µ£ēõĖĆÕ«ÜĶ¦äÕŠŗńÜä’╝īķĆÜÕĖĖõĖĆõĖ¬ńö©µłĘńÜäń¦»ÕłåõĖŹõ╝Üń¬üńäȵÜ┤Õó×µÜ┤ÕćÅ’╝īõĖĆĶł¼ńö©µłĘµĆ╗µś»Ķ”üÕ£©õĮÄÕłåÕī║µĘĘĶ┐╣ÕŠłķĢ┐õĖƵ«ĄµŚČķŚ┤µēŹõ╝ܵģóµģóÕŹćÕģźķ½śÕłåÕī║’╝īõ╣¤Õ░▒µś»Ķ»┤ńö©µłĘń¦»ÕłåńÜäÕłåÕĖāµĆ╗õĮōĶ»┤µØźµś»µ£ēÕī║µ«ĄńÜä’╝īµłæõ╗¼Ķ┐øõĖƵŁźµ│©µäÅÕł░ķ½śÕłåÕī║ńö©µłĘń¦»ÕłåńÜäń╗åÕŠ«ÕÅśÕī¢ÕģČÕ«×Õ»╣õĮÄÕłåµ«Ąńö©µłĘńÜäµÄÆÕÉŹÕĮ▒ÕōŹõĖŹÕż¦ŃĆéõ║ĵś»’╝īµłæõ╗¼ÕÅ»õ╗źµā│Õł░µīēń¦»ÕłåÕī║µ«ĄĶ┐øĶĪīń╗¤Ķ«ĪńÜäµ¢╣µ│Ģ’╝īÕ╝ĢÕģźõĖĆÕ╝ĀÕłåÕī║ń¦»ÕłåĶĪ©score_range’╝Ü
ĶĪ©ń╗ōµ×ä’╝Ü

µĢ░µŹ«ńż║õŠŗ’╝Ü
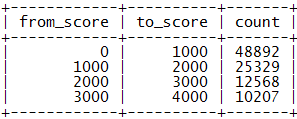
ĶĪ©ńż║[from_score, to_score)Õī║ķŚ┤µ£ēcountõĖ¬ńö©µłĘŃĆéĶŗźµłæõ╗¼µīēµ»Å1000ÕłåÕłÆÕłåõĖĆõĖ¬Õī║ķŚ┤ÕłÖµ£ē[0, 1000), [1000, 2000), ŌĆ”, [999000, 1000000)Ķ┐Ö1000õĖ¬Õī║ķŚ┤’╝īõ╗źÕÉÄÕ»╣ńö©µłĘń¦»ÕłåńÜäµø┤µ¢░Ķ”üńøĖÕ║öÕ£░µø┤µ¢░score_rangeĶĪ©ńÜäÕī║ķŚ┤ÕĆ╝ŃĆéÕ£©ÕłåÕī║ń¦»ÕłåĶĪ©ńÜäĶŠģÕŖ®õĖŗµ¤źĶ»óń¦»ÕłåõĖ║sńÜäńö©µłĘńÜäµÄÆÕÉŹ’╝īÕÅ»õ╗źķ”¢ÕģłńĪ«Õ«ÜÕģȵēĆÕ▒×Õī║ķŚ┤’╝īµŖŖķ½śõ║ÄsńÜäń¦»ÕłåÕī║ķŚ┤ńÜäcountÕĆ╝ń┤»ÕŖĀ’╝īńäČÕÉÄÕåŹµ¤źĶ»óÕć║Ķ»źńö©µłĘÕ£©µ£¼Õī║ķŚ┤ÕåģńÜäµÄÆÕÉŹ’╝īõ║īĶĆģńøĖÕŖĀÕŹ│ÕÅ»ĶÄĘÕŠŚńö©µłĘńÜäµÄÆÕÉŹŃĆé
õ╣ŹõĖĆń£ŗ’╝īĶ┐ÖõĖ¬µ¢╣µ│ĢĶ▓īõ╝╝ķĆÜĶ┐ćÕī║ķŚ┤ĶüÜÕÉłÕćÅÕ░æõ║嵤źĶ»óĶ«Īń«ŚķćÅ’╝īÕ«×ÕłÖõĖŹńäČŃĆéµ£ĆÕż¦ńÜäķŚ«ķóśÕ£©õ║ÄÕ”éõĮĢµ¤źĶ»óńö©µłĘÕ£©µ£¼Õī║ķŚ┤ÕåģńÜäµÄÆÕÉŹÕæó’╝¤Õ”éµ×£µś»Õ£©ń«Śµ│Ģ1õĖŁńÜäSQLõĖŁÕŖĀõĖŖń¦»ÕłåµØĪõ╗Č’╝Ü
select 1 + count(t2.uid) as rank from user_score t1, user_score t2 where t1.uid = @uid and t2.score > t1.score and t2.score < @to_score
Õ£©ńÉåµā│µāģÕåĄõĖŗ’╝īńö▒õ║ĵŖŖt2.scoreńÜäĶīāÕø┤ķÖÉÕłČÕ£©õ║å1000õ╗źÕåģ’╝īÕ”éµ×£Õ»╣scoreÕŁŚµ«ĄÕ╗║ń½ŗń┤óÕ╝Ģ’╝īµłæõ╗¼µ£¤µ£øµ£¼µØĪSQLĶ»ŁÕÅźÕ░åķĆÜĶ┐ćń┤óÕ╝ĢÕż¦Õż¦ÕćÅÕ░æµē½µÅÅńÜäuser_scoreĶĪ©ńÜäĶĪīµĢ░ŃĆéõĖŹĶ┐ćń£¤Õ«×µāģÕåĄÕ╣ČķØ×Õ”éµŁż’╝īt2.scoreńÜäĶīāÕø┤Õ£©1000õ╗źÕåģÕ╣ČõĖŹµäÅÕæ│ńØĆĶ»źÕī║ķŚ┤ÕåģńÜäńö©µłĘµĢ░õ╣¤µś»1000’╝īÕøĀõĖ║Ķ┐Öķćīµ£ēń¦»ÕłåńøĖÕÉīńÜäµāģÕåĄÕŁśÕ£©’╝üõ║īÕģ½Õ«ÜÕŠŗÕæŖĶ»ēµłæõ╗¼’╝īÕēŹ20%ńÜäõĮÄÕłåÕī║ÕŠĆÕŠĆķøåõĖŁõ║å80%ńÜäńö©µłĘ’╝īĶ┐ÖÕ░▒µś»Ķ»┤Õ»╣õ║ÄÕż¦ķćÅõĮÄÕłåÕī║ńö©µłĘĶ┐øĶĪīÕī║ķŚ┤ÕåģµÄÆÕÉŹµ¤źĶ»óńÜäµĆ¦ĶāĮĶ┐£õĖŹÕÅŖÕ»╣Õ░æµĢ░ńÜäķ½śÕłåÕī║ńö©µłĘ’╝īµēĆõ╗źÕ£©õĖĆĶł¼µāģÕåĄõĖŗĶ┐Öń¦ŹÕłåÕī║µ¢╣µ│ĢõĖŹõ╝ÜÕĖ”µØźÕ«×Ķ┤©µĆ¦ńÜäµĆ¦ĶāĮµÅÉÕŹćŃĆé
ń«Śµ│Ģńē╣ńé╣
õ╝śńé╣’╝ܵ│©µäÅÕł░õ║åń¦»ÕłåÕī║ķŚ┤ńÜäÕŁśÕ£©’╝īÕ╣ČķĆÜĶ┐ćķóäÕģłĶüÜÕÉłµČłķÖżµ¤źĶ»óńÜäÕģ©ĶĪ©µē½µÅÅŃĆé
ń╝║ńé╣’╝Üń¦»ÕłåķØ×ÕØćÕīĆÕłåÕĖāńÜäńē╣ńé╣õĮ┐ÕŠŚµĆ¦ĶāĮµÅÉÕŹćÕ╣ČõĖŹńÉåµā│ŃĆé
ń«Śµ│Ģ3’╝ܵĀæÕĮóÕłåÕī║Ķ«ŠĶ«Ī
ÕØćÕīĆÕłåÕī║µ¤źĶ»óń«Śµ│ĢńÜäÕż▒Ķ┤źµś»ńö▒õ║Äń¦»ÕłåÕłåÕĖāńÜäķØ×ÕØćÕīƵƦ’╝īķéŻõ╣łµłæõ╗¼Ķć¬ńäČÕ░▒õ╝ܵā│’╝īĶāĮõĖŹĶāĮµīēõ║īÕģ½Õ«ÜÕŠŗ’╝īµŖŖscore_rangeĶĪ©Ķ«ŠĶ«ĪõĖ║ķØ×ÕØćÕīĆÕī║ķŚ┤Õæó’╝¤µ»öÕ”é’╝īµŖŖõĮÄÕłåÕī║ÕłÆÕ»åķøåõĖĆńé╣’╝ī10ÕłåõĖĆõĖ¬Õī║ķŚ┤’╝īńäČÕÉÄķĆɵĖÉÕÅśµłÉ100Õłå’╝ī1000Õłå’╝ī10000Õłå ŌĆ” ÕĮōńäČ’╝īĶ┐ÖõĖŹÕż▒õĖ║õĖĆń¦Źµ¢╣µ│Ģ’╝īõĖŹĶ┐ćĶ┐Öń¦ŹÕłåµ│Ģµ£ēõĖĆÕ«ÜńÜäķÜŵäÅµĆ¦’╝īõĖŹÕ«╣µśōµŖŖµÅĪÕźĮ’╝īĶĆīõĖöµĢ┤õĖ¬ń│╗ń╗¤ńÜäń¦»ÕłåÕłåÕĖāõ╝ÜķÜÅńØĆõĮ┐ńö©ĶĆīķĆɵĖÉÕÅæńö¤ÕÅśÕī¢’╝īµ£ĆÕłØńÜäĶŠāÕźĮńÜäÕłåÕī║µ¢╣µ│ĢÕÅ»ĶāĮõ╝ÜÕÅśÕŠŚõĖŹķĆéÕ║öµ£¬µØźńÜäµāģÕåĄõ║åŃĆ鵳æõ╗¼ÕĖīµ£øµēŠÕł░õĖĆń¦ŹÕłåÕī║µ¢╣µ│Ģ’╝īµŚóÕÅ»õ╗źķĆéÕ║öń¦»ÕłåķØ×ÕØćÕīƵƦ’╝īÕÅłÕÅ»õ╗źķĆéÕ║öń│╗ń╗¤ń¦»ÕłåÕłåÕĖāńÜäÕÅśÕī¢’╝īĶ┐ÖÕ░▒µś»µĀæÕĮóÕłåÕī║ŃĆé
µłæõ╗¼ÕÅ»õ╗źµŖŖ[0, 1,000,000)õĮ£õĖ║õĖĆń║¦Õī║ķŚ┤’╝øÕåŹµŖŖõĖĆń║¦Õī║ķŚ┤ÕłåõĖ║õĖżõĖ¬2ń║¦Õī║ķŚ┤[0, 500,000), [500,000, 1,000,000)’╝īńäČÕÉĵŖŖõ║īń║¦Õī║ķŚ┤õ║īÕłåõĖ║4õĖ¬3ń║¦Õī║ķŚ┤[0, 250,000), [250,000, 500,000), [500,000, 750,000), [750,000, 1,000,000)’╝īõŠØµŁżń▒╗µÄ©’╝īµ£Ćń╗łµłæõ╗¼õ╝ÜÕŠŚÕł░1,000,000õĖ¬21ń║¦Õī║ķŚ┤[0,1), [1,2) ŌĆ” [999,999, 1,000,000)ŃĆéĶ┐ÖÕ«×ķÖģõĖŖµś»µŖŖÕī║ķŚ┤ń╗äń╗浳Éõ║åõĖĆń¦ŹÕ╣│ĶĪĪõ║īÕÅēµĀæń╗ōµ×ä’╝īµĀ╣ń╗ōńé╣õ╗ŻĶĪ©õĖĆń║¦Õī║ķŚ┤’╝īµ»ÅõĖ¬ķØ×ÕÅČÕŁÉń╗ōńé╣µ£ēõĖżõĖ¬ÕŁÉń╗ōńé╣’╝īÕĘ”ÕŁÉń╗ōńé╣õ╗ŻĶĪ©õĮÄÕłåÕī║ķŚ┤’╝īÕÅ│ÕŁÉń╗ōńé╣õ╗ŻĶĪ©ķ½śÕłåÕī║ķŚ┤ŃĆéµĀæÕĮóÕłåÕī║ń╗ōµ×äķ£ĆĶ”üÕ£©µø┤µ¢░µŚČõ┐صīüõĖĆń¦ŹõĖŹÕÅśķćÅ(Invariant)’╝ÜķØ×ÕÅČÕŁÉń╗ōńé╣ńÜäcountÕĆ╝µĆ╗µś»ńŁēõ║ÄÕģČÕĘ”ÕÅ│ÕŁÉń╗ōńé╣ńÜäcountÕĆ╝õ╣ŗÕÆīŃĆé
┬Ā
┬Ā
┬Ā
┬Ā
õ╗źÕÉÄ’╝īµ»Åµ¼Īńö©µłĘń¦»Õłåµ£ēÕÅśÕī¢µēĆķ£ĆĶ”üµø┤µ¢░ńÜäÕī║ķŚ┤µĢ░ķćÅÕÆīń¦»ÕłåÕÅśÕī¢ķćŵ£ēÕģ│ń│╗’╝īń¦»ÕłåÕÅśÕī¢ĶČŖÕ░ŵø┤µ¢░ńÜäÕī║ķŚ┤Õ▒éµ¼ĪĶČŖõĮÄŃĆéµĆ╗õĮōõĖŖ’╝īµ»Åµ¼ĪµēĆķ£ĆĶ”üµø┤µ¢░ńÜäÕī║ķŚ┤µĢ░ķćŵś»ńö©µłĘń¦»ÕłåÕÅśķćÅńÜälog(n)ń║¦Õł½ńÜä’╝īõ╣¤Õ░▒µś»Ķ»┤Õ”éµ×£ńö©µłĘń¦»ÕłåõĖƵ¼ĪÕÅśÕī¢Õ£©ńÖŠõĖćń║¦’╝īµø┤µ¢░Õī║ķŚ┤ńÜäµĢ░ķćÅÕ£©õ║īÕŹüĶ┐ÖõĖ¬ń║¦Õł½ŃĆéÕ£©Ķ┐Öń¦ŹµĀæÕĮóÕłåÕī║ń¦»ÕłåĶĪ©ńÜäĶŠģÕŖ®õĖŗµ¤źĶ»óń¦»ÕłåõĖ║sńÜäńö©µłĘµÄÆÕÉŹ’╝īÕ«×ķÖģõĖŖµś»õĖĆõĖ¬Õ£©Õī║ķŚ┤µĀæõĖŖńö▒õĖŖĶć│õĖŗŃĆüńö▒ń▓ŚÕł░ń╗åõĖƵŁźµŁźµśÄńĪ«sµēĆÕ£©õĮŹńĮ«ńÜäĶ┐ćń©ŗŃĆéµ»öÕ”é’╝īÕ»╣õ║Äń¦»Õłå499,000’╝īµłæõ╗¼ńö©õĖĆõĖ¬ÕłØÕĆ╝õĖ║0ńÜäµÄÆÕÉŹÕÅśķćÅµØźÕüÜń┤»ÕŖĀ’╝øķ”¢Õģł’╝īÕ«āÕ▒×õ║Ä1ń║¦Õī║ķŚ┤ńÜäÕĘ”ÕŁÉµĀæ[0, 500,000)’╝īķéŻõ╣łĶ»źńö©µłĘµÄÆÕÉŹÕ║öĶ»źÕ£©ÕÅ│ÕŁÉµĀæ[500,000, 1,000,000)ńÜäńö©µłĘµĢ░countõ╣ŗÕÉÄ’╝īµłæõ╗¼µŖŖĶ»źcountÕĆ╝ń┤»ÕŖĀÕł░Ķ»źńö©µłĘµÄÆÕÉŹÕÅśķćÅ’╝īĶ┐øÕģźõĖŗõĖĆń║¦Õī║ķŚ┤’╝øÕģȵ¼Ī’╝īÕ«āÕ▒×õ║Ä3ń║¦Õī║ķŚ┤ńÜä[250,000, 500,000)’╝īĶ┐Öµś»2ń║¦Õī║ķŚ┤ńÜäÕÅ│ÕŁÉµĀæ’╝īµēĆõ╗źõĖŹńö©ń┤»ÕŖĀcountÕł░µÄÆÕÉŹÕÅśķćÅ’╝īńø┤µÄźĶ┐øÕģźõĖŗõĖĆń║¦Õī║ķŚ┤’╝øÕåŹµ¼Ī’╝īÕ«āÕ▒×õ║Ä4ń║¦Õī║ķŚ┤ńÜäŌĆ”’╝øńø┤Õł░µ£ĆÕÉĵłæõ╗¼µŖŖńö©µłĘń¦»Õłåń▓ŠńĪ«Õ«ÜõĮŹÕ£©21ń║¦Õī║ķŚ┤[499,000, 499,001)’╝īµĢ┤õĖ¬ń┤»ÕŖĀĶ┐ćń©ŗÕ«īµłÉ’╝īÕŠŚÕć║µÄÆÕÉŹ’╝ü
ĶÖĮńäČ’╝īµ£¼ń«Śµ│ĢńÜäµø┤µ¢░ÕÆīµ¤źĶ»óķāĮµČēÕÅŖÕł░ĶŗźÕ╣▓õĖ¬µōŹõĮ£’╝īõĮåÕ”éµ×£µłæõ╗¼õĖ║Õī║ķŚ┤ńÜäfrom_scoreÕÆīto_scoreÕ╗║ń½ŗń┤óÕ╝Ģ’╝īĶ┐Öõ║øµōŹõĮ£ķāĮµś»Õ¤║õ║Äķö«ńÜ䵤źĶ»óÕÆīµø┤µ¢░’╝īõĖŹõ╝Üõ║¦ńö¤ĶĪ©µē½µÅÅ’╝īÕøĀµŁżµĢłńÄćµø┤ķ½śŃĆéÕÅ”Õż¢’╝īµ£¼ń«Śµ│ĢÕ╣ČõĖŹõŠØĶĄ¢õ║ÄÕģ│ń│╗µĢ░µŹ«µ©ĪÕ×ŗÕÆīSQLĶ┐Éń«Ś’╝īÕÅ»õ╗źĶĮ╗µśōÕ£░µö╣ķĆĀõĖ║NoSQLńŁēÕģČõ╗¢ÕŁśÕ驵¢╣Õ╝Å’╝īĶĆīÕ¤║õ║Äķö«ńÜäµōŹõĮ£õ╣¤ÕŠłÕ«╣µśōÕ╝ĢÕģźń╝ōÕŁśµ£║ÕłČĶ┐øõĖƵŁźõ╝śÕī¢µĆ¦ĶāĮŃĆéĶ┐øõĖƵŁź’╝īµłæõ╗¼ÕÅ»õ╗źõ╝░ń«ŚõĖĆõĖŗµĀæÕĮóÕī║ķŚ┤ńÜäµĢ░ńø«Õż¦ń║”õĖ║200,000,000’╝īĶĆāĶÖæµ»ÅõĖ¬ń╗ōńé╣ńÜäÕż¦Õ░Å’╝īµĢ┤õĖ¬ń╗ōµ×äÕÅ¬ÕŹĀńö©ÕćĀÕŹüMń®║ķŚ┤ŃĆéµēĆõ╗ź’╝īµłæõ╗¼Õ«īÕģ©ÕÅ»õ╗źÕ£©ÕåģÕŁśÕ╗║ń½ŗÕī║ķŚ┤µĀæń╗ōµ×ä’╝īÕ╣ČķĆÜĶ┐ćuser_scoreĶĪ©Õ£©O(n)ńÜ䵌ČķŚ┤ÕåģÕłØÕ¦ŗÕī¢Õī║ķŚ┤µĀæ’╝īńäČÕÉĵÄÆÕÉŹńÜ䵤źĶ»óÕÆīµø┤µ¢░µōŹõĮ£ķāĮÕÅ»õ╗źÕ£©ÕåģÕŁśĶ┐øĶĪīŃĆéõĖĆĶł¼µØźĶ«▓’╝īÕÉīµĀĘńÜäń«Śµ│Ģ’╝īõ╗ĵĢ░µŹ«Õ║ōÕł░ÕåģÕŁśń«Śµ│ĢńÜäµĆ¦ĶāĮµÅÉÕŹćÕĖĖÕĖĖÕÅ»õ╗źĶŠŠÕł░10^5õ╗źõĖŖ’╝øÕøĀµŁż’╝īµ£¼ń«Śµ│ĢÕÅ»õ╗źĶŠŠÕł░ķØ×ÕĖĖķ½śńÜäµĆ¦ĶāĮŃĆé
ń«Śµ│Ģńē╣ńé╣
õ╝śńé╣’╝Üń╗ōµ×äń©│Õ«Ü’╝īõĖŹÕÅŚń¦»ÕłåÕłåÕĖāÕĮ▒ÕōŹ’╝øµ»Åµ¼Īµ¤źĶ»óµł¢µø┤µ¢░ńÜäÕżŹµØéÕ║”õĖ║ń¦»Õłåµ£ĆÕż¦ÕĆ╝ńÜäO(log(n))ń║¦Õł½’╝īõĖöõĖÄńö©µłĘĶ¦äµ©ĪµŚĀÕģ│’╝īÕÅ»õ╗źÕ║öÕ»╣µĄĘķćÅĶ¦äµ©Ī’╝øõĖŹõŠØĶĄ¢õ║ÄSQL’╝īÕ«╣µśōµö╣ķĆĀõĖ║NoSQLµł¢ÕåģÕŁśµĢ░µŹ«ń╗ōµ×äŃĆé
ń╝║ńé╣’╝Üń«Śµ│ĢńøĖÕ»╣µø┤ÕżŹµØéŃĆé
ń«Śµ│Ģ4’╝Üń¦»ÕłåµÄÆÕÉŹµĢ░ń╗ä
ń«Śµ│Ģ3ĶÖĮńäȵƦĶāĮĶŠāķ½ś’╝īĶŠŠÕł░õ║åń¦»ÕłåÕÅśÕī¢ńÜäO(log(n))ńÜäÕżŹµØéÕ║”’╝īõĮåµś»Õ«×ńÄ░õĖŖµ»öĶŠāÕżŹµØéŃĆéÕÅ”Õż¢’╝īO(log(n))ńÜäÕżŹµØéÕ║”ÕŬգ©nńē╣Õł½Õż¦ńÜ䵌ČÕĆÖµēŹµśŠÕć║Õ«āńÜäõ╝śÕŖ┐’╝īĶĆīÕ«×ķÖģÕ║öńö©õĖŁń¦»ÕłåńÜäÕÅśÕī¢µāģÕåĄÕŠĆÕŠĆõĖŹõ╝ÜÕż¬Õż¦’╝īĶ┐ÖµŚČÕÆīO(n)ńÜäń«Śµ│ĢńøĖµ»öÕŠĆÕŠĆµ▓Īµ£ēµśÄµśŠńÜäõ╝śÕŖ┐’╝īńöÜĶć│ÕÅ»ĶāĮµø┤µģóŃĆé
ĶĆāĶÖæÕł░Ķ┐ÖõĖƵāģÕåĄ’╝īõ╗öń╗åĶ¦éÕ»¤õĖĆõĖŗń¦»ÕłåÕÅśÕī¢Õ»╣µÄÆÕÉŹńÜäÕģĘõĮōÕĮ▒ÕōŹ’╝īÕÅ»õ╗źÕÅæńÄ░µ¤Éńö©µłĘńÜäń¦»Õłåõ╗ÄsÕÅśõĖ║s+n’╝īń¦»ÕłåÕ░Åõ║Äsµł¢ĶĆģÕż¦õ║ÄńŁēõ║Äs+nńÜäÕģČõ╗¢ńö©µłĘµÄÆÕÉŹÕ«×ķÖģõĖŖÕ╣ČõĖŹõ╝ÜÕÅŚÕł░ÕĮ▒ÕōŹ’╝īÕŬµ£ēń¦»ÕłåÕ£©[s,s+n)Õī║ķŚ┤ÕåģńÜäńö©µłĘµÄÆÕÉŹõ╝ÜõĖŗķÖŹ1õĮŹŃĆ鵳æõ╗¼ÕÅ»õ╗źńö©õ║ÄõĖĆõĖ¬Õż¦Õ░ÅõĖ║100,000,000ńÜäµĢ░ń╗äĶĪ©ńż║ń¦»ÕłåÕÆīµÄÆÕÉŹńÜäÕ»╣Õ║öÕģ│ń│╗’╝īÕģČõĖŁrank[s]ĶĪ©ńż║ń¦»ÕłåsµēĆÕ»╣Õ║öńÜäµÄÆÕÉŹŃĆéÕłØÕ¦ŗÕī¢µŚČ’╝īrankµĢ░ń╗äÕÅ»õ╗źńö▒user_scoreĶĪ©Õ£©O(n)ńÜäÕżŹµØéÕ║”ÕåģĶ«Īń«ŚĶĆīµØźŃĆéńö©µłĘµÄÆÕÉŹńÜ䵤źĶ»óÕÆīµø┤µ¢░Õ¤║õ║ÄĶ┐ÖõĖ¬µĢ░ń╗äµØźĶ┐øĶĪīŃĆ鵤źĶ»óń¦»ÕłåsµēĆÕ»╣Õ║öńÜäµÄÆÕÉŹńø┤µÄźĶ┐öÕø×rank[s]ÕŹ│ÕÅ»’╝īÕżŹµØéÕ║”õĖ║O(1)’╝øÕĮōńö©µłĘń¦»Õłåõ╗ÄsÕÅśõĖ║s+n’╝īÕŬķ£ĆĶ”üµŖŖrank[s]Õł░rank[s+n-1]Ķ┐ÖnõĖ¬Õģāń┤ĀńÜäÕĆ╝Õó×ÕŖĀ1ÕŹ│ÕÅ»’╝īÕżŹµØéÕ║”õĖ║O(n)ŃĆé
ń«Śµ│Ģńē╣ńé╣
õ╝śńé╣’╝Üń¦»ÕłåµÄÆÕÉŹµĢ░ń╗äµ»öÕī║ķŚ┤µĀæµø┤ń«ĆÕŹĢ’╝īµśōõ║ÄÕ«×ńÄ░’╝øµÄÆÕÉŹµ¤źĶ»óÕżŹµØéÕ║”õĖ║O(1)’╝øµÄÆÕÉŹµø┤µ¢░ÕżŹµØéÕ║”O(n)’╝īÕ£©ń¦»ÕłåÕÅśÕī¢õĖŹÕż¦ńÜäµāģÕåĄõĖŗķØ×ÕĖĖķ½śµĢłŃĆé
ń╝║ńé╣’╝ÜÕĮōnµ»öĶŠāÕż¦µŚČ’╝īķ£ĆĶ”üµø┤µ¢░Õż¦ķćÅÕģāń┤Ā’╝īµĢłńÄćõĖŹÕ”éń«Śµ│Ģ3ŃĆé
µĆ╗ń╗ō
õĖŖķØóõ╗ŗń╗Źõ║åńö©µłĘń¦»ÕłåµÄÆÕÉŹńÜäÕćĀń¦Źń«Śµ│Ģ’╝īń«Śµ│Ģ1ń«ĆÕŹĢµśōõ║ÄńÉåĶ¦ŻÕÆīÕ«×ńÄ░’╝īķĆéńö©õ║ÄÕ░ÅĶ¦äµ©ĪÕÆīõĮÄÕ╣ČÕÅæÕ║öńö©’╝øń«Śµ│Ģ3Õ╝ĢÕģźõ║åµø┤ÕżŹµØéńÜäµĀæÕĮóÕłåÕī║ń╗ōµ×ä’╝īõĮåµś»O(log(n))ńÜäÕżŹµØéÕ║”µĆ¦ĶāĮõ╝śĶČŖ’╝īÕÅ»õ╗źÕ║öńö©õ║ĵĄĘķćÅĶ¦äµ©ĪÕÆīķ½śÕ╣ČÕÅæ’╝øń«Śµ│Ģ4ķććńö©ń«ĆÕŹĢńÜäµÄÆÕÉŹµĢ░ń╗ä’╝īµśōõ║ÄÕ«×ńÄ░’╝īÕ£©ń¦»ÕłåÕÅśÕī¢õĖŹÕż¦ńÜäµāģÕåĄõĖŗµĆ¦ĶāĮõĖŹõ║Üõ║Äń«Śµ│Ģ3ŃĆéµ£¼ķŚ«ķ󜵜»õĖĆõĖ¬Õ╝ƵöŠµĆ¦ńÜäķŚ«ķóś’╝īńøĖõ┐ĪõĖĆÕ«ÜĶ┐śµ£ēÕģČõ╗¢õ╝śń¦ĆńÜäń«Śµ│ĢÕÆīĶ¦ŻÕå│µ¢╣µĪł’╝īµ¼óĶ┐ĵÄóĶ«©’╝ü
Õłåõ║½Õł░’╝Ü





ńøĖÕģ│µÄ©ĶŹÉ
ÕēŹõ║øÕż®ÕÆīµ£ŗÕÅŗĶ«©Ķ«║õĖĆõĖ¬ķŚ«ķóś’╝īõ╗¢õ╗¼ńÜäÕ║öńö©µ£ēÕćĀÕŹüõĖćõ╝ÜÕæśńäČÕÉÄÕ»╣Õ║öµ£ēń¦»Õłå’╝īńÄ░Õ£©µā│ÕüÜń¦»ÕłåµÄÆÕÉŹńÜäķ£Ćµ▒é’╝īķŚ«µ£ēµ▓Īµ£ēõ╗Ćõ╣łÕźĮµ¢╣µĪłŃĆéĶ┐ÖõĖ¬ķŚ«ķóśõ╣¤ń«ŚÕĖĖĶ¦ü’╝īÕŠłÕżÜÕ£░µ¢╣ķāĮĶāĮń£ŗÕł░’╝īÕĖĖĶ¦äÕüܵ│ĢõĖĆĶł¼µś»µĢ░µŹ«Õ«ÜµŚČĶĘæµē╣µŖŖĶ«Īń«Śń╗ōµ×£Õł░õĖŁķŚ┤ĶĪ©ńäČÕÉÄńø┤µÄźµ¤źĶĪ©...
3. **µĖĖµłÅÕī¢Õģāń┤Ā**’╝ÜķĆÜĶ┐ćń¦»ÕłåŃĆüńŁēń║¦ŃĆüµłÉÕ░▒ńŁēµ£║ÕłČµ┐ĆÕŖ▒ńö©µłĘÕÅéõĖÄ’╝īµÅÉķ½śńö©µłĘń▓śµĆ¦ŃĆé 4. **õĖ¬µĆ¦Õī¢µÄ©ĶŹÉ**’╝ܵĀ╣µŹ«ńö©µłĘńÜäÕģ┤ĶČŻÕÆīĶĪīõĖ║ÕÄåÕÅ▓’╝īµÄ©ĶŹÉńøĖÕģ│ńÜäÕŁ”µ£»ĶĄäµ║ÉÕÆīµ┤╗ÕŖ©ŃĆé 5. **ÕŹÅõĮ£ÕĘźÕģĘ**’╝ܵö»µīüÕøóķś¤ÕÉłõĮ£’╝īÕ”éÕ£©ń║┐ń╝¢ĶŠæµ¢ćµĪŻŃĆüķĪ╣ńø«...
ÕģŹń¦»ÕłåõĖŗĶĮĮÕÖ©ńÜäõĮ┐ńö©µ¢╣µ│ĢÕż¦õĮōÕłåõĖ║õ╗źõĖŗÕćĀµŁź’╝Ü 1. **õĖŗĶĮĮÕ«ēĶŻģ**’╝Üķ”¢Õģł’╝īńö©µłĘķ£ĆĶ”üõ╗ÄÕÅ»õ┐ĪĶĄ¢ńÜäµØźµ║ÉõĖŗĶĮĮńÖŠÕ║”µ¢ćÕ║ōÕģŹń¦»ÕłåõĖŗĶĮĮÕÖ©’╝īõŠŗÕ”éŌĆ£Fish-v323ŌĆØĶ┐ÖµĀĘńÜäńēłµ£¼ŃĆéńĪ«õ┐ØõĖŗĶĮĮńÜäĶĮ»õ╗ČµØźĶć¬Õ«ēÕģ©ńÜäµĖĀķüō’╝īķü┐ÕģŹõĖŗĶĮĮÕɽµ£ēńŚģµ»Æµł¢µüȵäÅĶĮ»õ╗ČńÜä...
õ╗źõĖŖõ╗ŗń╗Źõ║åÕćĀń¦ŹÕĖĖĶ¦üńÜäµĢ░ÕŁ”Õ╗║µ©Īń«Śµ│Ģ’╝īµ»Åń¦Źń«Śµ│ĢķāĮµ£ēÕģČńŗ¼ńē╣ńÜäõ╝śÕŖ┐ÕÆīÕ║öńö©Õ£║µÖ»ŃĆéÕ£©Õ«×ķÖģÕ║öńö©õĖŁ’╝īÕŠĆÕŠĆķ£ĆĶ”üµĀ╣µŹ«ÕģĘõĮōķŚ«ķóśńÜäńē╣ńé╣ķĆēµŗ®ÕÉłķĆéńÜäń«Śµ│Ģµł¢ĶĆģÕ░åÕżÜń¦Źń«Śµ│Ģń╗ōÕÉłõĮ┐ńö©’╝īõ╗źĶŠŠÕł░µ£ĆõĮ│µĢłµ×£ŃĆéõ║åĶ¦ŻÕ╣ȵÄīµÅĪĶ┐Öõ║øń«Śµ│ĢõĖŹõ╗ģÕÅ»õ╗źÕĖ«ÕŖ®µłæõ╗¼µø┤...
5. **ķÜÉÕ╝Å-µśŠÕ╝ÅÕżÜµŁźµ£ēķÖÉÕģāµ¢╣µ│Ģ**’╝łIMEX’╝ē’╝ÜĶ┐Öµś»õĖĆń¦Źń╗ōÕÉłķÜÉÕ╝ÅÕÆīµśŠÕ╝ŵŚČķŚ┤ń¦»ÕłåńŁ¢ńĢźńÜäµĢ░ÕĆ╝µ¢╣µ│Ģ’╝īķĆéńö©õ║ÄÕżäńÉåÕ»╣µĄüµē®µĢŻµ¢╣ń©ŗŃĆéķÜÉÕ╝Åķā©ÕłåÕżäńÉåń©│Õ«ÜńÜäÕ»╣µĄüķĪ╣’╝īĶĆīµśŠÕ╝Åķā©ÕłåÕżäńÉåń©│Õ«ÜńÜäµē®µĢŻķĪ╣’╝īĶ┐ÖµĀĘÕÅ»õ╗źÕ╣│ĶĪĪĶ«Īń«ŚµĢłńÄćÕÆīń©│Õ«ÜµĆ¦ŃĆé 6. *...
ĶĆīK-Meansń«Śµ│ĢõĮ£õĖ║õĖĆń¦ŹÕĖĖńö©ńÜäĶüÜń▒╗Õłåµ×ɵ¢╣µ│Ģ’╝īĶó½ķĆēõĖ║µ£¼ń│╗ń╗¤Ķ«ŠĶ«ĪńÜäÕ¤║ńĪĆń«Śµ│ĢŃĆéńäČĶĆī’╝īõ╝Āń╗¤K-Meansń«Śµ│ĢÕ£©ÕżäńÉåÕŁżń½ŗńé╣µĢ░µŹ«µŚČµĢłµ×£õĖŹõĮ│’╝īÕøĀµŁżńĀöń®ČĶĆģÕ»╣ń«Śµ│ĢĶ┐øĶĪīõ║åµö╣ķĆĀ’╝īõ╗źµÅÉķ½śÕģČÕ£©õ╝ÜÕæśµČłĶ┤╣ń¦»Õłåń│╗ń╗¤õĖŁńÜäÕ║öńö©µĢłµ×£ŃĆé Õ£©µĢ░µŹ«µī¢µÄś...
FCMĶüÜń▒╗ń«Śµ│ĢķĆÜĶ┐浩Īń│ŖńÉåĶ«║µÅÉõŠøõ║åõĖĆń¦Źµø┤õĖ║ńüĄµ┤╗õĖöķĆéÕ║öµĆ¦Õ╝║ńÜäĶüÜń▒╗µ¢╣µ│Ģ’╝īĶāĮÕż¤ÕżäńÉåµĢ░µŹ«ńé╣õĖÄÕżÜõĖ¬ń░ćõ╣ŗķŚ┤ńÜäÕżŹµØéÕģ│ń│╗ŃĆéķĆÜĶ┐ćMATLABńŁēÕĘźÕģĘńÜäÕ«×ńÄ░’╝īFCMÕÅ»õ╗źµ£ēµĢłÕ£░Õ║öńö©õ║ÄÕÉäń¦ŹÕ«×ķÖģķŚ«ķóś’╝īÕ”éÕøŠÕāÅÕłåµ×ÉŃĆüµ¢ćµ£¼Õłåń▒╗ÕÆīńö¤ńē®õ┐Īµü»ÕŁ”ńŁē’╝īÕĖ«ÕŖ®...
4. **ń«Śµ│Ģõ╝śÕī¢**’╝ÜõĖ║õ║åµÅÉķ½śĶ«Īń«ŚµĢłńÄć’╝īÕÅ»ĶāĮķ£ĆĶ”üÕ»╣ń«ĆĶ░ɵī»ÕŁÉń«Śµ│ĢĶ┐øĶĪīõ╝śÕī¢’╝īõŠŗÕ”éķććńö©µø┤ķ½śµĢłńÜäµĢ░ÕĆ╝ń¦»Õłåµ¢╣µ│Ģ’╝īµł¢ĶĆģÕł®ńö©GPUĶ┐øĶĪīńĪ¼õ╗ČÕŖĀķƤŃĆé 5. **õ║æĶ«Īń«Śµ£ŹÕŖĪ**’╝ÜõĮ┐ńö©Õ”éAmazon Web Services (AWS)ŃĆüMicrosoft Azureµł¢Google ...
Õ£©µĢ░µŹ«Õłåµ×ÉķóåÕ¤¤’╝īK-Meansń«Śµ│Ģµś»õĖĆń¦ŹÕ╣┐µ│øÕ║öńö©ńÜ䵌ĀńøæńØŻÕŁ”õ╣Āµ¢╣µ│Ģ’╝īÕ░żÕģČķĆéńö©õ║ÄÕż¦µĢ░µŹ«ķøåõĖŁńÜäÕłåń▒╗ÕÆīĶüÜń▒╗õ╗╗ÕŖĪŃĆéµ£¼ķĪ╣ńø«õ╗źĶł¬ń®║Õģ¼ÕÅĖńÜäõ╗ĘÕĆ╝Õłåµ×ÉõĖ║ńĀöń®ČÕ»╣Ķ▒Ī’╝īķĆÜĶ┐ćK-Meansń«Śµ│ĢµÅŁńż║Ķł¬ń®║Õģ¼ÕÅĖńÜäÕ«óµłĘńŠżõĮōńē╣ÕŠü’╝īõ╗ÄĶĆīµÅÉÕŹćĶ┐ÉĶÉźµĢłńÄćÕÆīÕ«óµłĘ...
ķÆłÕ»╣ÕģŹĶ┤╣õĖŗĶĮĮńÜäķ£Ćµ▒é’╝īµ£ēõ╗źõĖŗÕćĀń¦Źµ¢╣µ│Ģ’╝Ü 1. **ńø┤µÄźõĖŗĶĮĮ**’╝ÜÕ»╣õ║ĵŚĀķÖÉÕłČńÜäÕģŹĶ┤╣µ¢ćµĪŻ’╝īÕŬķ£ĆÕ£©ńÖŠÕ║”µ¢ćÕ║ōķĪĄķØóńé╣Õć╗ŌĆ£ÕģŹĶ┤╣õĖŗĶĮĮŌĆØ’╝īńäČÕÉĵīēńģ¦µÅÉńż║µōŹõĮ£ÕŹ│ÕÅ»ŃĆéõĮåĶ┐Öń¦Źµ¢╣Õ╝ÅÕÅ»ĶāĮõ╝ÜķüćÕł░ķ£ĆĶ”üńÖ╗ÕĮĢµł¢ĶĆģĶ¦éń£ŗÕ╣┐ÕæŖńÜäµāģÕåĄŃĆé 2. **õĮ┐ńö©õĖŗĶĮĮ...
ńäČĶĆī’╝īµ£ēõ║øńö©µłĘÕ»╗µēŠÕģŹĶ┤╣õĖŗĶĮĮķĆöÕŠäõ╗źĶŖéń║”µłÉµ£¼’╝īõĖŗķØóÕ░åĶ»”ń╗åõ╗ŗń╗ŹÕćĀń¦ŹÕĖĖĶ¦üńÜäńÖŠÕ║”µ¢ćÕ║ōÕģŹĶ┤╣õĖŗĶĮĮµŖĆÕʦŃĆé 1. **µĄÅĶ¦łÕÖ©µÅÆõ╗Č**’╝ÜõĖĆõ║øµĄÅĶ¦łÕÖ©µÅÆõ╗ČÕ”éŌĆ£Õå░ńé╣µ¢ćÕ║ōõĖŗĶĮĮÕÖ©ŌĆصł¢ŌĆ£DocDownŌĆØĶāĮÕż¤ÕĖ«ÕŖ®ńö©µłĘń╗ĢĶ┐ćńÖŠÕ║”µ¢ćÕ║ōńÜäõ╗śĶ┤╣õĖŗĶĮĮķÖÉÕłČŃĆéÕ«ēĶŻģ...
õ╝Āń╗¤õĖŖ’╝īńÜ«ĶéżńŚģńÜäńĪ«Ķ»ŖķĆÜÕĖĖõŠØĶĄ¢õ║ÄńÜ«ĶéżķĢ£µłÉÕāŵŖƵ£»’╝īĶ┐Öµś»õĖĆń¦ŹķØ×õŠĄÕģźµĆ¦ńÜ䵳ÉÕāŵ¢╣µ│Ģ’╝īĶāĮÕż¤µÅÉõŠøķ½śĶ┤©ķćÅńÜäńÜ«ĶéżµöŠÕż¦ÕøŠÕāÅ’╝īµ£ēÕŖ®õ║ĵÅÉķ½śĶ»Ŗµ¢ŁÕćåńĪ«µĆ¦ŃĆéńäČĶĆī’╝īķÜÅńØĆńÜ«ĶéżķĢ£ÕøŠÕāŵĢ░µŹ«ķćÅńÜäĶ┐ģķƤÕó×ķĢ┐’╝īõ╝Āń╗¤ńÜäµēŗÕŖ©ńŁøµ¤źµ¢╣Õ╝ÅÕÅśÕŠŚĶČŖµØźĶČŖõĖŹÕÅ»ĶĪī’╝ī...
µÉ£ń┤óÕ╝Ģµōĵś»õ║ÆĶüöńĮæõĖŖõĖŹÕÅ»µł¢ń╝║ńÜäõ┐Īµü»µŻĆń┤óÕĘźÕģĘ’╝īÕ«āķĆÜĶ┐ćÕżŹµØéńÜäń«Śµ│ĢÕÆīµŖƵ£»’╝īÕĖ«ÕŖ®ńö©µłĘÕ£©µĄĘķćÅńÜäńĮæķĪĄŃĆüµ¢ćµĪŻŃĆüÕøŠńēćŃĆüĶ¦åķóæńŁēµĢ░µŹ«õĖŁÕ┐½ķƤµēŠÕł░µēĆķ£ĆńÜäõ┐Īµü»ŃĆéµÉ£ń┤óÕ╝ĢµōÄńÜäÕ¤║µ£¼ÕĘźõĮ£µĄüń©ŗÕīģµŗ¼ńł¼ÕÅ¢ŃĆüń┤óÕ╝ĢŃĆüÕŁśÕé©ÕÆīµ¤źĶ»óÕøøõĖ¬õĖ╗Ķ”üķśČµ«ĄŃĆé 1. *...
ķÜÅńØĆõ║ÆĶüöńĮæµŖƵ£»ńÜäÕÅæÕ▒Ģ’╝īÕż¦ķćÅńÜäÕ£©ń║┐µ£ŹÕŖĪķ£ĆĶ”üÕżäńÉåµĄĘķćŵĢ░µŹ«ŃĆéńē╣Õł½µś»Õ£©ńżŠõ║żÕ¬ÆõĮōŃĆüÕ£©ń║┐µĢÖĶé▓ńŁēķóåÕ¤¤’╝īÕ”éõĮĢķ½śµĢłÕ£░ń«ĪńÉåÕÆīń╗¤Ķ«Īńö©µłĘńÜäĶĪīõĖ║µĢ░µŹ«ÕÅśÕŠŚÕ░żõĖ║ķćŹĶ”üŃĆéÕģČõĖŁ’╝īŌĆ£ńŁŠÕł░ŌĆØõĮ£õĖ║õĖĆķĪ╣ÕĖĖĶ¦üõĖöķćŹĶ”üńÜäńö©µłĘĶĪīõĖ║’╝īÕģČń╗¤Ķ«ĪõĖÄń«ĪńÉåńø┤µÄźÕĮ▒ÕōŹ...
6. **ń¦»ÕłåõĖÄń¦»Õłåµ¢╣ń©ŗ**’╝ܵÄóĶ«©MATLABÕ£©ń¦»ÕłåĶ«Īń«ŚÕÆīń¦»Õłåµ¢╣ń©ŗµ▒éĶ¦ŻõĖŖńÜäµ¢╣µ│Ģ’╝īÕīģµŗ¼Õ«Üń¦»ÕłåŃĆüõĖŹÕ«Üń¦»ÕłåŃĆüÕŠ«Õłåµ¢╣ń©ŗń╗äńÜäµĢ░ÕĆ╝Ķ¦ŻńŁēŃĆé 7. **õ╝śÕī¢õĖÄķØ×ń║┐µĆ¦µ¢╣ń©ŗµ▒éĶ¦Ż**’╝ܵȥńø¢MATLABńÜäõ╝śÕī¢ÕĘźÕģĘń«▒’╝īĶ«▓Ķ¦Żń║┐µĆ¦ÕÆīķØ×ń║┐µĆ¦µ¢╣ń©ŗń╗äńÜäĶ¦Żµ│Ģ’╝īõ╗źÕÅŖ...
ķØ×õŠĄÕģźÕ╝ÅĶ┤¤ĶŹĘńøæµĄŗ’╝łNILM’╝īNon-Intrusive Load Monitoring’╝ēµś»õĖĆń¦ŹķĆÜĶ┐ćÕłåµ×ɵĢ┤õĮōńöĄÕŖøµČłĶĆŚµØźĶ»åÕł½ÕŹĢõĖ¬Ķ«ŠÕżćĶ┤¤ĶŹĘńÜäµŖƵ£»’╝īµŚĀķ£ĆÕ£©µ»ÅõĖ¬Ķ«ŠÕżćõĖŖÕ«ēĶŻģķóØÕż¢ńÜäõ╝Āµä¤ÕÖ©µł¢Ķ«ĪķćÅĶ«ŠÕżć’╝īµ×üÕż¦Õ£░ķÖŹõĮÄõ║åµłÉµ£¼ÕÆīÕ«×µ¢ĮķÜŠÕ║”ŃĆéĶ»źµŖƵ£»Õ╣┐µ│øÕ║öńö©õ║ĵÖ║ĶāĮ...
ń¤Łń¤ŁÕćĀõĖ¬µ£łÕåģ’╝īÕģ©ńÉāĶīāÕø┤ÕåģÕ░▒ĶüÜķøåõ║åÕż¦ķćÅńö©µłĘŃĆé - **Õ╣┐µ│øÕ║öńö©**’╝ÜMathematicaÕøĀÕģČÕ╝║Õż¦ńÜäÕŖ¤ĶāĮÕÆīµśōńö©µĆ¦’╝īÕĘ▓Ķó½Õ╣┐µ│øÕ║öńö©õ║ÄÕĘźõĖÜŃĆüµĢÖĶé▓ńŁēÕżÜõĖ¬ķóåÕ¤¤ŃĆéÕ«āõĖŹõ╗ģõ┐āĶ┐øõ║åķ½śń║¦µĢ░ÕŁ”ÕÆīĶ«Īń«ŚÕ£©õ╝Āń╗¤ķØ×µŖƵ£»ķóåÕ¤¤ńÜäµÖ«ÕÅŖ’╝īĶ┐śµ×üÕż¦Õ£░µŗōÕ▒Ģõ║åń¦æµŖĆ...