
Õ”éµ×£ń¼¼õ║īµ¼Īń£ŗÕł░µłæńÜäµ¢ćń½Ā’╝īµ¼óĶ┐ÄŃĆīµ¢ćµ£½ŃĆŹµē½ńĀüĶ«óķśģµłæõĖ¬õ║║ńÜäÕģ¼õ╝ŚÕÅĘ’╝łĶĘ©ńĢīµ×ȵ×äÕĖł’╝ēÕō¤~┬Ā
µ»ÅÕæ©õ║öµŚ®8ńé╣ µīēµŚČķĆüĶŠŠÕł░Õģ¼õ╝ŚÕÅĘŃĆé
ÕĮōńäČõ║å’╝īõ╣¤õ╝ܵŚČõĖŹµŚČÕŖĀõĖ¬ķżÉ’Į×
┬Ā
Ķ┐Öń»ćµś»ŃĆīÕłåÕĖāÕ╝Åń│╗ń╗¤ńÉåĶ«║ŃĆŹń│╗ÕłŚńÜäń¼¼22ń»ć’╝īõ╣¤µś»µ£ĆÕÉÄõĖĆń»ćŃĆ鵳æõ╗¼µØźĶüŖĶüŖÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁńÜäµ£ĆÕÉÄõĖĆķüōõ┐ØķÜ£ŌĆöŌĆöńøæµÄ¦ŃĆé
┬Ā
ńøæµÄ¦Ķ┐ÖõĖ¬õ║ŗµāģ’╝īµ£ēńé╣Õāŵłæõ╗¼Õ╣│µŚČÕ»╣õ║║ńÜäÕüźÕ║ĘõĮōµŻĆŃĆéµā│Ķ”üµĢłµ×£ÕźĮŃĆüń╗ōµ×£ķØĀĶ░▒’╝īÕ░▒ÕŠŚŌĆ£Õģ©ķØóõĮōµŻĆŌĆØ’╝īµ»ÅõĖĆķĪ╣ķāĮÕüÜ’╝īÕÉ”ÕłÖÕō¬µĆĢµŻĆµ¤źµŖźÕæŖķāĮµś»µŁŻÕĖĖ’╝īõ╣¤õĖŹõ╗ŻĶĪ©µ▓Īµ£ēķŚ«ķóśŃĆéõĖŗķØóĶ┐ÖõĖ¬µÖ»Ķ▒Īµś»õĖŹµś»ÕŠłń夵éē’╝¤
┬Ā
Ķ┐ÉĶÉźÕ░ÅÕ¦ÉÕ¦ÉķŚ«’╝ÜńÄ░Õ£©ń│╗ń╗¤ÕźĮÕŹĪÕĢŖŃĆé
┬Ā
ń©ŗÕ║ÅÕæśÕ░ÅÕōźÕōźńŁö’╝ܵłæĶ┐ÖķćīõĖŹÕŹĪÕĢŖ’╝īĶĆīõĖöõ╗ĵĢ░µŹ«µØźń£ŗÕŠłµŁŻÕĖĖŃĆé
┬Ā
Ķ┐ÉĶÉźÕ░ÅÕ¦ÉÕ¦ÉķŚ«’╝Ü[õĖĆÕ╝Āµł¬ÕøŠ]’╝īõĮĀń£ŗõĖĆńø┤Õ£©ÕŖĀĶĮĮŃĆé
┬Ā
ń©ŗÕ║ÅÕæśÕ░ÅÕōźÕōźńŁö’╝ÜõĮĀńÜäµ£¼Õ£░ńĮæń╗£õĖŹÕźĮÕɦ’╝īµēōÕ╝ĆÕł½ńÜäńĮæń½ÖĶ»ĢĶ»ĢŃĆé
┬Ā
┬ĀŌĆ”ŌĆ”
┬Ā
ńøæµÄ¦ķćīńÜäŌĆ£Õģ©ķØóõĮōµŻĆŌĆص£ēõĖ¬ķ½śÕż¦õĖŖńÜäÕŽµ│Ģ’╝īŃĆīń½ŗõĮōÕī¢ńøæµÄ¦ŃĆŹŃĆé
┬Ā
õĮåµś»’╝īĶČŖÕģ©ķØó’╝īµłÉµ£¼ĶČŖķ½śŃĆéµēĆõ╗ź’╝īµĀ╣µŹ«µēĆÕżäńÜ䵌ȵ£¤õ╗ÄõĖŁµīæķĆēÕÉłķĆéńÜäńøæµÄ¦µ¢╣Õ╝ŵø┤ÕŖĀķćŹĶ”üŃĆé
┬Ā
µÄźõĖŗÕÄ╗’╝īZÕōźµØźÕÆīõĮĀõĖĆĶĄĘµó│ńÉåõĖĆõĖŗķéŻõ║øµ£ēÕ┐ģĶ”üÕüÜńøæµÄ¦ńÜäÕ£░µ¢╣ŃĆéµ£ĆÕÉÄÕåŹń╗ÖõĮĀõĖĆõĖ¬µÖ«ķĆéµĆ¦ńÜäÕ╗║Ķ««ŃĆé
┬Ā
┬Ā
ńøæµÄ¦ńÜäõĖēõĖ¬Õ▒éµ¼Ī
õ╗ÄńøæµÄ¦ńÜäńø«µĀćµØźń£ŗ’╝īńøæµÄ¦ÕÅ»õ╗źÕłåõĖ║õĖēõĖ¬Õ▒éµ¼ĪŃĆéÕłåÕł½µś»ŃĆīńÄ»ÕóāµīćµĀćŃĆŹŃĆüŃĆīń©ŗÕ║ŵīćµĀćŃĆŹŃĆüŃĆīõĖÜÕŖĪµīćµĀćŃĆŹŃĆé
┬Ā
┬Ā
ńÄ»ÕóāµīćµĀć
ńÄ»ÕóāµīćµĀćõĖ╗Ķ”üµś»ńĮæń╗£I/OŃĆüńĮæń╗£Õ╗ČĶ┐¤ŃĆüńŻüńøśI/OŃĆüńŻüńøśÕŹĀńö©Õż¦Õ░ÅŃĆüCPUõĮ┐ńö©ńÄćŃĆüÕåģÕŁśõĮ┐ńö©ńÄćŃĆüõ║żµŹóÕłåÕī║ńŁēńŁēŃĆé
┬Ā
Õ«āõ╗¼ńÜäńø«ńÜ䵜»Ķ¦éµĄŗń©ŗÕ║ŵēĆÕ£©ńÜäńÄ»Õóā’╝īµś»õĖŹµś»ń©│Õ«ÜŃĆéÕ░▒ÕźĮµ»öŃĆīµ░┤Õ¤╣ń╗┐ń«®ŃĆŹ’╝īÕåŹµĆÄõ╣łÕźĮÕģ╗ńÜ䵿Źńē®’╝īõĮĀµŖŖõĖŗķØóńÜäµ░┤ńģ«õĖĆõ╝Ü’╝īķāĮÕŠŚµīéŃĆé
┬Ā
┬Ā
ÕüÜńÄ»ÕóāµīćµĀćńÜäńøæµÄ¦ÕŠłń«ĆÕŹĢŃĆéZÕōźÕ╗║Ķ««õĮĀõ║īķĆēõĖĆÕ░▒ÕźĮõ║åŃĆé
┬Ā
µŚĀĶäæńö©ńÜäĶ»Ø’╝īÕ░▒ZabbixÕɦŃĆéķØ×ÕĖĖµłÉńå¤ńÜäõ╝üõĖÜń║¦ńøæµÄ¦õ║¦ÕōüŃĆéńĮæõĖŖÕ«ēĶŻģµĢÖń©ŗµ£ēÕŠłÕżÜ’╝īķÜÅõŠ┐µÉ£õĖĆõĖŗÕ░▒µś»ŃĆé
┬Ā
Õ”éµ×£µ£ŹÕŖĪÕÖ©ÕżÜńÜäĶ»Ø’╝īÕ░åZabbixµēōÕīģÕł░Ķ┐øµōŹõĮ£ń│╗ń╗¤’╝īÕüܵłÉõĖĆõĖ¬ķĢ£ÕāÅŃĆéĶ┐ÖµĀĘõĖĆµØź’╝īõĖĆÕÅ░µ¢░µ£ŹÕŖĪÕÖ©ÕŬĶ”üµś»õ╗ÄķĢ£ÕāÅÕ«ēĶŻģńÜä’╝īÕ░▒õ╝ÜĶć¬ÕŖ©ÕŖĀÕģźÕł░ńøæµÄ¦õĖŁŃĆé
┬Ā
┬Ā
Õ”éµ×£µä┐µäŵŖśĶģŠ’╝īµā│õ║īµ¼ĪÕ╝ĆÕÅæńÜäĶ»ØÕÅ»õ╗źõĮ┐ńö©Õ░Åń▒│Õ╝Ƶ║ÉńÜäopen-falconŃĆéķĪ╣ńø«ńÜäµ┤╗ĶĘāÕ║”Ķ┐śõĖŹķöÖ’╝īÕÅ»õ╗źõ║åĶ¦ŻõĖĆõĖŗ’╝Ühttps://github.com/open-falcon/falcon-plusŃĆé
┬Ā
ĶÖĮńäČÕŖ¤ĶāĮńÜäõĖ░Õ»īÕ║”õĖŖµ»öZabbixÕĘ«õĖĆõ║ø’╝īõĮåµś»µ»Ģń½¤µś»ÕøĮõ║║ńÜäõ║¦Õōü’╝īµø┤ÕŖĀń¼”ÕÉłõĖŁÕøĮÕøĮµāģŃĆéÕøĮÕåģµ£ēõĖŹÕ░æõ║ÆĶüöńĮæõ╝üõĖÜõ╣¤Õ£©ńö©’╝īµł¢ĶĆģÕ¤║õ║ÄÕ«āĶ┐øĶĪīõ║åõ║īµ¼ĪÕ╝ĆÕÅæ’╝īµ£Ćµ£ēÕÉŹńÜ䵜»ńŠÄÕøóõ║īµ¼ĪÕ╝ĆÕÅæńÜämt-falconńÜäŃĆéÕ”éµ×£Õå│Õ«ÜĶ┐øĶĪīõ║īµ¼ĪÕ╝ĆÕÅæńÜäĶ»Ø’╝īÕÅ»õ╗źÕƤķē┤õĖĆõ║ømt-falconÕ£©ńĮæõĖŖńÜäÕģ¼Õ╝Ćõ┐Īµü»ŃĆé
┬Ā
┬Ā
ń©ŗÕ║ŵīćµĀć
ń©ŗÕ║ŵīćµĀćķÖżõ║åÕÆīńÄ»ÕóāµīćµĀćõĖƵĀĘńÜäCPUõĮ┐ńö©ńÄćŃĆüÕåģÕŁśõĮ┐ńö©ńÄćĶ┐Öń¦ŹŌĆ£Õż¢ķā©ŌĆ£ĶĪ©ńÄ░ńÜäµīćµĀćõ╣ŗÕż¢’╝īĶ┐śµ£ēÕ║öńö©ń©ŗÕ║ÅķöÖĶ»»µĢ░ŃĆüÕ║öńö©ń©ŗÕ║ÅĶ»Ęµ▒éķćÅŃĆüÕ║öńö©Õ╣│ÕØćÕōŹÕ║öµŚČķŚ┤Ķ┐Öń¦ŹŌĆØÕåģķā©ŌĆ£ĶĪ©ńÄ░ńÜäµīćµĀćŃĆé
┬Ā
ÕģČÕ«×ÕüÜńøæµÄ¦ńÜ䵌ČÕĆÖµ£ēõĖĆõĖ¬ńŚøńé╣’╝īµś»õĖŹµś»ŃĆīµŚĀõŠĄÕģźŃĆŹńÜä’╝¤
┬Ā
ÕøĀõĖ║õĖƵŚ”ķ£ĆĶ”üõŠĄÕģźÕł░ÕģĘõĮōńÜäń©ŗÕ║ÅõĖŁÕÄ╗ń╝¢ÕåÖŃĆīÕ¤ŗńé╣ŃĆŹõ╗ŻńĀü’╝īÕ░▒ÕŠłķ║╗ńā”’╝īµ»Ģń½¤µČēÕÅŖÕł░µø┤ÕżÜńÜäõ║║õĖĆĶĄĘķģŹÕÉłÕśø’╝īµÄ©Ķ┐øµø┤Õø░ķÜŠŃĆé
┬Ā
CPUõĮ┐ńö©ńÄćŃĆüÕåģÕŁśõĮ┐ńö©ńÄćńÜäńøæµÄ¦µ»öĶŠāń«ĆÕŹĢ’╝īÕÅ»õ╗źńø┤µÄźķĆÜĶ┐ćshellµł¢ĶĆģcmdĶ░āńö©ń│╗ń╗¤APIĶÄĘÕÅ¢’╝īÕÆīÕēŹķØóńÜäńÄ»ÕóāµīćµĀćõĖƵĀĘŃĆé
┬Ā
õĮåÕ»╣õ║ÄÕ║öńö©ń©ŗÕ║ÅķöÖĶ»»µĢ░ŃĆüÕ║öńö©ń©ŗÕ║ÅĶ»Ęµ▒éķćÅŃĆüÕ║öńö©Õ╣│ÕØćÕōŹÕ║öµŚČķŚ┤ńÜäńøæµÄ¦’╝īĶ┐Öķćīµś»õĖĆõĖ¬Õłåµ░┤Õ▓Ł’╝īÕøĀõĖ║Ķ┐Öķćīµā│Ķ”üÕüÜÕł░ŃĆīµŚĀõŠĄÕģźŃĆŹńÜäµĢłµ×£’╝īķ£ĆĶ”üÕüÜõĖĆõ║øķóØÕż¢ńÜäÕĘźõĮ£’╝īÕÉ”ÕłÖÕŬĶāĮń╝¢ÕåÖÕż¦ķćÅńÜäŌĆ£Õ¤ŗńé╣ŌĆØõ╗ŻńĀüŃĆé
┬Ā
µ»öÕ”é’╝īµś»õĖŹµś»µ£ēõĖĆõĖ¬ńĮæÕģ│µØźń╗¤õĖĆĶ┐øĶĪīµĄüķćÅÕłåÕÅæ’╝¤µś»õĖŹµś»µ£ēõĖĆõĖ¬ń╗¤õĖĆńÜäRPCµĪåµ×ČŃĆüµĢ░µŹ«Õ║ōĶ«┐ķŚ«µĪåµ×ČńŁēńŁēŃĆéÕ”éµ×£µ£ēĶ┐ÖµĀĘńÜäń╗¤õĖƵ©ĪÕØŚÕ░▒ÕźĮÕŖ×õ║å’╝īńø┤µÄźÕ£©Ķ┐Öõ║øµ©ĪÕØŚķćīÕó×ÕŖĀńøæµÄ¦ÕŖ¤ĶāĮŃĆé
┬Ā

┬Ā
õĖŠõĖ¬õŠŗÕŁÉ’╝īõĮĀńÜärpcµĪåµ×ȵś»ń╗¤õĖĆńÜä’╝īķéŻõ╣łÕŬĶ”üÕ£©µ»Åµ¼Īµ¢╣µ│ĢĶ░āńö©ÕēŹÕÆīĶ░āńö©ÕÉÄĶ«░ÕĮĢÕźĮńøĖÕ║öńÜäµĢ░µŹ«’╝īÕ░▒ÕÅ»ńö©õ║ÄÕÉÄń╗Łń╗¤Ķ«ĪÕć║ń╗ōµ×£ŃĆé
┬Ā
Õģ│õ║ÄķććķøåÕł░ńÜäµĢ░µŹ«Õ”éõĮĢÕŁśÕé©’╝īõĖ╗µĄüńÜäķĆēµŗ®µś»Õ░åµĢ░µŹ«ÕåÖÕģźÕł░õĖĆõĖ¬ŃĆīµŚČÕ║ŵĢ░µŹ«Õ║ōŃĆŹõĖŁŃĆéµ»öÕ”éPrometheus’╝īĶ┐Öµś»õĖĆõĖ¬õĖōķŚ©ÕüÜńøæµÄ¦µŖźĶŁ”ńÜäÕ╝Ƶ║ɵĪåµ×Č’╝īÕ£©Õģ©ńÉāķāĮµ»öĶŠāńü½’╝īgithubõĖŖµ£ē23KńÜästarŃĆéÕĮōńäČõĮĀõ╣¤ÕÅ»õ╗źķĆēµŗ®ÕģČõ╗¢ńÜ䵌ČÕ║ŵĢ░µŹ«Õ║ō’╝īÕ”éInfluxDBŃĆüOpenTSDBõ╣ŗń▒╗ŃĆé
┬Ā
ÕåŹķģŹÕÉłõ╗źõĖĆõĖ¬ÕÅ»Ķ¦åÕī¢µĪåµ×Č’╝īµ»öÕ”égrafana’╝īÕ░åÕģČõĖŁńÜäµĢ░µŹ«Õ▒Ģńż║Õć║µØź’╝īÕ░▒Õ«īµłÉõ║åµĢ┤õĖ¬ńøæµÄ¦ń│╗ń╗¤ńÜäµÉŁÕ╗║ŃĆéńĮæõĖŖńÜäµÉŁÕ╗║µĢÖń©ŗõ╣¤µ£ēÕŠłÕżÜ’╝īÕ░▒õĖŹÕżÜĶ»┤õ║åŃĆé
┬Ā
┬Ā
Õ”éµ×£µ▓Īµ£ēń╗¤õĖƵĪåµ×ČńÜäĶ»Ø’╝īÕÅ»õ╗źõ╝śÕģłĶĆāĶÖæķĆÜĶ┐ćAOPńÜäµ¢╣Õ╝Å’╝īõ╗źµŁżÕ░ĮķćÅķÖŹõĮÄÕ¤ŗńé╣õ╗ŻńĀüńÜäń╝¢ÕåÖķćÅŃĆé
┬Ā
µĢ░µŹ«ķććķøåÕ░▒Õ£©AOPÕłćÕģźńÜäõĮŹńĮ«Ķ┐øĶĪīŃĆé
┬Ā
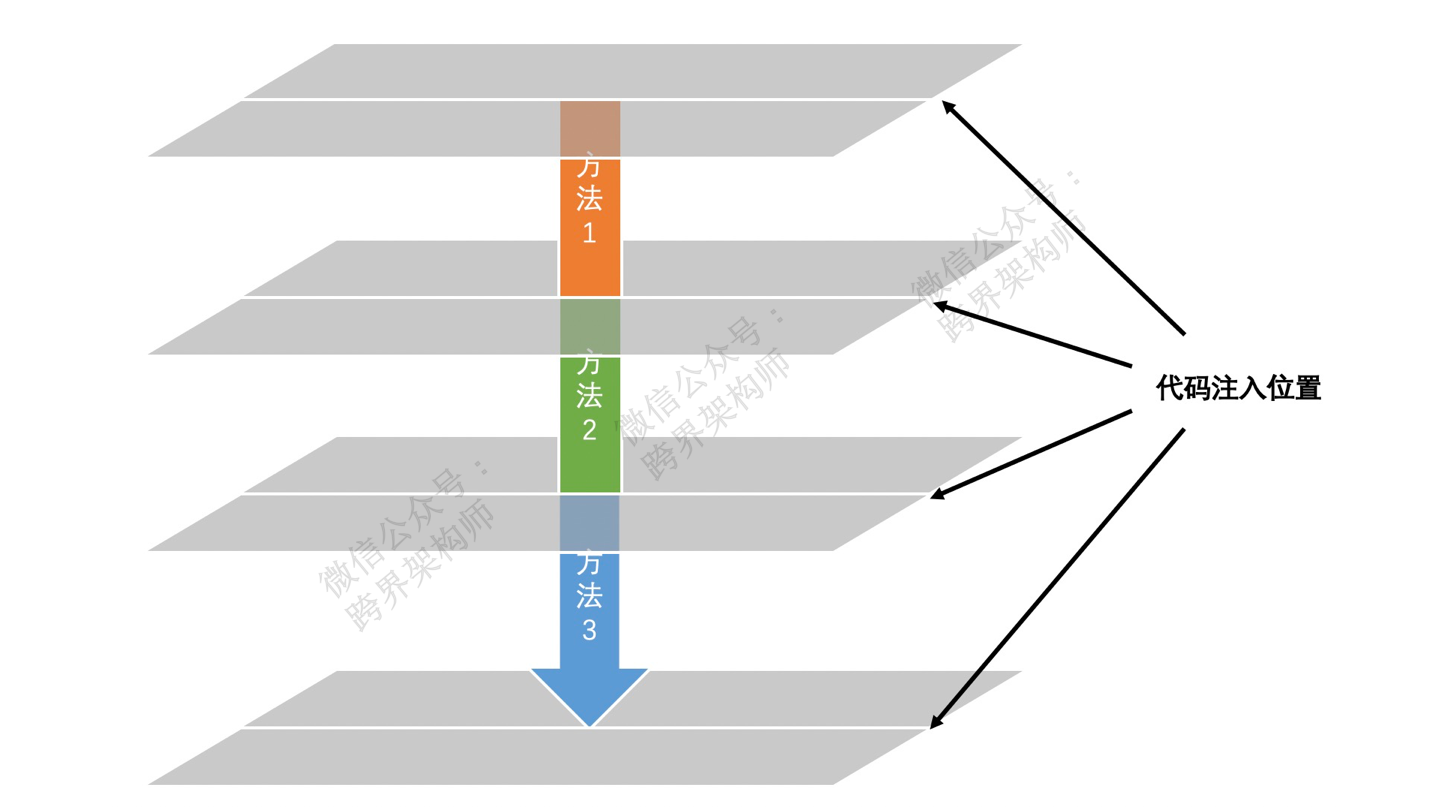
┬Ā
ńē╣Õł½µ│©µäÅõĖĆńé╣’╝īńö▒õ║ÄńøæµÄ¦õ║¦ńö¤ńÜ䵌źÕ┐ŚµĢ░ķćÅÕ║×Õż¦’╝īõĖŹÕ╗║Ķ««ńø┤µÄźõĖÄĶ┐£ń©ŗµĢ░µŹ«Õ║ōõ║żõ║ÆŃĆéµēĆõ╗źķ£ĆĶ”üÕƤÕŖ®õĖĆõ║øõĖōķŚ©ńÜ䵌źÕ┐ŚķććķøåÕÆīõ╝ĀĶŠōµĪåµ×ČŃĆéµ»öÕ”éflumeŃĆülogstashŃĆé
┬Ā
µĆÄõ╣łµä¤Ķ¦ēõĖĆõĖŗÕŁÉÕ╝ĢÕģźõ║åÕźĮÕżÜµ¢░µĪåµ×Č’Į×’╝īµ▓ĪÕŖ×µ│Ģ’╝īń£¤Ķ”üÕüÜÕźĮńøæµÄ¦µś»µī║ń╣üńÉÉńÜäŃĆé
┬Ā
┬Ā
õĖÜÕŖĪµīćµĀć
Õ£©ÕģĖÕ×ŗńÜäń©ŗÕ║ÅÕæśµĆØń╗┤ķćī’╝īĶ«żõĖ║õĖÜÕŖĪµīćµĀćÕģ│µłæõ╗Ćõ╣łõ║ŗŃĆéÕģČÕ«×µü░µü░õĖÜÕŖĪµīćµĀćńÜäńøæµÄ¦µø┤ÕŖĀńÜäŌĆ£µ£ēµĢłŌĆØŃĆéÕøĀõĖ║õĖÜÕŖĪµīćµĀćÕć║ķŚ«ķóśõ║å’╝īĶ»┤µśÄÕ┐ģńäČÕō¬Õć║ķŚ«ķóśõ║å’╝īõĖŹõ╝ÜÕāÅÕēŹķØóĶüŖńÜäõĖżõĖ¬Õ▒éķØóńÜäµīćµĀć’╝īÕÅ»ĶāĮń£ŗńØĆÕźĮÕźĮńÜä’╝īõĮåµś»Õ«×ķÖģõĖÜÕŖĪÕŹ┤Õć║õ║åķŚ«ķóśŃĆé
┬Ā
µ£ĆĶ┐æĶ┐Ö2Õ╣┤Õ£©Ķ┐ÉĶÉźÕ£łķćīĶó½ŌĆ£ńłåńéÆŌĆØńÜäŃĆīÕó×ķĢ┐ķ╗æÕ«óŃĆŹµ”éÕ┐Ą’╝īµ£¼Ķ┤©õĖŖÕ░▒µś»ķĆÜĶ┐ćµĢ░µŹ«ķ®▒ÕŖ©ńÜäµ¢╣Õ╝ÅµØźÕüÜĶ┐ÉĶÉźÕĘźõĮ£ŃĆéĶĆīĶ┐ÖĶāīÕÉÄõŠØĶĄ¢ńÜäÕ░▒µś»õĖĆõĖ¬õĖÜÕŖĪµīćµĀćńøæµÄ¦ń│╗ń╗¤ŃĆé
┬Ā
┬Ā
µ»ÅõĖĆõĖ¬õĖÜÕŖĪõ╝Üń╗ÅĶ┐ćńÜäÕģ│ķö«ńŖȵĆü’╝īķāĮÕÅ»õ╗źõĮ£õĖ║ŃĆīõĖÜÕŖĪµīćµĀćŃĆŹµØźńøæµÄ¦ŃĆéõĮåµś»ńö▒õ║ÄõĖÜÕŖĪµīćµĀćÕŠĆÕŠĆõĖŹÕģʵ£ēŃĆīķĆÜńö©µĆ¦ŃĆŹ’╝īµēĆõ╗ź’╝īķ£ĆĶ”üµēŗÕŖ©Õ£©ń©ŗÕ║ÅķćīŃĆīÕ¤ŗńé╣ŃĆŹŃĆé
┬Ā
ÕøĀµŁż’╝īÕ»╣õĖÜÕŖĪµīćµĀćńÜäńøæµÄ¦Õ┐ģńäȵś»ŃĆīõŠĄÕģźµĆ¦ŃĆŹńÜäŃĆé
┬Ā
ĶāĮõĖŹĶāĮõĖŹĶ”üÕ¤ŗńé╣’╝¤õ╣¤õĖŹµś»µ▓Īµ£ēÕŖ×µ│ĢŃĆé
┬Ā
Õ”éµ×£Õ£©õĖĆõĖ¬ń│╗ń╗¤ńÜäÕłØµ£¤’╝īµ»öÕ”éµŚźPVÕ£©ńÖŠõĖćõ╗źõĖŗńÜä’╝īńø┤µÄźķĆÜĶ┐ćõĖÜÕŖĪµĢ░µŹ«Õ║ōµŗēµĢ░µŹ«õ╣¤õĖŹÕż▒õĖ║õĖĆõĖ¬ÕÅ¢ÕʦńÜäÕŖ×µ│ĢŃĆéĶ┐ÖµĀĘÕ░▒õĖŹńö©ÕåÖõ╗Ćõ╣łÕ¤ŗńé╣õ╗ŻńĀü’╝īń«ĆÕŹĢń▓ŚµÜ┤ŃĆé
┬Ā
Õł░õ║åµłÉķĢ┐µ£¤’╝īńø┤µÄźµŗēõĖÜÕŖĪµĢ░µŹ«Õ║ōĶĪīõĖŹķĆÜõ║å’╝īÕøĀõĖ║õ╝ÜÕ»╣µŁŻÕĖĖńÜäõĖÜÕŖĪÕżäńÉåõ║¦ńö¤µśŠĶæŚńÜäµĆ¦ĶāĮÕĮ▒ÕōŹŃĆéõĖŹĶ┐ć’╝īµŁżµŚČĶ┐śÕÅ»õ╗źķĆÜĶ┐ćµĢ░µŹ«Õ║ōÕ▒éķØóÕüÜõ║īµ¼ĪÕłåÕÅæ’╝īÕ░åµĢ░µŹ«Õ«×µŚČÕ£░ÕżŹÕłČÕł░õĖĆõĖ¬ÕŹĢńŗ¼ńÜäÕ║ōõĖŁ’╝īõ╗ÄĶ┐ÖõĖ¬Õ║ōµŗēµĢ░µŹ«õ╣¤ĶāĮŌĆ£µÆæŌĆØõĖƵ«ĄµŚČķŚ┤ŃĆé
┬Ā
ÕĮōńäČõ║å’╝īĶ┐Öõ║øÕŖ×µ│ĢÕŬĶāĮĶ¦ŻÕå│õĖĆķā©ÕłåķŚ«ķóśŃĆéÕ”éµ×£ķ£ĆĶ”üńøæµÄ¦ńÜäõĖÜÕŖĪµīćµĀćõĖŹÕŁśÕ£©õ║ÄõĖÜÕŖĪµĄüĶĮ¼ńÜäµĢ░µŹ«õĖŁ’╝łµ»öÕ”éńö©µłĘĶĪīõĖ║µĢ░µŹ«’╝ē’╝īķéŻÕ░▒µ▓ĪÕŖ×µ│Ģõ║å’╝īÕŬĶāĮĶĆüĶĆüÕ«×Õ«×ńÜäÕåÖŃĆīÕ¤ŗńé╣ŃĆŹõ╗ŻńĀüŃĆé
┬Ā
┬Ā
µĆ╗õĮōµØźń£ŗ’╝īĶ┐ÖõĖēÕ▒éµīćµĀćµü░ÕźĮµ×䵳ÉõĖĆõĖ¬ķćæÕŁŚÕĪöń╗ōµ×äŃĆéõ╗ÄńøæµÄ¦õ╗ĘÕĆ╝µØźń£ŗ õĖÜÕŖĪµīćµĀć > ń©ŗÕ║ŵīćµĀć > ńÄ»ÕóāµīćµĀćŃĆéõ╗ÄÕ«×µ¢ĮńÜäõĖĆõĖ¬µłÉµ£¼µØźń£ŗ’╝īõ╣¤µś» õĖÜÕŖĪµīćµĀć > ń©ŗÕ║ŵīćµĀć > ńÄ»ÕóāµīćµĀćŃĆé
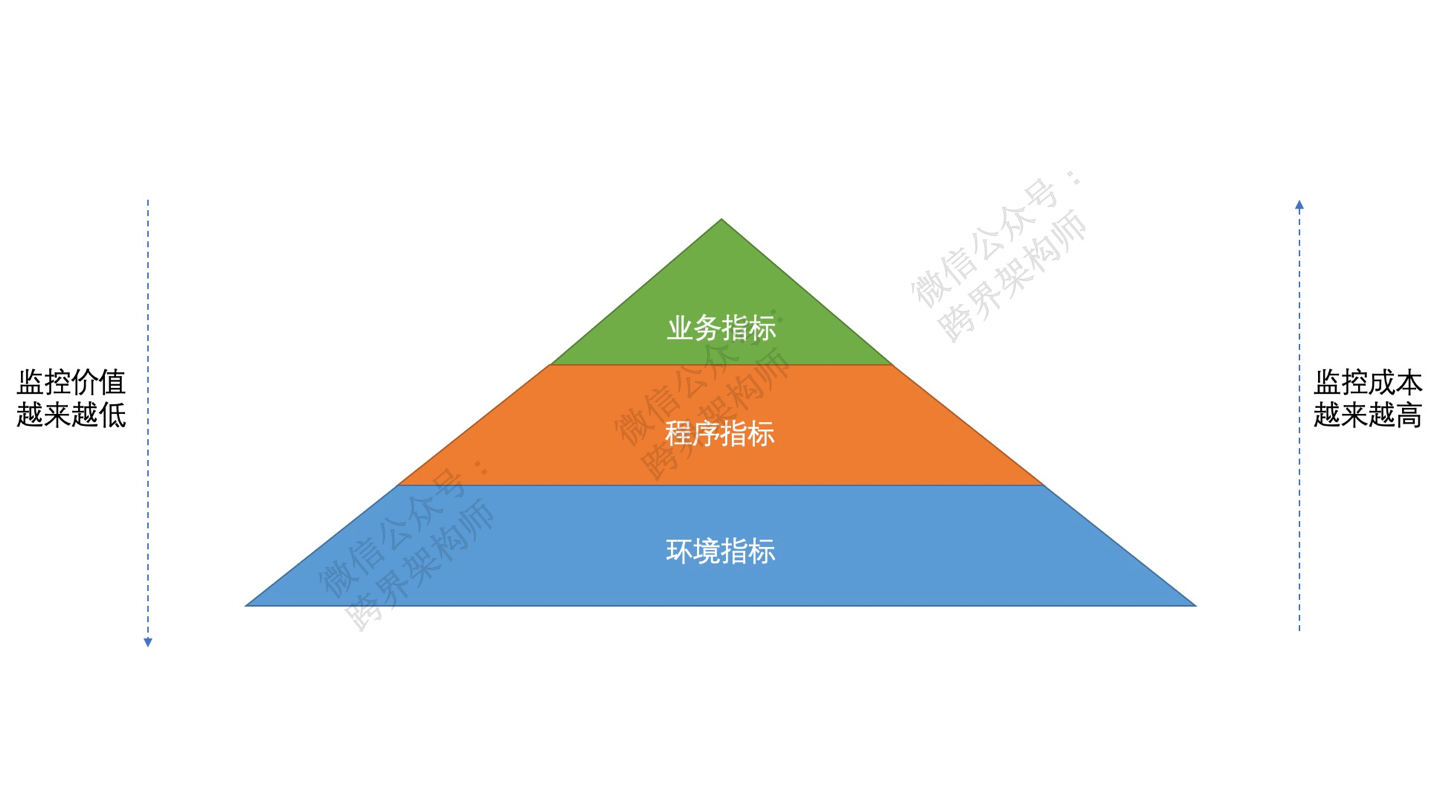
ZÕōźń╗ÖõĮĀńÜäµÖ«ķĆéµĆ¦Õ╗║Ķ««µś»’╝īõĖŹń«ĪµĆÄõ╣łµĀĘ’╝īńÄ»ÕóāµīćµĀćÕģłÕüÜõ║å’╝īµ»Ģń½¤µŖĢÕģźńÜ䵳ɵ£¼ķØ×ÕĖĖÕ░Å’╝īĶüŖĶā£õ║ĵŚĀÕśøŃĆé
┬Ā
Õģȵ¼Ī’╝īÕģłķĆÜĶ┐ćńø┤µÄźµŗēdbńÜäµ¢╣Õ╝ÅńøæµÄ¦ķā©ÕłåķćŹńé╣õĖÜÕŖĪµīćµĀćŃĆé
┬Ā
ńäČÕÉÄ’╝īÕåŹµŖŖń©ŗÕ║ŵīćµĀćńøæµÄ¦ĶĪźÕģģõĖŖŃĆé
┬Ā
µ£ĆÕÉÄ’╝īÕåŹµ¤źµ╝ÅĶĪźń╝║Õ«īµłÉµēĆĶ░ōńÜäÕģ©µ¢╣õĮŹŃĆīń½ŗõĮōÕī¢ńøæµÄ¦ŃĆŹŃĆé
┬Ā
┬Ā
ÕæŖĶŁ”ńŁ¢ńĢź
ÕÅ»ĶāĮõĮĀõ╝ÜĶ¦ēÕŠŚµ¢ćń½ĀÕł░Ķ┐Öķćīń╗ōµØ¤õ║å’╝īÕģČÕ«×Ķ┐śµ▓Ī’╝īÕēŹķØóõĖ╗Ķ”üĶüŖõ║åńøæµÄ¦õĮōń│╗ńÜäŌĆ£ń£ŗŌĆØŃĆéõĮåµś»ńøæµÄ¦õĮōń│╗Ķ┐śµ£ēÕÅ”Õż¢õĖĆõĖ¬ķćŹńé╣µś»ŌĆ£ÕŽŌĆØŃĆéń╝║Õ░æõ║åŃĆīÕæŖĶŁ”µ£║ÕłČŃĆŹńÜäńøæµÄ¦õĮōń│╗µø┤Õāŵś»õĖ¬ŌĆ£ķØóÕŁÉÕĘźń©ŗŌĆØ’╝īÕ«×ķÖģńÜäńö©Õżäµ»öĶŠāµ£ēķÖÉŃĆé
┬Ā
ÕĮōõĮĀńÜäń│╗ń╗¤Ķ┐śµ»öĶŠāÕ░ÅńÜ䵌ČÕĆÖ’╝īÕæŖĶŁ”µĆÄõ╣łÕ╝äķāĮĶĪī’╝īÕō¬µĆĢµ»ÅõĖƵ¼ĪÕ╝éÕĖĖķāĮĶ¦”ÕÅæÕæŖĶŁ”ŃĆéõĮåµś»ķÜÅńØĆń│╗ń╗¤ńÜäÕÅæÕ▒Ģ’╝īÕæŖĶŁ”µ¼ĪµĢ░õĖĆÕżÜ’╝īÕ░▒ķ║╗ńā”õ║å’╝īÕ«īÕģ©Ķó½ŌĆ£µĘ╣µ▓ĪŌĆØÕ£©õ║åÕæŖĶŁ”õ┐Īµü»ńÜäŌĆصĄĘµ┤ŗŌĆ£õĖŁ’╝īńē╣Õł½µś»ķéŻń¦ŹõĖōķŚ©µ£ēõĖ¬ŌĆ£ÕæŖĶŁ”ńŠżŌĆØńÜäµāģÕåĄõĖŗŃĆé
┬Ā
µā│Ķ▒ĪõĖĆõĖŗ’╝īÕæŖĶŁ”ńŠżķćīµ»ÅÕłåķƤķāĮÕ£©Õ╝╣Õć║µ¢░ńÜäÕæŖĶŁ”’╝īÕō¬µĆĢõĮĀµ£ēŌĆ£õĖēÕż┤ÕģŁĶćéŌĆØõ╣¤ÕżäńÉåõĖŹĶ┐ćµØźŌĆ”ŌĆ”
┬Ā
µēĆõ╗źĶ┐Öķćīķ£ĆĶ”üÕ╝ĢÕģźõĖĆõĖ¬ÕæŖĶŁ”ńŁ¢ńĢź’╝īõĮ┐ÕŠŚÕæŖĶŁ”µø┤ÕŖĀńÜäõ║║µĆ¦Õī¢ŃĆéĶ┐ÖõĖ¬µ£║ÕłČńÜäµĀĖÕ┐āÕ░▒µś»4ńé╣ŃĆé
┬Ā
-
µó│ńÉåõĖŹÕÉīńÜäÕæŖĶŁ”ń║¦Õł½
-
ÕłČÕ«ÜÕæŖĶŁ”ķóæńÄćõ╗źÕÅŖÕüÜÕźĮŃĆīµöȵĢøŃĆŹ’╝łõĖ╗Ķ”üµś»ÕÄ╗ķćŹŃĆüÕÉłÕ╣ȵĢ░ķćÅ’╝ē
-
Õå│Õ«ÜõĖŹÕÉīńÜäÕæŖĶŁ”ń║¦Õł½ķĆÜĶ┐ćõ╗Ćõ╣łÕĮóÕ╝ÅÕÅæÕć║ķĆÜń¤ź’╝łń¤Łõ┐ĪŃĆüµēŗµ£║ķĆÜń¤źŃĆüķé«õ╗ČńŁē’╝ē
-
ÕÅæń╗ÖĶ░ü’╝łµ»öÕ”é’╝īµś»õĖŹµś»ķ£ĆĶ”üŌĆ£ĶĮ«ĶĮ¼ŌĆصł¢ĶĆģŌĆ£ķĆÉń║¦õĖŖµŖźŌĆØĶ┐ÖµĀĘ’╝ē
┬Ā
ÕĮōńäČõ║å’╝īńÄ░Õ£©ĶČŖµØźĶČŖÕżÜńÜäÕż¦Õ×ŗÕ╝ĆÕÅæÕøóķś¤Õ╝ĆÕ¦ŗÕ╝ĢÕģźAIµØźõĮ┐ÕŠŚÕæŖĶŁ”µø┤ÕŖĀńÜäµÖ║ĶāĮÕī¢’╝īõĮåµś»ń”╗µłæõ╗¼Õż¦ÕżÜµĢ░õ║║µēĆÕżäńÜäÕĘźõĮ£Õ£║µÖ»Ķ┐śµś»µ£ēõĖĆÕ«ÜĶĘØń”╗ńÜä’╝īõĖŹńö©µĆź’╝īõĖƵŁźõĖƵŁźµØźŃĆé
┬Ā
┬Ā
µĆ╗ń╗ō
ÕźĮõ║å’╝īµØźõĖĆĶĄĘµĆ╗ń╗ōõĖĆõĖŗŃĆé
┬Ā
Ķ┐Öµ¼ĪÕæó’╝īZÕōźõĖ╗Ķ”üÕÆīõĮĀĶüŖõ║åÕ£©õĖēõĖ¬Õ▒éµ¼ĪõĖŖńÜäńøæµÄ¦Õüܵ│Ģ’╝īÕ╣ČõĖöń╗ÖÕć║õ║åõĖ¬õ║║Ķ«żõĖ║ńøĖÕ»╣Õ╣│µ╗æńÜäµ╝öĶ┐øĶĘ»ń║┐’╝īõŠøõĮĀÕÅéĶĆāŃĆé
┬Ā
ńäČÕÉÄ’╝īÕåŹĶüŖõ║åõĖŗÕæŖĶŁ”ńŁ¢ńĢźńÜäÕłČիܵ¢╣Õ╝ÅŃĆéÕæŖĶŁ”ķ£ĆĶ”üµø┤ÕŖĀńÜäõ║║µĆ¦Õī¢’╝īÕ”éµŁżµēŹĶāĮĶ«®õ║║ķćŹĶ¦åŃĆé
┬Ā
ÕĖīµ£øÕ»╣õĮĀµ£ēµēĆÕĖ«ÕŖ®ŃĆé
┬Ā
┬Ā

┬Ā
┬Ā
µÄ©ĶŹÉķśģĶ»╗’╝Ü
┬Ā
┬Ā
õĮ£ĶĆģ’╝ÜZachary
Õć║Õżä’╝Ühttps://www.cnblogs.com/Zachary-Fan/p/monitor.html
┬Ā
Õ”éµ×£õĮĀÕ¢£µ¼óĶ┐Öń»ćµ¢ćń½Ā’╝īÕÅ»õ╗źńé╣õĖĆõĖŗõĖŗµ¢╣ńÜäŃĆīÕż¦µŗćµīćŃĆŹŃĆé
Ķ┐ÖµĀĘÕÅ»õ╗źń╗ÖµłæõĖĆńé╣ÕÅŹķ”łŃĆé: )
Ķ░óĶ░óõĮĀńÜäõĖŠµēŗõ╣ŗÕŖ│ŃĆé
┬Ā
Ō¢ČÕģ│õ║ÄõĮ£ĶĆģ’╝ÜÕ╝ĀÕĖå’╝łZachary’╝īõĖ¬õ║║ÕŠ«õ┐ĪÕÅĘ’╝ÜZachary-ZF’╝ēŃĆéÕØܵīüńö©Õ┐āµēōńŻ©µ»ÅõĖĆń»ćķ½śĶ┤©ķćÅÕÄ¤ÕłøŃĆéµ¼óĶ┐ĵē½µÅÅõĖŗµ¢╣ńÜäõ║īń╗┤ńĀü~ŃĆé
իܵ£¤ÕÅæĶĪ©ÕÄ¤ÕłøÕåģÕ«╣’╝ܵ×ȵ×äĶ«ŠĶ«ĪõĖ©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖ©õ║¦ÕōüõĖ©Ķ┐ÉĶÉźõĖ©õĖĆõ║øµĆØĶĆāŃĆé
Õ”éµ×£õĮĀµś»ÕłØń║¦ń©ŗÕ║ÅÕæś’╝īµā│µÅÉÕŹćõĮåõĖŹń¤źķüōÕ”éõĮĢõĖŗµēŗŃĆéÕÅłµł¢ĶĆģÕüÜń©ŗÕ║ÅÕæśÕżÜÕ╣┤’╝īķÖĘÕģźõ║åõĖĆõ║øńōČķółµā│µŗōÕ«ĮõĖĆõĖŗĶ¦åķćÄŃĆéµ¼óĶ┐ÄÕģ│µ│©µłæńÜäÕģ¼õ╝ŚÕÅĘŃĆīĶĘ©ńĢīµ×ȵ×äÕĖłŃĆŹ’╝īÕø×ÕżŹŃĆīµŖƵ£»ŃĆŹ’╝īķĆüõĮĀõĖĆõ╗ĮµłæķĢ┐µ£¤µöČķøåÕÆīµĢ┤ńÉåńÜäµĆØń╗┤Õ»╝ÕøŠŃĆé
Õ”éµ×£õĮĀµś»Ķ┐ÉĶÉź’╝īķØóÕ»╣õĖŹµ¢ŁÕÅśÕī¢ńÜäÕĖéÕ£║µØ¤µēŗµŚĀńŁ¢ŃĆéÕÅłµł¢ĶĆģµā│õ║åĶ¦ŻõĖ╗µĄüńÜäĶ┐ÉĶÉźńŁ¢ńĢź’╝īõ╗źõĖ░Õ»īĶć¬ÕĘ▒ńÜäŌĆ£õ╗ōÕ║ōŌĆØŃĆéµ¼óĶ┐ÄÕģ│µ│©µłæńÜäÕģ¼õ╝ŚÕÅĘŃĆīĶĘ©ńĢīµ×ȵ×äÕĖłŃĆŹ’╝īÕø×ÕżŹŃĆīĶ┐ÉĶÉźŃĆŹ’╝īķĆüõĮĀõĖĆõ╗ĮµłæķĢ┐µ£¤µöČķøåÕÆīµĢ┤ńÉåńÜäµĆØń╗┤Õ»╝ÕøŠŃĆé

┬Ā



ńøĖÕģ│µÄ©ĶŹÉ
ÕłåÕĖāÕ╝Åń│╗ń╗¤Ķ«ŠĶ«Īµ©ĪÕ╝ŵś»µīćÕ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁ’╝īõĖ║õ║åĶ¦ŻÕå│Õ”éõĮĢÕłÆÕłåµ£ŹÕŖĪŃĆüÕ”éõĮĢķā©ńĮ▓µ£ŹÕŖĪõ╗źÕÅŖÕ”éõĮĢń╗äń╗ćµ£ŹÕŖĪķŚ┤ķĆÜõ┐ĪńŁēķŚ«ķóśĶĆīķććńö©ńÜäõĖĆõ║øķĆÜńö©µ¢╣µĪłÕÆīńŁ¢ńĢźŃĆéĶ┐Öõ║øµ©ĪÕ╝ÅĶāĮÕż¤Õ£©õĖŹÕÉīńÜäÕłåÕĖāÕ╝ÅńÄ»ÕóāÕÆīÕ║öńö©Õ£║µÖ»õĖŁÕ║öńö©’╝īõ╗źµ£¤ĶŠŠÕł░ń│╗ń╗¤Ķ«ŠĶ«ĪńÜäµ£Ćõ╝śĶ¦Ż...
Prometheusõ║Ä2012Õ╣┤ńö▒SoundCloudÕłøÕ╗║’╝īńø«ÕēŹÕĘ▓ń╗ÅÕĘ▓ÕÅæÕ▒ĢõĖ║µ£ĆńāŁķŚ©ńÜäÕłåÕĖāÕ╝ÅńøæµÄ¦ń│╗ń╗¤ŃĆéPrometheusÕ«īÕģ©Õ╝Ƶ║ÉńÜä’╝īĶó½ÕŠłÕżÜõ║æÕÄéÕĢå’╝łµ×ȵ×ä’╝ēÕåģńĮ«’╝īÕ£©Ķ┐Öõ║øÕÄéÕĢå’╝łµ×ȵ×ä’╝ēõĖŁ’╝īÕÅ»õ╗źń«ĆÕŹĢķā©ńĮ▓Prometheus’╝īńö©µØźńøæµÄ¦µĢ┤õĖ¬õ║æÕ¤║ńĪƵ×ȵ×äĶ«Šµ¢ĮŃĆé...
ŃĆŖÕłåÕĖāÕ╝Åń│╗ń╗¤ÕĤńÉåõĖÄĶīāÕ×ŗŃĆŗõĮ£õĖ║õĖƵ£¼ń│╗ń╗¤õ╗ŗń╗ŹÕłåÕĖāÕ╝Åń│╗ń╗¤Õ¤║µ£¼ÕĤńÉåõĖÄÕ«×ĶĘĄÕ║öńö©ńÜäõ╣”ń▒Ź’╝īµČĄńø¢õ║åÕłåÕĖāÕ╝Åń│╗ń╗¤Ķ«ŠĶ«ĪõĖÄÕ«×ńÄ░ńÜäµĀĖÕ┐āńÉåÕ┐ĄŃĆéÕłåÕĖāÕ╝Åń│╗ń╗¤µīćńÜ䵜»ńö▒ÕżÜõĖ¬ÕÅ»õ╗źńŗ¼ń½ŗĶ┐ÉĶĪīńÜäĶ«Īń«ŚÕŹĢÕģāµ×䵳ÉńÜäń│╗ń╗¤’╝īĶ┐Öõ║øĶ«Īń«ŚÕŹĢÕģāķĆÜĶ┐ćķĆÜõ┐ĪńĮæń╗£ńøĖõ║Æ...
"Õ¤║õ║ÄScrapyńÜäÕłåÕĖāÕ╝ŵĢ░µŹ«ķććķøåõĖÄÕłåµ×ÉŌĆöŌĆöõ╗źń¤źõ╣ÄĶ»ØķóśõĖ║õŠŗ" µ£¼µ¢ćõĖ╗Ķ”üõ╗ŗń╗Źõ║åÕ¤║õ║ÄScrapyµĪåµ×ČńÜäÕłåÕĖāÕ╝ŵĢ░µŹ«ķććķøåõĖÄÕłåµ×ɵ¢╣µ│Ģ’╝īõ╗źń¤źõ╣ÄĶ»ØķóśõĖ║õŠŗŃĆéĶ»źµ¢╣µ│ĢķĆÜĶ┐ćÕ«×ńÄ░õĖ╗õ╗ÄÕ╝Åń╗ōµ×äńÜäÕłåÕĖāÕ╝ÅńĮæń╗£ńł¼ĶÖ½’╝īĶ┐Éńö©Õ╝Ƶ║ÉķĪ╣ńø«Scrapy-RedisµØźķā©ńĮ▓...
µ£¼õ╣”µČĄńø¢õ║åÕŖĀÕ»åµŖƵ£»ŃĆüĶ«żĶ»üµ£║ÕłČŃĆüĶ«┐ķŚ«µÄ¦ÕłČńŁēµ¢╣ķØóńÜäń¤źĶ»åńé╣’╝īÕ╣Čõ╗ŗń╗Źõ║åÕ”éõĮĢµ×äÕ╗║Õ«ēÕģ©ÕÅ»ķØĀńÜäÕłåÕĖāÕ╝Åń│╗ń╗¤ŃĆé #### ÕøøŃĆüµĪłõŠŗÕłåµ×É ķÖżõ║åńÉåĶ«║ķā©Õłåõ╣ŗÕż¢’╝īŃĆŖÕłåÕĖāÕ╝Åń│╗ń╗¤’╝ܵ”éÕ┐ĄõĖÄĶ«ŠĶ«ĪŃĆŗĶ┐śµÅÉõŠøõ║åõĖ░Õ»īńÜäµĪłõŠŗńĀöń®Č’╝īķĆÜĶ┐ćÕģĘõĮōńÜäõŠŗÕŁÉÕĖ«ÕŖ®...
#ĶĄäµ║ÉĶŠŠõ║║Õłåõ║½Ķ«ĪÕłÆ#
ÕŹŚńÉåÕĘź ķŁÅµØŠµØ░ Õ»╣Õ║öõ╗¢ńÜäĶŗ▒µ¢ćńēłµ£¼PPTÕżŹõ╣ĀÕÅ»ńö©’╝īÕÉīµŚČµś»ÕŁ”õ╣ĀÕłåÕĖāÕ╝Åń│╗ń╗¤ńÜäÕŠłÕźĮńÜäPPT’╝īÕłåÕĖāÕ╝Åń│╗ń╗¤pptÕ»╣Õ║öÕłåÕĖāÕ╝Åń│╗ń╗¤ń¼¼õ║öńēłĶŗ▒µ¢ćńēłppt’╝īÕżŹõ╣Ā’╝īĶć¬ÕŁ”ÕÅ»ńö©’╝īõ║åĶ¦ŻÕłåÕĖāÕ╝Åń│╗ń╗¤’╝īÕģ▒10ń½Ā’╝ī01-µ”éĶ┐░’╝ī02-ń│╗ń╗¤µ©ĪÕ×ŗ’╝ī03-Ķ┐øń©ŗķŚ┤ķĆÜõ┐Ī’╝ī04-...
#ĶĄäµ║ÉĶŠŠõ║║Õłåõ║½Ķ«ĪÕłÆ#
ÕłåÕĖāÕ╝Åń╗╝ÕÉłĶāĮµ║Éń│╗ń╗¤Ķ¦äÕłÆµŖźÕæŖŌĆöŌĆö.pdf
### ÕłåÕĖāÕ╝ŵ¢ćõ╗Čń│╗ń╗¤ńĀöń®ČŌĆöŌĆöµ░æķŚ┤ÕŁ”õ╣ĀµĆ╗ń╗ō #### µ”éĶ┐░õĖÄÕ«Üõ╣ē ÕłåÕĖāÕ╝ŵ¢ćõ╗Čń│╗ń╗¤’╝łDistributed File System, DFS’╝ēµś»õĖĆń¦Źµ¢ćõ╗Čń│╗ń╗¤µ©ĪÕ×ŗ’╝īÕ«āĶāĮÕż¤õĮ┐ńö©µłĘķĆÜĶ┐ćńĮæń╗£Ķ«┐ķŚ«Ķ┐£ń©ŗńÜäµ¢ćõ╗Č’╝īÕ░▒Õ”éÕÉīĶ┐Öõ║øµ¢ćõ╗ČÕŁśÕé©Õ£©µ£¼Õ£░õĖƵĀĘŃĆéDFSÕģüĶ«Ėńö©µłĘ...
ÕłåÕĖāÕ╝Åńź×ń╗ÅńĮæń╗£µĪåµ×ČŌĆöŌĆöÕłåÕĖāÕ╝Åńź×ń╗ÅńĮæń╗£
15. **µĆ¦ĶāĮńøæµÄ¦õĖÄĶ░āõ╝ś**’╝ÜÕ»╣ÕłåÕĖāÕ╝Åń│╗ń╗¤ńÜäµĆ¦ĶāĮńøæµÄ¦ÕÆīĶ░āõ╝śµś»µīüń╗ŁńÜäÕĘźõĮ£’╝īõ╗źńĪ«õ┐Øń│╗ń╗¤ńÜäń©│Õ«ÜµĆ¦ÕÆīµĢłńÄćŃĆé ń╗╝õĖŖµēĆĶ┐░’╝īŃĆŖÕłåÕĖāÕ╝Åń│╗ń╗¤ÕĤńÉåõĖÄĶīāÕ×ŗ’╝łń¼¼õ║īńēł’╝ēŃĆŗńÜäńŁöµĪłµ¢ćµĪŻÕÅ»ĶāĮõ╝ܵȥńø¢õ╗źõĖŖµēƵ£ēµł¢ķā©Õłåń¤źĶ»åńé╣’╝īõĖ║Ķ»╗ĶĆģµÅÉõŠøÕ»╣ÕłåÕĖāÕ╝Å...
µ£¼Ķ»Šõ╗Č"ÕłåÕĖāÕ╝Åń│╗ń╗¤PPT"ÕÅ»ĶāĮµČĄńø¢õ║åõ╗źõĖŗÕćĀõĖ¬µĀĖÕ┐āń¤źĶ»åńé╣’╝Ü 1. **ÕłåÕĖāÕ╝Åń│╗ń╗¤Õ¤║µ£¼µ”éÕ┐Ą**’╝ÜĶ«▓Ķ¦ŻÕłåÕĖāÕ╝Åń│╗ń╗¤ńÜäÕ¤║µ£¼ń╗䵳ÉÕģāń┤Ā’╝īÕ”éĶŖéńé╣ŃĆüńĮæń╗£ŃĆüķĆÜõ┐ĪÕŹÅĶ««ńŁē’╝īÕ╣Čõ╗ŗń╗ŹÕģČõĖÄķøåõĖŁÕ╝Åń│╗ń╗¤ńÜäÕī║Õł½ŃĆéÕłåÕĖāÕ╝Åń│╗ń╗¤ńÜäµĀĖÕ┐āńē╣µĆ¦Õīģµŗ¼ķĆŵśÄµĆ¦ŃĆüõĖĆĶć┤...
ÕłåÕĖāÕ╝ÅÕ«×µŚČńøæµÄ¦ń│╗ń╗¤µś»õĖĆń¦Źńö©õ║ÄńøæµÄ¦ÕłåÕĖāÕ╝Åń│╗ń╗¤Ķ┐ÉĶĪīńŖȵĆüńÜäÕĘźÕģĘ’╝īÕ«āĶāĮÕż¤Õ«×µŚČÕ£░µöČķøåÕÆīÕłåµ×ÉÕłåÕĖāÕ╝Åń│╗ń╗¤ÕÉäńÄ»ĶŖéńÜäµĆ¦ĶāĮµĢ░µŹ«’╝īõ╗ÄĶĆīÕĖ«ÕŖ®Õ╝ĆÕÅæĶĆģÕ┐½ķĆ¤Õ«ÜõĮŹķŚ«ķóśŃĆüõ╝śÕī¢ń│╗ń╗¤µĆ¦ĶāĮŃĆüĶ┐øĶĪīµĢģķÜ£ķóäĶŁ”ÕÆīÕłåµ×ÉńŁēŃĆéĶ┐Öń▒╗ńøæµÄ¦ń│╗ń╗¤Õ£©Õż¦Õ×ŗÕłåÕĖāÕ╝Åń│╗ń╗¤...
#ĶĄäµ║ÉĶŠŠõ║║Õłåõ║½Ķ«ĪÕłÆ#
Õ£©µÄóĶ«©ŌĆ£Õ壵ØæÕłåÕĖāÕ╝ÅÕģēõ╝ÅÕÅæńöĄµŖĢĶĄäķŻÄķÖ®Õłåµ×ÉŌĆöŌĆöÕ¤║õ║ÄĶÆÖńē╣ÕŹĪµ┤øµ©Īµŗ¤ŌĆØńÜäÕåģÕ«╣õ╣ŗÕēŹ’╝īµłæõ╗¼ķ”¢Õģłķ£ĆĶ”üõ║åĶ¦ŻÕćĀõĖ¬Õģ│ķö«µ”éÕ┐ĄŃĆé Õģēõ╝ÅÕÅæńöĄµś»Õł®ńö©ÕŹŖÕ»╝õĮōńĢīķØóńÜäÕģēńö¤õ╝Åńē╣µĢłÕ║ö’╝īÕ░åÕż¬ķś│ĶŠÉÕ░äĶāĮńø┤µÄźĶĮ¼µŹóµłÉńöĄĶāĮńÜäõĖĆń¦Źµ¢░Õ×ŗĶāĮµ║ɵŖƵ£»ŃĆéÕłåÕĖāÕ╝ÅÕģēõ╝Å...
Ķ┐Öõ║øµŖƵ£»µČĄńø¢õ║åÕłåÕĖāÕ╝ÅµČłµü»µ£ŹÕŖĪŃĆüÕłåÕĖāÕ╝ÅĶ«Īń«ŚŃĆüÕłåÕĖāÕ╝ÅÕŁśÕé©ŃĆüÕłåÕĖāÕ╝ÅńøæµÄ¦ń│╗ń╗¤ŃĆüÕłåÕĖāÕ╝Åńēłµ£¼µÄ¦ÕłČŃĆüRESTfulŃĆüÕŠ«µ£ŹÕŖĪŃĆüÕ«╣ÕÖ©ńŁēķóåÕ¤¤ńÜäÕåģÕ«╣ŃĆéń¼¼õĖēķā©ÕłåķĆēõĖŠõ║åõ╗źµĘśÕ«ØńĮæÕÆī Twitter õĖ║õ╗ŻĶĪ©ńÜäÕøĮÕåģÕż¢ń¤źÕÉŹõ║ÆĶüöńĮæõ╝üõĖÜńÜäÕż¦Õ×ŗÕłåÕĖāÕ╝Åń│╗ń╗¤...
ŃĆÉÕłåÕĖāÕ╝Åń│╗ń╗¤ÕŁ”õ╣ĀŌĆöŌĆöGFSĶ░ʵŁīµ¢ćõ╗Čń│╗ń╗¤Paperń┐╗Ķ»æ1ŃĆæ Ķ░ʵŁīµ¢ćõ╗Čń│╗ń╗¤’╝łGoogle File System, GFS’╝ēµś»õĖĆõĖ¬õĖōõĖ║Õż¦Ķ¦äµ©ĪÕłåÕĖāÕ╝ŵĢ░µŹ«ÕżäńÉåĶ«ŠĶ«ĪńÜäÕÅ»µē®Õ▒ĢńÜäÕłåÕĖāÕ╝ŵ¢ćõ╗Čń│╗ń╗¤ŃĆéÕ«āÕ¤║õ║ĵ֫ķĆÜńÜäŃĆüõ╗ʵĀ╝ķĆéõĖŁńÜäńĪ¼õ╗ČĶ«ŠÕżć’╝īµŚ©Õ£©Õ£©Õ«╣ķöֵƦŃĆüµĆ¦ĶāĮ...