
HadoopеЃґжЧПз≥їеИЧжЦЗзЂ†пЉМдЄїи¶БдїЛзїНHadoopеЃґжЧПдЇІеУБпЉМеЄЄзФ®зЪДй°єзЫЃеМЕжЛђHadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, ChukwaпЉМжЦ∞еҐЮеК†зЪДй°єзЫЃеМЕжЛђпЉМYARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hueз≠ЙгАВ
дїО2011еєіеЉАеІЛпЉМдЄ≠еЫљињЫеЕ•е§ІжХ∞жНЃй£ОиµЈдЇСжґМзЪДжЧґдї£пЉМдї•HadoopдЄЇдї£и°®зЪДеЃґжЧПиљѓдїґпЉМеН†жНЃдЇЖе§ІжХ∞жНЃе§ДзРЖзЪДеєњйШФеЬ∞зЫШгАВеЉАжЇРзХМеПКеОВеХЖпЉМжЙАжЬЙжХ∞жНЃиљѓдїґпЉМжЧ†дЄАдЄНеРСHadoopйЭ†жЛҐгАВHadoopдєЯдїОе∞ПдЉЧзЪДйЂШеѓМеЄЕйҐЖеЯЯпЉМеПШжИРдЇЖе§ІжХ∞жНЃеЉАеПСзЪДж†ЗеЗЖгАВеЬ®HadoopеОЯжЬЙжКАжЬѓеЯЇз°АдєЛдЄКпЉМеЗЇзО∞дЇЖHadoopеЃґжЧПдЇІеУБпЉМйАЪињЗвАЬе§ІжХ∞жНЃвАЭж¶ВењµдЄНжЦ≠еИЫжЦ∞пЉМжО®еЗЇзІСжКАињЫж≠•гАВ
дљЬдЄЇITзХМзЪДеЉАеПСдЇЇеСШпЉМжИСдїђдєЯи¶БиЈЯдЄКиКВе•ПпЉМжКУдљПжЬЇйБЗпЉМиЈЯзЭАHadoopдЄАиµЈйЫДиµЈпЉБ
еЕ≥дЇОдљЬиАЕпЉЪ
- еЉ†дЄє(Conan), з®ЛеЇПеСШJava,R,PHP,Javascript
- weiboпЉЪ@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
иљђиљљиѓЈж≥®жШОеЗЇе§ДпЉЪ
http://blog.fens.me/hadoop-maven-eclipse/

еЙНи®А
HadoopзЪДMapReduceзОѓеҐГжШѓдЄАдЄ™е§НжЭВзЪДзЉЦз®ЛзОѓеҐГпЉМжЙАдї•жИСдїђи¶Бе∞љеПѓиГљеЬ∞зЃАеМЦжЮДеїЇMapReduceй°єзЫЃзЪДињЗз®ЛгАВMavenжШѓдЄАдЄ™еЊИдЄНйФЩзЪДиЗ™еК®еМЦй°єзЫЃжЮДеїЇеЈ•еЕЈпЉМйАЪињЗMavenжЭ•еЄЃеК©жИСдїђдїОе§НжЭВзЪДзОѓеҐГйЕНзљЃдЄ≠иІ£иД±еЗЇжЭ•пЉМдїОиАМж†ЗеЗЖеМЦеЉАеПСињЗз®ЛгАВжЙАдї•пЉМеЖЩMapReduceдєЛеЙНпЉМиЃ©жИСдїђеЕИиК±зВєжЧґйЧіжККеИАз£®ењЂпЉБпЉБељУзДґпЉМйЩ§дЇЖMavenињШжЬЙеЕґдїЦзЪДйАЙжЛ©Gradle(жО®иНР), IvyвА¶.
еРОйЭҐе∞ЖдЉЪжЬЙдїЛзїНеЗ†зѓЗMapReduceеЉАеПСзЪДжЦЗзЂ†пЉМйГљи¶БдЊЭиµЦдЇОжЬђжЦЗдЄ≠MavenзЪДжЮДеїЇзЪДMapReduceзОѓеҐГгАВ
зЫЃељХ
- MavenдїЛзїН
- MavenеЃЙи£Е(win)
- HadoopеЉАеПСзОѓеҐГдїЛзїН
- зФ®MavenжЮДеїЇHadoopзОѓеҐГ
- MapReduceз®ЛеЇПеЉАеПС
- ж®°жЭњй°єзЫЃдЄКдЉ†github
1. MavenдїЛзїН
Apache MavenпЉМжШѓдЄАдЄ™JavaзЪДй°єзЫЃзЃ°зРЖеПКиЗ™еК®жЮДеїЇеЈ•еЕЈпЉМзФ±ApacheиљѓдїґеЯЇйЗСдЉЪжЙАжПРдЊЫгАВеЯЇдЇОй°єзЫЃеѓєи±°ж®°еЮЛпЉИзЉ©еЖЩпЉЪPOMпЉЙж¶ВењµпЉМMavenеИ©зФ®дЄАдЄ™дЄ≠е§Ѓдњ°жБѓзЙЗжЦ≠иГљзЃ°зРЖдЄАдЄ™й°єзЫЃзЪДжЮДеїЇгАБжК•еСКеТМжЦЗж°£з≠Йж≠•й™§гАВжЫЊжШѓJakartaй°єзЫЃзЪДе≠Рй°єзЫЃпЉМзО∞дЄЇзЛђзЂЛApacheй°єзЫЃгАВ
mavenзЪДеЉАеПСиАЕеЬ®дїЦдїђеЉАеПСзљСзЂЩдЄКжМЗеЗЇпЉМmavenзЪДзЫЃж†ЗжШѓи¶БдљњеЊЧй°єзЫЃзЪДжЮДеїЇжЫіеК†еЃєжШУпЉМеЃГжККзЉЦиѓСгАБжЙУеМЕгАБжµЛиѓХгАБеПСеЄГз≠ЙеЉАеПСињЗз®ЛдЄ≠зЪДдЄНеРМзОѓиКВжЬЙжЬЇзЪДдЄ≤иБФдЇЖиµЈжЭ•пЉМеєґдЇІзФЯдЄАиЗізЪДгАБйЂШиі®йЗПзЪДй°єзЫЃдњ°жБѓпЉМдљњеЊЧй°єзЫЃжИРеСШиГље§ЯеПКжЧґеЬ∞еЊЧеИ∞еПНй¶ИгАВmavenжЬЙжХИеЬ∞жФѓжМБдЇЖжµЛиѓХдЉШеЕИгАБжМБзї≠йЫЖжИРпЉМдљУзО∞дЇЖйЉУеК±ж≤ЯйАЪпЉМеПКжЧґеПНй¶ИзЪДиљѓдїґеЉАеПСзРЖењµгАВе¶ВжЮЬиѓіAntзЪДе§НзФ®жШѓеїЇзЂЛеЬ®вАЭжЛЈиіЭвАУз≤ШиіівАЭзЪДеЯЇз°АдЄКзЪДпЉМйВ£дєИMavenйАЪињЗжПТдїґзЪДжЬЇеИґеЃЮзО∞дЇЖй°єзЫЃжЮДеїЇйАїиЊСзЪДзЬЯж≠£е§НзФ®гАВ
2. MavenеЃЙи£Е(win)
дЄЛиљљMavenпЉЪhttp://maven.apache.org/download.cgi
дЄЛиљљжЬАжЦ∞зЪДxxx-bin.zipжЦЗдїґпЉМеЬ®winдЄКиІ£еОЛеИ∞ D:\toolkit\maven3
еєґжККmaven/binзЫЃељХиЃЊзљЃеЬ®зОѓеҐГеПШйЗПPATHпЉЪ
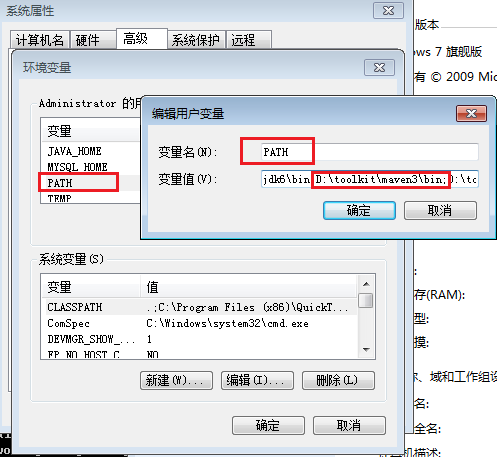
зДґеРОпЉМжЙУеЉАеСљдї§и°МиЊУеЕ•mvnпЉМжИСдїђдЉЪзЬЛеИ∞mvnеСљдї§зЪДињРи°МжХИжЮЬ
~ C:\Users\Administrator>mvn
[INFO] Scanning for projects...
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 0.086s
[INFO] Finished at: Mon Sep 30 18:26:58 CST 2013
[INFO] Final Memory: 2M/179M
[INFO] ------------------------------------------------------------------------
[ERROR] No goals have been specified for this build. You must specify a valid lifecycle phase or a goal in the format : or :[:]:. Available lifecycle phases are: validate, initialize, generate-sources, process-sources, generate-resources, process-resources, compile, process-class
es, generate-test-sources, process-test-sources, generate-test-resources, process-test-resources, test-compile, process-test-classes, test, prepare-package, package, pre-integration-test, integration-test, post-integration-test, verify, install, deploy, pre-clean, clean, post-clean, pre-site, site, post-site, site-deploy. -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/NoGoalSpecifiedException
еЃЙи£ЕEclipseзЪДMavenжПТдїґпЉЪMaven Integration for Eclipse
MavenзЪДEclipseжПТдїґйЕНзљЃ

3. HadoopеЉАеПСзОѓеҐГдїЛзїН
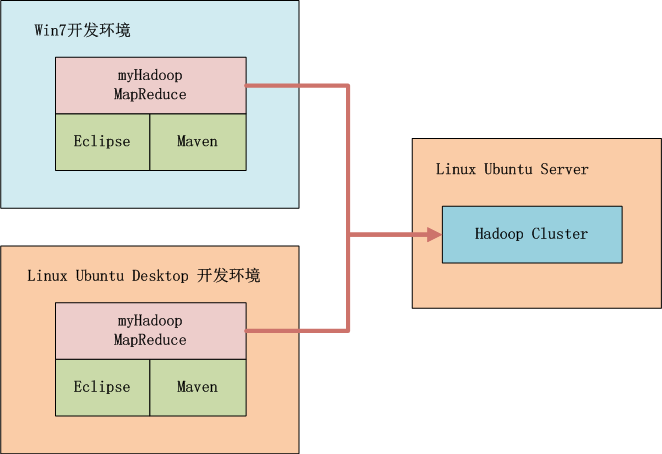
е¶ВдЄКеЫЊжЙАз§ЇпЉМжИСдїђеПѓдї•йАЙжЛ©еЬ®winдЄ≠еЉАеПСпЉМдєЯеПѓдї•еЬ®linuxдЄ≠еЉАеПСпЉМжЬђеЬ∞еРѓеК®HadoopжИЦиАЕињЬз®Ли∞ГзФ®HadoopпЉМж†ЗйЕНзЪДеЈ•еЕЈйГљжШѓMavenеТМEclipseгАВ
HadoopйЫЖзЊ§з≥їзїЯзОѓеҐГпЉЪ
- Linux: Ubuntu 12.04.2 LTS 64bit Server
- Java: 1.6.0_29
- Hadoop: hadoop-1.0.3пЉМеНХиКВзВєпЉМIP:192.168.1.210
4. зФ®MavenжЮДеїЇHadoopзОѓеҐГ
- 1. зФ®MavenеИЫеїЇдЄАдЄ™ж†ЗеЗЖеМЦзЪДJavaй°єзЫЃ
- 2. еѓЉеЕ•й°єзЫЃеИ∞eclipse
- 3. еҐЮеК†hadoopдЊЭиµЦпЉМдњЃжФєpom.xml
- 4. дЄЛиљљдЊЭиµЦ
- 5. дїОHadoopйЫЖзЊ§зОѓеҐГдЄЛиљљhadoopйЕНзљЃжЦЗдїґ
- 6. йЕНзљЃжЬђеЬ∞host
1). зФ®MavenеИЫеїЇдЄАдЄ™ж†ЗеЗЖеМЦзЪДJavaй°єзЫЃ
~ D:\workspace\java>mvn archetype:generate -DarchetypeGroupId=org.apache.maven.archetypes -DgroupId=org.conan.myhadoop.mr
-DartifactId=myHadoop -DpackageName=org.conan.myhadoop.mr -Dversion=1.0-SNAPSHOT -DinteractiveMode=false
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building Maven Stub Project (No POM) 1
[INFO] ------------------------------------------------------------------------
[INFO]
[INFO] >>> maven-archetype-plugin:2.2:generate (default-cli) @ standalone-pom >>>
[INFO]
[INFO] <<< maven-archetype-plugin:2.2:generate (default-cli) @ standalone-pom <<<
[INFO]
[INFO] --- maven-archetype-plugin:2.2:generate (default-cli) @ standalone-pom ---
[INFO] Generating project in Batch mode
[INFO] No archetype defined. Using maven-archetype-quickstart (org.apache.maven.archetypes:maven-archetype-quickstart:1.
0)
Downloading: http://repo.maven.apache.org/maven2/org/apache/maven/archetypes/maven-archetype-quickstart/1.0/maven-archet
ype-quickstart-1.0.jar
Downloaded: http://repo.maven.apache.org/maven2/org/apache/maven/archetypes/maven-archetype-quickstart/1.0/maven-archety
pe-quickstart-1.0.jar (5 KB at 4.3 KB/sec)
Downloading: http://repo.maven.apache.org/maven2/org/apache/maven/archetypes/maven-archetype-quickstart/1.0/maven-archet
ype-quickstart-1.0.pom
Downloaded: http://repo.maven.apache.org/maven2/org/apache/maven/archetypes/maven-archetype-quickstart/1.0/maven-archety
pe-quickstart-1.0.pom (703 B at 1.6 KB/sec)
[INFO] ----------------------------------------------------------------------------
[INFO] Using following parameters for creating project from Old (1.x) Archetype: maven-archetype-quickstart:1.0
[INFO] ----------------------------------------------------------------------------
[INFO] Parameter: groupId, Value: org.conan.myhadoop.mr
[INFO] Parameter: packageName, Value: org.conan.myhadoop.mr
[INFO] Parameter: package, Value: org.conan.myhadoop.mr
[INFO] Parameter: artifactId, Value: myHadoop
[INFO] Parameter: basedir, Value: D:\workspace\java
[INFO] Parameter: version, Value: 1.0-SNAPSHOT
[INFO] project created from Old (1.x) Archetype in dir: D:\workspace\java\myHadoop
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 8.896s
[INFO] Finished at: Sun Sep 29 20:57:07 CST 2013
[INFO] Final Memory: 9M/179M
[INFO] ------------------------------------------------------------------------
ињЫеЕ•й°єзЫЃпЉМжЙІи°МmvnеСљдї§
~ D:\workspace\java>cd myHadoop
~ D:\workspace\java\myHadoop>mvn clean install
[INFO]
[INFO] --- maven-jar-plugin:2.3.2:jar (default-jar) @ myHadoop ---
[INFO] Building jar: D:\workspace\java\myHadoop\target\myHadoop-1.0-SNAPSHOT.jar
[INFO]
[INFO] --- maven-install-plugin:2.3.1:install (default-install) @ myHadoop ---
[INFO] Installing D:\workspace\java\myHadoop\target\myHadoop-1.0-SNAPSHOT.jar to C:\Users\Administrator\.m2\repository\o
rg\conan\myhadoop\mr\myHadoop\1.0-SNAPSHOT\myHadoop-1.0-SNAPSHOT.jar
[INFO] Installing D:\workspace\java\myHadoop\pom.xml to C:\Users\Administrator\.m2\repository\org\conan\myhadoop\mr\myHa
doop\1.0-SNAPSHOT\myHadoop-1.0-SNAPSHOT.pom
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 4.348s
[INFO] Finished at: Sun Sep 29 20:58:43 CST 2013
[INFO] Final Memory: 11M/179M
[INFO] ------------------------------------------------------------------------
2). еѓЉеЕ•й°єзЫЃеИ∞eclipse
жИСдїђеИЫеїЇе•љдЇЖдЄАдЄ™еЯЇжЬђзЪДmavenй°єзЫЃпЉМзДґеРОеѓЉеЕ•еИ∞eclipseдЄ≠гАВ ињЩйЗМжИСдїђжЬАе•љеЈ≤еЃЙи£Ее•љдЇЖMavenзЪДжПТдїґгАВ
3). еҐЮеК†hadoopдЊЭиµЦ
ињЩйЗМжИСдљњзФ®hadoop-1.0.3зЙИжЬђпЉМдњЃжФєжЦЗдїґпЉЪpom.xml
~ vi pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.conan.myhadoop.mr</groupId>
<artifactId>myHadoop</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>myHadoop</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
4). дЄЛиљљдЊЭиµЦ
дЄЛиљљдЊЭиµЦпЉЪ
~ mvn clean installеЬ®eclipseдЄ≠еИЈжЦ∞й°єзЫЃпЉЪ
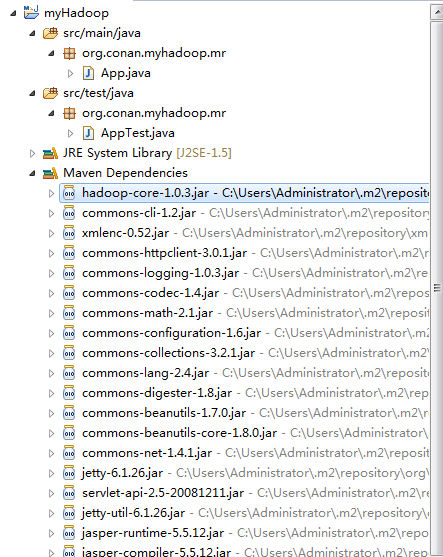
й°єзЫЃзЪДдЊЭиµЦз®ЛеЇПпЉМ襀иЗ™еК®еК†иљљзЪДеЇУиЈѓеЊДдЄЛйЭҐгАВ
5). дїОHadoopйЫЖзЊ§зОѓеҐГдЄЛиљљhadoopйЕНзљЃжЦЗдїґ
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
жЯ•зЬЛcore-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/conan/hadoop/tmp</value>
</property>
<property>
<name>io.sort.mb</name>
<value>256</value>
</property>
</configuration>
жЯ•зЬЛhdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/home/conan/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
жЯ•зЬЛmapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://master:9001</value>
</property>
</configuration>
дњЭе≠ШеЬ®src/main/resources/hadoopзЫЃељХдЄЛйЭҐ
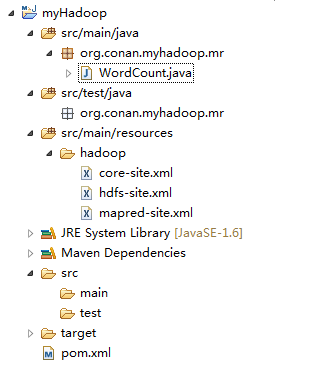
еИ†йЩ§еОЯиЗ™еК®зФЯжИРзЪДжЦЗдїґпЉЪApp.javaеТМAppTest.java
6).йЕНзљЃжЬђеЬ∞hostпЉМеҐЮеК†masterзЪДеЯЯеРНжМЗеРС
~ vi c:/Windows/System32/drivers/etc/hosts
192.168.1.210 master
6. MapReduceз®ЛеЇПеЉАеПС
зЉЦеЖЩдЄАдЄ™зЃАеНХзЪДMapReduceз®ЛеЇПпЉМеЃЮзО∞wordcountеКЯиГљгАВ
жЦ∞дЄАдЄ™JavaжЦЗдїґпЉЪWordCount.java
package org.conan.myhadoop.mr;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCount {
public static class WordCountMapper extends MapReduceBase implements Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
public static class WordCountReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterator values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
result.set(sum);
output.collect(key, result);
}
}
public static void main(String[] args) throws Exception {
String input = "hdfs://192.168.1.210:9000/user/hdfs/o_t_account";
String output = "hdfs://192.168.1.210:9000/user/hdfs/o_t_account/result";
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("WordCount");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(WordCountMapper.class);
conf.setCombinerClass(WordCountReducer.class);
conf.setReducerClass(WordCountReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
JobClient.runJob(conf);
System.exit(0);
}
}
еРѓеК®Java APP.
жОІеИґеП∞йФЩиѓѓ
2013-9-30 19:25:02 org.apache.hadoop.util.NativeCodeLoader
и≠¶еСК: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2013-9-30 19:25:02 org.apache.hadoop.security.UserGroupInformation doAs
дЄ•йЗН: PriviledgedActionException as:Administrator cause:java.io.IOException: Failed to set permissions of path: \tmp\hadoop-Administrator\mapred\staging\Administrator1702422322\.staging to 0700
Exception in thread "main" java.io.IOException: Failed to set permissions of path: \tmp\hadoop-Administrator\mapred\staging\Administrator1702422322\.staging to 0700
at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:689)
at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:662)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:509)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:344)
at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:189)
at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:116)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:856)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:850)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1121)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:850)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:824)
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1261)
at org.conan.myhadoop.mr.WordCount.main(WordCount.java:78)
ињЩдЄ™йФЩиѓѓжШѓwinдЄ≠еЉАеПСзЙєжЬЙзЪДйФЩиѓѓпЉМжЦЗдїґжЭГйЩРйЧЃйҐШпЉМеЬ®LinuxдЄЛеПѓдї•ж≠£еЄЄињРи°МгАВ
иІ£еЖ≥жЦєж≥ХжШѓпЉМдњЃжФє/hadoop-1.0.3/src/core/org/apache/hadoop/fs/FileUtil.javaжЦЗдїґ
688-692и°Мж≥®йЗКпЉМзДґеРОйЗНжЦ∞зЉЦиѓСжЇРдї£з†БпЉМйЗНжЦ∞жЙУдЄАдЄ™hadoop.jarзЪДеМЕгАВ
685 private static void checkReturnValue(boolean rv, File p,
686 FsPermission permission
687 ) throws IOException {
688 /*if (!rv) {
689 throw new IOException("Failed to set permissions of path: " + p +
690 " to " +
691 String.format("%04o", permission.toShort()));
692 }*/
693 }
жИСињЩйЗМиЗ™еЈ±жЙУдЇЖдЄАдЄ™hadoop-core-1.0.3.jarеМЕпЉМжФЊеИ∞дЇЖlibдЄЛйЭҐгАВ
жИСдїђињШи¶БжЫњжНҐmavenдЄ≠зЪДhadoopз±їеЇУгАВ
~ cp lib/hadoop-core-1.0.3.jar C:\Users\Administrator\.m2\repository\org\apache\hadoop\hadoop-core\1.0.3\hadoop-core-1.0.3.jar
еЖНжђ°еРѓеК®Java APPпЉМжОІеИґеП∞иЊУеЗЇпЉЪ
2013-9-30 19:50:49 org.apache.hadoop.util.NativeCodeLoader
и≠¶еСК: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2013-9-30 19:50:49 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
и≠¶еСК: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
2013-9-30 19:50:49 org.apache.hadoop.mapred.JobClient copyAndConfigureFiles
и≠¶еСК: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
2013-9-30 19:50:49 org.apache.hadoop.io.compress.snappy.LoadSnappy
и≠¶еСК: Snappy native library not loaded
2013-9-30 19:50:49 org.apache.hadoop.mapred.FileInputFormat listStatus
дњ°жБѓ: Total input paths to process : 4
2013-9-30 19:50:50 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
дњ°жБѓ: Running job: job_local_0001
2013-9-30 19:50:50 org.apache.hadoop.mapred.Task initialize
дњ°жБѓ: Using ResourceCalculatorPlugin : null
2013-9-30 19:50:50 org.apache.hadoop.mapred.MapTask runOldMapper
дњ°жБѓ: numReduceTasks: 1
2013-9-30 19:50:50 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
дњ°жБѓ: io.sort.mb = 100
2013-9-30 19:50:50 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
дњ°жБѓ: data buffer = 79691776/99614720
2013-9-30 19:50:50 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
дњ°жБѓ: record buffer = 262144/327680
2013-9-30 19:50:50 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
дњ°жБѓ: Starting flush of map output
2013-9-30 19:50:50 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
дњ°жБѓ: Finished spill 0
2013-9-30 19:50:50 org.apache.hadoop.mapred.Task done
дњ°жБѓ: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
2013-9-30 19:50:51 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
дњ°жБѓ: map 0% reduce 0%
2013-9-30 19:50:53 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
дњ°жБѓ: hdfs://192.168.1.210:9000/user/hdfs/o_t_account/part-m-00003:0+119
2013-9-30 19:50:53 org.apache.hadoop.mapred.Task sendDone
дњ°жБѓ: Task 'attempt_local_0001_m_000000_0' done.
2013-9-30 19:50:53 org.apache.hadoop.mapred.Task initialize
дњ°жБѓ: Using ResourceCalculatorPlugin : null
2013-9-30 19:50:53 org.apache.hadoop.mapred.MapTask runOldMapper
дњ°жБѓ: numReduceTasks: 1
2013-9-30 19:50:53 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
дњ°жБѓ: io.sort.mb = 100
2013-9-30 19:50:53 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
дњ°жБѓ: data buffer = 79691776/99614720
2013-9-30 19:50:53 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
дњ°жБѓ: record buffer = 262144/327680
2013-9-30 19:50:53 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
дњ°жБѓ: Starting flush of map output
2013-9-30 19:50:53 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
дњ°жБѓ: Finished spill 0
2013-9-30 19:50:53 org.apache.hadoop.mapred.Task done
дњ°жБѓ: Task:attempt_local_0001_m_000001_0 is done. And is in the process of commiting
2013-9-30 19:50:54 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
дњ°жБѓ: map 100% reduce 0%
2013-9-30 19:50:56 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
дњ°жБѓ: hdfs://192.168.1.210:9000/user/hdfs/o_t_account/part-m-00000:0+113
2013-9-30 19:50:56 org.apache.hadoop.mapred.Task sendDone
дњ°жБѓ: Task 'attempt_local_0001_m_000001_0' done.
2013-9-30 19:50:56 org.apache.hadoop.mapred.Task initialize
дњ°жБѓ: Using ResourceCalculatorPlugin : null
2013-9-30 19:50:56 org.apache.hadoop.mapred.MapTask runOldMapper
дњ°жБѓ: numReduceTasks: 1
2013-9-30 19:50:56 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
дњ°жБѓ: io.sort.mb = 100
2013-9-30 19:50:56 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
дњ°жБѓ: data buffer = 79691776/99614720
2013-9-30 19:50:56 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
дњ°жБѓ: record buffer = 262144/327680
2013-9-30 19:50:56 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
дњ°жБѓ: Starting flush of map output
2013-9-30 19:50:56 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
дњ°жБѓ: Finished spill 0
2013-9-30 19:50:56 org.apache.hadoop.mapred.Task done
дњ°жБѓ: Task:attempt_local_0001_m_000002_0 is done. And is in the process of commiting
2013-9-30 19:50:59 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
дњ°жБѓ: hdfs://192.168.1.210:9000/user/hdfs/o_t_account/part-m-00001:0+110
2013-9-30 19:50:59 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
дњ°жБѓ: hdfs://192.168.1.210:9000/user/hdfs/o_t_account/part-m-00001:0+110
2013-9-30 19:50:59 org.apache.hadoop.mapred.Task sendDone
дњ°жБѓ: Task 'attempt_local_0001_m_000002_0' done.
2013-9-30 19:50:59 org.apache.hadoop.mapred.Task initialize
дњ°жБѓ: Using ResourceCalculatorPlugin : null
2013-9-30 19:50:59 org.apache.hadoop.mapred.MapTask runOldMapper
дњ°жБѓ: numReduceTasks: 1
2013-9-30 19:50:59 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
дњ°жБѓ: io.sort.mb = 100
2013-9-30 19:50:59 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
дњ°жБѓ: data buffer = 79691776/99614720
2013-9-30 19:50:59 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
дњ°жБѓ: record buffer = 262144/327680
2013-9-30 19:50:59 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
дњ°жБѓ: Starting flush of map output
2013-9-30 19:50:59 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
дњ°жБѓ: Finished spill 0
2013-9-30 19:50:59 org.apache.hadoop.mapred.Task done
дњ°жБѓ: Task:attempt_local_0001_m_000003_0 is done. And is in the process of commiting
2013-9-30 19:51:02 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
дњ°жБѓ: hdfs://192.168.1.210:9000/user/hdfs/o_t_account/part-m-00002:0+79
2013-9-30 19:51:02 org.apache.hadoop.mapred.Task sendDone
дњ°жБѓ: Task 'attempt_local_0001_m_000003_0' done.
2013-9-30 19:51:02 org.apache.hadoop.mapred.Task initialize
дњ°жБѓ: Using ResourceCalculatorPlugin : null
2013-9-30 19:51:02 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
дњ°жБѓ:
2013-9-30 19:51:02 org.apache.hadoop.mapred.Merger$MergeQueue merge
дњ°жБѓ: Merging 4 sorted segments
2013-9-30 19:51:02 org.apache.hadoop.mapred.Merger$MergeQueue merge
дњ°жБѓ: Down to the last merge-pass, with 4 segments left of total size: 442 bytes
2013-9-30 19:51:02 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
дњ°жБѓ:
2013-9-30 19:51:02 org.apache.hadoop.mapred.Task done
дњ°жБѓ: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
2013-9-30 19:51:02 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
дњ°жБѓ:
2013-9-30 19:51:02 org.apache.hadoop.mapred.Task commit
дњ°жБѓ: Task attempt_local_0001_r_000000_0 is allowed to commit now
2013-9-30 19:51:02 org.apache.hadoop.mapred.FileOutputCommitter commitTask
дњ°жБѓ: Saved output of task 'attempt_local_0001_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/o_t_account/result
2013-9-30 19:51:05 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
дњ°жБѓ: reduce > reduce
2013-9-30 19:51:05 org.apache.hadoop.mapred.Task sendDone
дњ°жБѓ: Task 'attempt_local_0001_r_000000_0' done.
2013-9-30 19:51:06 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
дњ°жБѓ: map 100% reduce 100%
2013-9-30 19:51:06 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
дњ°жБѓ: Job complete: job_local_0001
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Counters: 20
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: File Input Format Counters
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Bytes Read=421
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: File Output Format Counters
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Bytes Written=348
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: FileSystemCounters
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: FILE_BYTES_READ=7377
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: HDFS_BYTES_READ=1535
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: FILE_BYTES_WRITTEN=209510
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: HDFS_BYTES_WRITTEN=348
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Map-Reduce Framework
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Map output materialized bytes=458
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Map input records=11
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Reduce shuffle bytes=0
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Spilled Records=30
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Map output bytes=509
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Total committed heap usage (bytes)=1838546944
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Map input bytes=421
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: SPLIT_RAW_BYTES=452
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Combine input records=22
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Reduce input records=15
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Reduce input groups=13
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Combine output records=15
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Reduce output records=13
2013-9-30 19:51:06 org.apache.hadoop.mapred.Counters log
дњ°жБѓ: Map output records=22
жИРеКЯињРи°МдЇЖwordcountз®ЛеЇПпЉМйАЪињЗеСљдї§жИСдїђжЯ•зЬЛиЊУеЗЇзїУжЮЬ
~ hadoop fs -ls hdfs://192.168.1.210:9000/user/hdfs/o_t_account/result
Found 2 items
-rw-r--r-- 3 Administrator supergroup 0 2013-09-30 19:51 /user/hdfs/o_t_account/result/_SUCCESS
-rw-r--r-- 3 Administrator supergroup 348 2013-09-30 19:51 /user/hdfs/o_t_account/result/part-00000
~ hadoop fs -cat hdfs://192.168.1.210:9000/user/hdfs/o_t_account/result/part-00000
1,abc@163.com,2013-04-22 1
10,ade121@sohu.com,2013-04-23 1
11,addde@sohu.com,2013-04-23 1
17:21:24.0 5
2,dedac@163.com,2013-04-22 1
20:21:39.0 6
3,qq8fed@163.com,2013-04-22 1
4,qw1@163.com,2013-04-22 1
5,af3d@163.com,2013-04-22 1
6,ab34@163.com,2013-04-22 1
7,q8d1@gmail.com,2013-04-23 1
8,conan@gmail.com,2013-04-23 1
9,adeg@sohu.com,2013-04-23 1
ињЩж†ЈпЉМжИСдїђе∞±еЃЮзО∞дЇЖеЬ®win7дЄ≠зЪДеЉАеПСпЉМйАЪињЗMavenжЮДеїЇHadoopдЊЭиµЦзОѓеҐГпЉМеЬ®EclipseдЄ≠еЉАеПСMapReduceзЪДз®ЛеЇПпЉМзДґеРОињРи°МJavaAPPгАВHadoopеЇФзФ®дЉЪиЗ™еК®жККжИСдїђзЪДMRз®ЛеЇПжЙУжИРjarеМЕпЉМеЖНдЄКдЉ†зЪДињЬз®ЛзЪДhadoopзОѓеҐГдЄ≠ињРи°МпЉМињФеЫЮжЧ•ењЧеЬ®EclipseжОІеИґеП∞иЊУеЗЇгАВ
7. ж®°жЭњй°єзЫЃдЄКдЉ†github
https://github.com/bsspirit/maven_hadoop_template
е§ІеЃґеПѓдї•дЄЛиљљињЩдЄ™й°єзЫЃпЉМеБЪдЄЇеЉАеПСзЪДиµЈзВєгАВ
~ git clone https://github.com/bsspirit/maven_hadoop_template.git
жИСдїђеЃМжИРзђђдЄАж≠•пЉМдЄЛйЭҐе∞±е∞Жж≠£еЉПињЫеЕ•MapReduceеЉАеПСеЃЮиЈµгАВ
 
иљђиљљиѓЈж≥®жШОеЗЇе§ДпЉЪ
http://blog.fens.me/hadoop-maven-eclipse/
 



зЫЄеЕ≥жО®иНР
жЬђжЦЗе∞Жиѓ¶зїЖдїЛзїНе¶ВдљХдљњзФ®EclipseеТМMavenжЮДеїЇHadoopй°єзЫЃгАВ дЄАгАБMavenдїЛзїН MavenжШѓдЄАдЄ™й°єзЫЃзЃ°зРЖеЈ•еЕЈпЉМеПѓдї•еѓєJavaй°єзЫЃињЫи°МжЮДеїЇгАБдЊЭиµЦзЃ°зРЖгАВMavenеЯЇдЇОй°єзЫЃеѓєи±°ж®°еЮЛпЉИProject Object ModelпЉМPOMпЉЙж¶ВењµпЉМдљњзФ®дЄАдЄ™дЄ≠е§Ѓдњ°жБѓ...
гАРж†ЗйҐШгАС"winдЄЛmavenеИЫеїЇзЪДhadoopз®ЛеЇПdemo"жґЙеПКдЇЖе§ЪдЄ™ITйҐЖеЯЯзЪДзЯ•иѓЖзВєпЉМеМЕжЛђWindowsжУНдљЬз≥їзїЯгАБMavenжЮДеїЇеЈ•еЕЈгАБ...ињЩдЄ™ж°ИдЊЛжЧ®еЬ®еЄЃеК©еЉАеПСиАЕдЇЖиІ£еТМжОМжП°еЬ®WindowsдЄКдљњзФ®MavenжЮДеїЇHadoop MapReduceз®ЛеЇПзЪДеЯЇжЬђж≠•й™§еТМжЦєж≥ХгАВ
### дљњзФ®MavenзЉЦиѓСHadoop 2.7.1 зЪДиѓ¶зїЖж≠•й™§еПКж≥®жДПдЇЛй°є #### дЄАгАБзЉЦиѓСеЙНзЪДеЗЖе§З **1.1 дЄЛиљљеєґиІ£еОЛHadoopжЇРз†БеМЕ** ж†єжНЃдљЬиАЕgyqiangзЪДиѓіжШОпЉМи¶БзЉЦиѓСзЪДжШѓApache Hadoop 2.7.1зЙИжЬђпЉМиѓ•зЙИжЬђеПСеЄГдЇО2016еєі1жЬИ4жЧ•пЉМжШѓељУжЧґ...
зїЉеРИдЄКињ∞жКАжЬѓпЉМжЮДеїЇHadoopеИЖеЄГеЉПдЇСзЫШз≥їзїЯдЄНдїЕйЬАи¶БзРЖиІ£еРДдЄ™зїДдїґзЪДеЈ•дљЬеОЯзРЖпЉМињШйЬАи¶БжОМжП°еЃГдїђдєЛйЧіе¶ВдљХеНПеРМеЈ•дљЬгАВжЬђеЯєиЃ≠й°єзЫЃе∞ЖйАЪињЗеЃЮйЩЕжР≠еїЇеТМжµЛиѓХHadoopзОѓеҐГпЉМдљње≠¶еСШиГље§ЯдЇ≤жЙЛеЃЮжЦљжѓПдЄАдЄ™ж≠•й™§пЉМдїОеЃЙи£ЕйЕНзљЃеИ∞дЉШеМЦзїіжК§пЉМз°ЃдњЭ...
6. **ињРи°МдЄОи∞ГиѓХ**пЉЪдљњзФ®MavenжЮДеїЇй°єзЫЃеРОпЉМеПѓдї•йАЪињЗEclipseзЪД`Run As`иПЬеНХйАЙжЛ©`Hadoop Job`жЭ•ињРи°МHadoopз®ЛеЇПгАВеЬ®и∞ГиѓХжЧґпЉМеПѓдї•иЃЊзљЃжЦ≠зВєеєґдљњзФ®`Debug As`йАЙй°єињЫи°Ми∞ГиѓХгАВ 7. **hadoop01**пЉЪињЩеПѓиГљжШѓз§ЇдЊЛдї£з†БдЄ≠еМЕеРЂзЪДдЄА...
Hadoop Maven RepositoryжШѓдЄАдЄ™йЗНи¶БзЪДеЈ•еЕЈпЉМеЃГжШѓJavaеЉАеПСдЇЇеСШеЬ®жЮДеїЇHadoopзЫЄеЕ≥й°єзЫЃжЧґдљњзФ®зЪДиµДжЇРеЇУгАВMavenжШѓдЄАдЄ™й°єзЫЃзЃ°зРЖеТМзїЉеРИеЈ•еЕЈпЉМеЃГеЄЃеК©еЉАеПСиАЕзЃ°зРЖй°єзЫЃзЪДжЮДеїЇгАБжК•еСКеТМжЦЗж°£з≠ЙзФЯеСљеС®жЬЯињЗз®ЛгАВиАМHadoop Maven ...
иАМMavenжШѓJavaй°єзЫЃзЃ°зРЖеЈ•еЕЈпЉМиГље§ЯеЄЃеК©еЉАеПСиАЕзЃ°зРЖеТМжЮДеїЇй°єзЫЃпЉМеМЕжЛђе§ДзРЖдЊЭиµЦеЕ≥з≥їгАВжЬђиѓЭйҐШе∞Жиѓ¶зїЖжОҐиЃ®еЬ®MavenдїУеЇУдЄ≠еЕ≥дЇОHadoopдї•еПКдЄОHadoopзЫЄеЕ≥зЪДHiveдЊЭиµЦгАВ HadoopзЪДж†ЄењГзїДдїґеМЕжЛђHDFSпЉИHadoop Distributed File System...
ињЩжШѓдЄАдЄ™еЯЇдЇОJavaжКАжЬѓж†ИпЉМеИ©зФ®SpringMVCгАБSpringгАБHBaseеТМMavenжЮДеїЇзЪДHadoopеИЖеЄГеЉПдЇСзЫШз≥їзїЯзЪДй°єзЫЃгАВиѓ•й°єзЫЃжЧ®еЬ®еЃЮзО∞дЄАдЄ™йЂШжХИзЪДгАБеПѓжЙ©е±ХзЪДдЇСе≠ШеВ®иІ£еЖ≥жЦєж°ИпЉМеИ©зФ®HadoopзЪДеИЖеЄГеЉПзЙєжАІжЭ•е§ДзРЖе§ІиІДж®°жХ∞жНЃе≠ШеВ®йЬАж±ВгАВ й¶ЦеЕИпЉМ...
MavenжШѓдЄАдЄ™й°єзЫЃзЃ°зРЖеТМзїЉеРИеЈ•еЕЈпЉМеЃГзЃАеМЦдЇЖJavaй°єзЫЃзЪДжЮДеїЇгАБдЊЭиµЦзЃ°зРЖеТМжЦЗж°£зФЯжИРињЗз®ЛгАВHadoopеИЩжШѓдЄАдЄ™еИЖеЄГеЉПиЃ°зЃЧж°ЖжЮґпЉМзФ®дЇОе§ДзРЖеТМе≠ШеВ®е§ІиІДж®°жХ∞жНЃгАВйАЪињЗMavenпЉМжИСдїђеПѓдї•жЦєдЊњеЬ∞зЃ°зРЖHadoopзЫЄеЕ≥еЇУзЪДдЊЭиµЦпЉМдљњеЊЧеЉАеПСеТМжµЛиѓХ...
ељУдљ†йЬАи¶БеѓєHadoopжЇРз†БињЫи°МзЉЦиѓСжЧґпЉМMavenжШѓењЕдЄНеПѓе∞СзЪДеЈ•еЕЈпЉМеЫ†дЄЇеЃГеПѓдї•еЄЃеК©жИСдїђиЗ™еК®еМЦжЮДеїЇињЗз®ЛпЉМзЃ°зРЖй°єзЫЃзЪДдЊЭиµЦеЕ≥з≥їпЉМдї•еПКжЙІи°МеРДзІНжЮДеїЇзФЯеСљеС®жЬЯйШґжЃµгАВ зЉЦиѓСHadoopжЇРз†БзЪДињЗз®ЛжґЙеПКеИ∞дї•дЄЛеЗ†дЄ™еЕ≥йФЃзЯ•иѓЖзВєпЉЪ 1. **Maven...
жЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®е¶ВдљХеЬ®WindowsзОѓеҐГдЄЛпЉМдљњзФ®EclipseгАБMavenдї•еПКHadoopжЭ•еЃЮзО∞дЄАдЄ™еЯЇз°АзЪДWordCountз®ЛеЇПгАВWordCountжШѓHadoopзЪДзїПеЕЄз§ЇдЊЛпЉМзФ®дЇОзїЯиЃ°жЦЗжЬђдЄ≠еРДдЄ™еНХиѓНеЗЇзО∞зЪДжђ°жХ∞пЉМеЃГжШѓзРЖиІ£MapReduceзЉЦз®Лж®°еЮЛзЪДдЄАдЄ™иЙѓе•љиµЈзВєгАВ ...
- **жЮДеїЇHadoop**пЉЪеЬ®Hadoopй°єзЫЃж†єзЫЃељХдЄЛињРи°М`mvn clean install`пЉМMavenдЉЪиЗ™еК®дЄЛиљљжЙАйЬАдЊЭиµЦпЉМзЉЦиѓСжЇРдї£з†БпЉМзФЯжИРjarеМЕгАВ 4. **дљњзФ®MavenињЫи°МHadoopеЉАеПС** - **еИЫеїЇжЦ∞й°єзЫЃ**пЉЪдљњзФ®`mvn archetype:generate`еИЫеїЇдЄАдЄ™...
еЕґдЄ≠`lzo-2.06.tar.gz`жПРдЊЫдЇЖLZOеОЛзЉ©еЇУпЉМ`hadoop-lzo-master.zip`еМЕеРЂдЇЖеЬ®HadoopдЄКдљњзФ®LZOзЪДдї£з†БпЉМиАМ`apache-maven-3.3.9-bin.tar.gz`еИЩжШѓзФ®дЇОжЮДеїЇеТМзЃ°зРЖжХідЄ™й°єзЫЃзЪДеЈ•еЕЈгАВеѓєдЇОйЬАи¶Бе§ДзРЖе§ІйЗПжХ∞жНЃеєґдЉШеМЦжАІиГљзЪДеЉАеПСиАЕжЭ•...
йАЪињЗMavenпЉМеЉАеПСиАЕеПѓдї•иљїжЭЊеЬ∞зЃ°зРЖеТМжЮДеїЇHadoopй°єзЫЃпЉМеЫ†дЄЇеЃГиГљиЗ™еК®дЄЛиљљжЙАйЬАзЪДдЊЭиµЦеЇУпЉМеєґжМЙзЕІзЙєеЃЪзЪДзФЯеСљеС®жЬЯжЭ•зЉЦиѓСгАБжµЛиѓХеТМжЙУеМЕдї£з†БгАВ WordCountз®ЛеЇПжШѓHadoop MapReduceзЪДеЕ•йЧ®з§ЇдЊЛпЉМеЃГзФ±дЄ§дЄ™йШґжЃµзїДжИРпЉЪMapйШґжЃµеТМ...
еЬ®жЬђй°єзЫЃдЄ≠пЉМжИСдїђзїУеРИдЇЖSpringMVCгАБHadoopеТМMavenињЩдЄЙдЄ™жКАжЬѓпЉМжЮДеїЇдЇЖдЄАдЄ™иГље§ЯеЃЮзО∞жЦЗдїґдїОWebзЂѓдЄКдЉ†еИ∞HDFSпЉИHadoop Distributed File SystemпЉЙзЪДз≥їзїЯгАВдЄЛйЭҐе∞Жиѓ¶зїЖйШРињ∞ињЩдЄЙдЄ™жКАжЬѓеПКеЕґеЬ®й°єзЫЃдЄ≠зЪДеЇФзФ®гАВ й¶ЦеЕИпЉМSpringMVC...
MavenжШѓдЄАдЄ™й°єзЫЃзЃ°зРЖеТМиЗ™еК®еМЦжЮДеїЇеЈ•еЕЈпЉМеЃГдљњзФ®дЄАдЄ™дЄ≠е§Ѓдњ°жБѓзЃ°зРЖзЪДжЦєеЉПжЭ•зЃ°зРЖеТМжЮДеїЇй°єзЫЃгАВйАЪињЗMavenпЉМеПѓдї•еѓєй°єзЫЃзЪДжЮДеїЇгАБжЦЗж°£зФЯжИРгАБжК•еСКгАБдЊЭиµЦгАБSCMsгАБеПСеЄГгАБеИЖеПСз≠ЙињЫи°МзЃ°зРЖгАВеЬ®жЬђй°єзЫЃдЄ≠пЉМMavenдљЬдЄЇжЮДеїЇеЈ•еЕЈпЉМиіЯиі£...
еЬ®жЬђдЄїйҐШдЄ≠пЉМжИСдїђе∞ЖжЈ±еЕ•жОҐиЃ®е¶ВдљХдљњзФ®...5. дљњзФ®MavenжЮДеїЇзЫЃж†ЗзЉЦиѓСй°єзЫЃгАВ ињЩдЄ™ињЗз®ЛеѓєдЇОзРЖиІ£HadoopзЪДеЖЕйГ®еЈ•дљЬеОЯзРЖгАБи∞ГиѓХжИЦеЃЪеИґHadoopеКЯиГљйЭЮеЄЄжЬЙзФ®гАВеРМжЧґпЉМзЖЯзїГжОМжП°ињЩдЄАжµБз®ЛдєЯе∞ЖжПРеНЗдљ†еЬ®JavaеТМе§ІжХ∞жНЃеЉАеПСйҐЖеЯЯзЪДжКАиГљгАВ