
ńŞÇŃÇüGangliaš«Çń╗ő
Ganglia Šś» UC Berkeley ňĆĹŔÁĚšÜäńŞÇńެň╝ÇŠ║ÉšŤĹŔžćÚí╣šŤ«´╝îŔ«żŔ«íšöĘń║ÄŠÁőÚçĆŠĽ░ń╗ąňŹâŔ«íšÜäŔŐéšé╣ŃÇ銻ĆňĆ░Ŕ«íš«ŚŠť║ÚâŻŔ┐ÉŔíîńŞÇńެŠöÂÚŤćňĺîňĆĹÚÇüň║ŽÚçĆŠĽ░ŠŹ«´╝łňŽéňĄäšÉćňÖĘÚÇčň║ŽŃÇüňćůňşśńŻ┐šöĘÚçĆšşë´╝ëšÜäňÉŹńŞ║ gmond šÜäň«łŠŐĄŔ┐ŤšĘőŃÇéň«âň░ćń╗ÄŠôŹńŻťš│╗š╗čňĺîŠîçň«ÜńŞ╗Šť║ńŞşŠöÂÚŤćŃÇéŠÄąŠöŠëÇŠťëň║ŽÚçĆŠĽ░ŠŹ«šÜäńŞ╗Šť║ňĆ»ń╗ąŠśżšĄ║Ŕ┐Öń║ŤŠĽ░ŠŹ«ň╣ÂńŞöňĆ»ń╗ąň░ćŔ┐Öń║ŤŠĽ░ŠŹ«šÜäš▓żš«ÇŔíĘňŹĽń╝áÚÇĺňł░ň▒éŠČíš╗ôŠ×äńŞşŃÇ銺úňŤáńŞ║ŠťëŔ┐ÖšžŹň▒éŠČíš╗ôŠ×äŠĘíň╝Ć´╝îŠëŹńŻ┐ňżŚ Ganglia ňĆ»ń╗ąň«×šÄ░Ŕë»ňąŻšÜäŠëęň▒ĽŃÇégmond ňŞŽŠŁąšÜäš│╗š╗čŔ┤čŔŻŻÚŁ×ňŞŞň░Ĺ´╝îŔ┐ÖńŻ┐ňżŚň«âŠłÉńŞ║ňťĘÚŤćšżĄńŞşňÉäňĆ░Ŕ«íš«ŚŠť║ńŞŐŔ┐ÉŔíîšÜäńŞÇŠ«Áń╗úšáü´╝îŔÇîńŞŹń╝ÜňŻ▒ňôŹšöĘŠłĚŠÇžŔâŻ
1.1 Gangliaš╗äń╗Â
Ganglia šŤĹŠÄžňąŚń╗ÂňîůŠőČńŞëńެńŞ╗ŔŽüÚâĘňłć´╝Ügmond´╝îgmetad´╝îňĺĹÚíÁŠÄąňĆú´╝îÚÇÜňŞŞŔóźšž░ńŞ║ganglia-webŃÇé
Gmond :Šś»ńŞÇńެň«łŠŐĄŔ┐ŤšĘő´╝îń╗ľŔ┐ÉŔíîňťĘŠ»ĆńŞÇńŞ¬ÚťÇŔŽüšŤĹŠÁőšÜäŔŐéšé╣ńŞŐ´╝îŠöÂڍ暍ŊÁőš╗čŔ«í´╝îňĆĹÚÇüňĺîŠÄąňĆŚňťĘňÉîńŞÇńެš╗äŠĺşŠłľňŹĽŠĺşÚÇÜÚüôńŞŐšÜäš╗čŔ«íń┐íŠü» ňŽéŠ×ťń╗ľŠś»ńŞÇńެňĆĹÚÇüŔÇů(mute=no)ń╗ľń╝ÜŠöÂÚŤćňč║ŠťČŠîçŠáç´╝öňŽéš│╗š╗čŔ┤čŔŻŻ´╝łload_one´╝ë,CPUňłęšöĘšÄçŃÇéń╗ľňÉÂń╣čń╝ÜňĆĹÚÇüšöĘŠłĚÚÇÜŔ┐çŠĚ╗ňŐáC/PythonŠĘíňŁŚŠŁąŔç¬ň«Üń╣ëšÜäŠîçŠáçŃÇé ňŽéŠ×ťń╗ľŠś»ńŞÇńެŠÄąŠöÂŔÇů´╝łdeaf=no´╝ëń╗ľń╝ÜŔüÜňÉłŠëÇŠťëń╗ÄňłźšÜäńŞ╗Šť║ńŞŐňĆĹŠŁąšÜäŠîçŠáç´╝îň╣ŠŐŐň«âń╗ČÚâŻń┐ŁňşśňťĘňćůňşśš╝ôňć▓ňî║ńŞşŃÇé
Gmetad:ń╣芜»ńŞÇńެň«łŠŐĄŔ┐ŤšĘő´╝îń╗ľň«ÜŠťčŠúÇŠčągmonds´╝îń╗ÄÚéúÚçîŠőëňĆľŠĽ░ŠŹ«´╝îň╣Âň░ćń╗ľń╗ČšÜäŠîçŠáçňşśňéĘňťĘRRDňşśňéĘň╝ĽŠôÄńŞşŃÇéń╗ľňĆ»ń╗ąŠčąŔ»óňĄÜńŞ¬ÚŤćšżĄň╣ÂŔüÜňÉłŠîçŠáçŃÇéń╗ľń╣čŔóźšöĘń║Äšö芳ɚöĘŠłĚšĽîÚŁóšÜäwebň돚ź»ŃÇé
Ganglia-web :ÚíżňÉŹŠÇŁń╣ë´╝îń╗ľň║öŔ»ąň«ëŔúůňťĘŠťëgmetadŔ┐ÉŔíîšÜ䊝║ňÖĘńŞŐ´╝îń╗ąńż┐Ŕ»╗ňĆľRRDŠľçń╗ÂŃÇé ÚŤćšżĄŠś»ńŞ╗Šť║ňĺîň║ŽÚçĆŠĽ░ŠŹ«šÜäÚÇ╗ŔżĹňłćš╗ä´╝öňŽéŠĽ░ŠŹ«ň║ôŠťŹňŐíňÖĘ´╝ĹÚíÁŠťŹňŐíňÖĘ´╝îšöčń║ž´╝îŠÁőŔ»Ľ´╝îQAšşë´╝îń╗ľń╗ČÚ⯊ś»ň«îňůĘňłćň╝ÇšÜä´╝îńŻáÚťÇŔŽüńŞ║Š»ĆńŞ¬ÚŤćšżĄŔ┐ÉŔíîňŹĽšőČšÜägmondň«×ńżőŃÇé
ńŞÇŔłČŠŁąŔ»┤Š»ĆńŞ¬ÚŤćšżĄÚťÇŔŽüńŞÇńެŠÄąŠöšÜägmond´╝ĆńެšŻĹšźÖÚťÇŔŽüńŞÇńެgmetadŃÇé
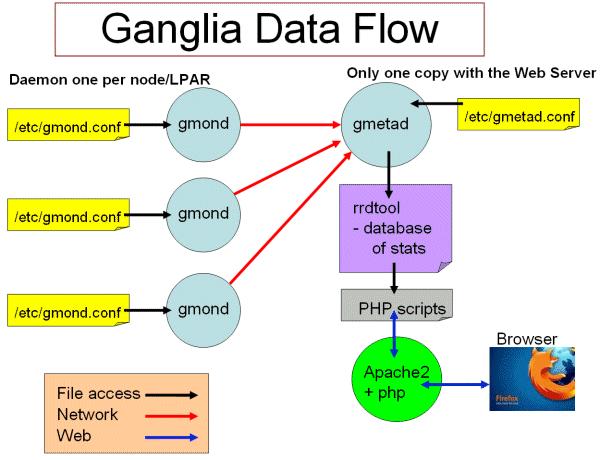 ŃÇÇ
ŃÇÇ
ňŤż1 gangliaňĚąńŻťŠÁü
GangliaňĚąńŻťŠÁüňŽéňŤż1ŠëÇšĄ║´╝Ü
ňĚŽŔż╣Šś»Ŕ┐ÉŔíîňťĘňÉäńެŔŐéšé╣ńŞŐšÜägmondŔ┐ŤšĘő´╝îŔ┐ÖńެŔ┐ŤšĘőšÜäÚůŹšŻ«ňƬšö▒ŔŐéšé╣ńŞŐ/etc/gmond.confšÜ䊾çń╗Âňć│ň«ÜŃÇéŠëÇń╗ą´╝îňťĘňÉäńެšŤĹŔžćŔŐéšé╣ńŞŐÚâŻÚťÇŔŽüň«ëŔúůňĺîÚůŹšŻ«Ŕ»ąŠľçń╗ÂŃÇé
ňĆ│ńŞŐŔžĺŠś»ŠŤ┤ňŐáŔ┤čŔ┤úšÜäńŞşň┐⊝║´╝łÚÇÜňŞŞŠś»Ŕ┐ÖńŞ¬ÚŤćšżĄńŞşšÜäńŞÇňĆ░´╝îń╣čňĆ»ń╗ąńŞŹŠś»´╝ëŃÇéňťĘŔ┐ÖńެňĆ░Šť║ňÖĘńŞŐŔ┐ÉŔíîŔ┐ÖšŁÇgmetadŔ┐ŤšĘő´╝îŠöÂڍ抣ąŔç¬ňÉäńެŔŐéšé╣ńŞŐšÜäń┐íŠü»ň╣ÂňşśňéĘňťĘRRDtoolńŞŐ´╝îŔ»ąŔ┐ŤšĘőšÜäÚůŹšŻ«ňƬšö▒/etc/gmetad.confňć│ň«ÜŃÇé ŃÇÇŃÇÇ
ňĆ│ńŞőŔžĺŠśżšĄ║ń║ćňů│ń║ÄšŻĹÚíÁŠľ╣ÚŁóšÜäńŞÇń║Ťń┐íŠü»ŃÇ銳Ĺń╗ČšÜäŠÁĆŔžłšŻĹšźÖŠŚÂŔ░âšöĘphpŔäÜŠťČ´╝îń╗ÄRRDToolŠĽ░ŠŹ«ň║ôńŞşŠŐôňĆľń┐íŠü»´╝îňŐĘŠÇüšÜäšö芳ÉňÉäš▒╗ňŤżŔíĘŃÇé
1.2 GangliaŔ┐ÉŔíîŠĘíň╝Ć´╝łňŹĽŠĺşńŞÄňĄÜŠĺş´╝ëŃÇÇŃÇÇ
GangliašÜäŠöÂڍ押░ŠŹ«ňĚąńŻťňĆ»ń╗ąňĚąńŻťňťĘňŹĽŠĺş´╝łunicast)ŠłľňĄÜŠĺş(multicast)ŠĘíň╝ĆńŞő´╝îÚ╗śŔ«ĄńŞ║ňĄÜŠĺşŠĘíň╝ĆŃÇé
ňŹĽŠĺş´╝ÜňĆĹÚÇüŔç¬ňĚ▒ŠöÂÚŤćňł░šÜ䚍ŊĞŠĽ░ŠŹ«ňł░šë╣ň«ÜšÜäńŞÇňĆ░ŠłľňçáňĆ░Šť║ňÖĘńŞŐ´╝îňĆ»ń╗ąŔĚĘšŻĹŠ«ÁŃÇé
ňĄÜŠĺş´╝ÜňĆĹÚÇüŔç¬ňĚ▒ŠöÂÚŤćňł░šÜ䚍ŊĞŠĽ░ŠŹ«ňł░ňÉîńŞÇšŻĹŠ«ÁňćůŠëÇŠťëšÜ䊝║ňÖĘńŞŐ´╝îňÉŠöÂÚŤćňÉîńŞÇšŻĹŠ«ÁňćůšÜäŠëÇŠťëŠť║ňÖĘňĆĹÚÇüŔ┐犣ąšÜ䚍ŊĞŠĽ░ŠŹ«ŃÇéňŤáńŞ║Šś»ń╗ąň╣┐ŠĺşňîůšÜäňŻóň╝ĆňĆĹÚÇü´╝îňŤáŠşĄÚťÇŔŽüňÉîńŞÇšŻĹŠ«ÁňćůŃÇéńŻćňÉîńŞÇšŻĹŠ«Áňćů´╝îňĆłňĆ»ń╗ąň«Üń╣ëńŞŹňÉîšÜäňĆĹÚÇüÚÇÜÚüôŃÇé
 
ń║îŃÇüň«ëŔúůganglia
1ŃÇüŠőôŠëĹŔ»┤ŠśÄ
3ňĆ░ńŞ╗Šť║´╝îňłćňłźńŞ║´╝Ü
- 10.171.29.191 master  
- 10.171.94.155  slave1  
- 10.251.0.197 slave3  
ňůÂńŞşmasterň░ćgmetaňĆŐweb´╝îńŞëňĆ░Šť║ÚâŻńŻťgmon
ń╗ąńŞőŠşąÚ¬ĄňŁçńŻ┐šöĘrootšöĘŠłĚŠëžŔíî
2ŃÇümasterńŞŐň«ëŔúůgmetaňĆŐweb
- yum install ganglia-web.x86_64  
- yum install ganglia-gmetad.x86_64  
3ŃÇüňťĘńŞëňĆ░Šť║ńŞŐÚâŻň«ëŠŐÜgmond
- yum install ganglia-gmond.x86_64  
4ŃÇüňťĘńŞëňĆ░Šť║ňÖĘńŞŐÚůŹšŻ«/etc/ganglia/gmond.conf´╝îń┐«Šö╣ń╗ąńŞőňćůň«╣´╝Ü
- udp_send_channel {  
-   #bind_hostname = yes # Highly recommended, soon to be default.  
-                        # This option tells gmond to use a source address  
-                        # that resolves to the machine's hostname.  Without  
-                        # this, the metrics may appear to come from any  
-                        # interface and the DNS names associated with  
-                        # those IPs will be used to create the RRDs.  
-   mcast_join = 10.171.29.191  
-   port = 8649  
-   ttl = 1  
- }  
- /* You can specify as many udp_recv_channels as you like as well. */  
- udp_recv_channel {  
-   #mcast_join = 239.2.11.71  
-   port = 8649  
-   #bind = 239.2.11.71  
- }  
ňŹ│ň░ćÚ╗śŔ«ĄšÜäňĄÜŠĺşňť░ňŁÇŠö╣ńŞ║masterňť░ňŁÇ´╝îň░ćudp_recv_channel šÜä2ńެIPŠ│ĘÚçŐŠÄëŃÇé
5ŃÇüňťĘmasterńŞŐń┐«Šö╣/etc/ganglia/gmetad.conf
ń┐«Šö╣data_source´╝îŠö╣ŠłÉ´╝Ü
- data_source┬á"my┬áclusterÔÇŁ┬á10.171.29.191┬á┬á
6ŃÇüln -s /usr/share/ganglia /var/www/ganglia
ŔőąŠťëÚŚ«Úóś´╝îňĆ»ń╗ąň░ć/usr/share/gangliašÜäňćůň«╣šŤ┤ŠÄąňĄŹňłÂňł░/var/www/ganglia
7ŃÇüń┐«Šö╣/etc/httpd/conf.d/ganglia.conf´╝îŠö╣ŠłÉ´╝Ü
- #  
-   # Ganglia monitoring system php web frontend  
-   #  
-    
-   Alias /ganglia /usr/share/ganglia  
-   
-   <Location /ganglia>  
-     Order deny,allow  
-     Allow from all  
-     Allow from 127.0.0.1  
-     Allow from ::1  
-     # Allow from .example.com  
-   </Location>  
ňŹ│ň░ć┬á┬á┬á Deny from all Šö╣ńŞ║┬á┬á┬á Allow from all´╝îňÉŽňłÖňťĘÚíÁÚŁóŔ«┐ÚŚ«ŠŚÂŠťëŠŁâÚÖÉÚŚ«ÚóśŃÇé
8ŃÇüňÉ»ňŐĘ
- service gmetad start  
- service gmond start  
- /usr/sbin/apachectl start  
9ŃÇüń╗ÄÚíÁÚŁóńŞŐŔ«┐ÚŚ«
http://ip/ganglia
ńŞÇń║ŤŠ│ĘŠäĆÚŚ«Úóś´╝Ü
1ŃÇügmetadŠöÂÚŤćňł░šÜäń┐íŠü»ŔóźŠöżňł░/var/lib/ganglia/rrds/
2ŃÇüňĆ»ń╗ąÚÇÜŔ┐çń╗ąńŞőňĹŻń╗ĄŠúNJ蹊ś»ňÉŽŠťëŠĽ░ŠŹ«ňťĘń╝áŔżô
- tcpdump port 8649  
ńŞëŃÇüÚůŹšŻ«hadoopńŞÄhbase
1ŃÇüÚůŹšŻ«hadoop
hadoop-metrics2.properties
 
- # syntax: [prefix].[source|sink|jmx].[instance].[options]  
- # See package.html for org.apache.hadoop.metrics2 for details  
-   
- *.sink.file.class=org.apache.hadoop.metrics2.sink.FileSink  
-   
- #namenode.sink.file.filename=namenode-metrics.out  
-   
- #datanode.sink.file.filename=datanode-metrics.out  
-   
- #jobtracker.sink.file.filename=jobtracker-metrics.out  
-   
- #tasktracker.sink.file.filename=tasktracker-metrics.out  
-   
- #maptask.sink.file.filename=maptask-metrics.out  
-   
- #reducetask.sink.file.filename=reducetask-metrics.out  
- # Below are for sending metrics to Ganglia  
- #  
- # for Ganglia 3.0 support  
- # *.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink30  
- #  
- # for Ganglia 3.1 support  
- *.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31  
-   
- *.sink.ganglia.period=10  
-   
- # default for supportsparse is false  
- *.sink.ganglia.supportsparse=true  
-   
- *.sink.ganglia.slope=jvm.metrics.gcCount=zero,jvm.metrics.memHeapUsedM=both  
- *.sink.ganglia.dmax=jvm.metrics.threadsBlocked=70,jvm.metrics.memHeapUsedM=40  
- menode.sink.ganglia.servers=10.171.29.191:8649  
-   
- datanode.sink.ganglia.servers=10.171.29.191:8649  
-   
- jobtracker.sink.ganglia.servers=10.171.29.191:8649  
- tasktracker.sink.ganglia.servers=10.171.29.191:8649  
-   
- maptask.sink.ganglia.servers=10.171.29.191:8649  
-   
- reducetask.sink.ganglia.servers=10.171.29.191:8649  
 
 
2ŃÇüÚůŹšŻ«hbase
hadoop-metrics.properties
 
- # See http://wiki.apache.org/hadoop/GangliaMetrics  
- # Make sure you know whether you are using ganglia 3.0 or 3.1.  
- # If 3.1, you will have to patch your hadoop instance with HADOOP-4675  
- # And, yes, this file is named hadoop-metrics.properties rather than  
- # hbase-metrics.properties because we're leveraging the hadoop metrics  
- # package and hadoop-metrics.properties is an hardcoded-name, at least  
- # for the moment.  
- #  
- # See also http://hadoop.apache.org/hbase/docs/current/metrics.html  
- # GMETADHOST_IP is the hostname (or) IP address of the server on which the ganglia   
- # meta daemon (gmetad) service is running  
-   
- # Configuration of the "hbase" context for NullContextWithUpdateThread  
- # NullContextWithUpdateThread is a  null context which has a thread calling  
- # periodically when monitoring is started. This keeps the data sampled  
- # correctly.  
- hbase.class=org.apache.hadoop.metrics.spi.NullContextWithUpdateThread  
- hbase.period=10  
-   
- # Configuration of the "hbase" context for file  
- # hbase.class=org.apache.hadoop.hbase.metrics.file.TimeStampingFileContext  
- # hbase.fileName=/tmp/metrics_hbase.log  
-   
- # HBase-specific configuration to reset long-running stats (e.g. compactions)  
- # If this variable is left out, then the default is no expiration.  
- hbase.extendedperiod = 3600  
-   
- # Configuration of the "hbase" context for ganglia  
- # Pick one: Ganglia 3.0 (former) or Ganglia 3.1 (latter)  
- # hbase.class=org.apache.hadoop.metrics.ganglia.GangliaContext  
- hbase.class=org.apache.hadoop.metrics.ganglia.GangliaContext31  
- hbase.period=10  
- hbase.servers=10.171.29.191:8649  
-   
- # Configuration of the "jvm" context for null  
- jvm.class=org.apache.hadoop.metrics.spi.NullContextWithUpdateThread  
- jvm.period=10  
-   
- # Configuration of the "jvm" context for file  
- # jvm.class=org.apache.hadoop.hbase.metrics.file.TimeStampingFileContext  
- # jvm.fileName=/tmp/metrics_jvm.log  
-   
- # Configuration of the "jvm" context for ganglia  
- # Pick one: Ganglia 3.0 (former) or Ganglia 3.1 (latter)  
- # jvm.class=org.apache.hadoop.metrics.ganglia.GangliaContext  
- jvm.class=org.apache.hadoop.metrics.ganglia.GangliaContext31  
- jvm.period=10  
- jvm.servers=10.171.29.191:8649  
-   
- # Configuration of the "rpc" context for null  
- rpc.class=org.apache.hadoop.metrics.spi.NullContextWithUpdateThread  
- rpc.period=10  
-   
- # Configuration of the "rpc" context for file  
- # rpc.class=org.apache.hadoop.hbase.metrics.file.TimeStampingFileContext  
- # rpc.fileName=/tmp/metrics_rpc.log  
-   
- # Configuration of the "rpc" context for ganglia  
- # Pick one: Ganglia 3.0 (former) or Ganglia 3.1 (latter)  
- # rpc.class=org.apache.hadoop.metrics.ganglia.GangliaContext  
- rpc.class=org.apache.hadoop.metrics.ganglia.GangliaContext31  
- rpc.period=10  
- rpc.servers=10.171.29.191:8649  
-   
- # Configuration of the "rest" context for ganglia  
- # Pick one: Ganglia 3.0 (former) or Ganglia 3.1 (latter)  
- # rest.class=org.apache.hadoop.metrics.ganglia.GangliaContext  
- rest.class=org.apache.hadoop.metrics.ganglia.GangliaContext31  
- rest.period=10  
- rest.servers=10.171.29.191:8649  
ÚçŹňÉ»hadoopńŞÄhbae
 
ŔŻČŔ笴╝Ühttp://blog.csdn.net/jediael_lu/article/details/44104859
 
 



šŤŞňů│ŠÄĘŔŹÉ
GangliaŃÇüHadoopňĺîHBaseÚ⯊ś»ňĄžŠĽ░ŠŹ«ÚóćňččšÜäÚçŹŔŽüš╗äń╗´╝îŔÇîNagiosňłÖŠś»ńŞÇšžŹň╣┐Š│ŤńŻ┐šöĘšÜäš│╗š╗蚍ŊĞňĚąňůĚŃÇéŔ┐Öš»çňŹÜŠľçÚôżŠÄąŠĆÉńżŤšÜäŔÁäŠ║ÉŔüÜšäŽń║ÄňŽéńŻĽň░ćŔ┐Öń║ŤŠŐÇŠť»š╗ôňÉłńŻ┐šöĘ´╝îň╣ÂŔ┐ŤŔí늼łšÜ䚍ŊĞŃÇé GangliaŠś»ńŞÇńެňłćňŞâň╝ĆšŤĹŠÄžš│╗š╗č´╝îŔâŻňĄčŠöÂÚŤćň╣Â...
ňťĘŔ┐ÖÚçî´╝Ĺń╗Čň░ćŔ«ĘŔ«║ňŽéńŻĽńŻ┐šöĘJavań╗úšáüŠŁąň«×šÄ░HBaseÚŤćšżĄšÜ䚍ŊĞŃÇé šŤĹŠÄžHBaseÚŤćšżĄšÜäÚçŹŔŽüŠÇž´╝Ü ňťĘšöčń║žš│╗š╗čńŞş´╝îŔ┐Éš╗┤ń║║ňĹśÚťÇŔŽüšŤĹŠÄžš│╗š╗čšÜäšŐŠÇüňĺîŔíĘšÄ░´╝îń╗ąńż┐ň┐źÚÇčň«ÜńŻŹÚŚ«ÚóśšÜäŠá╣Š║ÉŃÇéÚÇÜŔ┐皍ŊĞHBaseÚŤćšżĄ´╝îňĆ»ń╗ąň«×ŠŚÂń║ćŔžúš│╗š╗čšÜäŠÇžŔâŻ...
ŃÇÉHadoopńŞÄHBaseÚâĘšŻ▓ŠľçŠíúŃÇĹ ...ň«îŠłÉńŞŐŔ┐░ŠşąÚ¬ĄňÉÄ´╝îńŻáň░▒ŠłÉňŐčňť░ÚâĘšŻ▓ń║ćHadoopňĺîHBaseÚŤćšżĄ´╝îňĆ»ń╗ąň╝ÇňžőŔ┐ŤŔíîňĄžŠĽ░ŠŹ«šÜäňşśňéĘňĺîňĄäšÉćń╗╗ňŐíŃÇéšäÂŔÇî´╝îÚâĘšŻ▓ňƬŠś»šČČńŞÇŠşą´╝îňÉÄŠťčšÜäŔ┐Éš╗┤ňĺîń╝śňîľňÉîŠáĚÚçŹŔŽü´╝îňîůŠőČŠÇžŔ⯚ŤĹŠÄžŃÇüŠĽůÚÜťŠÄĺŠčąňĺîš│╗š╗čňŹçš║žšşëŃÇé
4. **šŤĹŠÄžńŞÄŔ░âń╝ś**´╝ÜńŻ┐šöĘHBaseŔç¬ňŞŽšÜ䚍ŊĞňĚąňůĚŠłľšČČńŞëŠľ╣ňĚąňůĚ´╝łňŽéGangliaŃÇüPrometheus´╝뚍ŊĞš│╗š╗čŠÇžŔ⯴╝îŠá╣ŠŹ«šŤĹŠÄžš╗ôŠ×ťŔ░⊼┤ňĆ銼░ŃÇé 5. **ŠĽ░ŠŹ«ňÄőš╝ę**´╝ÜňÉ»šöĘŠĽ░ŠŹ«ňÄőš╝ęňĆ»ń╗ąňçĆň░ĹňşśňéĘšę║ÚŚ┤´╝îňÉÂÚÖŹńŻÄšŻĹš╗ťń╝áŔżôÚçĆ´╝îŠĆÉÚźśŠÇžŔâŻŃÇéHBase...
HadoopńŞÄHBaseňĆ銼░Ŕ░âń╝śŠś»ňĄžŠĽ░ŠŹ«ňĄäšÉćňĺîňşśňéĘÚóćňččšÜäÚçŹŔŽüňćůň«╣ŃÇéÚÜĆšŁÇŠŐÇŠť»šÜäńŞŹŠľşŠ╝öŔ┐Ť´╝îň»╣...ÚÇÜŔ┐çň»╣ňÉäńެňĆ銼░šÜäš╗ćŔç┤Ŕ░⊼┤ňĺîńŞŹŠľşšÜäň«×Ú¬îÚ¬îŔ»ü´╝îňĆ»ń╗ąńŻ┐ňżŚHadoopňĺîHBaseÚŤćšżĄŔżżňł░ŠťÇń╝śšÜäňĚąńŻťšŐŠÇü´╝îń╗ÄŔÇ늼łňť░Šö»ŠĺĹňĄžŠĽ░ŠŹ«ňĄäšÉćňĺîňłćŠ×ÉňĚąńŻťŃÇé
ŠťÇňÉÄ´╝Ĺń╗ČňĆ»ń╗ąÚÇÜŔ┐皍ŊĞňĚąňůĚ´╝łňŽéAmbariŠłľGanglia´╝ëŔžéň»čHadoopňĺîHBasešÜäŔ┐ÉŔíîšŐŠÇü´╝îń╗ąňĆŐSnappyňÄőš╝ꊼłŠ×ť´╝îń╗ąńż┐Ŕ┐ŤńŞÇŠşąń╝śňǞŔâŻŃÇéňÉ´╝îŠîüš╗şňů│Š│ĘHadoopňĺîHBasešÜ䊾░šëłŠťČňĆĹňŞâ´╝îÚÇ銌ÂŔ┐ŤŔíîňŹçš║žń╗ąŔÄĚňĆľŠťÇŠľ░šÜäňŐčŔâŻňĺîŠÇžŔ⯊ö╣Ŕ┐ŤŃÇé ...
1. **Gmond (Ganglia Monitoring Daemon)**´╝ÜŔ┐ÖŠś»GangliašÜäŔŐéšé╣ń╗úšÉćšĘőň║Ć´╝îň«âŔ┐ÉŔíîňťĘŠ»ĆńŞÇńެŔ󟚍ŊĞšÜäńŞ╗Šť║ńŞŐ´╝îŠöÂÚŤćŔ»ŞňŽéCPUńŻ┐šöĘšÄçŃÇüňćůňşśńŻ┐šöĘŃÇüšúüšŤśI/OŃÇüšŻĹš╗ťŠÁüÚçĆšşëš│╗š╗čŠîçŠáç´╝îň╣Âň░ćŔ┐Öń║ŤŠĽ░ŠŹ«ňĆĹÚÇüňł░GangliaÚŤćšżĄńŞşšÜäňůÂń╗ľŔŐéšé╣Šłľ...
ÚůŹšŻ«HBaseÚŤćšżĄÚťÇŔŽüń┐«Šö╣`hbase-site.xml`´╝îňůÂńŞşňîůňÉźHMasterŃÇüHRegionServeršÜäňť░ňŁÇ´╝îZookeeperŔ┐׊ĹňşŚšČŽńŞ▓´╝îń╗ąňĆŐŠĽ░ŠŹ«ňŁŚňĄžň░ĆšşëŔ«żšŻ«ŃÇé **Spark** Šś»ńŞÇńެň┐źÚÇčŃÇüÚÇÜšöĘšÜäňĄžŠĽ░ŠŹ«ňĄäšÉćň╝ĽŠôÄ´╝îŠö»ŠîüŠë╣ňĄäšÉćŃÇüń║Ąń║ĺň╝ĆŠčąŔ»ó´╝łSpark SQL...
ÚŤćšżĄšŤĹŠÄžňîůŠőČňťĘÚŤćšżĄńŞşšÜäňÉäńެŔŐéšé╣ńŞŐň«ëŔúůňĺîÚůŹšŻ«gmondŃÇüń┐«Šö╣gmondÚůŹšŻ«Šľçń╗Âgmond.confń╗ąÚÇéň║öÚŤćšżĄšÄ»ňóâŃÇüŔ«żšŻ«ganglia-webšÜäŔ«┐ÚŚ«ŠŁâÚÖÉŃÇüÚůŹšŻ«gmetadń╗ąŠşúší«ŔüÜňÉłňĺîňşśňéĘŠĽ░ŠŹ«ŃÇüń╗ąňĆŐň»╣ń║ÄÚŤćšżĄňćůšë╣ň«Üň║öšöĘ´╝łňŽéHadoopňĺîHBase´╝ëšÜäÚůŹšŻ«ŃÇé...
- **HBaseÚŤćšżĄŠŽéŔ┐░**´╝ÜŔ»ąÚŤćšżĄÚççšöĘ0.94.xšëłŠťČ´╝îň╣ÂŔ┐ŤŔíîń║ćŠëęň▒Ľń╝śňîľ´╝îŠőąŠťëŔÂůŔ┐ç300ňĆ░ŠťŹňŐíňÖĘ´╝îňşśňéĘň«╣ÚçĆŔÂůŔ┐ç300TB´╝ĆňĄęšÜ䊼░ŠŹ«ŠŤ┤Šľ░ÚçĆňŹáŠÇ╗ÚçĆšÜä10%ŃÇ隍ŊĞš│╗š╗čÚççšöĘGangliaňĺîJMX´╝îší«ń┐ŁÚŤćšżĄšÜäšĘ│ň«ÜŔ┐ÉŔíîňĺîŠÇžŔ⯚ŤĹŠÄžŃÇé - **HBase...
ńŞşňŤŻšöÁń┐íńŻ┐šöĘ Ganglia ňĺî Zabbix šşëňĚąňůĚŠŁąšŤĹŠÄž HBase ÚŤćšżĄšÜäŠÇžŔâŻňĺîšŐŠÇü´╝îň╣ÂńŻ┐šöĘŔ┐Öń║ŤňĚąňůĚŠŁąń╝śňîľ HBase šÜäŠÇžŔâŻňĺîšĘ│ň«ÜŠÇžŃÇé HBase ňťĘńŞşňŤŻšöÁń┐íšÜäň║öšöĘ HBase ňťĘńŞşňŤŻšöÁń┐íšÜäň║öšöĘňîůŠőČŠĽ░ŠŹ«ňşśňéĘŃÇüŠĽ░ŠŹ«ňĄäšÉćŃÇüň«×ŠŚÂŔ«íš«ŚňĺîňłćŠ×Éšşë...
- **šŤĹŠÄžńŞÄŠŚąň┐Śš«íšÉć**´╝ÜńŻ┐šöĘňĚąňůĚňŽéGangliaŃÇüNagiosšŤĹŠÄžÚŤćšżĄňüąň║ĚšŐÂňćÁ´╝îň«ÜŠťčŠúNJ蹊Śąň┐ŚŠľçń╗Âń╗ąÚóäÚś▓ŠŻťňťĘÚŚ«ÚóśŃÇé - **ŠĽ░ŠŹ«ňĄçń╗ŻńŞÄŠüóňĄŹ**´╝ÜňłÂň«ÜňÉłšÉćšÜ䊼░ŠŹ«ňĄçń╗ŻšşľšĽą´╝îń╗ąńż┐ňťĘňç║šÄ░ŠĽůÚÜťŠŚÂŔâŻňĄčň┐źÚÇčŠüóňĄŹŠťŹňŐíŃÇé #### ń║öŃÇüš╗ôŔ«║ ...
Ŕ»żŠŚÂ6´╝ÜńŻ┐šöĘGangliašŤĹŠÄžHBase Ŕ»żŠŚÂ7´╝ÜŔ┐çŠ╗ĄňÖĘň«×Šłśń╣őŠ»öŔżâŔ┐çŠ╗ĄňÖĘ Ŕ»żŠŚÂ8´╝ÜŔ┐çŠ╗ĄňÖĘň«×Šłśń╣őńŞôšöĘŔ┐çŠ╗ĄňÖĘńŞÄFilterList Ŕ»żŠŚÂ9´╝ÜŔ┐çŠ╗ĄňÖĘň«×Šłśń╣őŔç¬ň«Üń╣ëŔ┐çŠ╗ĄňÖĘ Ŕ»żŠŚÂ10´╝ÜObserverňŹĆňĄäšÉćňÖĘň«×Šłśń╣őMasterš║žňłźňÄčšÉćň뾊×É Ŕ»żŠŚÂ11´╝ÜObserverňŹĆ...
- ň«ëŔúůňĺîÚůŹšŻ«šŤĹŠÄžňĚąňůĚ´╝îňŽéGangliaŠłľAmbari´╝îń╗ąńż┐šŤĹŠÄžÚŤćšżĄšÜäŠÇžŔâŻňĺîňüąň║ĚšŐÂňćÁŃÇé ÚÇÜŔ┐çń╗ąńŞŐŠşąÚ¬Ą´╝îńŞÇńެňč║ŠťČšÜäHadoopň«îňůĘňłćňŞâň╝ĆÚŤćšżĄńż┐ňżŚń╗ąň╗║šźőŃÇéŠ│ĘŠäĆ´╝îň«×ÚÖůÚâĘšŻ▓ňĆ»ŔâŻŔ┐śÚťÇŔŽüŠá╣ŠŹ«šŻĹš╗ťšÄ»ňóâŃÇüšíČń╗ÂŔÁäŠ║Éňĺîň«ëňůĘšşľšĽąŔ┐ŤŔíŞň║öŔ░⊼┤ŃÇé...
- ňÉ»ňŐĘHBaseÚŤćšżĄ´╝îňîůŠőČMasterŃÇüRegionServerňĺîZookeeperŠťŹňŐíŃÇé - ňłŤň╗║HBaseŔíĘň╣ÂňłćÚůŹRegionŃÇé 6. **SpringBootÚůŹšŻ«**´╝Ü ňťĘSpringBootšÜäÚůŹšŻ«Šľçń╗Â`application.properties`Šłľ`application.yml`ńŞş´╝îÚůŹšŻ«HBaseŔ┐׊Ĺ...
ňťĘÚŤćšżĄšŤĹŠÄžÚâĘňłć´╝îń╗őš╗Źń║ćHBaseňŽéńŻĽňłęšöĘGangliaŃÇüJMXŃÇüNagiosšşëňĚąňůĚŔ┐ŤŔíîŠÇžŔ⯚ŤĹŠÄžňĺůÚÜťŠúÇŠÁőŃÇéňÉ´╝îŠĆÉńżŤń║ćŔ┐Éš╗┤ń║║ňĹśŠŚąňŞŞš«íšÉćŠëÇڝǚÜäńŞÇš│╗ňłŚń╗╗ňŐíňłŚŔíĘ´╝îňîůŠőČŠĽ░ŠŹ«ň»╝ňůąň»╝ňç║ŃÇüŠŚąň┐Śš║žňłźŔ░⊼┤ŃÇüÚŚ«ÚóśŠÄĺŠčąšşë´╝îń╗ąší«ń┐ŁHBaseÚŤćšżĄšÜäšĘ│ň«Ü...
3. Ambari´╝ÜňŤżňŻóňîľš«íšÉćňĚąňůĚ´╝îš«ÇňîľHadoopÚŤćšżĄšÜäň«ëŔúůŃÇüÚůŹšŻ«ŃÇüšŤĹŠÄžňĺîš«íšÉćŃÇé ÚÇÜŔ┐çŔ┐Öńެ41ÚíÁšÜäŔ»żšĘő´╝îńŻáň░ćňůĘÚŁóń║ćŔžúHadoopÚŤćšżĄšÜäŠÉşň╗║ŃÇüŔ┐Éš╗┤ń╗ąňĆŐňťĘňĄžŠĽ░ŠŹ«ňłćŠ×ÉńŞşšÜäň║öšöĘŃÇ銌áŔ«║Šś»ňłŁňşŽŔÇůŔ┐śŠś»Šťëš╗ĆÚ¬îšÜäň╝ÇňĆĹŔÇů´╝îÚâŻŔâŻń╗ÄńŞşňĆŚšŤŐ´╝îŠĆÉňŹç...
- **Ganglia**Šłľ**Nagios**´╝ÜšŤĹŠÄžš│╗š╗č´╝ŊĞڍ暿ĄšÜäCPUŃÇüňćůňşśŃÇüšúüšŤśňĺŚ╗ťšşëŔÁäŠ║ÉńŻ┐šöĘŠâůňćÁŃÇé 7. **ň«ëňůĘŠÇžńŞÄŔ«ĄŔ»ü** - **Kerberos**´╝Üň«×šÄ░Ŕ║źń╗ŻÚ¬îŔ»üšÜäň«ëňůĘňŹĆŔ««´╝îšöĘń║ÄHadoopÚŤćšżĄšÜäŔ║źń╗ŻÚ¬îŔ»üŃÇé - **SSLňŐáň»ć**´╝Üń┐ŁŠŐĄŠĽ░ŠŹ«...
Ŕ┐ÖÚâĘňłćňĆ»Ŕ⯊ÂëňĆŐAmbariŃÇüGangliašşëšŤĹŠÄžňĚąňůĚšÜäńŻ┐šöĘŃÇé ÚÇÜŔ┐çŔ┐Öń║ŤPPTšÜäňşŽń╣á´╝îńŻáňĆ»ń╗ąš│╗š╗čŠÇžňť░ŠÄîŠĆíHadoopňĆŐňůšöčŠÇüš│╗š╗č´╝îńŞŹń╗ůšÉćŔžúňůÂňč║ŠťČňÄčšÉć´╝îŔ┐śŔâŻňůĚňĄçň«×ÚÖůŠôŹńŻťňĺîÚí╣šŤ«ň«×ŠľŻŔâŻňŐŤŃÇéŔ┐Öň»╣ń║ÄňťĘňĄžŠĽ░ŠŹ«ÚóćňččňĚąńŻťŠłľŔ┐ŤńŞÇŠşąňşŽń╣áŠĚ▒ÚÇáÚâŻ...