Yahoo!研究人员使用Hadoop完成了Jim Gray基准排序,此排序包含许多相关的基准,每个基准都有自己的规则。所有的排序基准都是通过测量不同记录的排序时间来制定的,每个记录为100字节,其中前面的10字节是键,剩余的部分是数值。MinuteSort是比较在一分钟内所排序的数据量大小,GraySort是比较在对大规模数据(至少100TB)进行排序时的排序速率(TBs/minute)。基准规则具体如下:
- 输入数据必须与数据生成器生成的数据完全匹配;
- 任务开始的时候,输入数据不能在操作系统的文件缓存中。在Linux环境下,排序程序之间需要使用内存来交换其他内容;
- 输入和输出数据都是没有经过压缩的;
- 输出不能对输入进行重写;
- 输出文件必须存放到磁盘上;
- 必须计算输入和输出数据的每个键/值对的CRC32,共128位校验和,当然,输入和输出必须对应相等;
- 输出如果分成多个输出文件,那么必须是完全有序的,也就是将这些输出文件连接以后必须是完全有序的输出;
- 开始和分布程序到集群上也要记入计算时间内;
- 任何抽样也要记入计算时间内。
Yahoo!的研究人员使用Hadoop排列1TB数据用时62秒,排列1PB数据用时16.25个小时,具体如表3-2所示,它获得了Daytona类GraySort和MinuteSort级别的冠军。
表3-2 数据规模与排序时间
| 数据大小(Bytes) |
节 点 数 |
副 本 数 |
时 间 |
| 500 000 000 000 |
1406 |
1 |
59秒 |
| 1 000 000 000 000 |
1460 |
1 |
62秒 |
| 100 000 000 000 000 |
3452 |
2 |
173分钟 |
| 1 000 000 000 000 000 |
3658 |
2 |
975分钟 |
下面的内容是根据基准排序的官方网站(http://sortbenchmark.org/)上有关使用Hadoop排序的相关内容整理而成。
- Yahoo!的研究人员编写了三个Hadoop应用程序来进行TB级数据的排序:
- TeraGen是产生数据的map/reduce程序;
- TeraSort进行数据取样,并使用map/reduce对数据进行排序;
- TeraValidate是用来验证输出数据是否有序的map/reduce程序。
TeraGen用来产生数据,它将数据按行排列并且根据执行任务的数目为每个map分配任务,每个map任务产生所分配行数范围内的数据。最后,TeraGen使用1800个任务产生总共100亿行的数据存储在HDFS上,每个存储块的大小为512MB。
TeraSort是标准的map/reduce排序程序,但这里使用的是不同的分配方法。程序中使用N-1个已排好序的抽样键值来为reduce任务分配排序数据的行数范围。例如,键值key在范围sample[i-1]<=key<sample[i]的数据会分配给第i个reduce任务。这样就保证了第i个reduce任务输出的数据都比第i+1个reduce任务输出的数据小。为了加速分配过程,分配器在抽样键值上建立两层的索引结构树。TeraSort在任务提交之前在输入数据中进行抽样,并将产生的抽样数据写入HDFS中。这里规定了输入输出格式,使得三个应用程序可以正确地读取并写入数据。reduce任务的副本数默认是3,这里设置为1,因为输出数据不需要复制到多个节点上。这里配置的任务为1800个map任务和1800个reduce任务,并为任务的栈设置了充足的空间,防止产生的中间数据溢出到磁盘上。抽样器使用100
000个键值来决定reduce任务的边界,如图3-9所示,分布并不是很完美。
TeraValidate保证输出数据是全部排好序的,它为输出目录的每个文件分配一个map任务(如图3-10所示),map任务检查每个值是否大于等于前一个值,同时输出最大值和最小值给reduce任务,reduce任务检查第i个文件的最小值是否大于第i-1文件的最大值,如果不是则产生错误报告。

图3-9 reduce任务的输出大小和完成时间分布图
以上应用程序运行在雅虎搭建的集群上,其集群配置为:
- 910个节点;
- 每个节点拥有4个英特尔双核2.0GHz至强处理器;
- 每个节点拥有4个SATA硬盘;
- 每个节点有8GB的内存;
- 每个节点有1GB的以太网带宽;
- 40个节点一个rack;
- 每个rack到核心有8GB的以太网带宽;
- 操作系统为Red HatEnterprise Linux Server Release 5.1(kernel 2.6.18);
- JDK为Sun Java JDK1.6.0_05-b13。
整个排序过程在209秒(3.48分钟)内完成,尽管拥有910个节点,但是网络核心是与其他2000个节点的集群共享的,所以运行时间会因为其他集群的活动而有所变化。
使用Hadoop进行 GraySort基准排序时,Yahoo!的研究人员将上面的map/reduce应用程序稍加修改以适应新的规则,整个程序分为4个部分,分别为:
- TeraGen是产生数据的map/reduce程序;
- TeraSort进行数据取样,并使用map/reduce对数据进行排序;
- TeraSum是map/reduce程序,用来计算每个键/值对的CRC32,共128位校验和;
- TeraValidate是用来验证输出数据是否有序的map/reduce程序,并且计算校验和的总和。
TeraGen和TeraSort与上面介绍的一样,TeraValidate除了增加了计算输出目录校验和总和的任务以外,其他都一样,这里不再赘述。
TeraSum计算每个键/值对的CRC32的校验和,每个map任务计算输入的校验和并输出,然后一个reduce任务将每个map生成的校验和相加。这个程序用来计算输入目录下每个键/值对校验和的和,还用来检查排序输出后的正确性。
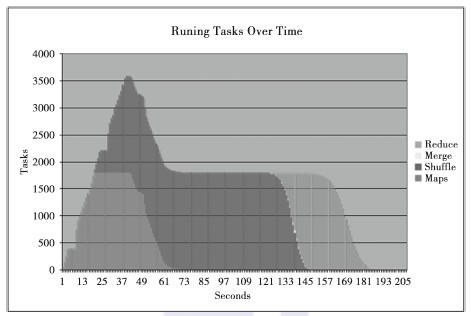
图3-10 每个阶段的任务数
这次基准测试运行在Yahoo!的Hammer集群上,集群的具体细节如下:
- 将近3800个节点(在这样大规模的集群中,一些节点会坏掉);
- 每个节点两个双核2.5GHz的Xeons处理器;
- 每个节点4个SATA硬盘;
- 每个节点8GB内存(在PB级排序前会升级到16GB);
- 每个节点1GB的以太网带宽;
- 每个rack拥有40个节点;
- 每个节点到核心有8GB的以太网带宽;
- 操作系统为Red HatEnterprise Linux Server Realease 5.1(kernel 2.6.18);
- JDK为Sun Java JDK(1.6.0 05-b13and 1.6.0 13-b03)(32 and 64 bit)。
对于较大规模的排序,这里NameNode和JobTracker使用的是64位的JVM。排序测试所用的Hadoop平台也做了一些变化,主要有:
- 重新实现了Hadoopshuffle阶段的reducer部分,在重新设计后提高了shuffle的性能,解除了瓶颈,而且代码也更容易维护和理解了;
- 新的shuffle过程从一个节点获取多个map的结果,而不是之前的一次只取一个结果。这样防止了多余的连接和传输开销;
- 允许配置shuffle连接的超时时间,在小规模排序时则可以将其减小,因为一些情况下shuffle会在超时时间到期后停止,这会增加任务的延迟时间;
- 设置TCP为无延迟并增加TaskTracker和TaskTracker之间ping的频率,以减少发现问题的延迟时间;
- 增加一些代码,用来检测从shuffle传输数据的正确性,防止引起reduce任务的失败。
- 在map输出的时候使用LZO压缩,LZO能压缩45%的数据量;
- 在shuffle阶段,在内存中将map的结果聚集输出的时候实现了reduce需要的内存到内存的聚集,这样减少了reduce运行时的工作量;
- 使用多线程实现抽样过程,并编写一个基于键值平均分布的较为简单的分配器;
- 在较小规模的集群上,配置系统在TaskTracker和JobTracker之间拥有较快的心跳频率,以减少延迟(默认为10秒/1000节点,配置为2秒/1000节点);
- 默认的JobTracker按照先来先服务策略为TaskTracker分配任务,这种贪心的任务分配方法并不能很好地分布数据。从全局的角度来看,如果一次性为map分配好任务,系统会拥有较好的分布,但是为所有的Hadoop程序实现全局调度策略是非常困难的,这里只是实现了TeraSort的全局调度策略;
- Hadoop 0.20增加了安装和清除任务的功能,但是在排序基准测试里这并不需要,可以设置为不启动来减少开始和结束任务的延迟;
- 删除了框架中与较大任务无关的一些硬编码等待循环,因为它会增加任务延迟时间;
- 允许为任务设置日志的级别,这样通过配置日志级别可以从INFO到WARN减少日志的内容,减少日志的内容对系统的性能有较大的提高,但是增加了调试和分析的困难;
- 优化任务分配代码,但还未完成。目前,对输入文件使用RPC请求到NameNode上会花费大量的时间。
Hadoop与上面的测试相比有了很大的改进,可以在更短的时间内执行更多的任务。值得注意的是,在大集群和分布式应用程序中需要转移大量数据,这会导致执行时间有很大的变化。但是随着Hadoop的改进,它能够更好地处理硬件故障,这种时间变化也就微不足道了。不同规模的数据排序所需的时间如表3-2所示。
因为较小规模的数据需要更短的延迟和更快的网络,所以使用集群中的部分节点来进行计算。将较小规模计算的输出副本数设置为1,因为整个过程较短且运行在较小的集群上,节点坏掉的可能性相对较小。而在较大规模的计算上,节点坏掉是难免的,于是将节点副本数设置为2。HDFS保证节点换掉后数据不会丢失,因为不同的副本放在不同的节点上。
Yahoo!的研究人员统计了JobTracker上从任务提交状况获得的任务数随时间的变化,图3-11、图3-12、图3-13、图3-14显示了每个时间点下的任务数。maps只有一个阶段,而reduces拥有三个阶段:shuffle、merge和reduce。shuffle是从maps中转移数据的,merge在测试中并不需要;reduce阶段进行最后的聚集并写到HDFS上。如果将这些图与图3-6进行比较,你会发现建立任务的速度变快了。图3-6中每次心跳建立一个任务,那么所有任务建立起来需要40秒,现在Hadoop每次心跳可以设置好一个TaskTracker,可见减少任务建立的开销是非常重要的。
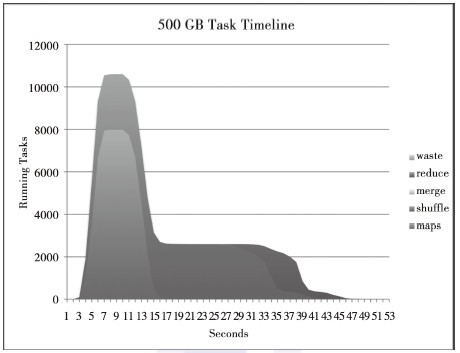
图3-11 数据量为500GB时任务数随时间的变化

图3-12 数据量为1TB时任务数随时间的变化
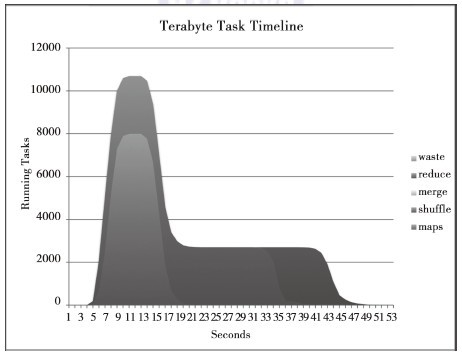
图3-13 数据量为100TB时任务数随时间的变化

图3-14 数据量为1PB时任务数随时间的变化
运行大规模数据时,数据传输的次数对任务性能的影响也是非常大的。在PB级数据排序中,每个map处理15GB的数据而不是默认的128MB,每个reduce处理50GB的数据。如果按照1.5GB/map进行处理,需要 40个小时才能完成。因此,为了增加吞吐量,增加每个块的大小是非常重要的。
----------------------------------

本文节选自《Hadoop实战》第3章 3.5节“Hadoop平台上的海量数据排序
”
作者:陆嘉恒
样张试读下载http://download.csdn.net/detail/hzbooks/3704577
访问本书官网http://datasearch.ruc.edu.cn/HadoopInAction/
分享到:





相关推荐
### Hadoop平台下的海量数据分类应用 随着信息技术的迅速发展,大数据分析已成为当前研究与实践中的热点领域之一。本文探讨了在Hadoop平台上利用MapReduce框架进行海量数据分类的应用技术,重点介绍了InterIMAGE ...
数据挖掘在本质上是提取存储在数据库、信息库等中的海量数据的有效知识的过程。这些知识具有未知性、实用性和有效性,它们隐藏在大量数据中,需要通过寻找数据之间的联系来有效获取。Hadoop云平台提供的分布式计算...
综上所述,基于Hadoop的海量数据处理模型在应对大数据挑战方面展现出了强大的潜力。它不仅能够处理PB级别的数据,还能提供高效、低成本和易于维护的解决方案。随着大数据技术的不断发展,Hadoop及其相关生态系统将...
综上所述,本文研究了云计算、Hadoop、海量数据处理等领域,提出了一种新的海量电信数据云计算平台设计方法,旨在通过Hadoop技术提高电信数据处理的效率和分析速度,为电信运营商提供决策支持的同时降低运营成本。...
"基于Hadoop平台的数据处理及应用" 本文主要介绍了基于Hadoop平台的数据处理及应用,讨论了Hadoop技术在现代数据处理中的重要性,并介绍了Hadoop技术的应用领域和关键技术要点。 在现代社会,互联网的应用和普及正...
Hadoop平台下海量日志数据处理模型的研究及改进
基于Hadoop平台的海量数据挖掘算法的研究,旨在开发更高效的数据处理与分析技术,以应对日益增长的数据存储和处理需求。 在研究中,Hadoop的架构设计至关重要。Hadoop通过其核心组件HDFS(Hadoop Distributed File ...
### 基于Hadoop的海量数据存储平台设计与开发 #### 摘要与背景 随着北部湾海洋生态资源的开发与利用,《北部湾经济区发展规划》的实施催生了一系列重大的基础研究专项和科学研究项目。这些项目在推进的过程中产生...
为了解决这些问题,文章提出了一种基于开源框架Hadoop的海量日志数据处理方法。Hadoop是一个由Apache软件基金会支持的开源分布式存储和计算平台。其核心是MapReduce编程模型,该模型特别适用于大数据的并行处理。...
在总结时,基于Hadoop的海量数据处理平台的研究与应用,为企业提供了处理大规模数据的新途径,它不仅能够加速数据的处理和分析速度,而且对于推动企业服务的个性化和精准化发展有着重要的意义。未来,随着大数据技术...
### 基于Hadoop的海量遥感数据处理关键技术 #### 摘要与背景介绍 随着卫星技术的发展以及地球表面信息的不断丰富,遥感数据的规模正在急剧增长。这些数据不仅包括图像本身,还涵盖了多种类型的地理信息。面对如此...
在大数据处理领域,Hadoop是一个不可或缺的核心框架,它主要用于存储和处理海量数据。在这个基于Hadoop的电信客服数据分析项目中,我们重点探讨如何利用Hadoop生态系统来解析和分析电信行业的客户通话记录,从而获取...
2. **分布式计算**:Hadoop等分布式计算框架可以在大量廉价服务器上实现数据并行处理,显著提高了数据处理的速度。 3. **成本效益**:相比于自建数据中心,使用云计算服务可以大大降低企业的运维成本。 综上所述,...
综上所述,基于Hadoop平台的并行数据挖掘算法工具箱与数据挖掘云技术为解决海量数据挖掘问题提供了有力的支持。通过对现有技术的改进和创新,未来有望进一步提升数据挖掘的效率和效果,为大数据时代的信息处理提供...
这篇研究基于Hadoop平台的海量医疗数据挖掘算法,致力于通过有效的算法挖掘医疗数据中的潜在信息。通过对医疗数据的分析与处理,提出了一种基于Hadoop的医疗数据挖掘算法,并通过实验验证了算法的性能。 这个资源...
在大数据处理领域,Hadoop是一个不可或缺的开源框架,它为海量数据的存储和处理提供了高效、可靠的解决方案。本文将深入探讨“Hadoop之外卖订单数据分析系统”,并介绍如何利用Hadoop进行大规模数据处理,以及如何将...
文章《基于Hadoop的PB级海量数据处理系统的设计与实现》详细介绍了如何利用Hadoop技术搭建集群平台,用以应对PB级海量数据的存储和处理问题。搭建的集群平台显著提升了系统处理海量数据的能力,具体体现在对1PB级别...