jacky-zhang
- 浏览: 317656 次
- 性别:

- 来自: 成都
-

文章分类
最新评论
-
a455642158:
xiajy 写道他妈的都该名字了,更可恶的金山手机助手是:sj ...
解决ADB server didn't ACK问题 -
wwt455653509:
关闭tadb.exe,重启eclipse搞定
解决ADB server didn't ACK问题 -
Frederic:
感谢,真是帮了大忙!腾讯
解决ADB server didn't ACK问题 -
xiajy:
他妈的都该名字了,更可恶的金山手机助手是:sjk_daemon ...
解决ADB server didn't ACK问题 -
xiaofeilv321:
赞同
解决ADB server didn't ACK问题
Monitoring Bandwidth
The ability to monitor the effective bandwidth previously seen by an application directly supports the ability to adapt to variable runtime environments. Some bandwidth measures that may be valuable to an adaptive distributed system are:
*
Average data throughput rate over a given time period
*
Total data throughput over a given time period
*
Estimate of time until a given amount of data will be available
*
Other first- and second-order statistics on data rate and throughput over time (variances, median rate, data "acceleration," or change in throughput rate, etc.).
Ideally, we would like to capture these bandwidth measures in real time, or as close to real time as we can get, and we would like to have these measures in terms of both raw (unprocessed) data throughput and real (application) data throughput.
The DataMonitor class shown in Example 8-1 provides a container for holding byte counts of data (either inbound or outbound), along with corresponding start and stop times. The start and stop times log the time interval for the data transaction. The DataMonitor provides an addSample() method for adding bandwidth measurement samples. Each of these samples is interpreted as being the number of bytes processed since the last sample, and the time interval during which the data was processed. Once a number of samples have been collected by the DataMonitor, it can be queried for statistics about the historical data rate. In this example we only show three methods offering basic measurements of data throughput: one provides the average data rate for all samples stored in the monitor (getAverageRate()), another provides the data rate for any given sample stored in the monitor (getRateFor()), and the third returns the data rate for the last sample stored (getLastRate()).
Example 8-1. A Data Monitoring Class
8.4.1. Raw Data Monitoring
Logically, in order to monitor the raw data throughput of our local agent, we need to put a "bytemeter" on the input and output streams used to transmit data. The RTInputStream and RTOutputStream classes shown in Examples Example 8-2 and Example 8-3 are extensions of FilterInputStream and FilterOutputStream that monitor their own data rates using the DataMonitor class. After each read() and write() operation, a data point is stored in the stream's DataMonitor. During the course of a transaction, the agent can query the stream for statistics on its throughput over time.
Example 8-2. A Self-Monitoring Input Stream
Example 8-3. A Self-Monitoring Output Stream
One problem with monitoring resource usage is that measuring resources affects the measurements themselves (along the lines of the Hiesenberg Uncertainty Principle). In our case, adding more operations for gathering measurements of data rates can affect the rate that we send and receive data. In our RTInputStream, for example, we've added three operations to the read() method from FilterInputStream:
Suppose we are streaming an audio file from a server for local, real-time playback. If we assume that data I/O, decoding, and writing to the local audio device are all done from a single thread, then the flow of control over time is fairly simple: some data is read in, which takes a finite amount of time. This data is decoded and converted to a format suitable for our audio device. Then the audio data is written to the audio device, and more data is read in to start the cycle over again. In this case, the effective raw data input rate for the system over one read/decode/write cycle is the total amount of data read (dT), divided by the sum of the times for the reading (tr), decoding (td) and writing (tw) of the data:
figure
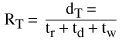
Now suppose we use the RTInputStream to monitor the raw data rate that we see from the server in order to react to overflow or underflow of our buffers. Each read() operation now carries the additional overhead of registering a data sample with the DataMonitor on the RTInputStream (tc). So our net data rate is modified by the addition of this term:
figure
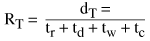
Ideally, the time to register a measurement is negligible compared to the time allocated to reading, decoding, and writing data, so that the effect of measuring on the data rate is minimized. One way to accomplish this is to read and process large amounts of data in each cycle (take relatively few data rate measurements). This hinders our ability to track data rate variations over time, relying instead on rate averages over significant stretches of time. The opposite approach is to ignore the effect of data monitoring, and read very small packets of data in each cycle, resulting in many rate measurements over time. This will cause a larger negative impact on the data rate itself. The art of effective data throughput monitoring lies in achieving a good compromise between these two positions: gather enough information to make reasonable judgements about the state of our bandwidth resources, but limit the information collection process so that the impact on the data rate is bearable.
8.4.2. Real Data Monitoring
A measurement of the raw data throughput our local agent is seeing only tells us how well we are pushing or pulling data at the network level. It doesn't tell us anything about whether our local data processing is keeping up with the network requirements of the system. For example, we may be pulling encoded audio data from the network fast enough, but if decoding that data takes longer than expected, then the playback quality may suffer from skips and silent gaps as our local buffers for holding raw data overflow, or our buffers for holding decoded data underflow. To detect and react to these situations, we need to be able to monitor real data throughput: the rate at which we are processing data from its format on the network to a format suitable for the local application, and vice versa.
With a basic data monitoring facility in place, such as our DataMonitor class, we can construct an infrastructure for monitoring the production and consumption of real application data. Data flowing into an agent from the network is generally filtered in some way before being displayed, saved, or otherwise used locally. Similarly, local data is typically filtered before being sent out on the network to another agent. These filters may compress, modify, or subdivide the data passed through them, for example. We can think of these filters as content producers, consumers, or both, depending on our perspective and their roles in the local agent. These producers and consumers are data processors that are wrapped around data input and output streams.
One way to construct this infrastructure is to develop basic interfaces for these content consumers and producers, which include the ability to monitor the rate at which data is consumed or produced. Example 8-4 shows a ContentConsumer class and Example 8-5 shows a ContentProducer class that demonstrates this idea. A ContentConsumer accepts data and consumes it, which can mean various things depending on the circumstances. A consumer may display data on the screen, store data in a database or file, or it may feed some kind of analysis engine. A ContentProducer generates data (perhaps by asking a user for manual input) by pulling data from persistent storage, or as a product of some processing by another producer. Both classes contain a source that is a ContentProducer, and a destination that is a ContentConsumer. This allows for chaining consumers and producers together to form data processing pipelines. The source of a ContentConsumer is the ContentProducer that is feeding it data, and its destination is the next consumer in the pipeline. The source of a ContentProducer is the previous producer in the pipeline, and its destination is a consumer to which it can feed data.
Example 8-4. A Content Consumer Class
Example 8-5. A Content Producer Class
The ContentConsumer has consume() and consumeAll() methods. The consumeAll() method accepts no arguments, and its default implementation consumes data from its producer until it is exhausted. The consume() method accepts a data buffer in the form of a byte array, and consumes the data by calling its preConsume(), doConsume(), and postConsume() methods. The default implementation of the preConsume() method does nothing, but can be overridden in subclasses to prepare for the consumption process (e.g., open the database connection, connect to the display device, etc.). The default doConsume() method simply writes the data to the next consumer in the chain, if present, but could be overridden to store data in a database, draw data to a display device, etc. The default postConsume() method also does nothing, but can be overridden to clean up after the data is consumed (e.g., close the database connection, disconnect from the display device, etc.). In addition to calling these methods, the consume() method also creates a data sample for the Data-Monitor associated with the consumer. The start of the consume() method is noted, the consumption methods are called in order, the finish time is noted, and the sample is given to the DataMonitor for recording.
A ContentProducer has produce() and produceAll() methods that are analogous to the consume() and consumeAll() methods on Content-Consumer. The produceAll() method produces data and passes it to the destination consumer, if present, until the producer is exhausted. The produce() method generates a chunk of data by calling the preProduction(), doProduction(), and postProduction() methods. The default preProduction() and postProduction() methods do nothing, and the default doProduction() method simply requests a data chunk from the previous producer in the chain, if present.
Using these classes, we can construct both consumption pipelines and production pipelines that monitor their data throughput. For example, we can create a consumption pipeline that sends an input data stream to replicated databases on the network:
Once the replication process is finished, we can ask each consumer for its estimated average bandwidth to get a feel for the quality of our connection to each database. We could also monitor the bandwidth levels during the replication process if we wanted to try to optimize the process, perhaps by dropping off databases with unreasonably slow connections.
We can also create production pipelines. For example, we could generate a graphics pipeline where image data from a file is sequentially modified with various effects to produce a finished image that is displayed on the screen:
We can also monitor both raw and real data rates if we want to compare the two. Suppose we feed our image processing pipeline with an image read from an InputStream; we can wrap the input stream with an RTInputStream to monitor the rate of the "raw" image data flowing into the pipeline:
During or after the image processing, we can monitor the estimated rate of raw image input, or the rate of processed data production at any point in the pipeline.
Creating explicit representations of content consumers and producers is necessary only because we are discussing environments in which bandwidth is the limiting factor. Applications that deal with data in any way (which all applications do) can be broken down logically into data consumers and producers, and many of the objects that are defined to implement a system can be thought of as producers or consumers of data, or both. For example, in our scheduling database system from Chapter 7, "Databases" we could consider the SchedResource class as both a producer and consumer of data, since it both delivered data from the schedule database to the local agent and delivered data from the local agent to the database when the parameters of the resource object were updated. It is only our need to monitor the flow of data that makes it valuable for us to represent our data flow with producer and consumer classes.
The sourcehttp://docstore.mik.ua/orelly/java-ent/dist/ch08_04.htm
The ability to monitor the effective bandwidth previously seen by an application directly supports the ability to adapt to variable runtime environments. Some bandwidth measures that may be valuable to an adaptive distributed system are:
*
Average data throughput rate over a given time period
*
Total data throughput over a given time period
*
Estimate of time until a given amount of data will be available
*
Other first- and second-order statistics on data rate and throughput over time (variances, median rate, data "acceleration," or change in throughput rate, etc.).
Ideally, we would like to capture these bandwidth measures in real time, or as close to real time as we can get, and we would like to have these measures in terms of both raw (unprocessed) data throughput and real (application) data throughput.
The DataMonitor class shown in Example 8-1 provides a container for holding byte counts of data (either inbound or outbound), along with corresponding start and stop times. The start and stop times log the time interval for the data transaction. The DataMonitor provides an addSample() method for adding bandwidth measurement samples. Each of these samples is interpreted as being the number of bytes processed since the last sample, and the time interval during which the data was processed. Once a number of samples have been collected by the DataMonitor, it can be queried for statistics about the historical data rate. In this example we only show three methods offering basic measurements of data throughput: one provides the average data rate for all samples stored in the monitor (getAverageRate()), another provides the data rate for any given sample stored in the monitor (getRateFor()), and the third returns the data rate for the last sample stored (getLastRate()).
Example 8-1. A Data Monitoring Class
package dcj.util.Bandwidth;
import java.util.Vector;
import java.util.Date;
import java.util.Enumeration;
class DataSample {
long byteCount;
Date start;
Date end;
DataSample(long bc, Date ts, Date tf) {
byteCount = bc;
start = ts;
end = tf;
}
}
public class DataMonitor {
protected Vector samples;
protected Date epoch;
public DataMonitor() {
samples = new Vector();
epoch = new Date();
}
// Add a sample with a start and finish time.
public void addSample(long bcount, Date ts, Date tf) {
samples.addElement(new DataSample(bcount, ts, tf));
}
// Get the data rate of a given sample.
public float getRateFor(int sidx) {
float rate = 0.0;
int scnt = samples.size();
if (scnt > sidx && sidx >= 0) {
DataSample s = samples.elementAt(sidx);
Date start = s.start;
Date end = s.end;
if (start == null && sidx >= 1) {
DataSample prev = samples.elementAt(sidx - 1);
start = prev.end;
}
if (start != null && end != null) {
long msec = end.getTime() - start.getTime();
rate = 1000 * (float)s.byteCount / (float)msec;
}
}
return rate;
}
// Get the rate of the last sample
public float getLastRate() {
int scnt = samples.size();
return getRateFor(scnt - 1);
}
// Get the average rate over all samples.
public float getAverageRate() {
long msCount = 0;
long byteCount = 0;
Date start;
Date finish;
int scnt = samples.size();
for (int i = 0; i < scnt; i++) {
DataSample ds = (DataSample)samples.elementAt(i);
if (ds.start != null)
start = ds.start;
else if (i > 0) {
DataSample prev = (DataSample)samples.elementAt(i-1);
start = ds.end;
}
else
start = epoch;
if (ds.end != null)
finish = ds.end;
else if (i < scnt - 1) {
DataSample next = (DataSample)samples.elementAt(i+1);
finish = ds.start;
}
else
finish = new Date();
// Only include this sample if we could figure out a start
// and finish time for it.
if (start != null && finish != null) {
byteCount += ds.byteCount;
msCount += finish.getTime() - start.getTime();
}
}
float rate = -1;
if (msCount > 0) {
rate = 1000 * (float)byteCount / (float)msCount;
}
return rate;
}
}
8.4.1. Raw Data Monitoring
Logically, in order to monitor the raw data throughput of our local agent, we need to put a "bytemeter" on the input and output streams used to transmit data. The RTInputStream and RTOutputStream classes shown in Examples Example 8-2 and Example 8-3 are extensions of FilterInputStream and FilterOutputStream that monitor their own data rates using the DataMonitor class. After each read() and write() operation, a data point is stored in the stream's DataMonitor. During the course of a transaction, the agent can query the stream for statistics on its throughput over time.
Example 8-2. A Self-Monitoring Input Stream
package dcj.util.Bandwidth;
import java.io.InputStream;
import java.io.FilterInputStream;
import java.util.Date;
import java.io.IOException;
public class RTInputStream extends FilterInputStream {
DataMonitor monitor;
RTInputStream(InputStream in) {
super(in);
monitor = new DataMonitor();
}
public int read() throws IOException {
Date start = new Date();
int b = super.read();
monitor.addSample(1, start, new Date());
return b;
}
public int read(byte data[]) throws IOException {
Date start = new Date();
int cnt = super.read(data);
monitor.addSample(cnt, start, new Date());
return cnt;
}
public int read(byte data[], int off, int len)
throws IOException {
Date start = new Date();
int cnt = super.read(data, off, len);
monitor.addSample(cnt, start, new Date());
return cnt;
}
public float averageRate() {
return monitor.getAverageRate();
}
public float lastRate() {
return monitor.getLastRate();
}
}
Example 8-3. A Self-Monitoring Output Stream
package dcj.util.Bandwidth;
import java.io.OutputStream;
import java.io.FilterOutputStream;
import java.util.Date;
import java.io.IOException;
public class RTOutputStream extends FilterOutputStream {
DataMonitor monitor;
RTOutputStream(OutputStream out) {
super(out);
monitor = new DataMonitor();
}
public void write(int b) throws IOException {
Date start = new Date();
super.write(b);
monitor.addSample(1, start, new Date());
}
public void write(byte data[]) throws IOException {
Date start = new Date();
super.write(data);
monitor.addSample(data.length, start, new Date());
}
public void write(byte data[], int off, int len)
throws IOException {
Date start = new Date();
super.write(data, off, len);
monitor.addSample(data.length, start, new Date());
}
public float averageRate() {
return monitor.getAverageRate();
}
public float lastRate() {
return monitor.getLastRate();
}
}
One problem with monitoring resource usage is that measuring resources affects the measurements themselves (along the lines of the Hiesenberg Uncertainty Principle). In our case, adding more operations for gathering measurements of data rates can affect the rate that we send and receive data. In our RTInputStream, for example, we've added three operations to the read() method from FilterInputStream:
public int read() throws IOException {
Date start = new Date();
int b = super.read();
monitor.addSample(1, start, new Date());
return b;
}
Suppose we are streaming an audio file from a server for local, real-time playback. If we assume that data I/O, decoding, and writing to the local audio device are all done from a single thread, then the flow of control over time is fairly simple: some data is read in, which takes a finite amount of time. This data is decoded and converted to a format suitable for our audio device. Then the audio data is written to the audio device, and more data is read in to start the cycle over again. In this case, the effective raw data input rate for the system over one read/decode/write cycle is the total amount of data read (dT), divided by the sum of the times for the reading (tr), decoding (td) and writing (tw) of the data:
figure
Now suppose we use the RTInputStream to monitor the raw data rate that we see from the server in order to react to overflow or underflow of our buffers. Each read() operation now carries the additional overhead of registering a data sample with the DataMonitor on the RTInputStream (tc). So our net data rate is modified by the addition of this term:
figure
Ideally, the time to register a measurement is negligible compared to the time allocated to reading, decoding, and writing data, so that the effect of measuring on the data rate is minimized. One way to accomplish this is to read and process large amounts of data in each cycle (take relatively few data rate measurements). This hinders our ability to track data rate variations over time, relying instead on rate averages over significant stretches of time. The opposite approach is to ignore the effect of data monitoring, and read very small packets of data in each cycle, resulting in many rate measurements over time. This will cause a larger negative impact on the data rate itself. The art of effective data throughput monitoring lies in achieving a good compromise between these two positions: gather enough information to make reasonable judgements about the state of our bandwidth resources, but limit the information collection process so that the impact on the data rate is bearable.
8.4.2. Real Data Monitoring
A measurement of the raw data throughput our local agent is seeing only tells us how well we are pushing or pulling data at the network level. It doesn't tell us anything about whether our local data processing is keeping up with the network requirements of the system. For example, we may be pulling encoded audio data from the network fast enough, but if decoding that data takes longer than expected, then the playback quality may suffer from skips and silent gaps as our local buffers for holding raw data overflow, or our buffers for holding decoded data underflow. To detect and react to these situations, we need to be able to monitor real data throughput: the rate at which we are processing data from its format on the network to a format suitable for the local application, and vice versa.
With a basic data monitoring facility in place, such as our DataMonitor class, we can construct an infrastructure for monitoring the production and consumption of real application data. Data flowing into an agent from the network is generally filtered in some way before being displayed, saved, or otherwise used locally. Similarly, local data is typically filtered before being sent out on the network to another agent. These filters may compress, modify, or subdivide the data passed through them, for example. We can think of these filters as content producers, consumers, or both, depending on our perspective and their roles in the local agent. These producers and consumers are data processors that are wrapped around data input and output streams.
One way to construct this infrastructure is to develop basic interfaces for these content consumers and producers, which include the ability to monitor the rate at which data is consumed or produced. Example 8-4 shows a ContentConsumer class and Example 8-5 shows a ContentProducer class that demonstrates this idea. A ContentConsumer accepts data and consumes it, which can mean various things depending on the circumstances. A consumer may display data on the screen, store data in a database or file, or it may feed some kind of analysis engine. A ContentProducer generates data (perhaps by asking a user for manual input) by pulling data from persistent storage, or as a product of some processing by another producer. Both classes contain a source that is a ContentProducer, and a destination that is a ContentConsumer. This allows for chaining consumers and producers together to form data processing pipelines. The source of a ContentConsumer is the ContentProducer that is feeding it data, and its destination is the next consumer in the pipeline. The source of a ContentProducer is the previous producer in the pipeline, and its destination is a consumer to which it can feed data.
Example 8-4. A Content Consumer Class
package dcj.util.Bandwidth;
import java.io.InputStream;
import java.io.OutputStream;
public class ContentConsumer
{
protected ContentProducer source = null;
protected ContentConsumer dest = null;
protected DataMonitor monitor = new DataMonitor();
public ContentConsumer(ContentProducer src) {
source = src;
}
public ContentConsumer(ContentConsumer dst) {
dest = dst;
}
public void setSource(ContentProducer p) {
source = p;
}
public void setDest(ContentConsumer c) {
dest = c;
}
// Consume data from our producer until it is exhausted.
public boolean consumeAll() {
boolean success = false;
if (source != null) {
byte[] data = source.produce(0);
while (data != null) {
success = consume(data);
data = source.produce(0);
}
}
return success;
}
// Consume a chunk of data
public boolean consume(byte[] data) {
// Log the start of the consumption cycle
Date start = new Date();
boolean success;
success = preConsume(data);
if (success)
success = doConsume(data);
if (success)
success = postConsume(data);
// Mark the end of our consumption cycle
monitor.addSample(data.length, start, new Date());
// Pass the data on to the next consumer in the chain,
// if present.
if (dest != null) {
dest.consume(data);
}
return success;
}
protected boolean preConsume(byte[] data) {
return true;
}
// Default consumption procedure.
protected boolean doConsume(byte[] data) {
return true;
}
// Default post-consumption procedure: log the data consumption
// size and finish time with our monitor.
protected boolean postConsume(byte[] data) {
return true;
}
}
Example 8-5. A Content Producer Class
package dcj.util.Bandwidth;
import java.io.InputStream;
import java.io.OutputStream;
public class ContentProducer
{
protected ContentProducer source = null;
protected ContentConsumer dest = null;
protected DataMonitor monitor = new DataMonitor();
public ContentProducer(ContentProducer src) {
source = src;
}
public ContentProducer(ContentConsumer dst) {
dest = dst;
}
public void setSource(ContentProducer p) {
source = p;
}
public void setDest(ContentConsumer c) {
dest = c;
}
// Produce data and pass it to our destination, if present.
public boolean produceAll() {
boolean success = false;
if (dest != null) {
byte[] data = produce();
while (data != null) {
success = dest.consume(data);
if (success)
data = produce();
else
data = null;
}
}
return success;
}
// Produce a chunk of data, within the given limit.
public byte[] produce(long limit) {
// Record the start time.
Date start = new Date();
boolean success;
byte[] data = null;
success = preProduction(limit);
if (success)
data = doProduction(limit);
if (success && data != null)
success = postProduction(data, limit);
// Record the data sample in our monitor.
monitor.addSample(data.length, start, new Date());
// Pass the data on to our destination, if present
if (data != null && dest != null)
dest.consume(data);
return data;
}
// Default preconsumption procedure.
protected boolean preProduction(long limit) {
return true;
}
// Default production procedure: ask for data from our source,
// if present, and pass along unmodified (e.g., a no-op).
protected byte[] doProduction(long limit) {
byte[] data = null;
if (source != null) {
data = source.produce(limit);
}
return data;
}
// Default postconsumption procedure.
protected boolean postProduction(byte[] data, long limit) {
return true;
}
}
The ContentConsumer has consume() and consumeAll() methods. The consumeAll() method accepts no arguments, and its default implementation consumes data from its producer until it is exhausted. The consume() method accepts a data buffer in the form of a byte array, and consumes the data by calling its preConsume(), doConsume(), and postConsume() methods. The default implementation of the preConsume() method does nothing, but can be overridden in subclasses to prepare for the consumption process (e.g., open the database connection, connect to the display device, etc.). The default doConsume() method simply writes the data to the next consumer in the chain, if present, but could be overridden to store data in a database, draw data to a display device, etc. The default postConsume() method also does nothing, but can be overridden to clean up after the data is consumed (e.g., close the database connection, disconnect from the display device, etc.). In addition to calling these methods, the consume() method also creates a data sample for the Data-Monitor associated with the consumer. The start of the consume() method is noted, the consumption methods are called in order, the finish time is noted, and the sample is given to the DataMonitor for recording.
A ContentProducer has produce() and produceAll() methods that are analogous to the consume() and consumeAll() methods on Content-Consumer. The produceAll() method produces data and passes it to the destination consumer, if present, until the producer is exhausted. The produce() method generates a chunk of data by calling the preProduction(), doProduction(), and postProduction() methods. The default preProduction() and postProduction() methods do nothing, and the default doProduction() method simply requests a data chunk from the previous producer in the chain, if present.
Using these classes, we can construct both consumption pipelines and production pipelines that monitor their data throughput. For example, we can create a consumption pipeline that sends an input data stream to replicated databases on the network:
ContentProducer input = new MyProducer(host, port);
ContentConsumer dbase1 =
new RDBMSConsumer("jdbc:odbc://dbhost/mydata");
input.setDest(dbase1);
ContentConsumer dbase2 = ...;
dbase1.setDest(dbase2);
...
input.produceAll();
Once the replication process is finished, we can ask each consumer for its estimated average bandwidth to get a feel for the quality of our connection to each database. We could also monitor the bandwidth levels during the replication process if we wanted to try to optimize the process, perhaps by dropping off databases with unreasonably slow connections.
We can also create production pipelines. For example, we could generate a graphics pipeline where image data from a file is sequentially modified with various effects to produce a finished image that is displayed on the screen:
ContentProducer source = new FileProducer("source.jpg");
ContentProducer effect1 = new BlurEffect();
effect1.setSource(source);
ContentProducer effect2 = new GrainEffect();
effect2.setSource(effect1);
ContentConsumer display = new ScreenConsumer();
display.setSource(effect2);
display.consumeAll();
We can also monitor both raw and real data rates if we want to compare the two. Suppose we feed our image processing pipeline with an image read from an InputStream; we can wrap the input stream with an RTInputStream to monitor the rate of the "raw" image data flowing into the pipeline:
InputStream imgStream = ...;
RTInputStream rtStream = new RTInputStream(imgStream);
ContentProducer source = new StreamProducer(rtStream);
...
During or after the image processing, we can monitor the estimated rate of raw image input, or the rate of processed data production at any point in the pipeline.
Creating explicit representations of content consumers and producers is necessary only because we are discussing environments in which bandwidth is the limiting factor. Applications that deal with data in any way (which all applications do) can be broken down logically into data consumers and producers, and many of the objects that are defined to implement a system can be thought of as producers or consumers of data, or both. For example, in our scheduling database system from Chapter 7, "Databases" we could consider the SchedResource class as both a producer and consumer of data, since it both delivered data from the schedule database to the local agent and delivered data from the local agent to the database when the parameters of the resource object were updated. It is only our need to monitor the flow of data that makes it valuable for us to represent our data flow with producer and consumer classes.
The sourcehttp://docstore.mik.ua/orelly/java-ent/dist/ch08_04.htm
分享到:


发表评论

-
Ftp多线程下载
2011-02-23 17:50 1094Ftp协议支持REST和RETR指令,可以用这两个指令来指定要 ... -
ftp and firewalls
2011-01-10 10:58 1184The File Transfer Protocol (FTP ... -
限制上传和下载
2010-12-29 16:32 1026不多说了,自己看吧 public class FlowCont ... -
通过代理访问一些网址
2010-11-11 14:14 1417import java.io.IOException; im ... -
程序中的常见异常
2007-12-14 09:41 10871. java.lang.NullPointerExcepti ...
相关推荐
在安装Bandwidth Splitter后,管理员可以通过配置界面(如"shaping rules"、"quota rules"、"quota counters"和"monitoring"等)进行设置,实现带宽管理和流量限制策略。通过这些功能,企业可以有效地节约网络成本,...
bandwidth with SNMP using the RRDTool engine—developed by Tobi Oeticker who is already the creator of the famous MRTG. RRDtool is a program developed in C and it stores collected data on .rrd files...
set -g @plugin 'xamut/tmux-network-bandwidth' 按prefix + I提取插件并获取其源代码。 完毕。 手动的 在某个地方克隆仓库。 在.tmux.conf添加run-shell : run-shell PATH_TO_REPO/tmux-network-bandwidth.tmux...
`ping-check.sh` 可能用于验证到特定服务器的连通性,而`bandwidth.sh` 可能用于记录和报告网络流量。 3. **服务监控**:针对特定服务的脚本,如HTTP、SMTP或数据库服务,确保它们正常运行并响应请求。`...
在安装和配置Bandwidth Splitter后,管理员可以在ISA Server的控制面板中直观地看到相关设置,包括导入和导出配置,创建和编辑流量整形规则(shaping rules)、配额规则(quota rules)、配额计数器(quotacounters...
监控(Monitoring)** 监控功能是Bandwidth Splitter的重要部分,它可以显示每台计算机的实时流量、连接数以及其他详细信息,如协议、目标主机IP和端口等。这有助于管理员及时发现并解决网络性能问题。 除了上述...
This paper presents a passive monitoring mechanism, lossy nodes inference (LoNI), to identify lossy nodes in wireless sensor network using end-to-end application traffic. Given topology dynamics ...
- **Control and Status Partition:** Registers for controlling and monitoring the host controller. - **Memory Pointer Partition:** Registers pointing to various memory areas used by the host controller...
1. 网络性能监控(Network Performance Monitoring):带宽测量(Bandwidth Gauges )、路由CPU负荷(Router CPU Load)、带宽监控(Bandwidth Monitor)、CPU测量(CPU Gauge)、网络性能监控器(Network ...
Configurable alarms can notify you about important events, such as suspicious packets, high bandwidth utilization, or unknown addresses. CommView includes a VoIP module for in-depth analysis, ...
1. 网络性能监控(Network Performance Monitoring):带宽测量(Bandwidth Gauges )、路由CPU负荷(Router CPU Load)、带宽监控(Bandwidth Monitor)、CPU测量(CPU Gauge)、网络性能监控器(Network ...
Wide sensor bandwidth: 330 Hz Autonomous operation and data collection No external configuration commands required Start-up time: 180 ms Factory-calibrated sensitivity, bias, and axial alignment ...
The calibration results show that axis sensitivity is 45 dB (re: 0 dB = 1 rad/g), with a fluctuation less than 0.9 dB in a frequency bandwidth of 10–450 Hz. The cross sensitivity
Monitoring tool that meets the following requirements • The client should ping the server with a specified time t • The server should support multiple clients’ requests • As a ...
Configurable alarms can notify you about important events, such as suspicious packets, high bandwidth utilization, or unknown addresses. CommView includes a VoIP module for in-depth analysis, ...
OpenWRT的带宽跟踪器 该Luci模块使用跟踪带宽使用情况。 特征 每5秒自动刷新一次(可以更改) 跟踪每个客户端的速度(如果启用了自动刷新) 不需要cron作业(wrtbwmon可按需更新) ... 能够在重新启动和固件更新...
6. **缓存和内存监控技术**:CMT(Cache Monitoring Technology)、MBM(Memory Bandwidth Monitoring)和CAT(Cache Allocation Technology)以及CDP(Code and Data Prioritization)是Intel提供的硬件框架,用于...
3. RLM(Radio Link Monitoring,无线链路监控)只能在DLBWP(Downlink Bandwidth Part,下行子载波带宽部分)上执行。这是因为RLM主要涉及下行链路的质量评估,以判断是否存在链路质量下降或中断的情况。 4. TCI...
bandwidth limiting, and automatic anti-anti-time-out plus anti-hammering measures. * Can run as a 'system service' in Windows 95 and a tray-icon in Windows 95, Windows 98, and NT 4. * Users can...