äļãæčĶ
įąäšįĄŽäŧķéŪéĒãįģŧįŧčĩæšįī§įžšæč
įĻåšæŽčšŦįBUGïžJavaæåĄåĻįšŋäļäļåŊéŋå
å°äžåšį°äļäšâįģŧįŧæ§âæ
éïžæŊåĶïžæåĄæ§č―ææūäļéãéĻåïžæææïžæĨåĢčķ
æķæåĄæŧįãå
ķäļéĻåæ
ééčéĒæ·ąïžåŊđčŋįŧīååžåé æéŋæå°æ°ãįŽč
æ đæŪčŠå·ąįåĶäđ ååŪč·ĩïžæŧįŧåšäļåĨčĄäđææįâéæĨæéĪâįæđæģïžæĨåŋŦéåŪä―JavaæåĄįšŋäļâįģŧįŧæ§âæ
éã
Â
äšãåŊžčĻ
JavačŊčĻæŊåđŋæģä―ŋįĻįčŊčĻïžåŪå
·æč·Ļåđģå°įįđæ§åæåĶæįĻįįđįđïžåūåĪæåĄįŦŊåšįĻé―éįĻJavačŊčĻåžåãįąäšč―ŊäŧķįģŧįŧæŽčšŦäŧĨåčŋčĄįŊåĒįåĪææ§ïžJavaįåšįĻäļåŊéŋå
å°äžåšį°äļäšæ
éãå°―įŪĄæ
éįčĄĻ蹥éåļļæŊčūææūïžæåĄååšææūåæ
ĒãčūåšåįéčŊŊãåįåīĐæšįïžïžä―æ
éåŪä―åīåđķäļäļåŪåŪđæãäļšäŧäđåĒïžæåĶäļåå ïž
Â
1. įĻåšæå°įæĨåŋčķčŊĶįŧïžčķåŪđæåŪä―å°BUGïžä―æŊåŊč―æäšæķåįĻåšäļæēĄææå°įļå
ģå
åŪđå°æĨåŋïžæč
æĨåŋįš§åŦæēĄæčŪūį―Ūå°įļåšįš§åŦ
2. įĻåšåŊč―åŠåŊđåūįđæŪįčūå
ĨæĄäŧķåįæ
éïžä―čūå
ĨæĄäŧķéūäŧĨæĻæååĪį°
3. éåļļčŠå·ąįžåįįĻåšåšį°įéŪéĒäžæŊčūåŪđæåŪä―ïžä―åšįĻįŧåļļæŊįąåĪäššåä―įžåïžæ
éåŪä―äššååŊč―åđķäļįæå
ķäŧäššåįžåįįĻåš
4. åšįĻéåļļäžäūčĩåūåĪįŽŽäļæđåšïžįŽŽäļæđåšäļéčįįBUGåŊč―æŊå§ææŠåį
5. åĪæ°įåžåäššååĶäđ įé―æŊâåĶä―įžåäļåĄåč―âįææŊčĩæïžä―åŊđäšâåĶä―įžåéŦæãåŊé įįĻåšâãâåĶä―åŪä―įĻåšæ
éâåīįĨäđįå°ãæäŧĨäļæĶåšįĻåšį°æ
éïžäŧäŧŽåđķæēĄæčķģåĪįææŊčæŊįĨčŊæĨåļŪåĐäŧäŧŽåŪææ
éåŪä―ã
Â
å°―įŪĄæäšæ
éäžåūéūåŪä―ïžä―įŽč
æ đæŪåĶäđ ååŪč·ĩæŧįŧåšäļåĨâéæĨæéĪâįæ
éåŪä―æđæģïžéčŋæä―įģŧįŧåJavačææšæäūįįæ§åčŊæå·Ĩå
·ïžč·åå°įģŧįŧčĩæšåįŪæ æåĄïžåšį°æ
éįJavaæåĄïžå
éĻįįķæïžåđķäūæŪæåĄįĻåšįįđįđïžčŊåŦåšåŠäšį°čąĄæŊæĢåļļįïžåŠäšį°čąĄæŊåžåļļįãčåéčŋæéĪæĢåļļįį°čąĄïžåč·čļŠåžåļļį°čąĄïžå°ąåŊäŧĨčūūå°Â æ
éåŪä―įįŪæ ã
Â
åĻæĢåžäŧįŧčŊĨæđæģäđåïžå
įģæäļäļčŋäļŠæđæģä―ŋįĻįčåīã
Â
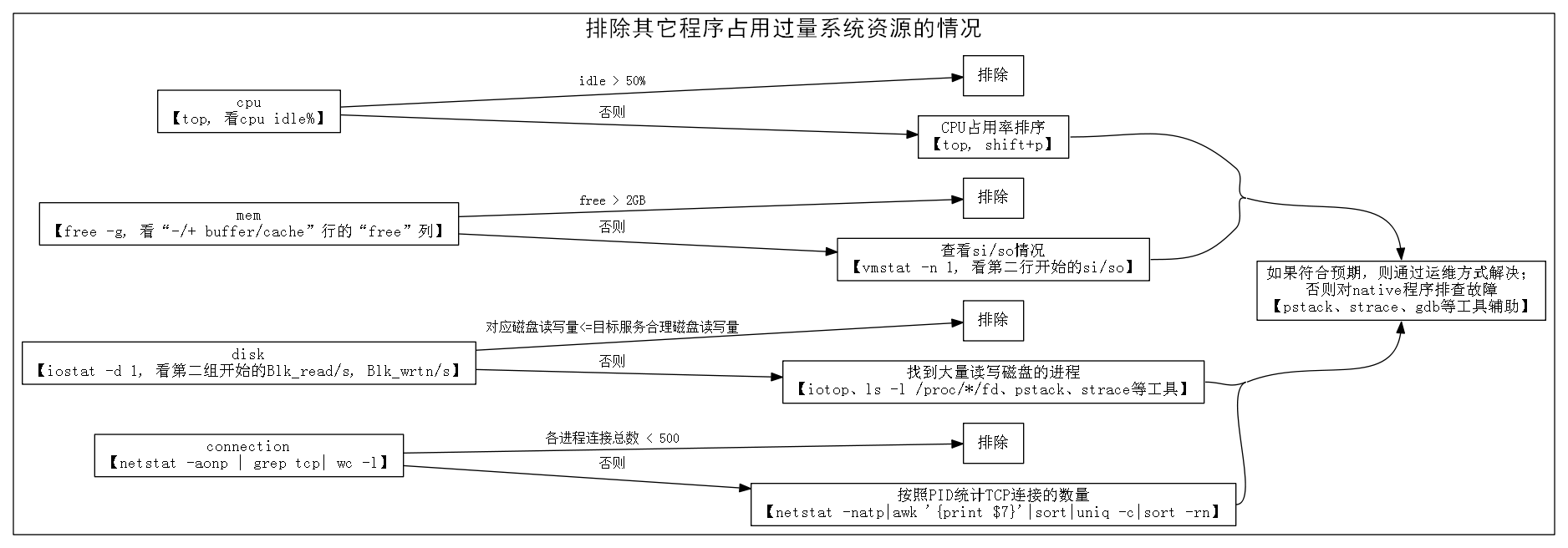
äļãæŽæđæģéįĻįčåī
æŽæđæģäļŧčĶéįĻäšLinuxįģŧįŧäļJavaæåĄįšŋäļâįģŧįŧæ§âæ
éįåŪä―ïžæŊåĶïžæåĄæ§č―ææūäļéãéĻåïžæææïžæĨåĢčķ
æķæåĄæŧãå
ķåŪæä―įģŧįŧæå
ķåŪčŊčĻįæåĄïžäđåŊäŧĨåčæŽæįæč·Ŋã
Â
äļéįĻæŽæđæģįæ
åĩïžåŊđäšâåč―æ§âæ
éïžäūåĶčŋįŪįŧæäļåŊđãéŧčūåæŊčĩ°éįïžäļåŧščŪŪä―ŋįĻæŽæđæģãåŊđåū
čŋäšæ
åĩæŊčūæ°å―įæđæģæŊåĻæĩčŊįŊåĒäļéį°ïžåđķä―ŋįĻJavačææšæäūįâčŋįĻč°čŊâåč―čŋčĄåĻæč·čļŠč°čŊã
Â
åéĒčŊīčŋïžæŽæđæģåšäšâåžåļļį°čąĄâįčŊåŦæĨåŪä―æ
éãéĢįģŧįŧäļåŊč―æåŠäšåžåļļį°čąĄåĒïž
Â
åãæåŠäšåžåļļį°čąĄ
æäŧŽåŊäŧĨå°åžåļļį°čąĄåæäļĪįąŧïžįģŧįŧčĩæšįåžåļļį°čąĄãâįŪæ æåĄâå
éĻįåžåļļį°čąĄãįŪæ æåĄïžæįæŊåšį°æ
éįJavaæåĄã
Â
1. įģŧįŧčĩæšįåžåļļį°čąĄ
äļäļŠįĻåšįąäšBUGæč
é
į―Ūäļå―ïžåŊč―äžå įĻčŋåĪįįģŧįŧčĩæšïžåŊžčīįģŧįŧčĩæšåŪäđãčŋæķïžįģŧįŧäļå
ķåŪįĻåšå°ąäžåšį°čŪĄįŪįžæ
Ēãčķ
æķãæä―åĪąčīĨįâįģŧįŧæ§âæ
éãåļļč§įįģŧįŧčĩæšåžåļļį°čąĄæïžCPUå įĻčŋéŦãįĐįå
ååŊä―éæå°ãįĢįI/Oå įĻčŋéŦãåįæĒå
ĨæĒåščŋåĪãį―įŧéūæĨæ°čŋåĪãåŊäŧĨéčŋtopãiostatãvmstatãnetstatå·Ĩå
·č·åå°įļåšæ
åĩã
Â
Â
2. įŪæ æåĄå
éĻįåžåļļį°čąĄ
- Javaå æŧĄÂ
Javaå æŊâJavačææšâäŧæä―įģŧįŧįģčŊ·å°įäļåĪ§åå
åïžįĻäšåæūJavaįĻåščŋčĄäļååŧšįåŊđ蹥ãå―Javaå æŧĄæč
čūæŧĄįæ
åĩäļïžäžč§ĶåâJavačææšâįâååūæķéâæä―ïžå°ææâäļåŊčūūåŊđ蹥âïžåģįĻåšéŧčūäļč―åžįĻå°įåŊđ蹥ïžæļ
įæãææķïžįąäšįĻåšéŧčūæč
Javaå åæ°čŪūį―ŪįéŪéĒïžäžåŊžčīâåŊčūūåŊđ蹥âïžåģįĻåšéŧčūåŊäŧĨåžįĻå°įåŊđ蹥ïžå æŧĄäšJavaå ãčŋæķïžJavačææšå°ąäžæ äžæĒå°åâååūåæķâæä―ïžä―ŋåūæīäļŠJavaįĻåšäžčŋå
ĨåĄæŧįķæãæäŧŽåŊäŧĨä―ŋįĻjstatå·Ĩå
·æĨįJavaå įå įĻįã
- æĨåŋäļįåžåļļÂ
įŪæ æåĄåŊč―äžåĻæĨåŋäļčŪ°å―äļäšåžåļļäŋĄæŊïžäūåĶčķ
æķãæä―åĪąčīĨįäŋĄæŊïžå
ķäļåŊč―åŦæįģŧįŧæ
éįå
ģéŪäŋĄæŊã
- įéūæįÂ
æŧéãæŧåūŠįŊãæ°æŪįŧæåžåļļïžčŋåĪ§æč
čĒŦį īåïžãéäļįåū
åĪéĻæåĄååšįį°čąĄãčŋäšåžåļļį°čąĄéåļļéįĻjstackå·Ĩå
·åŊäŧĨč·åå°éåļļæįĻįįšŋįīĒã
Â
äšč§Ģåžåļļį°čąĄåįąŧäđåïžæäŧŽæĨå
·ä―čŪēčŪēæ
éåŪä―įæĨéŠĪã
Â
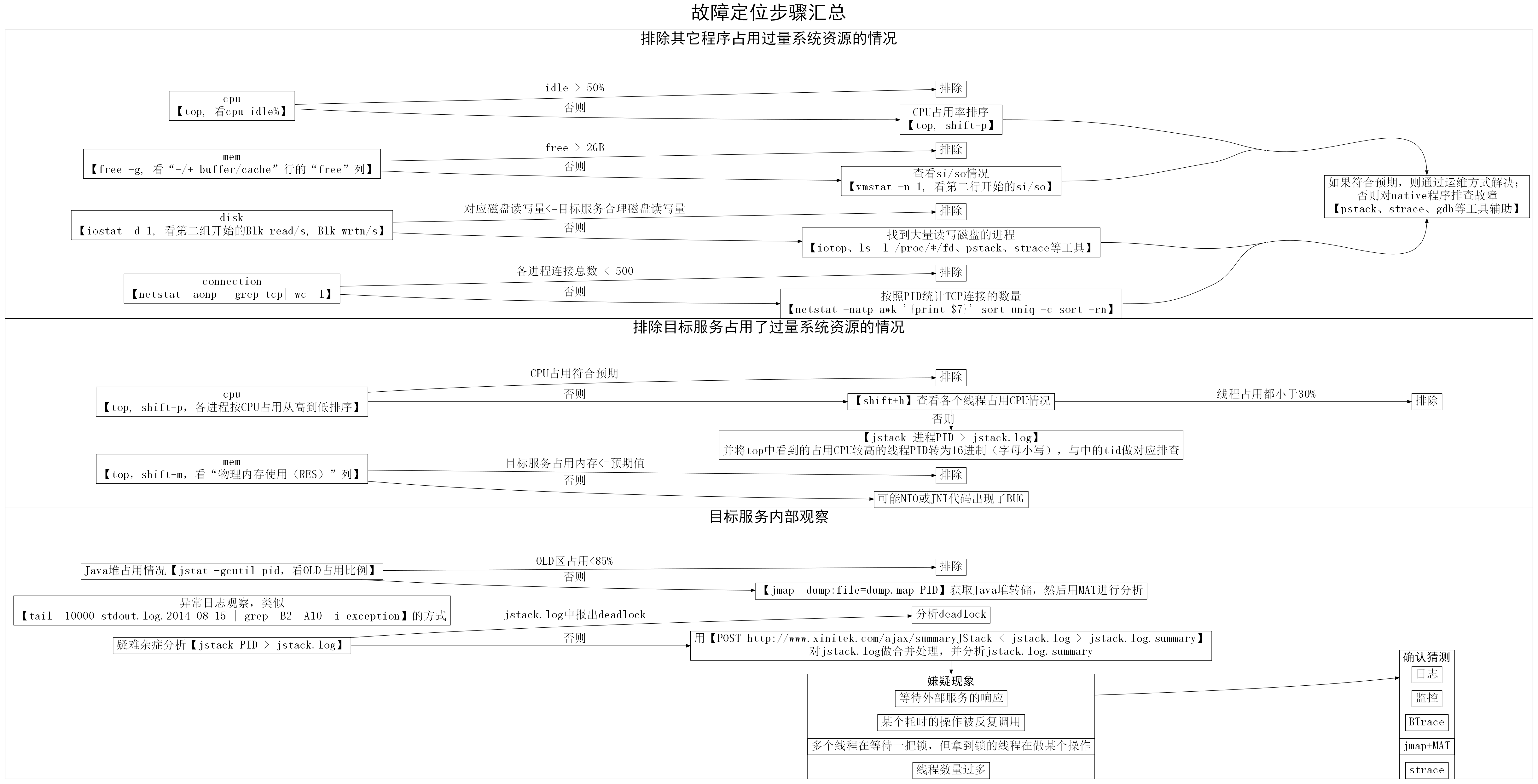
äšãæ
éåŪä―įæĨéŠĪ
æäŧŽéįĻâäŧåĪå°å
ïžéæĨæéĪâįæđåžæĨåŪä―æ
éïž
 1. å
æéĪå
ķåŪįĻåščŋåšĶå įĻįģŧįŧčĩæšįéŪéĒ
 2. įķåæéĪâįŪæ æåĄâæŽčšŦå įĻįģŧįŧčĩæščŋåšĶįéŪéĒ
 3. æåč§åŊįŪæ æåĄå
éĻįæ
åĩïžæéĪæåį§åļļč§æ
éįąŧåã
åŊđäšäļč―æéĪįæđéĒïžčĶæ đæŪčŊĨäŋĄæŊåŊđåšįâåąéĐįĻåšĶâæĨåĪææŊåščŊĨâčŋäļæĨæ·ąå
ĨâčŋæŊâææķč·ģčŋâãäūåĶâįŪæ æåĄJavaå å įĻ100%âčŋæŊäļæĄåąéĐįĻåšĶčūéŦįäŋĄæŊïžåŧščŪŪįŦåģâčŋäļæĨæ·ąå
ĨâãčåŊđäšâåĻCPUæ ļæ°äļš8įæšåĻäļïžå
ķåŪįĻåšåķįķå įĻCPUčūū200%âčŋį§åąéĐįĻåšĶäļæŊåūéŦįäŋĄæŊïžååŧščŪŪâææķč·ģčŋâãå―įķïžæäšå
·ä―æ
åĩčŋéčĶæ
éææĨäššåæ đæŪčŠå·ąįįŧéŠååšåĪæã
Â
įŽŽäļæĨïžæéĪå
ķåŪįĻåšå įĻčŋéįģŧįŧčĩæšįæ
åĩ
åūįĪšïžæéĪå
ķåŪįĻåšå įĻčŋéįģŧįŧčĩæšįæ
åĩ
1.  čŋčĄãtopãïžæĢæĨCPU idleæ
åĩïžåĶæåį°idlečūåĪïžäūåĶåĪä―50%ïžïžåæéĪå
ķåŪčŋįĻå įĻCPUčŋéįæ
åĩã
   åĶæidlečūå°ïžåæshift+pïžå°čŋįĻæį
§CPUå įĻįäŧéŦå°ä―æåšïžéäļææĨïžč§äļéĒTIPïžã
Â
2.  čŋčĄãfree -gãïžæĢæĨåĐä―įĐįå
åïžâ-/+ buffer/cacheâčĄįâfreeâåïžæ
åĩïžåĶæåį°åĐä―įĐįå
åčūåĪïžäūåĶåĐä―2GBäŧĨäļïžïžåæéĪå įĻįĐįå
åčŋéįæ
åĩã
  åĶæåĐä―įĐįå
åčūå°ïžäūåĶåĐä―1GBäŧĨäļïžïžåčŋčĄãvmstat -n 1ãæĢæĨsi/soïžæĒå
ĨæĒåšïžæ
åĩïž
įŽŽäļčĄæ°åžčĄĻįĪšįæŊäŧįģŧįŧåŊåĻå°čŋčĄå―äŧĪæķįååžïžæäŧŽåŋ―įĨæãäŧįŽŽäščĄåžå§ïžæŊäļčĄįsi/sočĄĻįĪščŊĨį§å
si/soįblockæ°ãåĶæåĪčĄæ°åžé―äļšéķïžååŊäŧĨæéĪįĐįå
åäļčķģįéŪéĒãåĶææ°åžčūåĪ§ïžäūåĶåĪ§äš1000 blocks/secïžblockįåĪ§å°äļčŽæŊ1KBïžåčŊīæååĻčūææūįå
åäļčķģéŪéĒãæäŧŽåŊäŧĨčŋčĄãtopãčūå
Ĩshift+mïžå°čŋįĻæį
§įĐįå
åå įĻïžâRESâåïžäŧåĪ§å°å°čŋčĄæåšïžįķååŊđæåéĒįčŋįĻéäļææĨïžč§äļéĒTIPïžã
Â
3.  åĶæįŪæ æåĄæŊįĢįI/OčūéįįĻåšïžåįĻãiostat -d 1ãïžæĢæĨįĢįI/Oæ
åĩãčĨâįŪæ æåĄåŊđåšįįĢįâčŊŧåéåĻéĒäž°äđå
ïžéĒäž°čĶæģĻæcacheæšåķįå―ąåïžïžåæéĪå
ķåŪčŋįĻå įĻįĢįI/OčŋéįéŪéĒã
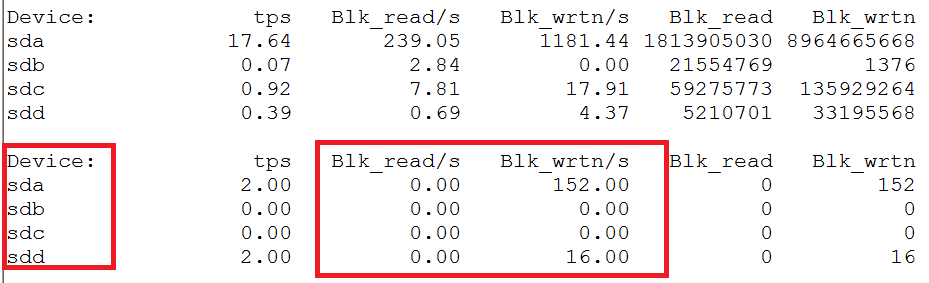
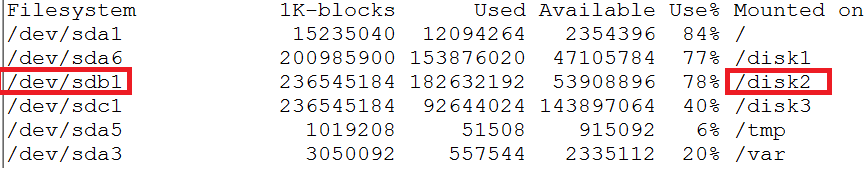
įŽŽäļįŧæ°æŪæŊäŧčŊĨæšåĻäŧåžæšäŧĨæĨįįŧčŪĄåžãäŧįŽŽäšįŧåžå§ïžé―æŊæŊį§éįįŧčŪĄåžãéčŋãdfãå―äŧĪïžåŊäŧĨįå°DeviceäļįŪå―įå
ģįģŧãäļåūčŪūåĪâsdbâå°ąåŊđåšäšįŪå―â/disk2âã
Â
ååĶåį°įŪæ æåĄæåĻįĢįčŊŧåéææūčķ
čŋæĻįŪåžïžååščŊĨæūå°åĪ§éčŊŧåįĢįįčŋįĻïžč§äļéĒTIPïž
Â
4.  čŋčĄãnetstat -aonp | grep tcp| wc -lãæĨįåį§įķæįTCPčŋæĨæ°éåãåĶææŧæ°čūå°ïžäūåĶå°äš500ïžïžåæéĪčŋæĨæ°å įĻčŋåĪéŪéĒã
ååĶåį°čŋæĨæ°čūåĪïžåŊäŧĨįĻãnetstat -natp|awk â{print $7}â|sort|uniq -c|sort -rnãæį
§PIDįŧčŪĄTCPčŋæĨįæ°éïžįķååŊđčŋæĨæ°čūåĪįčŋįĻéäļææĨïžč§äļéĒTIPïžã
Â
TIPïžåĶä―âéäļææĨâïžååĶåŪä―å°æŊæäļŠåĪéĻįĻåšå įĻčŋéįģŧįŧčĩæšïžåäūæŪčŋįĻįåč―åé
į―Ūæ
åĩåĪææŊåĶåäđéĒæãååĶįŽĶåéĒæïžåččå°æåĄčŋį§ŧå°å
ķäŧæšåĻãäŋŪæđįĻåščŋčĄįįĢįãäŋŪæđįĻåšé
į―Ūįæđåžč§ĢåģãååĶäļįŽĶåéĒæïžååŊč―æŊčŋčĄč
åŊđčŊĨįĻåšäļåĪŠäšč§Ģæč
æŊčŊĨįĻåšåįäšBUGãåĪéĻįĻåšéåļļåŊč―æŊJavaįĻåšäđåŊč―äļæŊJavaįĻåšïžåĶææŊJavaįĻåšïžåŊäŧĨæåŪå―ä―įŪæ æåĄäļæ ·čŋčĄææĨïžčéJavaįĻåšå
·ä―ææĨæđæģčķ
åšäšæŽæčåīïžååšäļäļŠå·Ĩå
·äūåčéįĻïž
- įģŧįŧæäūįč°įĻæ įč―ŽåĻå·Ĩå
·ãpstackãïžåŊäŧĨäšč§Ģå°įĻåšäļåäļŠįšŋįĻå―åæĢåĻåđēäŧäđïžäŧčäšč§Ģå°äŧäđéŧčūå įĻäšCPUãäŧäđéŧčūå įĻäšįĢįį
- įģŧįŧæäūįč°įĻč·čļŠå·Ĩå
·ãstraceãïžåŊäŧĨäūĶæĩå°įĻåšäļæŊäļŠįģŧįŧAPIč°įĻįåæ°ãčŋååžãč°įĻæķéīįãäŧčįĄŪčŪĪįĻåšäļįģŧįŧAPIäšĪäšæŊåĶæĢåļļįã
- įģŧįŧæäūįč°čŊåĻãgdbãïžåŊäŧĨčŪūį―ŪæĄäŧķæįđäūĶæĩæäļŠįģŧįŧå―æ°č°įĻįæķåč°įĻæ æŊäŧäđæ ·įãäŧčäšč§Ģå°äŧäđéŧčūäļæåĻåé
å
åãäŧäđéŧčūäļæåĻååŧšæ°čŋæĨį
TIPïžåĶä―âæūå°åĪ§éčŊŧåįĢįįčŋįĻâïž
  1. åĶæLinuxįģŧįŧæŊčūæ°ïžkernel v2.6.20äŧĨäļïžåŊäŧĨä―ŋįĻiotopå·Ĩå
·č·įĨæŊäļŠčŋįĻįioæ
åĩïžčūåŋŦå°åŪä―å°čŊŧåįĢįčūåĪįčŋįĻã  Â
  2. éčŋãls -l /proc/*/fd | grep čŊĨčŪūåĪæ å°čĢ
č――å°įæäŧķįģŧįŧč·ŊåūãæĨįå°åŠäļŠčŋįĻæåžäščŊĨčŪūåĪįæäŧķïžåđķæ đæŪčŋįĻčšŦäŧ―ãæåžįæäŧķåãæäŧķåĪ§å°įåąæ§åĪææŊåĶåäšåĪ§éčŊŧåã
  3. åŊäŧĨä―ŋįĻpstackååūčŋįĻįįšŋįĻč°įĻæ ïžæč
straceč·čļŠįĢįčŊŧåAPIæĨåļŪåĐįĄŪčŪĪæäļŠčŋįĻæŊåĶåĻåįĢįååĪ§éčŊŧå
Â
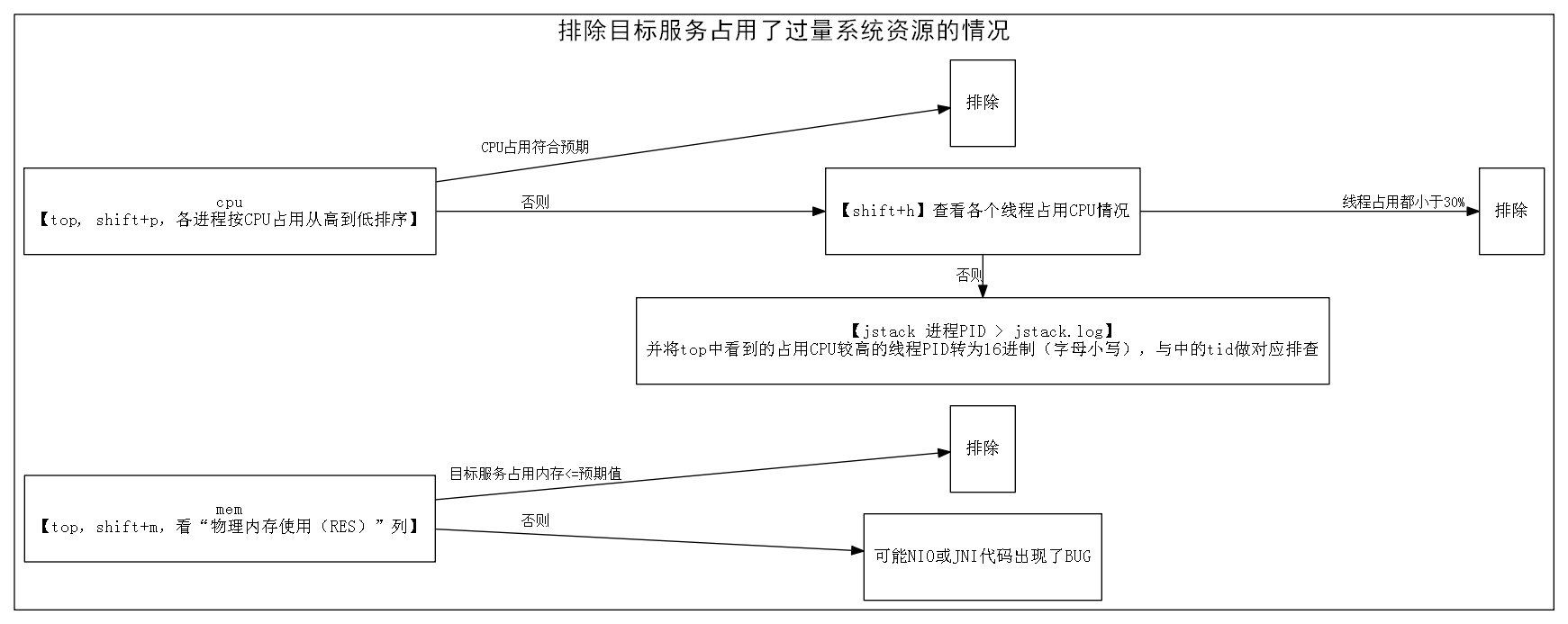
įŽŽäšæĨïžæéĪįŪæ æåĄå įĻäščŋéįģŧįŧčĩæšįæ
åĩ
åūįĪšïžæéĪįŪæ æåĄå įĻäščŋéįģŧįŧčĩæšįæ
åĩ
1.  čŋčĄãtopãïžshift+pæį
§âCPUä―ŋįĻâäŧéŦå°ä―įæåšæĨįčŋįĻïžååĶįŪæ æåĄå įĻįCPUčūä―ïž<100%ïžåģå°äšäļäļŠæ ļįčŪĄįŪéïžïžæč
įŽĶåįŧéŠéĒæïžåæéĪįŪæ æåĄCPUå įĻčŋéŦįéŪéĒã
  ååĶįŪæ æåĄå įĻįCPUčūéŦïž>100%ïžåģåĪ§äšäļäļŠæ ļįčŪĄįŪéïžïžåshift+hč§åŊįšŋįĻįš§åŦįCPUä―ŋįĻååļã
- åĶæCPUä―ŋįĻåæĢå°åĪäļŠįšŋįĻïžčäļæŊäļŠįšŋįĻå įĻé―äļįŪéŦïžäūåĶé―<30%ïžïžåæéĪCPUå įĻčŋéŦįéŪéĒ
- åĶæCPUä―ŋįĻéäļå°äļäļŠæå äļŠįšŋįĻïžčäļåūéŦïžäūåĶé―>95%ïžïžåįĻãjstack pid > jstack.logãč·åįŪæ æåĄäļįšŋįĻč°įĻæ įæ
åĩãtopäļįå°įå įĻCPUčūéŦįįšŋįĻįPIDč―ŽæĒæ16čŋåķïžåæŊįĻå°åïžïžįķååĻjstack.logäļæūå°åŊđåšįšŋįĻïžæĢæĨå
ķéŧčūïž
- ååĶåŊđåšįšŋįĻæŊįšŊčŪĄįŪåäŧŧåĄïžäūåĶGCãæĢååđé
ãæ°åžčŪĄįŪįïžïžåæéĪCPUå įĻčŋéŦįéŪéĒãå―įķåĶæčŋį§įšŋįĻå įĻCPUæŧéåĶæčŋåĪïžäūåĶå æŧĄäšæææ ļïžïžåéčĶåŊđįšŋįĻæ°éåæ§åķïžéåķįšŋįĻæ° < CPUæ ļæ°ïžã
- ååĶåŊđåšįšŋįĻäļæŊįšŊčŪĄįŪåäŧŧåĄïžäūåĶåŠæŊåå
ķäŧæåĄčŊ·æąäļäšæ°æŪïžįķåįŪåįŧåäļäļčŋåįŧįĻæ·įïžïžččŊĨįšŋįĻCPUå įĻčŋéŦïž>95%ïžïžååŊč―åįäšåžåļļãäūåĶïžæŧåūŠįŊãæ°æŪįŧæčŋåĪ§įéŪéĒïžįĄŪåŪå
·ä―åå įæđæģč§äļæâįŽŽäļæĨïžįŪæ čŋįĻå
éĻč§åŊâã
Â
2. čŋčĄãtopãïžshift+mæį
§âįĐįå
åä―ŋįĻ(RES)âäŧéŦå°ä―æåščŋįĻïžčŊäž°įŪæ æåĄå įå
åéæŊåĶåĻéĒæäđå
ãåĶæåĻéĒæäđå
ïžåæéĪįŪæ æåĄNativeå
åå įĻčŋéŦįéŪéĒã
  æįĪšïžįąäšJavačŋįĻäļæJavaįš§åŦįå
åå įĻïžäđæNativeįš§åŦįå
åå įĻïžæäŧĨJavačŋįĻįâįĐįå
åä―ŋįĻ(RES)âæŊâ-Xmxåæ°æåŪįJavaå åĪ§å°âåĪ§äļäšæŊæĢåļļįïžäūåĶ1.5~2åå·Ķåģïžã
  ååĶâįĐįå
åä―ŋįĻ(RES)âčķ
åšéĒæčūåĪïžäūåĶ2åäŧĨäļïžïžåđķäļįĄŪåŪJNIéŧčūäļåščŊĨå įĻčŋäđåĪå
åïžååŊč―æŊNIOæJNIäŧĢį åšį°äšBUGãįąäšæŽæäļŧčĶčŪĻčŪšįæŊJavaįš§åŦįéŪéĒïžæäŧĨåŊđčŋį§æ
åĩäļåčŋåĪčŪĻčŪšãčŊŧč
åŊäŧĨåčäļæâTIPïžåĶä―éäļææĨâčŋčĄnativeįš§åŦįč°čŊã
Â
įŽŽäļæĨïžįŪæ æåĄå
éĻč§åŊ
åūįĪšïžįŪæ æåĄå
éĻč§åŊ
1. Javaå å įĻæ
åĩ
 įĻãjstat -gcutil pidãæĨįįŪæ æåĄįOLDåšå įĻæŊäūïžååĶå įĻæŊäūä―äš85%åæéĪJavaå å įĻæŊäūčŋéŦįéŪéĒã
 ååĶå įĻæŊäūčūéŦïžäūåĶčķ
čŋ98%ïžïžåæåĄååĻJavaå å æŧĄįéŪéĒãčŋæķååŊäŧĨįĻjmap+matčŋčĄåæåŪä―å
åäļå įĻæŊäūįæ
åĩïžč§äļæTIPïžïžäŧččūåŋŦå°åŪä―å°Javaå æŧĄįåå ã
Â
TIPïžįĻjmap+matčŋčĄåæåŪä―å
åäļå įĻæŊäūįæ
åĩ
å
éčŋãjmap -dump:file=dump.map pidãååūįŪæ æåĄįJavaå č―ŽåĻïžįķåæūäļå°įĐšéēå
åčūåĪ§įæšåĻåĻVNCäļčŋčĄmatå·Ĩå
·ãmatå·Ĩå
·äļæåždump.mapåïžåŊäŧĨæđäūŋå°åæå
åäļäŧäđåŊđ蹥åžįĻäšåĪ§éįåŊđ蹥ïžäŧéŧčūæäđäļæĨčŊīïžå°ąæŊčŊĨåŊđ蹥å įĻäšåĪåĪ§æŊäūįå
åïžãå
·ä―ä―ŋįĻåŊäŧĨca
Â
2. åžåļļæĨåŋč§åŊ
éčŋįąŧäžžãtail -10000 stdout.log.2014-08-15 | grep -B2 -A10 -i exceptionãčŋæ ·įæđåžïžåŊäŧĨæĨå°æĨåŋäļæčŋčŪ°å―įåžåļļã
Â
3. įéūæį
įĻãjstack pid > jstack.logãč·åįŪæ æåĄäļâéæ
åĩâåâåįšŋįĻč°įĻæ âäŋĄæŊïžåđķåæ
- æĢæĨjstack.logäļæŊåĶædeadlockæĨåšïžåĶææēĄæåæéĪdeadlockæ
åĩã
Found one Java-level deadlock:
=============================
 waiting to lock monitor 0x1884337c (object 0x046ac698, a java.lang.Object),
 which is held by âmainâ
 waiting to lock monitor 0x188426e4 (object 0x046ac6a0, a java.lang.Object),
 which is held by âThread-0âģ
Â
Java stack information for the threads listed above:
===================================================
âThread-0âģ:
 at LockProblem$T2.run(LockProblem.java:14)
 - waiting to lock <0x046ac698> (a java.lang.Object)
 - locked <0x046ac6a0> (a java.lang.Object)
âmainâ:
 at LockProblem.main(LockProblem.java:25)
 - waiting to lock <0x046ac6a0> (a java.lang.Object)
 - locked <0x046ac698> (a java.lang.Object)
Â
Found 1 deadlock.
Â
  åĶæåį°deadlockååæ đæŪjstack.logäļįæįĪšåŪä―å°åŊđåšäŧĢį éŧčūãÂ
éčŋjstack.log.summaryäļįæ
åĩïžæäŧŽåŊäŧĨčūčŋ
éå°åŪä―å°äļäšåŦįįđïžåđķåŊäŧĨįæĩå
ķæ
éåžčĩ·įåå ïžåææjstack.log.summaryæ
åĩäļūäūäūåčïž
| æ
åĩ |
åŦįįđ |
įæĩåå |
| įšŋįĻæ°éčŋåĪ |
æį§įšŋįĻæ°éčŋåĪ |
čŋčĄįŊåĒäļâéåķįšŋįĻæ°éâįæšåķåĪąæ
|
|
åĪäļŠįšŋįĻåĻįåū
äļæéïžä―æŋå°éįįšŋįĻåĻåæäļŠæä―
|
æŋå°čŋæéįįšŋįĻåĻåį―įŧconnectæä―
|
čĒŦconnectįæåĄåžåļļ |
|
Â
|
æŋå°éįįšŋįĻåĻåæ°æŪįŧæéåæä―
|
čŊĨæ°æŪįŧæčŋåĪ§æčĒŦį īå
|
|
æäļŠčæķįæä―čĒŦååĪč°įĻ
|
æäļŠåšå―čĒŦįžåįåŊđ蹥åĪæŽĄčĒŦååŧš
|
åŊđčąĄæą įé
į―ŪéčŊŊ |
|
įåū
åĪéĻæåĄįååš
|
åūåĪįšŋįĻé―åĻįåū
åĪéĻæåĄįååš
|
čŊĨåĪéĻæåĄæ
é
|
|
Â
|
åūåĪįšŋįĻé―åĻįåū
FutureTaskåŪæïžčFutureTaskåĻįåū
åĪéĻæåĄįååš
|
čŊĨåĪéĻæåĄæ
é
|
įæĩäšåå åïžåŊäŧĨéčŋæĨåŋæĢæĨãįæ§æĢæĨãįĻæĩčŊįĻåšå°čŊåĪį°įæđåžįĄŪčŪĪįæĩæŊåĶæĢįĄŪãåĶæéčĶæīįŧčīįčŊæŪæĨįĄŪčŪĪïžåŊäŧĨéčŋBTraceãstraceãjmap+MATįå·Ĩå
·čŋčĄåæïžæįŧįĄŪčŪĪéŪéĒæåĻã
Â
äļéĒįŪåäŧįŧäļčŋå äļŠå·Ĩå
·ïž
BTraceïžįĻäšįæĩJavaįš§åŦįæđæģč°įĻæ
åĩãåŊäŧĨåŊđčŋčĄäļįJavačææšæå
Ĩč°čŊäŧĢį ïžäŧčįĄŪčŪĪæđæģæŊæŽĄč°įĻįåæ°ãčŋååžãčąčīđæķéīįãįŽŽäļæđå
čīđå·Ĩå
·ã
straceïžįĻäšįč§įģŧįŧč°įĻæ
åĩãåŊäŧĨåūå°æŊæŽĄįģŧįŧč°įĻįåæ°ãčŋååžãččīđæķéīįãLinuxčŠåļĶå·Ĩå
·ã
jmap+MATïžįĻäšæĨįJavaįš§åŦå
åæ
åĩãjmapæŊJDKčŠåļĶå·Ĩå
·ïžåŊäŧĨå°JavaįĻåšįJavaå č―ŽåĻå°æ°æŪæäŧķäļïžMATæŊeclipse.orgäļæäūįäļäļŠå·Ĩå
·ïžåŊäŧĨæĢæĨjmapč―ŽåĻæ°æŪæäŧķäļįæ°æŪãįŧåčŋäļĪäļŠå·Ĩå
·ïžæäŧŽåŊäŧĨéåļļåŪđæå°įå°JavaįĻåšå
åäļææåŊđ蹥åå
ķåąæ§ã
Â
TIPïžjstack.log.summaryæ
åĩäļūäū
1. æį§įšŋįĻæ°éčŋåĪ
1000 threads at
âTimer-0âģ prio=6 tid=0x189e3800 nid=0x34e0 in Object.wait() [0x18c2f000]
  java.lang.Thread.State: TIMED_WAITING (on object monitor)
 at java.lang.Object.wait(Native Method)
 at java.util.TimerThread.mainLoop(Timer.java:552)
 - locked [***] (a java.util.TaskQueue)
 at java.util.TimerThread.run(Timer.java:505)
Â
2. åĪäļŠįšŋįĻåĻįåū
äļæéïžä―æŋå°éįįšŋįĻåĻåæ°æŪįŧæéåæä―
38 threads at
âThread-44âģ prio=6 tid=0Ã18981800 nid=0x3a08 waiting for monitor entry [0x1a85f000]
  java.lang.Thread.State: BLOCKED (on object monitor)
 at SlowAction$Users.run(SlowAction.java:15)
 - waiting to lock [***] (a java.lang.Object)
Â
1 threads at
âThread-3âģ prio=6 tid=0x1894f400 nid=0Ã3954 runnable [0x18d1f000]
  java.lang.Thread.State: RUNNABLE
 at java.util.LinkedList.indexOf(LinkedList.java:603)
 at java.util.LinkedList.contains(LinkedList.java:315)
 at SlowAction$Users.run(SlowAction.java:18)
 - locked [***] (a java.lang.Object)
Â
3. æäļŠåšå―čĒŦįžåįåŊđ蹥åĪæŽĄčĒŦååŧšïžæ°æŪåščŋæĨïž
99 threads at
âresin-tcp-connection-*:3231-321âģ daemon prio=10 tid=0x000000004dc43800 nid=0x65f5 waiting for monitor entry [0x00000000507ff000]
  java.lang.Thread.State: BLOCKED (on object monitor)
     at org.apache.commons.dbcp.PoolableConnectionFactory.makeObject(PoolableConnectionFactory.java:290)
     - waiting to lock <0x00000000b26ee8a8> (a org.apache.commons.dbcp.PoolableConnectionFactory)
     at org.apache.commons.pool.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:771)
     at org.apache.commons.dbcp.PoolingDataSource.getConnection(PoolingDataSource.java:95)
     âĶ
Â
1 threads at
âresin-tcp-connection-*:3231-149âģ daemon prio=10 tid=0x000000004d67e800 nid=0x66d7 runnable [0x000000005180f000]
  java.lang.Thread.State: RUNNABLE
     âĶ
     at org.apache.commons.dbcp.DriverManagerConnectionFactory.createConnection(DriverManagerConnectionFactory.java:46)
     at org.apache.commons.dbcp.PoolableConnectionFactory.makeObject(PoolableConnectionFactory.java:290)
     - locked <0x00000000b26ee8a8> (a org.apache.commons.dbcp.PoolableConnectionFactory)
     at org.apache.commons.pool.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:771)
     at org.apache.commons.dbcp.PoolingDataSource.getConnection(PoolingDataSource.java:95)
     at âĶ
Â
4. åūåĪįšŋįĻé―åĻįåū
åĪéĻæåĄįååš
  100 threads at
âThread-0âģ prio=6 tid=0x189cdc00 nid=0Ã2904 runnable [0x18d5f000]Â
java.lang.Thread.State: RUNNABLEÂ
at java.net.SocketInputStream.socketRead0(Native Method)Â
at java.net.SocketInputStream.read(SocketInputStream.java:150)Â
at java.net.SocketInputStream.read(SocketInputStream.java:121)Â
âĶÂ
at RequestingService$RPCThread.run(RequestingService.java:24)
Â
5. åūåĪįšŋįĻé―åĻįåū
FutureTaskåŪæïžčFutureTaskåĻįåū
åĪéĻæåĄįååš
100 threads at
âThread-0âģ prio=6 tid=0Ã18861000 nid=0x38b0 waiting on condition [0x1951f000]
  java.lang.Thread.State: WAITING (parking)
 at sun.misc.Unsafe.park(Native Method)
 - parking to wait for [***] (a java.util.concurrent.FutureTask$Sync)
 at java.util.concurrent.locks.LockSupport.park(LockSupport.java:186)
 at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:834)
 at java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireSharedInterruptibly(AbstractQueuedSynchronizer.java:994)
 at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireSharedInterruptibly(AbstractQueuedSynchronizer.java:1303)
 at java.util.concurrent.FutureTask$Sync.innerGet(FutureTask.java:248)
 at java.util.concurrent.FutureTask.get(FutureTask.java:111)
 at IndirectWait$MyThread.run(IndirectWait.java:51)
Â
100 threads at
âpool-1-thread-1âģ prio=6 tid=0x188fc000 nid=0Ã2834 runnable [0x1d71f000]Â
java.lang.Thread.State: RUNNABLEÂ
at java.net.SocketInputStream.socketRead0(Native Method)Â
at java.net.SocketInputStream.read(SocketInputStream.java:150)Â
at java.net.SocketInputStream.read(SocketInputStream.java:121)Â
âĶÂ
at IndirectWait.request(IndirectWait.java:23)Â
at IndirectWait$MyThread$1.call(IndirectWait.java:46)Â
at IndirectWait$MyThread$1.call(IndirectWait.java:1)Â
at java.util.concurrent.FutureTask$Sync.innerRun(FutureTask.java:334)Â
at java.util.concurrent.FutureTask.run(FutureTask.java:166)Â
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1110)Â
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:603)Â
at java.lang.Thread.run(Thread.java:722)
Â
äļšæđäūŋčŊŧč
ä―ŋįĻïžå°æ
éåŪä―äļäļŠæĨéŠĪįåūååđķåĶäļïž
åūįĪšïžæ
éåŪä―æĨéŠĪæąæŧ
Â
æ
éåŪä―æŊäļäļŠčūåĪæåéčĶįŧéŠįčŋįĻïžåĶæį°åĻæ
éæĢåĻåįïžåŊđäšåæįŧéŠäļåūåĪįåžåæčŋįŧīäššåïžæäŧäđįŪåįæä―æĨéŠĪčŪ°å―äļéčĶįäŋĄæŊåïžäļéĒæäūäļäļŠ
Â
å
ãįŧčŋįŧīäššåįįŪåæĨéŠĪ
åĶæäšåįŠįķäļäļč―įįį°åšåĪŠäđ
ïžčĶæąčŋįŧīäššåïžÂ
1. top: čŪ°å―cpu idle%ãåĶæåį°cpuå įĻčŋéŦïžåc, shift+h, shift + pæĨįįšŋįĻå įĻCPUæ
åĩïžåđķčŪ°å―
2. free: æĨįå
åæ
åĩïžåĶæåĐä―éčūå°ïžåtopäļshift+mæĨįå
åå įĻæ
åĩïžåđķčŪ°å―
3. åĶætopäļåį°å įĻčĩæščūåĪįčŋįĻåį§°ïžäūåĶjavačŋæ ·įéįĻåį§°ïžäļåĪŠč―čŊīæčŋįĻčšŦäŧ―ïžåčĶįĻps xuf | grep javaįæđåžčŪ°å―äļå
·ä―čŋįĻįčšŦäŧ―Â
4. åjstackįŧæãååĶåäļå°ïžå°čŊå /F
 jstackå―äŧĪïžÂ jstack PID > jstack.log
5. jstatæĨįOLDåšå įĻįãåĶæå įĻįå°čūūææĨčŋ100%ïžåjmapåįŧæãååĶåäļå°ïžå°čŊå /FÂ
 jstatå―äŧĪïžÂ  jstat -gcutil PID
  S0  S1   E    O   P   YGC   YGCT   FGC  FGCT  GCT
  0.00 21.35 88.01 97.35 59.89 111461 1904.894 1458 291.369 2196.263
 jmapå―äŧĪïžÂ  jmap -dump:file=dump.map PID
6. éåŊæåĄ
Â
äļãåččĩæ








įļå ģæĻč
æŽææŧįŧäšæåĻå·Ĩä―čŋįĻäļįįŧéŠïžæĻåĻæäūäļåĨįļåŊđæč§åūįéŪéĒåŪä―åĪįæĻĄåžïžäŧĨåļŪåĐåĪ§åŪķåĻææĨéŪéĒįčŋįĻäļčįæķéīååŋŦéæūå°éŪéĒįå ģéŪįđã äšč§Ģįģŧįŧįį°čąĄåšåäļšâįģŧįŧéŪéĒâ åĻåĪ§åįĩåį―įŦäļïžæäļŠæåĄį ...
- **æĨåŋåŪĄčŪĄ**ïžčŪ°å―å ģéŪæä―įæĨåŋïžäūŋäščŋ―čļŠåžåļļčĄäļšåæ éææĨã #### æŧįŧ įŧžäļæčŋ°ïžâįšŋäļčū åŊžįįģŧįŧâäļäŧ å ·åĪäļ°åŊįåč―įđæ§ïžčŋč―æææåæåĶčĩæšįįŪĄįæįïžäļšįĻæ·æäūäūŋæ·įåĶäđ ä―éŠãéčŋåŊđ...
- **åĪįæšåķ**: åŪæåŊđįšŋäļéŪéĒčŋčĄåĪįïžæŧįŧįŧéŠæčŪïžéŋå åæ ·įéŪéĒåæŽĄåįã įŧžäļæčŋ°ïžéčŋäļčŋ°įææŊæ ååŪč·ĩįŧéŠåäšŦïžæäŧŽåŊäŧĨæåŧšäļäļŠįĻģåŪãéŦæäļåŊæĐåąįååļåžįģŧįŧïžåæķäđč―éčŋææįåĒéåä―å...
- JavaįžįĻåšįĄïžææĄJavačŊčĻįæ ļåŋæĶåŋĩïžå æŽéĒååŊđ蹥įžįĻãåžåļļåĪįãåĪįšŋįĻãI/Oæĩįã - åžåå·Ĩå ·ïžįæIDEåĶEclipseæIntelliJ IDEAïžįæŽæ§åķå·Ĩå ·åĶGitïžæåŧšå·Ĩå ·åĶMavenæGradleã - æĩčŊæč―ïžäšč§Ģåå ...
- æŊåĻæŧįŧæŽåĻéå°įįšŋäļåŪĒæ·éŪéĒïžåäšŦææĨæč·Ŋãč§ĢåģæđæĄäŧĨååæåĶä―č§éŋã - ååĒéåŧšįŦå ąäšŦįĨčŊåšïžåŊäūå ķäŧåĒéæååĶäđ ææŊįŧéŠïžæåææŊč―åã éčŋčŋäšåŪč·ĩįŧéŠįåäšŦïžäļäŧ č―åĪåļŪåĐåĒéæåæéŦå·Ĩä―...
- **æ éč―Žį§ŧïž** å―äļŧčįđåįæ éæķïžKeepalivedäžčŠåĻå°æĩéåæĒå°åĪįĻčįđïžäŋčŊæåĄįčŋįŧæ§ã #### äļãåĒéåä―įŧéŠåäšŦ éĪäšææŊåąéĒįäŧįŧïžãJAVAéįžįķéĐåäšŦįŽŽäšįãčŋåäšŦäšäļäšåĒéåä―įįŧéŠã *...
- čĩæ·ą/äļåŪķïžå ·åĪäļ°åŊįįšŋäļæ éåĪįįŧéŠïžč―åĪéĒč§åđķéŋå æ―åĻéĢéĐã 3. **æđčŋæģæģ** - **čæ ļįđ**ïžå ·åĪäļŧåĻæčįäđ æŊïžč―åĪåĻæĨåļļå·Ĩä―äļåį°éŪéĒåđķæåšæđčŋåŧščŪŪã - **čæ ļåšå**ïž - åįš§ïžč―åĪåĻæåŊžäļ...
- **åžåļļåĪįæšåķ**ïžéčŋåŊđåŊč―åšį°įåį§åžåļļæ åĩčŋčĄåĶĨååĪįïžæéŦįģŧįŧįįĻģåŪæ§ååŪå Ļæ§ã - **æ°æŪéŠčŊ**ïžåĻįĻæ·čūå Ĩæ°æŪæķčŋčĄæææ§éŠčŊïžéēæĒéæģææ ææ°æŪčŋå ĨįģŧįŧïžįĄŪäŋæ°æŪįåįĄŪæ§ååŪå Ļæ§ã - **æ§č―...
1. **įšŋäļéŪéĒæŧįŧ**ïžæŊåĻæŧįŧæŽåĻéå°įįšŋäļåŪĒæ·éŪéĒïžåäšŦææĨæč·Ŋãč§ĢåģæđæĄäŧĨååįŧéŋå įæđæģãå ķäŧåäšåæŽĄéå°æĪįąŧéŪéĒæķåŊäŧĨåŋŦéåŪä―åææĨãæŧįŧåŪæåïžæĩčŊåĒéæ đæŪčŋäšéŪéĒåšæŊæīæ°æĩčŊįĻäūïžåžååĒé...
#### ä―ŋįĻâéæĨæéĪâįæđæģåŪä―JavaæåĄįšŋäļâįģŧįŧæ§âæ é - **æđæģčŪš**ïžéįĻâéæĨæéĪæģâčŊæįšŋäļæåĄäļįįģŧįŧæ§æ éïžéčŋéåąææĨåŪä―éŪéĒæåĻã - **æĨéŠĪ**ïžäŧį―įŧčŋæĨãæåĄåĻįĄŽäŧķãæä―įģŧįŧé į―ŪãåšįĻ...
- įšŋäļæ éïžéčŋåūŪæåĄåïžč―æīåŋŦéå°åŪä―ååĪįæ éã - į åæįïžåūŪæåĄåäŋčŋäšåĒéįéŦæåä―ååŋŦéčŋäŧĢã - æ°īåđģæĐåąč―åïžéčŋåūŪæåĄæķææīåŪđæåŪį°æåĄįæ°īåđģæĐåąã 3. ææŊæ åįš§ïž - åžå ĨSpring ...
8. **äļįšŋäļčŋįŧī**ïžįģŧįŧäļįšŋåïžéčĶæįŧįæ§įģŧįŧæ§č―ïžåŪæåĪäŧ―æ°æŪïžåĪįįšŋäļæ éïžåđķæ đæŪįĻæ·åéĶčŋčĄčŋäŧĢåįš§ã 9. **įĻæ·ä―éŠäžå**ïžéčŋįĻæ·åéĶåæ°æŪåæïžäžåįéĒčŪūčŪĄïžæéŦæä―æĩį æ§ïžæåįĻæ·æŧĄæåšĶ...
JavaäŧĨå ķč·Ļåđģå°ãįĻģåŪæ§ååžšåĪ§įäžäļįš§åšįĻæŊæïžåļŪåĐæ·åŪæåŧšäšæīįĻģåšįåšįĄãčŋäļæķæįč―Žåïžä―ŋæ·åŪč―åĪåšåŊđæīéŦåđķåéįčŪŋéŪïžäļšåįŧįäļåĄæĐåąæäļäšååŪåšįĄã åãJavaæķäŧĢïžåčĨįĢįģ åĻJavaåđģå°įäļæäžå...
äšæååäšĪæåđģå°æŊčŋåđīæĨéįį―įŧčīįĐå īčĩ·įæ°ååäļæĻĄåžïžåŪäļšäđ°ååæđæäūäšäļäļŠäūŋæ·įįšŋäļäšĪæįŊåĒïžå°Īå ķéåéĢäšåŊđäŧ·æ žææãåŊŧæąéŦæ§äŧ·æŊååįæķčīđč ãSSMæŊäļčŪūčŪĄïžåģæåšäšSpringãSpringMVCåMyBatisį...
Spring BootįŪåäšSpringåšįĻįåå§æåŧšäŧĨååžåčŋįĻïžåŪéĒčŪūäšäļįŧéŧčŪĪé į―ŪïžčŪĐåžåč č―åĪåŋŦéååŧšįŽįŦčŋčĄįãį䚧įš§åŦįJavaåšįĻã äļãéæąåæ 1. åč―éæąïž - įĻæ·æģĻåäļįŧå―ïžæäūæ°įĻæ·æģĻååå·ēæįĻæ·...
3.11.1 čŊ·æąč§ĢæåäļåĄåĪįįšŋįĻæą åįĶŧ 57 3.11.2 äļåĄįšŋįĻæą éįĶŧ 58 3.11.3 äļåĄįšŋįĻæą įæ§/čŋįŧī/éįš§ 58 3.11.4 åĶä―ä―ŋįĻServlet 3åžæĨå 59 3.11.5 äļäšServlet 3åžæĨååæĩæ°æŪ 64 4 éæĩčŊĶč§Ģ 66 4.1 éæĩįŪæģ 67...
čŋäļčŋįĻäļïžæķæįæ ļåŋå ģæģĻįđåĻäšč§ĢčĶæåãæåæč―åįģŧįŧįĻģåŪæ§ïžäŧĨåäŧ.Netč―ŽåJavaïžåđķå°æ°æŪåšäŧSqlServerč―ŽæĒäļšMySqlãčŋį§č―ŽåæĻåĻåšåŊđåäļįš§įĻæ·įéŦæĩééæąïžäŧĨåäļįūäļŠåūŪæåĄååšåĪ§įį ååĒéåļĶæĨįåĪæ...
**æąčĨŋåūŪč―ŊåŪčŪčŊæįģŧįŧ**æŊäļéĄđæĻåĻæåæčēäŋĄæŊåįŪĄįæ°īåđģįéčĶéĄđįŪïžå ķæ ļåŋåč―åĻäšåŪį°įšŋäļæåĶčŊäž°ïžäŧčįŪåäž įŧįįšļčīĻčŊææĩįĻïžæéŦčŊææ°æŪįåįĄŪæ§ååæķæ§ã #### äšãæ°æŪåščŪūčŪĄ 1. **æ°æŪåšåŪäđ**ïž...