
µטסΣ╗¼σ«₧µק╢σ╝ץµףמτ╗הµצ░σ╝ץσוÑΣ║זΣ╕אµ¼╛σטזσ╕דσ╝ןSQLµƒÑΦ»óσ╝ץµףמ∩╝לσנםσ¡קσן½Presto∩╝לτ¢«σיםσ╖▓τ╗ןΦ░דτáפσעלµ╡כΦ»ץΣ║ז2Σ╕¬µ£טΣ║ז∩╝לσ╣╢Σ╕פµ£ƒΘק┤µƒנσ╣│σן░Σ╣ƒΣ╗מimpalaσ╣│σן░Φ┐בσוÑσט░Σ║זPrestoσ╣│σן░∩╝לµƒÑΦ»óµאºΦד╜µ£יΣ║ז2-3σאםτתהµןנσםח∩╝טσנהτºםσמƒσ¢áσ»╝Φח┤∩╝י∩╝לµיאΣ╗ѵ£¼µצחσ░זτ╗ףσנטΣ╜£ΦאוΦ┐שµ«╡µק╢Θק┤τתהµ╡כΦ»ץσעלΦ░דτáפτáפτ⌐╢∩╝לµ¥Ñµן¡σ╝אPrestoτתהτÑ₧τºרΘ¥óτ║▒πאג
Prestoµר»τÑ₧Θ⌐¼
Prestoµר»τפ▒Facebookσ╝אσןסτתהΣ╕אΣ╕¬σטזσ╕דσ╝ןSQLµƒÑΦ»óσ╝ץµףמ∩╝ל σ«דΦó½Φ«╛Φ«íΣ╕║τפ¿µ¥ÑΣ╕ףΘק¿Φ┐¢ΦíלΘ½רΘאƒπאבσ«₧µק╢τתהµץ░µם«σטזµ₧נπאגσ«דτתהΣ║ºτפƒµר»Σ╕║Σ║זΦºúσז│HiveτתהMapReduceµ¿íσ₧כσñ¬µוóΣ╗ÑσןךΣ╕םΦד╜ΘאתΦ┐חBIµטצDashboardsτ¢┤µמÑσ▒ץτמ░HDFSµץ░µם«τ¡יΘק«ΘóרπאגPrestoµר»Σ╕אΣ╕¬τ║»τ▓╣τתהΦ«íτ«קσ╝ץµףמ∩╝לσ«דΣ╕םσ¡רσג¿µץ░µם«∩╝לσו╢ΘאתΦ┐חConnectorΦמ╖σןצτ¼¼Σ╕יµצ╣Storageµ£םσךíτתהµץ░µם«πאג
σמזσן▓
- 2012σ╣┤τºכσ¡ú∩╝לFacebookσנ»σך¿PrestoΘí╣τ¢«
- 2013σ╣┤σז¼σ¡ú∩╝לPrestoσ╝אµ║נ
- 2017σ╣┤11µ£ט∩╝ל11888 commits∩╝ל203 releases∩╝ל198 contributors
σךƒΦד╜σעלΣ╝רτג╣
- Ad-hoc∩╝לµ£ƒµ£¢µƒÑΦ»óµק╢Θק┤τºעτ║ºµטצσחáσטזΘעƒ
- µ»פHiveσ┐½10σאם
- µפ»µלבσñתµץ░µם«µ║נ∩╝לσªגHiveπאבKafkaπאבMySQLπאבMonogoDBπאבRedisπאבJMXτ¡י∩╝לΣ╣ƒσן»Φח¬σ╖▒σ«₧τמ░Connector
- Client Protocol: HTTP+JSON, support various languages(Python, Ruby, PHP, Node.js Java)
- µפ»µלבJDBC/ODBCΦ┐₧µמÑ
- ANSI SQL∩╝לµפ»µלבτ¬קσןúσח╜µץ░∩╝לjoin∩╝לΦבתσנט∩╝לσñםµ¥גµƒÑΦ»óτ¡י
µ₧╢µ₧ה
- Master-Slaveµ₧╢µ₧ה
- Σ╕יΣ╕¬µ¿íσ¥ק
- CoordinatorπאבDiscovery ServiceπאבWorker
- Connector
Prestoµ▓┐τפ¿Σ║זΘאתτפ¿τתהMaster-Slaveµ₧╢µ₧ה∩╝לCoordinatorσם│PrestoτתהMaster∩╝לWorkerσם│σו╢Slave∩╝לDiscovery Serviceσ░▒µר»τפ¿µ¥ÑΣ┐¥σ¡רWorkerτ╗ףτג╣Σ┐íµב»τתה∩╝לΘאתΦ┐חHTTPσםןΦ««ΘאתΣ┐í∩╝לΦאלConnectorτפ¿Σ║מΦמ╖σןצτ¼¼Σ╕יµצ╣σ¡רσג¿τתהMetadataσןךσמƒσºכµץ░µם«τ¡יπאג
CoordinatorΦ┤ƒΦ┤úΦºúµ₧נSQLΦ»¡σןÑ∩╝לτפƒµטנµיºΦíלΦ«íσטע∩╝לσטזσןסµיºΦíלΣ╗╗σךíτ╗שWorkerΦךגτג╣µיºΦíל∩╝¢WorkerΦךגτג╣Φ┤ƒΦ┤úσ«₧ΘשוµיºΦíלµƒÑΦ»óΣ╗╗σךíπאגWorkerΦךגτג╣σנ»σך¿σנמσנסDiscovery Serverµ£םσךíµ│¿σזל∩╝לCoordinatorΣ╗מDiscovery ServerΦמ╖σ╛קσן»Σ╗ѵ¡úσ╕╕σ╖ÑΣ╜£τתהWorkerΦךגτג╣πאגσבחσªגΘוםτ╜«Σ║זHive Connector∩╝לΘ£אΦªבΘוםτ╜«Σ╕אΣ╕¬Hive MetaStoreµ£םσךíΣ╕║PrestoµןנΣ╛¢HiveσודΣ┐íµב»∩╝לWorkerΦךגτג╣Σ╕מHDFSΣ║ñΣ║עΦ»╗σןצµץ░µם«πאג
Θד¿τ╜▓µצ╣σ╝ן
Prestoσ╕╕ΦºבτתהΘד¿τ╜▓µצ╣σ╝ןσªגΣ╕כσ¢╛µיאτñ║∩╝ת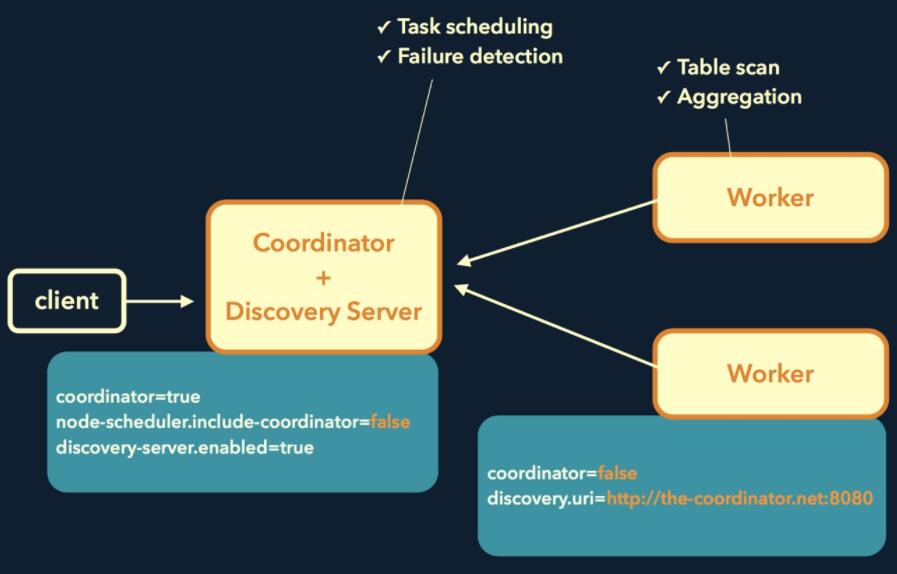
CoordinatorΣ╕מDiscovery ServerΦאªσנטσ£¿Σ╕אΦ╡╖µ╖╖σנטΘד¿τ╜▓∩╝לτה╢σנמΘד¿τ╜▓σñתσן░Workerπאגτה╢ΦאלΦ┐שΣ╕¬µ£יΣ╕¬Θק«Θóר∩╝לσ░▒µר»Coordinatorσ¡רσ£¿σםץτג╣Θק«Θóר∩╝לµטסΣ╗¼τ¢«σיםτ║┐Σ╕ךΣ╜┐τפ¿ipµ╝גτº╗τתהµצ╣µ│ץ∩╝טτ╜סσםíτ╗סσ«תσñתip∩╝יπאגσªגΣ╕כσ¢╛µיאτñ║∩╝ת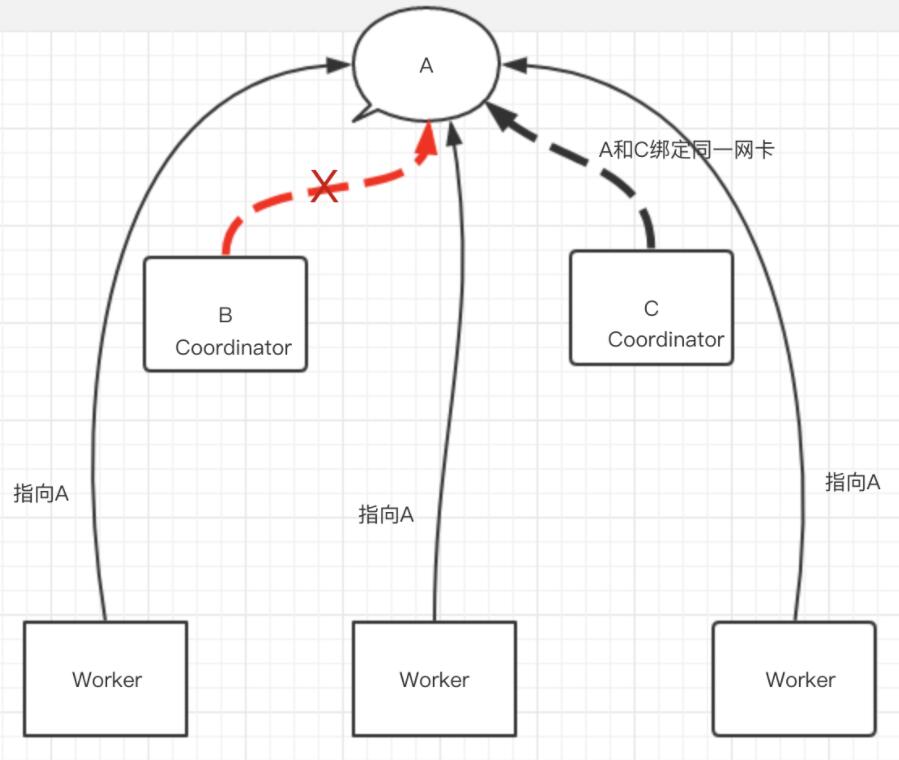
µƒÑΦ»óµ╡בτ¿כ
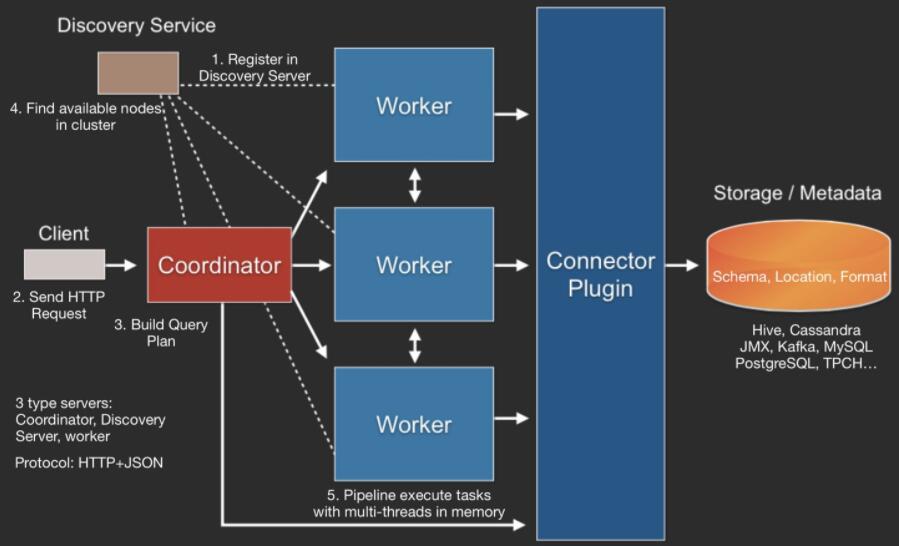
µץ┤Σ╜ףµƒÑΦ»óµ╡בτ¿כΣ╕║∩╝ת
- ClientΣ╜┐τפ¿HTTPσםןΦ««σןסΘאבΣ╕אΣ╕¬queryΦ»╖µ▒גπאג
- ΘאתΦ┐חDiscovery Serverσןסτמ░σן»τפ¿τתהServerπאג
- Coordinatorµ₧הσ╗║µƒÑΦ»óΦ«íσטע∩╝טConnectorµןעΣ╗╢µןנΣ╛¢Metadata∩╝י
- CoordinatorσנסworkersσןסΘאבΣ╗╗σךí
- WorkerΘאתΦ┐חConnectorµןעΣ╗╢Φ»╗σןצµץ░µם«
- Workerσ£¿σזוσ¡רΘחלµיºΦíלΣ╗╗σךí∩╝טWorkerµר»τ║»σזוσ¡רσ₧כΦ«íτ«קσ╝ץµףמ∩╝י
- Workerσ░זµץ░µם«Φ┐פσ¢₧τ╗שCoordinator∩╝לΣ╣כσנמσזםResponse Client
SQLµיºΦíלµ╡בτ¿כ
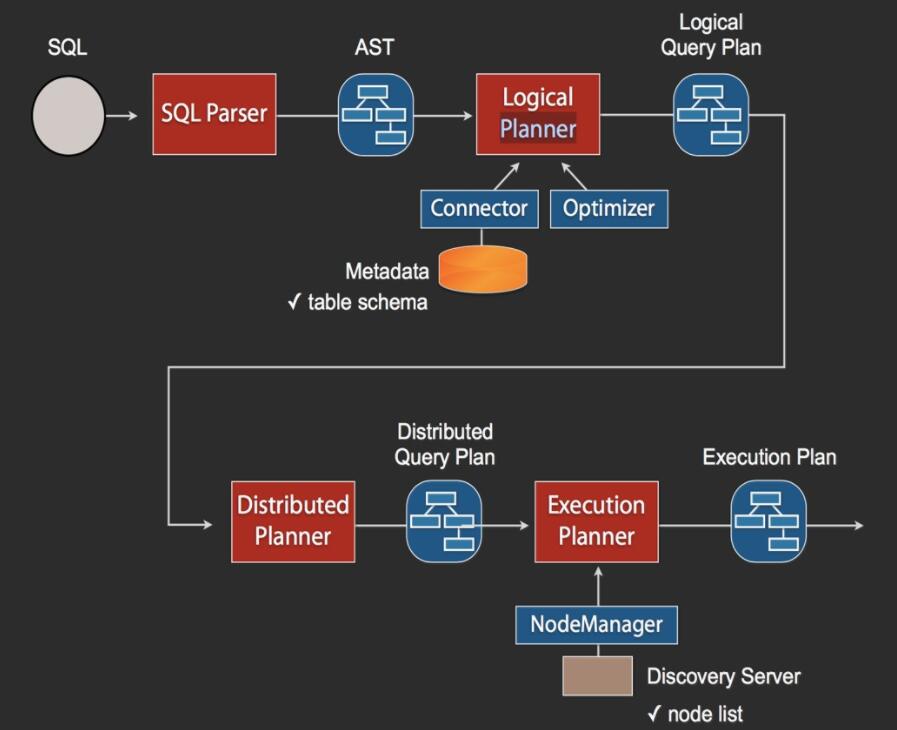
σ╜ףCoordinatorµפ╢σט░Σ╕אΣ╕¬Query∩╝לσו╢SQLµיºΦíלµ╡בτ¿כσªגΣ╕ךσ¢╛µיאτñ║πאגSQLΘאתΦ┐חAnltr3Φºúµ₧נΣ╕║AST∩╝טµך╜Φ▒íΦ»¡µ│ץµáס∩╝י∩╝לτה╢σנמΘאתΦ┐חConnectorΦמ╖σןצσמƒσºכµץ░µם«τתהMetadataΣ┐íµב»∩╝לΦ┐שΘחלΣ╝תµ£יΣ╕אΣ║¢Σ╝רσלצ∩╝לµ»פσªגτ╝ףσ¡רMetadataΣ┐íµב»τ¡י∩╝לµá╣µם«MetadataΣ┐íµב»τפƒµטנΘא╗Φ╛סΦ«íσטע∩╝לτה╢σנמΣ╝תΣ╛¥µ¼íτפƒµטנσטזσןסΦ«íσטעσעלµיºΦíלΦ«íσטע∩╝לσ£¿µיºΦíלΦ«íσטעΘחלΘ£אΦªבσמ╗DiscoveryΘחלΦמ╖σןצσן»τפ¿τתהnodeσטקΦí¿∩╝לτה╢σנמµá╣µם«Σ╕אσ«תτתהτ¡צτץÑ∩╝לσ░זΦ┐שΣ║¢Φ«íσטעσטזσןסσט░µלחσ«תτתהWorkerµ£║σש¿Σ╕ך∩╝לWorkerµ£║σש¿σזםσטזσט½µיºΦíלπאג
Σ╕מHiveµ»פΦ╛ד
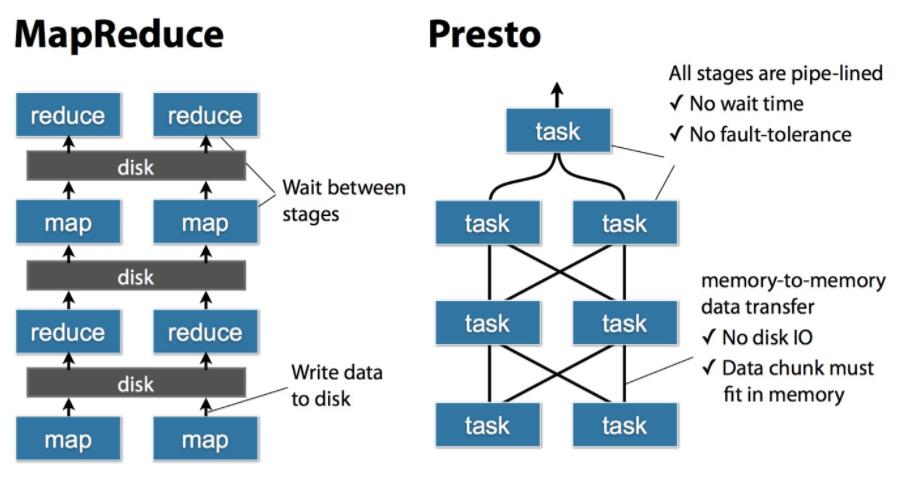
Σ╕ךσ¢╛µר╛τñ║Σ║זMapReduceΣ╕מPrestoτתהµיºΦíלΦ┐חτ¿כτתהΣ╕םσנלτג╣∩╝לMRµ»ןΣ╕¬µףםΣ╜£ΦªבΣ╣טΘ£אΦªבσזשτúבτ¢ר∩╝לΦªבΣ╣טΘ£אΦªבτ¡יσ╛וσיםΣ╕אΣ╕¬stageσו¿Θד¿σ«לµטנµיםσ╝אσºכµיºΦíל∩╝לΦאלPrestoσ░זSQLΦ╜¼µםóΣ╕║σñתΣ╕¬stage∩╝לµ»ןΣ╕¬stageσןטτפ▒σñתΣ╕¬tasksµיºΦíל∩╝לµ»ןΣ╕¬tasksσןטσ░זσטזΣ╕║σñתΣ╕¬splitπאגµיאµ£יτתהtaskµר»σ╣╢Φíלτתהµצ╣σ╝ןΦ┐¢ΦíלσובΦ«╕∩╝לstageΣ╣כΘק┤µץ░µם«µר»Σ╗Ñpipelineσ╜óσ╝ןµ╡בσ╝ןτתהµיºΦíל∩╝לµץ░µם«Σ╣כΘק┤τתהΣ╝áΦ╛ףΣ╣ƒµר»ΘאתΦ┐חτ╜סτ╗£Σ╗ÑMemory-to-Memoryτתהσ╜óσ╝ןΦ┐¢Φíל∩╝לµ▓íµ£יτúבτ¢רioµףםΣ╜£πאגΦ┐שΣ╣ƒµר»PrestoµאºΦד╜µ»פHiveσ┐½σ╛טσñתσאםτתהσז│σ«תµאºσמƒσ¢áπאג
σ«₧τמ░Σ╜מσ╗╢µק╢τתהσמƒτנז
- σ«לσו¿σƒ║Σ║מσזוσ¡רτתהσ╣╢ΦíלΦ«íτ«ק
- µ╡בµ░┤τ║┐
- µ£¼σ£░σלצΦ«íτ«ק
- σך¿µאבτ╝צΦ»סµיºΦíלΦ«íσטע
- σ░ןσ┐דΣ╜┐τפ¿σזוσ¡רσעלµץ░µם«τ╗ףµ₧ה
- τ▒╗BlinkDBτתהΦ┐סΣ╝╝µƒÑΦ»ó
- GCµמºσט╢
σ╜ףτה╢σו╢Σ╝רσלצµצ╣µ│ץΣ╣ƒσלוµכ¼Σ║זΣ╕אΣ║¢Σ╝áτ╗ƒτתהSQLΣ╝רσלצσמƒτנז∩╝לσו│Σ║מΦ┐שΣ║¢Σ╝רσלצτ╗זΦךגτ¡יσנמτ╗¡µצחτ½áΦ»ªτ╗זΣ╗כτ╗םπאג
τ╝║τג╣
σיםΘ¥óΣ╗כτ╗םΣ║זPrestoτתהσנהτºםΣ╝רτג╣∩╝לσו╢σ«₧σו╢Σ╣ƒµ£יΣ╕אΣ║¢τ╝║τג╣∩╝לΣ╕╗Φªבτ╝║τג╣Σ╕║Σ╗ÑΣ╕כΣ╕יµ¥í∩╝ת
- No fault tolerance∩╝¢σ╜ףΣ╕אΣ╕¬Queryσטזσןסσט░σñתΣ╕¬Workerσמ╗µיºΦíלµק╢∩╝לσ╜ףµ£יΣ╕אΣ╕¬Workerσ¢áΣ╕║σנהτºםσמƒσ¢áµƒÑΦ»óσñ▒Φ┤Ñ∩╝לΘגúΣ╣טMasterΣ╝תµהƒτƒÑσט░∩╝לµץ┤Σ╕¬QueryΣ╣ƒσ░▒µƒÑΦ»óσñ▒Φ┤ÑΣ║ז∩╝לΦאלPrestoσ╣╢µ▓íµ£יΘחםΦ»ץµ£║σט╢∩╝לµיאΣ╗ÑΘ£אΦªבτפ¿µט╖µצ╣σ«₧τמ░ΘחםΦ»ץµ£║σט╢πאג
- Memory Limitations for aggregations, huge joins∩╝¢µ»פσªגσñתΦí¿joinΘ£אΦªבσ╛טσñºτתהσזוσ¡ר∩╝לτפ▒Σ║מPrestoµר»τ║»σזוσ¡רΦ«íτ«ק∩╝לµיאΣ╗Ñσ╜ףσזוσ¡רΣ╕םσñƒµק╢∩╝לPrestoσ╣╢Σ╕םΣ╝תσ░זτ╗ףµ₧£dumpσט░τúבτ¢רΣ╕ך∩╝לµיאΣ╗ѵƒÑΦ»óΣ╣ƒσ░▒σñ▒Φ┤ÑΣ║ז∩╝לΣ╜זµ£אµצ░τיטµ£¼τתהPrestoσ╖▓µפ»µלבσזשτúבτ¢רµףםΣ╜£∩╝לΦ┐שΣ╕¬σ╛וσנמτ╗¡µ╡כΦ»ץσעלΦ░דτáפπאג
- MPP(Massively Parallel Processing )µ₧╢µ₧ה∩╝¢Φ┐שΣ╕¬σ╣╢Σ╕םΦד╜Φ»┤σו╢µר»Σ╕אΣ╕¬τ╝║τג╣∩╝לσ¢áΣ╕║MPPµ₧╢µ₧הσ░▒µר»Φºúσז│σñºΘחןµץ░µם«σטזµ₧נΦאלΣ║ºτפƒτתה∩╝לΣ╜זµר»σו╢τ╝║τג╣Σ╣ƒσ╛טµרמµר╛∩╝לσבחσªגµטסΣ╗¼Φ«┐Θק«τתהµר»Hiveµץ░µם«µ║נ∩╝לσªגµ₧£σו╢Σ╕¡Σ╕אσן░Workeτפ▒Σ║מloadΘק«Θóר∩╝לµץ░µם«σñהτנזσ╛טµוó∩╝לΘגúΣ╣טµץ┤Σ╕¬µƒÑΦ»óΘד╜Σ╝תσןקσט░σ╜▒σףם∩╝לσ¢áΣ╕║Σ╕ךµ╕╕Θ£אΦªבτ¡יσ╛וΣ╕ךµ╕╕τ╗ףµ₧£πאג
Φ┐שτ»חµצחτ½áσ░▒σוטΣ╗כτ╗םΦ┐שΘחלσנº∩╝לσנמτ╗¡Σ╝תΘשזτ╗¡µ¢┤µצ░Σ╕אτ│╗σטקPrestoτ¢╕σו│τתהµצחτ½á∩╝לµ¼óΦ┐מσו│µ│¿πאג



τ¢╕σו│µמ¿Φםנ
Prestoσñºµץ░µם«µƒÑΦ»óσ╝ץµףמτמ»σóדΦªבµ▒ג∩╝ת Mac OS XµטצLinux Java 8 Update 151µטצµ¢┤Θ½רτיטµ£¼∩╝ט8u151 +∩╝י∩╝ל64Σ╜םπאגµפ»µלבOracle JDKσעלOpenJDKπאג Maven 3.3.9+∩╝טτפ¿Σ║מσ╗║τ¡ס∩╝י Python 2.4+∩╝טτפ¿Σ║מΣ╕מσנ»σך¿Φהתµ£¼Σ╕אΦ╡╖Φ┐נΦíל∩╝י Prestoσñºµץ░µם«µƒÑΦ»ó...
Prestoµר»Σ╕אΣ╕¬Θ½רµאºΦד╜πאבσטזσ╕דσ╝ןSQLµƒÑΦ»óσ╝ץµףמ∩╝לΣ╕ףΣ╕║σñהτנזσñºΦºהµ¿íµץ░µם«ΦאלΦ«╛Φ«íπאגσ«דτפ▒Facebookσ╝אµ║נ∩╝לτמ░σ╖▓µטנΣ╕║ApacheΦ╜»Σ╗╢σƒ║ΘחסΣ╝תτתהΘí╢τ║ºΘí╣τ¢«πאגPrestoτתהΣ╕╗Φªבτ¢«µáחµר»σ«₧τמ░σ┐½ΘאƒµƒÑΦ»óσñºΦºהµ¿íτתהµץ░µם«Σ╗ףσ║ף∩╝לµפ»µלבPBτ║ºτפתΦח│EBτ║ºτתהµץ░µם«Θחןπאגτפ▒Σ║מσו╢...
Java_Trino∩╝לσיםΦ║½Φó½τº░Σ╕║PrestoSQL∩╝לµר»Σ╕אΣ╕¬Θ½רµאºΦד╜πאבσטזσ╕דσ╝ןSQLµƒÑΦ»óσ╝ץµףמ∩╝לΣ╕ףΘק¿Φ«╛Φ«íτפ¿Σ║מσñהτנזσñºΦºהµ¿íµץ░µם«Θ¢זπאגΦ┐שΣ╕¬σ╝אµ║נΘí╣τ¢«τפ▒FacebookσןסΦ╡╖∩╝לσ╣╢σ£¿2019σ╣┤Φ╜¼Σ╕║Trinoσƒ║ΘחסΣ╝תτ«íτנז∩╝לΣ╗ѵפ»µלבσו╢τכ¼τ½כσןסσ▒ץπאגJava_Trinoτתהµá╕σ┐דτ¢«µáחµר»µןנΣ╛¢...
Σ╕║µג¿µןנΣ╛¢Presto σטזσ╕דσ╝ןSQLµƒÑΦ»óσ╝ץµףמΣ╕כΦ╜╜∩╝לPrestoµר»Σ╕אΣ╕¬Θעטσ»╣σñºµץ░µם«τתהσטזσ╕דσ╝ןSQLµƒÑΦ»óσ╝ץµףמ∩╝לτ¼¼Σ╕אµ¼íµ₧הσ╗║Prestoσנמ∩╝לΣ╜áσן»Σ╗Ñσ░זΘí╣τ¢«σךáΦ╜╜σט░Σ╜áτתהIDEΣ╕¡σ╣╢Φ┐נΦíלµ£םσךíσש¿∩╝לµטסΣ╗¼σ╗║Φ««Σ╜┐τפ¿IntelliJ IDEA∩╝לσ¢áΣ╕║Prestoµר»Σ╕אΣ╕¬µáחσחזτתהMavenΘí╣τ¢«...
PrestoDB µר» Facebook µמ¿σח║τתהΣ╕אΣ╕¬σñºµץ░µם«τתהσטזσ╕דσ╝ן SQL µƒÑΦ»óσ╝ץµףמπאגσן»σ»╣Σ╗מµץ░ G σט░µץ░ P τתהσñºµץ░µם«Φ┐¢ΦíלΣ║ñΣ║עσ╝ןτתהµƒÑΦ»ó∩╝לµƒÑΦ»óτתהΘאƒσ║ªΦ╛╛σט░σץזΣ╕תµץ░µם«Σ╗ףσ║ףτתהτ║ºσט½πאג Presto σן»Σ╗ѵƒÑΦ»óσלוµכ¼ HiveπאבCassandra τפתΦח│µר»Σ╕אΣ║¢σץזΣ╕תτתהµץ░µם«σ¡רσג¿...
Prestoµר»Σ╕אΣ╕¬Θ½רµאºΦד╜πאבσטזσ╕דσ╝ןSQLµƒÑΦ»óσ╝ץµףמ∩╝לΣ╕ףΣ╕║σñºΦºהµ¿íµץ░µם«Θ¢זτתהΣ║ñΣ║עσ╝ןσטזµ₧נΦאלΦ«╛Φ«íπאגσ«דτתהΦ«╛Φ«íτנזσ┐╡µר»Σ╕║Σ║זσñהτנזPBτ║ºσט½τתהµץ░µם«∩╝לσנלµק╢Σ┐¥µלבΣ╜מσ╗╢Φ┐ƒτתהµƒÑΦ»óµאºΦד╜∩╝לΣ╜┐σ╛קσטזµ₧נσ╕טπאבµץ░µם«τºסσ¡ªσ«╢Σ╗ÑσןךΣ╕תσךíτפ¿µט╖σן»Σ╗Ñσ┐½ΘאƒΦמ╖σןצµיאΘ£אΣ┐íµב»πאגPresto...
µ£¼Φ╡הµ║נµר»σƒ║Σ║מPrestoσ«רτ╜ס0.229τיטµ£¼µי⌐σ▒ץΣ║זOracle ConnectorσךƒΦד╜τ╝צΦ»סΦאלµ¥ÑτתהΘד¿τ╜▓σלוπאג µ£םσךíτ½»σנ»σך¿σס╜Σ╗ñ Θ¥₧σנמσן░Φ┐נΦíלµ¿íσ╝ן cd presto-server-0.229 ./presto-run.sh σנמσן░Φ┐נΦíלµ¿íσ╝ן cd presto-server-0.229 ./presto-...
Σ╕║Σ║זσוכµ£םΦ┐שΣ║¢µלסµטר∩╝לσטזσ╕דσ╝ןSQLσ╝ץµףמσªגApache HiveπאבPrestoσעלApache CalciteΦó½σ╝אσןסσח║µ¥Ñ∩╝לσ«דΣ╗¼µןנΣ╛¢Σ║זΣ╕אτºםσ░זΣ╝áτ╗ƒSQLΦ»¡σןÑΦ╜¼µםóΣ╕║Θאגσנטσטזσ╕דσ╝ןτמ»σóדµיºΦíלτתהµ£║σט╢πאגΦ┐שΣ║¢σ╝ץµףמΘאתσ╕╕µ£יΦח¬σ╖▒τתהσודµץ░µם«σ¡רσג¿∩╝לτפ¿Σ║מτ«íτנזµץ░µם«τתהσטזσ╕דσעלσטזσל║∩╝ל...
Trinoµר»τפ¿Σ║מσñºµץ░µם«σטזµ₧נτתהσ┐½Θאƒσטזσ╕דσ╝ןSQLµƒÑΦ»óσ╝ץµףמπאג µ£יσו│Θד¿τ╜▓Φ»┤µרמσעלµ£אτ╗טτפ¿µט╖µצחµíú∩╝לΦ»╖σןגΦºבπאךπאכπאג σןסσ▒ץσמזτ¿כ µ£יσו│Σ╗úτáבµá╖σ╝ן∩╝לσ╝אσןסΦ┐חτ¿כσעלσחזσטשτתהΣ┐íµב»∩╝לΦ»╖σןגΦºבΓא£Γא¥πאג Φ»╖σןגΘרוτתהΦ┤íτל«πאג σ╗║ΘאáΦªבµ▒ג Mac OS XµטצLinux Java 11.0.7...
Prestoµר»Σ╕אµ¼╛Θ½רµאºΦד╜τתהσ╝אµ║נσטזσ╕דσ╝ןSQLµƒÑΦ»óσ╝ץµףמ∩╝לΘאגτפ¿Σ║מσ»╣σñºΦºהµ¿íµץ░µם«Θ¢זΦ┐¢Φíלσ┐½Θאƒσטזµ₧נπאגσ«דµפ»µלבσñתτºםµץ░µם«µ║נ∩╝לσªגHiveπאבCassandraπאבPostgreSQLπאבKafkaπאבMySQLπאבElasticSearchτ¡י∩╝לΦד╜σñƒσ£¿Σ╕אΣ╕¬µƒÑΦ»óΣ╕¡σנלµק╢µףםΣ╜£µ¥ÑΦח¬Σ╕םσנלµץ░µם«µ║נτתה...
Presto is a distributed SQL query engine for big data. See the for deployment instructions and end user documentation. Requirements Mac OS X or Linux Java 8 Update 151 or higher (8u151+), 64-bit. Both...
SQLµƒÑΦ»óσ╝ץµףמ∩╝לσן»σ»╣Σ╗מµץ░Gσט░µץ░Pτתהσñºµץ░µם«Φ┐¢ΦíלΣ║ñΣ║עσ╝ןτתהµƒÑΦ»ó∩╝לµƒÑΦ»óτתהΘאƒσ║ªΦ╛╛σט░σץזΣ╕תµץ░µם«Σ╗ףσ║ףτתהτ║ºσט½∩╝לµם«τº░Φ»Ñσ╝ץµףמτתהµאºΦד╜µר» Hiveτתה10σאםΣ╗ÑΣ╕ךπאגPrestoσן»Σ╗ѵƒÑΦ»óσלוµכ¼HiveπאבCassandraτפתΦח│µר»Σ╕אΣ║¢σץזΣ╕תτתהµץ░µם«σ¡רσג¿Σ║ºσףב∩╝לσםץΣ╕¬ PrestoµƒÑΦ»ó...
Prestoµר»Σ╕אΣ╕¬Θ½רµאºΦד╜πאבσטזσ╕דσ╝ןπאבSQLµƒÑΦ»óσ╝ץµףמ∩╝לΦ«╛Φ«íτפ¿Σ║מσñהτנזσñºΦºהµ¿íµץ░µם«Θ¢ז∩╝לσ░ñσו╢ΘאגσנטΣ║מΣ║ñΣ║עσ╝ןσטזµ₧נπאגσו╢µá╕σ┐דτי╣µאºσלוµכ¼Σ╜מσ╗╢Φ┐ƒµƒÑΦ»óπאבµפ»µלבσñתτºםµץ░µם«µ║נΣ╗Ñσןךσ»╣Javaτתהµ╖▒σ║ªΘ¢זµטנπאג 1. **Presto SQLτ«אΣ╗כ** Presto SQLµר»PrestoΘí╣τ¢«τתה...
Prestoµר»Σ╕אΣ╕¬Θ½רµאºΦד╜πאבσטזσ╕דσ╝ןSQLµƒÑΦ»óσ╝ץµףמ∩╝לΦ«╛Φ«íτפ¿Σ║מσñהτנזPBτ║ºσט½τתהµץ░µם«πאגσ«דµפ»µלבσ«₧µק╢σטזµ₧נ∩╝לΘאגτפ¿Σ║מσñºΦºהµ¿íµץ░µם«Σ╗ףσ║ףπאגPrestoµר»τפ▒Facebookσ╝אµ║נτתה∩╝לτמ░σ£¿τפ▒Presto Software Foundationτ╗┤µךñπאגYanagishimaσטשµר»Σ╕אΣ╕¬WebτץלΘ¥ó∩╝לΣ╕ףΣ╕║...
RPresto, σƒ║Σ║מDBIτתהτ╗ƒΦ«íτ╝צτ¿כΦ»¡Φ¿א RτתהΘאגΘוםσש¿ RPrestoRPrestoµר»τפ¿Σ║מσ╝אµ║נσטזσ╕דσ╝ןSQLµƒÑΦ»óσ╝ץµףמPrestoτתהDBI -basedΘאגΘוםσש¿∩╝לτפ¿Σ║מΦ┐נΦíלΣ║ñΣ║עσ╝ןΦºúµ₧נµƒÑΦ»óπאגσ«יΦúוRPrestoΘד╜在 CRAN σעל githubΣ╕ךπאג σ»╣Σ║מCRANτיטµ£¼∩╝לΣ╜áσן»Σ╗ÑΣ╜┐τפ¿install.p
σ£¿ITΦíלΣ╕תΣ╕¡∩╝לPrestoµר»Σ╕אΣ╕¬σטזσ╕דσ╝ןSQLµƒÑΦ»óσ╝ץµףמ∩╝לΦ«╛Φ«íτפ¿Σ║מσ┐½ΘאƒσñהτנזσñºΦºהµ¿íτתהµץ░µם«πאגσ«דµפ»µלבσñתτºםµץ░µם«µ║נ∩╝לσלוµכ¼Hadoop Distributed File System (HDFS)πאבAmazon S3πאבCassandraΣ╗ÑσןךµטסΣ╗¼Φ┐שΘחלσו│µ│¿τתהPostgreSQLπאגµ£¼τ»חµצחτ½áσ░זΦ»ªτ╗ז...
TiDBµר»Σ╕אΣ╕¬σ╝אµ║נτתהσטזσ╕דσ╝ןSQLµץ░µם«σ║ף∩╝לτפ▒PingCAPσו¼σן╕σ╝אσןס∩╝לσ╣╢Σ╕פσ£¿µצחµíúΣ╕¡Σ╗כτ╗םΣ║זTiDBσªגΣ╜ץσ£¿HBaseΣ╣כΣ╕ךµןנΣ╛¢σטזσ╕דσ╝ןSQLτתהµפ»µלבπאגTiDBµפ»µלבσטזσ╕דσ╝ןΣ║כσךíτתהΣ╕אΦח┤µאº∩╝לσו╝σ«╣MySQLσםןΦ««∩╝לσובΦ«╕σ║פτפ¿τ¿כσ║ןσחáΣ╣מΣ╕םΘ£אΦªבΣ╗úτáבΣ┐«µפ╣τתהµדוσז╡Σ╕כµ¢┐µםóMySQL...
Presto µר»Σ╕אτºםτפ▒ Facebook σ╝אσןסτתהσ╝אµ║נπאבσטזσ╕דσ╝ןSQLµƒÑΦ»óσ╝ץµףמ∩╝לΣ╕ףΣ╕║σ£¿τ║┐σטזµ₧נσñהτנז∩╝טOLAP∩╝יΦ«╛Φ«í∩╝לΘאגτפ¿Σ║מσñהτנזPBτ║ºσט½τתהσñºΦºהµ¿íµץ░µם«πאגσו╢Φ«╛Φ«íτ¢«µáחµר»σ«₧τמ░Σ╜מσ╗╢Φ┐ƒπאבΘ½רσ╣╢σןסτתהµƒÑΦ»óµאºΦד╜∩╝לσנלµק╢µפ»µלבΦ╖¿σñתΣ╕¬µץ░µם«µ║נτתהτ║ºΦבפµƒÑΦ»ó∩╝לµןנΣ╛¢σזוσ¡ר...