
1 为什么要做日志采集?
日志, 对于不同团队来说会有不同的使用目的:
- 对于数据仓库团队来说, 日志是他们要分析的信息数据来源之一;
- 对于安全团队来说, 日志是他们构建安全防御与漏洞挖掘的一种特征来源和触发信号源;
- 对于应用团队来说, 日志是他们了解自己的系统运行状态与排除错误的一种手段;
- etc.
在服务结点不多的情况下, 各个团队怎么使用这些日志或许可以百花齐放,但在中大规模服务部署的情况下, 日志类别 * 技术方案 * 对接的系统等等这些因素的组合将极大加重系统研发和维护的负担,所以, 我们需要一套分布式环境下集中采集,分析和管理日志的技术体系。
最原始的登录服务器查看日志等操作,对于信息安全要求需要逐步加强的互联网金融企业来讲, 最终一定是要杜绝的,权限收缩并规范化管理我们将逐渐执行落地, 届时, 所有的日志查看,分析等工作将只能通过我们的日志平台进行。
2 挖财自己的日志采集和分析体系应该怎么建?
一套日志的管理体系通常需要处理以下几个阶段的工作:
- 日志的采集
- 日志的汇总与过滤
- 日志的存储
- 日志的分析与查询
ELK技术栈(即Logstash + ElasticSearch + Kibana)属于业界已经应用比较广泛且成熟的开源方案,这套一站式解决方案基本上可以满足大部分企业对日志管理体系的需求,但对于我们挖财来讲, 需要更多的灵活性以处理遗留系统以及现有技术基础设施的复用, 故此, 我们自己的日志管理技术体系我希望是如下的样子:
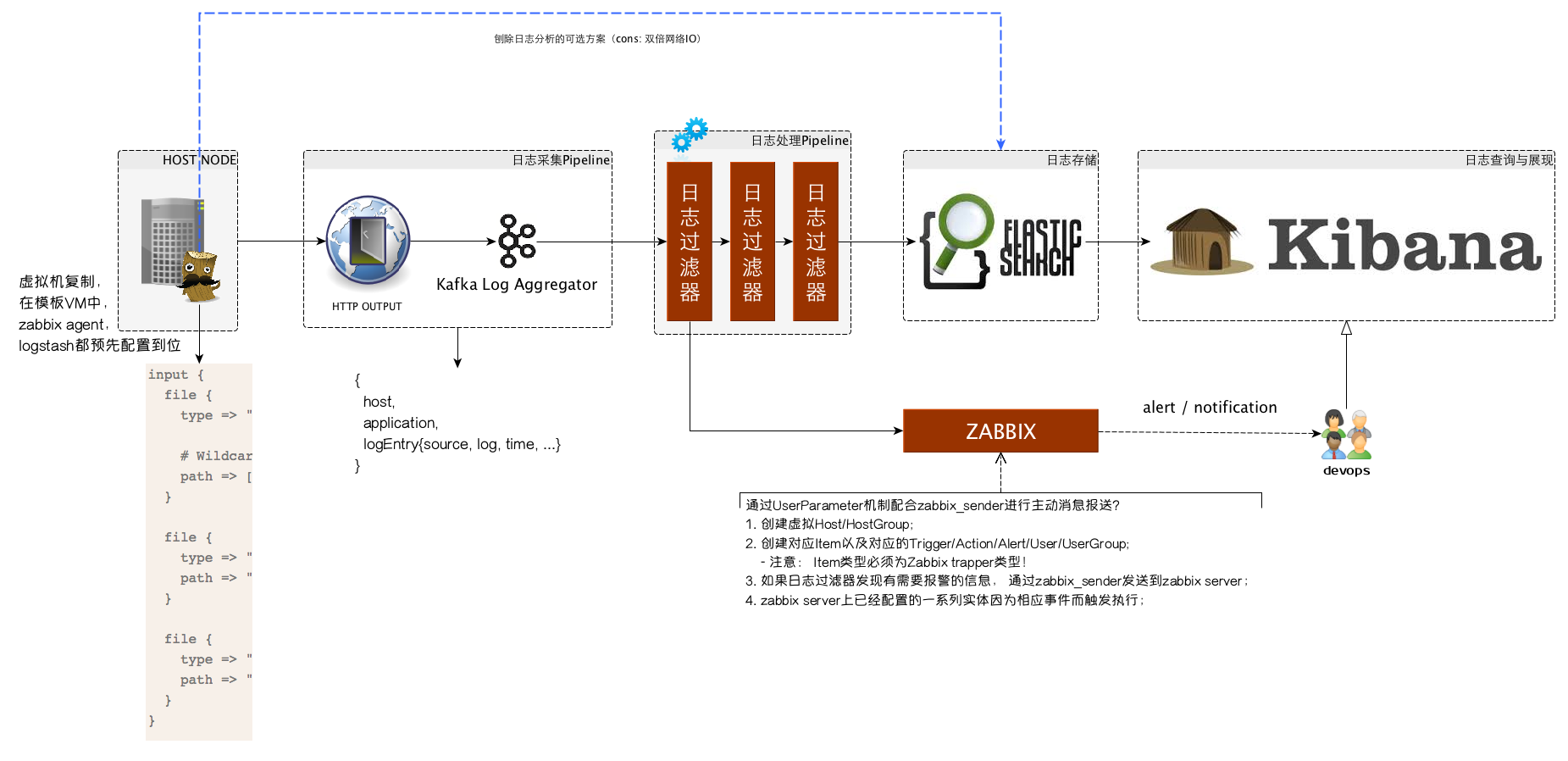
2.1 日志的采集
灵活性是我们选择日志采集方案更看重的因素,所以logstash属于首先方案, 它可以兼顾多种不同系统和应用类型等因素的差异,从源头上进行一些初步的日志预处理。
logstash唯一的小缺憾是它的不轻便, 因为它是使用jruby开发并跑在java虚拟机上的agent, 当然啦,同时也是优点,即各种平台上都可以用。
2.2 日志的汇总与过滤
kafka在我们挖财已经属于核心的中间件服务, 所以, 日志的汇总自然而然会倾向于使用kafka。
日志的过滤和处理因为需求的多样性,可以直接对接订阅kafka, 然后根据各自的需求进行日志的定制处理, 比如过滤和监控应用日志的异常,即使通过zabbix进行预警; 或者数据仓库方面在原始日志的基础上进行清洗和转换,然后加载到新的数据源中;
2.3 日志的存储
原始的日志存储我们采用ElasticSearch, 即ELK技术栈中E的原本用途,遵循ELK技术栈中各个方案之间的通用规范, 比如日志如索引采用logstash与kibana之间约定的index pattern。
日志的衍生数据则日志使用各方根据需求自行选择。
2.4 日志的分析与查询
ELK技术栈中的Kibana已经可以很好的满足这一需求,这里我们不折腾。
3 需要解决哪些技术问题?
因为我们在ELK技术栈的处理链路上插入了一些扩展点,所以,有些问题需要解决和澄清...
3.1 logstash与kafka的对接
ELK技术栈中, Logstash和Elastic Search是通过logstash的elasticsearch或者elasticsearch_http这几个output直接对接的, 为了让logstash转而对接kafka,我们有几种选择:
- logstash-kafka
- logstash-output-kafka
- logstash的
httpoutput
第一种和第二种方案都需要编译打包相应的依赖到logstash,然后随同logstash一起部署到服务结点, 虽然可以work, 但依赖重, 资源消耗多, 通用性不强;
个人更倾向于第三种方案,即使用logstash默认提供的http这个output, 因为http比较通用, 而且本身我们的kafka前面就有为了多系统对接而提供的http proxy方案部署。另外,依赖的管理和升级都在服务端维护,对每个服务结点是透明的。 当然, 唯一的弱点是效率可能不如基于长连接的消息传递高,只是暂时不是问题,即使将来成为瓶颈,也可以通过sharding的形式进行扩展。
3.2 kafka到elastic search的数据链路对接
kafka和es之间我们要加入一套日志过滤与处理系统, 这套系统是我们发挥整个体系最大威力的地方。 在整个系统的处理pipeline中,我们可以根据需求添加任意需要的Filter/Processor, 比如服务于应用报警的Filter/Processor,服务于数据仓库ETL的Filter/Processor等等。 但不管前面做了多少事情, 日志最终是要接入到ES进行存储的。
因为ELK技术栈中三者的对接遵循一些规范或者说规则, 而我们又需要继续复用这个技术栈中的服务提供的特定功能, 所以,即使是我们在整个处理链路中插入了扩展点,但数据的存储依然需要遵循ELK原来的规范和规则, 以便Kibana可以从ES中捞日志出来分析和展示的时候不需要任何改动。
logstash存入ES的日志,一般遵循如下的index pattern:
logstash-%{+YYYY.MM.dd}
使用日期进行索引(index)界定的好处是, 可以按照日期范围定期进行清理。
NOTE
进一步深入说明一下, 针对不同的日志类别, index pattern也最好分类对应。
更多信息:
Each log line from the input file is associated with a logstash event. Each logstash event has fields associated with it. By default, "message", "@timestamp", "@version", "host", "path" are created. The "message" field, referenced in the conditional statement, contains all the original text of the log line.
日志处理系统可以使用ES的java客户端或者直接通过ES的HTTP服务进行采集到的日志索引操作。
3.2.1 参考
- http://www.rsyslog.com/output-to-elasticsearch-in-logstash-format-kibana-friendly/
- https://sematext.atlassian.net/wiki/display/PUBLOGSENE/Index+Events+via+Elasticsearch+API
- http://stackoverflow.com/questions/27127326/is-logstash-a-mandatory-prefix-of-indices-in-kibana
3.3 日志报警功能与zabbix的集成
我们的监控平台选择了使用zabbix, 所以各个系统如果有监控需求,最好都对接zabbix, 避免维护多套不必要的运维系统。
在应用日志处理过程中, 我们希望可以识别错误或者异常信号, 然后通过zabbix报警和通知相应devops人员, 为了达到这一目的,我们可以复用zabbix中的action/user/usergroup等实体配置, 并且配置相应的虚拟host/item/trigger等实体,然后由日志处理系统在需要的时候,直接通过active的方式上报数据, 具体操作方式为:
- 在日志处理系统中, 通过zabbix_sender或者根据zabbix_sender的通信协议,在合适的时机发送状态数据;
- 在zabbix中, 配置相应的host/item/trigger, item为zabbix trapper类型,key与zabbix_sender发送的key相对应;
- 其它配置根据需要配套即可(找zabbix管理者提需求即可 - @多宝)。
TIPS
zabbix_sender协议参考https://www.zabbix.org/wiki/Docs/protocols/zabbix_sender/2.0
4 补充和小结
虽然我在架构图中从具体的服务器结点通过虚线的形式引入了一条直接到ElasticSearch和Kibana的链路,但并不推荐这种方案, 原因可能是(但不限于):
- 本身我们的日志管理体系中对日志的处理/过滤需求是不可避免的, 所以, 日志的存储入库可以通过一条链路直接完成, 只维护一套规范即可;
- 在每个结点开两个口子, 本身会对网络IO造成双倍压力;
所以, 以上架构规范中所有推荐的做法是综合考虑后最完善的方案。
转自:http://afoo.me/columns/tec/logging-platform-spec.html



相关推荐
《深入理解ELK日志分析系统:以kibana 5.4.2为例》 在信息化时代,日志管理与分析成为企业监控系统运行、排查问题的关键环节。ELK(Elasticsearch、Logstash、Kibana)堆栈正是这样一个强大的日志处理和分析工具。...
《大数据搜索与日志挖掘及可视化方案——ELK Stack:Elasticsearch Logstash Kibana(第2版)》是高凯所著的一本深入解析ELK Stack技术的专著。这本书详细介绍了如何利用ELK Stack进行大数据处理、日志分析和可视化...
在《大数据搜索与日志挖掘及可视化方案:ELK Stack(Elasticsearch, Logstash, Kibana)第二版》中,读者可以深入学习: - ELK Stack的安装与配置,包括集群搭建和性能优化。 - 如何使用Logstash设计有效的数据采集...
对于这些异常情况,需要利用日志分析工具深入挖掘,并结合流量监控数据综合判断。 6. 日志分析与流量监控在安全防护中的作用 日志分析与流量监控在网络安全防护中扮演着至关重要的角色。一方面,通过日志可以及时...
《实战ELK——分布式大数据搜索与日志挖掘及可视化解决方案》是针对现代企业对数据处理需求的一本实用指南。ELK(Elasticsearch、Logstash、Kibana)是目前广泛应用的大数据日志管理和分析工具栈,它为海量数据的...
对于数据驱动型应用,如广告服务,日志数据的分析和挖掘能提高广告投放的精准度和成本效率。随着企业应用向微服务架构的转型,传统的集中式日志管理方案已无法满足需求,因为微服务架构中,日志数据分散在大量虚拟机...
2. **日志分析**:日志分析是对服务器日志进行深度挖掘的过程,通常包括清洗、归类、关联分析等步骤。这个过程中,可能需要用到编程语言(如Python或Java)编写脚本,或者利用专门的日志分析工具(如ELK Stack:...
Kibana则是一个数据分析和可视化平台,允许用户对Elasticsearch中的数据进行直观的分析与展示。 在ELK系统中,Elasticsearch作为数据存储与检索的核心,拥有分布式特性,可实现数据的高可用与水平扩展。同时,ES...
总的来说,ELK栈是IT运维和大数据分析的强大工具,能够帮助企业更好地管理和理解他们的系统日志,实现问题快速定位,优化系统性能,甚至挖掘出潜在的业务洞察。通过合理配置和使用ELK,可以提升IT运营的效率和质量。
《实战Elasticsearch、Logstash、Kibana++分布式大数据搜索与日志挖掘及可视化解决方案》这本书涵盖了在大数据环境中如何高效地实现数据搜索、处理、分析以及可视化的关键技术和工具。以下是该书所涉及的核心知识点...
学习这些数据集和ELK栈的应用,你可以深入理解如何在实际环境中管理、分析和展示日志数据。通过实验,你可以了解如何配置Logstash输入和输出插件,如何在Elasticsearch中索引和查询数据,以及如何在Kibana中设计直观...
《实战Elasticsearch、Logstash、Kibana++分布式大数据搜索与日志挖掘及可视化解决方案》这本书主要聚焦于使用Elasticsearch、Logstash和Kibana构建高效的大数据处理和可视化平台。以下是对这些关键组件及其在实际...
3. **分析能力**:Elasticsearch的分析功能允许对日志进行深入挖掘,比如统计、聚类和预测分析。 4. **监控与报警**:ELK可以结合其他工具(如Metricbeat、Heartbeat等)实现监控和报警,及时发现系统异常。 在搭建...
本篇将深入探讨关于“认识与分析日志文件”的基本知识点。 1. **日志文件的类型** - **系统日志**:记录操作系统级别的事件,如启动和关闭、硬件故障、系统级错误等。 - **应用日志**:由应用程序产生的日志,...
通过以上组件的结合,开发者可以构建出一个强大的日志管理和分析系统,不仅能够收集来自Spring Boot应用的日志,还能进行深入的数据挖掘和可视化,为故障排查、性能优化和业务洞察提供强大支持。这个7.9.0版本的ELK...
4. 分布式大数据搜索与日志挖掘:Elasticsearch、Logstash和Kibana组成的ELK Stack(现在称为Elastic Stack)可以实现分布式搜索、日志收集、处理和可视化的一体化解决方案。在分布式系统中,数据会被自动分割成小的...
此外,日志数据与用户行为、交易数据等其他类型数据的融合,进一步提升了分析价值。 安全和治理也是日志大数据架构中的关键环节。确保数据的隐私和合规性是必须考虑的问题。这包括数据加密、访问控制和审计日志等...
日志分析是IT运维和故障排查的关键环节,通过对日志数据的深入挖掘,可以洞察系统的性能、流量模式、异常行为以及潜在的问题。对于"10000_access.log"这样的访问日志,我们可以从中获取以下关键信息: 1. **请求URL...
《日志标准化规范详解》 随着信息技术的飞速发展,日志...采用如ELK(Elasticsearch, Logstash, Kibana)这样的日志分析平台,结合SpringAOP,可以实现日志的高效收集、处理和分析,为企业的信息化建设提供强大保障。