
大家都知道,目前BT应用的发展具有一个非常显著的趋势,那就是用来交换电影、游戏、ISO等大尺寸的数据文件。然而我们也能够观察到另一个事实,那就是:下载文件所对应的索引文件(.torrent)也越来越大,越来越难以下载;这是因为在索引文件中保存了被下载文件中所有数据块的20字节SHA1校验值,而文件越大,数据块越多,则.torrent文件越长(块数=文件长度/数据块长,Bit Torrent标准协议建议块长一般不超过512KB)。
索引文件长度的膨胀将直接加重索引服务器的下载负担,因为所有BT用户均必须从服务器上下载同一份.torrent文件,而这一下载行为本身是集中式的,因而导致系统的扩展性受到较大限制,尤其是用于交换热门资源时;另一方面,为避免索引文件过大,人们在发布种子、制作索引文件时不得不采用增加其基本数据块长度(比如2MB)的方式来减少数据块总数,这将有可能对端对端数据交换性能造成一系列负面影响:因为块长越小,越能帮助我们及时地发现传输错误,试想在2MB块长的情况下,用户直到下载完整个数据块时才通过校验发现传输有误,然后不得不再次重传整个2MB块,这显然较块长为512KB时更加浪费带宽和时间。归根到底,导致上述麻烦的根本原因在于这么一个事实:“.torrent中包含了所有数据块的SHA1校验信息”。
有什么办法让我们既能获得较小的块长而又能减少索引文件长度?Merkle哈希树校验方式为我们提供了一个很好的思路,它试图从校验信息获取及实际校验过程两个方面来改善上述问题。先说说什么是哈希树,以最简单的二叉方式为例,如下图所示,设某文件共13个数据块,我们可以将其padding到16(2的整数次方)个块(注意,padding的空白块仅用于辅助校验,而无需当作数据进行实际传输),每个块均对应一个SHA1校验值,然后再对它们进行反复的两两哈希,直到得出一个唯一的根哈希值为止(root hash, H0),这一计算过程便构成了一棵二元的Merkle哈希树,树中最底层的叶子节点(H15~H30)对应着数据块的实际哈希值,而那些内部节点(H1~H14)我们则可以将其称为“路径哈希值”,它们构成了实际块哈希值与根哈希值H0之间的“校验路径”,比如,数据块8所对应的实际哈希值为H23,则有:SHA1(((SHA1(SHA1(H23,H24),H12),H6),H1)应该等于H0。当然,我们也可以进一步采用n元哈希树来进行上述校验过程,其过程是类似的。
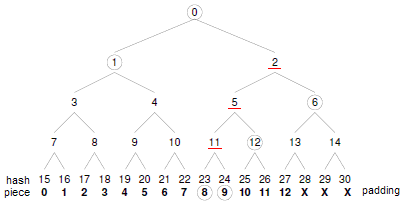
采用Merkle哈希树校验方式能够极大地减小.torrent文件的尺寸,这是因为,一旦采用这种方式来校验数据块,那么便没有必要在.torrent文件中保存所有数据块的校验值了,其中仅需保存一个20字节的SHA1哈希值即可,即整个下载文件的根哈希值H0。想象一下一个3、4GB的文件,其对应.torrent文件却只有100-200字节的样子?heh
下面,让我们来看看其数据块交换及校验的详细过程:
- 以下载某大文件F为例,为启动BT交换,每一个client均必须从索引服务器中下载F所相应的.torrent文件,从而得到文件长度、数据块长及根哈希值H0等必要信息;
- 任一client均可通过轮询Tracking服务器或者是DHT方式来定位其他参与交换F数据的peer,进而与之建立TCP连接进行P2P文件交换,其定位peer的方式基本上没有什么改变。
- 当client从某一peer下载一个数据块时,它将事先向peer发出相应的校验查询请求,要求对方提供校验当前下载块所需的路径哈希值,这一过程可以很方便地通过扩展标准的Peer Wire Protocol实现。以上图为例,当client下载的是数据块8时,在下载开始之前,它将要求peer提供校验块8所需的全部路径哈希值:H24、H12、H6和H1;
- 当client下载完某数据块之后,它将对其进行哈希树校验;仍以校验块8为例,client将首先计算出块8的哈希值H23',然后再根据peer所提供的信息依次计算各层路径哈希值,直至求得一个唯一的根校验值H0',如果H0'等于.torrent文件中的H0,则数据块下载无误,校验通过;反之则校验失败。
- 一旦某数据块校验通过,与其哈希树校验过程相关的所有路径哈希值均可以作为cache缓存下来,而不管其究竟是从peer查询所得的,还是由client自身计算所得的;但值得注意的是,如果该数据块的校验未通过,则其所有相关的路径哈希值均不能被cache,而只能被废弃,因为此时我们无法保证peer所提供的路径哈希值的正确性(不能排除peer故意提供错误路径哈希值和哈希值传输出错的可能)。例如,所有与块8校验相关的路径哈希包括:H24、H12、H6、H1、H11、H5、H2,其中前面4个经查询peer所得,而后面3个则由client自己计算所得。块8验证的结果将决定这7个路径哈希是否可信及是否能被cache。
- 当一定数量的路径哈希值被缓存之后,后继数据块的校验过程将被极大简化。此时我们可以直接利用校验路径上层次最低的已知路径哈希值来对数据块进行部分校验,而无需每次都校验至根哈希值H0,这主要是因为:某一路径哈希值被cache这一事实本身便能够证明其是可信的;例如,在块8校验完成之后,client无需进行额外的peer查询便可以直接对块9进行校验,因此它已经知道了H24的值,并且通过块8的校验过程验证了H24的正确性;而当client需要对块10进行校验时,它仅需向peer查询H26一个校验值即可,由于我们已经知道了H12值,因此对块10的校验仅需2次SHA1哈希即可:一次是计算块哈希H25,一次是计算SHA1(H25,H26),并比较其等不等于H12。同理,当需要验证块12时,由于已知H6,client仅需查询2个路径哈希(H28和H14)和3次SHA1计算(H27、SHA1(H27,H28)和SHA1(H13,H14))即可。缓存的路径哈希值越多,则后继数据块校验越容易,速度也越快。
- 为了进一步提高校验效率,可以考虑在.torrent文件上再做做文章:令其保存整个哈希树中最上面的若干层路径哈希值,而不仅仅只是一个根哈希值H0,底层的路径哈希值则仍然依靠询问peer或client自身计算所得,从而实现.torrent文件尺寸与校验效率的有效折衷。
最后再来看看上述算法的时空效率如何。假设某文件的总块数为M,将其padding至N个块(N=2^p),块长为K,不难看出:
- 为了校验整个文件,共需缓存Sum(2^i):i=0 to p,即2N-1个20字节的SHA1哈希值(包括根哈希值、所有路径哈希值和块哈希值)。以512KB为块长的一个4GB的文件为例,M=8000,则N=8192,p=13,所需存储空间为(2*8192-1)*20=327660 Bytes=319KB,其缓冲区较普通校验方式翻倍,但即便如此,校验所需的数据量仍完全可以接受,即使在最糟糕的情况下:完全不用cache、全部依赖peer查询来获得这些校验值,也无非总共增加了1个基本块不到的流量而已,而且这些流量还是通过P2P方式得到的。
- 在无校验失败的理想情况下,校验整个文件共需M次块长为K的SHA1计算,和N-1次长度为20字节的SHA1运算。即,以哈希树方式校验块长512KB的4GB文件,共需进行8000次长度为512KB的SHA1计算,同时外加8191次长为2*20字节的路径哈希计算,与普通校验方式相比,后者是哈希树额外引入的开销,但由于每次路径哈希的计算量非常小,其影响几可忽略。
综上所述,通过采用哈希树校验方式,我们可以将诸多校验所需哈希值的获取工作分散在P2P数据交换时捎带进行,而不是从.torrent文件中集中获取,从而有利于缓解索引服务器集中下载瓶颈,优化Peer to Peer数据传输性能;在实现上述目的的同时,哈希树校验机制仍能保证以P2P方式获取的校验信息的可靠性,在小块长的情况下,恶意peer几乎无法通过故意提供错误路径哈希值的方式来实现有效的服务拒绝攻击。采用这种方式,我们所需付出的额外代价主要包括几近1倍的校验缓存空间及其SHA1计算量的增长,但是经过简要分析不难看出其实际影响不甚明显,这对于换取较小的块长、提高大文件P2P交换效率而言是值得的。Merkle哈希树校验方式与分布式哈希表技术势必能够帮助BitTorrent协议进一步克服自身的非结构化缺陷,取得更大的应用发展。



相关推荐
- **Merkle Tree**:用于验证数据完整性的哈希树结构,使得文件的校验更加高效,尤其是在有部分文件更新的情况下。 - **Piece-based Downloading**:将大文件分割成多个小块,用户可以并行下载不同块,提高了下载...
3. **文件分块**:在BitTorrent中,大文件被分割成多个小的数据块,通常每个块大小为16KB或更小。这种分块方式允许文件下载和上传并行进行,提高了下载速度。 4. **哈希校验**:每个数据块都有一个唯一的SHA1哈希值...
5. **哈希校验**:每个文件块都有一个唯一的哈希值,确保数据在传输过程中不被篡改。下载完成后,所有块的哈希值会与原始种子文件进行比较,以验证文件完整性。 在 Python 源码包中,我们可以期待看到以下组件: 1...
2. 文件分块:BitTorrent将大型文件拆分成许多小块,每个块都有唯一的哈希值用于验证数据完整性。下载时,用户可以并行下载这些块,加快了整体下载速度。 3. Tracker服务器通信:Tracker服务器是BitTorrent网络中的...
BitTorrent核心算法研究与改进,
4. **Piece下载与验证**:文件被分割成固定大小的块(Pieces),客户端并行下载这些块,然后使用校验和验证数据的完整性。源码将详细展示如何管理这些Piece,确保正确无误地组装成原始文件。 5. ** choking 和 ...
2. **元数据文件(.torrent)**:包含有关要下载的文件的信息,如文件名、大小、校验和以及Tracker服务器的地址。 3. **碎片下载**:文件被分割成多个小块,允许同时从多个来源下载,提高速度。 4. **片块交换**:每...
4. **哈希表和块校验**:每个数据块都有一个独特的哈希值,用于验证数据完整性。源代码中会包含计算和验证哈希的算法。 5. **片块请求和交换**:客户端根据需要请求特定的文件块,并可能与其他客户端交换这些块。源...
在BitTorrent协议中,客户端之间需要交换数据块以完成文件的下载和上传,这就需要使用Socket进行数据传输。 在实现BitTorrent客户端时,关键的组件包括: 1. **Tracker**:客户端首先会连接到Tracker服务器,获取...
BitTorrent磁力链接生成器从种子哈希中生成磁力链接。 这样,您就不必依赖笨拙的torrent网站来下载您的torrent。 只需放入torrent哈希,即可开始使用。 不要忘记在您的BitTorrent客户端中启用DHT以获得更多的对等方...
BitTorrent中的“阻塞”是指节点拒绝向其他节点传输数据,而“非阻塞”则表示允许数据传输。系统通过调整阻塞状态来控制上传资源的分配。Tit-for-tat(TFT)阻塞算法是BitTorrent的基础,它选择当前上传速度最快的几...
客户端软件支持搜索 torrent 文件(.torrent 文件是BitTorrent网络中的元数据文件,包含有关如何下载文件的信息),连接到 tracker(跟踪服务器),并管理与其他 peers(对等节点)的连接。 Tracker是BitTorrent...
2. **文件分割**:在BitTorrent中,原始文件首先被分割成多个小块(称为“块”或“piece”),每个块都有一个唯一的哈希值作为标识。这样做的目的是为了提高文件传输的效率和可靠性。 3. **跟踪器(Tracker)**:在...
1. **协议规范**:详细描述BitTorrent协议的各个部分,如BEP(BitTorrent扩展协议)文档,解释了如何进行握手、交换块、交换元数据以及使用扩展协议进行更高效的数据传输。 2. **设计原理**:解释BitTorrent如何...
2. **Bencoding**:BitTorrent 使用 Bencoding 进行数据编码,这是一种类似于 JSON 的二进制编码方式,用于存储元数据如.torrent 文件。Bencoding 包含字典、列表、整数和字符串四种数据类型,是解析 .torrent 文件...