huangxx
- 浏览: 325607 次
- 来自: ...
-

最新评论
-
梦回秘蓝:
whichisnotuse 写道非也, 除非需要很执行一段代码 ...
什么情况需要 if (log.isDebugEnabled()) {} -
wupy:
一直while的话会不会太耗内存呢?
java socket 长连接 短连接 -
xy2401:
<type-mapping> <sql-t ...
hibernate tools oracle nvarchar2 被映射成Serializable -
xy2401:
xy2401 写道额,原来配置文件可以改啊。。。不过我已经生成 ...
hibernate tools oracle nvarchar2 被映射成Serializable -
郭玉成:
你好, 我已经找到原因了!
java 编译非文本形式的文件
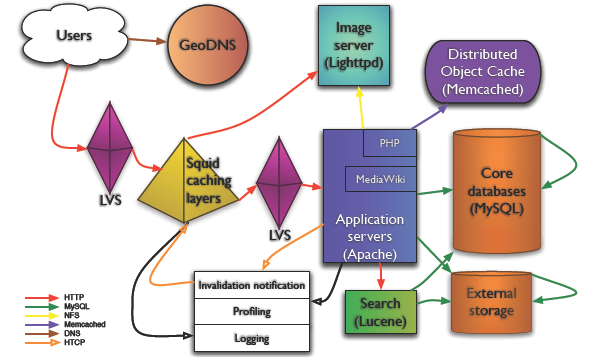 Copy @Mark Bergsma
Copy @Mark Bergsma


{kind=link}
相关推荐
524MB中文维基百科语料链接:https://huggingface.co/datasets/pleisto/wikipedia-cn-20230720-filtered 参考这个博客链接进行使用:...
这些文件是针对人工智能和深度学习领域研究的数据集,特别是与社交网络分析和自然语言处理相关的。数据集在科研中扮演着至关重要的角色,因为它们帮助研究人员验证算法、模型和理论,推动科技进步。以下是对这些文件...
在标签中,“人工智能”和“深度学习”是现代技术的核心领域,它们已经广泛应用于自然语言处理、计算机视觉、推荐系统等多个场景。而“数据集”是这些领域研究的基础,一个高质量的数据集可以极大地推动模型的性能。...
对于`wikipedia_histories-1.0.0-py3-none-any.whl`,`py3`表示它兼容Python 3版本,`none`代表这个包没有特定于任何平台的构建,`any`则表明它可以运行在任何CPU架构上。 `wikipedia_histories`库的核心功能在于与...
wikipedia-tools-for-google-spreadsheets, 用于Google电子表格—文档的维基百科工具 用于Google电子表格的维基百科工具Google电子表格 add-on makes working Wikipedia Wikipedia Wikipedia Wikipedia Wikipedia ...
资源来自pypi官网。 资源全名:wikipedia_histories-0.0.4-py3-none-any.whl
《Python库wikipedia_histories-0.0.4-py3-none-any.whl深度解析》 在Python的世界里,库是开发者的重要工具,它们提供了丰富的功能,极大地简化了编程工作。今天我们要关注的是一个名为“wikipedia_histories”的...
JWPL DataMachine jar
资源分类:Python库 所属语言:Python 资源全名:wikipedia_for_humans-0.2.1.tar.gz 资源来源:官方 安装方法:https://lanzao.blog.csdn.net/article/details/101784059
深度学习在处理大规模数据时,往往需要大量的计算资源和复杂的模型架构。对于“ml_wikipedia.csv”,我们可以使用预训练的词嵌入模型(如Word2Vec或BERT)来初始化文章内容的向量表示,然后通过GNN进一步学习和优化...
《基于Python的Wikipedia-Named-Entity-Recognition:在Heroku上的实现与应用》 在当前的自然语言处理(NLP)领域,命名实体识别(NER)是一项关键任务,它涉及从文本中提取出具有特定意义的实体,如人名、地名、...
jar包,官方版本,自测可用
jar包,官方版本,自测可用
jar包,官方版本,自测可用
jar包,官方版本,自测可用
jar包,官方版本,自测可用
jar包,官方版本,自测可用
jar包,官方版本,自测可用
jar包,官方版本,自测可用