жқҘжәҗпјҡhttp://www.cnblogs.com/kevinyang/archive/2009/02/01/1381803.html
еҸ‘иЎЁиҖ…пјҡGoogleпјҲи°·жӯҢпјүз ”з©¶е‘ҳ еҗҙеҶӣ
еңЁ ж—Ҙеёёз”ҹжҙ»дёӯпјҢеҢ…жӢ¬еңЁи®ҫи®Ўи®Ўз®—жңәиҪҜ件时пјҢжҲ‘们з»ҸеёёиҰҒеҲӨж–ӯдёҖдёӘе…ғзҙ жҳҜеҗҰеңЁдёҖдёӘйӣҶеҗҲдёӯгҖӮжҜ”еҰӮеңЁеӯ—еӨ„зҗҶиҪҜ件дёӯпјҢйңҖиҰҒжЈҖжҹҘдёҖдёӘиӢұиҜӯеҚ•иҜҚжҳҜеҗҰжӢјеҶҷжӯЈзЎ®пјҲд№ҹе°ұжҳҜиҰҒеҲӨж–ӯе®ғ жҳҜеҗҰеңЁе·ІзҹҘзҡ„еӯ—е…ёдёӯпјүпјӣеңЁ FBIпјҢдёҖдёӘе«Ңз–‘дәәзҡ„еҗҚеӯ—жҳҜеҗҰе·Із»ҸеңЁе«Ңз–‘еҗҚеҚ•дёҠпјӣеңЁзҪ‘з»ңзҲ¬иҷ«йҮҢпјҢдёҖдёӘзҪ‘еқҖжҳҜеҗҰиў«и®ҝй—®иҝҮзӯүзӯүгҖӮжңҖзӣҙжҺҘзҡ„ж–№жі•е°ұжҳҜе°ҶйӣҶеҗҲдёӯе…ЁйғЁзҡ„е…ғзҙ еӯҳеңЁи®Ўз®—жңәдёӯпјҢйҒҮеҲ°дёҖдёӘж–° е…ғзҙ ж—¶пјҢе°Ҷе®ғе’ҢйӣҶеҗҲдёӯзҡ„е…ғзҙ зӣҙжҺҘжҜ”иҫғеҚіеҸҜгҖӮдёҖиҲ¬жқҘи®ІпјҢи®Ўз®—жңәдёӯзҡ„йӣҶеҗҲжҳҜз”Ёе“ҲеёҢиЎЁпјҲhash
tableпјүжқҘеӯҳеӮЁзҡ„гҖӮе®ғзҡ„еҘҪеӨ„жҳҜеҝ«йҖҹеҮҶзЎ®пјҢзјәзӮ№жҳҜиҙ№еӯҳеӮЁз©әй—ҙгҖӮеҪ“йӣҶеҗҲжҜ”иҫғе°Ҹж—¶пјҢиҝҷдёӘй—®йўҳдёҚжҳҫи‘—пјҢдҪҶжҳҜеҪ“йӣҶеҗҲе·ЁеӨ§ж—¶пјҢе“ҲеёҢиЎЁеӯҳеӮЁж•ҲзҺҮдҪҺзҡ„й—®йўҳе°ұжҳҫзҺ°еҮәжқҘ дәҶгҖӮжҜ”еҰӮиҜҙпјҢдёҖдёӘиұЎ Yahoo,Hotmail е’Ң Gmai йӮЈж ·зҡ„е…¬дј—з”өеӯҗйӮ®д»¶пјҲemailпјүжҸҗдҫӣе•ҶпјҢжҖ»жҳҜйңҖиҰҒиҝҮж»ӨжқҘиҮӘеҸ‘йҖҒеһғеңҫйӮ®д»¶зҡ„дәәпјҲspamerпјүзҡ„еһғеңҫйӮ®д»¶гҖӮдёҖдёӘеҠһжі•е°ұжҳҜи®°еҪ•дёӢйӮЈдәӣеҸ‘еһғеңҫйӮ®д»¶зҡ„ email ең°еқҖгҖӮз”ұдәҺйӮЈдәӣеҸ‘йҖҒиҖ…дёҚеҒңең°еңЁжіЁеҶҢж–°зҡ„ең°еқҖпјҢе…Ёдё–з•Ңе°‘иҜҙд№ҹжңүеҮ еҚҒдәҝдёӘеҸ‘еһғеңҫйӮ®д»¶зҡ„ең°еқҖпјҢе°Ҷ他们йғҪеӯҳиө·жқҘеҲҷйңҖиҰҒеӨ§йҮҸзҡ„зҪ‘з»ңжңҚеҠЎеҷЁгҖӮеҰӮжһңз”Ёе“ҲеёҢиЎЁпјҢжҜҸеӯҳеӮЁдёҖдәҝ дёӘ email
ең°еқҖпјҢ е°ұйңҖиҰҒ 1.6GB зҡ„еҶ…еӯҳпјҲз”Ёе“ҲеёҢиЎЁе®һзҺ°зҡ„е…·дҪ“еҠһжі•жҳҜе°ҶжҜҸдёҖдёӘ email ең°еқҖеҜ№еә”жҲҗдёҖдёӘе…«еӯ—иҠӮзҡ„дҝЎжҒҜжҢҮзә№
googlechinablog.com/2006/08/blog-post.htmlпјҢ 然еҗҺе°ҶиҝҷдәӣдҝЎжҒҜжҢҮзә№еӯҳе…Ҙе“ҲеёҢиЎЁпјҢз”ұдәҺе“ҲеёҢиЎЁзҡ„еӯҳеӮЁж•ҲзҺҮдёҖиҲ¬еҸӘжңү 50%пјҢеӣ жӯӨдёҖдёӘ email ең°еқҖйңҖиҰҒеҚ з”ЁеҚҒе…ӯдёӘеӯ—иҠӮгҖӮдёҖдәҝдёӘең°еқҖеӨ§зәҰиҰҒ 1.6GBпјҢ еҚіеҚҒе…ӯдәҝеӯ—иҠӮзҡ„еҶ…еӯҳпјүгҖӮеӣ жӯӨеӯҳиҙ®еҮ еҚҒдәҝдёӘйӮ®д»¶ең°еқҖеҸҜиғҪйңҖиҰҒдёҠзҷҫ GB зҡ„еҶ…еӯҳгҖӮйҷӨйқһжҳҜи¶…зә§и®Ўз®—жңәпјҢдёҖиҲ¬жңҚеҠЎеҷЁжҳҜж— жі•еӯҳеӮЁзҡ„гҖӮ
д»ҠеӨ©пјҢжҲ‘们д»Ӣз»ҚдёҖз§Қз§°дҪңеёғйҡҶиҝҮж»ӨеҷЁзҡ„ж•°еӯҰе·Ҙе…·пјҢе®ғеҸӘйңҖиҰҒе“ҲеёҢиЎЁ 1/8 еҲ° 1/4 зҡ„еӨ§е°Ҹе°ұиғҪи§ЈеҶіеҗҢж ·зҡ„й—®йўҳгҖӮ
еёғйҡҶиҝҮж»ӨеҷЁжҳҜз”ұе·ҙйЎҝ.еёғйҡҶдәҺдёҖд№қдёғйӣ¶е№ҙжҸҗеҮәзҡ„гҖӮе®ғе®һйҷ…дёҠжҳҜдёҖдёӘеҫҲй•ҝзҡ„дәҢиҝӣеҲ¶еҗ‘йҮҸе’ҢдёҖзі»еҲ—йҡҸжңәжҳ е°„еҮҪж•°гҖӮжҲ‘们йҖҡиҝҮдёҠйқўзҡ„дҫӢеӯҗжқҘиҜҙжҳҺиө·е·ҘдҪңеҺҹзҗҶгҖӮ
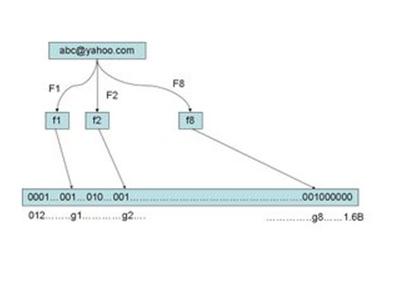
еҒҮ е®ҡжҲ‘们еӯҳеӮЁдёҖдәҝдёӘз”өеӯҗйӮ®д»¶ең°еқҖпјҢжҲ‘们е…Ҳе»әз«ӢдёҖдёӘеҚҒе…ӯдәҝдәҢиҝӣеҲ¶пјҲжҜ”зү№пјүпјҢеҚідёӨдәҝеӯ—иҠӮзҡ„еҗ‘йҮҸпјҢ然еҗҺе°ҶиҝҷеҚҒе…ӯдәҝдёӘдәҢиҝӣеҲ¶е…ЁйғЁи®ҫзҪ®дёәйӣ¶гҖӮеҜ№дәҺжҜҸдёҖдёӘз”өеӯҗйӮ®д»¶ең°еқҖ XпјҢжҲ‘们用八дёӘдёҚеҗҢзҡ„йҡҸжңәж•°дә§з”ҹеҷЁпјҲF1,F2, ...,F8пјү дә§з”ҹе…«дёӘдҝЎжҒҜжҢҮзә№пјҲf1, f2, ..., f8пјүгҖӮеҶҚз”ЁдёҖдёӘйҡҸжңәж•°дә§з”ҹеҷЁ G жҠҠиҝҷе…«дёӘдҝЎжҒҜжҢҮзә№жҳ е°„еҲ° 1 еҲ°еҚҒе…ӯдәҝдёӯзҡ„е…«дёӘиҮӘ然数 g1, g2, ...,g8гҖӮзҺ°еңЁжҲ‘们жҠҠиҝҷе…«дёӘдҪҚзҪ®зҡ„дәҢиҝӣеҲ¶е…ЁйғЁи®ҫзҪ®дёәдёҖгҖӮеҪ“жҲ‘们еҜ№иҝҷдёҖдәҝдёӘ
email ең°еқҖйғҪиҝӣиЎҢиҝҷж ·зҡ„еӨ„зҗҶеҗҺгҖӮдёҖдёӘй’ҲеҜ№иҝҷдәӣ email ең°еқҖзҡ„еёғйҡҶиҝҮж»ӨеҷЁе°ұе»әжҲҗдәҶгҖӮпјҲи§ҒдёӢеӣҫпјү
зҺ° еңЁпјҢи®©жҲ‘们зңӢзңӢеҰӮдҪ•з”ЁеёғйҡҶиҝҮж»ӨеҷЁжқҘжЈҖжөӢдёҖдёӘеҸҜз–‘зҡ„з”өеӯҗйӮ®д»¶ең°еқҖ Y жҳҜеҗҰеңЁй»‘еҗҚеҚ•дёӯгҖӮжҲ‘们用зӣёеҗҢзҡ„е…«дёӘйҡҸжңәж•°дә§з”ҹеҷЁпјҲF1, F2, ..., F8пјүеҜ№иҝҷдёӘең°еқҖдә§з”ҹе…«дёӘдҝЎжҒҜжҢҮзә№ s1,s2,...,s8пјҢ然еҗҺе°Ҷиҝҷе…«дёӘжҢҮзә№еҜ№еә”еҲ°еёғйҡҶиҝҮж»ӨеҷЁзҡ„е…«дёӘдәҢиҝӣеҲ¶дҪҚпјҢеҲҶеҲ«жҳҜ t1,t2,...,t8гҖӮеҰӮжһң Y еңЁй»‘еҗҚеҚ•дёӯпјҢжҳҫ然пјҢt1,t2,..,t8 еҜ№еә”зҡ„е…«дёӘдәҢиҝӣеҲ¶дёҖе®ҡжҳҜдёҖгҖӮиҝҷж ·еңЁйҒҮеҲ°д»»дҪ•еңЁй»‘еҗҚеҚ•дёӯзҡ„з”өеӯҗйӮ®д»¶ең°еқҖпјҢжҲ‘们йғҪиғҪеҮҶзЎ®ең°еҸ‘зҺ°гҖӮ
еёғйҡҶиҝҮж»ӨеҷЁеҶідёҚдјҡжјҸжҺүд»»дҪ•дёҖдёӘеңЁй»‘еҗҚеҚ•дёӯзҡ„еҸҜ з–‘ең°еқҖгҖӮдҪҶжҳҜпјҢе®ғжңүдёҖжқЎдёҚи¶ід№ӢеӨ„гҖӮд№ҹе°ұжҳҜе®ғжңүжһҒе°Ҹзҡ„еҸҜиғҪе°ҶдёҖдёӘдёҚеңЁй»‘еҗҚеҚ•дёӯзҡ„з”өеӯҗйӮ®д»¶ең°еқҖеҲӨе®ҡдёәеңЁй»‘еҗҚеҚ•дёӯпјҢеӣ дёәжңүеҸҜиғҪжҹҗдёӘеҘҪзҡ„йӮ®д»¶ең°еқҖжӯЈе·§еҜ№еә”дёӘе…«дёӘйғҪ иў«и®ҫзҪ®жҲҗдёҖзҡ„дәҢиҝӣеҲ¶дҪҚгҖӮеҘҪеңЁиҝҷз§ҚеҸҜиғҪжҖ§еҫҲе°ҸгҖӮжҲ‘们жҠҠе®ғз§°дёәиҜҜиҜҶжҰӮзҺҮгҖӮеңЁдёҠйқўзҡ„дҫӢеӯҗдёӯпјҢиҜҜиҜҶжҰӮзҺҮеңЁдёҮеҲҶд№ӢдёҖд»ҘдёӢгҖӮ
еёғйҡҶиҝҮж»ӨеҷЁзҡ„еҘҪеӨ„еңЁдәҺеҝ«йҖҹпјҢзңҒз©әй—ҙгҖӮдҪҶжҳҜжңүдёҖе®ҡзҡ„иҜҜиҜҶеҲ«зҺҮгҖӮеёёи§Ғзҡ„иЎҘж•‘еҠһжі•жҳҜеңЁе»әз«ӢдёҖдёӘе°Ҹзҡ„зҷҪеҗҚеҚ•пјҢеӯҳеӮЁйӮЈдәӣеҸҜиғҪеҲ«иҜҜеҲӨзҡ„йӮ®д»¶ең°еқҖгҖӮ
еҲҶдә«еҲ°пјҡ





зӣёе…іжҺЁиҚҗ
еёғйҡҶиҝҮж»ӨеҷЁжҳҜдёҖз§Қж•°жҚ®з»“жһ„пјҢдё»иҰҒз”ЁдәҺеҲӨж–ӯдёҖдёӘе…ғзҙ жҳҜеҗҰеҸҜиғҪеңЁдёҖдёӘйӣҶеҗҲдёӯеӯҳеңЁгҖӮе®ғеҸҜд»ҘеңЁжҸ’е…Ҙе’ҢжҹҘиҜўж•°жҚ®ж—¶еҝ«йҖҹең°еҲӨж–ӯдёҖдёӘе…ғзҙ жҳҜеҗҰеҸҜиғҪеңЁиҝҷдёӘйӣҶеҗҲдёӯпјҢжҜ”еҰӮеңЁзј“еӯҳдёӯжҹҘиҜўдёҖдёӘе…ғзҙ жҳҜеҗҰеӯҳеңЁгҖӮ е®ғзҡ„еҺҹзҗҶжҳҜдҪҝз”ЁеӨҡдёӘе“ҲеёҢеҮҪж•°еҜ№...
еёғйҡҶиҝҮж»ӨеҷЁжҳҜдёҖз§Қз©әй—ҙж•ҲзҺҮжһҒй«ҳзҡ„жҰӮзҺҮеһӢж•°жҚ®з»“жһ„пјҢз”ЁдәҺеҲӨж–ӯдёҖдёӘе…ғзҙ жҳҜеҗҰеҸҜиғҪеңЁдёҖдёӘйӣҶеҗҲдёӯгҖӮе®ғжҳҜз”ұ Burton Howard Bloom еңЁ1970е№ҙжҸҗеҮәзҡ„пјҢдё»иҰҒеә”з”ЁдәҺеӨ§ж•°жҚ®еӯҳеӮЁе’ҢжЈҖзҙўпјҢе°Өе…¶еңЁж•°жҚ®еә“гҖҒзј“еӯҳзі»з»ҹе’ҢзҪ‘з»ңжҗңзҙўзӯүйўҶеҹҹжңүе№ҝжіӣ...
еёғйҡҶиҝҮж»ӨеҷЁпјҲBloom FilterпјүжҳҜдёҖз§Қз©әй—ҙж•ҲзҺҮжһҒй«ҳзҡ„жҰӮзҺҮеһӢж•°жҚ®з»“жһ„пјҢз”ЁдәҺеҲӨж–ӯдёҖдёӘе…ғзҙ жҳҜеҗҰеҸҜиғҪеңЁдёҖдёӘйӣҶеҗҲдёӯгҖӮеңЁJavaејҖеҸ‘дёӯпјҢзү№еҲ«жҳҜеңЁеӨ„зҗҶеӨ§ж•°жҚ®гҖҒеҶ…еӯҳйҷҗеҲ¶жҲ–йңҖиҰҒеҝ«йҖҹжҹҘиҜўжҳҜеҗҰеӯҳеңЁжҹҗдёӘе…ғзҙ зҡ„еңәжҷҜдёӢпјҢеёғйҡҶиҝҮж»ӨеҷЁжҳҜдёҖдёӘ...
еёғйҡҶиҝҮж»ӨеҷЁпјҲBloom FilterпјүжҳҜдёҖз§Қз©әй—ҙж•ҲзҺҮжһҒй«ҳзҡ„жҰӮзҺҮеһӢж•°жҚ®з»“жһ„пјҢз”ЁдәҺеҲӨж–ӯдёҖдёӘе…ғзҙ жҳҜеҗҰеҸҜиғҪеңЁдёҖдёӘйӣҶеҗҲдёӯгҖӮз”ұеёғйҡҶеңЁ1970е№ҙжҸҗеҮәпјҢе®ғдёҚеғҸдј з»ҹзҡ„ж•°жҚ®з»“жһ„еҰӮе“ҲеёҢиЎЁйӮЈж ·дҝқиҜҒдёҚиҜҜеҲӨпјҢиҖҢжҳҜе…Ғи®ёжңүдёҖе®ҡзҡ„й”ҷиҜҜзҺҮгҖӮиҝҷз§Қзү№жҖ§дҪҝеҫ—...
еёғйҡҶиҝҮж»ӨеҷЁпјҲBloom FilterпјүжҳҜдёҖз§Қз©әй—ҙж•ҲзҺҮжһҒй«ҳзҡ„жҰӮзҺҮеһӢж•°жҚ®з»“жһ„пјҢз”ЁдәҺеҲӨж–ӯдёҖдёӘе…ғзҙ жҳҜеҗҰеңЁдёҖдёӘйӣҶеҗҲдёӯгҖӮе®ғеҸҜиғҪдјҡиҜҜеҲӨпјҢдҪҶдёҚдјҡжјҸеҲӨпјҢеҚіеҰӮжһңе®ғиҜҙдёҖдёӘе…ғзҙ еңЁйӣҶеҗҲдёӯпјҢйӮЈеҸҜиғҪжҳҜй”ҷиҜҜзҡ„пјҢдҪҶеҰӮжһңе®ғиҜҙдёҖдёӘе…ғзҙ дёҚеңЁйӣҶеҗҲдёӯпјҢйӮЈд№Ҳ...
дҫӢеҰӮпјҢ`bf_create(size_t capacity, uint8_t num_hashes)`з”ЁдәҺеҲӣе»әдёҖдёӘеёғйҡҶиҝҮж»ӨеҷЁпјҢ`bf_insert(bloom_filter* filter, const void* item)`з”ЁдәҺжҸ’е…Ҙе…ғзҙ пјҢ`bf_query(bloom_filter* filter, const void* item)`з”ЁдәҺ...
RedisйӣҶжҲҗеёғйҡҶиҝҮж»ӨеҷЁйңҖиҰҒдҪҝз”ЁRedis 4.0д»ҘдёҠзүҲжң¬пјҢжҲ–иҖ…дҪҝз”ЁRedis 6.xзүҲжң¬пјҢдҪҝз”Ёе®ҳж–№жҸҗдҫӣзҡ„жҸ’件жңәеҲ¶жҲ–зј–иҜ‘е®үиЈ…RedisBloomжЁЎеқ—гҖӮдҪҝз”ЁеёғйҡҶиҝҮж»ӨеҷЁеҸҜд»Ҙи§ЈеҶіеӨ§йҮҸж•°жҚ®еҺ»йҮҚй—®йўҳпјҢжҸҗй«ҳзі»з»ҹжҖ§иғҪе’Ңж•ҲзҺҮгҖӮ еёғйҡҶиҝҮж»ӨеҷЁзҡ„дјҳзӮ№жҳҜпјҡ ...
еёғйҡҶиҝҮж»ӨеҷЁпјҲBloom FilterпјүжҳҜдёҖз§Қз©әй—ҙж•ҲзҺҮжһҒй«ҳзҡ„жҰӮзҺҮеһӢж•°жҚ®з»“жһ„пјҢз”ЁдәҺеҲӨж–ӯдёҖдёӘе…ғзҙ жҳҜеҗҰеҸҜиғҪеңЁдёҖдёӘйӣҶеҗҲдёӯгҖӮеңЁеӨ§ж•°жҚ®еӨ„зҗҶгҖҒзј“еӯҳзі»з»ҹгҖҒеҲҶеёғејҸеӯҳеӮЁзӯүйўҶеҹҹжңүзқҖе№ҝжіӣзҡ„еә”з”ЁгҖӮиҝҷдёӘеҺӢзј©еҢ…ж–Ү件вҖңbloom filterеёғйҡҶиҝҮж»ӨеҷЁеӯҰд№ ...
- `Intersection(other *BloomFilter)`: и®Ўз®—дёӨдёӘеёғйҡҶиҝҮж»ӨеҷЁзҡ„дәӨйӣҶпјҢеҲӣе»әдёҖдёӘж–°зҡ„еёғйҡҶиҝҮж»ӨеҷЁпјҢеҸӘдҝқз•ҷеҗҢж—¶еӯҳеңЁдәҺдёӨдёӘиҝҮж»ӨеҷЁдёӯзҡ„е…ғзҙ зҡ„дҪҚгҖӮ 4. **дјҳеҢ–зӯ–з•Ҙ**пјҡ - **дҪҚж•°з»„еӨ§е°Ҹ**пјҡдҪҚж•°з»„зҡ„еӨ§е°ҸзӣҙжҺҘеҪұе“ҚиҜҜеҲӨзҺҮпјҢйңҖиҰҒ...
еёғйҡҶиҝҮж»ӨеҷЁжҳҜдёҖз§Қй«ҳж•Ҳзҡ„з©әй—ҙиҠӮзңҒзҡ„ж•°жҚ®з»“жһ„пјҢз”ЁдәҺеҲӨж–ӯдёҖдёӘе…ғзҙ жҳҜеҗҰеҸҜиғҪеңЁдёҖдёӘйӣҶеҗҲдёӯпјҢдҪҶеҸҜиғҪдјҡдә§з”ҹдёҖе®ҡзҡ„иҜҜеҲӨзҺҮгҖӮе®ғз”ұдёҖдёӘеҫҲй•ҝзҡ„дәҢиҝӣеҲ¶еҗ‘йҮҸе’ҢеӨҡдёӘзӢ¬з«Ӣзҡ„е“ҲеёҢеҮҪж•°з»„жҲҗгҖӮеёғйҡҶиҝҮж»ӨеҷЁзҡ„еҹәжң¬еҺҹзҗҶжҳҜпјҢеҪ“дёҖдёӘе…ғзҙ иў«ж·»еҠ еҲ°...
`bloomfilter.js`еҸҜиғҪжҳҜJavaScriptзүҲжң¬зҡ„еёғйҡҶиҝҮж»ӨеҷЁе®һзҺ°пјҢиҖҢ"Go-еёғйҡҶиҝҮж»ӨеҷЁзҡ„дёҖдёӘGoе®һзҺ°еҸӮиҖғbloomfilter.js"еҲҷиЎЁжҳҺиҜҘGoзүҲжң¬зҡ„е®һзҺ°жҳҜеҖҹйүҙдәҶJavaScriptзүҲжң¬зҡ„и®ҫи®ЎжҖқи·ҜжҲ–д»Јз Ғз»“жһ„гҖӮ Goе®һзҺ°еёғйҡҶиҝҮж»ӨеҷЁзҡ„关键组件еҢ…жӢ¬пјҡ ...
C++е®һзҺ°зҡ„еёғйҡҶиҝҮж»ӨеҷЁпјҢе…¶дёӯдҪҝз”ЁеҲ°зҡ„bitsetд№ҹжҳҜиҮӘе·ұз®ҖеҚ•е®һзҺ°зҡ„дёҖдёӘBitContainerгҖӮеҸҜд»ҘеӨ„зҗҶеҚғдёҮжқЎеҲ°дәҝжқЎи®°еҪ•зҡ„еӯҳеңЁжҖ§еҲӨж–ӯгҖӮеҒҡжҲҗdllеҸҜд»ҘеңЁеҫҲеӨҡеңәеҗҲдҪҝз”ЁпјҢеҰӮиҮӘе·ұеҶҷзҲ¬иҷ«пјҢиҰҒеҲӨж–ӯдёҖдёӘurlжҳҜеҗҰе·Із»Ҹи®ҝй—®иҝҮпјҢеҲӨж–ӯдёҖдёӘеҚ•иҜҚжҳҜеҗҰ...
еёғйҡҶиҝҮж»ӨеҷЁпјҢеӨ§е®¶еӯҰиҝҮж•°жҚ®з»“жһ„зҡ„еә”иҜҘйғҪжё…жҘҡпјҢдёҖиҲ¬зҡ„еӯ—е…ёж ‘иҰҒе®һзҺ°еөҢе…Ҙе’ҢжҹҘжүҫйғҪеҶ…еӯҳзҡ„ж¶ҲиҖ—йқһеёёеӨ§пјҢеёғйҡҶиҝҮж»ӨеҷЁжңүBloomFilter,string, BKDRHash, APHash, DJBHash> bfдә”дёӘеҸӮж•°дҪ иҰҒжҹҘжүҫзҡ„е…ғзҙ дёӘж•°пјҢжҹҘжүҫе…ғзҙ зұ»еһӢпјҢдёүдёӘ...
еёғйҡҶиҝҮж»ӨеҷЁпјҲBloom FilterпјүжҳҜдёҖз§Қз©әй—ҙж•ҲзҺҮжһҒй«ҳзҡ„жҰӮзҺҮеһӢж•°жҚ®з»“жһ„пјҢз”ЁдәҺеҲӨж–ӯдёҖдёӘе…ғзҙ жҳҜеҗҰеҸҜиғҪеңЁдёҖдёӘйӣҶеҗҲдёӯгҖӮеңЁC++дёӯе®һзҺ°еёғйҡҶиҝҮж»ӨеҷЁпјҢеҸҜд»Ҙжңүж•Ҳең°еӨ„зҗҶеӨ§йҮҸж•°жҚ®пјҢе°Өе…¶жҳҜеңЁеҶ…еӯҳжңүйҷҗзҡ„жғ…еҶөдёӢгҖӮиҝҷдёӘеҺӢзј©еҢ…ж–Ү件"Bloom_filter...
еңЁPythonдёӯпјҢжңүеӨҡдёӘеә“е®һзҺ°дәҶеёғйҡҶиҝҮж»ӨеҷЁпјҢе…¶дёӯдёҖдёӘе°ұжҳҜжҲ‘们иҝҷйҮҢжҸҗеҲ°зҡ„"python-bloomfilter-master"гҖӮ иҝҷдёӘPythonеә“жҸҗдҫӣдәҶеҜ№еёғйҡҶиҝҮж»ӨеҷЁзҡ„з®ҖеҚ•жҺҘеҸЈпјҢдҪҝеҫ—ејҖеҸ‘иҖ…еҸҜд»Ҙж–№дҫҝең°еңЁйЎ№зӣ®дёӯеә”з”ЁеёғйҡҶиҝҮж»ӨеҷЁгҖӮе®үиЈ…иҝҮзЁӢйқһеёёзӣҙи§ӮпјҢ...
еёғйҡҶиҝҮж»ӨеҷЁеңЁзҪ‘йЎөеҺ»йҮҚдёӯзҡ„еә”з”Ё , жө·йҮҸж•°жҚ®еӨ„зҗҶдёӯзҡ„дёҖдёӘз»қеҘҪеә”з”Ё
**еёғйҡҶиҝҮж»ӨеҷЁпјҲBloom Filterпјү**жҳҜдёҖз§Қз©әй—ҙж•ҲзҺҮжһҒй«ҳзҡ„жҰӮзҺҮеһӢж•°жҚ®з»“жһ„пјҢз”ЁдәҺжөӢиҜ•дёҖдёӘе…ғзҙ жҳҜеҗҰеңЁдёҖдёӘйӣҶеҗҲдёӯгҖӮз”ұBurton Howard BloomеңЁ1970е№ҙжҸҗеҮәпјҢдё»иҰҒз”ЁдәҺиҠӮзңҒеӯҳеӮЁз©әй—ҙпјҢе°Өе…¶еңЁеӨ§ж•°жҚ®еңәжҷҜдёӢпјҢе®ғиғҪжңүж•Ҳең°и§ЈеҶіеӨ§и§„жЁЎ...
еңЁPHPе’ҢRedisдёӯе®һзҺ°еёғйҡҶиҝҮж»ӨеҷЁпјҢеҸҜд»ҘеҲ©з”ЁPHPзҡ„жү©еұ•еә“пјҢеҰӮBloomFilterеә“пјҢжҲ–иҖ…зӣҙжҺҘеңЁRedisдёӯдҪҝз”ЁBF.ADDгҖҒBF.MEMBERSе’ҢBF.EXISTSзӯүе‘Ҫд»Өж“ҚдҪңеёғйҡҶиҝҮж»ӨеҷЁгҖӮRedisзҡ„еёғйҡҶиҝҮж»ӨеҷЁжЁЎеқ—жҸҗдҫӣдәҶж–№дҫҝзҡ„ж“ҚдҪңжҺҘеҸЈпјҢиғҪеӨҹеңЁеҲҶеёғејҸзҺҜеўғ...
еңЁJavaдёӯпјҢеёғйҡҶиҝҮж»ӨеҷЁзҡ„е®һзҺ°йқһеёёдҫҝжҚ·пјҢе°Өе…¶жҳҜеҲ©з”ЁдәҶGuavaеә“жҸҗдҫӣзҡ„BloomFilterзұ»гҖӮејҖеҸ‘иҖ…еҸҜд»Ҙйқһеёёз®ҖеҚ•ең°йҖҡиҝҮи°ғз”Ёputж–№жі•ж·»еҠ е…ғзҙ пјҢйҖҡиҝҮmayContainж–№жі•жқҘжЈҖжҹҘе…ғзҙ жҳҜеҗҰеӯҳеңЁгҖӮдёҚд»…еҰӮжӯӨпјҢеёғйҡҶиҝҮж»ӨеҷЁиҝҳе…Ғи®ёејҖеҸ‘иҖ…иҮӘе®ҡд№ү...
еёғйҡҶиҝҮж»ӨеҷЁжҳҜдёҖз§ҚжҰӮзҺҮеһӢж•°жҚ®з»“жһ„пјҢз”ЁдәҺеҲӨж–ӯдёҖдёӘе…ғзҙ жҳҜеҗҰеҸҜиғҪеңЁдёҖдёӘйӣҶеҗҲдёӯгҖӮе®ғжҳҜз”ұBurton Howard BloomеңЁ1970е№ҙжҸҗеҮәзҡ„пјҢдё»иҰҒз”ЁдәҺи§ЈеҶіеӨ§ж•°жҚ®йӣҶзҡ„еӯҳеӮЁе’ҢжҹҘиҜўй—®йўҳпјҢе°Өе…¶еңЁз©әй—ҙж•ҲзҺҮдёҠжңүзқҖжҳҫи‘—дјҳеҠҝгҖӮеңЁж•°жҚ®еә“гҖҒжҗңзҙўеј•ж“ҺгҖҒ...