- وµڈ览: 367325 و¬،
- و€§هˆ«:

- و¥è‡ھ: è‹ڈه·
-

و–‡ç« هˆ†ç±»
社هŒ؛版ه—
- وˆ‘çڑ„资讯 ( 2)
- وˆ‘çڑ„è®؛ه› ( 19)
- وˆ‘çڑ„é—®ç” ( 0)
هکو،£هˆ†ç±»
- 2011-12 ( 2)
- 2011-11 ( 2)
- 2011-10 ( 4)
- و›´ه¤ڑهکو،£...
وœ€و–°è¯„è®؛
-
hqmanï¼ڑ
export LD_PRELOAD=/lib/libpam.s ...
OpenVPN 详细é…چç½® -
wutao8818ï¼ڑ
ه‘µه‘µï¼Œو ‡é¢کوŒ؛ه¥½ï¼Œه†…ه®¹و²،看
说è¯ه‰چن½ وک¯è¯çڑ„ن¸»ن؛؛,说è¯هگژن½ وک¯è¯çڑ„ن»†ن؛؛ -
wutao8818ï¼ڑ
é¢ï¼Œن½ 需è¦پçڑ„ه°±وک¯è®¤ه‡†ن¸€ن»¶ن؛‹م€‚ن½†è¯´èµ·و¥ç®€هچ•ï¼Œه¯¹وںگن؛›ن؛؛و¥è¯´è؟™ه¾ˆéڑ¾ï¼Œ ...
وˆ‘ه¾ˆوµ®è؛پ -
damoqiongqiuï¼ڑ
هڈ¯وƒœه›¾ç‰‡ن¸€ن¸ھ都و²،وœ‰ن؛†م€‚
amfوک¯ن»€ن¹ˆن¸œن¸œ -
fzfx88ï¼ڑ
貌ن¼¼Apache + tomcate هڈ¯ن»¥è§£ه†³
解ه†³dwrè·¨هںںé—®é¢ک
هژں链وژ¥
Uncover the hood of J2EE Clustering
1 ه‰چ言
è¶ٹو¥è¶ٹه¤ڑçڑ„ه…³é”®ن»»هٹ،ه’Œه¤§ه‹ه؛”用و£è؟گè،Œهœ¨J2EEه¹³هڈ°ن¸ٹ,è±،银è،Œن¹‹ç±»çڑ„ه؛”用è¦پو±‚ه¾ˆé«کçڑ„هڈ¯ç”¨و€§(HA),ه¤§ه‹ç³»ç»ںو¯”ه¦‚googleه’ŒYahooهˆ™è¦پو±‚و›´ه¥½çڑ„ن¼¸ 缩و€§م€‚ن»ٹه¤©é«کهڈ¯ç”¨و€§ه’Œن¼¸ç¼©و€§çڑ„é‡چè¦پو€§ه¯¹ن؛ژن؛’èپ”ن¸–ç•Œو—¥ç›ٹه¢é•؟,وœ€è‘—هگچçڑ„è¯پوکژوک¯1999ه¹´eBayن¸و–ن؛†22ه°ڈو—¶çڑ„وœچهٹ،,هژںه› وک¯è¶…è؟‡230ن¸‡و¬،çڑ„و‹چهچ–,وœ€ç»ˆه¯¼ 致eBayè‚،票ن¸‹è·Œن؛†9.2ن¸ھ百هˆ†ç‚¹م€‚
J2EE集群وک¯وœ€ه¸¸ç”¨çڑ„وٹ€وœ¯ï¼Œç”¨و¥وڈگن¾›é«کهڈ¯ç”¨و€§ه’Œن¼¸ç¼©و€§çڑ„ه®¹é”™وœچهٹ،م€‚ن½†ç”±ن؛ژç¼؛ن¹ڈJ2EE规范çڑ„و”¯وŒپ,J2EEوڈگن¾›هژ‚ه•†ه®çژ°çڑ„集群ه°½ن¸چ相هگŒï¼Œه¼•èµ·è®¸ه¤ڑJ2EEو¶و„ه¸ˆه’Œه¼€هڈ‘者çڑ„é؛»çƒ¦ï¼Œو¯”ه¦‚ن¸‹é¢ï¼ڑ
1. ن¸؛ن»€ن¹ˆé™„ه¸¦é›†ç¾¤èƒ½هٹ›çڑ„ه•†ن¸ڑJ2EEوœچهٹ،ه™¨ه¦‚و¤وک‚è´µï¼ں(و¯”ن¸چه¸¦é›†ç¾¤èƒ½هٹ›çڑ„è´µ10ه€چ)
2. ن¸؛ن»€ن¹ˆوˆ‘هœ¨هچ•وœ؛ن¸ٹهˆ›ه»؛çڑ„ه؛”用و— و³•è؟گè،Œهœ¨é›†ç¾¤و¨،ه¼ڈï¼ں
3. ن¸؛ن»€ن¹ˆوˆ‘çڑ„ه؛”用هœ¨é›†ç¾¤و—¶è؟گè،Œç¼“و…¢ن½†ن¸چ集群و—¶هچ´ه¾ˆه؟«é€ںï¼ں
4. ن¸؛ن»€ن¹ˆوˆ‘çڑ„集群ه؛”用ن¸چ能ن¸ژه…¶ن»–وڈگن¾›ه•†çڑ„وœچهٹ،ه™¨é€ڑن؟،ï¼ں
2 هں؛وœ¬وœ¯è¯
讨è®؛ن¸چهگŒه®çژ°ن¹‹ه‰چ,çگ†è§£é›†ç¾¤وٹ€وœ¯çڑ„و¦‚ه؟µوک¯ه¾ˆوœ‰و„ڈن¹‰çڑ„,وˆ‘ه¸Œوœ›ن¸چن»…能给ن½ وڈگن¾›ه…³ن؛ژJ2EE集群ن؛§ه“پهں؛وœ¬çڑ„设è®،çگ†ه؟µه’Œو¦‚ه؟µï¼Œè؟کهڈ¯ن»¥و¦‚و‹¬و€§çڑ„وڈڈç»کن¸چهگŒçڑ„集群ه®çژ°ï¼Œن½؟ه®ƒن»¬و›´ه®¹وک“被çگ†è§£م€‚
2.1 ن¼¸ç¼©و€§(Scalability)
ه¤§ه‹ç³»ç»ںه¾ˆéڑ¾é¢„وµ‹ç»ˆç«¯ç”¨وˆ·çڑ„و•°é‡ڈن¸ژè،Œن¸؛,ن¼¸ç¼©و€§وک¯وŒ‡ç³»ç»ںهڈ¯ن»¥و”¯وŒپ用وˆ·çڑ„ه؟«é€ںه¢é•؟م€‚وڈگé«کوœچهٹ،ه™¨هگŒو—¶ه¤„çگ†ه¹¶هڈ‘ن¼ڑè¯çڑ„وœ€ç›´è§‰çڑ„و–¹ه¼ڈه°±وک¯ه¢هٹ وœچهٹ،ه™¨èµ„و؛گ(ه†…هک, CPU,وˆ–ç،¬ç›ک),集群وک¯è§£ه†³ن¼¸ç¼©و€§çڑ„هڈ¦ن¸€ç§چهڈ¯é€‰و–¹ه¼ڈم€‚ه®ƒه…پ许ن¸€ç»„وœچهٹ،ه™¨هˆ†و‹…ه¤„çگ†ç¹پé‡چçڑ„ن»»هٹ،,而逻辑ن¸ٹه°±è±،ن¸€هڈ°وœچهٹ،ه™¨ن¸€و ·م€‚
2.2 é«کهڈ¯ç”¨و€§(High Availability)
وڈگé«کن¼¸ç¼©و€§çڑ„هچ•وœچهٹ،ه™¨è§£ه†³و–¹و،ˆ(و·»هٹ ه†…هکه’ŒCPU)وک¯ه¹¶ن¸چه¼؛ه£®çڑ„هٹو³•ï¼Œه› ن¸؛هچ•ç‚¹ه¤±و•ˆهژںه› م€‚ه…³é”®ن»»هٹ،ه؛”用ن¸چ能ه®¹ه؟چوœچهٹ،ن¸و–ه“ھو€•ن¸€هˆ†é’ںم€‚ه®ƒè¦پو±‚ن»»ن½•و—¶ه€™éƒ½هڈ¯ن»¥هگˆçگ†هœ°هڈ¯é¢„وœںçڑ„ه“چه؛”و—¶é—´è®؟é—®è؟™ن؛›وœچهٹ،,集群هڈ¯ن»¥é€ڑè؟‡وڈگن¾›é¢ه¤–çڑ„وœچهٹ،ه™¨ن½؟ه…¶هœ¨ن¸€هڈ°وœچهٹ،ه™¨ه®و•ˆو—¶وڈگن¾›وœچهٹ،,ن»ژ而وڈگé«کهڈ¯ç”¨و€§م€‚
2.3 è´ںè½½ه‡è،،(Load balancing)
è´ںè½½ه‡è،،وک¯é›†ç¾¤وٹ€وœ¯ن¹‹هگژçڑ„ن¸€ن¸ھه…³é”®وٹ€وœ¯ï¼Œé€ڑè؟‡هˆ†هڈ‘请و±‚هˆ°ن¸چهگŒçڑ„وœچهٹ،ه™¨و¥وڈگé«کهڈ¯ç”¨و€§ه’Œو›´ه¥½çڑ„و€§èƒ½م€‚è´ںè½½ه‡è،،ه™¨هڈ¯ن»¥وک¯ن¸€ن¸ھServletوˆ–وڈ’ن»¶(ن¾‹ه¦‚a linux box using ipchains),除هˆ†هڈ‘请و±‚ن¹‹ه¤–,è´ںè½½ه‡è،،ه™¨ه؛”è´ںè´£ه…¶ن»–ن¸€ن؛›é‡چè¦پçڑ„ن»»هٹ،,ن¾‹ه¦‚“ن¼ڑè¯é»ڈ附â€ï¼Œن½؟ه¾—وںگن¸ھ用وˆ·ن¼ڑè¯ه§‹ç»ˆهœ¨ن¸€هڈ°وœچهٹ،ه™¨ن¸ٹهکو´»ï¼Œè؟کوœ‰â€œه؟ƒè·³و£€ وµ‹â€ï¼Œéک²و¢هˆ†هڈ‘请و±‚هˆ°ه¤±و•ˆçڑ„وœچهٹ،ه™¨م€‚وœ‰و—¶ه€™è´ںè½½ه‡è،،ه™¨ن¹ںهڈ‚ن¸ژهˆ°â€œه¤±و•ˆè½¬ç§»â€ه¤„çگ†م€‚
2.4 ه®¹é”™(Fault Tolerance)
é«کهڈ¯ç”¨و€§و•°وچ®ن¸چه؟…وک¯ن¸¥و ¼و£ç،®و•°وچ®.هœ¨J2EE集群ن¸ï¼Œه½“ن¸€ن¸ھوœچهٹ،ه™¨ه®ن¾‹ه¤±و•ˆو—¶ï¼Œوœچهٹ،ن»چ然هڈ¯ç”¨ï¼Œه› ن¸؛و–°çڑ„请و±‚هڈ¯ç”±ه…¶ن»–ه†—ن½™çڑ„وœچهٹ،ه™¨ه®ن¾‹ه¤„çگ†م€‚ن½†ه¦‚وœè¯·و±‚و£هœ¨ه¤„çگ†ه½“ن¸و—¶وœچهٹ،ه™¨ه®ن¾‹ه¤±و•ˆï¼Œهˆ™ن¸چ能能ه¾—هˆ°و£ç،®çڑ„و•°وچ®م€‚然而ه®¹é”™وœچهٹ،هˆ™و€»وک¯ن؟è¯پن¸¥و ¼و£ç،®çڑ„è،Œن¸؛م€‚
2.5 ه¤±و•ˆè½¬ç§»(Failover)
ه¤±و•ˆè½¬ç§»وک¯هڈ¦ن¸€é،¹ن½؟ه¾—集群ه®çژ°ه®¹é”™çڑ„ه…³é”®وٹ€وœ¯م€‚é€ڑè؟‡é€‰و‹©é›†ç¾¤ن¸هڈ¦ن¸€ن¸ھèٹ‚点,هژںه§‹èٹ‚点ه¤±و•ˆو—¶ه¤„çگ†ه°†ç»§ç»ن¸‹هژ»م€‚ه¤±و•ˆè½¬ç§»هڈ¯ن»¥وک¾ه¼ڈهœ°ç¼–ç پن¹ںهڈ¯ن»¥ç”±ن½ژه±‚ه¹³هڈ°è‡ھهٹ¨و‰§è،Œم€‚
2.6 ç‰ه¹‚و–¹و³•(Idempotent methods)
هڈ¯ن»¥ç”¨ç›¸هگŒçڑ„هڈ‚و•°é‡چه¤چ调用çڑ„و–¹و³•ï¼Œه¹¶ن¸”و€»وک¯ه¾—هˆ°ç›¸هگŒçڑ„结وœم€‚è؟™ن؛›و–¹و³•ن¸چه؛”该ه½±ه“چç³»ç»ںçٹ¶و€پ,هڈ¯ن»¥è¢«é‡چه¤چهœ°è°ƒç”¨è€Œن¸چه؟…و‹…ه؟ƒو”¹هڈکç³»ç»ںم€‚ن¾‹ه¦‚, “getUsername()†وک¯ç‰ه¹‚و–¹و³•ï¼Œè€Œâ€œdeleteFile()†ه°±ن¸چوک¯ç‰ه¹‚و–¹و³•م€‚ç‰ه¹‚وک¯HTTPن¼ڑè¯ه’ŒEJBه¤±و•ˆè½¬ç§»çڑ„é‡چè¦پو¦‚ه؟µم€‚
3 J2EE集群وک¯ن»€ن¹ˆï¼ں
ن¸€ن¸ھه¹¼ç¨ڑçڑ„é—®é¢ک,ن¸چوک¯هگ—ï¼ںن½†وˆ‘ن»چ然用ن¸€ن؛›è¯è¯ه’Œه›¾è،¨و¥ه›ç”ه®ƒم€‚é€ڑه¸¸J2EE集群وٹ€وœ¯هŒ…و‹¬â€œè´ںè½½ه‡è،،â€ه’Œâ€œه¤±و•ˆè½¬ç§»â€م€‚
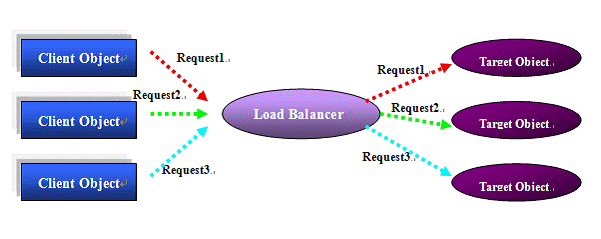
ه›¾1 è´ںè½½ه‡è،،
ه¦‚ه›¾1و‰€ç¤؛,وœ‰ه¾ˆه¤ڑه®¢وˆ·ç«¯ه¯¹è±،ه¹¶هڈ‘هڈ‘é€پ请و±‚هˆ°ç›®و ‡ه¯¹è±،م€‚è´ںè½½ه‡è،،ه™¨هˆ™ن½چن؛ژ调用者ه’Œè¢«è°ƒç”¨è€…ن¹‹é—´ï¼Œهˆ†هڈ‘请و±‚هˆ°ه†—ن½™çڑ„و‹¥وœ‰هگŒو ·هٹں能çڑ„ه¯¹è±،ن¸ٹم€‚用و¤و–¹و³•هڈ¯ن»¥ه®çژ°é«کهڈ¯ç”¨و€§ه’Œé«کو€§èƒ½م€‚
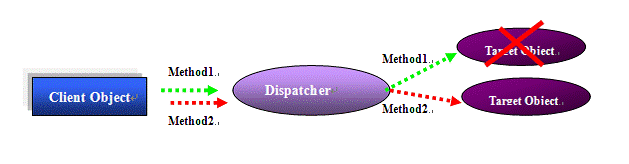
ه›¾2ï¼ڑه¤±و•ˆè½¬ç§»
ه¦‚ه›¾2و‰€ç¤؛,ه¤±و•ˆè½¬ç§»ن¸ژè´ںè½½ه‡è،،ن¸چهگŒم€‚وœ‰و—¶ه€™ï¼Œه®¢وˆ·ç«¯ه¯¹è±،ه¯¹ç›®و ‡ه¯¹è±،هڈ‘èµ·è؟ç»çڑ„و–¹و³•è¯·و±‚م€‚ه¦‚وœç›®و ‡ه¯¹è±،هœ¨è¯·و±‚ن¹‹é—´ه¤±و•ˆï¼Œه¤±و•ˆè½¬ç§»ç³»ç»ںه؛”该و£€وµ‹هˆ°ه¹¶ه°†هگژç»è¯·و±‚转هگ‘ه¯¼هڈ¦ن¸€ن¸ھهڈ¯ç”¨çڑ„ه¯¹è±،,ه®¹é”™ن¹ںهڈ¯ç”¨و¤é€”ه¾„ه®çژ°م€‚
ه¦‚وœوƒ³ن؛†è§£و›´ه¤ڑJ2EE集群,ن½ ه؛”该问و›´ه¤ڑçڑ„هں؛وœ¬é—®é¢ک,ن¾‹ه¦‚ï¼ڑ“ن»€ن¹ˆç±»ه‹çڑ„ه¯¹è±،هڈ¯ن»¥è¢«é›†ç¾¤ï¼ںâ€ï¼Œâ€œهœ¨وˆ‘çڑ„J2EEن»£ç پن¸ن»€ن¹ˆهœ°و–¹ه‡؛çژ°è´ںè½½ه‡è،،ه’Œه¤±و•ˆè½¬ 移ï¼ںâ€ï¼Œه¯¹ن؛ژçگ†è§£J2EE集群çڑ„هژںçگ†ï¼Œè؟™ن؛›éƒ½وک¯éه¸¸ه¥½çڑ„é—®é¢کم€‚ه®é™…ن¸ٹ,ن¸چوک¯و‰€وœ‰ه¯¹è±،هڈ¯ن»¥è¢«é›†ç¾¤ï¼Œن¹ںن¸چوک¯ن»»ن½•هœ°و–¹éƒ½هڈ¯ن»¥è´ںè½½ه‡è،،ه’Œه¤±و•ˆè½¬ç§»ï¼پ看看ن¸‹هˆ—ن»£ç پï¼ڑ

ه›¾3ï¼ڑن»£ç پن¾‹هگ
ه½““instance1â€ه¤±و•ˆو—¶ï¼Œâ€œClass Aâ€çڑ„“business()â€و–¹و³•ن¼ڑè´ںè½½ه‡è،،ه’Œه¤±و•ˆè½¬ç§»هˆ°هڈ¦ن¸€ن¸ھBه®ن¾‹هگ—ï¼ںن¸چ,ن¸چن¼ڑم€‚ه¯¹ن؛ژè´ںè½½ه‡è،،ه’Œه¤±و•ˆè½¬ç§»ï¼Œه؟…é،»è¦پهœ¨è°ƒç”¨è€…ه’Œè¢«è°ƒç”¨è€…ن¹‹é—´هکهœ¨ن¸€ن¸ھو‹¦ وˆھه™¨ï¼Œç”¨و¥هˆ†هڈ‘وˆ–者转هگ‘و–¹و³•è°ƒç”¨هˆ°ن¸چهگŒçڑ„ه¯¹è±،ن¸ٹم€‚Aه’ŒBçڑ„ه®ن¾‹ه¯¹è±،è؟گè،Œهœ¨هگŒن¸€ن¸ھJVMن¸ٹ,ه¹¶ç´§ه¯†è€¦هگˆم€‚ه¾ˆéڑ¾هœ¨و–¹و³•è°ƒç”¨ن¹‹é—´و·»هٹ هˆ†هڈ‘逻辑م€‚
و‰€ن»¥ï¼Œن»€ن¹ˆç±»ه‹çڑ„ه¯¹è±،هڈ¯ن»¥è¢«é›†ç¾¤ï¼ں---هڈھوœ‰هڈ‘ه¸ƒهœ¨هˆ†ه¸ƒه¼ڈ结و„çڑ„ه¯¹è±،م€‚
و‰€ن»¥ï¼Œن»€ن¹ˆهœ°و–¹ن¼ڑهڈ‘ç”ںè´ںè½½ه‡è،،ه’Œه¤±و•ˆè½¬ç§»ه‘¢ï¼ں--هڈھوœ‰هœ¨è°ƒç”¨ن¸€ن¸ھهˆ†ه¸ƒه¼ڈه¯¹è±،çڑ„و–¹و³•و—¶م€‚
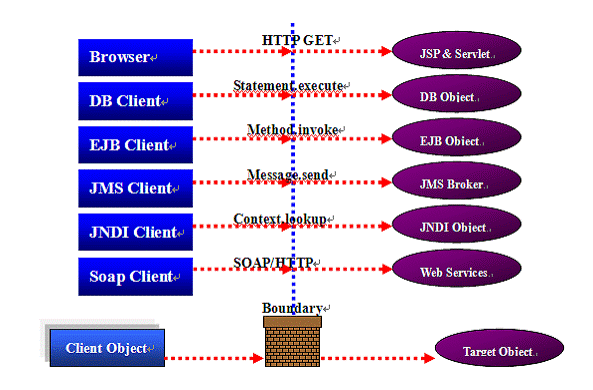
ه›¾4ï¼ڑهˆ†ه¸ƒه¼ڈه¯¹è±،
هœ¨هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒï¼Œه¦‚ه›¾4و‰€ç¤؛,调用者ه’Œè¢«è°ƒç”¨è€…被هˆ†ç¦»ن¸؛ن¸چهگŒè¾¹ç•Œçڑ„è؟گè،Œه®¹ه™¨ï¼Œè¾¹ç•Œوک¯JVM,è؟›ç¨‹وˆ–وœ؛ه™¨م€‚
ه½“ه®¢وˆ·ç«¯è°ƒç”¨ç›®و ‡ه¯¹è±،و—¶ï¼Œهœ¨ç›®و ‡ه¯¹è±،ه®¹ه™¨ه†…و‰§è،Œهٹں能م€‚ه®¢وˆ·ç«¯ه’Œç›®و ‡ه¯¹è±،é€ڑè؟‡و ‡ه‡†çڑ„网络هچڈè®®é€ڑن؟،م€‚هˆ©ç”¨è؟™ن؛›ç‰¹و€§و·»هٹ وœ؛هˆ¶هˆ°و–¹و³•è°ƒç”¨è·¯ç”±ن¸ï¼Œن»¥ه®çژ°è´ںè½½ه‡è،،ه’Œه¤±و•ˆè½¬ç§»م€‚
ه¦‚ه›¾4و‰€ç¤؛,وµڈ览ه™¨هڈ¯ن»¥é€ڑè؟‡HTTPهچڈ议调用è؟œç¨‹JSPه¯¹è±،م€‚JSPهœ¨Webوœچهٹ،ه™¨ن¸ٹو‰§è،Œï¼Œوµڈ览ه™¨ن¸چه…³ه؟ƒو‰§è،Œè؟‡ç¨‹ï¼Œه®ƒهڈھ需è¦پ结وœم€‚هœ¨è؟™و ·çڑ„هœ؛و™¯ن¸ï¼Œوœ‰ن؛›ن¸œ è¥؟هڈ¯ن»¥ن½چن؛ژوµڈ览ه™¨ه’Œwebوœچهٹ،ه™¨ن¹‹é—´ç”¨و¥ه®çژ°è´ںè½½ه‡è،،ه’Œه¤±و•ˆè½¬ç§»هٹں能م€‚هœ¨J2EEن¸ï¼Œهˆ†ه¸ƒه¼ڈوٹ€وœ¯هŒ…و‹¬ï¼ڑJSP(Servlet),JDBC ,EJB,JNDI,JMS,Webservicesه’Œه…¶ن»–م€‚ه½“هˆ†ه¸ƒه¼ڈو–¹و³•è¢«è°ƒç”¨و—¶هڈ¯ن»¥هڈ‘ç”ںè´ںè½½ه‡è،،ه’Œه¤±و•ˆè½¬ç§»م€‚ن¸‹é¢وˆ‘ن»¬ن¼ڑ讨è®؛细èٹ‚م€‚
4 webه±‚集群ه®çژ°
webه±‚集群وک¯J2EE集群ن¸وœ€é‡چè¦په’Œهں؛ç،€çڑ„هٹں能م€‚webه±‚集群وٹ€وœ¯هŒ…و‹¬ï¼ڑWebè´ںè½½ه‡è،،ه’ŒHTTPSessionه¤±و•ˆè½¬ç§»م€‚
4.1 webè´ںè½½ه‡è،،
J2EEوڈگن¾›ه•†وœ‰ه¾ˆه¤ڑو–¹و³•ه®çژ°webè´ںè½½ه‡è،،,هں؛وœ¬çڑ„,هœ¨وµڈ览ه™¨ه’Œwebوœچهٹ،ه™¨ن¹‹é—´و”¾ç½®è´ںè½½ه‡è،،ه™¨م€‚
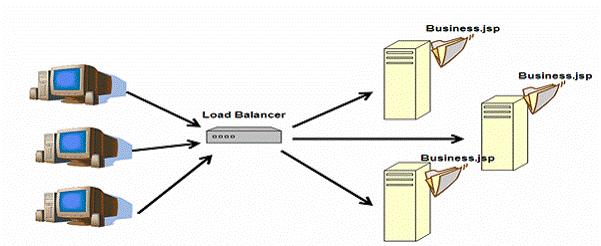
ه›¾5ï¼ڑwebè´ںè½½ه‡è،،
è´ںè½½ه‡è،،ه™¨هڈ¯ن»¥وک¯ç،¬ن»¶ن؛§ه“په¦‚F5 è´ںè½½ه‡è،،ه™¨ï¼Œن¹ںهڈ¯ن»¥وک¯هڈ¦ن¸€ن¸ھه¸¦وœ‰è´ںè½½ه‡è،،وڈ’ن»¶çڑ„webوœچهٹ،ه™¨م€‚简هچ•çڑ„ه¸¦وœ‰ipchainsçڑ„linux boxن¹ںهڈ¯ن»¥و‰§è،Œè´ںè½½ه‡è،،çڑ„هٹں能م€‚و— è®؛ن½•ç§چوٹ€وœ¯ï¼Œè´ںè½½ه‡è،،ه™¨é€ڑه¸¸وœ‰ن»¥ن¸‹ç‰¹و€§ï¼ڑ
*ه®çژ°è´ںè½½ه‡è،،ç®—و³•
ه½“ه®¢وˆ·ç«¯è¯·و±‚è¾¾هˆ°و—¶ï¼Œè´ںè½½ه‡è،،ه™¨ه†³ه®ڑه¦‚ن½•هˆ†هڈ‘请و±‚هˆ°هگژ端وœچهٹ،ه™¨ه®ن¾‹م€‚é€ڑه¸¸çڑ„ç®—و³•هŒ…و‹¬Round-Robin,(وŒ‡çڑ„وک¯ن½؟组ن¸و‰€وœ‰وˆگه‘ک都能ه‡ç‰هœ°ن»¥وںگç§چهگˆçگ† çڑ„é،؛ه؛ڈ被选و‹©هˆ°çڑ„ن¸€ç§چه®‰وژ’و–¹ه¼ڈ, é€ڑه¸¸وک¯ن»ژهˆ—è،¨çڑ„ه¤´è‡³ه°¾ï¼Œè€Œهگژه‘¨è€Œه¤چه§‹),éڑڈوœ؛ه’Œهں؛ن؛ژوƒé‡چم€‚ è´ںè½½ه‡è،،ه™¨è¯•ه›¾ن½؟و¯ڈن¸ھوœچهٹ،ه™¨ه®ن¾‹ه®Œوˆگ相هگŒçڑ„ه·¥ن½œé‡ڈ,ن½†ن»¥ن¸ٹç®—و³•éƒ½ن¸چ能çœںو£è¾¾هˆ°çگ†وƒ³çڑ„ç‰é‡ڈ,ه› ن¸؛ن»–ن»¬هڈھوک¯هں؛ن؛ژهˆ†هڈ‘هˆ°وںگن¸ھوœچهٹ،ه™¨ه®ن¾‹è¯·و±‚çڑ„و•°é‡ڈو¥è®،ç®—م€‚ن¸€ن؛›èپھ وکژçڑ„è´ںè½½ه‡è،،ه™¨ه®çژ°ç‰¹هˆ«çڑ„ç®—و³•ï¼Œن»–ن»¬ن¼ڑوµ‹è¯•و¯ڈن¸ھوœچهٹ،ه™¨çڑ„ه·¥ن½œè´ںè½½و¥ه†³ه®ڑهˆ†هڈ‘请و±‚م€‚
*ه؟ƒè·³و£€وµ‹
ه½“ن¸€ن؛›وœچهٹ،ه™¨ه®ن¾‹ه¤±و•ˆو—¶ï¼Œè´ںè½½ه‡è،،ه™¨ه؛”该و£€وµ‹هˆ°ه¤±و•ˆï¼Œه¹¶ن¸چه†چهˆ†هڈ‘请و±‚هˆ°ه¤±و•ˆçڑ„وœچهٹ،ه™¨ن¸ٹم€‚è´ںè½½ه‡è،،ه™¨ن¹ں需è¦پ监视وœچهٹ،ه™¨وپ¢ه¤چçٹ¶ه†µï¼Œه¹¶ç»™ه®ƒé‡چو–°هˆ†هڈ‘请و±‚م€‚
*ن¼ڑè¯ç²کè؟
ه‡ ن¹ژو¯ڈن¸ھwebه؛”用都وœ‰ن¼ڑè¯çٹ¶و€پ,ن½؟ه¾—è®°ن½ڈ用وˆ·وک¯هگ¦ç™»é™†وˆ–è´ç‰©è½¦هڈکه¾—éه¸¸ç®€هچ•م€‚ه› ن¸؛HTTPهچڈè®®وœ¬è؛«و²،وœ‰çٹ¶و€پ,ن¼ڑè¯çٹ¶و€پ需è¦پهکهœ¨وںگن¸ھهœ°و–¹ï¼Œه¹¶ه’Œوµڈ览ن¼ڑè¯ه…³ èپ”èµ·و¥ï¼Œهڈ¯ن»¥هœ¨ن¸‹ن¸€و¬،请و±‚و—¶ه¾ˆه®¹وک“هœ°è¢«و£€ç´¢هˆ°م€‚ه½“è´ںè½½ه‡è،،و—¶ï¼Œوœ€ه¥½é€‰و‹©هˆ†هڈ‘相هگŒçڑ„وµڈ览ه™¨ن¼ڑè¯è¯·و±‚هˆ°هگŒن¸€هڈ°وœچهٹ،ه™¨ه®ن¾‹ن¸ٹ,هگ¦هˆ™ه؛”用ه·¥ن½œن¼ڑن¸چو£ه¸¸م€‚
ه› ن¸؛ن¼ڑè¯çٹ¶و€پهکه‚¨هœ¨وںگن¸ھwebوœچهٹ،ه™¨ه®ن¾‹çڑ„ه†…هکن¸ï¼Œâ€œن¼ڑè¯ç²کè؟â€ه¯¹ن؛ژè´ںè½½ه‡è،،éه¸¸é‡چè¦پم€‚ن½†ï¼Œه¦‚وœن¸€هڈ°وœچهٹ،ه™¨ه®ن¾‹ه› ن¸؛وںگن؛›هژںه› ه¤±و•ˆï¼ˆو¯”ه¦‚و–电),那ن¹ˆè¯¥وœچهٹ، ه™¨ن¸ٹه¤ڑوœ‰çڑ„ن¼ڑè¯çٹ¶و€په°±ن¸¢ه¤±ن؛†م€‚è´ںè½½ه‡è،،ه™¨و£€وµ‹هˆ°ن؛†è¯¥ه¤±و•ˆï¼Œن¸چه†چهگ‘ه…¶هˆ†هڈ‘请و±‚م€‚ن½†هکه‚¨هœ¨ه¤±و•ˆوœچهٹ،ه™¨ن¸ٹçڑ„ن¼ڑè¯çڑ„é‚£ن؛›è¯·و±‚ه°†ن¸¢ه¤±ن¼ڑè¯ن؟،وپ¯ï¼Œè؟™ç§چوƒ…ه†µن¼ڑه¼•èµ·é”™è¯¯ï¼Œ ه› و¤ن¼ڑè¯ه¤±و•ˆè½¬ç§»هˆ°و¥ن؛†ï¼پ
4.2 HTTPSessionه¤±و•ˆè½¬ç§»
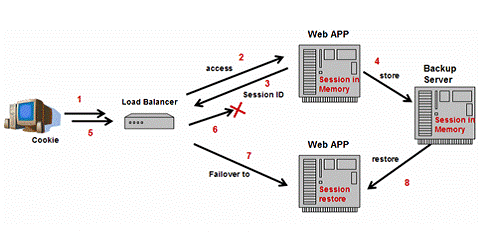
ه‡ ن¹ژو‰€وœ‰çڑ„وµپè،Œçڑ„J2EEوڈگن¾›ه•†éƒ½هœ¨ن»–ن»¬çڑ„集群ن؛§ه“پن¸ه®çژ°ن؛†HTTPSessionه¤±و•ˆè½¬ç§»ï¼Œç،®ن؟و‰€وœ‰çڑ„ه®¢وˆ·è¯·و±‚هڈ¯ن»¥ن¸چه› ن¸؛ن¸€ن؛›وœچهٹ،ه™¨ه®ن¾‹çڑ„ه¤±و•ˆè€Œن¸¢ه¤±ن»» ن½•ن¼ڑè¯çٹ¶و€پم€‚ه¦‚ه›¾6و‰€ç¤؛,ه½“وµڈ览ه™¨è®؟é—®ن¸€ن¸ھوœ‰çٹ¶و€پçڑ„webه؛”用(第1,2و¥ï¼‰ï¼Œو¤ه؛”用هڈ¯ن»¥هœ¨ه†…هکن¸هˆ›ه»؛ن¼ڑè¯ه¯¹è±،هکه‚¨ن؟،وپ¯ن»¥ه¤‡هگژ用م€‚هگŒو—¶ï¼Œهگ‘وµڈ览ه™¨é€په› HTTPSession ID,用و¥و ‡è®°è¯¥ن¼ڑè¯ه¯¹è±،(第3و¥ï¼‰م€‚وµڈ览ه™¨ن»¥cookieçڑ„و–¹ه¼ڈهکه‚¨è¯¥ID,ه¹¶ن¼ڑهœ¨ن¸‹و¬،هڈ‘起请و±‚و—¶é€په›webوœچهٹ،ه™¨م€‚ن¸؛ن؛†و”¯وŒپن¼ڑè¯ه¤±و•ˆè½¬ç§»ï¼Œن¼ڑè¯ه¯¹è±،ه°† هœ¨وںگو—¶وںگه¤„ه°†ه®ƒè‡ھه·±ه¤‡ن»½ï¼ˆç¬¬4و¥ï¼‰م€‚è´ںè½½ه‡è،،ه™¨هڈ¯ن»¥و£€وµ‹ه¤±و•ˆï¼ˆç¬¬5,6و¥ï¼‰ï¼Œهˆ†هڈ‘请و±‚هˆ°ه…¶ن»–وœچهٹ،ه™¨ه®ن¾‹ï¼ˆç¬¬7و¥ï¼‰م€‚ه› ن¸؛ن¼ڑè¯ه¯¹è±،ه·²ç»ڈ被ه¤‡ن»½ï¼Œو–°çڑ„webوœچ هٹ،ه™¨ه®ن¾‹هڈ¯ن»¥وپ¢ه¤چ该ن¼ڑè¯ه¹¶و£ç،®هœ°ه¤„çگ†è¯·و±‚م€‚
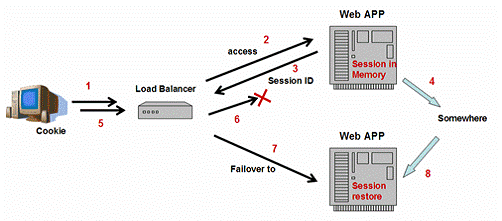
ه›¾6ï¼ڑHTTPSessionه¤±و•ˆè½¬ç§»
ن¸؛ن؛†ه®çژ°ن»¥ن¸ٹهٹں能,و³¨و„ڈن¸‹هˆ—é—®é¢کï¼ڑ
*ه…¨ه±€HTTPSession ID
ه¦‚ن¸ٹو‰€è؟°ï¼ŒHTTPSession ID用و¥و ‡è®°وںگن¸ھوœچهٹ،ه™¨ه®ن¾‹ه†…هکن¸çڑ„ن¼ڑè¯ه¯¹è±،م€‚هœ¨J2EEن¸ï¼ŒHTTPSession IDن¾èµ–ن؛ژJVMه®ن¾‹م€‚و¯ڈن¸ھJVMه®ن¾‹هڈ¯ن»¥وژ§هˆ¶ه¤ڑن¸ھwebه؛”用,و¯ڈن¸ھه؛”用هڈˆهڈ¯ن»¥وژ§هˆ¶è®¸ه¤ڑن¸چهگŒç”¨وˆ·çڑ„HTTPSession,HTTPSession IDوک¯هکهڈ–ه½“ه‰چJVMه®ن¾‹ن¸ç›¸ه…³ن¼ڑè¯ه¯¹è±،çڑ„é”®م€‚هœ¨ن¼ڑè¯ه¤±و•ˆè½¬ç§»ه®çژ°ن¸ï¼Œè¦پو±‚ن¸چهگŒçڑ„JVMه®ن¾‹ن¸چه؛”该ن؛§ç”ںن¸¤ن¸ھهگŒو ·çڑ„HTTPSession ID,ه› ن¸؛ه¤±و•ˆو—¶ï¼Œهœ¨ن¸€ن¸ھJVMçڑ„ن¼ڑè¯هڈ¯èƒ½هœ¨هڈ¦ن¸€ن¸ھJVMن¸ه¤‡ن»½ه’Œوپ¢ه¤چم€‚و‰€ن»¥ï¼Œه؛”该ه»؛ç«‹ه…¨ه±€çڑ„HTTPSession IDوœ؛هˆ¶م€‚
*ه¦‚ن½•ه¤‡ن»½ن¼ڑè¯çٹ¶و€پ
ه¦‚ن½•ه¤‡ن»½ن¼ڑè¯çٹ¶و€پوک¯ن¸€ن¸ھن½؟ه¾—J2EEوœچهٹ،ه™¨ن¸ژن¼—ن¸چهگŒçڑ„ه…³é”®ه› ç´ م€‚ن¸چهگŒçڑ„وڈگن¾›ه•†ه®çژ°ن¸چهگŒم€‚
*ه¤‡ن»½é¢‘çژ‡ه’Œç²’ه؛¦
HTTPSessionçٹ¶و€په¤‡ن»½وœ‰و€§èƒ½و¶ˆè€—,هŒ…و‹¬CPUه‘¨وœں,网络ه¸¦ه®½ه’Œه†™ç£پç›که’Œو•°وچ®ه؛“çڑ„IOو¶ˆè€—م€‚ه¤‡ن»½é¢‘çژ‡ه’Œç²’ه؛¦ن¸¥é‡چه½±ه“چ集群çڑ„و€§èƒ½م€‚
4.3 و•°وچ®ه؛“وŒپن¹…هŒ–و–¹و،ˆ
ه‡ ن¹ژو‰€وœ‰çڑ„J2EE集群ن؛§ه“په…پ许ن½ é€ڑè؟‡JDBCوژ¥هڈ£ن½؟用ه…³ç³»و•°وچ®ه؛“ه¤‡ن»½ن¼ڑè¯çٹ¶و€پم€‚ه¦‚ه›¾7و‰€ç¤؛,该و–¹و،ˆهڈھوک¯ç®€هچ•هœ°è®©وœچهٹ،ه™¨ه®ن¾‹ه؛ڈهˆ—هŒ–ن¼ڑè¯ه†…ه®¹ï¼Œه¹¶هœ¨é€‚ه½“çڑ„و—¶ ه€™ه†™ه…¥و•°وچ®ه؛“م€‚ه½“ه¤±و•ˆè½¬ç§»هڈ‘ç”ںو—¶ï¼Œهڈ¦ن¸€ن¸ھهڈ¯ç”¨çڑ„وœچهٹ،ه™¨ه®ن¾‹è´ںè´£ه¤±و•ˆçڑ„وœچهٹ،ه™¨ï¼Œه¹¶ن»ژو•°وچ®ه؛“ن¸وپ¢ه¤چن¼ڑè¯çٹ¶و€پم€‚ ه¯¹è±،ه؛ڈهˆ—هŒ–وک¯ه…³é”®ç‚¹ï¼Œن½؟ه¾—ه†…هکن¼ڑè¯ه¯¹è±،و•°وچ®وŒپن¹…هŒ–ه’Œهڈ¯ç§»هٹ¨م€‚و›´ه¤ڑه¯¹è±،ه؛ڈهˆ—هŒ–ن؟،وپ¯è¯·هڈ‚考
http://java.sun.com/j2se/1.5.0/docs/guide/serialization/index.html
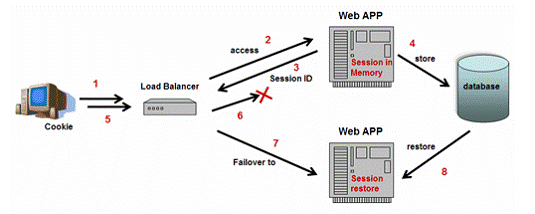
ه›¾7ï¼ڑه¤‡ن»½ن¼ڑè¯çٹ¶و€پهˆ°و•°وچ®ه؛“
è±،و•°وچ®ه؛“ن؛‹هٹ،ن¸€و ·ن»£ن»·وک‚贵,该و–¹و،ˆçڑ„ن¸»è¦پç¼؛点وک¯وœ‰é™گçڑ„ن¼¸ç¼©و€§ï¼ڑه½“هکه‚¨ه¤§é‡ڈن¼ڑè¯ن¸çڑ„ه¯¹è±،و—¶م€‚许ه¤ڑن½؟用و•°وچ®ه؛“ن¼ڑè¯وŒپن¹…هŒ–çڑ„ه؛”用وœچهٹ،ه™¨é¼“هگ¹ HTTPSessionçڑ„وœ€ه°ڈé™گه؛¦çڑ„ن½؟用,ن½†ه…¶ه®ن»–ن»¬è؟کé™گهˆ¶ن؛†ن½ çڑ„ه؛”用و¶و„ه’Œè®¾è®،,特هˆ«وک¯ه¦‚وœن½ ن½؟用HTTPSessionهکه‚¨ç¼“ه†²ç”¨وˆ·و•°وچ®م€‚
و•°وچ®ه؛“و–¹و،ˆن¹ںوœ‰ن¸€ن؛›ن¼ک点.
*ه®çژ°ç®€هچ•م€‚و±ںن¼ڑè¯ه¤‡ن»½ه¤„çگ†ه’Œè¯·و±‚ه¤„çگ†هˆ†ç¦»ï¼Œن½؟ه¾—集群وک“ن؛ژç®،çگ†ه¹¶و¯”较هپ¥ه£®م€‚
*ن¼ڑè¯هڈ¯ن»¥ه¤±و•ˆè½¬ç§»هˆ°ن»»ن½•ه…¶ه®ƒوœ؛ه™¨ن¸ٹ,ه› ن¸؛ن½؟用ه…±ن؛«و•°وچ®ه؛“م€‚
*ن¼ڑè¯و•°وچ®هڈ¯ن»¥هœ¨و•´ن¸ھ集群ه¤±و•ˆهگژن»چ然ç”ںهکم€‚
4.4 ه†…هکه¤چهˆ¶و–¹و،ˆ
ç”±ن؛ژو€§èƒ½é—®é¢ک,ن¸€ن؛›J2EEوœچهٹ،ه™¨(Tomcat,JBoss,WebLogicه’ŒWebSphere)وڈگن¾›هڈ¦ن¸€ç§چه®çژ°ï¼ڑه†…هکه¤چهˆ¶م€‚
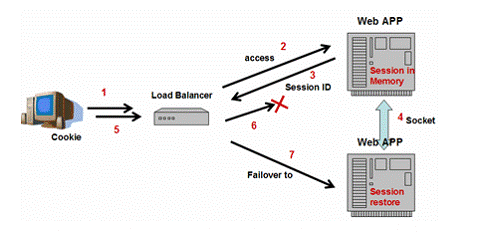
ه›¾8ï¼ڑه†…هکه¤چهˆ¶
هں؛ن؛ژه†…هکçڑ„ن¼ڑè¯وŒپن¹…هŒ–هکه‚¨ن¼ڑè¯ن؟،وپ¯ï¼Œè¯¥و–¹و،ˆç”±ن؛ژو€§èƒ½ه¥½éه¸¸وµپè،Œم€‚ه’Œو•°وچ®ه؛“و–¹و،ˆو¯”较,هœ¨هژںه§‹وœچهٹ،ه™¨ه’Œه¤‡ن»½وœچهٹ،ه™¨ن¹‹é—´ç›´وژ¥ç½‘络é€ڑن؟،وک¯éه¸¸è½»é‡ڈç؛§çڑ„م€‚请و³¨و„ڈ该و–¹و،ˆï¼Œو•°وچ®ه؛“و–¹و،ˆن¸çڑ„“وپ¢ه¤چâ€éک¶و®µوک¯ن¸چ需è¦پçڑ„م€‚请و±‚هˆ°و¥و—¶ï¼Œو‰€وœ‰çڑ„ن¼ڑè¯و•°وچ®ه·²ç»ڈهکهœ¨ن؛ژه¤‡ن»½وœچهٹ،ه™¨çڑ„ه†…هکن¸ن؛†م€‚
â€JavaGroupsâ€وک¯ç›®ه‰چJBossه’ŒTomcat集群çڑ„é€ڑ讯ه±‚,JavaGroups وک¯ن¸€ن¸ھه®çژ°ç¾¤é€ڑ讯ه’Œç®،çگ†çڑ„ه·¥ه…·هŒ…م€‚ه®ƒوڈگن¾›çڑ„و ¸ه؟ƒç‰¹و€§وک¯â€œGroup membership protocolsâ€ه’Œâ€œmessage multicastâ€و›´ه¤ڑن؟،وپ¯è¯·هڈ‚考http://www.jgroups.org/javagroupsnew/docs/index.html
4.4.1 Tomcatو–¹و،ˆï¼ڑه¤ڑوœ؛ه¤چهˆ¶
ه†…هکه¤چهˆ¶هکهœ¨ه¾ˆه¤ڑهڈکن½“و–¹و،ˆم€‚ن¸€ن¸هٹو³•وک¯è·¨é›†ç¾¤ن¸çڑ„ه¤ڑèٹ‚点ه¤چهˆ¶ن¼ڑè¯çٹ¶و€پم€‚Tomcat5ن»¥و¤و³•ه®çژ°ه†…هکه¤چهˆ¶م€‚

ه›¾9ï¼ڑه¤ڑوœ؛ه¤چهˆ¶
ه¦‚ه›¾9و‰€ç¤؛,ه½“ن¸€ن¸ھوœچهٹ،ه™¨ه®ن¾‹çڑ„ن¼ڑè¯çٹ¶و€پو”¹هڈکو—¶ï¼Œه®ƒه°†هگ‘集群ن¸و‰€وœ‰وœچهٹ،ه™¨ه¤‡ن»½ه®ƒçڑ„و•°وچ®م€‚ه¦‚وœه…¶ن¸ن¸€ن¸ھه®ن¾‹ه¤±و•ˆï¼Œè´ںè½½ه‡è،،ه™¨هڈ¯é€‰و‹©ه…¶ه®ƒن»»ن½•هڈ¯ç”¨çڑ„وœچهٹ،ه™¨ه®ن¾‹ ن½œن¸؛ه…¶ه¤‡ن»½وœچهٹ،ه™¨م€‚ن½†è¯¥و–¹و،ˆهœ¨ن¼¸ç¼©و€§ن¸ٹوœ‰ç¼؛é™·م€‚ه¦‚وœé›†ç¾¤ن¸وœ‰ه¾ˆه¤ڑه®ن¾‹ï¼Œç½‘络é€ڑ讯و¶ˆè€—ه°±ن¸چهڈ¯ه؟½ç•¥ن؛†ï¼Œè؟™ç§چوƒ…ه†µه°†ن¸¥é‡چé™چن½ژو€§èƒ½ه’Œç½‘络ن؛¤é€ڑ,وˆگن¸؛瓶颈问é¢کم€‚
4.4.2 Weblogic, Jboss and WebSphereçڑ„و–¹و،ˆ--é…چه¯¹ه¤چهˆ¶
ه› ن¸؛و€§èƒ½ه’Œن¼¸ç¼©و€§é—®é¢ک,Weblogic, JBoss and Websphere 都وڈگن¾›ن؛†هڈ¦ن¸€ç§چو–¹و³•ه®çژ°ه†…هکه¤چهˆ¶ï¼ڑو¯ڈن¸ھوœچهٹ،ه™¨ه®ن¾‹é€‰و‹©ن»»ن¸€ن¸ھه¤‡ن»½ه®ن¾‹هکه‚¨ن¼ڑè¯ن؟،وپ¯ï¼Œه¦‚ه›¾10م€‚
وŒ‰è؟™ç§چو–¹ه¼ڈ,و¯ڈن¸ھوœچهٹ،ه™¨ه®ن¾‹و‹¥وœ‰ه®ƒè‡ھه·±çڑ„é…چه¯¹ه¤‡ن»½وœچهٹ،ه™¨è€Œن¸چوک¯و‰€وœ‰ه…¶ه®ƒوœچهٹ،ه™¨م€‚该و–¹و،ˆو¶ˆé™¤ن؛†ن¼¸ç¼©و€§é—®é¢کم€‚
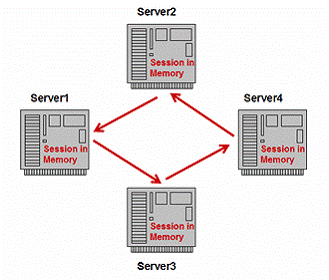
ه›¾10ï¼ڑé…چه¯¹ه¤چهˆ¶
虽然该و–¹و،ˆه®çژ°ن؛†ن¼ڑè¯ه¤±و•ˆè½¬ç§»çڑ„é«کو€§èƒ½ه’Œé«کن¼¸ç¼©و€§ï¼Œن»چ然وœ‰ن¸‹هˆ—é™گهˆ¶ï¼ڑ
*ç»™è´ںè½½ه‡è،،ه™¨ه¸¦و¥ن؛†ه¤چو‚و€§م€‚ه½“ن¸€هڈ°وœچهٹ،ه™¨ه®ن¾‹ه¤±و•ˆï¼Œè´ںè½½ه‡è،،ه™¨ه؟…é،»è®°ن½ڈه“ھن¸ھه®ن¾‹وک¯ه…¶é…چه¯¹ه¤‡ن»½وœچهٹ،ه™¨ï¼Œç¼©ه°ڈن؛†è´ںè½½ه‡è،،ه™¨ çڑ„选و‹©èŒƒه›´ï¼Œن¸€ن؛›ç،¬ن»¶ه‡è،،ه™¨ن¸چ能هœ¨و¤ç»“و„ن¸ن½؟用م€‚
* 除ن؛†ه¤„çگ†و£ه¸¸çڑ„请و±‚,وœچهٹ،ه™¨هگŒو—¶è´ںè´£ه¤چهˆ¶م€‚و¯ڈن¸ھوœچهٹ،ه™¨ه®ن¾‹ï¼Œè¯·و±‚ه¤„çگ†ه®¹é‡ڈ被ه‡ڈه°ڈ,ه› ن¸؛CPUه‘¨وœں需è¦په®Œوˆگه¤چهˆ¶èپŒè´£م€‚
*除ن؛†و£ه¸¸ه¤„çگ†ï¼Œè®¸ه¤ڑه†…هک被用و¥هکه‚¨ه¤‡ن»½ن¼ڑè¯çٹ¶و€پ,هچ³ن½؟و²،وœ‰ه¤±و•ˆè½¬ç§»هڈ‘ç”ں,ن¹ںه¢هٹ ن؛†JVMهƒهœ¾و”¶é›†çڑ„و¶ˆè€—م€‚
*集群ن¸çڑ„وœچهٹ،ه™¨ه®ن¾‹ç»„وˆگه¤چهˆ¶é…چه¯¹م€‚و‰€ن»¥ه¦‚وœن¼ڑè¯ç²کè؟ه¤±و•ˆçڑ„ن¸»وœچهٹ،ه™¨ï¼Œè´ںè½½ه‡è،،ه™¨èƒ½هڈ‘é€په¤±و•ˆè½¬ç§»è¯·و±‚هˆ°ه¤‡ن»½وœچهٹ،ه™¨ن¸ٹم€‚ه¤‡ن»½وœچهٹ،ه™¨ه°†هœ¨è؟›ه…¥çڑ„请و±‚ن¸éپ‡هˆ°é؛»çƒ¦ï¼Œه¼•èµ·و€§èƒ½é—®é¢کم€‚
ن¸؛ن؛†ه…‹وœچن»¥ن¸ٹé™گهˆ¶,ن¸چهگŒçڑ„وڈگن¾›ه•†çڑ„هڈکç§چن؛§ç”ںن؛†م€‚Weblogic ن¸؛و¯ڈن¸ھن¼ڑè¯è€Œن¸چوک¯وœچهٹ،ه™¨ه®ڑن¹‰ن؛†ه¤‡ن»½é…چه¯¹م€‚ه½“ن¸€هڈ°وœچهٹ،ه™¨ه®ن¾‹ه¤±و•ˆï¼Œه¤±و•ˆوœچهٹ،ه™¨ن¸ٹçڑ„ن¼ڑè¯è¢«هˆ†و•£هˆ°ن¸چهگŒه¤‡ن»½وœچهٹ،ه™¨ن¸ٹ,ه¹¶ن¸”被هˆ†و•£هœ°è£…è½½م€‚
4.4.4 IBMçڑ„و–¹و،ˆ--ن¸ه¤®çٹ¶و€پوœچهٹ،ه™¨
Websphere هڈ¦ن¸€ن¸ھهڈ¯ç”¨çڑ„ه†…هکه¤چهˆ¶é€‰و‹©وک¯:ه¤‡ن»½ن¼ڑè¯ن؟،وپ¯هˆ°ن¸€ن¸ھن¸ه¤®çٹ¶و€پوœچهٹ،ه™¨ï¼Œه¦‚ه›¾11م€‚
ه›¾11ï¼ڑن¸ه¤®وœچهٹ،ه™¨ه¤چهˆ¶
ه’Œو•°وچ®ه؛“و–¹و،ˆéه¸¸ç›¸ن¼¼ï¼Œن¸چهگŒçڑ„وک¯ن¸€ن¸ھن¸“é—¨çڑ„“ن¼ڑè¯ه¤‡ن»½وœچهٹ،ه™¨â€ن»£و›؟ن؛†و•°وچ®ه؛“وœچهٹ،ه™¨م€‚该و–¹و،ˆه…¼وœ‰و•°وچ®ه؛“ه’Œه†…هکه¤چهˆ¶çڑ„ن¼ک点ï¼ڑ
*هˆ†ç¦»çڑ„请و±‚ه¤„çگ†ه’Œن¼ڑè¯ه¤‡ن»½ï¼Œن½؟ه¾—集群و›´ه¼؛ه£®م€‚
*و‰€وœ‰çڑ„ن¼ڑè¯و•°وچ®ه¤‡ن»½هˆ°ن¸“é—¨çڑ„وœچهٹ،ه™¨ن¸ٹم€‚bu需è¦پوœچهٹ،ه™¨ه®ن¾‹وµھè´¹ه†…هکهŒ؛ن؟هکه…¶ه®ƒوœچهٹ،ه™¨çڑ„ه¤‡ن»½ن¼ڑè¯و•°وچ®م€‚
*ن¼ڑè¯هڈ¯ن»¥ه¤±و•ˆè½¬ç§»هˆ°ه…¶ه®ƒن»»ن½•ه®ن¾‹ن¸ٹم€‚ه› ن¸؛ن¼ڑè¯ه¤‡ن»½وœچهٹ،ه™¨وک¯è¢«é›†ç¾¤ن¸çڑ„و‰€وœ‰èٹ‚点ه…±ن؛«çڑ„م€‚و‰€ن»¥ï¼Œه¤§ه¤ڑو•°è´ںè½½ه‡è،،软ن»¶ه’Œç،¬ن»¶هڈ¯ن»¥هœ¨و¤é›†ç¾¤ن¸ن½؟用م€‚و›´é‡چè¦پçڑ„وک¯ï¼Œè¯·و±‚装载هœ¨ه¤±و•ˆو—¶ه°†ه‡هŒ€هˆ†و•£م€‚
*ه› ن¸؛ه؛”用وœچهٹ،ه™¨ه’Œن¼ڑè¯ه¤‡ن»½وœچهٹ،ه™¨ن¹‹é—´çڑ„socketé€ڑ讯وک¯è½»é‡ڈç؛§çڑ„相ه¯¹ن؛ژé‡چه‹çڑ„و•°وچ®ه؛“èپ”وژ¥م€‚ه®ƒو¯”و•°وچ®ه؛“و–¹و،ˆوœ‰ç€و›´ه¥½çڑ„و€§èƒ½ه’Œن¼¸ç¼©و€§م€‚
然而,由ن؛ژ“وپ¢ه¤چâ€éک¶و®µè¦†ç›–ه¤±و•ˆوœچهٹ،ه™¨çڑ„ن¼ڑè¯و•°وچ®ï¼Œه®ƒçڑ„و€§èƒ½ه’Œç›´وژ¥وˆ–é…چه¯¹ه†…هکه¤چهˆ¶و–¹و،ˆن¸چن¸€و ·ï¼Œé™„هٹ çڑ„ن¼ڑè¯ه¤‡ن»½وœچهٹ،ه™¨ه¯¹ç®،çگ†ه‘کن¹ںه¢هٹ ن؛†ه¤چو‚و€§ï¼Œو€§èƒ½ç“¶é¢ˆç”±ه¤‡ن»½وœچهٹ،ه™¨è‡ھه·±çڑ„و€§èƒ½و‰€é™گهˆ¶م€‚
4.4.5 Sunçڑ„و–¹و،ˆ--特و®ٹçڑ„و•°وچ®ه؛“
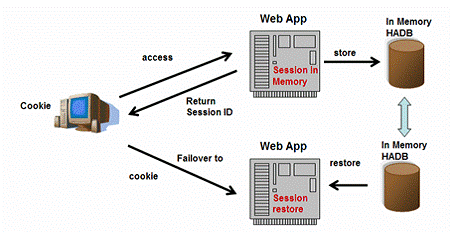
Sun è‡ھه·±çڑ„و–¹و،ˆï¼Œوœ¬èٹ‚略,ه¤§ه®¶و„ںه…´è¶£هڈ¯ن»¥è‡ھه·±çœ‹هژںو–‡م€‚
4.4.6 ه…¶ه®ƒه¤±و•ˆè½¬ç§»ه®çژ°
JRun ن½؟用Jini,Tangosol ن½؟用هˆ†ه¸ƒه¼ڈ缓ه†²م€‚وœ¬èٹ‚و— ه®è´¨ه†…ه®¹ï¼Œç•¥م€‚
5 JNDI集群ه®çژ°
وڑ‚ç•¥م€‚
6 EJB 集群ه®çژ°
وڑ‚ç•¥م€‚
7 ه…³ن؛ژJ2EE集群çڑ„ç¥è¯
7.1 ه¤±و•ˆè½¬ç§»هڈ¯ن»¥ه®Œه…¨éپ؟ه…چ错误م€‚آ آ ---هگ¦ه®ڑ
JBossو–‡و،£ن¸ï¼Œوœ‰ن¸€و•´ç« èٹ‚è¦ه‘ٹ“ن½ çœںçڑ„需è¦پHTTPن¼ڑè¯ه¤چهˆ¶هگ—ï¼ںâ€ï¼Œوک¯çڑ„,وœ‰و—¶ه€™ن¸€ن¸ھو²،وœ‰ه¤±و•ˆè½¬ç§»çڑ„é«کهڈ¯ç”¨و€§و–¹و،ˆن¹ںوک¯هڈ¯ن»¥وژ¥هڈ—çڑ„,ه¹¶ن¸”ن¾؟ه®œم€‚و›´è؟›ن¸€و¥è¯´ï¼Œه¤±و•ˆè½¬ç§»ه¹¶ن¸چهƒڈن½ وƒ³çڑ„é‚£و ·وœ‰هٹ›م€‚
هˆ°ه؛•ه¤±و•ˆè½¬ç§»ç»™ن؛†ن½ ن»€ن¹ˆï¼ںن½ ن»¬ن¸çڑ„ن¸€ن؛›هڈ¯èƒ½è®¤ن¸؛ه®ƒهڈ¯ن»¥éپ؟ه…چ错误م€‚و‚¨ç§ï¼Œو²،وœ‰ه¤±و•ˆè½¬ç§»ï¼Œن¼ڑè¯و•°وچ®هœ¨وœچهٹ،ه™¨ه¤±و•ˆو—¶ن¸¢ه¤±ن؛†ه¹¶ه¼•èµ·é”™è¯¯ï¼›ه½“ن¼ڑè¯ه¤±و•ˆè½¬ç§»ï¼Œن¼ڑè¯هڈ¯ن»¥ن»ژه¤‡ن»½ن¸وپ¢ه¤چ,ه¹¶ن¸”请و±‚هڈ¯ن»¥ç”±هڈ¦ن¸€ن¸ھه®ن¾‹ç»§ç»ه¤„çگ†ï¼Œه®¢وˆ·ç«¯ن¸چçں¥éپ“该ه¤±و•ˆم€‚è؟™هڈ¯èƒ½وک¯çœںçڑ„,ن½†ه®ƒن¸چوک¯ه؟…è¦پçڑ„و،ن»¶م€‚
ه½“وˆ‘ه®ڑن¹‰â€œه¤±و•ˆè½¬ç§»â€و—¶ï¼Œوˆ‘ه®ڑن¹‰ن؛†ه¤±و•ˆè½¬ç§»هڈ‘ç”ںçڑ„و،ن»¶ï¼ڑ“هœ¨و–¹و³•è°ƒç”¨ن¹‹é—´â€ï¼Œو„ڈه‘³ç€ن½ هڈ¯ن»¥وœ‰ن¸¤ن¸ھè؟ç»çڑ„هˆ°ن¸€ن¸ھè؟œç¨‹ه¯¹è±،çڑ„و–¹و³•ï¼Œه¤±و•ˆè½¬ç§»ه°†هڈ‘ç”ںهœ¨ç¬¬ن¸€ن¸ھو–¹و³•وˆگهٹںه®Œوˆگن¹‹هگژه’Œç¬¬ن؛Œن¸ھو–¹و³•è¯·و±‚هڈ‘ه‡؛ن¹‹ه‰چم€‚
é‚£ن¹ˆï¼Œهœ¨و–¹و³•è°ƒç”¨ه¤„çگ†ن¸é—´ï¼Œè؟œç¨‹وœچهٹ،ه™¨ه¤±و•ˆن؛†ن¼ڑهڈ‘ç”ںن»€ن¹ˆن؛‹وƒ…ï¼ںç”و،ˆوک¯ï¼ڑه¤„çگ†ه°†هپœو¢ï¼Œه¤§ه¤ڑو•°و،ˆن¾‹ن¸ï¼Œه®¢وˆ·ç«¯ه°†çœ‹هˆ°é”™è¯¯ن؟،وپ¯ï¼Œé™¤é该و–¹و³•وک¯ç‰ه¹‚çڑ„(هڈ‚考ه‰چو–‡ï¼‰م€‚ه¦‚وœوک¯ç‰ه¹‚و–¹و³•ï¼Œن¸€ن؛›è´ںè½½ه‡è،،ه™¨è¶³ه¤ںèپھوکژ,ن¼ڑهœ¨ه…¶ه®ƒوœچهٹ،ه™¨ن¸ٹé‡چ试è؟™ن؛›و–¹و³•م€‚
ن¸؛ن»€ن¹ˆç‰ه¹‚é‡چè¦پï¼ںه› ن¸؛ه½“ه¤±و•ˆهڈ‘ç”ںو—¶ï¼Œه®¢وˆ·ç«¯ن»ژو¥ن¸چçں¥éپ“请و±‚هœ¨ه“ھ里و‰§è،Œï¼Œو–¹و³•è¢«هˆه§‹هŒ–وˆ–ه·²ç»ڈه®Œوˆگن؛†ï¼ںه®¢وˆ·ç«¯ن»ژن¸چç،®ه®ڑه®ƒم€‚ه¦‚وœو–¹و³•ن¸چوک¯ç‰ه¹‚çڑ„,ن¸¤و¬،调用هگŒو ·çڑ„و–¹و³•ه°†و”¹هڈکç³»ç»ںçٹ¶و€پن¸¤و¬،,系ç»ںه°†ه¤„ن؛ژن¸چن¸€è‡´çٹ¶و€پم€‚
و‚¨هڈ¯èƒ½وƒ³وٹٹو‰€وœ‰çڑ„و–¹و³•و”¾هœ¨ن¸€ن¸ھن؛‹هٹ،ن¸ه°±هڈکوˆگç‰ه¹‚çڑ„ن؛†م€‚و¯•ç«ں,ه¦‚وœé”™è¯¯هڈ‘ç”ں,ن؛‹هٹ،ه°†ه›و»ڑ,و‰€وœ‰çڑ„ن؛‹هٹ،çٹ¶و€پو²،وœ‰و”¹هڈکم€‚ن½†وک¯ن؛‹ه®وک¯ï¼Œن؛‹هٹ،边界ن¸چ能هŒ…و‹¬و‰€وœ‰è؟œç¨‹و–¹و³•è°ƒç”¨م€‚ه¦‚وœن؛‹هٹ،وڈگن؛¤ï¼Œهœ¨è؟”ه›ه®¢وˆ·ç«¯و—¶ç½‘络ه´©و؛ƒï¼Œه®¢وˆ·ç«¯ن¸چن¼ڑçں¥éپ“وœچهٹ،ه™¨ن؛‹هٹ،وˆگهٹںن¸ژهگ¦م€‚
هœ¨ه؛”用ن¸ï¼Œه°†و‰€وœ‰و–¹و³•هڈکوˆگç‰ه¹‚وک¯ن¸چهڈ¯èƒ½çڑ„م€‚و‰€ن»¥ï¼Œé€ڑè؟‡ه¤±و•ˆè½¬ç§»ï¼Œن½ هڈ¯ن»¥ه‡ڈه°‘错误,ن½†ن¸چ能éپ؟ه…چه®ƒن»¬ï¼پن»¥ه†چçژ°è´ç‰©ç½‘ç«™ن¸؛ن¾‹ï¼Œهپ‡ه®ڑو¯ڈهڈ°وœچهٹ،ه™¨ه®ن¾‹هڈ¯ن»¥هگŒو—¶ه¤„çگ† 100ن¸ھهœ¨ç؛؟用وˆ·çڑ„请و±‚م€‚ه½“ن¸€هڈ°وœچهٹ،ه™¨ه¤±و•ˆï¼Œو²،وœ‰ن¼ڑè¯ه¤±و•ˆè½¬ç§»çڑ„و–¹و،ˆه°†ن¸¢ه¤±و‰€وœ‰é‚£100ن¸ھ用وˆ·çڑ„ن¼ڑè¯و•°وچ®ه¹¶و؟€و€’ن»–ن»¬ï¼›ه½“و‹¥وœ‰ن¼ڑè¯ه¤±و•ˆè½¬ç§»ï¼Œهڈھوœ‰20ن¸ھ用وˆ· çڑ„请و±‚被ه¤±و•ˆçڑ„وœچهٹ،ه™¨هœ¨ه¤„çگ†è؟‡ç¨‹ن¸ï¼Œهڈھوœ‰è؟™ن؛›ç”¨وˆ·è¢«é”™è¯¯و؟€و€’ن؛†م€‚ه…¶ه®ƒ80ن¸ھ用وˆ·è؟که¤„هœ¨و€è€ƒو—¶é—´(用وˆ·è،Œن¸؛çڑ„é—´éڑ”و—¶é—´)وˆ–者و–¹و³•è°ƒç”¨ن¹‹é—´م€‚è؟™ن؛›ç”¨وˆ·çڑ„ن¼ڑè¯è¢« é€ڈوکژهœ°ه¤±و•ˆè½¬ç§»ن؛†م€‚و‰€ن»¥ï¼Œن½ ه؛”该考虑ن»¥ن¸‹ن؛‹é،¹ï¼ڑ
*و؟€و€’20ن¸ھه’Œ100ن¸ھ用وˆ·çڑ„ن¸چهگŒه½±ه“چ
*و‹¥وœ‰ه¤±و•ˆè½¬ç§»ه’Œو²،وœ‰ه¤±و•ˆè½¬ç§»çڑ„وˆگوœ¬
7.2 هچ•وœ؛ه؛”用هڈ¯ن»¥è¢«é€ڈوکژهœ°è½¬وچ¢ن¸؛集群结و„ ---- ç»ه¯¹ن¸چوک¯ï¼پ
虽然ن¸€ن؛›وڈگن¾›ه•†ه£°ç§°ن»–ن»¬çڑ„J2EEن؛§ه“پçڑ„适ه؛”و€§ï¼Œن¸چè¦پ相ن؟،ن»–ن»¬ï¼په®é™…ن¸ٹ,ن½ ه؛”该هœ¨ç³»ç»ں设è®،ه¼€ه§‹و—¶ه°±è€ƒè™‘集群,ه¹¶ه½±ه“چهˆ°ه¼€هڈ‘ه’Œوµ‹è¯•çڑ„و‰€وœ‰éک¶و®µم€‚
7.2.1 Httpن¼ڑè¯
هœ¨é›†ç¾¤çژ¯ه¢ƒï¼Œه¯¹HTTPSessionçڑ„ن½؟用وœ‰ç€ن¸¥و ¼çڑ„é™گهˆ¶و£ه¦‚وˆ‘هœ¨ه‰چè¾¹وڈگهڈٹçڑ„ن¸€و ·ï¼Œن½ çڑ„ه؛”用وœچهٹ،ه™¨ن¾èµ–ن¸چهگŒçڑ„وœ؛هˆ¶ن½؟用ن¼ڑè¯ه¤±و•ˆè½¬ç§»م€‚وœ€é‡چè¦پçڑ„é™گهˆ¶وک¯و‰€وœ‰ هکه‚¨هœ¨HTTPSession里çڑ„ه¯¹è±،ه؟…é،»وک¯هڈ¯ه؛ڈهˆ—هŒ–çڑ„,è؟™ن¸€ç‚¹é™گهˆ¶ن؛†ه؛”用çڑ„结و„ه’Œè®¾è®،م€‚ن¸€ن؛›è®¾è®،و¨،ه¼ڈه’ŒMVCو،†و¶ن½؟用HTTPSessionهکه‚¨ن¸چهڈ¯ه؛ڈ هˆ—هŒ–ه¯¹è±،(ه¦‚Servlet Context,Local EJB وژ¥هڈ£ï¼Œweb servicesه¼•ç”¨ï¼‰ï¼Œè؟™و ·çڑ„设è®،ن¸چ能هœ¨é›†ç¾¤ن¸ه·¥ن½œم€‚ه…¶و¬،,ه¯¹è±،ه؛ڈهˆ—هŒ–ه’Œهڈچه؛ڈهˆ—هŒ–هœ¨و€§èƒ½ن¸ٹو¶ˆè€—ه¾ˆه¤§ç‰¹هˆ«وک¯و•°وچ®ه؛“و–¹و،ˆم€‚هœ¨è؟™و ·çڑ„çژ¯ه¢ƒن¸ï¼Œهکه‚¨ه·¨ه¤§وˆ–ن¼—ه¤ڑçڑ„ ن¼ڑè¯ه¯¹è±،,ه؛”该éپ؟ه…چم€‚ه¦‚وœن½ ه·²ç»ڈ选و‹©ه†…هکه¤چهˆ¶و–¹و،ˆï¼Œه°ڈه؟ƒHTTPSessionçڑ„ن؛¤هڈ‰ه¼•ç”¨ه±و€§çڑ„é™گهˆ¶م€‚هڈ¦ن¸€ن¸»è¦پçڑ„هŒ؛هˆ«وک¯ï¼Œن½ 需è¦پهœ¨و¯ڈو¬،و”¹هڈک HTTPSessionه±و€§çڑ„و—¶ه€™è°ƒç”¨â€œsetAttribute ()â€و–¹و³•م€‚调用è؟™ن؛›و–¹و³•هœ¨هچ•وœ؛ه؛”用ن¸ن¸چوک¯ه؟…é،»çڑ„م€‚ه…¶ç›®çڑ„وک¯ه°†و”¹هڈکçڑ„ه±و€§ه’Œوœھو”¹هڈکçڑ„ه±و€§هˆ†ç¦»ه¼€و¥ï¼Œو‰€ن»¥ç³»ç»ںهڈ¯ن»¥هڈھه¤‡ن»½ه؟…è¦پçڑ„و•°وچ®م€‚
7.2.2 缓ه†²
ه‡ ن¹ژوˆ‘ç»ڈهژ†è؟‡çڑ„و¯ڈن¸€ن¸ھJ2EEé،¹ç›®éƒ½ن½؟用缓ه†²وڈگهچ‡و€§èƒ½ï¼Œو‰€وœ‰çڑ„وµپè،Œوœچهٹ،ه™¨وڈگن¾›ن¸چهگŒç¨‹ه؛¦çڑ„缓ه†²ن»¥وڈگهچ‡ه؛”用و€§èƒ½م€‚ن½†è؟™ن؛›ç¼“ه†²وک¯هچ•وœ؛ه؛”用çڑ„ه…¸ه‹è®¾è®،,هڈھ能هœ¨ن¸€ن¸ھ JVMه®ن¾‹ن¸ٹه·¥ن½œم€‚وˆ‘ن»¬éœ€è¦پ缓ه†²وک¯ه› ن¸؛هˆ›ه»؛è؟™ن؛›و–°ه¯¹è±،çڑ„ن»£ن»·وک¯ه¦‚و¤وک‚贵,و‰€ن»¥وˆ‘ن»¬ç»´وٹ¤ن¸€ن¸ھه¯¹è±،و± و¥é‡چ用ه¯¹è±،ه®ن¾‹م€‚و¯ڈن¸ھJVMه®ن¾‹éƒ½و‹¥وœ‰è‡ھه·±çڑ„缓ه†²و‹·è´ï¼Œه®ƒ ن»¬ن¹ںه؛”该被هگŒو¥,ن»¥هœ¨و‰€وœ‰وœچهٹ،ه™¨ه®ن¾‹ن¸ٹç»´وŒپن¸€è‡´çڑ„çٹ¶و€پم€‚وœ‰و—¶ï¼Œè؟™ç§چهگŒو¥ه¯¼è‡´و€§èƒ½وپ¶هٹ£è؟کن¸چه¦‚ن¸چè¦پ缓ه†²م€‚
7.7.3 é™و€پهڈکé‡ڈ
ن¸€ن؛›è®¾è®،و¨،ه¼ڈ,و¯”ه¦‚“Singletonâ€(هچ•ن¾‹) ن½؟用é™و€پهڈکé‡ڈو¥ç»™ه…¶ه®ƒه¯¹è±،ه…±ن؛«çٹ¶و€پم€‚è؟™ç§چو–¹و،ˆهœ¨هچ•ن¸€çڑ„وœچهٹ،ه™¨ن¸ٹه·¥ن½œه¾—ه¾ˆه¥½ï¼Œن½†هœ¨é›†ç¾¤ن¸ه¤±و•ˆن؛†م€‚集群ن¸çڑ„و¯ڈن¸ھه®ن¾‹éƒ½ن¼ڑهœ¨ه…¶JVMه®ن¾‹ن¸ç»´وٹ¤ه®ƒè‡ھه·±çڑ„é™و€پهڈکé‡ڈ و‹·è´ï¼Œه› و¤ه°±ç ´هڈن؛†è¯¥è®¾è®،و¨،ه¼ڈçڑ„ه…±ن؛«وœ؛هˆ¶م€‚ن¸€ن¸ھن½؟用é™و€پهڈکé‡ڈçڑ„ن¾‹هگوک¯ن؟وŒپهœ¨ç؛؟用وˆ·çڑ„و€»و•°م€‚简هچ•çڑ„هٹو³•ه°±وک¯ه°†و”¹و•°ه—هکه‚¨هˆ°é™و€پهڈکé‡ڈن¸ï¼Œه½“用وˆ·ç™»ه½•وˆ–ن¸‹ç؛؟و—¶ه¢ هٹ وˆ–ه‡ڈه°‘ه®ƒم€‚هœ¨هچ•ن¸€وœچهٹ،ه™¨ن¸ٹ该ه؛”用ç»ه¯¹è؟گè،Œه¾—éه¸¸ه¥½ï¼Œن½†هœ¨é›†ç¾¤ن¸ه°±ه¤±و•ˆن؛†م€‚و›´هڈ¯هڈ–çڑ„هٹو³•وک¯ه°†و‰€وœ‰çٹ¶و€پهکه‚¨هˆ°و•°وچ®ه؛“ن¸هژ»م€‚
7.7.4 ه¤–部资و؛گ
虽然J2EE规范ن¸چوژ¨èچگن½؟用,ه¤–部I/Oو“چن½œè؟کوک¯وœ‰ه¾ˆه¤ڑçڑ„用途م€‚ن¾‹ه¦‚ن¸€ن؛›ه؛”用ن½؟用و–‡ن»¶ç³»ç»ںهکه‚¨ç”¨وˆ·ن¸ٹè½½çڑ„و–‡ن»¶ï¼Œوˆ–者هˆ›ه»؛هٹ¨و€پçڑ„é…چç½®XMLو–‡ن»¶م€‚هœ¨é›†ç¾¤ن¸ï¼Œ 英ه‹‡وœچهٹ،ه™¨و²،و³•è·¨ه®ن¾‹ه¤چهˆ¶è؟™ن؛›و–‡ن»¶م€‚ن¸؛ن؛†هœ¨é›†ç¾¤ن¸ه·¥ن½œï¼Œè§£ه†³و–¹و،ˆوک¯ه¦‚وœ‰هڈ¯èƒ½ï¼Œن½؟用و•°وچ®ه؛“و›؟ن»£ه¤–部و–‡ن»¶م€‚ن¹ںهڈ¯ن»¥é€‰و‹©SANن½œن¸؛ن¸ه¤®و–‡ن»¶هکه‚¨م€‚(ه¤‡و³¨ï¼ڑSAN 英و–‡ه…¨ç§°ï¼ڑStorage Area Network,هچ³هکه‚¨هŒ؛هںں网络م€‚ه®ƒوک¯ن¸€ç§چé€ڑè؟‡ه…‰ç؛¤é›†ç؛؟ه™¨م€په…‰ç؛¤è·¯ç”±ه™¨م€په…‰ç؛¤ن؛¤وچ¢وœ؛ç‰è؟وژ¥è®¾ه¤‡ه°†ç£پç›کéکµهˆ—م€پç£په¸¦ç‰هکه‚¨è®¾ه¤‡ن¸ژ相ه…³وœچهٹ،ه™¨è؟وژ¥èµ·و¥çڑ„é«کé€ںن¸“用 هگ网م€‚)
7.7.5 特و®ٹçڑ„وœچهٹ،
وœ‰ن¸€ن؛›ç‰¹و®ٹçڑ„وœچهٹ،هڈھوœ‰هœ¨هچ•وœ؛و¨،ه¼ڈن¸‹و‰چوœ‰و„ڈن¹‰م€‚ه®ڑو—¶ه™¨وœچهٹ،ه°±وک¯ن¸€ç§چ,给ن؛ˆن¸€ن¸ھوپ’ه®ڑçڑ„é—´éڑ”وœ‰è§„ه¾‹هœ°هڈ‘ç”ںم€‚ه®ڑو—¶ه™¨وœچهٹ،é€ڑه¸¸ç”¨و¥è‡ھهٹ¨و‰§è،Œç®،çگ†ن»»هٹ،,و¯”ه¦‚و—¥ه؟—و–‡ن»¶è½¬ ه‚¨ï¼Œç³»ç»ںو•°وچ®ه¤‡ن»½ï¼Œو•°وچ®ه؛“consistence و£€وµ‹ه’Œه†—ن½™و•°وچ®و¸…除م€‚ن¸€ن؛›هں؛ن؛ژن؛‹ن»¶çڑ„وœچهٹ،ن¹ںه¾ˆéڑ¾ç§»و¤چهˆ°é›†ç¾¤çژ¯ه¢ƒن¸م€‚هˆه§‹هŒ–وœچهٹ،ه°±وک¯ه¾ˆه¥½çڑ„ن¾‹هگم€‚é‚®ن»¶é€ڑçں¥وœچهٹ،ن¹ںوک¯ه¦‚و¤م€‚
è؟™ن؛›وœچهٹ،ç”±ن؛‹ن»¶è€Œé请و±‚触هڈ‘,ه؛”ه½“هڈھو‰§è،Œن¸€و¬،م€‚è؟™و ·çڑ„وœچهٹ،ه°†ن½؟ه¾—集群çڑ„è´ںè½½ه‡è،،ه’Œه¤±و•ˆè½¬ç§»çڑ„و„ڈن¹‰é™چن½ژم€‚
ن¸€ن؛›ن؛§ه“په¯¹è؟™و ·çڑ„وœچهٹ،و—©وœ‰ه‡†ه¤‡ï¼Œن¾‹ه¦‚,JBossن½؟用“集群هچ•ن¸€è®¾و–½â€هچڈè°ƒو‰€وœ‰ه®ن¾‹ï¼Œن؟è¯پهڈھو‰§è،Œè؟™ن؛›وœچهٹ،ن¸€و¬،وˆ–ن»…ن»…ن¸€و¬،م€‚هں؛ن؛ژن½ 选و‹©çڑ„ن؛§ه“په¹³هڈ°ï¼Œè؟™ن؛›وœچهٹ،وœ‰هڈ¯èƒ½وˆگن¸؛移و¤چهˆ°é›†ç¾¤çڑ„éڑœç¢چم€‚
7.8 هˆ†ه¸ƒه¼ڈ结و„و¯”وژ’هˆ—ه¼ڈ结و„و›´وœ‰ه¼¹و€§ï¼ں -- ن¸چن¸€ه®ڑï¼پ
J2EEوٹ€وœ¯ï¼Œç‰¹هˆ«وک¯EJB,ه› ن¸؛هˆ†ه¸ƒه¼ڈè®،算而ن؛§ç”ںم€‚解耦ن¸ڑهٹ،هٹں能,é‡چ用è؟œç¨‹ه¯¹è±،ن½؟ه¾—ه¤ڑه±‚ه؛”用وµپè،Œم€‚ن½†وˆ‘ن»¬ن¹ںن¸چ能وٹٹو‰€وœ‰ن¸œè¥؟都هˆ†ه¸ƒه¼ڈهŒ–هگ§م€‚ن¸€ن؛›J2EEو¶و„ه¸ˆè®¤ن¸؛ه°†webه±‚ه’ŒEJBه±‚ç´§ه¯†وژ’هˆ—و›´ه¥½م€‚
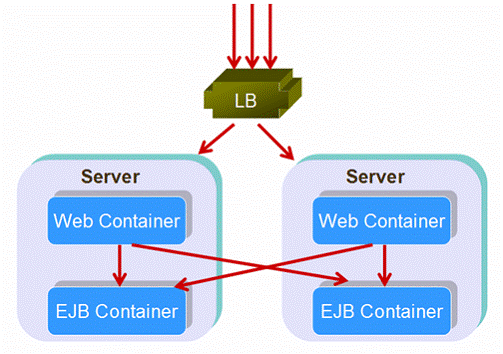
ه›¾20ï¼ڑهˆ†ه¸ƒه¼ڈ结و„
ه¦‚ه›¾20هˆ†ه¸ƒه¼ڈ结و„,ه½“请و±‚هˆ°و¥و—¶ï¼Œè´ںè½½ه‡è،،ه™¨ه°†ه®ƒن»¬هˆ†هڈ‘هˆ°ن¸چهگŒçڑ„وœچهٹ،ه™¨ن¸ٹçڑ„webه®¹ه™¨ï¼Œه¦‚请و±‚ن¸هŒ…و‹¬EJB调用,webه®¹ه™¨ه°†é‡چو–°هˆ†هڈ‘EJB调用هˆ°ه¸ƒé€ڑçڑ„EJBه®¹ه™¨م€‚è؟™و ·ï¼Œè¯·و±‚被è´ںè½½ه‡è،،ه’Œه¤±و•ˆè½¬ç§»ن؛†ن¸¤و¬،م€‚
ن¸€ن؛›ن؛؛ن¸چ看ه¥½هˆ†ه¸ƒه¼ڈ结و„,ن»–ن»¬وŒ‡ه‡؛ï¼ڑ
*第ن؛Œو¬،è´ںè½½ه‡è،،وک¯ن¸چه؟…è¦پçڑ„,ه› ن¸؛ه®ƒن¸چ能ن½؟ن»»هٹ،هˆ†é…چو›´ه‡هŒ€م€‚و¯ڈن¸ھوœچهٹ،ه™¨ه®ن¾‹هœ¨هگŒن¸€ن¸ھJVMه®ن¾‹ن¸éƒ½و‹¥وœ‰ه®ƒè‡ھه·±çڑ„webه®¹ه™¨ه’ŒEJBه®¹ه™¨م€‚让EJBه®¹ه™¨ه¤„çگ†ه…¶ه®ƒه®ن¾‹çڑ„webه®¹ه™¨çڑ„请و±‚,看ن¸چه‡؛و¯”ه®ن¾‹ه†…部调用وœ‰و›´ه¤ڑçڑ„ن¼ک点م€‚
*第ن؛Œو¬،ه¤±و•ˆè½¬ç§»وک¯ن¸چه؟…è¦پçڑ„,ه› ن¸؛ه®ƒه¹¶ن¸چه¢هٹ هڈ¯ç”¨و€§م€‚ه¤ڑو•°وڈگن¾›ه•†çڑ„ن؛§ه“پ都وک¯هœ¨هگŒن¸€JVMه®ن¾‹ن¸é›†وˆگن؛†webه®¹ه™¨ه’ŒEJBه®¹ه™¨م€‚ه¦‚وœEJBه®¹ه™¨ه¤±و•ˆï¼Œهœ¨ه¤ڑو•°وƒ…ه†µن¸‹ï¼Œwebه®¹ه™¨و¤و—¶ن¹ںوک¯ه¤±و•ˆçڑ„م€‚
*و€§èƒ½é™چن½ژن؛†م€‚设وƒ³ه؛”用ن¸çڑ„ن¸€ن¸ھو–¹و³•ه°†è°ƒç”¨ه‡ ن¸ھEJB,若ه¯¹و¯ڈن¸ھEJBè؟›è،Œè´ںè½½ه‡è،،,وœ€ç»ˆه؛”用ه®ن¾‹è·¨è¶ٹن؛†ه¾ˆه¤ڑçڑ„وœچهٹ،ه™¨ه®ن¾‹è؟گè،Œم€‚è؟™ن؛›وœچهٹ،ه™¨ه¯¹وœچهٹ،ه™¨çڑ„و¨ھè·¨é€ڑن؟،وک¯ن¸چه؟…è¦پçڑ„م€‚è؟کوœ‰ï¼Œه¦‚وœو–¹و³•هœ¨ن¸€ن¸ھن؛‹هٹ،ن¸ï¼Œن؛‹هٹ،边界ه°†هŒ…و‹¬è®¸ه¤ڑوœچهٹ،ه™¨ه®ن¾‹ï¼Œن¸¥é‡چه½±ه“چن؛†و€§èƒ½م€‚
هœ¨ه®é™…çڑ„è؟گè،Œçٹ¶و€پ,ه¤ڑو•°وڈگن¾›ه•†ï¼ˆهŒ…و‹¬Sun JES, Weblogic and JBoss)ن¼کهŒ–ن؛†EJBè´ںè½½ه‡è،،ن½؟ه¾—请و±‚首ه…ˆé€‰و‹©هœ¨هگŒن¸€ن¸ھوœچهٹ،ه™¨ن¸çڑ„EJBه®¹ه™¨م€‚用è؟™ç§چهٹو³•ï¼Œهڈھهœ¨webه±‚è؟›è،Œè´ںè½½ه‡è،،,هگژç»çڑ„وœچهٹ،都هœ¨هگŒن¸€وœچهٹ،ه™¨ن¸ٹه¤„ çگ†م€‚è؟™ç§چ结و„称ن¸؛وژ’هˆ—ه¼ڈ结و„م€‚وٹ€وœ¯ن¸ٹ说,ن¹ںوک¯هˆ†ه¸ƒه¼ڈ结و„çڑ„ن¸€ç§چم€‚
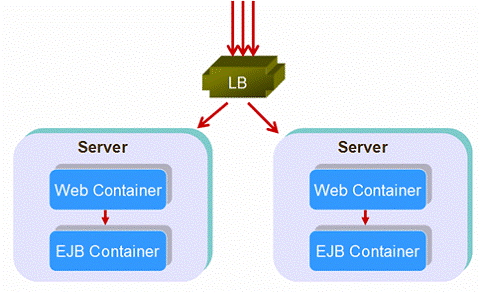
ه›¾2ï¼ڑوژ’هˆ—ه¼ڈ结و„
ن¸€ن¸ھوœ‰è¶£çڑ„é—®é¢کوک¯ï¼Œه› ن¸؛ه¤§éƒ¨هˆ†هڈ‘ه¸ƒè؟گè،Œو—¶وœ€هگژ都وˆگن¸؛ن؛†وژ’هˆ—ه¼ڈ结و„,ن¸؛ن»€ن¹ˆن¸چç›´وژ¥ن½؟用وœ¬هœ°وژ¥هڈ£ن»£و›؟è؟œç¨‹وژ¥هڈ£ï¼Œè؟™ه°†وڈگهچ‡و€§èƒ½م€‚ه½“然هڈ¯ن»¥è؟™و ·م€‚ن½†è¯·è®°ن½ڈ,ن½؟用وœ¬ هœ°وژ¥هڈ£ï¼Œweb组ن»¶ه’ŒEJBه°±ç´§ه¯†è€¦هگˆن؛†ï¼Œن½؟ه¾—و–¹و³•ç›´وژ¥è°ƒç”¨è€Œéé€ڑè؟‡IIOP/RMIم€‚è´ںè½½ه‡è،،ه™¨ه’Œه¤±و•ˆè½¬ç§»هˆ†هڈ‘ه™¨و²،وœ‰وœ؛ن¼ڑو‹¦وˆھوœ¬هœ°è°ƒç”¨ï¼Œâ€œWeb+ EJBâ€è؟‡ç¨‹ه°±è¢«ن½œن¸؛ن¸€ن¸ھو•´ن½“ن؛†م€‚
ن¸چه¹¸çڑ„وک¯ï¼Œé›†ç¾¤ن¸ï¼Œهœ¨J2EEوœچهٹ،ه™¨ن¸ٹن½؟用وœ¬هœ°وژ¥هڈ£وœ‰ه¾ˆه¤ڑé™گهˆ¶م€‚EJBوک¯ه¸¦وœ‰وœ¬هœ°وژ¥هڈ£çڑ„وœ¬هœ°ه¯¹è±،,ن½†ن»–ن»¬ن¸چهڈ¯ه؛ڈهˆ—هŒ–م€‚é™گهˆ¶ه°±وک¯وœ¬هœ°ه¼•ç”¨ن¸چه…پ许هکه‚¨هœ¨ HTTPSessionن¸م€‚ن¸€ن؛›ن؛§ه“پ,ه¦‚Sun JESهŒ؛هˆ«ه¤„çگ†وœ¬هœ°EJB,ن½؟ن»–ن»¬هڈ¯ه؛ڈهˆ—هŒ–ن¹ں能هکه‚¨هœ¨HTTPSessionن¸م€‚
هڈ¦ن¸€ن¸ھوœ‰è¶£çڑ„é—®é¢کوک¯ï¼ڑه› ن¸؛وژ’هˆ—ه¼ڈ结و„ه¾ˆوµپè،Œن¹ںوœ‰è‰¯ه¥½çڑ„و€§èƒ½ï¼Œن¸؛ن»€ن¹ˆè؟ک需è¦پهˆ†ه¸ƒه¼ڈ结و„ï¼ںه¤§ه¤ڑè‹ڈhوƒ…ه†µï¼Œن؛‹ه‡؛وœ‰ه› ,وœ‰و—¶هˆ†ه¸ƒه¼ڈ结و„ن¸چهڈ¯و›؟ن»£م€‚
*EJBن¸چن»…ن»…ç»™webه®¹ه™¨ن½؟用,ه¯Œه®¢وˆ·ç«¯ن¹ںوک¯ç”¨وˆ·ن¹‹ن¸€م€‚
*EJB组ن»¶ه’Œweb组ن»¶هڈ¯èƒ½هœ¨ن¸چهگŒçڑ„ه®‰ه…¨ç؛§هˆ«ï¼Œéœ€è¦پ物çگ†هœ°هˆ†éڑ”ه¼€و¥م€‚و‰€ن»¥ï¼Œéک²çپ«ه¢™هڈ¯èƒ½ç”¨و¥ن؟وٹ¤è؟گè،ŒEJBçڑ„و›´é‡چè¦پçڑ„وœ؛ه™¨م€‚
*Webه±‚ه’ŒEJBه±‚çڑ„وپ端ن¸چه¯¹ç§°ن¹ں许وک¯é€‰و‹©هˆ†ه¸ƒه¼ڈ结و„çڑ„ن¸€ن¸ھه¥½çگ†ç”±ï¼Œن¾‹ه¦‚,ن¸€ن؛›EJB组ن»¶ه¤ھه¤چو‚资و؛گو¶ˆè€—ه·¨ه¤§ï¼Œé‚£ن¹ˆه®ƒن»¬هڈھ能هœ¨ن¸€ن؛›وک‚è´µçڑ„ ه¤§وœچهٹ،ه™¨ن¸ٹè؟گè،Œï¼›هڈ¦ن¸€و–¹é¢ï¼Œweb组ن»¶(HTML,JSP,Servlet)éه¸¸ç®€هچ•هڈ¯ن»¥هœ¨ن¾؟ه®œçڑ„PCوœچهٹ،ه™¨ن¸ٹè؟گè،Œم€‚هœ¨è؟™ç§چو،ن»¶ن¸‹ï¼Œن¸“é—¨çڑ„webوœچهٹ،ه™¨وژ¥ و”¶ه®¢وˆ·ç«¯è¯·و±‚,وڈگن¾›é™و€پو•°وچ®ï¼ˆHTMLه’Œه›¾ç‰‡ï¼‰ه’Œç®€هچ•çڑ„web组ن»¶ï¼ˆJSPه’ŒServlet)م€‚ه¤§ه‹وœچهٹ،ه™¨هڈھ用و¥è؟›è،Œه¤چو‚è®،ç®—م€‚
8 结è®؛
集群ه’Œهچ•وœ؛çژ¯ه¢ƒوک¯ن¸چهگŒçڑ„م€‚J2EEوڈگن¾›ه•†ن»¥ن¸چهگŒçڑ„و–¹ه¼ڈه®çژ°é›†ç¾¤م€‚ن¸؛ن؛†و„ه»؛ن¸€ن¸ھه¤§ه‹çڑ„ç³»ç»ں,هœ¨é،¹ç›®ه¼€ه§‹و—¶ï¼Œن½ ه°±ه؛”该ن¸؛J2EE集群هپڑه‡†ه¤‡م€‚选و‹©هگˆé€‚çڑ„ J2EEن؛§ه“پوک¯gه’Œن½ çڑ„ه؛”用م€‚选و‹©هگˆé€‚çڑ„第ن¸‰و–¹è½¯ن»¶ه’Œو،†و¶و—¶ç،®ن؟ه®ƒن»¬هڈ¯ن»¥è¢«é›†ç¾¤م€‚然هگژ设è®،هگˆé€‚çڑ„و¶و„ن»¥ه¾—هˆ°é›†ç¾¤ه¸¦و¥çڑ„ه®é™…هˆ©ç›ٹم€‚
و¦‚è؟°
ن¸€ن¸ھ集群系ç»ںوک¯ن¸€ç¾¤و¾و•£ç»“هگˆçڑ„وœچهٹ،ه™¨ç»„,ه½¢وˆگن¸€ن¸ھè™ڑو‹ںçڑ„وœچهٹ،ه™¨ï¼Œن¸؛ه®¢وˆ·ç«¯ç”¨وˆ·وڈگن¾›ç»ںن¸€çڑ„وœچهٹ،م€‚ه¯¹ن؛ژè؟™ن¸ھه®¢وˆ·ç«¯و¥è¯´ï¼Œé€ڑه¸¸هœ¨è®؟问集群系ç»ںو—¶ن¸چن¼ڑو„ڈ识هˆ°ه®ƒçڑ„وœچهٹ،وک¯ç”±ه…·ن½“çڑ„ه“ھن¸€هڈ°وœچهٹ،ه™¨وڈگن¾›م€‚集群系ç»ںن¸€èˆ¬ه؛”ه…·é«کهڈ¯ç”¨و€§م€پهڈ¯ن¼¸ç¼©و€§م€پè´ںè½½ه‡è،،م€پو•…éڑœوپ¢ه¤چه’Œهڈ¯ç»´وٹ¤و€§ç‰ç‰¹و®ٹو€§èƒ½م€‚è¶ٹو¥è¶ٹه¤ڑçڑ„ه…³é”®ن»»هٹ،ه’Œه¤§ه‹ه؛”用و£è؟گè،Œهœ¨J2EEه¹³هڈ°ن¸ٹ,è±،银è،Œن¹‹ç±»çڑ„ه؛”用è¦پو±‚ه¾ˆé«کçڑ„هڈ¯ç”¨و€§(HA),ه¤§ه‹ç³»ç»ںو¯”ه¦‚ه¤§ه‹ç½‘ç«™هˆ™è¦پو±‚و›´ه¥½çڑ„ن¼¸ç¼©و€§م€‚J2EE集群وک¯وœ€ه¸¸ç”¨çڑ„وٹ€وœ¯ï¼Œç”¨و¥وڈگن¾›é«کهڈ¯ç”¨و€§ه’Œن¼¸ç¼©و€§çڑ„ه®¹é”™وœچهٹ،,هچ•وœ؛部署ه’Œه¤ڑوœ؛集群هŒ–部署ه·®هˆ«ه¾ˆه¤§ï¼Œç½‘ن¸ٹçڑ„资و–™ه¤§ه¤ڑè¯ç„‰ن¸چ详,هچ³ن½؟و–‡و،£ه›¾و–‡ه¹¶èŒ‚,ن¹ںوک¯هˆ°ن؛†ه…³é”®ه¤„ه°±éƒ¨ç½²وˆگهٹں,ه…¶ه®هگژé¢è؟کè¦پهپڑن؛›ه·¥ن½œو‰چè،Œï¼Œن¸”ه¤ڑن»¥هچ•وœ؛部署ه¤ڑن¸ھserverو¥و¨،و‹ں集群هŒ–部署,ه…¶ه®ه’Œçœںو£ه¤ڑوœ؛部署è؟کوک¯وœ‰و¯”较ه¤§çڑ„ه·®هˆ«م€‚وœ¬و–‡ن»…ن»¥weblogicه؛”用وœچهٹ،ه™¨ن¸؛ن¾‹è¯´وکژ集群هŒ–部署م€‚
集群ه±‚و¬،说وکژ
Webç؛§é›†ç¾¤ï¼Œوک¯J2EE集群ن¸وœ€é‡چè¦په’Œهں؛ç،€çڑ„هٹں能م€‚webه±‚集群وٹ€وœ¯هŒ…و‹¬ï¼ڑWebè´ںè½½ه‡è،،ه’ŒHTTPSessionه¤±و•ˆè½¬ç§»م€‚webè´ںè½½ه‡è،،,هں؛وœ¬çڑ„وک¯هœ¨وµڈ览ه™¨ه’Œwebوœچهٹ،ه™¨ن¹‹é—´و”¾ç½®è´ںè½½ه‡è،،ه™¨م€‚<o:p></o:p>
ه؛”用ç؛§é›†ç¾¤ï¼Œوک¯ejb集群,EJBوک¯J2EEه؛”用ه¹³هڈ°çڑ„و ¸ه؟ƒï¼ŒEJBوک¯ç”¨ن؛ژه¼€هڈ‘ه’Œéƒ¨ç½²ه…·ه¤ڑه±‚结و„çڑ„م€پهˆ†ه¸ƒه¼ڈçڑ„م€پé¢هگ‘ه¯¹è±،çڑ„Javaه؛”用系ç»ںè·¨ه¹³هڈ°çڑ„و„ن»¶ن½“系结و„م€‚ن¸»è¦پوک¯ن¸ڑهٹ،ه؛”用,部署هœ¨EJBه®¹ه™¨ن¸ٹم€‚<o:p></o:p>
و•°وچ®ه؛“ç؛§é›†ç¾¤ï¼Œوک¯oracleو•°وچ®ه؛“设置ه¤ڑن¸ھو•°وچ®ه؛“ه®ن¾‹ï¼Œه…¨éƒ¨وک ه°„هˆ°و•°وچ®ه؛“م€‚
Weblogic集群و¦‚ه؟µ
أکآ آ آ آ آ آ آ آ Domainï¼ڑç”±é…چç½®ن¸؛Administrator Serverçڑ„WebLogic Serverه®ن¾‹ç®،çگ†çڑ„逻辑هچ•ه…ƒï¼Œè؟™ن¸ھهچ•ه…ƒوک¯وœ‰و‰€وœ‰ç›¸ه…³èµ„و؛گçڑ„集هگˆم€‚
أکآ آ آ آ آ آ آ آ Serverï¼ڑ ن¸€ن¸ھ相ه¯¹ç‹¬ç«‹çڑ„,ن¸؛ه®çژ°وںگن؛›ç‰¹ه®ڑهٹں能而结هگˆهœ¨ن¸€èµ·çڑ„هچ•ه…ƒم€‚وŒ‰هٹں能هڈ¯هˆ†ن¸؛domain server ه’Œmanaged serverم€‚ن¸€ن¸ھDomain هڈ¯ن»¥هŒ…هگ«ن¸€ن¸ھوˆ–ه¤ڑن¸ھWebLogic Serverه®ن¾‹ï¼Œç”ڑ至وک¯Server集群م€‚ن¸€ن¸ھDomainن¸وœ‰ن¸€ن¸ھن¸”هڈھ能وœ‰ن¸€ن¸ھServer و‹…ن»»ç®،çگ†Serverçڑ„هٹں能,ه…¶ه®ƒçڑ„Serverه…·ن½“ه®çژ°ن¸€ن¸ھ特ه®ڑçڑ„逻辑هٹں能م€‚
أکآ آ آ آ آ آ آ آ Domainآ Serverï¼ڑهœ¨ن¸€ن¸ھ集群ن¸ï¼Œوœ‰ن¸”ن»…وœ‰ن¸€ن¸ھdomain server,هچ³ç®،çگ†server,该serverهڈھè´ںè´£ç®،çگ†ه¤ڑن¸ھManaged server(被ç®،çگ†server),هچ³domain serverن»…ن»…وک¯è،Œو”؟领ه¯¼ï¼Œè€ƒه‹¤ن¹‹ç±»çڑ„و´»هٹ¨ï¼Œه¦‚وںگن¸ھmanaged Severçڑ„çٹ¶و€پ,وک¯وœھçں¥ï¼ˆunKnown),è؟کوک¯è؟گè،Œï¼ˆrun),è؟کوک¯هپœو¢ï¼ˆshutdown),è؟œç¨‹هگ¯هٹ¨ç‰ç‰ï¼Œن¸چè´ںè´£ه…·ن½“ن¸ڑهٹ،م€‚ه› و¤éƒ¨ç½²و—¶domain serverن¸ٹن¸چè¦پ部署ه…·ن½“ن»»هٹ،,و¯•ç«ںن؛؛ه®¶وک¯ه½“ه®کçڑ„هگ—م€‚
أکآ آ آ آ آ آ آ آ Managedآ Serverï¼ڑçœںو£çڑ„ه®ه¹²ه®¶ï¼Œéƒ¨ç½²ه…·ن½“çڑ„ه؛”用م€‚ه؛”用هڈٹن¸ڑهٹ،逻辑组ن»¶è¢«هˆ†هڈ‘هœ¨ه¤ڑن¸ھهڈ—ç®،وœچهٹ،ه™¨ï¼ˆManaged Server)م€‚<o:p></o:p>
Weblogic集群è¦پو±‚
أکآ آ آ آ آ آ آ آ 集群ن¸çڑ„و‰€وœ‰Serverه؟…é،»ن½چن؛ژهگŒن¸€ç½‘و®µï¼Œه¹¶ن¸”ه؟…é،»وک¯IPه¹؟و’(UDP)هڈ¯هˆ°è¾¾çڑ„
أکآ آ آ آ آ آ آ آ 集群ن¸çڑ„و‰€وœ‰Serverه؟…é،»ن½؟用相هگŒçڑ„版وœ¬,هŒ…و‹¬Service Pack
أکآ آ آ آ آ آ آ آ 集群ن¸çڑ„Serverه؟…é،»ن½؟用و°¸ن¹…çڑ„é™و€پIPهœ°ه€م€‚هٹ¨و€پIPهœ°ه€هˆ†é…چن¸چ能用ن؛ژ集群çژ¯ه¢ƒم€‚ه¦‚وœوœچهٹ،ه™¨ن½چن؛ژéک²çپ«ه¢™هگژé¢ï¼Œè€Œه®¢وˆ·وœ؛ن½چن؛ژéک²çپ«ه¢™ه¤–é¢ï¼Œé‚£ن¹ˆوœچهٹ،ه™¨ه؟…é،»وœ‰ه…¬ه…±çڑ„é™و€پIPهœ°ه€ï¼Œهڈھوœ‰è؟™و ·ï¼Œه®¢وˆ·ç«¯و‰چ能è®؟é—®وœچهٹ،ه™¨ <o:p></o:p>
أکآ آ آ آ آ آ آ آ ن½؟用weblogicçڑ„و”¯وŒپ集群çڑ„licence<o:p></o:p>
é،¹ç›®ه®وˆک
é،¹ç›®و¦‚ه†µ
وˆ‘ن»¬çڑ„é،¹ç›®وک¯struts—ejb—hibernate—spring,ه› ن¸؛hibernateه’Œspring都ه؟…é،»è؟›è،Œهˆه§‹هŒ–ن¸”هˆه§‹هŒ–都ن¾èµ–ن؛ژservlet,هœ¨ç³»ç»ںهگ¯هٹ¨و—¶ه°±هˆه§‹هŒ–و•°وچ®ï¼Œه¹¶ن¸”وˆ‘ن»¬هœ¨webه±‚ه’Œejbه±‚هˆ†هˆ«éƒ¨ç½²ن¸؛web集群ه’Œejb集群,而hibernateه’Œspring都部署هœ¨ه؛”用وœچهٹ،ه™¨ن¸ٹم€‚ن¸؛و¤ï¼Œوˆ‘ن»¬و‰“ن؛†ن¸¤ن¸ھ部署هŒ…,ن¸€ن¸ھوک¯cnlife.war, cnlife_app.ear,ه…¶ن¸cnlife.warهŒ…部署هœ¨web集群ن¸ٹ,cnlife
_app.ear部署هœ¨ejb集群ن¸ٹ,cnlife_app.earهŒ…و‹¬ن¸¤ن¸ھهŒ…,ه…¶ن¸ن¸€ن¸ھوک¯cnlifeejb.jar(ejbهŒ…),
هڈ¦ه¤–ن¸€ن¸ھوک¯backgroudinit.war,backgroudinit.war用و¥هˆه§‹هŒ–spring,hibernateçڑ„هˆه§‹هŒ–و•°وچ®م€‚
<o:p>آ </o:p>
آ آ آ cnlife.warآ (部署هœ¨Web Server)
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ _backgroudinit.war
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ |
cnlife_app.ear-| (部署هœ¨ Application Server)
|_cnlifeejb.jar
<o:p>آ </o:p>
Ejbوک¯stateless Session bean,ن½؟用ejbçڑ„ç›®çڑ„ه°±وک¯ه؛”用وœچهٹ،ه™¨é›†ç¾¤ï¼Œéƒ¨ç½²ç¤؛و„ڈه›¾ه¦‚ن¸‹ï¼ڑ
<v:shapetype id="_x0000_t75" stroked="f" filled="f" path="m@4@5l@4@11@9@11@9@5xe" o:preferrelative="t" o:spt="75" coordsize="21600,21600"><v:stroke joinstyle="miter"></v:stroke><v:formulas><v:f eqn="if lineDrawn pixelLineWidth 0"></v:f><v:f eqn="sum @0 1 0"></v:f><v:f eqn="sum 0 0 @1"></v:f><v:f eqn="prod @2 1 2"></v:f><v:f eqn="prod @3 21600 pixelWidth"></v:f><v:f eqn="prod @3 21600 pixelHeight"></v:f><v:f eqn="sum @0 0 1"></v:f><v:f eqn="prod @6 1 2"></v:f><v:f eqn="prod @7 21600 pixelWidth"></v:f><v:f eqn="sum @8 21600 0"></v:f><v:f eqn="prod @7 21600 pixelHeight"></v:f><v:f eqn="sum @10 21600 0"></v:f></v:formulas><v:path o:connecttype="rect" gradientshapeok="t" o:extrusionok="f"></v:path><o:lock aspectratio="t" v:ext="edit"></o:lock></v:shapetype><v:shape id="_x0000_i1025" style="width: 414.75pt; height: 109.5pt;" o:ole="" type="#_x0000_t75"><v:imagedata o:title="" src="file:///C:%5CDOCUME%7E1%5CADMINI%7E1%5CLOCALS%7E1%5CTemp%5Cmsohtml1%5C01%5Cclip_image001.emz"></v:imagedata></v:shape>
Webç؛§é›†ç¾¤
Web集群ن¸ن½؟用ه†…هکه¤چهˆ¶ç–ç•¥<o:p></o:p>
weblogic.xml ه¦‚ن¸‹
<o:p></o:p>
8.1//EN" "http://www.bea.com/servers/wls810/dtd/weblogic810-web-jar.dtd"><o:p></o:p>
<o:p>آ </o:p>
<weblogic-web-app><o:p></o:p></weblogic-web-app>
آ آ آ آ آ آ آ <session-descriptor><o:p></o:p></session-descriptor>
آ &nb


- 2007-06-21 08:46
- وµڈ览 4353
- 评è®؛(1)
- وں¥çœ‹و›´ه¤ڑ
هڈ‘è،¨è¯„è®؛

-
用terracottaه®çژ° hibernate 2ç؛§ç¼“هکهˆ†ه¸ƒه¼ڈ
2007-08-03 23:53 110آ آ آ آ آ آ آ آ 看ن¸‹ hibernate و؛گç پ cache ... -
هں؛ن؛ژو—¶é—´وˆ³çڑ„缓هکو„و¶
2007-08-01 17:36 36هں؛ن؛ژو—¶é—´وˆ³çڑ„缓هکو„و¶ï¼ڑوœ€è؟‘çڑ„و•°وچ®و‹¥وœ‰وœ€ن½³çڑ„و€§èƒ½ niuji ... -
Memcachedن¸چوک¯ن¸‡èƒ½çڑ„
2007-07-20 09:02 1437آ آ آ آ آ هœ¨ه¾ˆه¤ڑو—¶ه€™ï¼Œmemcached都被و»¥ç”¨ن؛†ï¼Œè؟™ه½“然ه°‘ ... -
memcachedن¸چوک¯ن»€ن¹ˆ
2007-07-20 08:56 1193آ آ آ آ آ آ آ Memcachedوک¯danga.com(è؟گèگ¥ ... -
转贴ï¼ڑ集群هں؛ç،€
2007-06-19 14:10 1671و„é€ Clusterوک¯و¶و„ه¸ˆن»¬ه® ...
相ه…³وژ¨èچگ
3.ن»€ن¹ˆوک¯J2EE集群ï¼ں 4.WEBه±‚集群ه®çژ°8 4.1.WEBه±‚è´ںè½½ه‡è،، 4.2.HTTPن¼ڑè¯çڑ„ه¤±è´¥è½¬ç§» 4.2.1.و•°وچ®ه؛“وŒپن¹…و–¹و،ˆ 4.2.2.ه†…هکه¤چهˆ¶و–¹و،ˆ 4.2.3.Tomcatçڑ„و–¹و،ˆï¼ڑه¤ڑوœچهٹ،ه™¨ه¤چهˆ¶ 4.2.4.WebLogic, WebSphere, JBossçڑ„و–¹و،ˆï¼ڑ结ه¯¹...
J2EE集群设è®،ه¼€هڈ‘部署(هں؛ن؛ژIBM+WAS) J2EE集群设è®،ه¼€هڈ‘部署(هں؛ن؛ژIBM+WAS)
وœ¬ن¹¦ن¸چن»…详细解é‡ٹن؛†é›†ç¾¤çڑ„هں؛وœ¬وœ¯è¯ï¼Œè؟کن»‹ç»چن؛†J2EE集群çڑ„ه…·ن½“ه®çژ°ï¼ŒهŒ…و‹¬WEBه±‚م€پJNDIم€پEJBن»¥هڈٹJMSه’Œو•°وچ®ه؛“è؟وژ¥çڑ„集群و”¯وŒپ,هگŒو—¶وڈç¤؛ن؛†ن¸€ن؛›ه…³ن؛ژJ2EE集群çڑ„ه¸¸è§پ误هŒ؛م€‚ ### هں؛وœ¬وœ¯è¯ #### هڈ¯و‰©ه±•و€§ هڈ¯و‰©ه±•و€§وک¯وŒ‡ç³»ç»ں...
J2EE集群وک¯J2EEو¶و„ن¸çڑ„ن¸€ن¸ھé‡چè¦پو¦‚ه؟µï¼Œه®ƒو¶‰هڈٹهˆ°هˆ†ه¸ƒه¼ڈè®،ç®—م€پé«کهڈ¯ç”¨و€§م€پè´ںè½½ه‡è،،ه’Œو•…éڑœوپ¢ه¤چç‰ه¤ڑن¸ھو ¸ه؟ƒé¢†هںںم€‚ J2EE集群çڑ„هں؛وœ¬و€وƒ³وک¯é€ڑè؟‡ه°†ه¤ڑن¸ھوœچهٹ،ه™¨ه®ن¾‹ç»„هگˆهœ¨ن¸€èµ·ï¼Œه½¢وˆگن¸€ن¸ھه…±ن؛«èµ„و؛گه’Œوœچهٹ،çڑ„集هگˆن½“,ن»¥وڈگé«کç³»ç»ںçڑ„...
J2EE集群çڑ„هں؛وœ¬و€وƒ³وک¯ه°†هچ•ن¸ھوœچهٹ،ه™¨ه®ن¾‹و‰©ه±•هˆ°ه¤ڑن¸ھوœچهٹ،ه™¨ه®ن¾‹ï¼Œè؟™ن؛›ه®ن¾‹è¢«ç§°ن¸؛èٹ‚点م€‚è؟™ن؛›èٹ‚点هچڈهگŒه·¥ن½œï¼Œوڈگن¾›وœچهٹ،,ه¹¶ن¸”هœ¨ç³»ç»ںه‡؛çژ°و•…éڑœو—¶هڈ¯ن»¥ن؛’相ه¤‡ن»½م€‚集群çڑ„ن¸»è¦پç›®و ‡وک¯ه®çژ°è´ںè½½ه‡è،،م€پé«کهڈ¯ç”¨و€§ه’Œهڈ¯ن¼¸ç¼©و€§م€‚ 1. **...
وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨J2EE集群وٹ€وœ¯ï¼Œوڈç¤؛ه…¶و ¸ه؟ƒو¦‚ه؟µم€په®çژ°و–¹ه¼ڈن»¥هڈٹه®é™…ه؛”用ن¸çڑ„ه…³é”®è¦پ点م€‚ 首ه…ˆï¼ŒJ2EE集群وک¯ن¸€ç§چوœچهٹ،ه™¨éƒ¨ç½²و¨،ه¼ڈ,ه…¶ن¸ه¤ڑن¸ھJ2EEوœچهٹ،ه™¨ه®ن¾‹ï¼ˆèٹ‚点)هچڈهگŒه·¥ن½œï¼Œه½¢وˆگن¸€ن¸ھو•´ن½“çڑ„逻辑وœچهٹ،ه™¨م€‚集群çڑ„ن¸»è¦پç›®و ‡وک¯...
م€ٹوڈه¼€J2EE集群çڑ„ç¥ç§کé¢ç؛±م€‹وک¯و·±ه…¥çگ†è§£ن¼پن¸ڑç؛§Javaه؛”用集群部署çڑ„é‡چè¦پهڈ‚考资و–™م€‚هœ¨ن؟،وپ¯وٹ€وœ¯و—¥ç›ٹهڈ‘ه±•çڑ„ن»ٹه¤©ï¼ŒJ2EE(Java 2 Platform, Enterprise Edition)ن½œن¸؛ن¼پن¸ڑç؛§ه¼€هڈ‘çڑ„首选ه¹³هڈ°ï¼Œه…¶é›†ç¾¤وٹ€وœ¯ه¯¹ن؛ژç،®ن؟é«کهڈ¯ç”¨و€§م€پهڈ¯...
综ن¸ٹو‰€è؟°ï¼Œم€ٹوڈه¼€J2EE集群çڑ„é¢ç؛±م€‹وک¯ن¸€وœ¬ه…¨é¢ن»‹ç»چJ2EE集群وٹ€وœ¯çڑ„ن¹¦ç±چ,و— è®؛ن½ وک¯هˆه¦è€…è؟کوک¯ç»ڈéھŒن¸°ه¯Œçڑ„ه¼€هڈ‘者,都能ن»ژن¸èژ·ه¾—ه®è´µçڑ„و´è§پم€‚é€ڑè؟‡و·±ه…¥éک…读ه’Œه®è·µï¼Œن½ ه°†èƒ½ه¤ںوژŒوڈ،J2EE集群çڑ„精髓,ن»ژ而و„ه»؛ه‡؛و›´ه¼؛ه¤§م€پو›´هڈ¯é çڑ„...
وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨J2EE集群çڑ„و¦‚ه؟µم€پé‡چè¦پو€§ن»¥هڈٹه¦‚ن½•ه®çژ°ï¼Œو—¨هœ¨ه¸®هٹ©è¯»è€…çگ†è§£ه¹¶وژŒوڈ،è؟™ن¸€ه…³é”®çڑ„وٹ€وœ¯م€‚ ### ن¸€م€پJ2EE集群هں؛ç،€ J2EE集群وک¯ن¸€ç§چو¶و„و¨،ه¼ڈ,ه®ƒé€ڑè؟‡ه°†ه¤ڑن¸ھوœچهٹ،ه™¨ه®ن¾‹è؟وژ¥هœ¨ن¸€èµ·ï¼Œه½¢وˆگن¸€ن¸ھو•´ن½“,ن»¥وڈگن¾›é«کهڈ¯ç”¨و€§م€پ...
### وڈه¼€J2EE集群çڑ„ç¥ç§کé¢ç؛± #### ه؛ڈ言 éڑڈç€ن؛’èپ”网وٹ€وœ¯çڑ„ه؟«é€ںهڈ‘ه±•ï¼ŒJ2EE(Java 2 Platform, Enterprise Edition)ن½œن¸؛ن¼پن¸ڑç؛§ه؛”用ه¼€هڈ‘çڑ„و ‡ه‡†ه¹³هڈ°ن¹‹ن¸€ï¼Œهœ¨é‡‘èچم€پ电ه•†ç‰é¢†هںںه¾—هˆ°ن؛†ه¹؟و³›çڑ„ه؛”用م€‚ن¸؛ن؛†ç،®ن؟ه…³é”®ن¸ڑهٹ،ç³»ç»ںçڑ„...
م€ٹJ2EE集群وڈç§کم€‹è®²ه؛§ï¼Œوک¯ن¸€ن»½و·±ه…¥وژ¢è®¨ن¼پن¸ڑç؛§Javaه؛”用系ç»ںن¸é›†ç¾¤وٹ€وœ¯çڑ„çڈچ贵资و؛گ,ه®ƒç»“هگˆن؛†ه½•éں³è®²è§£ï¼Œن½؟ه¦ن¹ 者能ه¤ںو›´ç›´è§‚م€پو›´ç”ںهٹ¨هœ°çگ†è§£J2EE集群çڑ„و ¸ه؟ƒو¦‚ه؟µه’Œوٹ€وœ¯م€‚J2EE,ه…¨ç§°ن¸؛Java 2 Platform, Enterprise Edition...
### J2EE集群详解 #### 1. ه‰چ言 éڑڈç€ن؛’èپ”网çڑ„ه؟«é€ںهڈ‘ه±•ن¸ژن¼پن¸ڑç؛§ه؛”用çڑ„需و±‚وڈگهچ‡ï¼Œهں؛ن؛ژJava 2 Platform, Enterprise Edition (J2EE) çڑ„ه…³é”®ه؛”用ه’Œه¤§ه‹ه؛”用هڈکه¾—è¶ٹو¥è¶ٹو™®éپچم€‚ن¾‹ه¦‚,银è،Œç³»ç»ںه’Œè´¦هچ•ç³»ç»ںè؟™ç±»ه…³é”®ه؛”用需è¦پ...
### وڈه¼€J2EE集群çڑ„é¢ç؛± #### ه‰چ言 éڑڈç€ن؛’èپ”网وٹ€وœ¯çڑ„é£é€ںهڈ‘ه±•ï¼Œن¼پن¸ڑه’Œç»„织è¶ٹو¥è¶ٹن¾èµ–ن؛ژ稳ه®ڑهڈ¯é çڑ„ه؛”用程ه؛ڈو¥و”¯و’‘ه…¶ن¸ڑهٹ،è؟گن½œم€‚هœ¨è؟™و ·çڑ„背و™¯ن¸‹ï¼ŒJ2EE(Java 2 Platform, Enterprise Edition)ن½œن¸؛ن¸€ه¥—وˆگç†ںçڑ„ن¼پن¸ڑç؛§...
é€ڑè؟‡وœ¬و–‡çڑ„ن»‹ç»چ,وˆ‘ن»¬هڈ¯ن»¥çœ‹هˆ°ï¼ŒJ2EE集群وک¯ن¸€ن¸ھه¤چو‚çڑ„ç³»ç»ںه·¥ç¨‹ï¼Œو¶‰هڈٹهˆ°ن؛†ن¼—ه¤ڑوٹ€وœ¯ه’Œç–ç•¥م€‚و£ç،®çگ†è§£ه’Œè؟گ用集群وٹ€وœ¯ï¼Œه¯¹ن؛ژو„ه»؛é«کهڈ¯ç”¨م€پهڈ¯و‰©ه±•çڑ„ن¼پن¸ڑç؛§ه؛”用程ه؛ڈ至ه…³é‡چè¦پم€‚هœ¨وœھو¥çڑ„هڈ‘ه±•ن¸ï¼Œéڑڈç€وٹ€وœ¯çڑ„è؟›و¥ه’Œه؛”用هœ؛و™¯çڑ„...
وœ¬و–‡è¯¦ç»†ن»‹ç»چن؛†J2EE集群çڑ„هں؛وœ¬و¦‚ه؟µه’Œوٹ€وœ¯ه®çژ°ï¼Œوژ¢è®¨ن؛†è´ںè½½ه‡è،،م€په¤±è´¥è½¬ç§»م€پHTTPن¼ڑè¯ç®،çگ†م€پJNDI集群و”¯وŒپم€پEJB集群و”¯وŒپن»¥هڈٹJMSه’Œو•°وچ®ه؛“è؟وژ¥çڑ„集群و”¯وŒپç‰ه†…ه®¹م€‚é€ڑè؟‡ه¯¹è؟™ن؛›ه…³é”®وٹ€وœ¯ç‚¹çڑ„çگ†è§£ï¼Œهڈ¯ن»¥ه¸®هٹ©ç³»ç»ںو¶و„ه¸ˆه’Œه¼€هڈ‘...
J2EE集群هژںçگ†è¯¦è§£ J2EE集群وک¯ن¸€ç§چوٹ€وœ¯ï¼Œو—¨هœ¨وڈگé«که؛”用程ه؛ڈçڑ„هڈ¯ç”¨و€§ه’Œهڈ¯ن¼¸ç¼©و€§ï¼Œé€ڑè؟‡ه°†ه·¥ن½œè´ںè½½هˆ†و•£هˆ°ه¤ڑن¸ھوœچهٹ،ه™¨ن¸ٹه®çژ°è´ںè½½ه‡è،،,ه¹¶ç،®ن؟هœ¨هچ•ن¸ھوœچهٹ،ه™¨ه‡؛çژ°و•…éڑœو—¶ï¼Œوœچهٹ،ن»چ能و£ه¸¸è؟گè،Œï¼Œè؟™ç§°ن¸؛ه¤±è´¥وژ¥ç®،م€‚集群çڑ„و ¸ه؟ƒو¦‚ه؟µ...