Lucene并不是一个应用程序,而是提供了一个纯Java的高性能全文索引引擎工具包
Nutch是一个应用程序,是一个以Lucene为基础实现的搜索引擎应用(包含爬虫和其他附属搜索属性)
Hadoop: Hadoop 是一个能够对大量数据进行分布式处理的软件框架。但是 Hadoop 是以一种可靠、高效、可伸缩的方式进行处理的。Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop 还是可伸缩的,能够处理 PB 级数据。此外,Hadoop 依赖于社区服务器,因此它的成本比较低,任何人都可以使用。 Hadoop 有许多元素构成。主要包括两部分:最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件。HDFS(对于本文)的上一层是 MapReduce 引擎,该引擎由 JobTrackers 和 TaskTrackers组成。
1、HDFS
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。HDFS开始是为开源的apache项目nutch的基础结构而创建,HDFS是hadoop项目的一部分,而hadoop又是lucene的一部分。
HDFS是一个master/slave的结构,就通常的部署来说,在master上只运行一个Namenode,而在每一个slave上运行一个Datanode .HDFS支持传统的层次文件组织结构,同现有的一些文件系统在操作上很类似,比如你可以创建和删除一个文件,把一个文件从一个目录移到另一个目录,重命名等等操作。Namenode管理着整个分布式文件系统,对文件系统的操作(如建立、删除文件和文件夹)都是通过Namenode来控制。
下面是HDFS的结构:
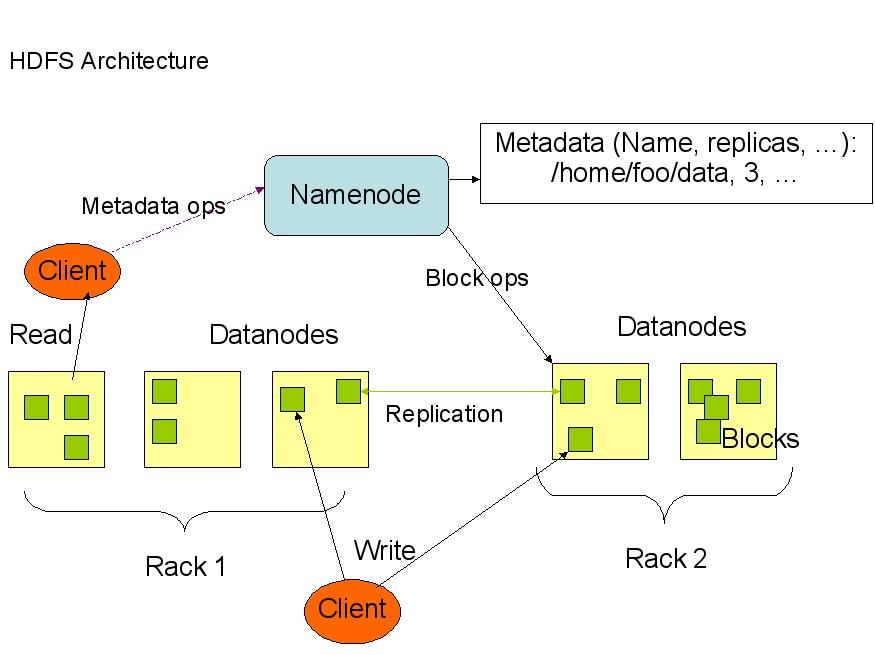
从上面的图中可以看出,Namenode,Datanode,Client之间的通信都是建立在TCP/IP的基础之上的。当Client要执行一个写入的操作的时候,命令不是马上就发送到Namenode,Client首先在本机上临时文件夹中缓存这些数据,当临时文件夹中的数据块达到了设定的Block的值(默认是64M)时,Client便会通知Namenode,Namenode便响应Client的RPC请求,将文件名插入文件系统层次中并且在Datanode中找到一块存放该数据的block,同时将该Datanode及对应的数据块信息告诉Client,Client便这些本地临时文件夹中的数据块写入指定的数据节点。
HDFS采取了副本策略,其目的是为了提高系统的可靠性,可用性。HDFS的副本放置策略是三个副本,一个放在本节点上,一个放在同一机架中的另一个节点上,还有一个副本放在另一个不同的机架中的一个节点上。
2、MapReduce的实现
MapReduce是Google 的一项重要技术,它是一个编程模型,用以进行大数据量的计算。对于大数据量的计算,通常采用的处理手法就是并行计算。至少现阶段而言,对许多开发人员来说,并行计算还是一个比较遥远的东西。MapReduce就是一种简化并行计算的编程模型,它让那些没有多少并行计算经验的开发人员也可以开发并行应用。
MapReduce的名字源于这个模型中的两项核心操作:Map和 Reduce。也许熟悉Functional Programming(函数式编程)的人见到这两个词会倍感亲切。简单的说来,Map是把一组数据一对一的映射为另外的一组数据,其映射的规则由一个函数来指定,比如对[1, 2, 3, 4]进行乘2的映射就变成了[2, 4, 6, 8]。Reduce是对一组数据进行归约,这个归约的规则由一个函数指定,比如对[1, 2, 3, 4]进行求和的归约得到结果是10,而对它进行求积的归约结果是24。
hive:hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。另外一个是Windows注册表文件。
HBase:HBase是一个分布式的、面向列的开源数据库,该技术来源于Chang et al所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库.另一个不同的是HBase基于列的而不是基于行的模式。
compass: Compass是一个构建于Lucene之上的开源项目,旨在简化检索与任何java应用程序的集成。 利用元数据实现OR。
Berkeley DB:Berkeley DB (DB)是一个高性能的,嵌入数据库编程库,Berkeley DB可以保存任意类型的键/值对,而且可以为一个键保存多个数据。Berkeley DB可以支持数千的并发线程同时操作数据库,支持最大256TB的数据
heritrix:Heritrix是一个爬虫框架。
httpclient:HttpClient 是 Apache Jakarta Common 下的子项目,可以用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。
HtmlParser:提取html元素的工具
DFS(Depth-First-Search)深度优先搜索算法,是搜索算法的一种。是一种在开发爬虫早期使用较多的方法。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件) 。
BFS(breadth-first search):每次将集合中的元素经过一些改动,分层生成当前状态的子状态(通常还删除父情况),添加到集合(队列)中,以实现遍历或搜索等目的的算法。
分享到:




相关推荐
名词解释44. 服务器结构4#Hadoop试验集群的部署结构4#系统和组建的依赖关系5#生产环境的部署结构65. Red hat Linux基础环境搭建6#linux 安装 (vm虚拟机)6#配置机器时间同步6#配置机器网络环境7#配置集群hosts列表10...
+ 因为我们最后Reduce过程要输出的结果是“单词-->文件名词频”,所以我们需要在Combine过程把key和value进行一个调整,从原来的“单词:文档-->词频”转变成”单词-->文件名词频”。 * Reduce过程的设计: + ...
二、HDFS 重要名词解释 Hadoop分布式文件系统的核心组件包括: * Namenode:Namenode是Hadoop分布式文件系统的核心组件,负责文件系统的命名空间管理和文件元数据管理。 * Secondary Namenode:Secondary Namenode...
这份"科技大数据结构名词解释+简答.zip"压缩包很可能是为了帮助学习者理解和掌握大数据技术中的核心概念,包括各种数据结构的定义、工作原理以及在实际问题中的应用。以下是对一些常见大数据结构的详细解释和简答: ...
以下是根据提供的文件内容对这些名词的详细解释: 1. RDS(关系型数据库服务):RDS 提供了一种即用即付的在线数据库服务,支持多种关系型数据库,如 MySQL、SQL Server 等。它具有高可用性、弹性伸缩和安全防护...
HDFS重要名词解释 - **Namenode**:HDFS的元数据管理节点,负责文件系统的命名空间和文件块的映射信息,是整个系统的“大脑”。 - **Secondary Namenode**:辅助Namenode的角色,定期与主Namenode同步元数据,以防...
EasyHadoop集群部署入门文档2目录21. 文档概述32. 背景33. 名词解释44. 服务器结构4#Hadoop试验集群的部署结构4#系统和组建的依赖关系5#生产环境的部署结构65. Red hat Linux基础环境搭建6
名词解释 - **Hadoop**:一个开源框架,用于存储和处理大规模数据集。Hadoop的核心组成部分包括HDFS(Hadoop Distributed File System)和MapReduce。 - **HDFS**:一种分布式文件系统,专为存储大量数据而设计。 -...
#### 名词解释 - **Hadoop**: 开源的分布式计算框架,由 Apache 基金会维护,包含 HDFS(Hadoop Distributed File System)和 MapReduce。 - **HDFS**: 分布式文件系统,提供高容错性和高吞吐量的数据存储。 - **...
3. **名词解释** - **Hadoop**:Apache Hadoop是一个开源的分布式计算框架,由HDFS(Hadoop Distributed File System)和MapReduce组成,用于处理和存储大量数据。 - **EasyHadoop**:一个简化Hadoop部署和管理的...
大数据名词解析是对大数据领域中常见的名词进行解释和分析的文档。该文档对大数据存储、处理和分析的各种概念和技术进行了详细的解释,从而帮助读者更好地理解大数据领域的知识。 结构化数据 结构化数据是指企业...
4. **Hadoop相关名词解释**:HBase提供的是高可靠性的列式数据库服务,而不是行式数据库(选项D错误)。 5. **Hadoop生态系统的组件**:Hadoop生态系统包括MapReduce(选项A未完整列出),此外还包括HDFS、YARN、...
3. 名词解释 ...................................................................................................................................................................... 3 4. 服务器结构 ........
大数据处理技术参考架构 在当前数字化时代,大数据已经成为企业决策、科研分析以及...附录中的名词解释将为读者提供更深入的理解,例如MPP、Hadoop、Spark等关键术语的定义,帮助读者更好地掌握大数据处理的核心概念。
题库内容多样,包括单项选择题、填空题、设计与应用题、名词解释等,覆盖了历年来的重点和难点,针对性强,对提升学生的理解和应用能力有着显著的帮助。 首先,我们要关注的是“数据库”这一主题。数据库是存储和...
大数据处理技术参考架构 ...附录中的名词解释对大数据处理中的一些专业术语进行了清晰的阐述,有助于读者更好地理解和应用这些技术。总的来说,这份文档为理解大数据处理技术及其应用提供了全面的视角和深入的探讨。
1.5 名词解释 - 数据采集:从各种数据源获取原始数据的过程。 - 数据处理:对采集到的数据进行清洗、整合、转换等操作,使其具备分析价值。 - 大数据计算平台:支持大规模数据处理和分析的软件框架,如Apache Hadoop...