
В
consistent hashingВ з®—жі•ж—©еңЁВ 1997В е№ҙе°ұеңЁи®әж–ҮВ Consistent hashing and random treesВ дёӯиў«жҸҗеҮәпјҢзӣ®еүҚеңЁcacheВ зі»з»ҹдёӯеә”з”Ёи¶ҠжқҘи¶Ҡе№ҝжіӣпјӣ
1В еҹәжң¬еңәжҷҜ
жҜ”еҰӮдҪ жңүВ NВ дёӘВ cacheВ жңҚеҠЎеҷЁпјҲеҗҺйқўз®Җз§°В cacheВ пјүпјҢйӮЈд№ҲеҰӮдҪ•е°ҶдёҖдёӘеҜ№иұЎВ objectВ жҳ е°„еҲ°В NВ дёӘВ cacheВ дёҠе‘ўпјҢдҪ еҫҲеҸҜиғҪдјҡйҮҮз”Ёзұ»дјјдёӢйқўзҡ„йҖҡз”Ёж–№жі•и®Ўз®—В objectВ зҡ„В hashВ еҖјпјҢ然еҗҺеқҮеҢҖзҡ„жҳ е°„еҲ°еҲ°В NВ дёӘВ cacheВ пјӣ
hash(object)%N
дёҖеҲҮйғҪиҝҗиЎҢжӯЈеёёпјҢеҶҚиҖғиҷ‘еҰӮдёӢзҡ„дёӨз§Қжғ…еҶөпјӣ
1В дёҖдёӘВ cacheВ жңҚеҠЎеҷЁВ m downВ жҺүдәҶпјҲеңЁе®һйҷ…еә”з”Ёдёӯеҝ…йЎ»иҰҒиҖғиҷ‘иҝҷз§Қжғ…еҶөпјүпјҢиҝҷж ·жүҖжңүжҳ е°„еҲ°В cache mВ зҡ„еҜ№иұЎйғҪдјҡеӨұж•ҲпјҢжҖҺд№ҲеҠһпјҢйңҖиҰҒжҠҠВ cache mВ д»ҺВ cacheВ дёӯ移йҷӨпјҢиҝҷж—¶еҖҷВ cacheВ жҳҜВ N-1В еҸ°пјҢжҳ е°„е…¬ејҸеҸҳжҲҗдәҶВ hash(object)%(N-1)В пјӣ
2В з”ұдәҺи®ҝй—®еҠ йҮҚпјҢйңҖиҰҒж·»еҠ В cacheВ пјҢиҝҷж—¶еҖҷВ cacheВ жҳҜВ N+1В еҸ°пјҢжҳ е°„е…¬ејҸеҸҳжҲҗдәҶВ hash(object)%(N+1)В пјӣ
1В е’ҢВ 2В ж„Ҹе‘ізқҖд»Җд№Ҳпјҹиҝҷж„Ҹе‘ізқҖзӘҒ然д№Ӣй—ҙеҮ д№ҺжүҖжңүзҡ„В cacheВ йғҪеӨұж•ҲдәҶгҖӮеҜ№дәҺжңҚеҠЎеҷЁиҖҢиЁҖпјҢиҝҷжҳҜдёҖеңәзҒҫйҡҫпјҢжҙӘж°ҙиҲ¬зҡ„и®ҝй—®йғҪдјҡзӣҙжҺҘеҶІеҗ‘еҗҺеҸ°жңҚеҠЎеҷЁпјӣ
еҶҚжқҘиҖғиҷ‘第дёүдёӘй—®йўҳпјҢз”ұдәҺ硬件иғҪеҠӣи¶ҠжқҘи¶ҠејәпјҢдҪ еҸҜиғҪжғіи®©еҗҺйқўж·»еҠ зҡ„иҠӮзӮ№еӨҡеҒҡзӮ№жҙ»пјҢжҳҫ然дёҠйқўзҡ„В hashВ з®—жі•д№ҹеҒҡдёҚеҲ°гҖӮ
В В жңүд»Җд№Ҳж–№жі•еҸҜд»Ҙж”№еҸҳиҝҷдёӘзҠ¶еҶөе‘ўпјҢиҝҷе°ұжҳҜВ consistent hashing...
2 hashВ з®—жі•е’ҢеҚ•и°ғжҖ§
гҖҖгҖҖВ HashВ з®—жі•зҡ„дёҖдёӘиЎЎйҮҸжҢҮж ҮжҳҜеҚ•и°ғжҖ§пјҲВ MonotonicityВ пјүпјҢе®ҡд№үеҰӮдёӢпјҡ
гҖҖгҖҖеҚ•и°ғжҖ§жҳҜжҢҮеҰӮжһңе·Із»ҸжңүдёҖдәӣеҶ…е®№йҖҡиҝҮе“ҲеёҢеҲҶжҙҫеҲ°дәҶзӣёеә”зҡ„зј“еҶІдёӯпјҢеҸҲжңүж–°зҡ„зј“еҶІеҠ е…ҘеҲ°зі»з»ҹдёӯгҖӮе“ҲеёҢзҡ„з»“жһңеә”иғҪеӨҹдҝқиҜҒеҺҹжңүе·ІеҲҶй…Қзҡ„еҶ…е®№еҸҜд»Ҙиў«жҳ е°„еҲ°ж–°зҡ„зј“еҶІдёӯеҺ»пјҢиҖҢдёҚдјҡиў«жҳ е°„еҲ°ж—§зҡ„зј“еҶІйӣҶеҗҲдёӯзҡ„е…¶д»–зј“еҶІеҢәгҖӮ
е®№жҳ“зңӢеҲ°пјҢдёҠйқўзҡ„з®ҖеҚ•В hashВ з®—жі•В hash(object)%NВ йҡҫд»Ҙж»Ўи¶іеҚ•и°ғжҖ§иҰҒжұӮгҖӮ
3 consistent hashingВ з®—жі•зҡ„еҺҹзҗҶ
consistent hashingВ жҳҜдёҖз§ҚВ hashВ з®—жі•пјҢз®ҖеҚ•зҡ„иҜҙпјҢеңЁз§»йҷӨВ /В ж·»еҠ дёҖдёӘВ cacheВ ж—¶пјҢе®ғиғҪеӨҹе°ҪеҸҜиғҪе°Ҹзҡ„ж”№еҸҳе·ІеӯҳеңЁВ keyВ жҳ е°„е…ізі»пјҢе°ҪеҸҜиғҪзҡ„ж»Ўи¶іеҚ•и°ғжҖ§зҡ„иҰҒжұӮгҖӮ
дёӢйқўе°ұжқҘжҢүз…§В 5В дёӘжӯҘйӘӨз®ҖеҚ•и®Іи®ІВ consistent hashingВ з®—жі•зҡ„еҹәжң¬еҺҹзҗҶгҖӮ
3.1В зҺҜеҪўhashВ з©әй—ҙ
иҖғиҷ‘йҖҡеёёзҡ„В hashВ з®—жі•йғҪжҳҜе°ҶВ valueВ жҳ е°„еҲ°дёҖдёӘВ 32В дёәзҡ„В keyВ еҖјпјҢд№ҹеҚіжҳҜВ 0~2^32-1В ж¬Ўж–№зҡ„ж•°еҖјз©әй—ҙпјӣжҲ‘们еҸҜд»Ҙе°ҶиҝҷдёӘз©әй—ҙжғіиұЎжҲҗдёҖдёӘйҰ–пјҲВ 0В пјүе°ҫпјҲВ 2^32-1В пјүзӣёжҺҘзҡ„еңҶзҺҜпјҢеҰӮдёӢйқўеӣҫВ 1В жүҖзӨәзҡ„йӮЈж ·гҖӮ

еӣҫВ 1В зҺҜеҪўВ hashВ з©әй—ҙ
3.2В жҠҠеҜ№иұЎжҳ е°„еҲ°hashВ з©әй—ҙ
жҺҘдёӢжқҘиҖғиҷ‘В 4В дёӘеҜ№иұЎВ object1~object4В пјҢйҖҡиҝҮВ hashВ еҮҪж•°и®Ўз®—еҮәзҡ„В hashВ еҖјВ keyВ еңЁзҺҜдёҠзҡ„еҲҶеёғеҰӮеӣҫВ 2В жүҖзӨәгҖӮ
hash(object1) = key1;
вҖҰ вҖҰ
hash(object4) = key4;

еӣҫВ 2 4В дёӘеҜ№иұЎзҡ„В keyВ еҖјеҲҶеёғ
3.3В жҠҠcacheВ жҳ е°„еҲ°hashВ з©әй—ҙ
Consistent hashingВ зҡ„еҹәжң¬жҖқжғіе°ұжҳҜе°ҶеҜ№иұЎе’ҢВ cacheВ йғҪжҳ е°„еҲ°еҗҢдёҖдёӘВ hashВ ж•°еҖјз©әй—ҙдёӯпјҢ并且дҪҝз”ЁзӣёеҗҢзҡ„В hashз®—жі•гҖӮ
еҒҮи®ҫеҪ“еүҚжңүВ A,BВ е’ҢВ CВ е…ұВ 3В еҸ°В cacheВ пјҢйӮЈд№Ҳе…¶жҳ е°„з»“жһңе°ҶеҰӮеӣҫВ 3В жүҖзӨәпјҢ他们еңЁВ hashВ з©әй—ҙдёӯпјҢд»ҘеҜ№еә”зҡ„В hashВ еҖјжҺ’еҲ—гҖӮ
hash(cache A) = key A;
вҖҰ вҖҰ
hash(cache C) = key C;

еӣҫВ 3 cacheВ е’ҢеҜ№иұЎзҡ„В keyВ еҖјеҲҶеёғ
В
иҜҙеҲ°иҝҷйҮҢпјҢйЎәдҫҝжҸҗдёҖдёӢВ cacheВ зҡ„В hashВ и®Ўз®—пјҢдёҖиҲ¬зҡ„ж–№жі•еҸҜд»ҘдҪҝз”ЁВ cacheВ жңәеҷЁзҡ„В IPВ ең°еқҖжҲ–иҖ…жңәеҷЁеҗҚдҪңдёәВ hashиҫ“е…ҘгҖӮ
3.4В жҠҠеҜ№иұЎжҳ е°„еҲ°cache
зҺ°еңЁВ cacheВ е’ҢеҜ№иұЎйғҪе·Із»ҸйҖҡиҝҮеҗҢдёҖдёӘВ hashВ з®—жі•жҳ е°„еҲ°В hashВ ж•°еҖјз©әй—ҙдёӯдәҶпјҢжҺҘдёӢжқҘиҰҒиҖғиҷ‘зҡ„е°ұжҳҜеҰӮдҪ•е°ҶеҜ№иұЎжҳ е°„еҲ°В cacheВ дёҠйқўдәҶгҖӮ
еңЁиҝҷдёӘзҺҜеҪўз©әй—ҙдёӯпјҢеҰӮжһңжІҝзқҖйЎәж—¶й’Ҳж–№еҗ‘д»ҺеҜ№иұЎзҡ„В keyВ еҖјеҮәеҸ‘пјҢзӣҙеҲ°йҒҮи§ҒдёҖдёӘВ cacheВ пјҢйӮЈд№Ҳе°ұе°ҶиҜҘеҜ№иұЎеӯҳеӮЁеңЁиҝҷдёӘВ cacheВ дёҠпјҢеӣ дёәеҜ№иұЎе’ҢВ cacheВ зҡ„В hashВ еҖјжҳҜеӣәе®ҡзҡ„пјҢеӣ жӯӨиҝҷдёӘВ cacheВ еҝ…然жҳҜе”ҜдёҖе’ҢзЎ®е®ҡзҡ„гҖӮиҝҷж ·дёҚе°ұжүҫеҲ°дәҶеҜ№иұЎе’ҢВ cacheВ зҡ„жҳ е°„ж–№жі•дәҶеҗ—пјҹпјҒ
дҫқ然继з»ӯдёҠйқўзҡ„дҫӢеӯҗпјҲеҸӮи§ҒеӣҫВ 3В пјүпјҢйӮЈд№Ҳж №жҚ®дёҠйқўзҡ„ж–№жі•пјҢеҜ№иұЎВ object1В е°Ҷиў«еӯҳеӮЁеҲ°В cache AВ дёҠпјӣВ object2В е’Ңobject3В еҜ№еә”еҲ°В cache CВ пјӣВ object4В еҜ№еә”еҲ°В cache BВ пјӣ
3.5В иҖғеҜҹcacheВ зҡ„еҸҳеҠЁ
еүҚйқўи®ІиҝҮпјҢйҖҡиҝҮВ hash 然еҗҺжұӮдҪҷзҡ„ж–№жі•еёҰжқҘзҡ„жңҖеӨ§й—®йўҳе°ұеңЁдәҺдёҚиғҪж»Ўи¶іеҚ•и°ғжҖ§пјҢеҪ“В cacheВ жңүжүҖеҸҳеҠЁж—¶пјҢВ cacheдјҡеӨұж•ҲпјҢиҝӣиҖҢеҜ№еҗҺеҸ°жңҚеҠЎеҷЁйҖ жҲҗе·ЁеӨ§зҡ„еҶІеҮ»пјҢзҺ°еңЁе°ұжқҘеҲҶжһҗеҲҶжһҗВ consistent hashingВ з®—жі•гҖӮ
3.5.1 移йҷӨВ cache
иҖғиҷ‘еҒҮи®ҫВ cache BВ жҢӮжҺүдәҶпјҢж №жҚ®дёҠйқўи®ІеҲ°зҡ„жҳ е°„ж–№жі•пјҢиҝҷж—¶еҸ—еҪұе“Қзҡ„е°Ҷд»…жҳҜйӮЈдәӣжІҝВ cache BВ йҖҶж—¶й’ҲйҒҚеҺҶзӣҙеҲ°дёӢдёҖдёӘВ cacheВ пјҲВ cache CВ пјүд№Ӣй—ҙзҡ„еҜ№иұЎпјҢд№ҹеҚіжҳҜжң¬жқҘжҳ е°„еҲ°В cache BВ дёҠзҡ„йӮЈдәӣеҜ№иұЎгҖӮ
еӣ жӯӨиҝҷйҮҢд»…йңҖиҰҒеҸҳеҠЁеҜ№иұЎВ object4В пјҢе°Ҷе…¶йҮҚж–°жҳ е°„еҲ°В cache CВ дёҠеҚіеҸҜпјӣеҸӮи§ҒеӣҫВ 4В гҖӮ

еӣҫВ 4 Cache B 被移йҷӨеҗҺзҡ„В cacheВ жҳ е°„
3.5.2В ж·»еҠ В cache
еҶҚиҖғиҷ‘ж·»еҠ дёҖеҸ°ж–°зҡ„В cache DВ зҡ„жғ…еҶөпјҢеҒҮи®ҫеңЁиҝҷдёӘзҺҜеҪўВ hashВ з©әй—ҙдёӯпјҢВ cache DВ иў«жҳ е°„еңЁеҜ№иұЎВ object2В е’Ңobject3В д№Ӣй—ҙгҖӮиҝҷж—¶еҸ—еҪұе“Қзҡ„е°Ҷд»…жҳҜйӮЈдәӣжІҝВ cache DВ йҖҶж—¶й’ҲйҒҚеҺҶзӣҙеҲ°дёӢдёҖдёӘВ cacheВ пјҲВ cache BВ пјүд№Ӣй—ҙзҡ„еҜ№иұЎпјҲе®ғ们жҳҜд№ҹжң¬жқҘжҳ е°„еҲ°В cache CВ дёҠеҜ№иұЎзҡ„дёҖйғЁеҲҶпјүпјҢе°ҶиҝҷдәӣеҜ№иұЎйҮҚж–°жҳ е°„еҲ°В cache DВ дёҠеҚіеҸҜгҖӮ
В
еӣ жӯӨиҝҷйҮҢд»…йңҖиҰҒеҸҳеҠЁеҜ№иұЎВ object2В пјҢе°Ҷе…¶йҮҚж–°жҳ е°„еҲ°В cache DВ дёҠпјӣеҸӮи§ҒеӣҫВ 5В гҖӮ

еӣҫВ 5В ж·»еҠ В cache DВ еҗҺзҡ„жҳ е°„е…ізі»
4В иҷҡжӢҹиҠӮзӮ№
иҖғйҮҸВ HashВ з®—жі•зҡ„еҸҰдёҖдёӘжҢҮж ҮжҳҜе№іиЎЎжҖ§В (Balance)В пјҢе®ҡд№үеҰӮдёӢпјҡ
е№іиЎЎжҖ§
гҖҖгҖҖе№іиЎЎжҖ§жҳҜжҢҮе“ҲеёҢзҡ„з»“жһңиғҪеӨҹе°ҪеҸҜиғҪеҲҶеёғеҲ°жүҖжңүзҡ„зј“еҶІдёӯеҺ»пјҢиҝҷж ·еҸҜд»ҘдҪҝеҫ—жүҖжңүзҡ„зј“еҶІз©әй—ҙйғҪеҫ—еҲ°еҲ©з”ЁгҖӮ
hash 算法并дёҚжҳҜдҝқиҜҒз»қеҜ№зҡ„е№іиЎЎпјҢеҰӮжһңВ cacheВ иҫғе°‘зҡ„иҜқпјҢеҜ№иұЎе№¶дёҚиғҪиў«еқҮеҢҖзҡ„жҳ е°„еҲ°В cacheВ дёҠпјҢжҜ”еҰӮеңЁдёҠйқўзҡ„дҫӢеӯҗдёӯпјҢд»…йғЁзҪІВ cache AВ е’ҢВ cache CВ зҡ„жғ…еҶөдёӢпјҢеңЁВ 4В дёӘеҜ№иұЎдёӯпјҢВ cache AВ д»…еӯҳеӮЁдәҶВ object1В пјҢиҖҢВ cache CВ еҲҷеӯҳеӮЁдәҶobject2В гҖҒВ object3В е’ҢВ object4В пјӣеҲҶеёғжҳҜеҫҲдёҚеқҮиЎЎзҡ„гҖӮ
дёәдәҶи§ЈеҶіиҝҷз§Қжғ…еҶөпјҢВ consistent hashingВ еј•е…ҘдәҶвҖңиҷҡжӢҹиҠӮзӮ№вҖқзҡ„жҰӮеҝөпјҢе®ғеҸҜд»ҘеҰӮдёӢе®ҡд№үпјҡ
вҖңиҷҡжӢҹиҠӮзӮ№вҖқпјҲВ virtual nodeВ пјүжҳҜе®һйҷ…иҠӮзӮ№еңЁВ hashВ з©әй—ҙзҡ„еӨҚеҲ¶е“ҒпјҲВ replicaВ пјүпјҢдёҖе®һйҷ…дёӘиҠӮзӮ№еҜ№еә”дәҶиӢҘе№ІдёӘвҖңиҷҡжӢҹиҠӮзӮ№вҖқпјҢиҝҷдёӘеҜ№еә”дёӘж•°д№ҹжҲҗдёәвҖңеӨҚеҲ¶дёӘж•°вҖқпјҢвҖңиҷҡжӢҹиҠӮзӮ№вҖқеңЁВ hashВ з©әй—ҙдёӯд»ҘВ hashВ еҖјжҺ’еҲ—гҖӮ
д»Қд»Ҙд»…йғЁзҪІВ cache AВ е’ҢВ cache CВ зҡ„жғ…еҶөдёәдҫӢпјҢеңЁеӣҫВ 4В дёӯжҲ‘们已з»ҸзңӢеҲ°пјҢВ cacheВ еҲҶеёғ并дёҚеқҮеҢҖгҖӮзҺ°еңЁжҲ‘们引е…ҘиҷҡжӢҹиҠӮзӮ№пјҢ并и®ҫзҪ®вҖңеӨҚеҲ¶дёӘж•°вҖқдёәВ 2В пјҢиҝҷе°ұж„Ҹе‘ізқҖдёҖе…ұдјҡеӯҳеңЁВ 4В дёӘвҖңиҷҡжӢҹиҠӮзӮ№вҖқпјҢВ cache A1, cache A2В д»ЈиЎЁдәҶcache AВ пјӣВ cache C1, cache C2В д»ЈиЎЁдәҶВ cache CВ пјӣеҒҮи®ҫдёҖз§ҚжҜ”иҫғзҗҶжғізҡ„жғ…еҶөпјҢеҸӮи§ҒеӣҫВ 6В гҖӮ

еӣҫВ 6В еј•е…ҘвҖңиҷҡжӢҹиҠӮзӮ№вҖқеҗҺзҡ„жҳ е°„е…ізі»
В
жӯӨж—¶пјҢеҜ№иұЎеҲ°вҖңиҷҡжӢҹиҠӮзӮ№вҖқзҡ„жҳ е°„е…ізі»дёәпјҡ
objec1->cache A2В пјӣВ objec2->cache A1В пјӣВ objec3->cache C1В пјӣВ objec4->cache C2В пјӣ
еӣ жӯӨеҜ№иұЎВ object1В е’ҢВ object2В йғҪиў«жҳ е°„еҲ°дәҶВ cache AВ дёҠпјҢиҖҢВ object3В е’ҢВ object4В жҳ е°„еҲ°дәҶВ cache CВ дёҠпјӣе№іиЎЎжҖ§жңүдәҶеҫҲеӨ§жҸҗй«ҳгҖӮ
еј•е…ҘвҖңиҷҡжӢҹиҠӮзӮ№вҖқеҗҺпјҢжҳ е°„е…ізі»е°ұд»ҺВ {В еҜ№иұЎВ ->В иҠӮзӮ№В }В иҪ¬жҚўеҲ°дәҶВ {В еҜ№иұЎВ ->В иҷҡжӢҹиҠӮзӮ№В }В гҖӮжҹҘиҜўзү©дҪ“жүҖеңЁВ cacheВ ж—¶зҡ„жҳ е°„е…ізі»еҰӮеӣҫВ 7В жүҖзӨәгҖӮ
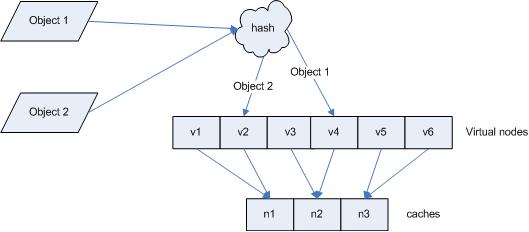
еӣҫВ 7В жҹҘиҜўеҜ№иұЎжүҖеңЁВ cache
В
вҖңиҷҡжӢҹиҠӮзӮ№вҖқзҡ„В hashВ и®Ўз®—еҸҜд»ҘйҮҮз”ЁеҜ№еә”иҠӮзӮ№зҡ„В IPВ ең°еқҖеҠ ж•°еӯ—еҗҺзјҖзҡ„ж–№ејҸгҖӮдҫӢеҰӮеҒҮи®ҫВ cache AВ зҡ„В IPВ ең°еқҖдёә202.168.14.241В гҖӮ
еј•е…ҘвҖңиҷҡжӢҹиҠӮзӮ№вҖқеүҚпјҢи®Ўз®—В cache AВ зҡ„В hashВ еҖјпјҡ
Hash(вҖң202.168.14.241вҖқ);
еј•е…ҘвҖңиҷҡжӢҹиҠӮзӮ№вҖқеҗҺпјҢи®Ўз®—вҖңиҷҡжӢҹиҠӮвҖқзӮ№В cache A1В е’ҢВ cache A2В зҡ„В hashВ еҖјпјҡ
Hash(вҖң202.168.14.241#1вҖқ);В В // cache A1
Hash(вҖң202.168.14.241#2вҖқ);В В // cache A2
5В е°Ҹз»“
Consistent hashingВ зҡ„еҹәжң¬еҺҹзҗҶе°ұжҳҜиҝҷдәӣпјҢе…·дҪ“зҡ„еҲҶеёғжҖ§зӯүзҗҶи®әеҲҶжһҗеә”иҜҘжҳҜеҫҲеӨҚжқӮзҡ„пјҢдёҚиҝҮдёҖиҲ¬д№ҹз”ЁдёҚеҲ°гҖӮ
http://weblogs.java.net/blog/2007/11/27/consistent-hashingВ дёҠйқўжңүдёҖдёӘВ javaВ зүҲжң¬зҡ„дҫӢеӯҗпјҢеҸҜд»ҘеҸӮиҖғгҖӮ
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspxВ иҪ¬иҪҪдәҶдёҖдёӘВ PHPВ зүҲзҡ„е®һзҺ°д»Јз ҒгҖӮ
http://www.codeproject.com/KB/recipes/lib-conhash.aspxВ CиҜӯиЁҖзүҲжң¬
В
В
дёҖдәӣеҸӮиҖғиө„ж–ҷең°еқҖпјҡ
http://portal.acm.org/citation.cfm?id=258660
http://en.wikipedia.org/wiki/Consistent_hashing
http://www.spiteful.com/2008/03/17/programmers-toolbox-part-3-consistent-hashing/
В http://weblogs.java.net/blog/2007/11/27/consistent-hashing
http://tech.idv2.com/2008/07/24/memcached-004/
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx
В
иҪ¬иҪҪең°еқҖпјҡhttp://blog.csdn.net/sparkliang/article/details/5279393



зӣёе…іжҺЁиҚҗ
еңЁеҲҶеёғејҸзі»з»ҹдёӯпјҢеёёеёёйңҖиҰҒдҪҝз”Ёзј“еӯҳпјҢиҖҢдё”йҖҡеёёжҳҜйӣҶзҫӨпјҢи®ҝй—®зј“еӯҳе’Ңж·»еҠ зј“еӯҳйғҪйңҖиҰҒдёҖдёӘ hash з®—жі•жқҘеҜ»жүҫеҲ°еҗҲйҖӮзҡ„ Cache иҠӮзӮ№гҖӮдҪҶпјҢйҖҡеёёдёҚжҳҜз”ЁеҸ–дҪҷhashпјҢиҖҢжҳҜдҪҝз”ЁжҲ‘们д»ҠеӨ©зҡ„дё»и§’вҖ”вҖ” дёҖиҮҙжҖ§ hash з®—жі•гҖӮ
дёҖиҮҙжҖ§е“ҲеёҢпјҲConsistent HashingпјүжҳҜдёҖз§Қз”ЁдәҺеҲҶеёғејҸзі»з»ҹзҡ„е“ҲеёҢз®—жі•пјҢдё»иҰҒеә”з”ЁдәҺеҲҶеёғејҸзј“еӯҳгҖҒеҲҶеёғејҸж•°жҚ®еә“зӯүеңәжҷҜпјҢзӣ®зҡ„жҳҜеңЁиҠӮзӮ№еҠЁжҖҒеўһеҮҸж—¶дҝқжҢҒе“ҲеёҢиЎЁзҡ„зЁіе®ҡжҖ§пјҢд»ҺиҖҢжңҖе°ҸеҢ–ж•°жҚ®иҝҒ移зҡ„еҪұе“ҚгҖӮе®ғи§ЈеҶідәҶдј з»ҹе“ҲеёҢеҸ–жЁЎж–№жі•еңЁ...
### дёҖиҮҙжҖ§ Hash з®—жі•иҜҰи§Ј #### дёҖгҖҒеј•иЁҖ дёҖиҮҙжҖ§ Hash з®—жі•жҳҜдёҖз§Қзү№ж®Ҡзҡ„е“ҲеёҢз®—жі•пјҢдё»иҰҒз”ЁдәҺи§ЈеҶіеҲҶеёғејҸзі»з»ҹдёӯиҠӮзӮ№еўһеҲ ж—¶ж•°жҚ®йҮҚе®ҡдҪҚзҡ„й—®йўҳгҖӮиҜҘз®—жі•жңҖж—©дәҺ1997е№ҙеңЁгҖҠConsistent hashing and random treesгҖӢиҝҷзҜҮи®әж–Үдёӯ...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•(Consistent Hashing)жҳҜдёҖз§ҚеңЁеҲҶеёғејҸзі»з»ҹдёӯе№іиЎЎж•°жҚ®еҲҶеёғзҡ„зӯ–з•ҘпјҢе°Өе…¶йҖӮз”ЁдәҺзј“еӯҳжңҚеҠЎеҰӮMemcachedжҲ–RedisгҖӮе®ғзҡ„ж ёеҝғжҖқжғіжҳҜйҖҡиҝҮе“ҲеёҢеҮҪж•°е°ҶеҜ№иұЎжҳ е°„еҲ°дёҖдёӘеӣәе®ҡеӨ§е°Ҹзҡ„зҺҜеҪўз©әй—ҙдёӯпјҢ然еҗҺе°ҶжңҚеҠЎеҷЁд№ҹжҳ е°„еҲ°иҝҷдёӘ...
е®ғжңҖж—©еңЁ1997е№ҙзҡ„и®әж–ҮгҖҠConsistent Hashing and Random TreesгҖӢдёӯиў«жҸҗеҮәпјҢж—ЁеңЁе…ӢжңҚдј з»ҹе“ҲеёҢз®—жі•еңЁеҠЁжҖҒж·»еҠ жҲ–еҲ йҷӨиҠӮзӮ№ж—¶еҜјиҮҙзҡ„еӨ§йҮҸж•°жҚ®иҝҒ移问йўҳгҖӮ дј з»ҹзҡ„е“ҲеёҢз®—жі•дјҡе°ҶеҜ№иұЎйҖҡиҝҮе“ҲеёҢеҮҪж•°жҳ е°„еҲ°дёҖдёӘеӣәе®ҡж•°йҮҸзҡ„жЎ¶пјҲдҫӢеҰӮ...
### дёҖиҮҙжҖ§Hashз®—жі•зҡ„еҺҹзҗҶеҸҠе®һзҺ° #### дёҖгҖҒеј•иЁҖ дёҖиҮҙжҖ§Hashз®—жі•жҳҜдёҖз§Қз”ЁдәҺи§ЈеҶіеҲҶеёғејҸзҺҜеўғдёӢж•°жҚ®еӯҳеӮЁе’ҢжЈҖзҙўй—®йўҳзҡ„йҮҚиҰҒжҠҖжңҜгҖӮе®ғжңҖеҲқз”ұDavid KargerзӯүдәәеңЁ1997е№ҙзҡ„и®әж–ҮгҖҠConsistent Hashing and Random Trees: ...
дёҖиҮҙжҖ§е“ҲеёҢпјҲConsistent HashingпјүжҳҜдёҖз§ҚеҲҶеёғејҸе“ҲеёҢиЎЁпјҲDHTпјүзҡ„з®—жі•пјҢе®ғдё»иҰҒеә”з”ЁдәҺеҲҶеёғејҸзј“еӯҳгҖҒиҙҹиҪҪеқҮиЎЎзӯүеңәжҷҜпјҢж—ЁеңЁи§ЈеҶіеңЁеҠЁжҖҒжү©еұ•жҲ–收缩系з»ҹ规模时пјҢе°ҪйҮҸеҮҸе°‘ж•°жҚ®иҝҒ移зҡ„й—®йўҳгҖӮеңЁиҝҷдёӘз®ҖеҚ•зҡ„е®һзҺ°дёӯпјҢжҲ‘们е°ҶжҺўи®ЁеҰӮдҪ•...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•пјҲConsistent HashingпјүжҳҜдёҖз§Қеёёз”ЁдәҺеҲҶеёғејҸзі»з»ҹдёӯзҡ„ж•°жҚ®еҲҶзүҮзӯ–з•ҘпјҢе®ғжңүж•Ҳең°и§ЈеҶідәҶж•°жҚ®еңЁеӨҡеҸ°жңҚеҠЎеҷЁй—ҙеқҮеҢҖеҲҶеёғзҡ„й—®йўҳпјҢеҗҢж—¶еҮҸе°‘дәҶеӣ иҠӮзӮ№еҠ е…ҘжҲ–зҰ»ејҖж—¶зҡ„ж•°жҚ®иҝҒ移жҲҗжң¬гҖӮ йҰ–е…ҲпјҢдёҖиҮҙжҖ§е“ҲеёҢзҡ„еҹәжң¬еҺҹзҗҶжҳҜе°Ҷ...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•пјҲConsistent HashingпјүжҳҜдёҖз§Қзү№ж®Ҡзҡ„е“ҲеёҢз®—жі•пјҢи®ҫи®Ўзӣ®зҡ„жҳҜдёәдәҶеңЁеҲҶеёғејҸзј“еӯҳзі»з»ҹдёӯи§ЈеҶіиҠӮзӮ№еҠЁжҖҒеўһеҮҸж—¶еҜјиҮҙзҡ„ж•°жҚ®еҲҶеёғдёҚеқҮй—®йўҳгҖӮиҜҘз®—жі•жңҖж—©еңЁ1997е№ҙзҡ„и®әж–ҮгҖҠConsistent Hashing and Random TreesгҖӢдёӯиў«...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•(Consistent Hashing)жҳҜдёҖз§Қзү№ж®Ҡзҡ„е“ҲеёҢз®—жі•пјҢи®ҫи®Ўзӣ®зҡ„жҳҜдёәдәҶеңЁеҲҶеёғејҸзј“еӯҳзі»з»ҹдёӯи§ЈеҶіиҠӮзӮ№еҠЁжҖҒеўһеҮҸж—¶еҜјиҮҙзҡ„й”®еҖјжҳ е°„еӨ§йҮҸеҸҳжӣҙзҡ„й—®йўҳгҖӮе®ғжңҖж—©еңЁ1997е№ҙзҡ„и®әж–ҮгҖҠConsistent hashing and random treesгҖӢдёӯиў«...
дёҖиҮҙжҖ§е“ҲеёҢз®—жі•пјҲConsistent HashingпјүжҳҜдёҖз§ҚеңЁеҲҶеёғејҸзі»з»ҹдёӯе®һзҺ°иҙҹиҪҪеқҮиЎЎзҡ„з®—жі•пјҢе°Өе…¶еңЁеҲҶеёғејҸзј“еӯҳеҰӮMemcachedе’ҢRedisзӯүеңәжҷҜдёӢе№ҝжіӣдҪҝз”ЁгҖӮе®ғи§ЈеҶідәҶдј з»ҹе“ҲеёҢз®—жі•еңЁиҠӮзӮ№еўһеҮҸж—¶еҜјиҮҙзҡ„еӨ§йҮҸж•°жҚ®иҝҒ移问йўҳпјҢжҸҗй«ҳдәҶзі»з»ҹзҡ„еҸҜз”Ё...
дёҖиҮҙжҖ§е“ҲеёҢпјҲConsistent HashingпјүжҳҜдёҖз§ҚеҲҶеёғејҸе“ҲеёҢз®—жі•пјҢдё»иҰҒеә”з”ЁдәҺеҲҶеёғејҸзј“еӯҳгҖҒиҙҹиҪҪеқҮиЎЎзӯүйўҶеҹҹпјҢд»Ҙи§ЈеҶіеңЁеҲҶеёғејҸзҺҜеўғдёӯеҠЁжҖҒж·»еҠ жҲ–еҲ йҷӨиҠӮзӮ№ж—¶пјҢе°ҪеҸҜиғҪе°‘ең°ж”№еҸҳе·Іжңүзҡ„е“ҲеёҢжҳ е°„е…ізі»гҖӮеңЁиҝҷдёӘJavaе®һзҺ°дёӯпјҢжҲ‘们зңӢеҲ°зҡ„жҳҜ...
жң¬ж–Үе®һдҫӢи®Іиҝ°дәҶPHPе®һзҺ°зҡ„дёҖиҮҙжҖ§Hashз®—жі•гҖӮеҲҶдә«з»ҷеӨ§е®¶дҫӣеӨ§е®¶еҸӮиҖғпјҢе…·дҪ“еҰӮдёӢпјҡ дёҖиҮҙжҖ§е“ҲеёҢз®—жі•жҳҜеҲҶеёғејҸзі»з»ҹдёӯеёёз”Ёзҡ„з®—жі•пјҢдёәд»Җд№ҲиҰҒз”ЁиҝҷдёӘз®—жі•пјҹ жҜ”еҰӮпјҡдёҖдёӘеҲҶеёғејҸеӯҳеӮЁзі»з»ҹпјҢиҰҒе°Ҷж•°жҚ®еӯҳеӮЁеҲ°е…·дҪ“зҡ„иҠӮзӮ№пјҲжңҚеҠЎеҷЁпјүдёҠпјҢ еңЁ...
#fly-archflylibеҲӣз«Ӣзҡ„еҗ„з§Қеёёи§Ғзҡ„жһ¶жһ„жҠҖжңҜеҶ…е®№еҲ—иЎЁcassandra-demo cassandraж•°жҚ®еә“зҡ„е…Ҙй—Ёзј–зЁӢconsistent-hash Java implementation of consistent-hashingеҹәдәҺjavaзҡ„дёҖиҮҙжҖ§hashзҡ„е®һзҺ°дёҖиҮҙжҖ§hash(consistent-hashing)...
дёҖиҮҙжҖ§е“ҲеёҢпјҲConsistent HashingпјүжҳҜдёҖз§ҚеҲҶеёғејҸе“ҲеёҢиЎЁпјҲDHT, Distributed Hash Tableпјүз®—жі•пјҢдё»иҰҒз”ЁдәҺи§ЈеҶіеңЁеҲҶеёғејҸзі»з»ҹдёӯж•°жҚ®еӯҳеӮЁе’ҢжЈҖзҙўзҡ„й—®йўҳпјҢе°Өе…¶жҳҜеңЁеҠЁжҖҒжү©еұ•йӣҶзҫӨиҠӮзӮ№ж—¶пјҢиғҪеӨҹе°ҪеҸҜиғҪең°еҮҸе°‘зј“еӯҳйҮҚе»әпјҢдҝқжҢҒзі»з»ҹ...
жң¬ж–Үе°Ҷдјҡд»Һе®һйҷ…еә”з”ЁеңәжҷҜеҮәеҸ‘пјҢд»Ӣз»ҚдёҖиҮҙжҖ§е“ҲеёҢз®—жі•пјҲConsistent HashingпјүеҸҠ е…¶еңЁеҲҶеёғејҸзі»з»ҹдёӯзҡ„еә”з”ЁгҖӮйҰ–е…Ҳжң¬ж–ҮдјҡжҸҸиҝ°дёҖдёӘеңЁж—ҘеёёејҖеҸ‘дёӯз»ҸеёёдјҡйҒҮеҲ°зҡ„й—®йўҳ еңәжҷҜпјҢеҖҹжӯӨд»Ӣз»ҚдёҖиҮҙжҖ§е“ҲеёҢз®—жі•д»ҘеҸҠиҝҷдёӘз®—жі•еҰӮдҪ•и§ЈеҶіжӯӨй—®йўҳпјӣжҺҘ...
дёҖиҮҙжҖ§е“ҲеёҢ(Consistent Hashing)жҳҜдёҖз§ҚеҲҶеёғејҸе“ҲеёҢиЎЁ(DHT, Distributed Hash Table)зҡ„з®—жі•пјҢдё»иҰҒз”ЁдәҺи§ЈеҶіеңЁеҲҶеёғејҸзі»з»ҹдёӯж•°жҚ®еҲҶзүҮгҖҒиҙҹиҪҪеқҮиЎЎгҖҒзј“еӯҳеҲҶеҸ‘зӯүй—®йўҳгҖӮеңЁдә‘и®Ўз®—е’ҢеӨ§ж•°жҚ®йўҶеҹҹпјҢдёҖиҮҙжҖ§е“ҲеёҢз®—жі•жңүзқҖе№ҝжіӣзҡ„еә”з”ЁпјҢ...
дёҖиҮҙжҖ§е“ҲеёҢпјҲConsistent HashingпјүжҳҜдёҖз§ҚеҲҶеёғејҸе“ҲеёҢпјҲDistributed Hash TableпјҢDHTпјүз®—жі•пјҢдё»иҰҒз”ЁдәҺи§ЈеҶіеңЁеҲҶеёғејҸзі»з»ҹдёӯзҡ„ж•°жҚ®еӯҳеӮЁе’ҢжЈҖзҙўй—®йўҳгҖӮеңЁдә‘и®Ўз®—гҖҒзј“еӯҳзі»з»ҹпјҲеҰӮRedisгҖҒMemcachedпјүд»ҘеҸҠиҙҹиҪҪеқҮиЎЎзӯүйўҶеҹҹе№ҝжіӣеә”з”Ё...