经过几天的测试,hadoop分布式系统搭建完毕。首先说一下这几天对hadoop理论知识的理解,然后说一下安装及碰到的问题。
第一:理论知识:
什么是hadoop:
由三部分组成:HDFS,MapReduce和Hbase。
维基百科这样说:一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。这里面关键就是高速运算和海量存储。我们首先讲海量存储,这个比较有意思,一会儿再说高速运算。
海量存储: HDFS<Hadoop Distributed File System>
前身来自google的一篇博文,所以自身带有浓厚的互联网色彩,比如读多于写的特性,高度的扩展性。 具体说一下他的特性:
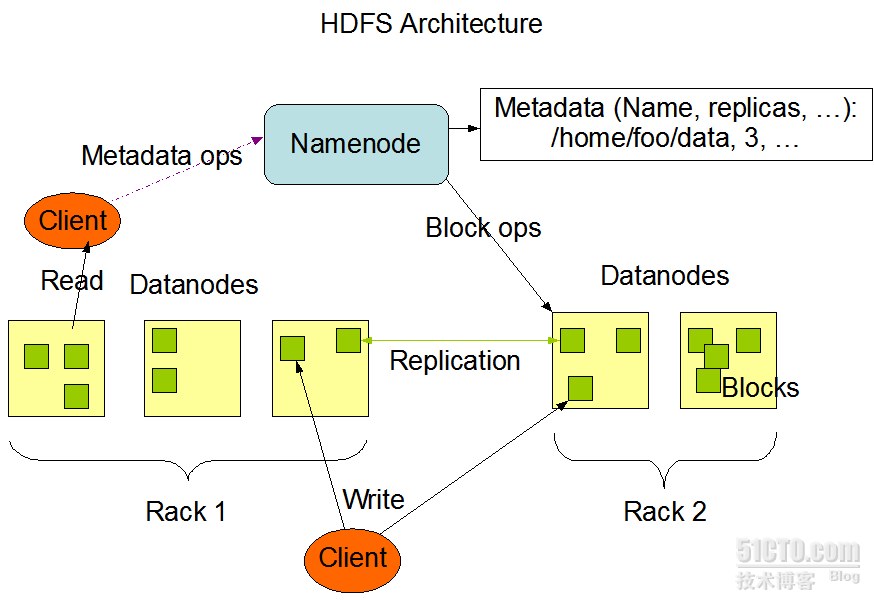
图1:HDFS结构示意图
<抄自 岑文初>
上图中展现了整个HDFS三个重要角色:NameNode、DataNode和Client。NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。Client就是需要获取分布式文件系统文件的应用程序。这里通过三个操作来说明他们之间的交互关系。
文件写入:
-
Client向NameNode发起文件写入的请求。
-
NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
-
Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
文件读取:
-
Client向NameNode发起文件读取的请求。
-
NameNode返回文件存储的DataNode的信息。
-
Client读取文件信息。
文件Block复制:
-
NameNode发现部分文件的Block不符合最小复制数或者部分DataNode失效。
-
通知DataNode相互复制Block。
-
DataNode开始直接相互复制。
HDFS的几个设计特点:
-
Block的放置:默认不配置。一个Block会有三份备份,一份放在NameNode指定的DataNode,另一份放在与指定 DataNode非同一Rack上的DataNode,最后一份放在与指定DataNode同一Rack上的DataNode上。备份无非就是为了数据安全,考虑同一Rack的失败情况以及不同Rack之间数据拷贝性能问题就采用这种配置方式。
-
心跳检测DataNode的健康状况,如果发现问题就采取数据备份的方式来保证数据的安全性。
-
数据复制(场景为DataNode失败、需要平衡DataNode的存储利用率和需要平衡DataNode数据交互压力等情况):这里先说一下,使用HDFS的balancer命令,可以配置一个Threshold来平衡每一个DataNode磁盘利用率。例如设置了Threshold为 10%,那么执行balancer命令的时候,首先统计所有DataNode的磁盘利用率的均值,然后判断如果某一个DataNode的磁盘利用率超过这个均值Threshold以上,那么将会把这个DataNode的block转移到磁盘利用率低的DataNode,这对于新节点的加入来说十分有用。
-
数据交验:采用CRC32作数据交验。在文件Block写入的时候除了写入数据还会写入交验信息,在读取的时候需要交验后再读入。
-
NameNode是单点:如果失败的话,任务处理信息将会纪录在本地文件系统和远端的文件系统中。
-
数据管道性的写入:当客户端要写入文件到DataNode上,首先客户端读取一个Block然后写到第一个DataNode上,然后由第一个DataNode传递到备份的DataNode上,一直到所有需要写入这个Block的NataNode都成功写入,客户端才会继续开始写下一个 Block。
-
安全模式:在分布式文件系统启动的时候,开始的时候会有安全模式,当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。运行期通过命令也可以进入安全模式。在实践过程中,系统启动的时候去修改和删除文件也会有安全模式不允许修改的出错提示,只需要等待一会儿即可。
下面说高速计算:
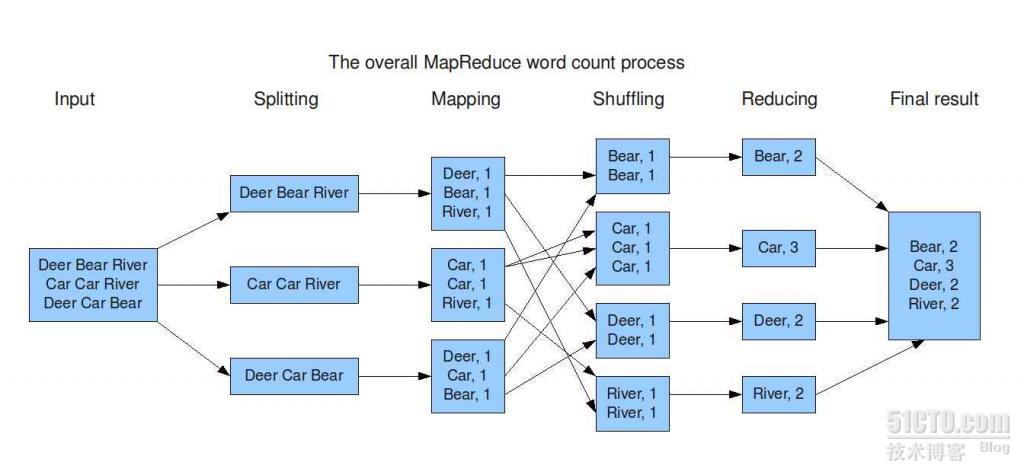
上面的图片是计算这个文件中每个单词出现的次数,这个任务被分裂成三个子任务,然后映射到集群中JobTracker指定的TaskTracker上运行子任务,每个子任务都可以在指定的TaskTracker上运行,然后把运行的结果保存在当地,然后reduce程序被调用。然后进行的是结果的整合,整合完毕,就是最终结果了。这是计算向数据靠拢的计算方式。
好了,我们开始说安装,好多都在讲0.17和0.18的安装,hadoop这玩意儿因为最近很火,所以变动很厉害,变动的速度估计和nginx有一拼,所以在安装的时候得批判的继承他们安装过程。
环境:
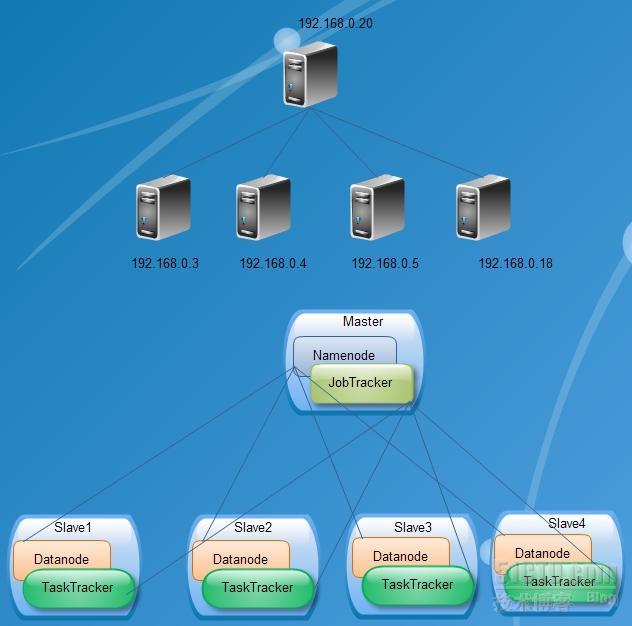
首先:在这几台机器上安装CentOS5.4(最简化安装)并升级完毕。

保证计算机名的全局唯一性:
hadoop1.diarc.com.cn-----192.168.0.3
hadoop2.diarc.com.cn-----192.168.0.4
hadoop3.diarc.com.cn-----192.168.0.5
hadoop4.diarc.com.cn-----192.168.0.18
hadoop5.diarc.com.cn-----192.168.0.20
修改方式:(5台服务器都设置)
[root@hadoop5 ~]# hostname hadoop5.diarc.com.cn
[root@hadoop5 ~]# cat /etc/hosts
# Do not remove the following line, or various programs
# that require network functionality will fail.
127.0.0.1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
192.168.0.20 hadoop5.diarc.com.cn hadoop5
[root@hadoop5 ~]# cat /etc/sysconfig/network
NETWORKING=yes
NETWORKING_IPV6=no
HOSTNAME=hadoop5.diarc.com.cn
GATEWAY=192.168.0.1
[root@hadoop5 ~]#
为了方便,关闭防火墙:(5台服务器都设置)
[root@hadoop5 ~]# service iptables stop
[root@hadoop5 ~]# chkconfig iptables off
方便起见,创建hadoop用户
[root@hadoop5 ~]# useradd hadoop
全部放入/home/hadoop目录。
[root@hadoop5 ~]# cp jdk-6u19-linux-i586.bin /usr/local/
[root@hadoop5 ~]# cd /usr/local/
[root@hadoop5 ~]# ./jdk-6u19-linux-i586.bin
[root@hadoop5 ~]# rm -rf jdk-6u19-linux-i586.bin
[root@hadoop5 ~]# cd /home/hadoop/
[root@hadoop5 hadoop]# tar zxvf hadoop-0.20.2.tar.gz
[root@hadoop5 ~]# cat /etc/profile ##放入如下信息
export JAVA_HOME=/usr/local/jdk1.6.0_19
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin:$PATH
export HADOOP_HOME=/home/hadoop/hadoop-0.20.2
export PATH=$PATH:$HADOOP_HOME/bin
然后执行如下命令:
[root@hadoop5 ~]# source /etc/profile
现在我们修改hadoop的配置文件:0.20以上的配置和以前的配置有些是不同的,我们以0.20.2为例做东西
[root@hadoop5 conf]# cat core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.0.20:54310/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp/</value>
</property>
</configuration>
===========================================================================
[root@hadoop5 conf]# echo "export JAVA_HOME=/usr/local/jdk1.6.0_19" >> hadoop-env.sh
===========================================================================
[root@hadoop5 conf]# cat hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
===========================================================================
[root@hadoop5 conf]# cat mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://192.168.0.20:54311/</value>
</property>
</configuration>
[root@hadoop5 conf]#
===========================================================================
[root@hadoop5 conf]# cat masters
192.168.0.20
[root@hadoop5 conf]# cat slaves
192.168.0.3
192.168.0.4
192.168.0.5
192.168.0.18
[root@hadoop5 conf]#
==========================================================================
现在我们做无密码的ssh登录:
建立Master到每一台Slave的SSH受信证书。由于Master将会通过SSH启动所有Slave的Hadoop,所以需要建立单向或者双向证书保证命令执行时不需要再输入密码。在Master和所有的Slave机器上执行:ssh-keygen -t rsa。执行此命令的时候,看到提示只需要回车。然后就会在/root/.ssh/下面产生id_rsa.pub的证书文件,通过scp将Master机器上的这个文件拷贝到Slave上(记得修改名称),例如:scp root@masterIP:/root/.ssh/id_rsa.pub /root/.ssh/46_rsa.pub,然后执行cat /root/.ssh/46_rsa.pub >>/root/.ssh/authorized_keys,建立authorized_keys文件即可,可以打开这个文件看看,也就是rsa的公钥作为key,user@IP作为value。此时可以试验一下,从master ssh到slave已经不需要密码了。由slave反向建立也是同样。为什么要反向呢?其实如果一直都是Master启动和关闭的话那么没有必要建立反向,只是如果想在Slave也可以关闭Hadoop就需要建立反向。
然后每台服务器上都修改ssh的配置文件:/etc/ssh/sshd_config 把GSSAPIAuthentication的值设置为no,然后:
[root@hadoop5 conf]# service sshd restart
[root@hadoop5 conf]#
我们从master向slave依次登录
然后压缩hadoop文件夹成为一个压缩包
[root@hadoop5 hadoop]# tar zcvf hadoop-0.20.2.tar.gz hadoop-0.20.2
然后在每台slave上执行如下命令
好,我们现在可以在master上执行如下命令:
[root@hadoop5 hadoop]# hadoop namenode -format
[root@hadoop5 hadoop]# cd /home/hadoop/hadoop-0.20.2/bin/
[root@hadoop5 bin]# ./start-all.sh
分享到:





相关推荐
hadoop原理浅析及安装.doc
理解MapReduce的工作原理对于开发和优化大数据处理应用至关重要,这也是Hadoop生态系统中的核心技能之一。通过持续学习和实践,开发者可以更好地利用MapReduce解决实际问题,驾驭海量数据的挑战。
【Hadoop环境搭建与WordCount实例浅析】 Hadoop是一个分布式计算框架,广泛应用于大数据处理。要搭建Hadoop环境并实现WordCount实例,你需要遵循以下步骤: 1. **环境准备**: - 首先,你需要一个Linux操作系统...
### Hadoop+HDFS和MapReduce架构浅析 #### 摘要 本文旨在深入剖析Hadoop中的两大核心组件——HDFS(Hadoop Distributed File System)和MapReduce的工作原理及其实现机制。首先,我们将介绍Hadoop NameNode与...
- `get /path`:获取指定节点的数据及元数据。 - `set /path data`:设置指定节点的数据。 - `create /path data`:创建指定节点,并设置初始数据。 - `delete /path`:删除指定节点。 #### ZooKeeper在Hadoop中的...
这篇博客将对 WordCount 的源码进行初步解析,帮助初学者理解 Hadoop MapReduce 的工作原理。 首先,我们要明白 WordCount 的基本流程。它分为两个主要阶段:Map 阶段和 Reduce 阶段。Map 阶段的任务是对输入数据...
在Hadoop分布式文件系统(HDFS)的性能评估中,有几个经典的压测工具,如Terasort、Slive和DFSIO,它们对理解HDFS的工作原理和优化至关重要。这些工具不仅帮助开发者了解系统的吞吐率,还能揭示不同组件的性能瓶颈。 ...
在大数据处理领域,Apache Hadoop的MapReduce框架是...实际上,这只是冰山一角,更深入的学习还包括理解HDFS的工作原理、容错机制、优化策略等。在实际项目中,熟练掌握MapReduce能够有效处理海量数据,解决复杂问题。
在处理海量图片时,常用的分布式存储系统有Hadoop HDFS(Hadoop Distributed File System)和Ceph等。HDFS设计目标是处理PB级别的数据,适合批量处理,而Ceph则更注重实时性,能提供对象存储、块存储和文件系统的...
### 云计算核心技术及其产业化浅析 #### 一、云计算的概念与发展背景 云计算作为一种新兴的商业计算模型,其概念源于分布式计算、并行处理、网格计算等技术领域的发展。这一概念的提出,旨在解决信息技术领域中...
除了基础算法和优化策略,本文还提到了将Apriori算法应用于Hadoop体系的实践,从而在大数据环境下实现算法的进一步优化。通过分布式计算框架,Apriori算法能够在处理大规模数据集时更加高效。 综上所述,关联规则...
3. 机器学习与深度学习:统计学与机器学习的交叉领域,如贝叶斯网络、深度学习模型,将统计学原理与强大的计算能力结合,提升预测精度。 4. 可解释性:在AI领域,统计模型的可解释性是关键。未来的研究将致力于构建...
首先,"ETL应用浅析.doc"文档很可能是对ETL技术的详细解析,包括ETL的工作原理、主要步骤、工具选择以及在实际项目中的应用场景。在ETL过程中,提取(Extract)阶段是从数据库、日志文件或其他数据源获取原始数据;...