
дЇСиЃ°зЃЧеТМHadoopдЄ≠зљСзїЬжШѓиЃ®иЃЇеЊЧзЫЄеѓєжѓФиЊГе∞СзЪДйҐЖеЯЯгАВжЬђжЦЗеОЯжЦЗзФ±DellдЉБдЄЪжКАжЬѓдЄУеЃґBrad HedlundжТ∞еЖЩпЉМдїЦжЫЊеЬ®жАЭзІСеЈ•дљЬе§ЪеєіпЉМдЄУйХњжШѓжХ∞жНЃдЄ≠ењГгАБдЇСзљСзїЬз≠ЙгАВжЦЗзЂ†зі†жЭРеЯЇдЇОдљЬиАЕиЗ™еЈ±зЪДз†Фз©ґгАБеЃЮй™МеТМClouderaзЪДеЯєиЃ≠иµДжЦЩгАВ
жЬђжЦЗе∞ЖзЭАйЗНдЇОиЃ®иЃЇHadoopйЫЖзЊ§зЪДдљУз≥їзїУжЮДеТМжЦєж≥ХпЉМеПКеЃГе¶ВдљХдЄОзљСзїЬеТМжЬНеК°еЩ®еЯЇз°АиЃЊжЦљзЪДеЕ≥з≥їгАВжЬАеЉАеІЛжИСдїђеЕИе≠¶дє†дЄАдЄЛHadoopйЫЖзЊ§ињРдљЬзЪДеЯЇз°АеОЯзРЖгАВ
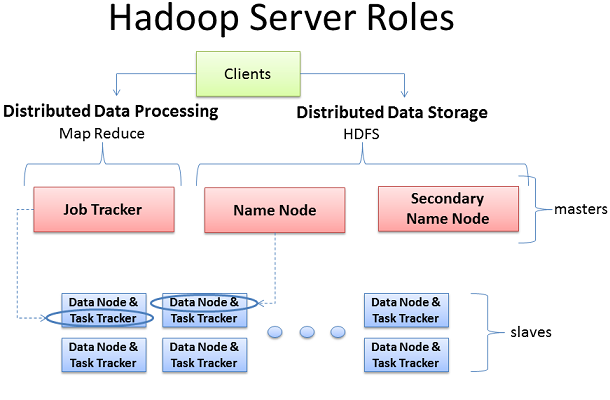
HadoopйЗМзЪДжЬНеК°еЩ®иІТиЙ≤
HadoopдЄїи¶БзЪДдїїеК°йГ®зљ≤еИЖдЄЇ3дЄ™йГ®еИЖпЉМеИЖеИЂжШѓпЉЪClientжЬЇеЩ®пЉМдЄїиКВзВєеТМдїОиКВзВєгАВдЄїиКВзВєдЄїи¶БиіЯиі£HadoopдЄ§дЄ™еЕ≥йФЃеКЯиГљж®°еЭЧHDFSгАБMap ReduceзЪДзЫСзЭ£гАВељУJob TrackerдљњзФ®Map ReduceињЫи°МзЫСжОІеТМи∞ГеЇ¶жХ∞жНЃзЪДеєґи°Ме§ДзРЖжЧґпЉМеРНзІ∞иКВзВєеИЩиіЯиі£HDFSзЫСиІЖеТМи∞ГеЇ¶гАВдїОиКВзВєиіЯиі£дЇЖжЬЇеЩ®ињРи°МзЪДзїЭе§ІйГ®еИЖпЉМжЛЕељУжЙАжЬЙжХ∞жНЃеВ®е≠ШеТМжМЗдї§иЃ°зЃЧзЪДиЛ¶еЈЃгАВжѓПдЄ™дїОиКВзВєжЧҐжЙЃжЉФиАЕжХ∞жНЃиКВзВєзЪДиІТиЙ≤еПИеЖ≤ељУдЄОдїЦдїђдЄїиКВзВєйАЪдњ°зЪДеЃИжК§ињЫз®ЛгАВеЃИжК§ињЫз®ЛйЪґе±ЮдЇОJob TrackerпЉМжХ∞жНЃиКВзВєеЬ®ељТе±ЮдЇОеРНзІ∞иКВзВєгАВ
ClientжЬЇеЩ®йЫЖеРИдЇЖHadoopдЄКжЙАжЬЙзЪДйЫЖзЊ§иЃЊзљЃпЉМдљЖжЧҐдЄНеМЕжЛђдЄїиКВзВєдєЯдЄНеМЕжЛђдїОиКВзВєгАВеПЦиАМдї£дєЛзЪДжШѓеЃҐжИЈзЂѓжЬЇеЩ®зЪДдљЬзФ®жШѓжККжХ∞жНЃеК†иљљеИ∞йЫЖзЊ§дЄ≠пЉМйАТдЇ§зїЩMap ReduceжХ∞жНЃе§ДзРЖеЈ•дљЬзЪДжППињ∞пЉМеєґеЬ®еЈ•дљЬзїУжЭЯеРОеПЦеЫЮжИЦиАЕжЯ•зЬЛзїУжЮЬгАВеЬ®е∞ПзЪДйЫЖзЊ§дЄ≠пЉИе§ІзЇ¶40дЄ™иКВзВєпЉЙеПѓиГљдЉЪйЭҐеѓєеНХзЙ©зРЖиЃЊе§Зе§ДзРЖе§ЪдїїеК°пЉМжѓФе¶ВеРМжЧґJob TrackerеТМеРНзІ∞иКВзВєгАВдљЬдЄЇе§ІйЫЖзЊ§зЪДдЄ≠йЧідїґпЉМдЄАиИђжГЕеЖµдЄЛйГљжШѓзФ®зЛђзЂЛзЪДжЬНеК°еЩ®еОїе§ДзРЖеНХдЄ™дїїеК°гАВ
еЬ®зЬЯж≠£зЪДдЇІеУБйЫЖзЊ§дЄ≠жШѓж≤°жЬЙиЩЪжЛЯжЬНеК°еЩ®еТМзЃ°зРЖе±ВзЪДе≠ШеЬ®зЪДпЉМињЩж†Је∞±ж≤°жЬЙдЇЖе§ЪдљЩзЪДжАІиГљжНЯиАЧгАВHadoopеЬ®Linuxз≥їзїЯдЄКињРи°МзЪДжЬАе•љпЉМзЫіжО•жУНдљЬеЇХе±Вз°ђдїґиЃЊжЦљгАВињЩе∞±иѓіжШОHadoopеЃЮйЩЕдЄКжШѓзЫіжО•еЬ®иЩЪжЛЯжЬЇдЄКеЈ•дљЬгАВињЩж†ЈеЬ®иК±иієгАБжШУе≠¶жАІеТМйАЯеЇ¶дЄКжЬЙзЭАжЧ†дЄОдЉ¶жѓФзЪДдЉШеКњгАВ
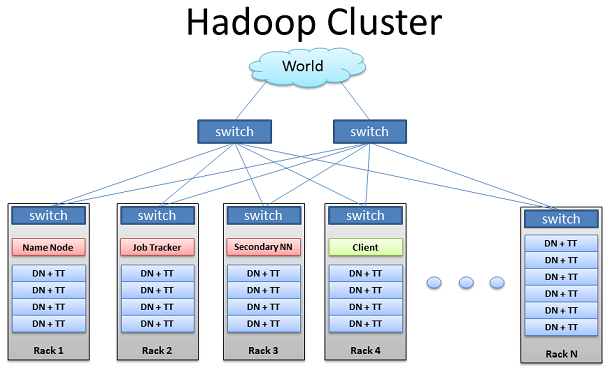
HadoopйЫЖзЊ§
дЄКйЭҐжШѓдЄАдЄ™еЕЄеЮЛHadoopйЫЖзЊ§зЪДжЮДйА†гАВдЄАз≥їеИЧжЬЇжЮґйАЪињЗе§ІйЗПзЪДжЬЇжЮґиљђжНҐдЄОжЬЇжЮґеЉПжЬНеК°еЩ®пЉИдЄНжШѓеИАзЙЗжЬНеК°еЩ®пЉЙињЮжО•иµЈжЭ•пЉМйАЪеЄЄдЉЪзФ®1GBжИЦиАЕ2GBзЪДеЃљеЄ¶жЭ•жФѓжТСињЮжО•гАВ10GBзЪДеЄ¶еЃљиЩљзДґдЄНеЄЄиІБпЉМдљЖжШѓеНіиГљжШЊиСЧзЪДжПРйЂШCPUж†ЄењГеТМз£БзЫШй©±еК®еЩ®зЪДеѓЖйЫЖжАІгАВдЄКдЄАе±ВзЪДжЬЇжЮґиљђжНҐдЉЪдї•зЫЄеРМзЪДеЄ¶еЃљеРМжЧґињЮжО•зЭАиЃЄе§ЪжЬЇжЮґпЉМ嚥жИРйЫЖзЊ§гАВе§ІйЗПжЛ•жЬЙиЗ™иЇЂз£БзЫШеВ®е≠ШеЩ®гАБCPUеПКDRAMзЪДжЬНеК°еЩ®е∞ЖжИРдЄЇдїОиКВзВєгАВеРМж†ЈжЬЙдЇЫжЬЇеЩ®е∞ЖжИРдЄЇдЄїиКВзВєпЉМињЩдЇЫжЛ•жЬЙе∞СйЗПз£БзЫШеВ®е≠ШеЩ®зЪДжЬЇеЩ®еНіжЬЙзЭАжЫіењЂзЪДCPUеПКжЫіе§ІзЪДDRAMгАВ
дЄЛйЭҐжИСдїђжЭ•зЬЛдЄАдЄЛеЇФзФ®з®ЛеЇПжШѓжАОж†ЈињРдљЬзЪДеРІпЉЪ

adoopзЪДеЈ•дљЬжµБз®Л
еЬ®иЃ°зЃЧжЬЇи°МдЄЪзЂЮдЇЙе¶Вж≠§жњАзГИзЪДжГЕеЖµдЄЛпЉМз©ґзЂЯдїАдєИжШѓHadoopзЪДзФЯе≠ШдєЛйБУпЉЯеЃГеПИеИЗеЃЮзЪДиІ£еЖ≥дЇЖдїАдєИйЧЃйҐШпЉЯзЃАиАМи®АдєЛпЉМеХЖдЄЪеПКжФњеЇЬйГље≠ШеЬ®е§ІйЗПзЪДжХ∞жНЃйЬАи¶Б襀圀йАЯзЪДеИЖжЮРеТМе§ДзРЖгАВжККињЩдЇЫе§ІеЭЧзЪДжХ∞жНЃеИЗеЉАпЉМзДґеРОеИЖзїЩе§ІйЗПзЪДиЃ°зЃЧжЬЇпЉМиЃ©иЃ°зЃЧжЬЇеєґи°МзЪДе§ДзРЖињЩдЇЫжХ∞жНЃ вАФ ињЩе∞±жШѓHadoopиГљеБЪзЪДгАВ
дЄЛйЭҐињЩдЄ™зЃАеНХзЪДдЊЛе≠РйЗМпЉМжИСдїђе∞ЖжЬЙдЄАдЄ™еЇЮе§ІзЪДжХ∞жНЃжЦЗдїґпЉИзїЩеЃҐжЬНйГ®йЧ®зЪДзФµе≠РйВЃдїґпЉЙгАВжИСжГ≥ењЂйАЯзЪДжИ™еПЦдЄЛвАЬRefundвАЭеЬ®йВЃдїґдЄ≠еЗЇзО∞зЪДжђ°жХ∞гАВињЩжШѓдЄ™зЃАеНХзЪДе≠ЧжХ∞зїЯиЃ°зїГдє†гАВClientе∞ЖжККжХ∞жНЃеК†иљљеИ∞йЫЖзЊ§дЄ≠пЉИFile.txtпЉЙпЉМжПРдЇ§жХ∞жНЃеИЖжЮРеЈ•дљЬзЪДжППињ∞пЉИword coutпЉЙпЉМйЫЖзЊ§е∞ЖдЉЪжККзїУжЮЬеВ®е≠ШеИ∞дЄАдЄ™жЦ∞зЪДжЦЗдїґдЄ≠пЉИResults.txtпЉЙпЉМзДґеРОClientе∞±дЉЪиѓїзїУжЮЬжЦЗж°£гАВ
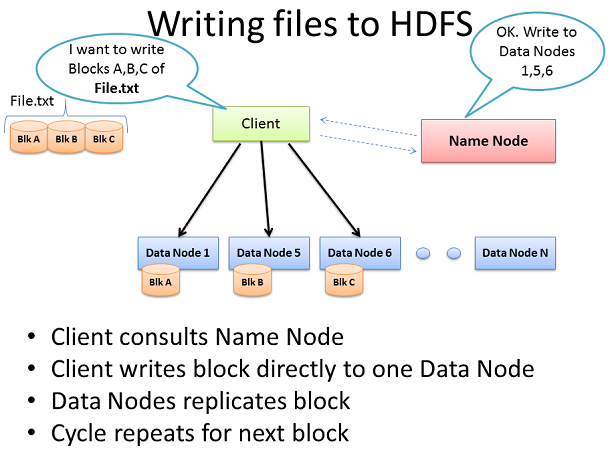
еРСHDFSйЗМеЖЩеЕ•File
HadoopйЫЖзЊ§еЬ®ж≤°жЬЙж≥®еЕ•жХ∞жНЃдєЛеЙНжШѓдЄНиµЈдљЬзФ®зЪДпЉМжЙАдї•жИСдїђеЕИдїОеК†иљљеЇЮе§ІзЪДFile.txtеИ∞йЫЖзЊ§дЄ≠еЉАеІЛгАВй¶Ци¶БзЪДзЫЃж†ЗељУзДґжШѓжХ∞жНЃењЂйАЯзЪДеєґи°Ме§ДзРЖгАВдЄЇдЇЖеЃЮзО∞ињЩдЄ™зЫЃж†ЗпЉМжИСдїђйЬАи¶БзЂЯеПѓиГље§ЪзЪДжЬЇеЩ®еРМжЧґеЈ•дљЬгАВжЬАеРОпЉМClientе∞ЖжККжХ∞жНЃеИЖжИРжЫіе∞ПзЪДж®°еЭЧпЉМзДґеРОеИЖеИ∞дЄНеРМзЪДжЬЇеЩ®дЄКиіѓз©њжХідЄ™йЫЖзЊ§гАВж®°еЭЧеИЖзЪДиґКе∞ПпЉМеБЪжХ∞жНЃеєґи°Ме§ДзРЖзЪДжЬЇеЩ®е∞±иґКе§ЪгАВеРМжЧґињЩдЇЫжЬЇеЩ®жЬЇеЩ®ињШеПѓиГљеЗЇжХЕйЪЬпЉМжЙАдї•дЄЇдЇЖйБњеЕНжХ∞ж́䪥姱е∞±йЬАи¶БеНХдЄ™жХ∞жНЃеРМжЧґеЬ®дЄНеРМзЪДжЬЇеЩ®дЄКе§ДзРЖгАВжЙАдї•жѓПеЭЧжХ∞жНЃйГљдЉЪеЬ®йЫЖзЊ§дЄК襀йЗНе§НзЪДеК†иљљгАВHadoopзЪДйїШиЃ§иЃЊзљЃжШѓжѓПеЭЧжХ∞жНЃйЗНе§НеК†иљљ3жђ°гАВињЩдЄ™еПѓдї•йАЪињЗhdfs-site.xmlжЦЗдїґдЄ≠зЪДdfs.replicationеПВжХ∞жЭ•иЃЊзљЃгАВ
ClientжККFile.txtжЦЗдїґеИЖжИР3еЭЧгАВCientдЉЪеТМеРНзІ∞иКВзВєиЊЊжИРеНПиЃЃпЉИйАЪеЄЄжШѓTCP 9000еНПиЃЃпЉЙзДґеРОеЊЧеИ∞е∞Жи¶БжЛЈиіЭжХ∞жНЃзЪД3дЄ™жХ∞жНЃиКВзВєеИЧи°®гАВзДґеРОClientе∞ЖдЉЪжККжѓПеЭЧжХ∞жНЃзЫіжО•еЖЩеЕ•жХ∞жНЃиКВзВєдЄ≠пЉИйАЪеЄЄжШѓTCP 50010еНПиЃЃпЉЙгАВжФґеИ∞жХ∞жНЃзЪДжХ∞жНЃиКВзВєе∞ЖдЉЪжККжХ∞жНЃе§НеИґеИ∞еЕґдїЦжХ∞жНЃиКВзВєдЄ≠пЉМеЊ™зОѓеП™еИ∞жЙАжЬЙжХ∞жНЃиКВзВєйГљеЃМжИРжЛЈиіЭдЄЇж≠ҐгАВеРНзІ∞иКВзВєеП™иіЯиі£жПРдЊЫжХ∞жНЃзЪДдљНзљЃеТМжХ∞жНЃеЬ®жЧПзЊ§дЄ≠зЪДеОїе§ДпЉИжЦЗдїґз≥їзїЯеЕГжХ∞жНЃпЉЙгАВ
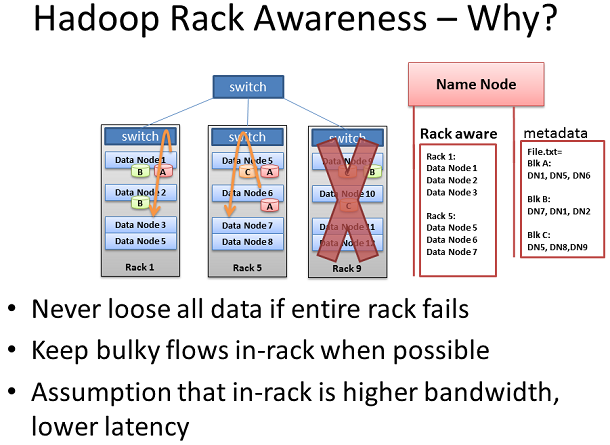
HadoopзЪДRack Awareness
HadoopињШжЛ•жЬЙвАЬRack AwarenessвАЭзЪДзРЖењµгАВдљЬдЄЇHadoopзЪДзЃ°зРЖеСШпЉМдљ†еПѓдї•еЬ®йЫЖзЊ§дЄ≠иЗ™и°МзЪДеЃЪдєЙдїОиКВзВєзЪДжЬЇжЮґжХ∞йЗПгАВдљЖжШѓдЄЇдїАдєИињЩж†ЈеБЪдЉЪзїЩдљ†еЄ¶жЭ•йЇїзГ¶еСҐпЉЯдЄ§дЄ™еЕ≥йФЃзЪДеОЯеЫ†жШѓпЉЪжХ∞жНЃжНЯ姱йҐДйШ≤еПКзљСзїЬжАІиГљгАВеИЂењШдЇЖпЉМдЄЇдЇЖйШ≤ж≠ҐжХ∞ж́䪥姱пЉМжѓПеЭЧжХ∞жНЃйГљдЉЪжЛЈиіЭеЬ®е§ЪдЄ™жЬЇеЩ®дЄКгАВеБЗе¶ВеРМдЄАеЭЧжХ∞жНЃзЪДе§ЪдЄ™жЛЈиіЭйГљеЬ®еРМдЄАдЄ™жЬЇжЮґдЄКпЉМиАМжБ∞еЈІзЪДжШѓињЩдЄ™жЬЇжЮґеЗЇзО∞дЇЖжХЕйЪЬпЉМйВ£дєИињЩеЄ¶жЭ•зЪДзїЭеѓєжШѓдЄАеЫҐз≥ЯгАВдЄЇдЇЖйШїж≠ҐињЩж†ЈзЪДдЇЛжГЕеПСзФЯпЉМеИЩењЕй°їжЬЙдЇЇзЯ•йБУжХ∞жНЃиКВзВєзЪДдљНзљЃпЉМеєґж†єжНЃеЃЮйЩЕжГЕеЖµеЬ®йЫЖзЊ§дЄ≠дљЬеЗЇжШОжЩЇзЪДдљНзљЃеИЖйЕНгАВињЩдЄ™дЇЇе∞±жШѓеРНзІ∞иКВзВєгАВ
еБЗдљњйАЪдЄ™жЬЇжЮґдЄ≠дЄ§еП∞жЬЇеЩ®еѓєжѓФдЄНеРМжЬЇжЮґзЪДдЄ§еП∞жЬЇеЩ®дЉЪжЬЙжЫіе§ЪзЪДеЄ¶еЃљжЫідљОзЪДеїґжЧґгАВе§ІйГ®еИЖжГЕеЖµдЄЛињЩжШѓзЬЯеЃЮе≠ШеЬ®зЪДгАВжЬЇжЮґиљђжНҐзЪДдЄКи°МеЄ¶еЃљдЄАиИђйГљдљОдЇОеЕґдЄЛи°МеЄ¶еЃљгАВж≠§е§ЦпЉМжЬЇжЮґеЖЕзЪДйАЪдњ°зЪДеїґжЧґдЄАиИђйГљдљОдЇОиЈ®жЬЇжЮґзЪДпЉИдєЯдЄНжШѓеЕ®йГ®пЉЙгАВйВ£дєИеБЗе¶ВHadoopиГљеЃЮзО∞вАЬRack AwarenessвАЭзЪДзРЖењµпЉМйВ£дєИеЬ®йЫЖзЊ§жАІиГљдЄКжЧ†зЦСдЉЪжЬЙзЭАжШЊиСЧзЪДжПРеНЗпЉБжШѓзЪДпЉМеЃГзЬЯзЪДеБЪеИ∞дЇЖпЉБ姙ж£ТдЇЖпЉМеѓєдЄНеѓєпЉЯ
дљЖжШѓжЙЂеЕізЪДдЇЛжГЕеПСзФЯдЇЖпЉМй¶Цжђ°дљњзФ®дљ†ењЕй°їжЙЛеК®зЪДеОїеЃЪдєЙеЃГгАВдЄНжЦ≠зЪДдЉШеМЦпЉМдњЭжМБдњ°жБѓзЪДеЗЖз°ЃгАВеБЗе¶ВжЬЇжЮґиљђжНҐиГље§ЯиЗ™еК®зЪДзїЩеРНзІ∞иКВзВєжПРдЊЫеЃГзЪДжХ∞жНЃиКВзВєеИЧи°®пЉМињЩж†ЈеПИеЃМзЊОдЇЖпЉЯжИЦиАЕеПНињЗжЭ•пЉМжХ∞жНЃиКВзВєеПѓдї•иЗ™и°МзЪДеСКзЯ•еРНзІ∞иКВзВєдїЦдїђжЙАињЮжО•зЪДжЬЇжЮґиљђжНҐпЉМињЩж†ЈдєЯзЪДиѓЭдєЯеРМж†ЈеЃМзЊОгАВ
еЬ®жЛђи°•зїУжЮДдЄ≠зљСзїЬдЄ≠пЉМеБЗе¶ВиГљзЯ•йБУеРНзІ∞иКВзВєеПѓдї•йАЪињЗOpenFlowжОІеИґеЩ®жߕ胥еИ∞иКВзВєзЪДдљНзљЃпЉМйВ£жЧ†зЦСжШѓжЫіеК†дї§дЇЇеЕіе•ЛзЪДгАВ
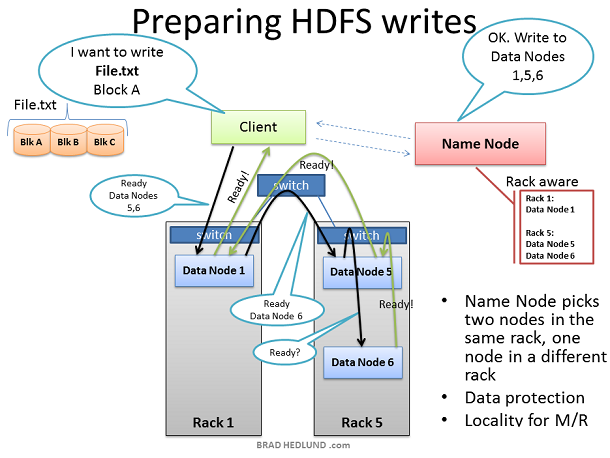
еЗЖе§ЗHDFSеЖЩеЕ•
зО∞еЬ®ClientеЈ≤зїПжККFile.txtеИЖеЭЧеєґеБЪе•љдЇЖеРСйЫЖзЊ§дЄ≠еК†иљљзЪДеЗЖе§ЗпЉМдЄЛйЭҐеЕИдїОBlock AеЉАеІЛгАВClientеРСеРНзІ∞иКВзВєеПСеЗЇеЖЩFile.txtзЪДиѓЈж±ВпЉМдїОеРНзІ∞иКВзВєе§ДиОЈеЊЧйАЪи°МиѓБпЉМзДґеРОеЊЧеИ∞жѓПеЭЧжХ∞жНЃзЫЃж†ЗжХ∞жНЃиКВзВєзЪДеИЧи°®гАВеРНзІ∞иКВзВєдљњзФ®иЗ™еЈ±зЪДRack AwarenessжХ∞жНЃжЭ•жФєеПШжХ∞жНЃиКВзВєжПРдЊЫеИЧи°®гАВж†ЄењГиІДеИЩе∞±жШѓеѓєдЇОжѓПеЭЧжХ∞жНЃ3дїљжЛЈиіЭпЉМжАїжЬЙдЄ§дїље≠ШеЬ®еРМдЄАдЄ™жЬЇжЮґдЄКпЉМеП¶е§ЦдЄАдїљеИЩењЕй°їжФЊеИ∞еП¶дЄАдЄ™жЬЇжЮґдЄКгАВжЙАдї•зїЩClientзЪДеИЧи°®йГљењЕй°їйБµдїОињЩдЄ™иІДеИЩгАВ
еЬ®Clientе∞ЖFile.txtзЪДвАЬBlock AвАЭйГ®еИЖеЖЩеЕ•йЫЖзЊ§дєЛеЙНпЉМClientињШжЬЯеЊЕзЯ•йБУжЙАжЬЙзЪДзЫЃж†ЗжХ∞жНЃиКВзВєжШѓеР¶еЈ≤еЗЖе§Зе∞±зї™гАВеЃГе∞ЖеПЦеЗЇеИЧи°®дЄ≠зїЩBlock AеЗЖе§ЗзЪДзђђдЄАдЄ™жХ∞жНЃиКВзВєпЉМжЙУеЉАTCP 50010еНПиЃЃпЉМеєґеСКиѓЙжХ∞жНЃиКВзВєпЉМж≥®жДПпЉБеЗЖе§Зе•љжО•жФґ1еЭЧжХ∞жНЃпЉМињЩйЗМињШжЬЙдЄАдїљеИЧи°®еМЕжЛђдЇЖжХ∞жНЃиКВзВє5еТМжХ∞жНЃиКВзВє6пЉМз°ЃдњЭдїЦдїђеРМж†ЈеЈ≤еЗЖе§Зе∞±зї™гАВзДґеРОеЖНзФ±1дЉ†иЊЊеИ∞5пЉМжО•зЭА5дЉ†иЊЊеИ∞6гАВ
жХ∞жНЃиКВзВєе∞ЖдїОеРМж†ЈзЪДTCPйАЪйБУдЄ≠еУНеЇФдЄКдЄАзЇІзЪДеСљдї§пЉМеП™еИ∞ClientжФґеИ∞еОЯеІЛжХ∞жНЃиКВзВє1еПСйАБзЪДзЪДвАЬе∞±зї™вАЭгАВеП™еИ∞ж≠§еИїпЉМClientжЙНзЬЯж≠£зЪДеЗЖе§ЗеЬ®йЫЖзЊ§дЄ≠еК†иљљжХ∞жНЃеЭЧгАВ
 
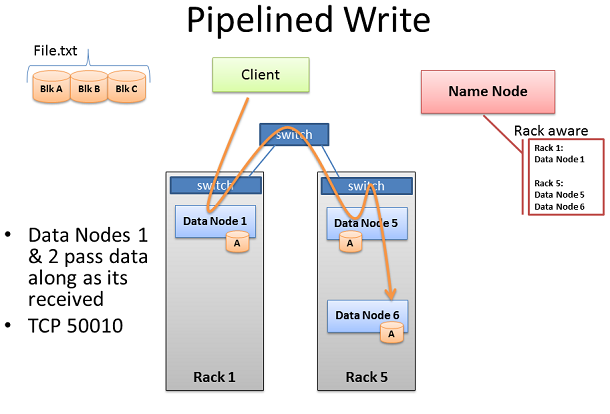
HDFSиљљеЕ•йАЪйБУ
ељУжХ∞жНЃеЭЧеЖЩеЕ•йЫЖзЊ§еРОпЉМ3дЄ™пЉИељУзДґжХ∞жНЃиКВзВєдЄ™жХ∞еПВзЕІдЄКжЦЗзЪДиЃЊзљЃпЉЙжХ∞жНЃиКВзВєе∞ЖжЙУеЉАдЄАдЄ™еРМж≠•йАЪйБУгАВињЩе∞±жДПеС≥зЭАпЉМељУдЄАдЄ™жХ∞жНЃиКВзВєжО•жФґеИ∞жХ∞жНЃеРОпЉМеЃГеРМжЧґе∞ЖеЬ®йАЪйБУдЄ≠зїЩдЄЛдЄАдЄ™жХ∞жНЃиКВзВєйАБдЄКдЄАдїљжЛЈиіЭгАВ
ињЩйЗМеРМж†ЈжШѓдЄАдЄ™еАЯеК©Rack AwarenessжХ∞жНЃжПРеНЗйЫЖзЊ§жАІиГљзЪДдЊЛе≠РгАВж≥®жДПеИ∞ж≤°жЬЙпЉМзђђдЇМдЄ™еТМзђђдЄЙдЄ™жХ∞жНЃиКВзВєињРиЊУеЬ®еРМдЄАдЄ™жЬЇжЮґдЄ≠пЉМињЩж†ЈдїЦдїђдєЛйЧізЪДдЉ†иЊУе∞±иОЈеЊЧдЇЖйЂШеЄ¶еЃљеТМдљОеїґжЧґгАВеП™еИ∞ињЩдЄ™жХ∞жНЃеЭЧ襀жИРеКЯзЪДеЖЩеЕ•3дЄ™иКВзВєдЄ≠пЉМдЄЛдЄАдЄ™е∞±жЙНдЉЪеЉАеІЛгАВ
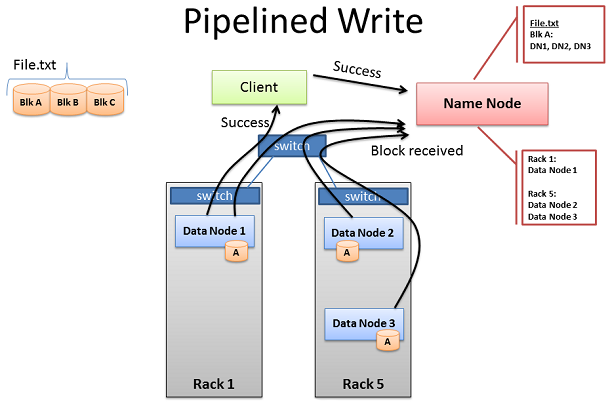
HDFSйАЪйБУиљљеЕ•жИРеКЯ
ељУ3дЄ™иКВзВєйГљжИРеКЯзЪДжО•жФґеИ∞жХ∞жНЃеЭЧеРОпЉМдїЦдїђе∞ЖзїЩеРНзІ∞иКВзВєеПСйАБдЄ™вАЬBlock ReceivedвАЭжК•еСКгАВеєґеРСйАЪйБУињФеЫЮвАЬSuccessвАЭжґИжБѓпЉМзДґеРОеЕ≥йЧ≠TCPеЫЮиѓЭгАВClientжФґеИ∞жИРеКЯжО•жФґзЪДжґИжБѓеРОдЉЪжК•еСКзїЩеРНзІ∞иКВзВєжХ∞жНЃеЈ≤жИРеКЯжО•жФґгАВеРНзІ∞иКВзВєе∞ЖдЉЪжЫіжЦ∞еЃГеЕГжХ∞жНЃдЄ≠зЪДиКВзВєдљНзљЃдњ°жБѓгАВClientе∞ЖдЉЪеЉАеРѓдЄЛдЄАдЄ™жХ∞жНЃеЭЧзЪДе§ДзРЖйАЪйБУпЉМеП™еИ∞жЙАжЬЙзЪДжХ∞жНЃеЭЧйГљеЖЩеЕ•жХ∞жНЃиКВзВєгАВ
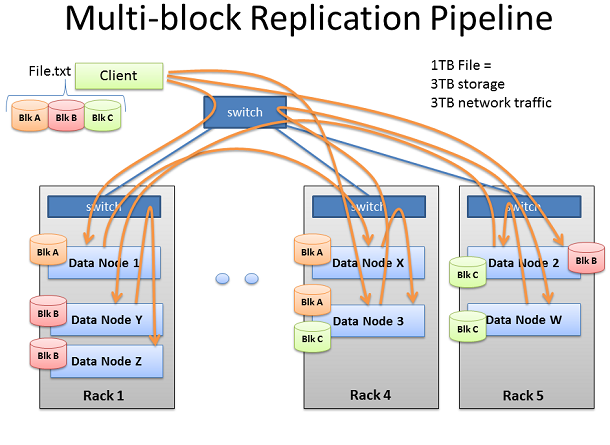
HadoopдЉЪдљњзФ®е§ІйЗПзЪДзљСзїЬеЄ¶еЃљеТМе≠ШеВ®гАВжИСдїђе∞Ждї£и°®жАІзЪДе§ДзРЖдЄАдЇЫTBзЇІеИЂзЪДжЦЗдїґгАВдљњзФ®HadoopзЪДйїШиЃ§йЕНзљЃпЉМжѓПдЄ™жЦЗдїґйГљдЉЪ襀е§НеИґдЄЙдїљгАВдєЯе∞±жШѓ1TBзЪДжЦЗдїґе∞ЖиАЧиіє3TBзЪДзљСзїЬдЉ†иЊУеПК3TBзЪДз£БзЫШз©ЇйЧігАВ
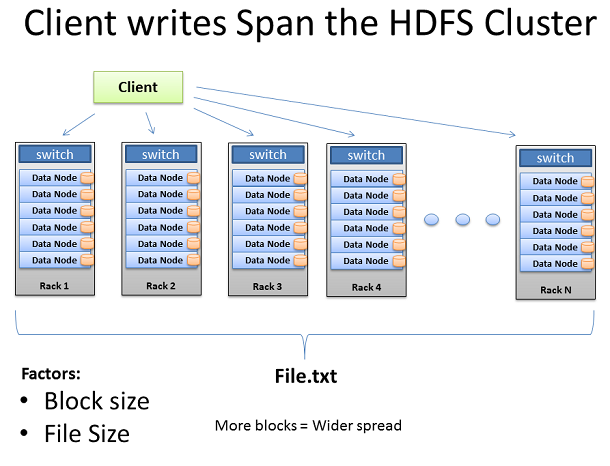
ClientеЖЩеЕ•иЈ®еЇ¶йЫЖзЊ§
жѓПдЄ™еЭЧзЪДе§НеИґзЃ°йБУеЃМжИРеРОзЪДжЦЗ俴襀жИРеКЯеЖЩеЕ•еИ∞йЫЖзЊ§гАВе¶ВйҐДжЬЯзЪДжЦЗ俴襀жХ£еЄГеЬ®жХідЄ™йЫЖзЊ§зЪДжЬЇеЩ®пЉМжѓПеП∞жЬЇеЩ®жЬЙдЄАдЄ™зЫЄеѓєиЊГе∞ПзЪДйГ®еИЖжХ∞жНЃгАВдЄ™жЦЗдїґзЪДеЭЧжХ∞иґКе§ЪпЉМжЫіе§ЪзЪДжЬЇеЩ®зЪДжХ∞жНЃжЬЙеПѓиГљдЉ†жТ≠гАВжЫіе§ЪзЪДCPUж†ЄењГеТМз£БзЫШй©±еК®еЩ®пЉМжДПеС≥зЭАжХ∞жНЃиГљеЊЧеИ∞жЫіе§ЪзЪДеєґи°Ме§ДзРЖиГљеКЫеТМжЫіењЂзЪДзїУжЮЬгАВињЩжШѓеїЇйА†е§ІеЮЛзЪДгАБеЃљзЪДйЫЖзЊ§зЪДиГМеРОзЪДеК®жЬЇпЉМдЄЇдЇЖжХ∞жНЃе§ДзРЖжЫіе§ЪгАБжЫіењЂгАВељУжЬЇеЩ®жХ∞еҐЮеК†еТМйЫЖзЊ§еҐЮеЃљжЧґпЉМжИСдїђзЪДзљСзїЬйЬАи¶БињЫи°МйАВељУзЪДжЙ©е±ХгАВ
жЙ©е±ХйЫЖзЊ§зЪДеП¶дЄАзІНжЦєж≥ХжШѓжЈ±еЕ•гАВе∞±жШѓеЬ®дљ†зЪДжЬЇеЩ®жЙ©е±ХжЫіе§ЪдЄ™з£БзЫШй©±еК®еЩ®еТМжЫіе§ЪзЪДCPUж†ЄењГпЉМиАМдЄНжШѓеҐЮеК†жЬЇеЩ®зЪДжХ∞йЗПгАВеЬ®жЙ©е±ХжЈ±еЇ¶дЄКпЉМдљ†жККиЗ™еЈ±зЪДж≥®жДПеКЫйЫЖдЄ≠еЬ®зФ®иЊГе∞СзЪДжЬЇеЩ®жЭ•жї°иґ≥жЫіе§ЪзЪДзљСзїЬI/OйЬАж±ВдЄКгАВеЬ®ињЩдЄ™ж®°еЮЛдЄ≠пЉМдљ†зЪДHadoopйЫЖзЊ§е¶ВдљХињЗжЄ°еИ∞дЄЗеЕЖ俕姙зљСиКВзВєжИРдЄЇдЄАдЄ™йЗНи¶БзЪДиАГиЩСеЫ†зі†гАВ
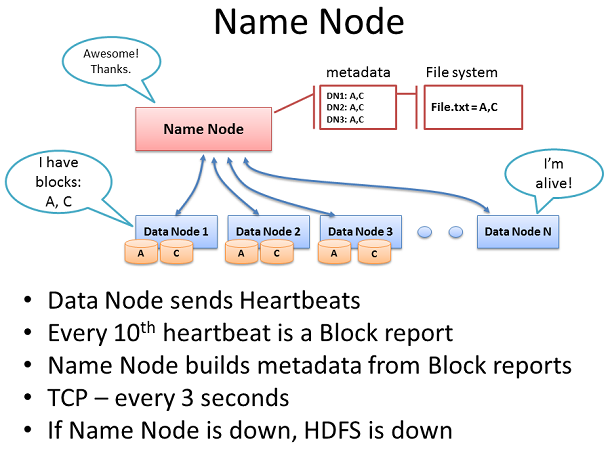
еРНзІ∞иКВзВє
еРНзІ∞иКВзВєеМЕеРЂжЙАжЬЙйЫЖзЊ§зЪДжЦЗдїґз≥їзїЯеЕГжХ∞жНЃеТМзЫСзЭ£еБ•еЇЈзКґеЖµзЪДжХ∞жНЃиКВзВєдї•еПКеНПи∞ГеѓєжХ∞жНЃзЪДиЃњйЧЃгАВињЩдЄ™еРНе≠ЧиКВзВєжШѓHDFSзЪДдЄ≠е§ЃжОІеИґеЩ®гАВеЃГжЬђиЇЂдЄНжЛ•жЬЙдїїдљХйЫЖзЊ§жХ∞жНЃгАВињЩдЄ™еРНзІ∞иКВзВєеП™зЯ•йБУеЭЧжЮДжИРдЄАдЄ™жЦЗдїґпЉМеєґеЬ®ињЩдЇЫеЭЧдљНдЇОйЫЖзЊ§дЄ≠гАВ
жХ∞жНЃиКВзВєжѓП3зІТйАЪињЗTCPдњ°еПЈдЇ§жНҐеРСеРНзІ∞иКВзВєеПСйАБж£АжµЛдњ°еПЈпЉМдљњзФ®зЫЄеРМзЪДзЂѓеП£еПЈеЃЪдєЙеРНзІ∞иКВзВєеЃИжК§ињЫз®ЛпЉМйАЪеЄЄTCP 9000гАВжѓП10дЄ™ж£АжµЛдњ°еПЈдљЬдЄЇдЄАдЄ™еЭЧжК•еСКпЉМйВ£йЗМзЪДжХ∞жНЃиКВзВєеСКзЯ•еЃГзЪДжЙАжЬЙеЭЧзЪДеРНзІ∞иКВзВєгАВеЭЧжК•еСКеЕБиЃЄеРНзІ∞иКВзВєжЮДеїЇеЃГзЪДеЕГжХ∞жНЃеТМз°ЃдњЭзђђдЄЙеЭЧеЙѓжЬђе≠ШеЬ®дЄНеРМзЪДжЬЇжЮґдЄКе≠ШеЬ®дЇОдЄНеРМзЪДиКВзВєдЄКгАВ
еРНзІ∞иКВзВєжШѓHadoopеИЖеЄГеЉПжЦЗдїґз≥їзїЯпЉИHDFSпЉЙзЪДдЄАдЄ™еЕ≥йФЃзїДдїґгАВж≤°жЬЙеЃГпЉМеЃҐжИЈзЂѓе∞ЖжЧ†ж≥ХдїОHDFSеЖЩеЕ•жИЦиѓїеПЦжЦЗдїґпЉМеЃГе∞±дЄНеПѓиГљеОїи∞ГеЇ¶еТМжЙІи°МMap ReduceеЈ•дљЬгАВж≠£еЫ†дЄЇе¶Вж≠§пЉМзФ®еПМзФµжЇРгАБзГ≠жПТжЛФй£ОжЙЗгАБеЖЧдљЩзљСеН°ињЮжО•з≠Йз≠ЙжЭ•и£Ее§ЗеРНзІ∞иКВзВєеТМйЕНзљЃйЂШеЇ¶еЖЧдљЩзЪДдЉБдЄЪзЇІжЬНеК°еЩ®дљњдЄАдЄ™дЄНйФЩзЪДжГ≥ж≥ХгАВ
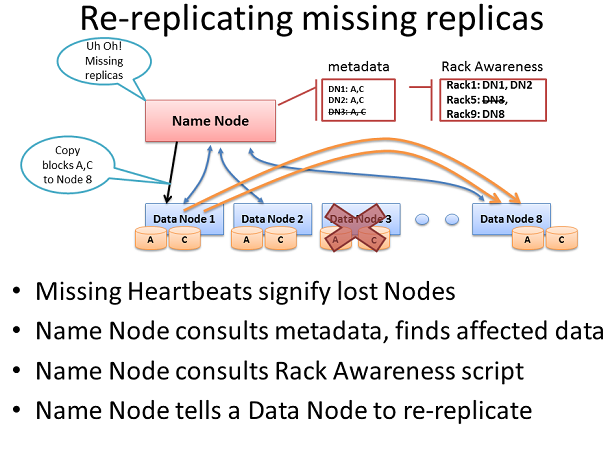
йЗНжЦ∞е§Неȴ犯姱еЙѓжЬђ
е¶ВжЮЬеРНзІ∞иКВзВєеБЬж≠ҐдїОдЄАдЄ™жХ∞жНЃиКВзВєжО•жФґж£АжµЛдњ°еПЈпЉМеБЗеЃЪеЃГеЈ≤зїПж≠їдЇ°пЉМдїїдљХжХ∞жНЃењЕй°їдєЯжґИ姱дЇЖгАВеЯЇдЇОеЭЧдїОж≠їдЇ°иКВзВєжО•еПЧеИ∞жК•еСКпЉМињЩдЄ™еРНзІ∞иКВзВєзЯ•йБУеУ™дЄ™еЙѓжЬђињЮеРМиКВзВєеЭЧж≠їдЇ°пЉМеєґеПѓеЖ≥еЃЪйЗНжЦ∞е§НеИґињЩдЇЫеЭЧеИ∞еЕґдїЦжХ∞жНЃиКВзВєгАВеЃГињШе∞ЖеПВиАГжЬЇжЮґжДЯзЯ•жХ∞жНЃпЉМдї•дњЭжМБеЬ®дЄАдЄ™жЬЇжЮґеЖЕзЪДдЄ§дЄ™еЙѓжЬђгАВ
иАГиЩСдЄАдЄЛињЩдЄ™еЬЇжЩѓпЉМжХідЄ™жЬЇжЮґзЪДжЬНеК°еЩ®зљСзїЬиД±иРљпЉМдєЯиЃЄжШѓеЫ†дЄЇдЄАдЄ™жЬЇжЮґдЇ§жНҐжЬЇжХЕйЪЬжИЦзФµжЇРжХЕйЪЬгАВињЩдЄ™еРНзІ∞иКВзВєе∞ЖеЉАеІЛжМЗз§ЇйЫЖзЊ§дЄ≠зЪДеЕґдљЩиКВзВєйЗНжЦ∞е§НеИґиѓ•жЬЇжЮґдЄ≠䪥姱зЪДжЙАжЬЙжХ∞жНЃеЭЧгАВе¶ВжЮЬеЬ®йВ£дЄ™жЬЇжЮґдЄ≠зЪДжѓПдЄ™жЬНеК°еЩ®жЬЙ12TBзЪДжХ∞жНЃпЉМињЩеПѓиГљжШѓжХ∞зЩЊдЄ™TBзЪДжХ∞жНЃйЬАи¶БеЉАеІЛз©њиґКзљСзїЬгАВ
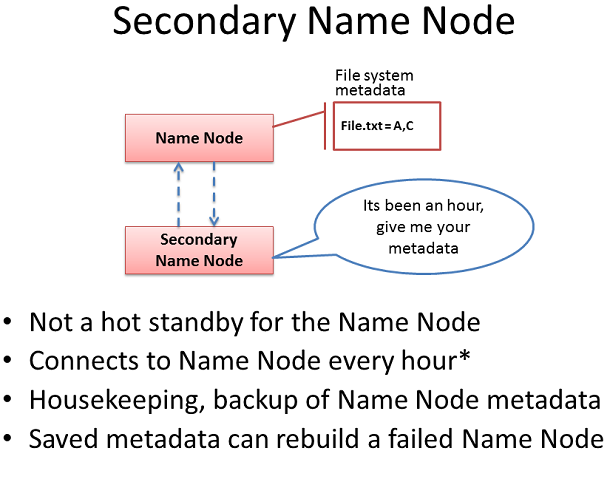
дЇМзЇІеРНзІ∞иКВзВє
HadoopжЬНеК°еЩ®иІТиЙ≤襀зІ∞дЄЇдЇМзЇІеРНзІ∞иКВзВєгАВдЄАдЄ™еЄЄиІБзЪДиѓѓиІ£жШѓпЉМињЩдЄ™иІТиЙ≤дЄЇеРНзІ∞иКВзВєжПРдЊЫдЇЖдЄАдЄ™йЂШеПѓзФ®жАІзЪДе§ЗдїљпЉМињЩеєґйЭЮе¶Вж≠§гАВ
дЇМзЇІеРНзІ∞иКВзВєеБґе∞ФињЮжО•еИ∞еРНе≠ЧиКВзВєпЉМеєґиОЈеПЦдЄАдЄ™еЙѓжЬђзЪДеРНе≠ЧиКВзВєеЖЕе≠ШдЄ≠зЪДеЕГжХ∞жНЃеТМжЦЗдїґзФ®дЇОе≠ШеВ®еЕГжХ∞жНЃгАВдЇМзЇІеРНзІ∞иКВзВєеЬ®дЄАдЄ™жЦ∞зЪДжЦЗдїґйЫЖдЄ≠зїУеРИињЩдЇЫдњ°жБѓпЉМеєґе∞ЖеЕґйАТйАБеЫЮеРНзІ∞иКВзВєпЉМеРМжЧґиЗ™иЇЂдњЭзХЩдЄАдїље§НжЬђгАВ
е¶ВжЮЬеРНзІ∞иКВзВєж≠їдЇ°пЉМдЇМзЇІеРНзІ∞иКВзВєдњЭзХЩзЪДжЦЗдїґеПѓзФ®дЇОжБҐе§НеРНзІ∞иКВзВєгАВ
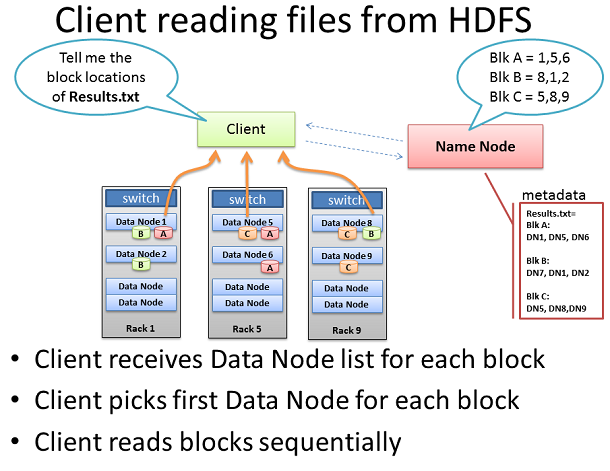
дїОHDFSеЃҐжИЈзЂѓиѓїеПЦ
ељУеЃҐжИЈжГ≥и¶БдїОHDFSиѓїеПЦдЄАдЄ™жЦЗдїґпЉМеЃГеЖНдЄАжђ°еҮ胥еРНзІ∞иКВзВєпЉМеєґи¶Бж±ВжПРдЊЫжЦЗдїґеЭЧзЪДдљНзљЃгАВ
еЃҐжИЈдїОжѓПдЄ™еЭЧеИЧи°®йАЙжЛ©дЄАдЄ™жХ∞жНЃиКВзВєеТМзФ®TCPзЪД50010зЂѓеП£иѓїеПЦдЄАдЄ™еЭЧгАВзЫіеИ∞еЙНеЭЧеЃМжИРпЉМеЃГжЙНдЉЪињЫеЕ•дЄЛдЄАдЄ™еЭЧгАВ
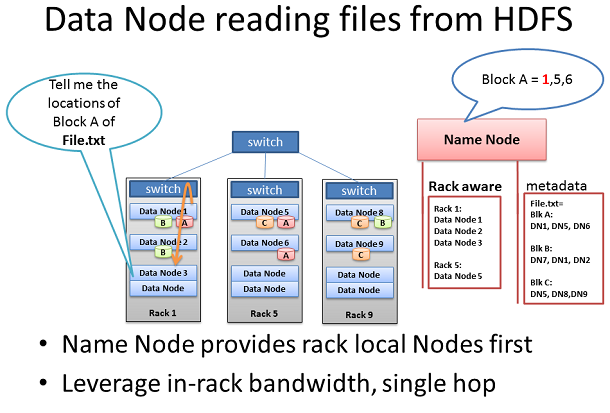
дїОHDFSдЄ≠иѓїеПЦжХ∞жНЃиКВзВє
жЬЙдЇЫжГЕеЖµдЄЛпЉМдЄАдЄ™жХ∞жНЃиКВзВєеЃИжК§ињЫз®ЛжЬђиЇЂйЬАи¶БдїОHDFSдЄ≠иѓїеПЦжХ∞жНЃеЭЧгАВдЄАзІНињЩж†ЈзЪДжГЕеЖµжШѓжХ∞жНЃиКВзº襀и¶Бж±Ве§ДзРЖжЬђеЬ∞ж≤°жЬЙзЪДжХ∞жНЃпЉМеЫ†ж≠§еЃГењЕй°їдїОзљСзїЬдЄКзЪДеП¶дЄАдЄ™жХ∞жНЃиКВзВєж£А糥жХ∞жНЃпЉМеЬ®еЃГеЉАеІЛе§ДзРЖдєЛеЙНгАВ
еП¶дЄАдЄ™йЗНи¶БзЪДдЊЛе≠РжШѓињЩдЄ™еРНзІ∞иКВзВєзЪДRack AwarenessиЃ§зЯ•жПРдЊЫдЇЖжЬАдљ≥зЪДзљСзїЬи°МдЄЇгАВељУжХ∞жНЃиКВзº胥йЧЃжХ∞жНЃеЭЧйЗМеРНзІ∞иКВзВєзЪДдљНзљЃжЧґпЉМеРНзІ∞иКВзВєе∞Жж£АжЯ•жШѓеР¶еЬ®еРМдЄАжЬЇжЮґдЄ≠зЪДеП¶дЄАзІНжХ∞жНЃиКВзВєжЬЙжХ∞жНЃгАВе¶ВжЮЬжШѓињЩж†ЈпЉМињЩдЄ™еРНзІ∞иКВзВєдїОж£А糥жХ∞жНЃйЗМжПРдЊЫдЇЖжЬЇжЮґдЄКзЪДдљНзљЃгАВиѓ•жµБз®ЛдЄНйЬАи¶БйБНеОЖдЄ§дЄ™дї•дЄКзЪДдЇ§жНҐжЬЇеТМжЛ•жМ§зЪДйУЊжО•жЙЊеИ∞еП¶дЄАдЄ™жЬЇжЮґдЄ≠зЪДжХ∞жНЃгАВеЬ®жЬЇжЮґдЄКж£А糥зЪДжХ∞жНЃжЫіењЂпЉМжХ∞жНЃе§ДзРЖе∞±еПѓдї•еЉАеІЛзЪДжЫіжЧ©пЉМ,еЈ•дљЬеЃМжИРеЊЧжЫіењЂгАВ
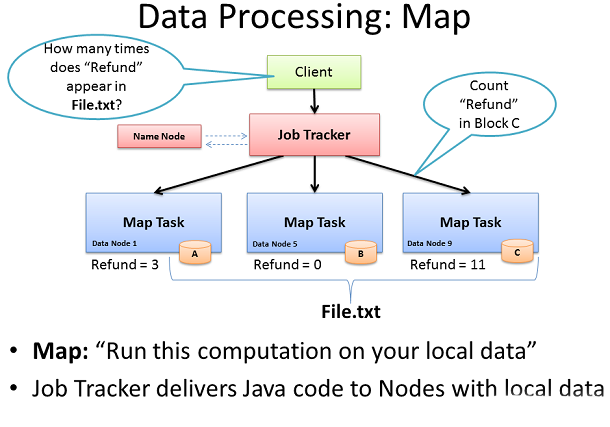
Map Task
зО∞еЬ®file.txtеЬ®жИСзЪДжЬЇеЩ®йЫЖзЊ§дЄ≠иФУеїґпЉМжИСжЬЙжЬЇдЉЪжПРдЊЫжЮБеЕґењЂйАЯеТМйЂШжХИзЪДеєґи°Ме§ДзРЖзЪДжХ∞жНЃгАВеМЕеРЂHadoopзЪДеєґи°Ме§ДзРЖж°Жж޴襀зІ∞дЄЇMap ReduceпЉМж®°еЮЛдЄ≠еСљеРНдєЛеРОзЪДдЄ§дЄ™ж≠•й™§жШѓMapеТМReduceгАВ
зђђдЄАж≠•жШѓMapињЗз®ЛгАВињЩе∞±жШѓжИСдїђеРМжЧґи¶Бж±ВжИСдїђзЪДжЬЇеЩ®дїЦдїђжЬђеЬ∞зЪДжХ∞жНЃеЭЧдЄКжЭ•ињРи°МдЄАдЄ™иЃ°зЃЧгАВеЬ®ињЩзІНжГЕеЖµдЄЛпЉМжИСдїђи¶Бж±ВжИСдїђзЪДжЬЇеЩ®еѓєвАЬRefundвАЭињЩдЄ™иѓНеЬ®File.txtзЪДжХ∞жНЃеЭЧдЄ≠еЗЇзО∞зЪДжђ°жХ∞ињЫи°МиЃ°жХ∞гАВ
еЉАеІЛж≠§ињЗз®ЛпЉМеЃҐжИЈзЂѓжЬЇеЩ®жПРдЇ§Map ReduceдљЬдЄЪзЪДJob TrackerпЉМ胥йЧЃвАЬе§Ъе∞Сжђ°дЄНдЉЪеЬ®File.txt дЄ≠еЗЇзО∞RefundвАЭ(жДПиѓСJavaдї£з†Б)гАВJob Trackerжߕ胥еРНзІ∞иКВзВєдЇЖиІ£еУ™дЇЫжХ∞жНЃиКВзВєжЬЙFile.txtеЭЧгАВJob TrackerжПРдЊЫдЇЖињЩдЇЫиКВзВєдЄКињРи°МзЪДTask TrackerдЄОJavaдї£з†БйЬАи¶БеЬ®дїЦдїђзЪДжЬђеЬ∞жХ∞жНЃдЄКжЙІи°МзЪДMapиЃ°зЃЧгАВињЩдЄ™Task TrackerеРѓеК®дЄАдЄ™MapдїїеК°еТМзЫСиІЖдїїеК°ињЫе±ХгАВињЩTask TrackerжПРдЊЫдЇЖж£АжµЛдњ°еПЈеєґеРСJob TrackerињФеЫЮдїїеК°зКґжАБгАВ
жѓПдЄ™MapдїїеК°еЃМжИРеРОпЉМжѓПдЄ™иКВзВєеЬ®еЕґдЄіжЧґжЬђеЬ∞е≠ШеВ®дЄ≠е≠ШеВ®еЕґжЬђеЬ∞иЃ°зЃЧзЪДзїУжЮЬгАВињЩ襀зІ∞дљЬвАЬдЄ≠йЧіжХ∞жНЃвАЭгАВ дЄЛдЄАж≠•е∞ЖйАЪињЗзљСзїЬдЉ†иЊУеПСйАБж≠§дЄ≠йЧіжХ∞жНЃеИ∞ReduceдїїеК°жЬАзїИиЃ°зЃЧиКВзВєдЄКињРи°МгАВ
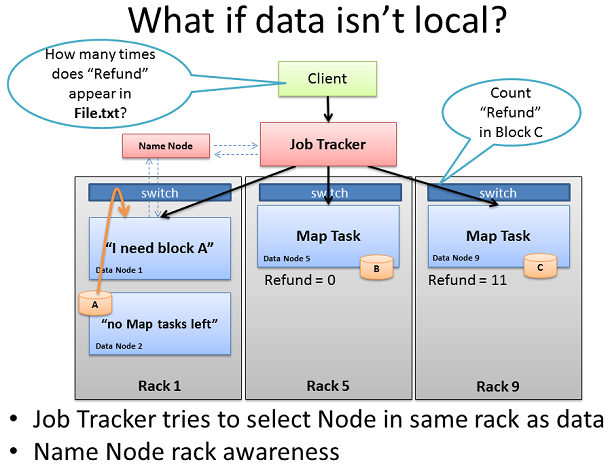
Map TaskйЭЮжЬђеЬ∞
иЩљзДґJob TrackerжАїжШѓиѓХеЫЊйАЙжЛ©дЄОељУеЬ∞жХ∞жНЃеБЪMap taskзЪДиКВзВєпЉМдљЖеЃГеПѓиГљеєґдЄНжАїжШѓиГље§ЯињЩж†ЈеБЪгАВеЕґдЄ≠дЄАдЄ™еОЯеЫ†еПѓиГљжШѓеЫ†дЄЇжЙАжЬЙзЪДиКВзВєдЄОжЬђеЬ∞жХ∞жНЃпЉМеЈ≤зїПжЬЙ姙е§ЪзЪДеЕґдїЦдїїеК°ињРи°МпЉМеєґдЄФдЄНиГљжО•еПЧдЇЖгАВ
еЬ®ињЩзІНжГЕеЖµдЄЛ, Job Trackerе∞ЖжЯ•йШЕеРНзІ∞иКВзВєзЪДRack AwarenessзЯ•иѓЖпЉМеПѓжО®иНРеРМдЄАжЬЇжЮґдЄ≠зЪДеЕґдїЦиКВзВєзЪДеРНзІ∞иКВзВєгАВдљЬдЄЪиЈЯиЄ™еЩ®е∞ЖжККињЩдЄ™дїїеК°дЇ§зїЩеРМдЄАжЬЇжЮґдЄ≠зЪДдЄАдЄ™иКВзВєпЉМиКВзВєеОїеѓїжЙЊзЪДжХ∞жНЃжЧґпЉМеЃГйЬАи¶БзЪДеРНзІ∞иКВзВєе∞ЖжМЗз§ЇеЕґжЬЇжЮґдЄ≠зЪДеП¶дЄАдЄ™иКВзВєжЭ•иОЈеПЦжХ∞жНЃгАВ
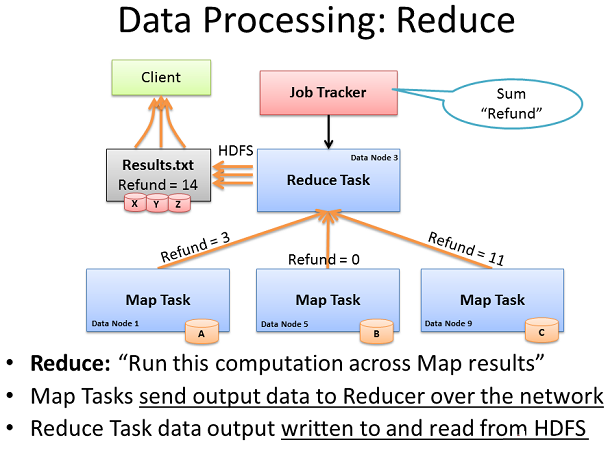
Reduce TaskдїОMap TasksиЃ°зЃЧжО•жФґеИ∞зЪДжХ∞жНЃ
зђђдЇМйШґжЃµзЪДMap Reduceж°ЖжЮґзІ∞дЄЇReduceгАВжЬЇеЩ®дЄКзЪДMapдїїеК°еЈ≤зїПеЃМжИРдЇЖеТМзФЯжИРеЃГдїђзЪДдЄ≠йЧіжХ∞жНЃгАВзО∞еЬ®жИСдїђйЬАи¶БжФґйЫЖжЙАжЬЙзЪДињЩдЇЫдЄ≠йЧіжХ∞жНЃпЉМзїДеРИеєґжПРзЇѓдї•дЊњињЫдЄАж≠•е§ДзРЖпЉМињЩж†ЈжИСдїђдЉЪжЬЙдЄАдЄ™жЬАзїИзїУжЮЬгАВ
Job TrackerеЬ®йЫЖзЊ§дЄ≠зЪДдїїдљХдЄАдЄ™иКВзВєдЄКеЉАеІЛдЄАдЄ™ReduceдїїеК°пЉМеєґжМЗз§ЇReduceдїїеК°дїОжЙАжЬЙеЈ≤еЃМжИРзЪДMapдїїеК°дЄ≠иОЈеПЦдЄ≠йЧіжХ∞жНЃгАВMapдїїеК°еПѓиГљеЗ†дєОеРМжЧґеЇФеѓєReducerпЉМеѓЉиЗіиЃ©дљ†дЄАдЄЛе≠РжЬЙе§ІйЗПзЪДиКВзВєеПСйАБTCPжХ∞жНЃеИ∞дЄАдЄ™иКВзВєгАВињЩзІНжµБйЗПзКґеЖµйАЪ媪襀зІ∞дЄЇвАЬIncastвАЭжИЦиАЕвАЬfan-inвАЭгАВеѓєдЇОзљСзїЬе§ДзРЖе§ІйЗПзЪДincastжЭ°дїґпЉМеЕґйЗНи¶БзЪДзљСзїЬдЇ§жНҐжЬЇжЛ•жЬЙз≤ЊењГиЃЊиЃ°зЪДеЖЕйГ®жµБйЗПзЃ°зРЖиГљеКЫпЉМдї•еПКиґ≥е§ЯзЪДзЉУеЖ≤еМЇпЉИдЄН姙姲дєЯдЄНиÚ姙е∞ПпЉЙгАВ
ReducerдїїеК°зО∞еЬ®еЈ≤зїПдїОMapдїїеК°йЗМжФґйЫЖдЇЖжЙАжЬЙзЪДдЄ≠йЧіжХ∞жНЃпЉМеПѓдї•еЉАеІЛжЬАеРОзЪДиЃ°зЃЧйШґжЃµгАВеЬ®жЬђдЊЛдЄ≠пЉМжИСдїђеП™йЬАжЈїеК†еЗЇзО∞вАЬRefundвАЭињЩдЄ™иѓНзЪДжАїжХ∞пЉМеєґе∞ЖзїУжЮЬеЖЩеЕ•еИ∞дЄАдЄ™еРНдЄЇResultsзЪДtxtжЦЗдїґйЗМгАВ
ињЩдЄ™еРНдЄЇResultsзЪДtxtжЦЗдїґпЉМ襀еЖЩеЕ•еИ∞HDFSдї•дЄЛжИСдїђеЈ≤зїПжґµзЫЦзЪДињЫз®ЛдЄ≠пЉМжККжЦЗдїґеИЖжИРеЭЧпЉМжµБж∞ізЇње§НеИґињЩдЇЫеЭЧз≠ЙгАВељУеЃМжИРжЧґпЉМеЃҐжИЈжЬЇеПѓдї•дїОHDFSеТМ襀聧䪯жШѓеЃМжХізЪДеЈ•дљЬйЗМиѓїеПЦResults.txtгАВ
жИСдїђзЃАеНХзЪДе≠ЧжХ∞зїЯиЃ°еЈ•дљЬеєґдЄНдЉЪеѓЉиЗіе§ІйЗПзЪДдЄ≠йЧіжХ∞жНЃеЬ®зљСзїЬдЄКдЉ†иЊУгАВзДґиАМпЉМеЕґдїЦеЈ•дљЬеПѓиГљдЉЪдЇІзФЯе§ІйЗПзЪДдЄ≠йЧіжХ∞жНЃпЉМжѓФе¶ВеѓєTBзЇІжХ∞жНЃињЫи°МжОТеЇПгАВ
е¶ВжЮЬдљ†жШѓдЄАдЄ™еЛ§е•ЛзЪДзљСзїЬзЃ°зРЖеСШпЉМдљ†е∞ЖдЇЖиІ£жЫіе§ЪеЕ≥дЇОMap ReduceеТМдљ†зЪДйЫЖзЊ§е∞ЖињРи°МзЪДдљЬдЄЪз±їеЮЛпЉМдї•еПКдљЬдЄЪз±їеЮЛе¶ВдљХељ±еУНдљ†зЪДзљСзїЬжµБйЗПгАВе¶ВжЮЬдљ†жШѓдЄАдЄ™HadoopзљСзїЬжШОжШЯпЉМдљ†зФЪиЗ≥иГље§ЯжПРеЗЇжЫіе•љзЪДдї£з†БжЭ•иІ£еЖ≥Map ReduceдїїеК°пЉМдї•дЉШеМЦзљСзїЬзЪДжАІиГљпЉМдїОиАМеК†ењЂеЈ•дљЬеЃМеЈ•жЧґйЧігАВ
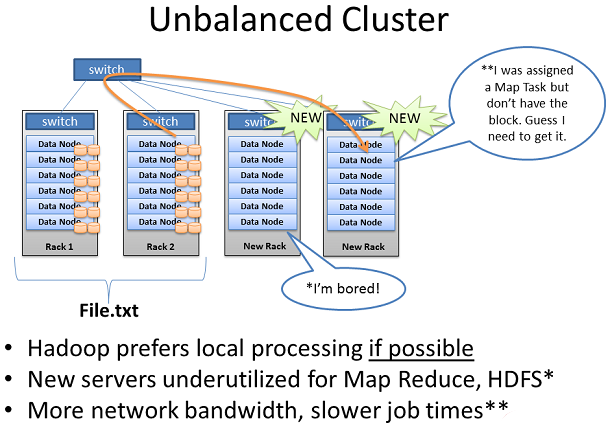
дЄНеє≥и°°зЪДHadoopйЫЖзЊ§
HadoopеПѓдї•дЄЇдљ†зЪДзїДзїЗжПРдЊЫдЄАдЄ™зЬЯж≠£зЪДжИРеКЯпЉМеЃГиЃ©дљ†иЇЂиЊєзЪДжХ∞жНЃеЉАеПСеЗЇдЇЖеЊИе§ЪдєЛеЙНжЬ™еПСзО∞зЪДдЄЪеК°дїЈеАЉгАВељУдЄЪеК°дЇЇеСШдЇЖиІ£ињЩдЄАзВєпЉМдљ†еПѓдї•з°Ѓдњ°пЉМеЊИењЂе∞±дЉЪжЬЙжЫіе§ЪзЪДйТ±дЄЇдљ†зЪДHadoopйЫЖзЊ§иі≠дє∞жЫіе§ЪжЬЇжЮґжЬНеК°еЩ®еТМзљСзїЬгАВ
ељУдљ†еЬ®зО∞жЬЙзЪДHadoopйЫЖзЊ§йЗМжЈїеК†жЦ∞зЪДжЬЇжЮґжЬНеК°еЩ®еТМзљСзїЬињЩзІНжГЕеЖµжЧґпЉМдљ†зЪДйЫЖзЊ§жШѓдЄНеє≥и°°зЪДгАВеЬ®ињЩзІНжГЕеЖµдЄЛпЉМжЬЇжЮґ1&2жШѓжИСзО∞жЬЙзЪДеМЕеРЂFile.txtзЪДжЬЇжЮґеТМињРи°МжИСзЪДMap ReduceдїїеК°зЪДжХ∞жНЃгАВељУжИСжЈїеК†дЇЖдЄ§дЄ™жЦ∞зЪДжЮґеИ∞йЫЖзЊ§пЉМжИСзЪДFile.txtжХ∞жНЃеєґдЄНдЉЪиЗ™еК®еЉАеІЛиФУеїґеИ∞жЦ∞зЪДжЬЇжЮґгАВ
жЦ∞зЪДжЬНеК°еЩ®жШѓйЧ≤зљЃзЪДпЉМзЫіеИ∞жИСеЉАеІЛеК†иљљжЦ∞жХ∞жНЃеИ∞йЫЖзЊ§дЄ≠гАВж≠§е§Ц,е¶ВжЮЬжЬЇжЮґ1&2дЄКжЬНеК°еЩ®йГљйЭЮеЄЄзєБењЩпЉМJob TrackerеПѓиГљж≤°жЬЙеЕґдїЦйАЙжЛ©пЉМдљЖдЉЪжМЗеЃЪFile.txtдЄКзЪДMapдїїеК°еИ∞жЦ∞зЪДж≤°жЬЙжЬђеЬ∞жХ∞жНЃзЪДжЬНеК°еЩ®дЄКгАВжЦ∞зЪДжЬНеК°еЩ®йЬАи¶БйАЪињЗзљСзїЬеОїиОЈеПЦжХ∞жНЃгАВдљЬдЄЇзїУжЮЬпЉМдљ†еПѓиГљзЬЛеИ∞жЫіе§ЪзЪДзљСзїЬжµБйЗПеТМиЊГйХњеЈ•дљЬеЃМжИРжЧґйЧігАВ
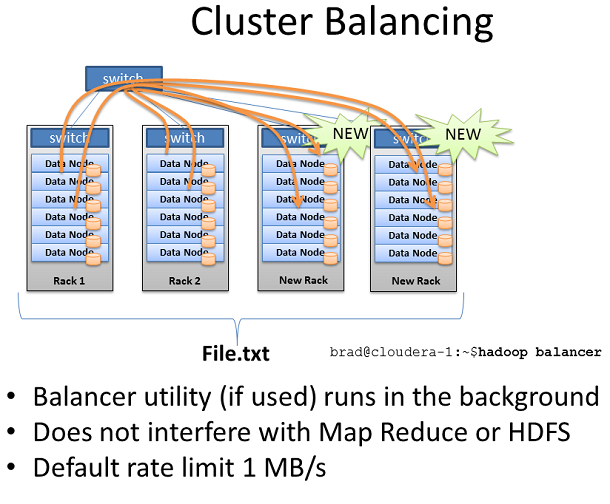
HadoopйЫЖзЊ§еЭЗи°°еЩ®
дЄЇдЇЖеЉ•и°•йЫЖзЊ§зЪДеє≥и°°жАІпЉМHadoopињШеМЕеРЂдЇЖеЭЗи°°еЩ®гАВ
BalancerзЫЃеЕЙиБЪзД¶дЇОиКВзВєйЧіжЬЙжХИеВ®е≠ШзЪДеЈЃеЉВпЉМеКЫжЙАиГљеПКзЪДе∞Жеє≥и°°зїіжМБеЬ®дЄАеЃЪзЪДдЄізХМеАЉдЄКгАВеБЗе¶ВеПСзО∞еЙ©дљЩе§ІйЗПеВ®е≠Шз©ЇйЧізЪДиКВзВєпЉМBalancerе∞ЖжЙЊеЗЇеВ®е≠Шз©ЇйЧіеЙ©дљЩйЗПе∞СзЪДиКВзВєеєґжККжХ∞жНЃеЙ™еИЗеИ∞жЬЙе§ІйЗПеЙ©дљЩз©ЇйЧізЪДиКВзВєдЄКгАВеП™жЬЙзЪДзїИзЂѓдЄКиЊУеЕ•жМЗдї§BalancerжЙНдЉЪињРи°МпЉМељУжО•жФґеИ∞зїИзЂѓеПЦжґИеСљдї§жИЦиАЕзїИ瀃襀еЕ≥йЧ≠жЧґпЉМBalancerе∞ЖдЉЪеЕ≥йЧ≠гАВ
BalancerеПѓдї•и∞ГзФ®зЪДзљСзїЬеЄ¶еЃљеЊИе∞ПпЉМйїШиЃ§еП™жЬЙ1MB/sгАВеЄ¶еЃљеПѓдї•йАЪињЗhdfs-site.xmlжЦЗдїґдЄ≠зЪДdfs.balance.bandwidthPerSecеПВжХ∞жЭ•иЃЊзљЃгАВ
BalancerжШѓйЫЖзЊ§зЪДе•љзЃ°еЃґгАВж≤°ељУжЬЙжЦ∞жЬЇзїДжЈїеК†жЧґеАЩе∞±дЉЪзФ®еИ∞еЃГпЉМзФЪиЗ≥дЄАзїПеЉАеРѓе∞±дЉЪињРи°МжХідЄ™жШЯжЬЯгАВзїЩеЭЗи°°еЩ®дљОеЄ¶еЃљеПѓдї•иЃ©еЃГдњЭжМБзЭАйХњжЧґйЧізЪДињРи°МгАВ
дЄ™дЇЇиЃ§дЄЇеБЗе¶ВеЭЗи°°еЩ®иГљжИРдЄЇHadoopзЪДж†ЄењГиАМдЄНжШѓеП™жШѓдЄАй°єеКЯиГљпЉМйВ£ж†ЈдЄАеЃЪдЉЪжѓФиЊГжЬЙжДПжАЭпЉБ



зЫЄеЕ≥жО®иНР
### жЈ±еЕ•зРЖиІ£HadoopйЫЖзЊ§дЄОзљСзїЬжЮґжЮД ...жАїдєЛпЉМжЈ±еЕ•зРЖиІ£HadoopйЫЖзЊ§еТМзљСзїЬеѓєдЇОжЮДеїЇйЂШжХИгАБеПѓйЭ†зЪДе§ІжХ∞жНЃе§ДзРЖеє≥еП∞иЗ≥еЕ≥йЗНи¶БгАВйАЪињЗеРИзРЖиЃЊиЃ°йЫЖзЊ§жЮґжЮДеТМзљСзїЬйЕНзљЃпЉМеПѓдї•еЕЕеИЖеПСжМ•HadoopеЬ®е§ІиІДж®°жХ∞жНЃе§ДзРЖжЦєйЭҐзЪДдЉШеКњгАВ
йАЪињЗгАКзїЖзїЖеУБеС≥Hadoop_HadoopйЫЖзЊ§пЉИзђђ2жЬЯпЉЙ_жЬЇеЩ®дњ°жБѓеИЖеЄГи°®гАЛпЉМжИСдїђдЄНдїЕдЇЖиІ£дЇЖжЮДеїЇеТМзЃ°зРЖHadoopйЫЖзЊ§зЪДеЯЇжЬђж≠•й™§пЉМињШжЈ±еЕ•иЃ§иѓЖдЇЖеЕґеЬ®з°ђдїґйЕНзљЃеТМзљСзїЬеЄГе±АдЄКзЪДеЕЈдљУеЃЮиЈµгАВињЩеѓєдЇОеИЭе≠¶иАЕеТМдїОдЄЪиАЕиАМи®АпЉМйГљжШѓеЃЭиіµзЪДе≠¶дє†иµДжЦЩеТМ...
йАЪињЗињЩдЄ™вАЬзїЖзїЖеУБеС≥Hadoop_HadoopйЫЖзЊ§пЉИзђђ9жЬЯпЉЙ_MapReduceеИЭзЇІж°ИдЊЛвАЭпЉМиѓїиАЕдЄНдїЕеПѓдї•жЈ±еЕ•дЇЖиІ£MapReduceзЪДеЈ•дљЬеОЯзРЖпЉМињШиГљжОМжП°е¶ВдљХеЬ®еЃЮйЩЕй°єзЫЃдЄ≠ињРзФ®ињЩдЇЫзЯ•иѓЖгАВеРМжЧґпЉМж°ИдЊЛз†Фз©ґе∞ЖеЄЃеК©зРЖиІ£HadoopйЫЖзЊ§зЪДзЃ°зРЖеТМзЫСжОІпЉМдї•еПК...
гАКHadoopйЫЖзЊ§з®ЛеЇПиЃЊиЃ°дЄОеЉАеПСжХЩжЭРжЬАзїИдї£з†БгАЛињЩдЄ™еОЛзЉ©еМЕжЦЗдїґжШѓйТИеѓєе≠¶дє†еТМзРЖиІ£HadoopеИЖеЄГеЉПиЃ°зЃЧж°ЖжЮґзЪДйЗНи¶БжХЩе≠¶иµДжЇРгАВHadoopжШѓApacheиљѓдїґеЯЇйЗСдЉЪеЉАеПСзЪДдЄАдЄ™еЉАжЇРй°єзЫЃпЉМеЃГдЄЇе§ІиІДж®°жХ∞жНЃе§ДзРЖжПРдЊЫдЇЖдЄАзІНеИЖеЄГеЉПгАБеЃєйФЩжАІеЉЇзЪДиІ£еЖ≥...
жАїдєЛпЉМвАЬHadoopйЫЖзЊ§жР≠еїЇиѓ¶зїЖзЃАжШОжХЩз®ЛвАЭе∞ЖеЉХеѓЉдљ†еЃМжИРдїОйЫґеИ∞дЄАзЪДHadoopйЫЖзЊ§еїЇиЃЊпЉМйАЪињЗеЃЮиЈµжУНдљЬпЉМдљ†еПѓдї•жЈ±еЕ•зРЖиІ£HadoopзЪДеЈ•дљЬеОЯзРЖпЉМдЄЇе§ДзРЖе§ІжХ∞жНЃйЧЃйҐШжЙУдЄЛеЭЪеЃЮзЪДеЯЇз°АгАВиЃ∞еЊЧдЄНжЦ≠е≠¶дє†еТМжΥ糥пЉМеЫ†дЄЇHadoopзФЯжАБз≥їзїЯеЬ®дЄНжЦ≠еПСе±Х...
е∞ЖmyEclipseдЄОHadoopйЫЖзЊ§ињЬз®ЛињЮжО•иµЈжЭ•пЉМеПѓдї•жЦєдЊњеЬ∞еЬ®еЉАеПСзОѓеҐГдЄ≠зЉЦеЖЩгАБжµЛиѓХеТМйГ®зљ≤HadoopеЇФзФ®з®ЛеЇПпЉМдїОиАМеЃЮзО∞йЂШжХИзЪДжХ∞жНЃеИЖжЮРеТМе§ДзРЖгАВ й¶ЦеЕИпЉМжИСдїђйЬАи¶БдЇЖиІ£myEclipseдЄ≠зЪДињЬз®Лз≥їзїЯиІЖеЫЊпЉИRemote Systems ViewпЉЙгАВињЩжШѓ...
жАїзЪДжЭ•иѓіпЉМLinuxдЄКзЪДHadoopйЫЖзЊ§еЃЙи£ЕжґЙеПКеИ∞е§Ъж≠•й™§зЪДйЕНзљЃеТМи∞ГиѓХпЉМйЬАи¶БеѓєLinuxз≥їзїЯеТМJavaжЬЙдЄАеЃЪдЇЖиІ£гАВйАЪињЗињЩдЇЫжЦЗж°£пЉМзФ®жИЈеПѓдї•йАРж≠•е≠¶дє†еєґжОМжП°HadoopзЪДеЃЙи£ЕеТМзЃ°зРЖпЉМдїОиАМжЮДеїЇиµЈиЗ™еЈ±зЪДе§ІжХ∞жНЃе§ДзРЖеє≥еП∞гАВиЃ∞дљПпЉМеЃЮиЈµжШѓж£Ай™МзЬЯзРЖ...
жО•зЭАпЉМдє¶дЄ≠иѓ¶зїЖиЃ≤иІ£дЇЖHadoopзЪДеЃЙи£ЕгАБйЕНзљЃеТМзЃ°зРЖпЉМињЩеѓєдЇОеЃЮйЩЕйГ®зљ≤еТМзїіжК§HadoopйЫЖзЊ§иЗ≥еЕ≥йЗНи¶БгАВиѓїиАЕе∞Же≠¶дє†е¶ВдљХиІДеИТз°ђдїґиµДжЇРгАБйЕНзљЃзљСзїЬзОѓеҐГдї•еПКдЉШеМЦHadoopжАІиГљгАВж≠§е§ЦпЉМињШдїЛзїНдЇЖзЫСжОІеТМжХЕйЪЬжОТжЯ•жКАеЈІпЉМеЄЃеК©иѓїиАЕеЇФеѓєеПѓиГљеЗЇзО∞...
дї•дЄКеРДж≠•й™§йГљйЬАи¶БеѓєHadoopжЮґжЮДжЬЙжЈ±еЕ•зРЖиІ£пЉМеМЕжЛђHDFSгАБYARNеТМMapReduceзЪДеЈ•дљЬеОЯзРЖгАВеЬ®еЃЮйЩЕжУНдљЬдЄ≠пЉМињШи¶БиАГиЩСйЫЖзЊ§зЪДеЃЙеЕ®жАІпЉМе¶ВиЃЊзљЃйШ≤зБЂеҐЩиІДеИЩпЉМдљњзФ®еЃЙеЕ®иЃ§иѓБжЬЇеИґе¶ВKerberosпЉМдї•еПКзЫСжОІеТМжЧ•ењЧзЃ°зРЖгАВзїіжК§HadoopйЫЖзЊ§ињШеМЕжЛђ...
"иЕЊиЃѓе§ІиІДж®°HadoopйЫЖзЊ§еЃЮиЈµ"жЈ±еЕ•жОҐиЃ®дЇЖиЕЊиЃѓе¶ВдљХеИ©зФ®HadoopиІ£еЖ≥жµЈйЗПжХ∞жНЃе§ДзРЖзЪДйЧЃйҐШпЉМдЄЇдЄЪзХМжПРдЊЫдЇЖеЃЭиіµзЪДеЃЮиЈµзїПй™МгАВ HadoopжШѓдЄАдЄ™еЉАжЇРзЪДеИЖеЄГеЉПиЃ°зЃЧж°ЖжЮґпЉМзФ±ApacheиљѓдїґеЯЇйЗСдЉЪеЉАеПСпЉМеЃГеЯЇдЇОGoogleзЪДMapReduceзЉЦз®Лж®°еЮЛеТМ...
жЬђеОЛзЉ©еМЕжЦЗдїґеМЕеРЂдЇЖдЄАз≥їеИЧеЕ≥дЇОHadoopйЫЖзЊ§йГ®зљ≤гАБеЃЮжИШеЇФзФ®дї•еПКзЫЄеЕ≥жКАжЬѓзЪДиѓ¶зїЖиµДжЦЩпЉМеѓєдЇОжГ≥и¶БжЈ±еЕ•дЇЖиІ£еТМжОМжП°HadoopжКАжЬѓзЪДдЇЇжЭ•иѓіпЉМжШѓйЭЮеЄЄеЃЭиіµзЪДиµДжЇРгАВ й¶ЦеЕИпЉМжИСдїђжЭ•зЬЛгАКEasyHadoopйЫЖзЊ§йГ®зљ≤жЦЗж°£.docгАЛгАВињЩдїљжЦЗж°£йАЪеЄЄдЉЪ...
йАЪињЗйШЕиѓїдє¶дЄ≠зЪДжЇРз†БпЉМжИСдїђеПѓдї•жЫізЫіиІВеЬ∞зРЖиІ£ињЩдЇЫеИЖеЄГеЉПиЃ°зЃЧеТМе≠ШеВ®з≥їзїЯзЪДеЈ•дљЬеОЯзРЖпЉМињЩеѓєдЇОдЉШеМЦHadoopйЫЖзЊ§зЪДжАІиГљгАБиІ£еЖ≥еЃЮйЩЕйЧЃйҐШдї•еПКињЫи°МдЇМжђ°еЉАеПСеЕЈжЬЙйЗНи¶БжДПдєЙгАВ HadoopеИЖеЄГеЉПжЦЗдїґз≥їзїЯпЉИHDFSпЉЙжШѓHadoopзФЯжАБз≥їзїЯзЪДеЯЇз°АпЉМ...
жАїдєЛпЉМжР≠еїЇLinuxдЄЛзЪДHadoopйЫЖзЊ§йЬАи¶БеѓєHadoopзЪДеЯЇжЬђжЮґжЮДжЬЙжЈ±еЕ•зРЖиІ£пЉМзЖЯжВЙLinuxзљСзїЬйЕНзљЃпЉМеєґиГљзЖЯзїГињЫи°Мз≥їзїЯзЇІеИЂзЪДиЃЊзљЃгАВињЩдЄ™ињЗз®ЛиЩљзДґзєБзРРпЉМдљЖйАЪињЗиЙѓе•љзЪДиІДеИТеТМзїЖиЗізЪДеЃЮжЦљпЉМеПѓдї•жЮДеїЇеЗЇз®≥еЃЪгАБйЂШжХИзЪДжХ∞жНЃе§ДзРЖеє≥еП∞гАВеЬ®еЃЮиЈµ...
зРЖиІ£ињЩдЇЫеЯЇжЬђж¶ВењµеТМAPIпЉМдљ†е∞±иГљзЉЦеЖЩеЗЇиГљдЄОHadoopйЫЖзЊ§жЬЙжХИдЇ§дЇТзЪДJavaеЇФзФ®з®ЛеЇПпЉМињЫи°Ме§ІжХ∞жНЃзЪДе§ДзРЖеТМеИЖжЮРгАВеЬ®еЃЮйЩЕеЉАеПСдЄ≠пЉМињШйЬАи¶БиАГиЩСйФЩиѓѓе§ДзРЖгАБжАІиГљдЉШеМЦдї•еПКйЫЖзЊ§зЪДзЃ°зРЖеТМзЫСжОІз≠ЙжЦєйЭҐпЉМињЩдЇЫйГљжШѓжИРдЄЇHadoopеЉАеПСе§ІеЄИзЪД...
жЬђзѓЗжЦЗзЂ†е∞ЖжЈ±еЕ•жОҐиЃ®HadoopйЫЖзЊ§зЪДйЂШеПѓзФ®жАІеТМжАІиГљдЉШеМЦз≠ЦзХ•пЉМеЄЃеК©дљ†жЮДеїЇжЫіеК†з®≥еЃЪгАБйЂШжХИзЪДHadoopзОѓеҐГгАВ дЄАгАБHadoopйЂШеПѓзФ®жАІ 1. **NameNode HA**: HadoopйЫЖзЊ§дЄ≠зЪДNameNodeжШѓеЕГжХ∞жНЃзЃ°зРЖзЪДеЕ≥йФЃиКВзВєпЉМеЕґйЂШеПѓзФ®жАІиЗ≥еЕ≥йЗНи¶БгАВ...