How could you create six unique random numbers between 1 and 49 with one SQL statement?
We would generate the set of numbers to pick from (see the innermost query that follows); any table with 49 or more records would do it. First the quick-and-dirty solution without a pipelined function.
select r
from (select r
from (select rownum r
from all_objects
where rownum < 50)
order by dbms_random.value)
where rownum <= 6;
R
----------
10
2
19
34
12
21
That query works by generating the numbers 1 .. 49, using the inline view. We wrap that innermost query as an inline view and sort it by a random value, using DBMS_RANDOM.VALUE. We wrap that result set in yet another inline view and just take the first six rows. If we run that query over and over, we'll get a different set of six rows each time.
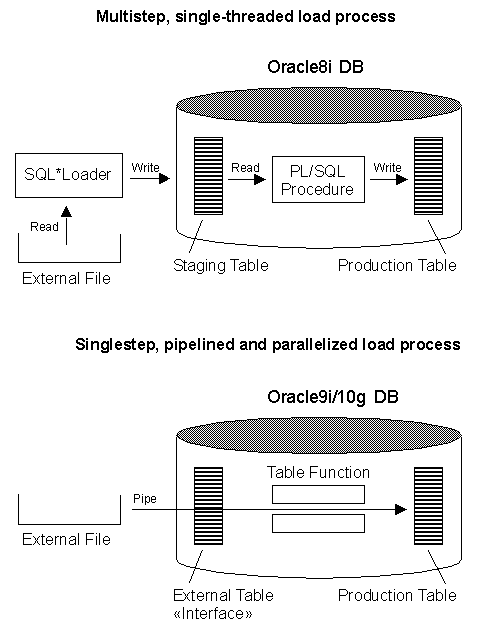
This sort of question comes up frequently—maybe not about how to generate a set of six random numbers but rather, "how can we get N rows?" For example, we'd like the inclusive set of all dates between 25-FEB-2004 and 10-MAR-2004. The question becomes how to do this without a "real" table, and the answer lies in Oracle9i/10g with its PIPELINED functioncapability. We can write a PL/SQL function that will operate like a table. We need to start with a SQL collection type; this describes what the PIPELINED function will return. In this case, we are choosing a table of numbers; the virtual table we are creating will simply return the numbers 1, 2, 3, ... N:
create type array
as table of number
/
Type created.
Next, we create the actual PIPELINED function. This function will accept an input to limit the number of rows returned. If no input is provided, this function will just keep generating rows for a very long time (so be careful and make sure to use ROWNUM or some other limit in the query itself!). The PIPELINED keyword on line 4 allows this function to work as if it were a table:
create function
gen_numbers(n in number default null)
return array
PIPELINED
as
begin
for i in 1 .. nvl(n,999999999)
loop
pipe row(i);
end loop;
return;
end;
/
Function created.
Suppose we needed three rows for something. We can now do that in one of two ways:
select * from TABLE(gen_numbers(3));
COLUMN_VALUE
------------
1
2
3
or
select * from TABLE(gen_numbers)
where rownum <= 3;
COLUMN_VALUE
------------
1
2
3
Now we are ready to re-answer the original question, using the following functionality:
select *
from (
select *
from (select * from table(gen_numbers(49)))
order by dbms_random.random
)
where rownum <= 6
/
COLUMN_VALUE
------------
47
42
40
15
48
23
We can use this virtual table functionality for many things, such as generating that range of dates:
select to_date('25-feb-2004')+
column_value-1
from TABLE(gen_numbers(15))
/
TO_DATE('
---------
25-FEB-04
26-FEB-04
27-FEB-04
28-FEB-04
29-FEB-04
01-MAR-04
02-MAR-04
03-MAR-04
04-MAR-04
05-MAR-04
06-MAR-04
07-MAR-04
08-MAR-04
09-MAR-04
10-MAR-04
Note the name of the column we used: COLUMN_VALUE. That is the default name for the column coming back from the PIPELINED function.
This are the typical steps to perform when using PL/SQL Table Functions:
- The producer function must use the PIPELINED keyword in its declaration.
- The producer function must use an OUT parameter that is a record, corresponding to a row in the result set.
- Once each output record is completed, it is sent to the consumer function through the use of the PIPE ROW keyword.
- The producer function must end with a RETURN statement that does not specify any return value.
- The consumer function or SQL statement then must use the TABLE keyword to treat the resulting rows from the PIPELINE function like a regular table.
The first step is to define the format of the rows that are going to be returned. In this case here, we're going to return a INT, DATE followed by a VARCHAR2(25).
CREATE OR REPLACE TYPE myObjectFormat
AS OBJECT
(
A INT,
B DATE,
C VARCHAR2(25)
)
/
Next a collection type for the type previously defined must be created.
CREATE OR REPLACE TYPE myTableType
AS TABLE OF myObjectFormat
/
Finally, the producer function is packaged in a package. It is a pipelined function as indicated by the keyword pipelined.
CREATE OR REPLACE PACKAGE myDemoPack
AS
FUNCTION prodFunc RETURN myTableType PIPELINED;
END;
/
CREATE OR REPLACE PACKAGE BODY myDemoPack AS
FUNCTION prodFunc RETURN myTableType PIPELINED IS
BEGIN
FOR i in 1 .. 5
LOOP
PIPE ROW (myObjectFormat(i,SYSDATE+i,'Row '||i));
END LOOP;
RETURN;
END;
END;
/
Test It:
ALTER SESSION SET NLS_DATE_FORMAT='dd.mm.yyyy';
SELECT * FROM TABLE(myDemoPack.prodFunc());
A B C
---------- ---------- ---------
1 31.05.2004 Row 1
2 01.06.2004 Row 2
3 02.06.2004 Row 3
4 03.06.2004 Row 4
5 04.06.2004 Row 5





相关推荐
传统的Map-Reduce框架通常运行在独立的计算集群上,而Oracle数据库通过其独特的特性——**Pipeline Table Functions**(管道表函数)——提供了一种直接在数据库内部实现Map-Reduce的方式,从而实现了真正的“in-...
Pipeline ADC设计指南 Pipeline ADC是一种常用的模数转换器架构,它通过将模拟信号分解成多个阶段来实现高精度的数字化。下面我们将详细介绍Pipeline ADC的设计指南。 一、Pipeline ADC的基本原理 Pipeline ADC...
Jenkins Pipeline 部署 SpringBoot 应用详解 本篇文章主要介绍了使用 Jenkins Pipeline 部署 SpringBoot 应用的详细教程,从安装依赖包到环境准备、安装 Jenkins 等步骤进行详细的介绍,对读者学习或工作具有一定的...
《gltf-pipeline:构建三维图形的利器》 gltf-pipeline 是一个强大的工具集,主要用于处理和优化基于 glTF(GL Transmission Format)的三维模型数据。glTF 是一种开放标准的三维模型格式,旨在高效、轻量地传输和...
Doris PipeLine设计文档 Doris PipeLine设计文档是关于Doris执行引擎的设计文档,旨在解决当前Doris执行引擎中存在的一些问题,如无法充分利用多核计算能力、提升查询性能、手动设置并行度等问题。该设计文档提出了...
高通QCOM camera Pipeline可视化工具 1.4版本
Avalon-MM Pipeline Bridge是Qsys系统中一种重要的互联组件,用于优化基于Avalon-MM接口的SoC(System-on-a-Chip)设计中的数据传输性能。Avalon-MM是Altera公司(现已被Intel收购)开发的一种内存映射协议,广泛...
本篇重点讲解的是Jenkins Pipeline的高级技巧,旨在帮助初学者,即"小白",快速搭建并掌握Pipeline项目的开发环境。 一、Jenkins Pipeline基础 Jenkins Pipeline是一种定义和执行CI/CD流程的声明式或脚本化方式。...
jenkins 构建项目之 pipeline基础教程 jenkins Pipeline 是一种基于工作流框架的自动化构建工具,它可以将原本独立运行于单个或者多个节点的任务连接起来,实现单个任务难以完成的复杂流程编排和可视化的工作。...
pipeline studio快速入门,确实容易上手
本文档将详细介绍Oracle Service Bus中的两个具体实例——Two Loan Application Examples的开发、部署及调试流程,并重点介绍如何使用Pipeline和RouteNode两种不同的方式来实现业务逻辑。 #### 查看 Web Service ...
在本文中,我们将深入探讨Netty中的关键概念,尤其是Pipeline(管道)的顺序及其工作原理。 首先,让我们理解Netty的核心组件:Server和Client。在Netty中,服务器端通常被称为BossGroup和WorkerGroup,BossGroup...
标题中的"PyPI 官网下载 | bamboo-pipeline-3.6.3.tar.gz"指出这是一个从Python Package Index(PyPI)官方站点获取的软件包,名为“bamboo-pipeline”。这个软件包的版本是3.6.3,并且是以tar.gz格式压缩的。在...
This book describes the Direct3D graphics pipeline, from presentation of scene data to pixels appearing on the screen. The book is organized sequentially following the data °ow through the pipeline ...
### Pipeline ADC概述与关键技术 #### 一、Pipeline ADC的基本概念 Pipeline ADC(流水线模数转换器)是一种高性能、高速度的模数转换技术,在现代通信系统、雷达系统及信号处理领域发挥着至关重要的作用。它能够...
https://stackoverflow.com/questions/41893846/jacoco-coverage-in-jenkins-pipeline jenkins官网介绍:https://jenkins.io/doc/pipeline/steps/jacoco/ 流水线语法的片段生成器可以选择jacoco,设置jacoco jacoco...
构建机器学习Pipeline,也就是构建机器学习流程线,是数据科学和软件工程领域中的一个重要议题。在现实世界中,数据科学家通常在一个为统计和机器学习量身定做的开发环境中工作,例如使用Python等工具,在一个“沙盒...
Hosted Community Edition - Try It Now! ...Email: help@pipeline.ai Web: https://support.pipeline.ai YouTube: https://youtube.pipeline.ai Slideshare: https://slideshare.pipeline.ai Work
Jenkins CI Pipeline 是一个强大的自动化工具,用于构建、测试和部署软件。Pipeline 允许开发者定义持续集成(CI)和持续部署(CD)的工作流程,这些工作流程是声明式的,可编写为版本化的代码,提高了可重复性和可...
在Jenkins自动化构建和部署的过程中,Pipeline作为一种强大的脚本化工具,可以让我们更灵活地管理持续集成和持续交付流程。本资料重点讲解了在Pipeline中如何通过代码串联多个job的执行,这对于构建复杂的CI/CD流程...