
(õĖĆ) µŗåÕłåÕ«×µ¢ĮńŁ¢ńĢźÕÆīńż║õŠŗµ╝öńż║
(õ║ī) Õģ©Õ▒ĆõĖ╗ķö«ńö¤µłÉńŁ¢ńĢź
(õĖē) Õģ│õ║ÄõĮ┐ńö©µĪåµ×ČĶ┐śµś»Ķć¬õĖ╗Õ╝ĆÕÅæõ╗źÕÅŖshardingÕ«×ńÄ░Õ▒éķØóńÜäĶĆāķćÅ
(Õøø) ÕżÜµĢ░µŹ«µ║ÉńÜäõ║ŗÕŖĪÕżäńÉå
(õ║ö) õĖĆń¦Źµö»µīüĶć¬ńö▒Ķ¦äÕłÆµŚĀķĪ╗µĢ░µŹ«Ķ┐üń¦╗ÕÆīõ┐«µö╣ĶĘ»ńö▒õ╗ŻńĀüńÜäShardingµē®Õ«╣µ¢╣µĪł
(õĖĆ) µŗåÕłåÕ«×µ¢ĮńŁ¢ńĢźÕÆīńż║õŠŗµ╝öńż║
ń¼¼õĖĆķā©Õłå’╝ÜÕ«×µ¢ĮńŁ¢ńĢź
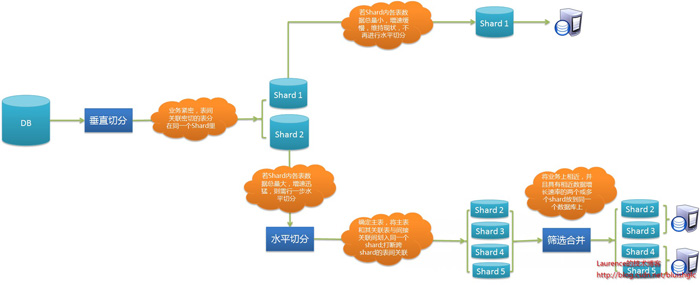
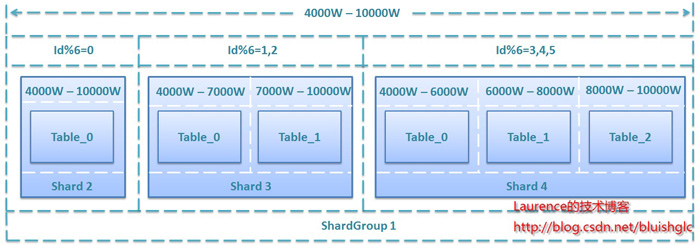
ÕøŠ1.µĢ░µŹ«Õ║ōÕłåÕ║ōÕłåĶĪ©(sharding)Õ«×µ¢ĮńŁ¢ńĢźÕøŠĶ¦Ż
1.ÕćåÕżćķśČµ«Ą
Õ»╣µĢ░µŹ«Õ║ōĶ┐øĶĪīÕłåÕ║ōÕłåĶĪ©(ShardingÕī¢)ÕēŹ’╝īķ£ĆĶ”üÕ╝ĆÕÅæõ║║ÕæśÕģģÕłåõ║åĶ¦Żń│╗ń╗¤õĖÜÕŖĪķĆ╗ĶŠæÕÆīµĢ░µŹ«Õ║ōschema.õĖĆõĖ¬ÕźĮńÜäÕ╗║Ķ««µś»ń╗śÕłČõĖĆÕ╝ĀµĢ░µŹ«Õ║ōERÕøŠµł¢ķóåÕ¤¤µ©ĪÕ×ŗÕøŠ’╝īõ╗źĶ┐Öń▒╗ÕøŠõĖ║Õ¤║ńĪĆÕłÆÕłåshard,ńø┤Ķ¦éµśōĶĪī’╝īÕÅ»õ╗źńĪ«õ┐ØÕ╝ĆÕÅæõ║║ÕæśÕ¦ŗń╗łõ┐صīüµĖģķåƵĆØĶĘ»ŃĆéÕ»╣õ║ĵś»ķĆēµŗ®µĢ░µŹ«Õ║ōERÕøŠĶ┐śµś»ķóåÕ¤¤µ©ĪÕ×ŗÕøŠĶ”üµĀ╣µŹ«ķĪ╣ńø«Ķć¬Ķ║½µāģÕåĄĶ┐øĶĪīķĆēµŗ®ŃĆéÕ”éµ×£ķĪ╣ńø«õĮ┐ńö©µĢ░µŹ«ķ®▒ÕŖ©ńÜäÕ╝ĆÕÅæµ¢╣Õ╝Å’╝īÕøóķś¤õ╗źµĢ░µŹ«Õ║ōERÕøŠõĮ£õĖ║õĖÜÕŖĪõ║żµĄüńÜäÕ¤║ńĪĆ’╝īÕłÖĶć¬ńäČõ╝ÜķĆēµŗ®µĢ░µŹ«Õ║ōERÕøŠ’╝īÕ”éµ×£ķĪ╣ńø«õĮ┐ńö©ńÜ䵜»ķóåÕ¤¤ķ®▒ÕŖ©ńÜäÕ╝ĆÕÅæµ¢╣Õ╝Å’╝īÕ╣ČķĆÜĶ┐ćOR-Mappingµ×äÕ╗║õ║åõĖĆõĖ¬Ķē»ÕźĮńÜäķóåÕ¤¤µ©ĪÕ×ŗ’╝īķéŻõ╣łķóåÕ¤¤µ©ĪÕ×ŗÕøŠµŚĀń¢æµś»µ£ĆÕźĮńÜäķĆēµŗ®ŃĆéÕ░▒µłæõĖ¬õ║║µØźĶ»┤’╝īµø┤ÕŖĀÕĆŠÕÉæõĮ┐ńö©ķóåÕ¤¤µ©ĪÕ×ŗÕøŠ’╝īÕøĀõĖ║Ķ┐øĶĪīÕłćÕłåµŚČµø┤ÕżÜńÜ䵜»õ╗źõĖÜÕŖĪõĖ║õŠØµŹ«Ķ┐øĶĪīÕłåµ×ÉÕłżµ¢Ł’╝īķóåÕ¤¤µ©ĪÕ×ŗµŚĀń¢æµø┤ÕŖĀµĖģµÖ░ÕÆīńø┤Ķ¦éŃĆé
2.Õłåµ×ÉķśČµ«Ą
1. Õ×éńø┤ÕłćÕłå
Õ×éńø┤ÕłćÕłåńÜäõŠØµŹ«ÕÄ¤ÕłÖµś»’╝ÜÕ░åõĖÜÕŖĪń┤¦Õ»å’╝īĶĪ©ķŚ┤Õģ│ĶüöÕ»åÕłćńÜäĶĪ©ÕłÆÕłåÕ£©õĖĆĶĄĘ’╝īõŠŗÕ”éÕÉīõĖƵ©ĪÕØŚńÜäĶĪ©ŃĆéń╗ōÕÉłÕĘ▓ń╗ÅÕćåÕżćÕźĮńÜäµĢ░µŹ«Õ║ōERÕøŠµł¢ķóåÕ¤¤µ©ĪÕ×ŗÕøŠ’╝īõ╗┐ńģ¦µ┤╗ÕŖ©ÕøŠõĖŁńÜäµ││ķüōµ”éÕ┐Ą’╝īõĖĆõĖ¬µ││ķüōõ╗ŻĶĪ©õĖĆõĖ¬shard’╝īµŖŖµēƵ£ēĶĪ©µĀ╝ÕłÆÕłåÕł░õĖŹÕÉīńÜäµ││ķüōõĖŁŃĆéõĖŗķØóńÜäÕłåµ×Éńż║õŠŗõ╝ÜÕ▒Ģńż║Ķ┐Öń¦ŹÕüܵ│ĢŃĆéÕĮōńäČ’╝īõĮĀõ╣¤ÕÅ»õ╗źÕ£©µēōÕŹ░Õć║ńÜäERÕøŠµł¢µ©ĪÕ×ŗÕøŠõĖŖńø┤µÄźńö©ķōģń¼öÕ£ł’╝īõĖĆÕłćÕÅ¢Õå│õ║ÄõĮĀĶć¬ÕĘ▒ńÜäÕ¢£ÕźĮŃĆé
2. µ░┤Õ╣│ÕłćÕłå
Õ×éńø┤ÕłćÕłåÕÉÄ’╝īķ£ĆĶ”üÕ»╣shardÕåģĶĪ©µĀ╝ńÜäµĢ░µŹ«ķćÅÕÆīÕó×ķƤĶ┐øõĖƵŁźÕłåµ×É’╝īõ╗źńĪ«Õ«Üµś»ÕÉ”ķ£ĆĶ”üĶ┐øĶĪīµ░┤Õ╣│ÕłćÕłåŃĆé
2.1ĶŗźÕłÆÕłåÕł░õĖĆĶĄĘńÜäĶĪ©µĀ╝µĢ░µŹ«Õó×ķĢ┐ń╝ōµģó’╝īÕ£©õ║¦ÕōüõĖŖń║┐ÕÉÄÕÅ»ķüćĶ¦üńÜäĶČ│Õż¤ķĢ┐ńÜ䵌ȵ£¤ÕåģÕØćÕÅ»õ╗źńö▒ÕŹĢõĖƵĢ░µŹ«Õ║ōµē┐ĶĮĮ’╝īÕłÖõĖŹķ£ĆĶ”üĶ┐øĶĪīµ░┤Õ╣│ÕłćÕłå’╝īµēƵ£ēĶĪ©µĀ╝ķ®╗ńĢÖÕÉīõĖĆshard,µēƵ£ēĶĪ©ķŚ┤Õģ│ĶüöÕģ│ń│╗õ╝ÜÕŠŚÕł░µ£ĆÕż¦ķÖÉÕ║”ńÜäõ┐ØńĢÖ’╝īÕÉīµŚČõ┐ØĶ»üõ║åõ╣”ÕåÖSQLńÜäĶć¬ńö▒Õ║”’╝īõĖŹµśōÕÅŚjoinŃĆügroup byŃĆüorder byńŁēÕŁÉÕÅźķÖÉÕłČŃĆé
2.2 ĶŗźÕłÆÕłåÕł░õĖĆĶĄĘńÜäĶĪ©µĀ╝µĢ░µŹ«ķćÅÕĘ©Õż¦’╝īÕó×ķƤĶ┐ģńīø’╝īķ£ĆĶ”üĶ┐øõĖƵŁźĶ┐øĶĪīµ░┤Õ╣│ÕłåÕē▓ŃĆéĶ┐øõĖƵŁźńÜäµ░┤Õ╣│ÕłåÕē▓Õ░▒Ķ┐ÖµĀĘĶ┐øĶĪī’╝Ü
2.2.1.ń╗ōÕÉłõĖÜÕŖĪķĆ╗ĶŠæÕÆīĶĪ©ķŚ┤Õģ│ń│╗’╝īÕ░åÕĮōÕēŹshardÕłÆÕłåµłÉÕżÜõĖ¬µø┤Õ░ÅńÜäshard,ķĆÜÕĖĖµāģÕåĄõĖŗ’╝īĶ┐Öõ║øµø┤Õ░ÅńÜäshardµ»ÅõĖĆõĖ¬ķāĮÕŬÕīģÕɽõĖĆõĖ¬õĖ╗ĶĪ©’╝łÕ░åõ╗źĶ»źĶĪ©IDĶ┐øĶĪīµĢŻÕłŚńÜäĶĪ©’╝ēÕÆīÕżÜõĖ¬õĖÄÕģČÕģ│Ķüöµł¢ķŚ┤µÄźÕģ│ĶüöńÜäµ¼ĪĶĪ©ŃĆéĶ┐Öń¦ŹõĖĆõĖ¬shardõĖĆÕ╝ĀõĖ╗ĶĪ©ÕżÜÕ╝Āµ¼ĪĶĪ©ńÜäńŖČÕåĄµś»µ░┤Õ╣│ÕłćÕłåńÜäÕ┐ģńäČń╗ōµ×£ŃĆéĶ┐ÖµĀĘÕłćÕłåõĖŗµØź’╝īshardµĢ░ķćÅÕ░▒õ╝ÜĶ┐ģķƤÕó×ÕżÜŃĆéÕ”éµ×£µ»ÅõĖĆõĖ¬shardõ╗ŻĶĪ©õĖĆõĖ¬ńŗ¼ń½ŗńÜäµĢ░µŹ«Õ║ō’╝īķéŻõ╣łń«ĪńÉåÕÆīń╗┤µŖżµĢ░µŹ«Õ║ōÕ░åõ╝ÜķØ×ÕĖĖķ║╗ńā”’╝īĶĆīõĖöĶ┐Öõ║øÕ░ÅshardÕŠĆÕŠĆÕŬµ£ēõĖżõĖēÕ╝ĀĶĪ©’╝īõĖ║µŁżĶĆīÕ╗║ń½ŗõĖĆõĖ¬µ¢░Õ║ō’╝īÕł®ńö©ńÄćÕ╣ČõĖŹķ½ś’╝īÕøĀµŁż’╝īÕ£©µ░┤Õ╣│ÕłćÕłåÕ«īµłÉÕÉÄÕÅ»ÕåŹĶ┐øĶĪīõĖƵ¼ĪŌĆ£ÕÅŹÕÉæńÜäMergeŌĆØ,ÕŹ│’╝ÜÕ░åõĖÜÕŖĪõĖŖńøĖĶ┐æ’╝īÕ╣ČõĖöÕģʵ£ēńøĖĶ┐æµĢ░µŹ«Õó×ķĢ┐ķƤńÄć’╝łõĖ╗ĶĪ©µĢ░µŹ«ķćÅÕ£©ÕÉīõĖƵĢ░ķćÅń║¦õĖŖ’╝ēńÜäõĖżõĖ¬µł¢ÕżÜõĖ¬shardµöŠÕł░ÕÉīõĖĆõĖ¬µĢ░µŹ«Õ║ōõĖŖ’╝īÕ£©ķĆ╗ĶŠæõĖŖÕ«āõ╗¼õŠØńäȵś»ńŗ¼ń½ŗńÜäshard’╝īµ£ēÕÉäĶć¬ńÜäõĖ╗ĶĪ©’╝īÕ╣ČõŠØµŹ«ÕÉäĶć¬õĖ╗ĶĪ©ńÜäIDĶ┐øĶĪīµĢŻÕłŚ’╝īõĖŹÕÉīńÜäÕŬµś»Õ«āõ╗¼ńÜäµĢŻÕłŚÕÅ¢µ©Ī’╝łÕŹ│ĶŖéńé╣µĢ░ķćÅ’╝ēÕ┐ģķ£Ćµś»õĖĆĶć┤ńÜäŃĆéĶ┐ÖµĀĘ’╝īµ»ÅõĖ¬µĢ░µŹ«Õ║ōń╗ōńé╣õĖŖńÜäĶĪ©µĀ╝µĢ░ķćÅÕ░▒ńøĖÕ»╣Õ╣│ÕØćõ║åŃĆé
2.2.2. µēƵ£ēĶĪ©µĀ╝ÕØćÕłÆÕłåÕł░ÕÉłķĆéńÜäshardõ╣ŗÕÉÄ’╝īµēƵ£ēĶĘ©ĶČŖshardńÜäĶĪ©ķŚ┤Õģ│ĶüöķāĮÕ┐ģķĪ╗µēōµ¢Ł’╝īÕ£©õ╣”ÕåÖsqlµŚČ’╝īĶĘ©shardńÜäjoinŃĆügroup byŃĆüorder byķāĮÕ░åĶó½ń”üµŁó’╝īķ£ĆĶ”üÕ£©Õ║öńö©ń©ŗÕ║ÅÕ▒éķØóÕŹÅĶ░āĶ¦ŻÕå│Ķ┐Öõ║øķŚ«ķóśŃĆé
ńē╣Õł½µā│µÅÉõĖĆńé╣’╝Üń╗ŵ░┤Õ╣│ÕłćÕłåÕÉÄ’╝īshardńÜäń▓ÆÕ║”ÕŠĆÕŠĆĶ”üµ»öÕŬÕüÜÕ×éńø┤ÕłćÕē▓ńÜäń▓ÆÕ║”Ķ”üÕ░Å’╝īÕÄ¤ÕŹĢõĖĆÕ×éńø┤shardõ╝ÜĶó½ń╗åÕłåõĖ║õĖĆÕł░ÕżÜõĖ¬õ╗źõĖĆõĖ¬õĖ╗ĶĪ©õĖ║õĖŁÕ┐āÕģ│Ķüöµł¢ķŚ┤µÄźÕģ│ĶüöÕżÜõĖ¬µ¼ĪĶĪ©ńÜäshard’╝īµŁżµŚČńÜäshardń▓ÆÕ║”õĖÄķóåÕ¤¤ķ®▒ÕŖ©Ķ«ŠĶ«ĪõĖŁńÜäŌĆ£ĶüÜÕÉłŌĆص”éÕ┐ĄõĖŹĶ░ŗĶĆīÕÉł’╝īńöÜĶć│ÕÅ»õ╗źĶ»┤µś»Õ«īÕģ©õĖĆĶć┤’╝īµ»ÅõĖ¬shardńÜäõĖ╗ĶĪ©µŁŻµś»õĖĆõĖ¬ĶüÜÕÉłõĖŁńÜäĶüÜÕÉłµĀ╣’╝ü
3.Õ«×µ¢ĮķśČµ«Ą
Õ”éµ×£ķĪ╣ńø«Õ£©Õ╝ĆÕÅæõ╝ŖÕ¦ŗÕ░▒Õå│Õ«ÜĶ┐øĶĪīÕłåÕ║ōÕłåĶĪ©’╝īÕłÖõĖźµĀ╝µīēńģ¦Õłåµ×ÉĶ«ŠĶ«Īµ¢╣µĪłµÄ©Ķ┐øÕŹ│ÕÅ»ŃĆéÕ”éµ×£µś»Õ£©õĖŁµ£¤µ×ȵ×äµ╝öĶ┐øõĖŁÕ«×µ¢Į’╝īķÖżµÉŁÕ╗║Õ«×ńÄ░shardingķĆ╗ĶŠæńÜäÕ¤║ńĪĆĶ«Šµ¢ĮÕż¢(Õģ│õ║ÄĶ»źĶ»Øķóśõ╝ÜÕ£©õĖŗń»ćµ¢ćń½ĀõĖŁĶ┐øĶĪīķśÉĶ┐░)’╝īĶ┐śķ£ĆĶ”üÕ»╣ÕĤµ£ēSQLķĆÉõĖĆĶ┐ćµ╗żÕłåµ×É’╝īõ┐«µö╣ķéŻõ║øÕøĀõĖ║shardingĶĆīÕÅŚÕł░ÕĮ▒ÕōŹńÜäsql.
ń¼¼õ║īķā©Õłå’╝Üńż║õŠŗµ╝öńż║
µ£¼µ¢ćķĆēµŗ®õĖĆõĖ¬õ║║Õ░ĮńÜåń¤źńÜäÕ║öńö©’╝ÜjpetstoreµØźµ╝öńż║Õ”éõĮĢĶ┐øĶĪīÕłåÕ║ōÕłåĶĪ©(sharding)Õ£©Õłåµ×ÉķśČµ«ĄńÜäÕĘźõĮ£ŃĆéńö▒õ║ÄõĖĆõ║øõĖ¬õ║║ÕĤÕøĀ’╝īµ╝öńż║õĮ┐ńö©ńÜäjpetstoreµØźĶć¬ÕĤibatisÕ«śµ¢╣ńÜäõĖĆõĖ¬Demońēłµ£¼’╝īSVNÕ£░ÕØĆõĖ║’╝Ühttp://mybatis.googlecode.com/svn/tags/java_release_2.3.4-726/jpetstore-5ŃĆéÕģ│õ║ÄjpetstoreńÜäõĖÜÕŖĪķĆ╗ĶŠæĶ┐ÖķćīõĖŹÕåŹõ╗ŗń╗Ź’╝īĶ┐Öµś»õĖĆõĖ¬ķØ×ÕĖĖń«ĆÕŹĢńÜäńöĄÕĢåń│╗ń╗¤ÕĤÕ×ŗ’╝īÕģČķóåÕ¤¤µ©ĪÕ×ŗÕ”éõĖŗÕøŠ’╝Ü
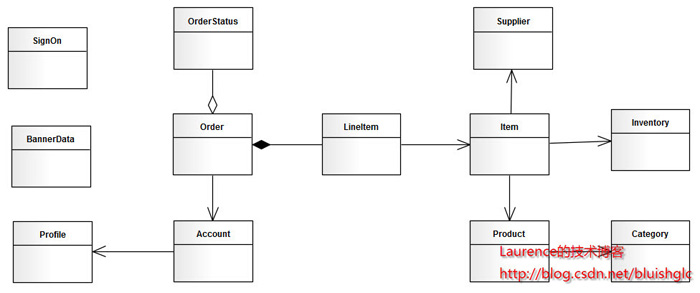
ÕøŠ2. jpetstoreķóåÕ¤¤µ©ĪÕ×ŗ
ńö▒õ║Äń│╗ń╗¤ĶŠāń«ĆÕŹĢ’╝īµłæõ╗¼ÕŠłÕ«╣µśōõ╗ĵ©ĪÕ×ŗõĖŖń£ŗÕć║’╝īÕģČõĖ╗Ķ”üńö▒õĖēõĖ¬µ©ĪÕØŚń╗䵳ɒ╝Üńö©µłĘ’╝īõ║¦ÕōüÕÆīĶ«óÕŹĢŃĆéķéŻõ╣łÕ×éńø┤ÕłćÕłåńÜäµ¢╣µĪłõ╣¤Õ░▒Õć║µØźõ║åŃĆéµÄźõĖŗµØźń£ŗµ░┤Õ╣│ÕłćÕłå’╝īÕ”éµ×£µłæõ╗¼õ╗ÄõĖĆõĖ¬Õ«×ķÖģńÜäÕ«Āńē®Õ║ŚÕć║ÕÅæĶĆāĶÖæ’╝īÕÅ»ĶāĮÕć║ńÄ░µĢ░µŹ«µ┐ĆÕó×ńÜäÕŹĢĶĪ©Õ║öĶ»źµś»AccountÕÆīOrder,ÕøĀµŁżĶ┐ÖõĖżÕ╝ĀĶĪ©ķ£ĆĶ”üĶ┐øĶĪīµ░┤Õ╣│ÕłćÕłåŃĆéÕ»╣õ║ÄProductµ©ĪÕØŚµØźĶ»┤’╝īÕ”éµ×£µś»õĖĆõĖ¬Õ«×ķÖģńÜäń│╗ń╗¤’╝īProductÕÆīItemńÜäµĢ░ķćÅķāĮõĖŹõ╝ÜÕŠłÕż¦’╝īÕøĀµŁżÕŬÕüÜÕ×éńø┤ÕłćÕłåÕ░▒ĶČ│Õż¤õ║å’╝īõ╣¤Õ░▒µś»’╝łProduct’╝īCategory’╝īItem’╝īIventory’╝īSupplier’╝ēõ║öÕ╝ĀĶĪ©Õ£©õĖĆõĖ¬µĢ░µŹ«Õ║ōń╗ōńé╣õĖŖ’╝łµ▓Īµ£ēµ░┤Õ╣│ÕłćÕłå’╝īõĖŹõ╝ÜÕŁśÕ£©õĖżõĖ¬õ╗źõĖŖńÜäµĢ░µŹ«Õ║ōń╗ōńé╣’╝ēŃĆéõĮåµś»õĮ£õĖ║õĖĆõĖ¬µ╝öńż║’╝īµłæõ╗¼ÕüćĶ«Šõ║¦Õōüµ©ĪÕØŚõ╣¤µ£ēÕż¦ķćÅńÜäµĢ░µŹ«ķ£ĆĶ”üµłæõ╗¼Õüܵ░┤Õ╣│ÕłćÕłå’╝īķéŻõ╣łÕłåµ×ÉµØźń£ŗ’╝īĶ┐ÖõĖ¬µ©ĪÕØŚĶ”üµŗåÕłåÕć║õĖżõĖ¬shard:õĖĆõĖ¬µś»’╝łProduct’╝łõĖ╗’╝ē’╝īCategory’╝ē’╝īÕÅ”õĖĆõĖ¬µś»’╝łItem’╝łõĖ╗’╝ē’╝īIventory’╝īSupplier’╝ē’╝īÕÉīµŚČ’╝īµłæõ╗¼Ķ«żõĖ║’╝ÜĶ┐ÖõĖżõĖ¬shardÕ£©µĢ░µŹ«Õó×ķƤõĖŖÕ║öĶ»źµś»ńøĖĶ┐æńÜä’╝īõĖöÕ£©õĖÜÕŖĪõĖŖõ╣¤ÕŠłń┤¦Õ»å’╝īķéŻõ╣łµłæõ╗¼ÕÅ»õ╗źµŖŖĶ┐ÖõĖżõĖ¬shardµöŠÕ£©ÕÉīõĖĆõĖ¬µĢ░µŹ«Õ║ōĶŖéńé╣õĖŖ’╝īItemÕÆīProductµĢ░µŹ«Õ£©µĢŻÕłŚµŚČÕÅ¢õĖƵĀĘńÜ䵩ĪŃĆéµĀ╣µŹ«ÕēŹµ¢ćõ╗ŗń╗ŹńÜäÕøŠń║Ėń╗śÕłČµ¢╣µ│Ģ’╝īµłæõ╗¼ÕŠŚÕł░õĖŗķØóĶ┐ÖÕ╝Āshardingńż║µäÅÕøŠ’╝Ü
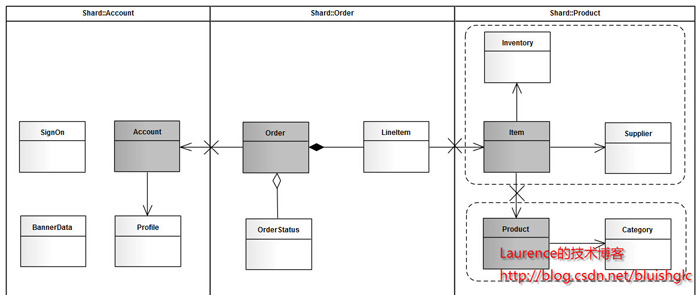
ÕøŠ3. jpetstore shardingńż║µäÅÕøŠ
Õ»╣õ║ÄĶ┐ÖÕ╝ĀÕøŠÕåŹĶ»┤µśÄÕćĀńé╣’╝Ü
1.õĮ┐ńö©µ││ķüōĶĪ©ńż║ńē®ńÉåshard’╝łõĖĆõĖ¬µĢ░µŹ«Õ║ōń╗ōńé╣’╝ē
2.ĶŗźÕ×éńø┤ÕłćÕłåÕć║ńÜäshardĶ┐øĶĪīõ║åĶ┐øõĖƵŁźńÜäµ░┤Õ╣│ÕłćÕłå’╝īõĮåÕģ¼ńö©õĖĆõĖ¬ńē®ńÉåshardńÜäĶ»Ø’╝īÕłÖńö©ĶÖÜń║┐µĪåõĮÅ’╝īĶĪ©ńż║ÕģČÕ£©ķĆ╗ĶŠæõĖŖµś»õĖĆõĖ¬ńŗ¼ń½ŗńÜäshardŃĆé
3.µĘ▒Ķē▓Õ«×õĮōĶĪ©ńż║õĖ╗ĶĪ©
4.XĶĪ©ńż║ķ£ĆĶ”üµēōµ¢ŁńÜäĶĪ©ķŚ┤Õģ│Ķüö
(õ║ī) Õģ©Õ▒ĆõĖ╗ķö«ńö¤µłÉńŁ¢ńĢź
ń¼¼õĖĆķā©Õłå’╝ÜõĖĆõ║øÕĖĖĶ¦üńÜäõĖ╗ķö«ńö¤µłÉńŁ¢ńĢź
õĖƵŚ”µĢ░µŹ«Õ║ōĶó½ÕłćÕłåÕł░ÕżÜõĖ¬ńē®ńÉåń╗ōńé╣õĖŖ’╝īµłæõ╗¼Õ░åõĖŹĶāĮÕåŹõŠØĶĄ¢µĢ░µŹ«Õ║ōĶć¬Ķ║½ńÜäõĖ╗ķö«ńö¤µłÉµ£║ÕłČŃĆéõĖƵ¢╣ķØó’╝īµ¤ÉõĖ¬ÕłåÕī║µĢ░µŹ«Õ║ōĶć¬ńö¤µłÉńÜäIDµŚĀµ│Ģõ┐ØĶ»üÕ£©Õģ©Õ▒ĆõĖŖµś»Õö»õĖĆńÜä’╝øÕÅ”õĖƵ¢╣ķØó’╝īÕ║öńö©ń©ŗÕ║ÅÕ£©µÅÆÕģźµĢ░µŹ«õ╣ŗÕēŹķ£ĆĶ”üÕģłĶÄĘÕŠŚID,õ╗źõŠ┐Ķ┐øĶĪīSQLĶĘ»ńö▒ŃĆéńø«ÕēŹÕćĀń¦ŹÕÅ»ĶĪīńÜäõĖ╗ķö«ńö¤µłÉńŁ¢ńĢźµ£ē’╝Ü
1. UUID’╝ÜõĮ┐ńö©UUIDõĮ£õĖ╗ķö«µś»µ£Ćń«ĆÕŹĢńÜäµ¢╣µĪł’╝īõĮåµś»ń╝║ńé╣õ╣¤µś»ķØ×ÕĖĖµśÄµśŠńÜäŃĆéńö▒õ║ÄUUIDķØ×ÕĖĖńÜäķĢ┐’╝īķÖżÕŹĀńö©Õż¦ķćÅÕŁśÕé©ń®║ķŚ┤Õż¢’╝īµ£ĆõĖ╗Ķ”üńÜäķŚ«ķ󜵜»Õ£©ń┤óÕ╝ĢõĖŖ’╝īÕ£©Õ╗║ń½ŗń┤óÕ╝ĢÕÆīÕ¤║õ║Äń┤óÕ╝ĢĶ┐øĶĪīµ¤źĶ»óµŚČķāĮÕŁśÕ£©µĆ¦ĶāĮķŚ«ķóśŃĆé
2. ń╗ōÕÉłµĢ░µŹ«Õ║ōń╗┤µŖżõĖĆõĖ¬SequenceĶĪ©’╝ܵŁżµ¢╣µĪłńÜäµĆØĶĘ»õ╣¤ÕŠłń«ĆÕŹĢ’╝īÕ£©µĢ░µŹ«Õ║ōõĖŁÕ╗║ń½ŗõĖĆõĖ¬SequenceĶĪ©’╝īĶĪ©ńÜäń╗ōµ×äń▒╗õ╝╝õ║Ä’╝Ü
[sql] view plaincopy
01.CREATE TABLE `SEQUENCE` (
02. `tablename` varchar(30) NOT NULL,
03. `nextid` bigint(20) NOT NULL,
04. PRIMARY KEY (`tablename`)
05.) ENGINE=InnoDB
µ»ÅÕĮōķ£ĆĶ”üõĖ║µ¤ÉõĖ¬ĶĪ©ńÜäµ¢░ń║¬ÕĮĢńö¤µłÉIDµŚČÕ░▒õ╗ÄSequenceĶĪ©õĖŁÕÅ¢Õć║Õ»╣Õ║öĶĪ©ńÜänextid,Õ╣ČÕ░ånextidńÜäÕĆ╝ÕŖĀ1ÕÉĵø┤µ¢░Õł░µĢ░µŹ«Õ║ōõĖŁõ╗źÕżćõĖŗµ¼ĪõĮ┐ńö©ŃĆ鵣żµ¢╣µĪłõ╣¤ĶŠāń«ĆÕŹĢ’╝īõĮåń╝║ńé╣ÕÉīµĀʵśÄµśŠ’╝Üńö▒õ║ĵēƵ£ēµÅÆÕģźõ╗╗õĮĢķāĮķ£ĆĶ”üĶ«┐ķŚ«Ķ»źĶĪ©’╝īĶ»źĶĪ©ÕŠłÕ«╣µśōµłÉõĖ║ń│╗ń╗¤µĆ¦ĶāĮńōČķół’╝īÕÉīµŚČÕ«āõ╣¤ÕŁśÕ£©ÕŹĢńé╣ķŚ«ķóś’╝īõĖƵŚ”Ķ»źĶĪ©µĢ░µŹ«Õ║ōÕż▒µĢł’╝īµĢ┤õĖ¬Õ║öńö©ń©ŗÕ║ÅÕ░åµŚĀµ│ĢÕĘźõĮ£ŃĆéµ£ēõ║║µÅÉÕć║õĮ┐ńö©Master-SlaveĶ┐øĶĪīõĖ╗õ╗ÄÕÉīµŁź’╝īõĮåĶ┐Öõ╣¤ÕŬĶāĮĶ¦ŻÕå│ÕŹĢńé╣ķŚ«ķóś’╝īÕ╣ČõĖŹĶāĮĶ¦ŻÕå│Ķ»╗ÕåÖµ»öõĖ║1:1ńÜäĶ«┐ķŚ«ÕÄŗÕŖøķŚ«ķóśŃĆé
ķÖżµŁżõ╣ŗÕż¢’╝īĶ┐śµ£ēõĖĆõ║øµ¢╣µĪł’╝īÕāÅÕ»╣µ»ÅõĖ¬µĢ░µŹ«Õ║ōń╗ōńé╣ÕłåÕī║µ«ĄÕłÆÕłåID,õ╗źÕÅŖńĮæõĖŖńÜäõĖĆõ║øIDńö¤µłÉń«Śµ│Ģ’╝īÕøĀõĖ║ń╝║Õ░æÕÅ»µōŹõĮ£µĆ¦ÕÆīÕ«×ĶĘĄµŻĆķ¬ī’╝īµ£¼µ¢ćÕ╣ČõĖŹµÄ©ĶŹÉŃĆéÕ«×ķÖģõĖŖ’╝īµÄźõĖŗµØź’╝īµłæõ╗¼Ķ”üõ╗ŗń╗ŹńÜ䵜»FickrõĮ┐ńö©ńÜäõĖĆń¦ŹõĖ╗ķö«ńö¤µłÉµ¢╣µĪł’╝īĶ┐ÖõĖ¬µ¢╣µĪłµś»ńø«ÕēŹµłæµēĆń¤źķüōńÜäµ£Ćõ╝śń¦ĆńÜäõĖĆõĖ¬µ¢╣µĪł’╝īÕ╣ČõĖöń╗ÅÕÅŚõ║åÕ«×ĶĘĄńÜ䵯Ćķ¬ī’╝īÕÅ»õ╗źõĖ║Õż¦ÕżÜµĢ░Õ║öńö©ń│╗ń╗¤µēĆÕƤķē┤ŃĆé
ń¼¼õ║īķā©Õłå’╝ÜõĖĆń¦Źµ×üõĖ║õ╝śń¦ĆńÜäõĖ╗ķö«ńö¤µłÉńŁ¢ńĢź
flickrÕ╝ĆÕÅæÕøóķś¤Õ£©2010Õ╣┤µÆ░µ¢ćõ╗ŗń╗Źõ║åflickrõĮ┐ńö©ńÜäõĖĆń¦ŹõĖ╗ķö«ńö¤µłÉµĄŗńŁ¢ńĢź’╝īÕÉīµŚČĶĪ©ńż║Ķ»źµ¢╣µĪłÕ£©flickrõĖŖńÜäÕ«×ķÖģĶ┐ÉĶĪīµĢłµ×£õ╣¤ķØ×ÕĖĖõ╗żõ║║µ╗ĪµäÅ’╝īÕĤµ¢ćĶ┐׵ğ’╝ÜTicket Servers: Distributed Unique Primary Keys on the Cheap Ķ┐ÖõĖ¬µ¢╣µĪłµś»µłæńø«ÕēŹń¤źķüōńÜäµ£ĆÕźĮńÜäµ¢╣µĪł’╝īÕ«āõĖÄõĖĆĶł¼SequenceĶĪ©µ¢╣µĪłµ£ēõ║øń▒╗õ╝╝’╝īõĮåÕŹ┤ÕŠłÕźĮÕ£░Ķ¦ŻÕå│õ║åµĆ¦ĶāĮńōČķółÕÆīÕŹĢńé╣ķŚ«ķóś’╝īµś»õĖĆń¦ŹķØ×ÕĖĖÕÅ»ķØĀĶĆīķ½śµĢłńÜäÕģ©Õ▒ĆõĖ╗ķö«ńö¤µłÉµ¢╣µĪłŃĆé
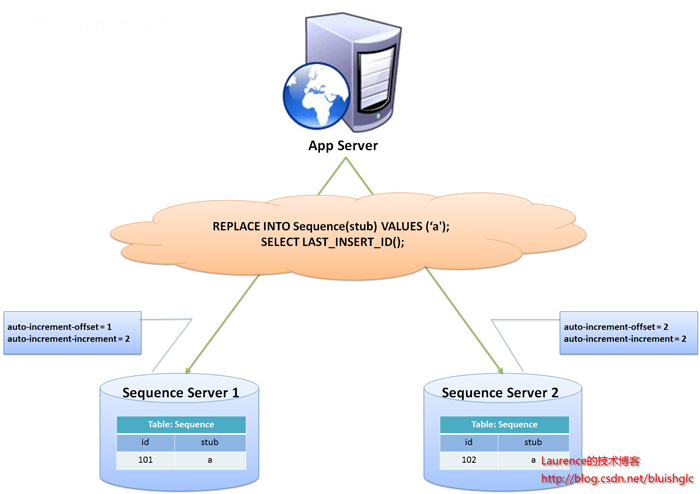
ÕøŠ1. flickrķććńö©ńÜäshardingõĖ╗ķö«ńö¤µłÉµ¢╣µĪłńż║µäÅÕøŠ
flickrĶ┐ÖõĖƵ¢╣µĪłńÜäµĢ┤õĮōµĆصā│µś»’╝ÜÕ╗║ń½ŗõĖżÕÅ░õ╗źõĖŖńÜäµĢ░µŹ«Õ║ōIDńö¤µłÉµ£ŹÕŖĪÕÖ©’╝īµ»ÅõĖ¬µ£ŹÕŖĪÕÖ©ķāĮµ£ēõĖĆÕ╝ĀĶ«░ÕĮĢÕÉäĶĪ©ÕĮōÕēŹIDńÜäSequenceĶĪ©’╝īõĮåµś»SequenceõĖŁIDÕó×ķĢ┐ńÜ䵣źķĢ┐µś»µ£ŹÕŖĪÕÖ©ńÜäµĢ░ķćÅ’╝īĶĄĘÕ¦ŗÕĆ╝õŠØµ¼ĪķöÖÕ╝Ć’╝īĶ┐ÖµĀĘńøĖÕĮōõ║ĵŖŖIDńÜäńö¤µłÉµĢŻÕłŚÕł░õ║åµ»ÅõĖ¬µ£ŹÕŖĪÕÖ©ĶŖéńé╣õĖŖŃĆéõŠŗÕ”é’╝ÜÕ”éµ×£µłæõ╗¼Ķ«ŠńĮ«õĖżÕÅ░µĢ░µŹ«Õ║ōIDńö¤µłÉµ£ŹÕŖĪÕÖ©’╝īķéŻõ╣łÕ░▒Ķ«®õĖĆÕÅ░ńÜäSequenceĶĪ©ńÜäIDĶĄĘÕ¦ŗÕĆ╝õĖ║1,µ»Åµ¼ĪÕó×ķĢ┐µŁźķĢ┐õĖ║2,ÕÅ”õĖĆÕÅ░ńÜäSequenceĶĪ©ńÜäIDĶĄĘÕ¦ŗÕĆ╝õĖ║2,µ»Åµ¼ĪÕó×ķĢ┐µŁźķĢ┐õ╣¤õĖ║2’╝īķéŻõ╣łń╗ōµ×£Õ░▒µś»ÕźćµĢ░ńÜäIDķāĮÕ░åõ╗Äń¼¼õĖĆÕÅ░µ£ŹÕŖĪÕÖ©õĖŖńö¤µłÉ’╝īÕüȵĢ░ńÜäIDķāĮõ╗Äń¼¼õ║īÕÅ░µ£ŹÕŖĪÕÖ©õĖŖńö¤µłÉ’╝īĶ┐ÖµĀĘÕ░▒Õ░åńö¤µłÉIDńÜäÕÄŗÕŖøÕØćÕīĆÕłåµĢŻÕł░õĖżÕÅ░µ£ŹÕŖĪÕÖ©õĖŖ’╝īÕÉīµŚČķģŹÕÉłÕ║öńö©ń©ŗÕ║ÅńÜäµÄ¦ÕłČ’╝īÕĮōõĖĆõĖ¬µ£ŹÕŖĪÕÖ©Õż▒µĢłÕÉÄ’╝īń│╗ń╗¤ĶāĮĶć¬ÕŖ©ÕłćµŹóÕł░ÕÅ”õĖĆõĖ¬µ£ŹÕŖĪÕÖ©õĖŖĶÄĘÕÅ¢ID’╝īõ╗ÄĶĆīõ┐ØĶ»üõ║åń│╗ń╗¤ńÜäÕ«╣ķöÖŃĆé
Õģ│õ║ÄĶ┐ÖõĖ¬µ¢╣µĪł’╝īµ£ēÕćĀńé╣ń╗åĶŖéĶ┐ÖķćīÕåŹĶ»┤µśÄõĖĆõĖŗ’╝Ü
- flickrńÜäµĢ░µŹ«Õ║ōIDńö¤µłÉµ£ŹÕŖĪÕÖ©µś»õĖōńö©µ£ŹÕŖĪÕÖ©’╝īµ£ŹÕŖĪÕÖ©õĖŖÕŬµ£ēõĖĆõĖ¬µĢ░µŹ«Õ║ō’╝īµĢ░µŹ«Õ║ōõĖŁĶĪ©ķāĮµś»ńö©õ║Äńö¤µłÉSequenceńÜä’╝īĶ┐Öõ╣¤µś»ÕøĀõĖ║auto-increment-offsetÕÆīauto-increment-incrementĶ┐ÖõĖżõĖ¬µĢ░µŹ«Õ║ōÕÅśķćŵś»µĢ░µŹ«Õ║ōÕ«×õŠŗń║¦Õł½ńÜäÕÅśķćÅŃĆé
- flickrńÜäµ¢╣µĪłõĖŁĶĪ©µĀ╝õĖŁńÜästubÕŁŚµ«ĄÕŬµś»õĖĆõĖ¬char(1) NOT NULLÕŁśµĀ╣ÕŁŚµ«Ą’╝īÕ╣ČķØ×ĶĪ©ÕÉŹ’╝īÕøĀµŁż’╝īõĖĆĶł¼µØźĶ»┤’╝īõĖĆõĖ¬SequenceĶĪ©ÕŬµ£ēõĖƵØĪń║¬ÕĮĢ’╝īÕÅ»õ╗źÕÉīµŚČõĖ║ÕżÜÕ╝ĀĶĪ©ńö¤µłÉID’╝īÕ”éµ×£ķ£ĆĶ”üĶĪ©ńÜäIDµś»µ£ēĶ┐×ń╗ŁńÜä’╝īķ£ĆĶ”üõĖ║Ķ»źĶĪ©ÕŹĢńŗ¼Õ╗║ń½ŗSequenceĶĪ©ŃĆé
- µ¢╣µĪłõĮ┐ńö©õ║åmysqlńÜäLAST_INSERT_ID()ÕćĮµĢ░’╝īĶ┐Öõ╣¤Õå│Õ«Üõ║åSequenceĶĪ©ÕŬĶāĮµ£ēõĖƵØĪĶ«░ÕĮĢŃĆé
- õĮ┐ńö©REPLACE INTOµÅÆÕģźµĢ░µŹ«’╝īĶ┐Öµś»ÕŠłĶ«©ÕʦńÜäõĮ£µ│Ģ’╝īõĖ╗Ķ”üµś»ÕĖīµ£øÕł®ńö©mysqlĶć¬Ķ║½ńÜäµ£║ÕłČńö¤µłÉID,õĖŹõ╗ģµś»ÕøĀõĖ║Ķ┐ÖµĀĘń«ĆÕŹĢ’╝īµø┤µś»ÕøĀõĖ║µłæõ╗¼ķ£ĆĶ”üIDµīēńģ¦µłæõ╗¼Ķ«ŠÕ«ÜńÜäµ¢╣Õ╝Å(ÕłØÕĆ╝ÕÆīµŁźķĢ┐)µØźńö¤µłÉŃĆé
- SELECT LAST_INSERT_ID()Õ┐ģķĪ╗Ķ”üõ║ÄREPLACE INTOĶ»ŁÕÅźÕ£©ÕÉīõĖĆõĖ¬µĢ░µŹ«Õ║ōĶ┐׵ğõĖŗµēŹĶāĮÕŠŚÕł░ÕłÜÕłÜµÅÆÕģźńÜäµ¢░ID’╝īÕÉ”ÕłÖĶ┐öÕø×ńÜäÕĆ╝µĆ╗µś»0
- Ķ»źµ¢╣µĪłõĖŁSequenceĶĪ©õĮ┐ńö©ńÜ䵜»MyISAMÕ╝ĢµōÄ’╝īõ╗źĶÄĘÕÅ¢µø┤ķ½śńÜäµĆ¦ĶāĮ’╝īµ│©µäÅ’╝ÜMyISAMÕ╝ĢµōÄõĮ┐ńö©ńÜ䵜»ĶĪ©ń║¦Õł½ńÜäķöü’╝īMyISAMÕ»╣ĶĪ©ńÜäĶ»╗ÕåÖµś»õĖ▓ĶĪīńÜä’╝īÕøĀµŁżõĖŹÕ┐ģµŗģÕ┐āÕ£©Õ╣ČÕÅæµŚČõĖżµ¼ĪĶ»╗ÕÅ¢õ╝ÜÕŠŚÕł░ÕÉīõĖĆõĖ¬ID(ÕÅ”Õż¢’╝īÕ║öĶ»źń©ŗÕ║Åõ╣¤õĖŹķ£ĆĶ”üÕÉīµŁź’╝īµ»ÅõĖ¬Ķ»Ęµ▒éńÜäń║┐ń©ŗķāĮõ╝ÜÕŠŚÕł░õĖĆõĖ¬µ¢░ńÜäconnection,õĖŹÕŁśÕ£©ķ£ĆĶ”üÕÉīµŁźńÜäÕģ▒õ║½ĶĄäµ║É)ŃĆéń╗ÅĶ┐ćÕ«×ķÖģÕ»╣µ»öµĄŗĶ»Ģ’╝īõĮ┐ńö©õĖƵĀĘńÜäSequenceĶĪ©Ķ┐øĶĪīIDńö¤µłÉ’╝īMyISAMÕ╝ĢµōÄĶ”üµ»öInnoDBĶĪ©ńÄ░ķ½śÕć║ÕŠłÕżÜ’╝ü
- ÕÅ»õĮ┐ńö©ń║»JDBCÕ«×ńÄ░Õ»╣SequenceĶĪ©ńÜäµōŹõĮ£’╝īõ╗źõŠ┐ĶÄĘÕŠŚµø┤ķ½śńÜäµĢłńÄć’╝īÕ«×ķ¬īĶĪ©µśÄ’╝īÕŹ│õĮ┐ÕŬõĮ┐ńö©Spring JDBCµĆ¦ĶāĮõ╣¤õĖŹÕÅŖń║»JDBCµØźÕŠŚÕ┐½
Õ«×ńÄ░Ķ»źµ¢╣µĪł’╝īÕ║öńö©ń©ŗÕ║ÅÕÉīµĀĘķ£ĆĶ”üÕüÜõĖĆõ║øÕżäńÉå’╝īõĖ╗Ķ”üµś»õĖżµ¢╣ķØóńÜäÕĘźõĮ£’╝Ü
1. Ķć¬ÕŖ©ÕØćĶĪĪµĢ░µŹ«Õ║ōIDńö¤µłÉµ£ŹÕŖĪÕÖ©ńÜäĶ«┐ķŚ«
2. ńĪ«õ┐ØÕ£©µ¤ÉõĖ¬µĢ░µŹ«Õ║ōIDńö¤µłÉµ£ŹÕŖĪÕÖ©Õż▒µĢłńÜäµāģÕåĄõĖŗ’╝īĶāĮÕ░åĶ»Ęµ▒éĶĮ¼ÕÅæÕł░ÕģČõ╗¢µ£ŹÕŖĪÕÖ©õĖŖµē¦ĶĪīŃĆé
(õĖē) Õģ│õ║ÄõĮ┐ńö©µĪåµ×ČĶ┐śµś»Ķć¬õĖ╗Õ╝ĆÕÅæõ╗źÕÅŖshardingÕ«×ńÄ░Õ▒éķØóńÜäĶĆāķćÅ
õĖĆŃĆüshardingķĆ╗ĶŠæńÜäÕ«×ńÄ░Õ▒éķØó
õ╗ÄõĖĆõĖ¬ń│╗ń╗¤ńÜäń©ŗÕ║ŵ×ȵ×äÕ▒éķØóµØźń£ŗ’╝īshardingķĆ╗ĶŠæÕÅ»õ╗źÕ£©DAOÕ▒éŃĆüJDBC APIÕ▒éŃĆüõ╗ŗõ║ÄDAOõĖÄJDBCõ╣ŗķŚ┤ńÜäSpringµĢ░µŹ«Ķ«┐ķŚ«Õ░üĶŻģÕ▒é(ÕÉäń¦ŹspringńÜätemplate)õ╗źÕÅŖõ╗ŗõ║ÄÕ║öńö©µ£ŹÕŖĪÕÖ©õĖĵĢ░µŹ«Õ║ōõ╣ŗķŚ┤ńÜäshardingõ╗ŻńÉåµ£ŹÕŖĪÕÖ©ÕøøõĖ¬Õ▒éķØóõĖŖÕ«×ńÄ░ŃĆé
ÕøŠ1. ShardingÕ«×ńÄ░Õ▒éķØóõĖÄńøĖÕģ│µĪåµ×Č/õ║¦Õōü
Õ£©DAOÕ▒éÕ«×ńÄ░
ÕĮōÕøóķś¤Õå│Õ«ÜĶć¬ĶĪīÕ«×ńÄ░shardingńÜ䵌ČÕĆÖ’╝īDAOÕ▒éÕÅ»ĶāĮµś»ÕĄīÕģźshardingķĆ╗ĶŠæńÜäķ”¢ķĆēõĮŹńĮ«’╝īÕøĀõĖ║Õ£©Ķ┐ÖõĖ¬Õ▒éķØóõĖŖ’╝īµ»ÅõĖĆõĖ¬DAOńÜäµ¢╣µ│ĢķāĮµśÄńĪ«Õ£░ń¤źķüōķ£ĆĶ”üĶ«┐ķŚ«ńÜäµĢ░µŹ«ĶĪ©õ╗źÕÅŖµ¤źĶ»óÕÅéµĢ░’╝īÕƤÕŖ®Ķ┐Öõ║øõ┐Īµü»ÕÅ»õ╗źńø┤µÄźÕ«ÜõĮŹÕł░ńø«µĀćshardõĖŖ’╝īĶĆīõĖŹÕ┐ģÕāŵĪåµ×Čķ鯵ĀĘķ£ĆĶ”üÕ»╣SQLĶ┐øĶĪīĶ¦Żµ×ÉńäČÕÉÄÕåŹõŠØµŹ«ķģŹńĮ«ńÜäĶ¦äÕłÖĶ┐øĶĪīĶĘ»ńö▒ŃĆéÕÅ”õĖĆõĖ¬õ╝śÕŖ┐µś»õĖŹõ╝ÜÕÅŚORMµĪåµ×ČńÜäÕłČń║”ŃĆéńö▒õ║ÄńÄ░Õ£©ńÜäÕż¦ÕżÜµĢ░Õ║öńö©Õ£©µĢ░µŹ«Ķ«┐ķŚ«Õ▒éõĖŖõ╝ÜõŠØĶĄ¢µ¤Éń¦ŹORMµĪåµ×Č’╝īĶĆīÕżÜµĢ░ńÜäshradingµĪåµ×ČÕŠĆÕŠĆµŚĀµ│Ģµö»µīüµł¢ÕŬĶāĮµö»µīüõĖĆń¦ŹormµĪåµ×Č’╝īĶ┐ÖõĮ┐ÕŠŚÕ£©ķĆēµŗ®ÕÆīÕ║öńö©µĪåµ×ȵŚČÕÅŚÕł░õ║åÕŠłÕż¦ńÜäÕłČń║”’╝īĶĆīĶć¬ĶĪīÕ«×ńÄ░shardingÕ«īÕģ©µ▓Īµ£ēĶ┐Öµ¢╣ķØóńÜäķŚ«ķóś’╝īńöÜĶć│õĖŹÕÉīńÜäshardõĮ┐ńö©õĖŹÕÉīńÜäormµĪåµ×ČķāĮÕÅ»õ╗źÕ£©õĖĆĶĄĘÕŹÅĶ░āÕĘźõĮ£ŃĆéµ»öÕ”éńÄ░Õ£©ńÜäjavaÕ║öńö©Õż¦ÕżÜõĮ┐ńö©hibernate’╝īõĮåµś»ÕĮōõĖŗĶ┐śµ▓Īµ£ēķØ×ÕĖĖõ╗żõ║║µ╗ĪµäÅńÜäÕ¤║õ║ÄhibernateńÜäshardingµĪåµ×Č’╝ī’╝łÕģ│õ║Ähibernate hardsõ╝ÜÕ£©õĖŗµ¢ćõ╗ŗń╗Ź’╝ē’╝īÕøĀµŁżÕŠłÕżÜÕøóķś¤õ╝ÜķĆēµŗ®Ķć¬ĶĪīÕ«×ńÄ░shardingŃĆé
ń«ĆÕŹĢµĆ╗ń╗ōõĖĆõĖŗ’╝īÕ£©DAOÕ▒éĶć¬ĶĪīÕ«×ńÄ░shardingńÜäõ╝śÕŖ┐Õ£©õ║Ä’╝ÜõĖŹÕÅŚORMµĪåµ×ČńÜäÕłČń║”ŃĆüÕ«×ńÄ░ĶĄĘµØźĶŠāõĖ║ń«ĆÕŹĢŃĆüµśōõ║ĵĀ╣µŹ«ń│╗ń╗¤ńē╣ńé╣Ķ┐øĶĪīńüĄµ┤╗ńÜäÕ«ÜÕłČŃĆüµŚĀķ£ĆSQLĶ¦Żµ×ÉÕÆīĶĘ»ńö▒Ķ¦äÕłÖÕī╣ķģŹ’╝īµĆ¦ĶāĮõĖŖĶĪ©ńÄ░õ╝Üń©ŹÕźĮõĖĆõ║ø;ÕŖŻÕŖ┐Õ£©õ║Ä’╝ܵ£ēõĖĆÕ«ÜńÜäµŖƵ£»ķŚ©µ¦ø’╝īÕĘźõĮ£ķćŵ»öõŠØķØĀµĪåµ×ČÕ«×ńÄ░Ķ”üÕż¦(ÕÅŹĶ┐ćµØźń£ŗ’╝īµĪåµ×Čõ╝ܵ£ēÕŁ”õ╣ĀµłÉµ£¼)ŃĆüõĖŹķĆÜńö©’╝īÕŬĶāĮÕ£©ńē╣Õ«Üń│╗ń╗¤ķćīÕĘźõĮ£ŃĆéÕĮōńäČ’╝īÕ£©DAOÕ▒éÕÉīµĀĘÕÅ»õ╗źķĆÜĶ┐ćXMLķģŹńĮ«µł¢µś»µ│©Ķ¦ŻÕ░åshardingķĆ╗ĶŠæµŖĮń”╗Õł░ŌĆ£Õż¢ķā©ŌĆØ’╝īÕĮóµłÉõĖĆÕźŚķĆÜńö©ńÜäµĪåµ×Č. õĖŹĶ┐ćńø«ÕēŹĶ┐śµ▓Īµ£ēÕć║ńÄ░µŁżń▒╗ńÜäµĪåµ×ČŃĆé
Õ£©ORMµĪåµ×ČÕ▒éÕ«×ńÄ░
Õ£©ORMµĪåµ×ČÕ▒éÕ«×ńÄ░shardingµ£ēõĖżõĖ¬µ¢╣ÕÉæ’╝īõĖĆõĖ¬µś»Õ£©Õ«×ńÄ░O-R MappingńÜäÕēŹµÅÉõĖŗÕÉīµŚČµÅÉõŠøshardingµö»µīü’╝īõ╗ÄĶĆīÕ«ÜõĮŹõĖ║õĖĆń¦ŹÕłåÕĖāÕ╝ÅńÜäµĢ░µŹ«Ķ«┐ķŚ«µĪåµ×Č’╝īĶ┐ÖõĖĆń▒╗ń▒╗Õ×ŗńÜäµĪåµ×Čõ╗ŻĶĪ©Õ░▒µś»guzzÕÅ”õĖĆõĖ¬µ¢╣ÕÉæµś»ķĆÜĶ┐ćÕ»╣µŚóµ£ēORMµĪåµ×ČĶ┐øĶĪīõ┐«µö╣Õó×Õ╝║µØźÕŖĀÕģźshardingµ£║ÕłČŃĆ鵣żń▒╗Õ×ŗńÜäõ╗ŻĶĪ©õ║¦Õōüµś»hibernate shard. Õ║öĶ»źĶ»┤õ╗źhibernateĶ┐ÖµĀĘõĖ╗µĄüńÜäÕ£░õĮŹ’╝īĶĪīõĖÜÕ»╣õ║ÄõĖƵ¼ŠķØóÕÉæhibernateńÜäshardingµĪåµ×ČńÜäķ£Ćµ▒鵜»ķØ×ÕĖĖĶ┐½ÕłćńÜä’╝īõĮåµś»Õ░▒ńø«ÕēŹńÜähibernate shardsµØźń£ŗ’╝īĶĪ©ńÄ░Ķ┐śń«ŚõĖŹõĖŖõ╗żõ║║µ╗ĪµäÅ’╝īõĖ╗Ķ”üµś»Õ«āÕ»╣õĮ┐ńö©hibernateńÜäķÖÉÕłČĶ┐ćÕżÜ’╝īµ»öÕ”éÕ«āÕ»╣HQLńÜäµö»µīüÕ░▒ķØ×ÕĖĖµ£ēķÖÉŃĆéÕ£©mybatisµ¢╣ķØó’╝īńø«ÕēŹĶ┐śµ▓Īµ£ēµłÉńå¤ńÜäńøĖÕģ│µĪåµ×Čõ║¦ńö¤ŃĆéµ£ēõ║║µÅÉÕć║Õł®ńö©mybatisńÜäµÅÆõ╗ȵ£║ÕłČÕ«×ńÄ░sharding,õĮåµś»ķüŚµåŠńÜ䵜»’╝īmybatisńÜäµÅÆõ╗ȵ£║ÕłČµÄ¦ÕłČõĖŹÕł░ÕżÜµĢ░µŹ«µ║ÉńÜäĶ┐׵ğÕ▒éķØó’╝īÕÅ”õĖƵ¢╣ķØó’╝īń”╗Õ╝ƵÅÆõ╗ČÕ▒éÕÅłÕż▒ÕÄ╗õ║åÕ»╣sqlĶ┐øĶĪīķøåõĖŁĶ¦Żµ×ÉÕÆīĶĘ»ńö▒ńÜäµ£║õ╝Ü’╝īÕøĀµŁżÕ£©mybatisµĪåµ×ČõĖŖ’╝īńø«ÕēŹĶ┐śµ▓Īµ£ēÕÅ»õŠøÕƤķē┤ńÜäµĪåµ×Č’╝īÕøóķś¤ÕÅ»ĶāĮĶ”üÕ£©DAOÕ▒鵳¢Springµ©ĪµØ┐ń▒╗õĖŖõĖŗÕŖ¤Õż½õ║åŃĆé
Õ£©JDBC APIÕ▒éÕ«×ńÄ░
JDBC APIÕ▒鵜»ÕŠłÕżÜõ║║ķāĮõ╝ܵā│Õł░ńÜäõĖĆõĖ¬Õ«×ńÄ░shardingńÜäń╗ØõĮ│Õ£║µēĆ’╝īÕ”éµ×£µłæõ╗¼ĶāĮµÅÉõŠøõĖĆõĖ¬Õ«×ńÄ░õ║åshardingķĆ╗ĶŠæńÜäJDBC APIÕ«×ńÄ░’╝īķéŻõ╣łshardingÕ»╣õ║ĵĢ┤õĖ¬Õ║öńö©ń©ŗÕ║ÅµØźĶ»┤Õ░▒µś»Õ«īÕģ©ķĆŵśÄńÜä’╝īĶĆīĶ┐ÖµĀĘńÜäÕ«×ńÄ░ÕÅ»õ╗źńø┤µÄźõĮ£õĖ║ķĆÜńö©ńÜäshardingõ║¦Õōüõ║åŃĆéõĮåµś»Ķ┐Öń¦Źµ¢╣µĪłńÜäµŖƵ£»ķŚ©µ¦øÕÆīÕĘźõĮ£ķćŵśŠńäČõĖŹµś»õĖĆĶł¼Õøóķś¤ĶāĮÕüÜÕŠŚµØźńÜä’╝īÕøĀµŁżÕ¤║µ£¼õĖŖµ▓Īµ£ēÕøóķś¤õ╝ÜÕ£©Ķ┐ÖõĖĆÕ▒éķØóõĖŖÕ«×ńÄ░sharding,ńöÜĶć│õ╣¤µ▓Īµ£ēµŁżń▒╗ńÜäÕ╝Ƶ║Éõ║¦ÕōüŃĆéń¼öĶĆģń¤źķüōńÜäÕŬµ£ēõĖƵ¼ŠÕĢåõĖÜõ║¦ÕōüdbShardsķććńö©ńÜ䵜»Ķ┐ÖõĖƵ¢╣µĪłŃĆé
Õ£©õ╗ŗõ║ÄDAOõĖÄJDBCõ╣ŗķŚ┤ńÜäSpringµĢ░µŹ«Ķ«┐ķŚ«Õ░üĶŻģÕ▒éÕ«×ńÄ░
Õ£©springdÕż¦ĶĪīÕģČķüōńÜäõ╗ŖÕż®’╝īÕćĀõ╣ĵ▓Īµ£ēÕō¬õĖ¬javaÕ╣│ÕÅ░õĖŖµ×äÕ╗║ńÜäÕ║öńö©õĖŹõĮ┐ńö©spring’╝īÕ£©DAOõĖÄJDBCõ╣ŗķŚ┤’╝īspringµÅÉõŠøõ║åÕÉäń¦ŹtemplateµØźń«ĪńÉåĶĄäµ║ÉńÜäÕłøÕ╗║õĖÄķćŖµöŠõ╗źÕÅŖõĖÄõ║ŗÕŖĪńÜäÕÉīµŁź’╝īÕż¦ÕżÜµĢ░Õ¤║õ║ÄspringńÜäÕ║öńö©ķāĮõ╝ÜõĮ┐ńö©templateń▒╗ÕüÜõĖ║µĢ░µŹ«Ķ«┐ķŚ«ńÜäÕģźÕÅŻ’╝īĶ┐Öń╗Öõ║åµłæõ╗¼ÕÅ”õĖĆõĖ¬ÕĄīÕģźshardingķĆ╗ĶŠæńÜäµ£║õ╝Ü’╝īÕ░▒µś»ķĆÜĶ┐ćµÅÉõŠøõĖĆõĖ¬ÕĄīÕģźõ║åshardingķĆ╗ĶŠæńÜätemplateń▒╗µØźÕ«īµłÉshardingÕĘźõĮ£.Ķ┐ÖõĖƵ¢╣µĪłÕ£©µĢłµ×£õĖŖõĖÄÕ¤║õ║ÄJDBC APIÕ«×ńÄ░ńÜäµ¢╣µĪłÕ¤║µ£¼õĖĆĶć┤’╝īÕÉīµĀʵś»Õ»╣õĖŖÕ▒éõ╗ŻńĀüķĆŵśÄ’╝īÕ£©Ķ┐øĶĪīshardingµö╣ķĆĀµŚČÕÅ»õ╗źÕ╣│µ╗æÕ£░Ķ┐ćÕ║”’╝īõĮåÕ«āńÜäÕ«×ńÄ░ÕŹ┤µ»öÕ¤║õ║ÄJDBC APIńÜäµ¢╣Õ╝Åń«ĆÕŹĢ’╝īÕøĀµŁżµłÉõĖ║õ║åõĖŹÕ░æµĪåµ×ČńÜäķĆēµŗ®’╝īķś┐ķćīķøåÕøóńĀöń®ČķÖóÕ╝Ƶ║ÉńÜäCobar ClientÕ░▒µś»Ķ┐Öń▒╗µ¢╣µĪłńÜäõĖĆń¦ŹÕ«×ńÄ░ŃĆé
Õ£©Õ║öńö©µ£ŹÕŖĪÕÖ©õĖĵĢ░µŹ«Õ║ōõ╣ŗķŚ┤ķĆÜĶ┐ćõ╗ŻńÉåÕ«×ńÄ░
Õ£©Õ║öńö©µ£ŹÕŖĪÕÖ©õĖĵĢ░µŹ«Õ║ōõ╣ŗķŚ┤ÕŖĀÕģźõĖĆõĖ¬õ╗ŻńÉå’╝īÕ║öńö©ń©ŗÕ║ÅÕÉæµĢ░µŹ«ÕÅæÕć║ńÜäµĢ░µŹ«Ķ»Ęµ▒éõ╝ÜÕģłķĆÜĶ┐ćõ╗ŻńÉå’╝īõ╗ŻńÉåõ╝ܵĀ╣µŹ«ķģŹńĮ«ńÜäĶĘ»ńö▒Ķ¦äÕłÖ’╝īÕ»╣SQLĶ┐øĶĪīĶ¦Żµ×ÉÕÉÄĶĘ»ńö▒Õł░ńø«µĀćshard’╝īÕøĀõĖ║Ķ┐Öń¦Źµ¢╣µĪłÕ»╣Õ║öńö©ń©ŗÕ║ÅÕ«īÕģ©ķĆŵśÄ’╝īķĆÜńö©µĆ¦ÕźĮ’╝īµēĆõ╗źµłÉõĖ║õ║åÕŠłÕżÜshardingõ║¦ÕōüńÜäķĆēµŗ®ŃĆéÕ£©Ķ┐Öµ¢╣ķØóĶŠāõĖ║ń¤źÕÉŹńÜäõ║¦Õōüµś»mysqlÕ«śµ¢╣ńÜäõ╗ŻńÉåÕĘźÕģĘ’╝ÜMysql ProxyÕÆīõĖƵ¼ŠÕøĮõ║║Õ╝ĆÕÅæńÜäõ║¦Õōü:amoebaŃĆémysql proxyµ£¼Ķ║½Õ╣ȵ▓Īµ£ēÕ«×ńÄ░õ╗╗õĮĢshardingķĆ╗ĶŠæ’╝īÕ«āÕŬµś»õĮ£õĖ║õĖĆń¦ŹķØóÕÉæmysqlµĢ░µŹ«Õ║ōńÜäõ╗ŻńÉå’╝īń╗ÖÕ╝ĆÕÅæõ║║ÕæśµÅÉõŠøõ║åõĖĆõĖ¬ÕĄīÕģźshardingķĆ╗ĶŠæńÜäÕ£║µēĆ’╝īÕ«āõĮ┐ńö©luaõĮ£õĖ║ń╝¢ń©ŗĶ»ŁĶ©Ć’╝īĶ┐ÖÕ»╣ÕŠłÕżÜÕøóķś¤µØźĶ»┤µś»ķ£ĆĶ”üĶĆāĶÖæńÜäõĖĆõĖ¬ķŚ«ķóśŃĆéamoebaÕłÖµś»õĖōķŚ©Õ«×ńÄ░Ķ»╗ÕåÖÕłåń”╗õĖÄshardingńÜäõ╗ŻńÉåõ║¦Õōü’╝īÕ«āõĮ┐ńö©ķØ×ÕĖĖń«ĆÕŹĢ’╝īõĖŹõĮ┐ńö©õ╗╗õĮĢń╝¢ń©ŗĶ»ŁĶ©Ć’╝īÕŬķ£ĆĶ”üķĆÜĶ┐ćxmlĶ┐øĶĪīķģŹńĮ«ŃĆéõĖŹĶ┐ćamoebaõĖŹµö»µīüõ║ŗÕŖĪ(õ╗ÄÕ║öńö©ń©ŗÕ║ÅÕÅæÕć║ńÜäÕīģÕɽõ║ŗÕŖĪõ┐Īµü»ńÜäĶ»Ęµ▒éÕł░ĶŠŠamoebaµŚČ’╝īõ║ŗÕŖĪõ┐Īµü»õ╝ÜĶó½µŖ╣ÕÄ╗’╝īÕøĀµŁż’╝īÕŹ│õĮ┐µś»ÕŹĢńé╣µĢ░µŹ«Ķ«┐ķŚ«õ╣¤õĖŹõ╝ܵ£ēõ║ŗÕŖĪÕŁśÕ£©)õĖĆńø┤µś»õĖ¬ńĪ¼õ╝żŃĆéÕĮōńäČ’╝īĶ┐ÖĶ”üń£ŗõ║¦ÕōüńÜäÕ«ÜõĮŹÕÆīĶ«ŠĶ«ĪńÉåÕ┐Ą’╝īµłæõ╗¼ÕŬĶāĮĶ»┤Õ»╣õ║ÄķéŻõ║øÕ»╣õ║ŗÕŖĪĶ”üµ▒éķØ×ÕĖĖķ½śńÜäń│╗ń╗¤’╝īamoebaµś»õĖŹķĆéÕÉłńÜäŃĆé
õ║īŃĆüõĮ┐ńö©µĪåµ×ČĶ┐śµś»Ķć¬õĖ╗Õ╝ĆÕÅæ’╝¤
ÕēŹķØóńÜäĶ«©Ķ«║õĖŁÕĘ▓ń╗ÅńĮŚÕłŚõ║åÕŠłÕżÜÕ╝Ƶ║ɵĪåµ×ČõĖÄõ║¦Õōü’╝īĶ┐ÖķćīÕåŹµĢ┤ńÉåõĖĆõĖŗ’╝ÜÕ¤║õ║Äõ╗ŻńÉåµ¢╣Õ╝ÅńÜäµ£ēMySQL ProxyÕÆīAmoeba’╝īÕ¤║õ║ÄHibernateµĪåµ×ČńÜ䵜»Hibernate Shards’╝īķĆÜĶ┐ćķćŹÕåÖspringńÜäibatis templateń▒╗µś»Cobar Client’╝īĶ┐Öõ║øµĪåµ×ČÕÉäµ£ēÕÉäńÜäõ╝śÕŖ┐õĖÄń¤ŁµØ┐’╝īµ×ȵ×äÕĖłÕÅ»õ╗źÕ£©µĘ▒ÕģźĶ░āńĀöõ╣ŗÕÉÄń╗ōÕÉłķĪ╣ńø«ńÜäÕ«×ķÖģµāģÕåĄĶ┐øĶĪīķĆēµŗ®’╝īõĮåµś»µĆ╗ńÜäµØźĶ»┤’╝īµłæõĖ¬õ║║Õ»╣õ║ĵĪåµ×ČńÜäķĆēµŗ®µś»µīüĶ░©µģĵĆüÕ║”ńÜäŃĆéõĖƵ¢╣ķØóÕżÜµĢ░µĪåµ×Čń╝║õ╣ŵłÉÕŖ¤µĪłõŠŗńÜäķ¬īĶ»ü’╝īÕģȵłÉńå¤µĆ¦õĖÄń©│Õ«ÜµĆ¦ÕĆ╝ÕŠŚµĆĆń¢æŃĆéÕÅ”õĖƵ¢╣ķØó’╝īõĖĆõ║øõ╗ĵłÉÕŖ¤ÕĢåõĖÜõ║¦ÕōüÕ╝Ƶ║ÉÕć║µĪåµ×Č’╝łÕ”éķś┐ķćīÕÆīµĘśÕ«ØńÜäõĖĆõ║øÕ╝Ƶ║ÉķĪ╣ńø«’╝ēµś»ÕÉ”ķĆéÕÉłõĮĀńÜäķĪ╣ńø«µś»ķ£ĆĶ”üµ×ȵ×äÕĖłµĘ▒ÕģźĶ░āńĀöÕłåµ×ÉńÜäŃĆéÕĮōńäČ’╝īµ£Ćń╗łńÜäķĆēµŗ®õĖĆիܵś»Õ¤║õ║ÄķĪ╣ńø«ńē╣ńé╣ŃĆüÕøóķś¤ńŖČÕåĄŃĆüµŖƵ£»ķŚ©µ¦øÕÆīÕŁ”õ╣ĀµłÉµ£¼ńŁēń╗╝ÕÉłÕøĀń┤ĀĶĆāķćÅńĪ«Õ«ÜńÜäŃĆé
(Õøø) ÕżÜµĢ░µŹ«µ║ÉńÜäõ║ŗÕŖĪÕżäńÉå
ÕłåÕĖāÕ╝Åõ║ŗÕŖĪ
Ķ┐Öµś»µ£ĆõĖ║õ║║õ╗¼µēĆńå¤ń¤źńÜäÕżÜµĢ░µŹ«µ║Éõ║ŗÕŖĪÕżäńÉåµ£║ÕłČŃĆéµ£¼µ¢ćÕ╣ČõĖŹµēōń«ŚÕ»╣ÕłåÕĖāÕ╝Åõ║ŗÕŖĪÕüÜĶ┐ćÕżÜõ╗ŗń╗Ź’╝īĶ»╗ĶĆģÕÅ»ÕÅéĶĆāµŁżµ¢ć’╝ÜÕģ│õ║ÄÕłåÕĖāÕ╝Åõ║ŗÕŖĪŃĆüõĖżķśČµ«ĄµÅÉõ║żŃĆüõĖĆķśČµ«ĄµÅÉõ║żŃĆüBest Efforts 1PCµ©ĪÕ╝ÅÕÆīõ║ŗÕŖĪĶĪźÕü┐µ£║ÕłČńÜäńĀöń®Č ŃĆéÕ£©Ķ┐ÖķćīÕŬµā│Õ»╣ÕłåÕĖāÕ╝Åõ║ŗÕŖĪńÜäÕł®Õ╝ŖõĮ£õĖĆõĖŗÕłåµ×ÉŃĆé
õ╝śÕŖ┐’╝Ü
1. Õ¤║õ║ÄõĖżķśČµ«ĄµÅÉõ║ż’╝īµ£ĆÕż¦ķÖÉÕ║”Õ£░õ┐ØĶ»üõ║åĶĘ©µĢ░µŹ«Õ║ōµōŹõĮ£ńÜäŌĆ£ÕÄ¤ÕŁÉµĆ¦ŌĆØ’╝īµś»ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŗµ£ĆõĖźµĀ╝ńÜäõ║ŗÕŖĪÕ«×ńÄ░µ¢╣Õ╝ÅŃĆé
2. Õ«×ńÄ░ń«ĆÕŹĢ’╝īÕĘźõĮ£ķćÅÕ░ÅŃĆéńö▒õ║ÄÕżÜµĢ░Õ║öńö©µ£ŹÕŖĪÕÖ©õ╗źÕÅŖõĖĆõ║øńŗ¼ń½ŗńÜäÕłåÕĖāÕ╝Åõ║ŗÕŖĪÕŹÅĶ░āÕÖ©ÕüÜõ║åÕż¦ķćÅńÜäÕ░üĶŻģÕĘźõĮ£’╝īõĮ┐ÕŠŚķĪ╣ńø«õĖŁÕ╝ĢÕģźÕłåÕĖāÕ╝Åõ║ŗÕŖĪńÜäķÜŠÕ║”ÕÆīÕĘźõĮ£ķćÅÕ¤║µ£¼õĖŖÕÅ»õ╗źÕ┐ĮńĢźõĖŹĶ«ĪŃĆé
ÕŖŻÕŖ┐’╝Ü
ń│╗ń╗¤ŌĆ£µ░┤Õ╣│ŌĆØõ╝Ėń╝®ńÜ䵣╗µĢīŃĆéÕ¤║õ║ÄõĖżķśČµ«ĄµÅÉõ║żńÜäÕłåÕĖāÕ╝Åõ║ŗÕŖĪÕ£©µÅÉõ║żõ║ŗÕŖĪµŚČķ£ĆĶ”üÕ£©ÕżÜõĖ¬ĶŖéńé╣õ╣ŗķŚ┤Ķ┐øĶĪīÕŹÅĶ░ā,µ£ĆÕż¦ķÖÉÕ║”Õ£░µÄ©ÕÉÄõ║åµÅÉõ║żõ║ŗÕŖĪńÜ䵌ČķŚ┤ńé╣’╝īÕ«óĶ¦éõĖŖÕ╗ČķĢ┐õ║åõ║ŗÕŖĪńÜäµē¦ĶĪīµŚČķŚ┤’╝īĶ┐Öõ╝ÜÕ»╝Ķć┤õ║ŗÕŖĪÕ£©Ķ«┐ķŚ«Õģ▒õ║½ĶĄäµ║ɵŚČÕÅæńö¤Õå▓ń¬üÕÆīµŁ╗ķöüńÜäµ”éńÄćÕó×ķ½ś’╝īķÜÅńØƵĢ░µŹ«Õ║ōĶŖéńé╣ńÜäÕó×ÕżÜ’╝īĶ┐Öń¦ŹĶČŗÕŖ┐õ╝ÜĶČŖµØźĶČŖõĖźķ插╝īõ╗ÄĶĆīµłÉõĖ║ń│╗ń╗¤Õ£©µĢ░µŹ«Õ║ōÕ▒éķØóõĖŖµ░┤Õ╣│õ╝Ėń╝®ńÜä"µ×Ęķöü"’╝ī Ķ┐Öµś»ÕŠłÕżÜShardingń│╗ń╗¤õĖŹķććńö©ÕłåÕĖāÕ╝Åõ║ŗÕŖĪńÜäõĖ╗Ķ”üÕĤÕøĀŃĆé
Õ¤║õ║ÄBest Efforts 1PCµ©ĪÕ╝ÅńÜäõ║ŗÕŖĪ
õĖÄÕłåÕĖāÕ╝Åõ║ŗÕŖĪķććńö©ńÜäõĖżķśČµ«ĄµÅÉõ║żõĖŹÕÉī’╝īBest Efforts 1PCµ©ĪÕ╝Åķććńö©ńÜ䵜»õĖĆķśČµ«Ąń½»µÅÉõ║ż’╝īńē║ńē▓õ║åõ║ŗÕŖĪÕ£©µ¤Éõ║øńē╣µ«ŖµāģÕåĄ(ÕĮōµ£║ŃĆüńĮæń╗£õĖŁµ¢ŁńŁē)õĖŗńÜäÕ«ēÕģ©µĆ¦’╝īÕŹ┤ĶÄĘÕŠŚõ║åĶē»ÕźĮńÜäµĆ¦ĶāĮ’╝īńē╣Õł½µś»µČłķÖżõ║åÕ»╣µ░┤Õ╣│õ╝Ėń╝®ńÜäµĪÄķģĘŃĆéDistributed transactions in Spring, with and without XAõĖƵ¢ćÕ»╣Best Efforts 1PCµ©ĪÕ╝ÅĶ┐øĶĪīõ║åĶ»”ń╗åńÜäĶ»┤µśÄ’╝īĶ»źµ¢ćµÅÉõŠøńÜäDemoõ╗ŻńĀüµø┤µś»ńø┤µÄźń╗ÖÕć║õ║åÕ£©SpringńÄ»ÕóāõĖŗÕ«×ńÄ░õĖĆķśČµ«ĄµÅÉõ║żńÜäÕżÜµĢ░µŹ«µ║Éõ║ŗÕŖĪń«ĪńÉåńż║õŠŗŃĆéõĖŹĶ┐ćķ£ĆĶ”üµ│©µäÅńÜ䵜»’╝īÕĤńż║õŠŗµś»Õ¤║õ║Äspring 3.0õ╣ŗÕēŹńÜäńēłµ£¼’╝īÕ”éµ×£õĮĀõĮ┐ńö©spring 3.0+,õ╝ÜÕŠŚÕł░Õ”éõĖŗķöÖĶ»»’╝Üjava.lang.IllegalStateException: Cannot activate transaction synchronization - already active’╝īÕ”éµ×£õĮ┐ńö©spring 3.0+’╝īõĮĀķ£ĆĶ”üÕÅéĶĆāspring-data-neo4jńÜäÕ«×ńÄ░ŃĆéķē┤õ║ÄBest Efforts 1PCµ©ĪÕ╝ÅńÜäµĆ¦ĶāĮõ╝śÕŖ┐’╝īõ╗źÕÅŖńøĖÕ»╣ń«ĆÕŹĢńÜäÕ«×ńÄ░µ¢╣Õ╝Å’╝īÕ«āĶó½Õż¦ÕżÜµĢ░ńÜäshardingµĪåµ×ČÕÆīķĪ╣ńø«ķććńö©ŃĆé
õ║ŗÕŖĪĶĪźÕü┐µ£║ÕłČ
Õ»╣õ║ÄķéŻõ║øÕ»╣µĆ¦ĶāĮĶ”üµ▒éÕŠłķ½ś’╝īõĮåÕ»╣õĖĆĶć┤µĆ¦Ķ”üµ▒éÕ╣ČõĖŹķ½śńÜäń│╗ń╗¤’╝īÕŠĆÕŠĆÕ╣ČõĖŹĶŗøµ▒éń│╗ń╗¤ńÜäÕ«×µŚČõĖĆĶć┤µĆ¦’╝īÕŬĶ”üÕ£©õĖĆõĖ¬ÕģüĶ«ĖńÜ䵌ČķŚ┤Õ橵£¤ÕåģĶŠŠÕł░µ£Ćń╗łõĖĆĶć┤µĆ¦ÕŹ│ÕÅ»’╝īĶ┐ÖõĮ┐ÕŠŚõ║ŗÕŖĪĶĪźÕü┐µ£║ÕłČµłÉõĖ║õĖĆń¦ŹÕÅ»ĶĪīńÜäµ¢╣µĪłŃĆéõ║ŗÕŖĪĶĪźÕü┐µ£║ÕłČµ£ĆÕłØĶó½µÅÉÕć║µś»Õ£©ŌĆ£ķĢ┐õ║ŗÕŖĪŌĆØńÜäÕżäńÉåõĖŁ’╝īõĮåµś»Õ»╣õ║ÄÕłåÕĖāÕ╝Åń│╗ń╗¤ńĪ«õ┐ØõĖĆĶć┤µĆ¦õ╣¤µ£ēÕŠłÕźĮńÜäÕÅéĶĆāµäÅõ╣ēŃĆéń¼╝ń╗¤Õ£░Ķ«▓’╝īõĖÄõ║ŗÕŖĪÕ£©µē¦ĶĪīõĖŁÕÅæńö¤ķöÖĶ»»ÕÉÄń½ŗÕŹ│Õø×µ╗ÜńÜäµ¢╣Õ╝ÅõĖŹÕÉī’╝īõ║ŗÕŖĪĶĪźÕü┐µś»õĖĆń¦Źõ║ŗÕÉĵŻĆµ¤źÕ╣ČĶĪźµĢæńÜäµÄ¬µ¢Į’╝īÕ«āÕŬµ£¤µ£øÕ£©õĖĆõĖ¬Õ«╣Ķ«ĖµŚČķŚ┤Õ橵£¤ÕåģÕŠŚÕł░µ£Ćń╗łõĖĆĶć┤ńÜäń╗ōµ×£Õ░▒ÕÅ»õ╗źõ║åŃĆéõ║ŗÕŖĪĶĪźÕü┐ńÜäÕ«×ńÄ░õĖÄń│╗ń╗¤õĖÜÕŖĪń┤¦Õ»åńøĖÕģ│’╝īÕ╣ȵ▓Īµ£ēõĖĆń¦ŹµĀćÕćåńÜäÕżäńÉåµ¢╣Õ╝ÅŃĆéõĖĆõ║øÕĖĖĶ¦üńÜäÕ«×ńÄ░µ¢╣Õ╝ŵ£ē’╝ÜÕ»╣µĢ░µŹ«Ķ┐øĶĪīÕ»╣ÕĖɵŻĆµ¤ź;Õ¤║õ║ĵŚźÕ┐ŚĶ┐øĶĪīµ»öÕ»╣;իܵ£¤ÕÉīµĀćÕćåµĢ░µŹ«µØźµ║ÉĶ┐øĶĪīÕÉīµŁź’╝īńŁēńŁēŃĆé
Õ░Åń╗ō
ÕłåÕĖāÕ╝Åõ║ŗÕŖĪ’╝īµ£ĆõĖźµĀ╝ńÜäõ║ŗÕŖĪÕ«×ńÄ░’╝īõĮåµĆ¦ĶāĮµś»õĖ¬Õż¦ķŚ«ķóś;Best Efforts 1PCµ©ĪÕ╝Å’╝īµĆ¦ĶāĮõĖÄõ║ŗÕŖĪÕÅ»ķØĀµĆ¦ńÜäÕ╣│ĶĪĪ’╝īµö»µīüń│╗ń╗¤µ░┤Õ╣│õ╝Ėń╝®’╝īÕż¦ÕżÜµĢ░µāģÕåĄõĖŗµś»µ£ĆÕÉłķĆéńÜäķĆēµŗ®;õ║ŗÕŖĪĶĪźÕü┐µ£║ÕłČ’╝īÕŬĶāĮķĆéńö©õ║ÄÕ»╣õ║ŗÕŖĪµĆ¦Ķ”üµ▒éõĖŹķ½ś’╝īÕģüĶ«ĖµĢ░µŹ«ŌĆ£µ£Ćń╗łõĖĆĶć┤ŌĆØÕŹ│ÕÅ»ńÜäń│╗ń╗¤’╝īńē║ńē▓Õ«×µŚČõĖĆĶć┤µĆ¦’╝īĶÄĘÕŠŚµ£ĆÕż¦ńÜäµĆ¦ĶāĮÕø×µŖźŃĆé
(õ║ö) õĖĆń¦Źµö»µīüĶć¬ńö▒Ķ¦äÕłÆµŚĀķĪ╗µĢ░µŹ«Ķ┐üń¦╗ÕÆīõ┐«µö╣ĶĘ»ńö▒õ╗ŻńĀüńÜäShardingµē®Õ«╣µ¢╣µĪł
µ£¼µ¢ćÕ░åķćŹńé╣Õø┤ń╗ĢŌĆ£µĢ░µŹ«Õ║ōµē®Õ«╣ŌĆØĶ┐øĶĪīµĘ▒ÕģźĶ«©Ķ«║’╝īÕ╣ȵÅÉÕć║õĖĆń¦ŹÕģüĶ«ĖĶć¬ńö▒Ķ¦äÕłÆÕ╣ČĶāĮķü┐ÕģŹµĢ░µŹ«Ķ┐üń¦╗ÕÆīõ┐«µö╣ĶĘ»ńö▒õ╗ŻńĀüńÜäShardingµē®Õ«╣µ¢╣µĪł
Shardingµē®Õ«╣ŌĆöŌĆöń│╗ń╗¤ń╗┤µŖżõĖŹĶāĮµē┐ÕÅŚõ╣ŗķćŹ
õ╗╗õĮĢShardingń│╗ń╗¤’╝īÕ£©õĖŖń║┐Ķ┐ÉĶĪīõĖƵ«ĄµŚČķŚ┤ÕÉÄ’╝īµĢ░µŹ«Õ░▒õ╝Üń¦»ń┤»Õł░ÕĮōÕēŹĶŖéńé╣Ķ¦äµ©ĪµēĆĶāĮµē┐ĶĮĮńÜäõĖŖķÖÉ’╝īµŁżµŚČÕ░▒ķ£ĆĶ”üÕ»╣µĢ░µŹ«Õ║ōĶ┐øĶĪīµē®Õ«╣õ║å’╝īõ╣¤Õ░▒µś»Õó×ÕŖĀµ¢░ńÜäńē®ńÉåń╗ōńé╣µØźÕłåµæŖµĢ░µŹ«ŃĆéÕ”éµ×£ń│╗ń╗¤õĮ┐ńö©ńÜ䵜»Õ¤║õ║ÄIDĶ┐øĶĪīµĢŻÕłŚńÜäĶĘ»ńö▒µ¢╣Õ╝Å’╝īķéŻõ╣łÕøóķś¤ķ£ĆĶ”üµĀ╣µŹ«µ¢░ńÜäĶŖéńé╣Ķ¦äµ©Īķ揵¢░Ķ«Īń«ŚµēƵ£ēµĢ░µŹ«Õ║öÕżäńÜäńø«µĀćShard’╝īÕ╣ČÕ░åÕģČĶ┐üń¦╗Ķ┐ćÕÄ╗’╝īĶ┐ÖÕ»╣Õøóķś¤µØźĶ»┤µŚĀń¢æµś»õĖĆõĖ¬ÕĘ©Õż¦ńÜäń╗┤µŖżĶ┤¤µŗģ’╝øĶĆīÕ”éµ×£ń│╗ń╗¤µś»µīēÕó×ķćÅÕī║ķŚ┤Ķ┐øĶĪīĶĘ»ńö▒(Ք鵻Å1ÕŹāõĖćµØĪµĢ░µŹ«µł¢µś»µ»ÅõĖĆõĖ¬µ£łńÜäµĢ░µŹ«ÕŁśµöŠÕ£©õĖĆõĖ¬ĶŖéńé╣õĖŖ )’╝īĶÖĮńäČÕÅ»õ╗źķü┐ÕģŹµĢ░µŹ«ńÜäĶ┐üń¦╗’╝īÕŹ┤µ£ēÕÅ»ĶāĮÕĖ”µØźŌĆ£ńāŁńé╣ŌĆØķŚ«ķóś’╝īõ╣¤Õ░▒µś»Ķ┐æµ£¤ń│╗ń╗¤ńÜäĶ»╗ÕåÖķāĮķøåõĖŁÕ£©µ£Ćµ¢░ÕłøÕ╗║ńÜäĶŖéńé╣õĖŖ(ÕŠłÕżÜń│╗ń╗¤ķāĮµ£ēµŁżń▒╗ńē╣ńé╣’╝ܵ¢░ńö¤µĢ░µŹ«ńÜäĶ»╗ÕåÖķóæńÄ浜ĵśŠķ½śõ║ĵŚ¦µ£ēµĢ░µŹ«)’╝īõ╗ÄĶĆīÕĮ▒ÕōŹõ║åń│╗ń╗¤µĆ¦ĶāĮŃĆéķØóÕ»╣Ķ┐Öń¦ŹõĖżķÜŠńÜäÕżäÕóā’╝īShardingµē®Õ«╣µśŠÕŠŚÕ╝éÕĖĖÕø░ķÜŠŃĆé
õĖĆĶł¼µØźĶ»┤’╝īŌĆ£ńÉåµā│ŌĆØńÜäµē®Õ«╣µ¢╣µĪłÕ║öĶ»źÕŖ¬ÕŖøµ╗ĪĶČ│õ╗źõĖŗÕćĀõĖ¬Ķ”üµ▒é’╝Ü
- µ£ĆÕźĮõĖŹĶ┐üń¦╗µĢ░µŹ« ’╝łµŚĀĶ«║Õ”éõĮĢ’╝īµĢ░µŹ«Ķ┐üń¦╗ķāĮµś»õĖĆõĖ¬Ķ«®Õøóķś¤ÕÄŗÕŖøÕ▒▒Õż¦ńÜäķŚ«ķóś’╝ē
- ÕģüĶ«ĖµĀ╣µŹ«ńĪ¼õ╗ČĶĄäµ║ÉĶć¬ńö▒Ķ¦äÕłÆµē®Õ«╣Ķ¦äµ©ĪÕÆīĶŖéńé╣ÕŁśÕé©Ķ┤¤ĶĮĮ
- ĶāĮÕØćÕīĆńÜäÕłåÕĖāµĢ░µŹ«Ķ»╗ÕåÖ’╝īķü┐ÕģŹŌĆ£ńāŁńé╣ŌĆØķŚ«ķóś
- õ┐ØĶ»üÕ»╣ÕĘ▓ń╗ÅĶŠŠÕł░ÕŁśÕé©õĖŖķÖÉńÜäĶŖéńé╣õĖŹÕåŹÕåÖÕģźµĢ░µŹ«
ńø«ÕēŹ’╝īĶāĮÕż¤ķü┐ÕģŹµĢ░µŹ«Ķ┐üń¦╗ńÜäõ╝śń¦Ćµ¢╣µĪłÕ╣ČõĖŹÕżÜ’╝īńøĖÕ»╣ÕÅ»ĶĪīńÜäµ£ēõĖżń¦Ź’╝īõĖĆń¦Źµś»ń╗┤µŖżõĖĆÕ╝ĀĶ«░ÕĮĢµĢ░µŹ«IDÕÆīńø«µĀćShardÕ»╣Õ║öÕģ│ń│╗ńÜ䵜ĀÕ░äĶĪ©’╝īÕåÖÕģźµŚČ’╝īµĢ░µŹ«ķāĮÕåÖÕģźµ¢░µē®Õ«╣ńÜäShard’╝īÕÉīµŚČÕ░åIDÕÆīńø«µĀćĶŖéńé╣ÕåÖÕģźµśĀÕ░äĶĪ©’╝īĶ»╗ÕÅ¢µŚČ’╝īÕģłµ¤źµśĀÕ░äĶĪ©’╝īµēŠÕł░ńø«µĀćShardÕÉÄÕåŹµē¦ĶĪīµ¤źĶ»óŃĆéĶ»źµ¢╣µĪłń«ĆÕŹĢµ£ēµĢł’╝īõĮåµś»Ķ»╗ÕåÖµĢ░µŹ«ķāĮķ£ĆĶ”üĶ«┐ķŚ«õĖżµ¼ĪµĢ░µŹ«Õ║ō’╝īõĖöµśĀÕ░äĶĪ©µ£¼Ķ║½õ╣¤µ×üµśōµłÉõĖ║µĆ¦ĶāĮńōČķółŃĆéõĖ║µŁżń│╗ń╗¤õĖŹÕŠŚõĖŹÕ╝ĢÕģźÕłåÕĖāÕ╝Åń╝ōÕŁśµØźń╝ōÕŁśµśĀÕ░äĶĪ©µĢ░µŹ«’╝īõĮåµś»Ķ┐ÖµĀĘõ╣¤µŚĀµ│Ģķü┐ÕģŹÕ£©ÕåÖÕģźµŚČĶ«┐ķŚ«õĖżµ¼ĪµĢ░µŹ«Õ║ō’╝īÕÉīµŚČÕż¦ķćŵśĀÕ░äµĢ░µŹ«Õ»╣ń╝ōÕŁśĶĄäµ║ÉńÜäµČłĶĆŚõ╗źÕÅŖõĖōķŚ©õĖ║µŁżĶĆīÕ╝ĢÕģźÕłåÕĖāÕ╝Åń╝ōÕŁśńÜäõ╗Żõ╗ĘķāĮµś»ķ£ĆĶ”üµØāĶĪĪńÜäķŚ«ķóśŃĆéÕÅ”õĖĆń¦Źµ¢╣µĪłµØźĶć¬µĘśÕ«Øń╗╝ÕÉłõĖÜÕŖĪÕ╣│ÕÅ░Õøóķś¤’╝īÕ«āÕł®ńö©Õ»╣2ńÜäÕĆŹµĢ░ÕÅ¢õĮÖÕģʵ£ēÕÉæÕēŹÕģ╝Õ«╣ńÜäńē╣µĆ¦’╝łÕ”éÕ»╣4ÕÅ¢õĮÖÕŠŚ1ńÜäµĢ░Õ»╣2ÕÅ¢õĮÖõ╣¤µś»1’╝ēµØźÕłåķģŹµĢ░µŹ«’╝īķü┐ÕģŹõ║åĶĪīń║¦Õł½ńÜäµĢ░µŹ«Ķ┐üń¦╗’╝īõĮåµś»õŠØńäČķ£ĆĶ”üĶ┐øĶĪīĶĪ©ń║¦Õł½ńÜäĶ┐üń¦╗’╝īÕÉīµŚČÕ»╣µē®Õ«╣Ķ¦äµ©ĪÕÆīÕłåĶĪ©µĢ░ķćÅķāĮµ£ēķÖÉÕłČŃĆéµĆ╗ÕŠŚµØźĶ»┤’╝īĶ┐Öõ║øµ¢╣µĪłķāĮõĖŹµś»ÕŹüÕłåńÜäńÉåµā│’╝īÕżÜÕżÜÕ░æÕ░æķāĮÕŁśÕ£©õĖĆõ║øń╝║ńé╣’╝īĶ┐Öõ╣¤õ╗ÄõĖĆõĖ¬õŠ¦ķØóÕÅŹµśĀÕć║õ║åShardingµē®Õ«╣ńÜäķÜŠÕ║”ŃĆé
ÕÅ¢ķĢ┐ĶĪźń¤Ł’╝īÕģ╝Õ«╣Õ╣ČÕīģŌĆöŌĆöõĖĆń¦ŹńÉåµā│ńÜäShardingµē®Õ«╣µ¢╣µĪł
Õ”éÕēŹµ¢ćµēĆĶ┐░’╝īShardingµē®Õ«╣õĖÄń│╗ń╗¤ķććńö©ńÜäĶĘ»ńö▒Ķ¦äÕłÖÕ»åÕłćńøĖÕģ│’╝ÜÕ¤║õ║ĵĢŻÕłŚńÜäĶĘ»ńö▒ĶāĮÕØćÕīĆÕ£░ÕłåÕĖāµĢ░µŹ«’╝īõĮåÕŹ┤ķ£ĆĶ”üµĢ░µŹ«Ķ┐üń¦╗’╝īÕÉīµŚČõ╣¤µŚĀµ│Ģķü┐ÕģŹÕ»╣ĶŠŠÕł░õĖŖķÖÉńÜäĶŖéńé╣õĖŹÕåŹÕåÖÕģźµ¢░µĢ░µŹ«’╝øÕ¤║õ║ÄÕó×ķćÅÕī║ķŚ┤ńÜäĶĘ»ńö▒Õż®ńäČõĖŹÕŁśÕ£©µĢ░µŹ«Ķ┐üń¦╗ÕÆīÕÉ浤ÉõĖĆĶŖéńé╣µŚĀõĖŖķÖÉÕåÖÕģźµĢ░µŹ«ńÜäķŚ«ķóś’╝īõĮåÕŹ┤ÕŁśÕ£©ŌĆ£ńāŁńé╣ŌĆØÕø░µē░ŃĆ鵳æõ╗¼Ķ«ŠĶ«Īµ¢╣µĪłńÜäÕłØĶĪĘÕ░▒µś»ÕĖīµ£øĶāĮń╗ōÕÉłõĖżń¦ŹĶĘ»ńö▒Ķ¦äÕłÖńÜäõ╝śÕŖ┐’╝īµæÆÕ╝āÕÉäĶć¬ńÜäÕŖŻÕŖ┐’╝īÕłøķĆĀÕć║õĖĆń¦ŹµÄźĶ┐æŌĆ£ńÉåµā│ŌĆØńŖȵĆüńÜäµē®Õ«╣µ¢╣Õ╝Å’╝īĶĆīĶ┐Öń¦Źµ¢╣Õ╝Åń«ĆÕŹĢµ”éµŗ¼ĶĄĘµØźÕ░▒µś»’╝ÜÕģ©Õ▒ƵīēÕó×ķćÅÕī║ķŚ┤ÕłåÕĖāµĢ░µŹ«’╝īõĮ┐ńö©Õó×ķćŵē®Õ«╣’╝īµŚĀµĢ░µŹ«Ķ┐üń¦╗’╝īÕ▒Ćķā©õĮ┐ńö©µĢŻÕłŚµ¢╣Õ╝ÅÕłåµĢŻµĢ░µŹ«Ķ»╗ÕåÖ’╝īĶ¦ŻÕå│ŌĆ£ńāŁńé╣ŌĆØķŚ«ķóś’╝īÕÉīµŚČÕ»╣Shardingµŗōµēæń╗ōµ×äĶ┐øĶĪīÕ╗║µ©Ī’╝īõĮ┐ńö©õĖĆĶć┤ńÜäĶĘ»ńö▒ń«Śµ│Ģ’╝īµē®Õ«╣µŚČÕŬķ£ĆĶ┐ĮÕŖĀĶŖéńé╣µĢ░µŹ«’╝īõĖŹÕåŹõ┐«µö╣µĢŻÕłŚķĆ╗ĶŠæõ╗ŻńĀüŃĆé
ÕĤńÉå
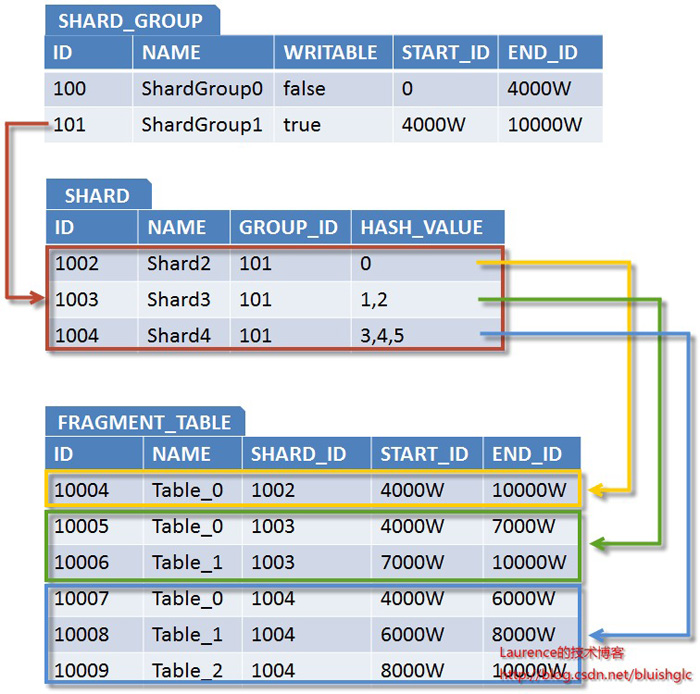
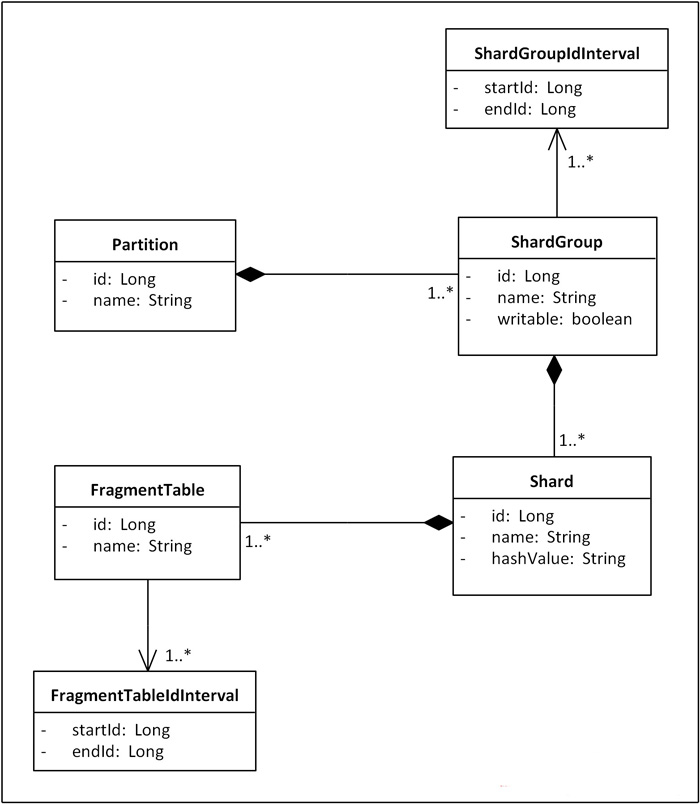
ķ”¢Õģł’╝īõĮ£õĖ║µ¢╣µĪłńÜäÕ¤║ń¤│’╝īõĖ║õ║åĶāĮõĮ┐ń│╗ń╗¤µä¤ń¤źÕł░ShardÕ╣ČÕ¤║õ║ÄShardńÜäÕłåÕĖāĶ┐øĶĪīĶĘ»ńö▒Ķ«Īń«Ś’╝īµłæõ╗¼ķ£ĆĶ”üÕ╗║ń½ŗõĖĆõĖ¬ÕÅ»õ╗źµÅÅĶ┐░Shardingµŗōµēæń╗ōµ×äńÜäń╝¢ń©ŗµ©ĪÕ×ŗŃĆéµīēńģ¦õĖĆĶł¼ńÜäÕłćÕłåÕÄ¤ÕłÖ’╝īõĖĆõĖ¬ÕŹĢõĖĆńÜäµĢ░µŹ«Õ║ōõ╝Üķ”¢ÕģłĶ┐øĶĪīÕ×éńø┤ÕłćÕłå’╝īÕ×éńø┤ÕłćÕłåÕŬµś»Õ░åÕģ│ń│╗Õ»åÕłćńÜäĶĪ©ÕłÆÕłåÕ£©õĖĆĶĄĘ’╝īµłæõ╗¼µŖŖĶ┐ÖµĀĘÕłåÕć║ńÜäõĖĆń╗äĶĪ©ń¦░õĖ║õĖĆõĖ¬PartitionŃĆé µÄźõĖŗµØź’╝īÕ”éµ×£PartitionķćīńÜäĶĪ©µĢ░µŹ«ķćÅÕŠłÕż¦õĖöÕó×ķƤĶ┐ģńīø’╝īÕ░▒ÕåŹĶ┐øĶĪīµ░┤Õ╣│ÕłćÕłå’╝īµ░┤Õ╣│ÕłćÕłåõ╝ÜÕ░åõĖĆÕ╝ĀĶĪ©ńÜäµĢ░µŹ«µīēÕó×ķćÅÕī║ķŚ┤µł¢µĢŻÕłŚµ¢╣Õ╝ÅÕłåµĢŻÕł░ÕżÜõĖ¬ShardõĖŖÕŁśÕé©ŃĆéÕ£©µłæõ╗¼ńÜäµ¢╣µĪłķćī’╝īµłæõ╗¼õĮ┐ńö©Õó×ķćÅÕī║ķŚ┤õĖĵĢŻÕłŚńøĖń╗ōÕÉłńÜäµ¢╣Õ╝Å’╝īÕģ©Õ▒ĆõĖŖ’╝īµĢ░µŹ«µīēÕó×ķćÅÕī║ķŚ┤ÕłåÕĖā’╝īõĮåµś»µ»ÅõĖ¬Õó×ķćÅÕī║ķŚ┤Õ╣ČõĖŹµś»µīēńģ¦µ¤ÉõĖ¬ShardńÜäÕŁśÕé©Ķ¦äµ©ĪÕłÆÕłåńÜä’╝īĶĆīµś»µĀ╣µŹ«õĖĆń╗äShardńÜäÕŁśÕ驵Ć╗ķćÅµØźńĪ«Õ«ÜńÜä’╝īµłæõ╗¼µŖŖĶ┐ÖµĀĘńÜäõĖĆń╗äShardń¦░õĖ║õĖĆõĖ¬ShardGroup’╝īÕ▒Ćķā©õĖŖ’╝īõ╣¤Õ░▒µś»õĖĆõĖ¬ShardGroupÕåģ’╝īĶ«░ÕĮĢõ╝ÜÕåŹµīēµĢŻÕłŚµ¢╣Õ╝ÅÕØćÕīĆÕłåÕĖāÕł░ń╗äÕåģÕÉäShardõĖŖŃĆéĶ┐ÖµĀĘ’╝īõĖƵØĪµĢ░µŹ«ńÜäĶĘ»ńö▒õ╝ÜÕģłµĀ╣µŹ«ÕģČIDµēĆÕżäńÜäÕī║ķŚ┤ńĪ«Õ«ÜShardGroup’╝īńäČÕÉÄÕåŹķĆÜĶ┐ćµĢŻÕłŚÕæĮõĖŁShardGroupÕåģńÜ䵤ÉõĖ¬ńø«µĀćShardŃĆéÕ£©µ»Åµ¼Īµē®Õ«╣µŚČ’╝īµłæõ╗¼õ╝ÜÕ╝ĢÕģźõĖĆń╗äµ¢░ńÜäShard’╝īń╗䵳ÉõĖĆõĖ¬µ¢░ńÜäShardGroup’╝īõĖ║ÕģČÕłåķģŹÕó×ķćÅÕī║ķŚ┤Õ╣ȵĀćĶ«░õĖ║ŌĆ£ÕÅ»ÕåÖÕģźŌĆØ’╝īÕÉīµŚČÕ░åÕĤµ£ēShardGroupµĀćĶ«░õĖ║ŌĆ£õĖŹÕÅ»ÕåÖÕģźŌĆØ’╝īõ║ĵś»µ¢░ńö¤µĢ░µŹ«Õ░▒õ╝ÜÕåÖÕģźµ¢░ńÜäShardGroup’╝īµŚ¦µ£ēµĢ░µŹ«õĖŹķ£ĆĶ”üĶ┐üń¦╗ŃĆéÕÉīµŚČ’╝īÕ£©ShardGroupÕåģķā©ÕÉäShardõ╣ŗķŚ┤õĮ┐ńö©µĢŻÕłŚµ¢╣Õ╝ÅÕłåÕĖāµĢ░µŹ«Ķ»╗ÕåÖ’╝īĶ┐øĶĆīÕÅłķü┐ÕģŹõ║åŌĆ£ńāŁńé╣ŌĆØķŚ«ķóśŃĆéµ£ĆÕÉÄ’╝īÕ£©ShardÕåģķā©’╝īÕĮōÕŹĢĶĪ©µĢ░µŹ«ĶŠŠÕł░õĖĆÕ«ÜõĖŖķÖɵŚČ’╝īĶĪ©ńÜäĶ»╗ÕåֵƦĶāĮÕ░▒Õ╝ĆÕ¦ŗÕż¦Õ╣ģõĖŗµ╗æ’╝īõĮåµś»µĢ┤õĖ¬µĢ░µŹ«Õ║ōÕ╣ȵ▓Īµ£ēĶŠŠÕł░ÕŁśÕé©ÕÆīĶ┤¤ĶĮĮńÜäõĖŖķÖÉ’╝īõĖ║õ║åÕģģÕłåÕÅæµīźµ£ŹÕŖĪÕÖ©ńÜäµĆ¦ĶāĮ’╝īµłæõ╗¼ķĆÜÕĖĖõ╝ܵ¢░Õ╗║ÕżÜÕ╝Āń╗ōµ×äõĖƵĀĘńÜäĶĪ©’╝īÕ╣ČÕ£©µ¢░ĶĪ©õĖŖń╗¦ń╗ŁÕåÖÕģźµĢ░µŹ«’╝īµłæõ╗¼µŖŖĶ┐ÖµĀĘńÜäĶĪ©ń¦░õĖ║ŌĆ£Õłåµ«ĄĶĪ©ŌĆØ’╝łFragment Table’╝ēŃĆéõĖŹĶ┐ć’╝īÕ╝ĢÕģźÕłåµ«ĄĶĪ©ÕÉĵēƵ£ēńÜäSQLÕ£©µē¦ĶĪīÕēŹķāĮķ£ĆĶ”üµĀ╣µŹ«IDÕ░åÕģČõĖŁńÜäĶĪ©ÕÉŹµø┐µŹóµłÉń£¤µŁŻńÜäÕłåµ«ĄĶĪ©ÕÉŹ’╝īĶ┐ÖµŚĀń¢æÕó×ÕŖĀõ║åÕ«×ńÄ░ShardingńÜäķÜŠÕ║”’╝īÕ”éµ×£ń│╗ń╗¤ÕåŹõĮ┐ńö©õ║嵤Éń¦ŹORMµĪåµ×Č’╝īķéŻõ╣łµø┐µŹóĶĄĘµØźÕÅ»ĶāĮõ╝ܵø┤ÕŖĀÕø░ķÜŠŃĆéńø«ÕēŹÕŠłÕżÜµĢ░µŹ«Õ║ōµÅÉõŠøõĖĆń¦ŹõĖÄÕłåµ«ĄĶĪ©ń▒╗õ╝╝ńÜäŌĆ£ÕłåÕī║ŌĆص£║ÕłČ’╝īõĮåµ▓Īµ£ēÕłåµ«ĄĶĪ©ńÜäÕē»õĮ£ńö©’╝īÕøóķś¤ÕÅ»õ╗źµĀ╣µŹ«ń│╗ń╗¤ńÜäÕ«×ńÄ░µāģÕåĄÕ£©Õłåµ«ĄĶĪ©ÕÆīÕłåÕī║µ£║ÕłČõĖŁńüĄµ┤╗ķĆēµŗ®ŃĆéµĆ╗õ╣ŗ’╝īÕ¤║õ║ÄõĖŖĶ┐░ÕłćÕłåÕĤńÉå’╝īµłæõ╗¼Õ░åÕŠŚÕł░Õ”éõĖŗShardingµŗōµēæń╗ōµ×äńÜäķóåÕ¤¤µ©ĪÕ×ŗ’╝Ü
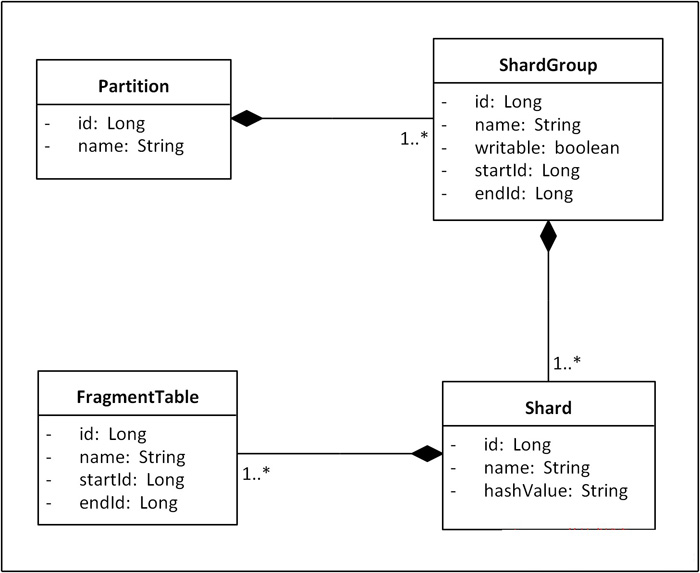
ÕøŠ1. Shardingµŗōµēæń╗ōµ×äķóåÕ¤¤µ©ĪÕ×ŗ
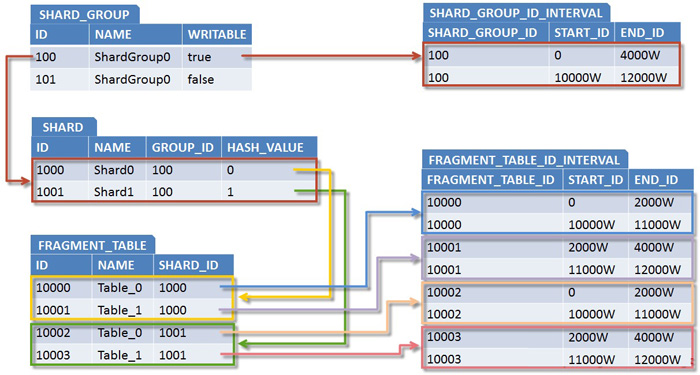
Õ£©Ķ┐ÖõĖ¬µ©ĪÕ×ŗõĖŁ’╝īµ£ēÕćĀõĖ¬ń╗åĶŖéķ£ĆĶ”üµ│©µäÅ’╝ÜShardGroupńÜäwritableÕ▒׵Ʀńö©õ║ĵĀćĶ»åĶ»źShardGroupµś»ÕÉ”ÕÅ»õ╗źÕåÖÕģźµĢ░µŹ«’╝īõĖĆõĖ¬PartitionÕ£©õ╗╗õĮĢµŚČÕĆÖÕŬĶāĮµ£ēõĖĆõĖ¬ShardGroupµś»ÕÅ»ÕåÖńÜä’╝īĶ┐ÖõĖ¬ShardGroupÕŠĆÕŠĆµś»µ£ĆĶ┐æõĖƵ¼Īµē®Õ«╣Õ╝ĢÕģźńÜä’╝østartIdÕÆīendIdÕ▒׵Ʀńö©õ║ĵĀćĶ»åĶ»źShardGroupńÜäIDÕó×ķćÅÕī║ķŚ┤’╝øShardńÜähashValueÕ▒׵Ʀńö©õ║ĵĀćĶ»åĶ»źShardĶŖéńé╣µÄźÕÅŚÕō¬õ║øµĢŻÕłŚÕĆ╝ńÜäµĢ░µŹ«’╝øFragmentTableńÜästartIdÕÆīendIdµś»ńö©õ║ĵĀćĶ»åĶ»źÕłåµ«ĄĶĪ©Õé©ÕŁśµĢ░µŹ«ńÜäIDÕī║ķŚ┤ŃĆé
ńĪ«ń½ŗõĖŖĶ┐░µ©ĪÕ×ŗÕÉÄ’╝īµłæõ╗¼ķ£ĆĶ”üķĆÜĶ┐ćķģŹńĮ«µ¢ćõ╗ȵł¢µś»Õ£©µĢ░µŹ«Õ║ōõĖŁÕ╗║ń½ŗõĖÄõ╣ŗÕ»╣Õ║öńÜäĶĪ©µØźÕŁśÕé©ĶŖéńé╣ÕģāµĢ░µŹ«’╝īĶ┐ÖµĀĘ’╝īµĢ┤õĖ¬ÕŁśÕé©ń│╗ń╗¤ńÜäµŗōµēæń╗ōµ×äÕ░▒ÕÅ»õ╗źĶó½µīüõ╣ģÕī¢ĶĄĘµØź’╝īń│╗ń╗¤ÕÉ»ÕŖ©µŚČÕ░▒ĶāĮõ╗ÄķģŹńĮ«µ¢ćõ╗ȵł¢µĢ░µŹ«Õ║ōõĖŁÕŖĀĶĮĮÕć║ÕĮōÕēŹńÜäShardingµŗōµēæń╗ōµ×äĶ┐øĶĪīĶĘ»ńö▒Ķ«Īń«Śõ║å’╝īµē®Õ«╣µŚČÕŬķ£ĆĶ”üÕÉæÕ»╣Õ║öńÜäµ¢ćõ╗ȵł¢ĶĪ©õĖŁÕŖĀÕģźńøĖÕģ│ńÜäĶŖéńé╣õ┐Īµü»ķćŹÕÉ»ń│╗ń╗¤ÕŹ│ÕÅ»’╝īõĖŹķ£ĆĶ”üõ┐«µö╣õ╗╗õĮĢĶĘ»ńö▒ķĆ╗ĶŠæõ╗ŻńĀüŃĆé
ńż║õŠŗ
Ķ«®µłæõ╗¼ķĆÜĶ┐ćńż║õŠŗµØźõ║åĶ¦ŻĶ┐ÖÕźŚµ¢╣µĪłµś»Õ”éõĮĢÕĘźõĮ£ńÜäŃĆé
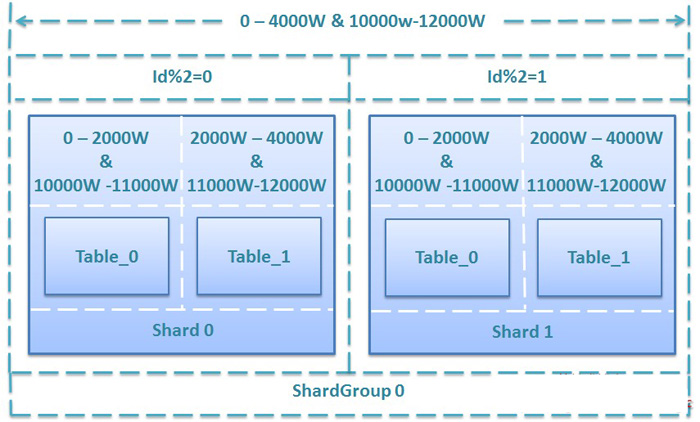
ķśČµ«ĄõĖĆ’╝ÜÕłØÕ¦ŗõĖŖń║┐
ÕüćĶ«Šµ¤Éń│╗ń╗¤ÕłØÕ¦ŗõĖŖń║┐’╝īĶ¦äÕłÆõĖ║µ¤ÉĶĪ©µÅÉõŠø4000WµØĪĶ«░ÕĮĢńÜäÕŁśÕé©ĶāĮÕŖø’╝īĶŗźÕŹĢĶĪ©ÕŁśÕé©õĖŖķÖÉõĖ║1000WµØĪ’╝īÕŹĢÕ║ōÕŁśÕé©õĖŖķÖÉõĖ║2000WµØĪ’╝īÕģ▒ķ£Ć2õĖ¬Shard’╝īµ»ÅõĖ¬ShardÕīģÕɽõĖżõĖ¬Õłåµ«ĄĶĪ©’╝īShardGroupÕó×ķćÅÕī║ķŚ┤õĖ║0-4000W’╝īµīē2ÕÅ¢õĮÖÕłåµĢŻÕł░2õĖ¬ShardõĖŖ’╝īÕģĘõĮōĶ¦äÕłÆµ¢╣µĪłÕ”éõĖŗ’╝Ü
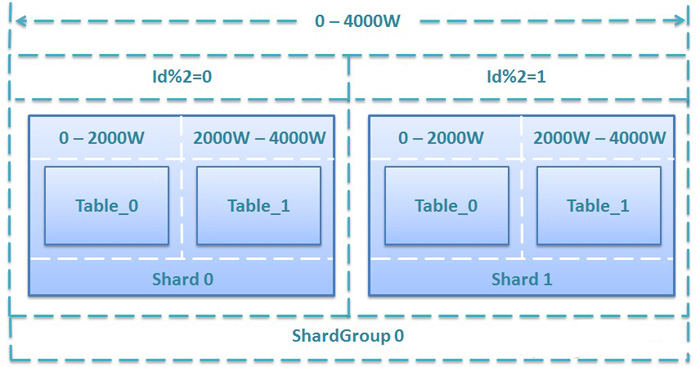
ÕøŠ2. ÕłØÕ¦ŗ4000WÕŁśÕé©Ķ¦äµ©ĪńÜäĶ¦äÕłÆµ¢╣µĪł
õĖÄõ╣ŗńøĖķĆéÕ║ö’╝īShardingµŗōµēæń╗ōµ×äńÜäÕģāµĢ░µŹ«Õ”éõĖŗ’╝Ü
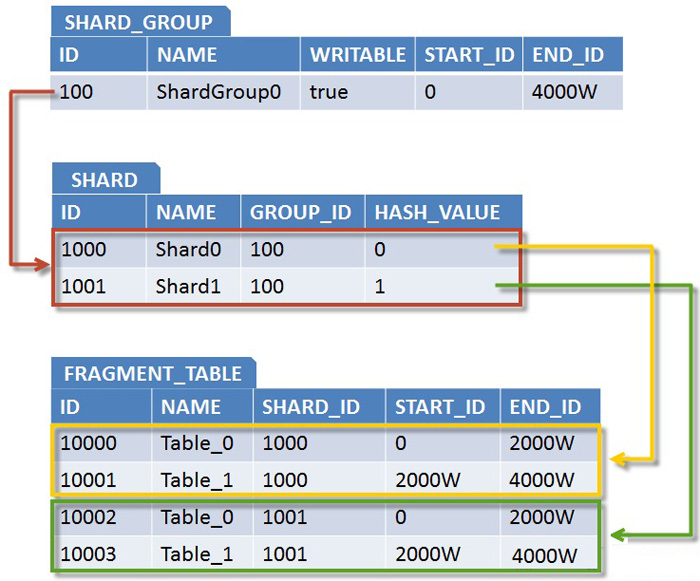
ÕøŠ3. Õ»╣Õ║öShardingÕģāµĢ░µŹ«
ķśČµ«Ąõ║ī’╝Üń│╗ń╗¤µē®Õ«╣
ń╗ÅĶ┐ćõĖƵ«ĄµŚČķŚ┤ńÜäĶ┐ÉĶĪī’╝īÕĮōÕĤĶĪ©µĆ╗µĢ░µŹ«ķĆ╝Ķ┐æ4000WµØĪõĖŖķÖɵŚČ’╝īń│╗ń╗¤Õ░▒ķ£ĆĶ”üµē®Õ«╣õ║åŃĆéõĖ║õ║åµ╝öńż║µ¢╣µĪłńÜäńüĄµ┤╗µĆ¦’╝īµłæõ╗¼ÕüćĶ«ŠńÄ░Õ£©µ£ēõĖēÕÅ░µ£ŹÕŖĪÕÖ©Shard2ŃĆüShard3ŃĆüShard4’╝īÕģȵƦĶāĮÕÆīÕŁśÕé©ĶāĮÕŖøĶĪ©ńÄ░õŠØµ¼ĪõĖ║Shard2<Shard3<Shard4’╝īµłæõ╗¼Õ«ēµÄÆShard2Õé©ÕŁś1000WµØĪĶ«░ÕĮĢ’╝īShard3Õé©ÕŁś2000WµØĪĶ«░ÕĮĢ’╝īShard4Õé©ÕŁś3000WµØĪĶ«░ÕĮĢ’╝īĶ┐ÖµĀĘ’╝īĶ»źĶĪ©ńÜäµĆ╗ÕŁśÕé©ĶāĮÕŖøÕ░åńö▒µē®Õ«╣ÕēŹńÜä4000WµØĪµÅÉÕŹćÕł░10000WµØĪ’╝īõ╗źõĖŗµś»Ķ»”ń╗åńÜäĶ¦äÕłÆµ¢╣µĪł’╝Ü
ÕøŠ4. õ║īµ¼Īµē®Õ«╣6000WÕŁśÕé©Ķ¦äµ©ĪńÜäĶ¦äÕłÆµ¢╣µĪł
ńøĖÕ║öµŗōµēæń╗ōµ×äĶĪ©µĢ░µŹ«õĖŗ’╝Ü
ÕøŠ5. Õ»╣Õ║öShardingÕģāµĢ░µŹ«
õ╗ÄĶ┐ÖõĖ¬µē®Õ«╣µĪłõŠŗõĖŁµłæõ╗¼ÕÅ»õ╗źń£ŗÕć║Ķ»źµ¢╣µĪłÕģüĶ«ĖµĀ╣µŹ«ńĪ¼õ╗ȵāģÕåĄĶ┐øĶĪīńüĄµ┤╗Ķ¦äÕłÆ’╝īÕ»╣µē®Õ«╣Ķ¦äµ©ĪÕÆīĶŖéńé╣µĢ░ķćŵ▓Īµ£ēńĪ¼µĆ¦Ķ¦äÕ«Ü’╝īµś»õĖĆń¦ŹķØ×ÕĖĖĶć¬ńö▒ńÜäµē®Õ«╣µ¢╣µĪłŃĆé
Õó×Õ╝║
µÄźõĖŗµØźĶ«®µłæõ╗¼Ķ«©Ķ«║õĖĆõĖ¬ķ½śń║¦Ķ»Øķóś’╝ÜÕ»╣ŌĆ£ÕåŹńö¤ŌĆØÕŁśÕé©ń®║ķŚ┤ńÜäÕł®ńö©ŃĆéÕ»╣õ║ÄÕż¦ÕżÜµĢ░ń│╗ń╗¤µØźĶ»┤’╝īÕÄåÕÅ▓µĢ░µŹ«ĶŠāõĖ║ń©│Õ«Ü’╝īĶó½µø┤µ¢░µł¢µś»ÕłĀķÖżńÜäµ”éńÄćÕ╣ČõĖŹķ½ś’╝īÕÅŹµśĀÕł░µĢ░µŹ«Õ║ōõĖŖÕ░▒µś»ÕÄåÕÅ▓ShardńÜäµĢ░µŹ«ķćÅÕ¤║µ£¼õ┐صīüµüÆÕ«Ü’╝īõĮåõ╣¤õĖŹµÄÆķÖżµ¤Éõ║øń│╗ń╗¤ÕģȵĢ░µŹ«µ£ēÕÉīńŁēńÜäÕłĀķÖżµ”éńÄć’╝īńöÜĶć│µś»ĶČŖĶĆüńÜäµĢ░µŹ«Ķó½ÕłĀķÖżńÜäÕÅ»ĶāĮµĆ¦ĶČŖÕż¦’╝īĶ┐ÖµĀĘÕÅŹµśĀÕł░µĢ░µŹ«Õ║ōõĖŖÕ░▒µś»ÕÄåÕÅ▓ShardķÜÅńØƵŚČķŚ┤ńÜäµÄ©ń¦╗’╝īµĢ░µŹ«ķćÅõ╝ܵīüń╗ŁõĖŗķÖŹ’╝īÕ£©ń╗ÅÕÄåõ║åõĖƵ«ĄµŚČķŚ┤ÕÉÄ’╝īĶŖéńé╣Õ░▒õ╝ÜĶģŠÕć║ÕŠłÕż¦õĖĆķā©ÕłåÕŁśÕé©ń®║ķŚ┤’╝īµłæõ╗¼µŖŖĶ┐ÖµĀĘńÜäÕŁśÕé©ń®║ķŚ┤ÕŽŌĆ£ÕåŹńö¤ŌĆØÕŁśÕé©ń®║ķŚ┤’╝īÕ”éõĮĢµ£ēµĢłÕł®ńö©ÕåŹńö¤ÕŁśÕé©ń®║ķŚ┤µś»Ķ┐Öõ║øń│╗ń╗¤Õ£©Ķ«ŠĶ«Īµē®Õ«╣µ¢╣µĪłµŚČķ£ĆĶ”üńē╣Õł½ĶĆāĶÖæńÜäŃĆéÕø×Õł░µłæõ╗¼ńÜäµ¢╣µĪł’╝īÕ«×ķÖģõĖŖµłæõ╗¼ÕŬķ£ĆĶ”üÕ£©ńÄ░µ£ēÕ¤║ńĪĆõĖŖĶ┐øĶĪīõĖĆõĖ¬ń«ĆÕŹĢńÜäÕŹćń║¦Õ░▒ÕÅ»õ╗źÕ«×ńÄ░Õ»╣ÕåŹńö¤ÕŁśÕé©ń®║ķŚ┤ńÜäÕł®ńö©’╝īÕŹćń║¦ńÜäÕģ│ķö«Õ░▒µś»Õ░åĶ┐ćÕÄ╗ShardGroupÕÆīFragmentTableńÜäÕŹĢõĖĆńÜäIDÕī║ķŚ┤µÅÉÕŹćõĖ║ÕżÜķćŹIDÕī║ķŚ┤ŃĆéõĖ║µŁżµłæõ╗¼µŖŖShardGroupÕÆīFragmentTableńÜäIDÕī║ķŚ┤Õ▒׵ƦµŖĮń”╗Õć║µØź’╝īÕłåÕł½ńö©ShardGroupIntervalÕÆīFragmentTableIdIntervalĶĪ©ńż║’╝īÕ╣ČÕÆīÕ«āõ╗¼õ┐صīüõĖĆÕ»╣ÕżÜÕģ│ń│╗ŃĆé
ÕøŠ6. Õó×Õ╝║ÕÉÄńÜäShardingµŗōµēæń╗ōµ×äķóåÕ¤¤µ©ĪÕ×ŗ
Ķ«®µłæõ╗¼Ķ┐śµś»ķĆÜĶ┐ćõĖĆõĖ¬ńż║õŠŗµØźõ║åĶ¦ŻÕŹćń║¦ÕÉÄńÜäµ¢╣µĪłµś»Õ”éõĮĢÕĘźõĮ£ńÜäŃĆé
ķśČµ«ĄõĖē’╝ÜõĖŹµē®Õ«╣’╝īķćŹÕżŹÕł®ńö©ÕåŹńö¤ÕŁśÕé©ń®║ķŚ┤
ÕüćĶ«Šń│╗ń╗¤ÕÅłń╗ÅĶ┐ćõĖƵ«ĄµŚČķŚ┤ńÜäĶ┐ÉĶĪīõ╣ŗÕÉÄ’╝īõ║īµ¼Īµē®Õ«╣ńÜä6000WµØĪÕŁśÕé©ń®║ķŚ┤ÕŹ│Õ░åĶĆŚÕ░Į’╝īõĮåµś»ńö▒õ║Äń│╗ń╗¤Ķć¬Ķ║½ńÜäńē╣ńé╣’╝īµŚ®µ£¤ńÜäÕŠłÕżÜµĢ░µŹ«Ķó½ÕłĀķÖż’╝īShard0ÕÆīShard1ÕÅłÕÉäĶć¬ĶģŠÕć║õ║åõĖĆÕŹŖńÜäÕŁśÕé©ń®║ķŚ┤’╝īõ║ĵś»ShardGroup0µĆ╗Ķ«Īµ£ē2000WµØĪńÜäÕŁśÕé©ń®║ķŚ┤ÕÅ»õ╗źķ揵¢░Õł®ńö©ŃĆéõĖ║µŁż’╝īµłæõ╗¼ķ揵¢░Õ░åShardGroup0µĀćĶ«░õĖ║writable=true’╝īÕ╣Čń╗ÖÕ«āĶ┐ĮÕŖĀõĖƵ«ĄIDÕī║ķŚ┤’╝Ü10000W-12000W’╝īĶ┐øĶĆīÕŠŚÕł░Õ”éõĖŗĶ¦äÕłÆµ¢╣µĪł’╝Ü
ÕøŠ7. ķćŹÕżŹÕł®ńö©2000WÕåŹńö¤ÕŁśÕé©ń®║ķŚ┤ńÜäĶ¦äÕłÆµ¢╣µĪł
ńøĖÕ║öµŗōµēæń╗ōµ×äńÜäÕģāµĢ░µŹ«Õ”éõĖŗ’╝Ü
ÕøŠ8. Õ»╣Õ║öShardingÕģāµĢ░µŹ«
Õ░Åń╗ō
Ķ┐ÖÕźŚµ¢╣µĪłń╗╝ÕÉłÕł®ńö©õ║åÕó×ķćÅÕī║ķŚ┤ÕÆīµĢŻÕłŚõĖżń¦ŹĶĘ»ńö▒µ¢╣Õ╝ÅńÜäõ╝śÕŖ┐’╝īķü┐ÕģŹõ║åµĢ░µŹ«Ķ┐üń¦╗ÕÆīŌĆ£ńāŁńé╣ŌĆØķŚ«ķóś’╝īÕÉīµŚČ’╝īÕ«āÕ»╣Shardingµŗōµēæń╗ōµ×äÕ╗║µ©Ī’╝īõĮ┐ńö©õ║åõĖĆĶć┤ńÜäĶĘ»ńö▒ń«Śµ│Ģ’╝īõ╗ÄĶĆīķü┐ÕģŹõ║åµē®Õ«╣µŚČõ┐«µö╣ĶĘ»ńö▒õ╗ŻńĀü’╝īµś»õĖĆń¦ŹńÉåµā│ńÜäShardingµē®Õ«╣µ¢╣µĪłŃĆé



ńøĖÕģ│µÄ©ĶŹÉ
ÕłåÕ║ōÕłåĶĪ©ķććńö©sharding-jdbc µĢ░µŹ«Õ║ōĶ┐׵ğµ▒Āń«ĪńÉåµś»alibabańÜädruid-spring-boot-starter ķĪ╣ńø«õĮ┐ńö©springbootµÉŁÕ╗║’╝ījunitµĄŗĶ»Ģ’╝īõĖ║õ║åµ¢╣õŠ┐Õ«×ńÄ░Õ»╣µĢ░µŹ«Õ║ōµōŹõĮ£ń╗¦µē┐õ║åmybatisplus’╝īõĖ║õ║åÕ░æõ║øgetŃĆüset Õ╝ĢÕģźlombok
### µĢ░µŹ«Õ║ōÕłåÕ║ōÕłåĶĪ©’╝łSharding’╝ēµŖƵ£»Ķ»”Ķ¦Ż #### õĖĆŃĆüÕ¤║µ£¼µ”éÕ┐ĄõĖÄÕĤńÉå **µĢ░µŹ«Õ║ōÕłåÕ║ōÕłåĶĪ©’╝łSharding’╝ē**µś»õĖĆń¦ŹÕĖĖĶ¦üńÜäµĢ░µŹ«Õ║ōõ╝śÕī¢µŖƵ£»’╝īõĖ╗Ķ”üńö©õ║ÄĶ¦ŻÕå│Õż¦Ķ¦äµ©ĪµĢ░µŹ«ÕŁśÕé©ÕÆīķ½śÕ╣ČÕÅæĶ«┐ķŚ«ÕĖ”µØźńÜäµĆ¦ĶāĮńōČķółķŚ«ķóśŃĆéÕ«āķĆÜĶ┐ćÕ░åÕŹĢõĖƵĢ░µŹ«Õ║ō...
Õ¤╣Ķ«ŁµĢ░µŹ«Õ║ōÕłåÕ║ōÕłåĶĪ©’╝īõ╗źÕÅŖÕłåÕĖāÕ╝ŵĢ░µŹ«Õ║ōµÉŁÕ╗║ÕÉäń¦ŹķŚ«ķóśĶ¦ŻÕå│µ¢╣µĪł 1.µĢ░µŹ«Õ║ōÕłåńēćÕĤńÉå 2.MycatõĖÄSharding-JDBC Õ»╣µ»ö 3.ÕłåÕĖāÕ╝ŵĢ░µŹ«Õ║ōķŚ«ķóśĶ¦ŻÕå│µ¢╣µĪł’╝īÕīģµŗ¼ÕłåķģŹŃĆüõĖĆĶć┤µĆ¦ŃĆüõ║ŗÕŖĪµÄ¦ÕłČńŁē
µĢ░µŹ«Õ║ōÕłåÕ║ōÕłåĶĪ©µś»Õ║öÕ»╣Õż¦µĢ░µŹ«ķćÅŃĆüķ½śÕ╣ČÕÅæĶ«┐ķŚ«Õ£║µÖ»õĖŗńÜäķćŹĶ”üĶ¦ŻÕå│µ¢╣µĪł’╝īµŚ©Õ£©µÅÉķ½śµĢ░µŹ«Õ║ōń│╗ń╗¤ńÜäµĆ¦ĶāĮÕÆīÕÅ»µē®Õ▒ĢµĆ¦ŃĆéSharding-JDBCµś»ķś┐ķćīÕĘ┤ÕĘ┤Õ╝Ƶ║ÉńÜäõĖƵ¼ŠĶĮ╗ķćÅń║¦ńÜäJavaµĪåµ×Č’╝īńö©õ║ÄÕ«×ńÄ░µĢ░µŹ«Õ║ōńÜäµ░┤Õ╣│µŗåÕłå’╝īÕ«āµś»Õ¤║õ║ÄJDBCńÜäõĖŁķŚ┤õ╗Č’╝ī...
Ķ┐ÖõĖ¬"mysqlÕłåÕ║ōÕłåĶĪ©sharding-jdbc-sharding-jdbc-demo.zip"ÕÄŗń╝®ÕīģµÅÉõŠøńÜäÕ░▒µś»õĖĆõĖ¬õĮ┐ńö©Sharding-JDBCĶ┐øĶĪīµĢ░µŹ«Õ║ōÕłåÕ║ōÕłåĶĪ©ńÜäńż║õŠŗķĪ╣ńø«ŃĆé Sharding-JDBCńÜäÕĘźõĮ£ÕĤńÉåµś»ķĆÜĶ┐ćķĆŵśÄÕī¢ńÜäJDBCÕ▒é’╝īÕ░åµĢ░µŹ«ĶĘ»ńö▒ŃĆüÕłåńēćĶ¦äÕłÖŃĆüĶ»╗ÕåÖÕłåń”╗...
µ£¼ķĪ╣ńø«Õ¤║õ║ÄJavaŃĆüSpringBootŃĆüMyBatisõ╗źÕÅŖShardingJDBCÕ«×ńÄ░õ║åõĖĆõĖ¬ÕłåÕ║ōÕłåĶĪ©ńÜäĶ¦ŻÕå│µ¢╣µĪł’╝īµŚ©Õ£©ÕĖ«ÕŖ®Õ╝ĆÕÅæĶĆģńÉåĶ¦ŻÕ╣ȵÄīµÅĪĶ┐ÖõĖƵŖƵ£»ŃĆéõ╗źõĖŗµś»Õģ│õ║ÄĶ┐Öõ║øµŖƵ£»ńÜäĶ»”ń╗åõ╗ŗń╗Ź’╝Ü **Java**’╝Ü Javaµś»õĖĆń¦ŹÕ╣┐µ│øõĮ┐ńö©ńÜäķØóÕÉæÕ»╣Ķ▒ĪńÜäń╝¢ń©ŗĶ»ŁĶ©Ć’╝ī...
µĆ╗ńÜäµØźĶ»┤’╝īŌĆ£Sharding + Mybatis-Plus ÕłåÕ║ōÕłåĶĪ©ŌĆصś»õĖĆń¦Źµ£ēµĢłńÜäĶ¦ŻÕå│Õż¦µĢ░µŹ«ķćÅÕ£║µÖ»õĖŗńÜäµĢ░µŹ«Õ║ōµē®Õ▒ĢńŁ¢ńĢź’╝īÕ«āķĆÜĶ┐ćJavańÜäõĖŁķŚ┤õ╗ȵŖƵ£»’╝īÕ«×ńÄ░õ║åµĢ░µŹ«Õ║ōÕ▒éķØóńÜäµ░┤Õ╣│µē®Õ▒Ģ’╝īń╗ōÕÉłMybatis-PlusńÜäõŠ┐Õł®µĆ¦’╝īķÖŹõĮÄõ║åÕ╝ĆÕÅæÕżŹµØéÕ║”’╝īµÅÉÕŹćõ║åń│╗ń╗¤...
### ÕĮōÕĮōÕ╝Ƶ║ÉSharding-JDBC’╝ÜĶĮ╗ķćÅń║¦µĢ░µŹ«Õ║ōÕłåÕ║ōÕłåĶĪ©õĖŁķŚ┤õ╗Č #### µ”éĶ┐░ ÕĮōÕĮōńĮæĶ┐æµ£¤Õ╝Ƶ║Éõ║åõĖƵ¼ŠÕÉŹõĖ║Sharding-JDBCńÜäĶĮ╗ķćÅń║¦µĢ░µŹ«Õ║ōÕłåÕ║ōÕłåĶĪ©õĖŁķŚ┤õ╗ČŃĆéõĮ£õĖ║õĖƵ¼Šķ½śµĆ¦ĶāĮŃĆüµśōńö©µĆ¦ķ½śńÜäµĢ░µŹ«Õ║ōµ░┤Õ╣│ÕłåńēćµĪåµ×Č’╝īSharding-JDBCÕ£©Ķ«ŠĶ«ĪõĖŖ...
Õ£©ITĶĪīõĖÜõĖŁ’╝īµĢ░µŹ«Õ║ōµē®Õ▒Ģµś»Ķ¦ŻÕå│ķ½śÕ╣ČÕÅæŃĆüÕż¦µĢ░µŹ«ķćÅÕ£║µÖ»õĖŗńÜäķćŹĶ”üńŁ¢ńĢźõ╣ŗõĖĆ’╝ī"shardingÕłåÕ║ōÕłåĶĪ©"Õ░▒µś»ÕģČõĖŁõĖĆń¦ŹÕĖĖĶ¦üńÜäµ¢╣µ│ĢŃĆéµ£¼ńż║õŠŗķĆÜĶ┐ćµĢ┤ÕÉłõĖĆń│╗ÕłŚµŖƵ£»’╝īÕīģµŗ¼SpringBootŃĆüShardingSphereŃĆüSwaggerÕÆīMyBatis-Plus’╝īµØźµ╝öńż║Õ”éõĮĢ...
µĢ░µŹ«Õ║ōÕłåÕ║ōÕłåĶĪ©(sharding)
µ£¼Ķ»Šń©ŗµś»µ¢░õĖĆõ╗ŻÕłåÕ║ōÕłåĶĪ© Sharding-JDBC µ£ĆõĮ│Õ«×ĶĘĄõĖōķóśĶ»Šń©ŗŃĆéĶ»Šń©ŗÕåģÕ«╣õĖ░Õ»ī’╝īµČĄńø¢õ║å MySQL µ×ȵ×äµ╝öÕÅśÕŹćń║¦ŃĆüÕłåÕ║ōÕłåĶĪ©ńÜäõ╝śń╝║ńé╣ŃĆüÕĖĖĶ¦üńŁ¢ńĢźÕÅŖõĖŁķŚ┤õ╗Čõ╗ŗń╗ŹńŁēÕżÜõĖ¬µ¢╣ķØóŃĆé Ķ»Šń©ŗķ”¢Õģłõ╗ŗń╗Źõ║åÕłåÕ║ōÕłåĶĪ©ńÜäĶāīµÖ»’╝īÕīģµŗ¼ MySQL µĢ░µŹ«Õ║ōµ×ȵ×ä...
Sharding-JDBCõĮ£õĖ║ķś┐ķćīÕĘ┤ÕĘ┤Õ╝Ƶ║ÉńÜäõĖƵ¼ŠĶĮ╗ķćÅń║¦µĢ░µŹ«Õ║ōõĖŁķŚ┤õ╗Č’╝īÕ«āµÅÉõŠøõ║åõĖĆń¦ŹµŚĀõŠĄÕģźńÜäÕłåÕ║ōÕłåĶĪ©Ķ¦ŻÕå│µ¢╣µĪł’╝īķØ×ÕĖĖķĆéÕÉłõ║ÄÕŹĢõĮōķĪ╣ńø«ńÜäµĢ░µŹ«Õ║ōµē®Õ▒ĢŃĆéÕ£©Ķ┐ÖõĖ¬"ķøåµłÉsharding-jdbcÕ«×ńÄ░ÕłåÕ║ōÕłåĶĪ©.zip"ńÜäÕÄŗń╝®ÕīģõĖŁ’╝īµłæõ╗¼ÕÅ»õ╗źµĘ▒ÕģźÕŁ”õ╣ĀÕ”éõĮĢÕ░å...
### ÕłåÕ║ōÕłåĶĪ©shardingjdbcń¤źĶ»åńé╣Ķ»”Ķ┐░ #### õĖĆŃĆüń«Ćõ╗ŗ Apache ShardingSphere µś»õĖĆõĖ¬ÕłåÕĖāÕ╝ÅńÜäµĢ░µŹ«Õ║ōõĖŁķŚ┤õ╗ČķĪ╣ńø«’╝īµŚ©Õ£©µÅÉõŠøń«ĆÕŹĢµśōńö©ŃĆüķ½śÕ║”ÕÅ»µē®Õ▒ĢńÜäµĢ░µŹ«ÕłåńēćĶ¦ŻÕå│µ¢╣µĪłŃĆéShardingSphere µö»µīüÕżÜń¦Źµ©ĪÕ╝Å’╝īÕīģµŗ¼ JDBC µ©ĪÕ╝ÅŃĆü...
1ŃĆüshardingsphere Õ╣ČõĖŹńø┤µÄźµö»µīüĶŠŠµó”µĢ░µŹ«Õ║ō’╝īķ£ĆĶ”üÕ«×ńÄ░ķā©ÕłåµÄźÕÅŻķĆ╗ĶŠæŃĆé 2ŃĆüµ£¼demoÕ╣ČõĖŹÕ«īÕģ©µö»µīüĶŠŠµó”sql 3ŃĆüÕīģķćīķØóÕɽµ£ētest demoÕÅ»õ╗źńø┤µÄźµĄŗĶ»Ģ 4ŃĆüµä¤Ķ░óshardingsphere Õøóķś¤ŃĆé 5ŃĆüÕģĘõĮōÕ”éõĮĢÕ«×ńÄ░ńÜä Ķ»Ęµ¤źń£ŗµłæńÜäÕŹÜµ¢ć ...
Õ£©JavaÕ╝ĆÕÅæõĖŁ’╝īķØóÕ»╣Õż¦µĢ░µŹ«ķćÅńÜäµĢ░µŹ«Õ║ōµōŹõĮ£µŚČ’╝īÕłåÕ║ōÕłåĶĪ©µłÉõĖ║õĖĆń¦ŹÕĖĖĶ¦üńÜäĶ¦ŻÕå│µ¢╣µĪł’╝īõ╗źµÅÉķ½śµĢ░µŹ«Ķ»╗ÕåֵƦĶāĮÕÆīń│╗ń╗¤ÕÅ»ńö©µĆ¦ŃĆéSharding-JDBCõĮ£õĖ║ķś┐ķćīÕĘ┤ÕĘ┤Õ╝Ƶ║ÉńÜäĶĮ╗ķćÅń║¦JavaµĪåµ×Č’╝īµś»Õ«×ńÄ░ÕłåÕ║ōÕłåĶĪ©ńÜäõĖĆń¦Źõ╝śń¦ĆķĆēµŗ®ŃĆéµ£¼µ¢ćÕ░åµĘ▒ÕģźµÄóĶ«©...
µĀćķóś"sharding-jdbcõ╣ŗŌĆöŌĆöÕłåÕ║ōÕłåĶĪ©Õ«×õŠŗÕ«īµĢ┤µ║ÉńĀü"µīćÕć║õ║åµ£¼õĖ╗ķóśńÜäµĀĖÕ┐ā’╝īÕŹ│`Sharding-JDBC`Õ£©Õ«×ńÄ░µĢ░µŹ«Õ║ōÕłåÕ║ōÕłåĶĪ©õĖŁńÜäÕ║öńö©ŃĆéSharding-JDBCµś»ķś┐ķćīÕĘ┤ÕĘ┤Õ╝Ƶ║ÉńÜäĶĮ╗ķćÅń║¦JavaµĪåµ×Č’╝īÕ«āÕÅ»õ╗źÕ£©õĖŹõ┐«µö╣ńÄ░µ£ēµĢ░µŹ«Õ║ōńÜäµāģÕåĄõĖŗ’╝īÕ»╣µĢ░µŹ«Õ║ō...
Sharding-JDBCµś»ķś┐ķćīÕĘ┤ÕĘ┤Õ╝Ƶ║ÉńÜäÕģ│ń│╗Õ×ŗµĢ░µŹ«Õ║ōõĖŁķŚ┤õ╗Č’╝īµÅÉõŠøõ║åµĢ░µŹ«Õ║ōÕłåÕ║ōÕłåĶĪ©ŃĆüĶ»╗ÕåÖÕłåń”╗ŃĆüµĢ░µŹ«Õ║ōĶĘ»ńö▒ńŁēÕŖ¤ĶāĮŃĆéµ£¼µĢÖń©ŗÕ░åµīćÕ»╝Ķ»╗ĶĆģõĮ┐ńö©Sharding-JDBCÕ«×ńÄ░Spring BootķĪ╣ńø«õĖŁńÜäÕłåÕ║ōÕłåĶĪ©ÕÆīĶ»╗ÕåÖÕłåń”╗ŃĆé õĖĆŃĆüSharding-JDBCń«Ćõ╗ŗ ...
µĢ░µŹ«Õ║ōÕłåÕ║ōÕłåĶĪ©(sharding)ń│╗ÕłŚ(õ║ī) Õģ©Õ▒ĆõĖ╗ķö«ńö¤µłÉńŁ¢ńĢź