С║їТЅІС╣дтИѓтю║Тў»ућ▒СИцСИфТѕфуёХСИЇтљїуџётИѓтю║у╗ёТѕљ№╝їСИђжЃетѕєТў»ТЋЎуДЉС╣д№╝їТаАтЏГС║цТўЊТў»У┐ЎСИфтИѓтю║уџёТаИт┐Ѓ№╝їтЁиТюЅУХЁт╝║уџёТхЂтіеТђД№╝їтЋєтЊЂуДЇу▒╗уЏИт»╣УЙЃт░Љ№╝їС╣░т«ХтњїтЇќт«ХтцџтдѓуЅЏТ»Џ№╝їт«╣ТўЊС╗ЦтљѕжђѓуџёС╗иТа╝С╣░тѕ░СИГТёЈуџёС║ДтЊЂ№╝їСйєт░▒тГўУ┤ДС╝џтЏаСИ║уЅѕТюгуџёТЏ┤Тќ░УђїУбФТИЁТ┤ЌСИђТгАсђѓСИђжЃетѕєТў»жЮътГдТю»ућеС╣д№╝їТхЂтіеТђДУЙЃти«№╝їтЋєтЊЂуДЇу▒╗тЙѕтцџ№╝їС╣░т«ХтњїтЇќт«ХТЋ░жЄЈСИЇУХ│№╝їТЅЙтѕ░тљѕТёЈС║ДтЊЂуџёТдѓујЄтЙѕт░Јсђѓ
Alibrisт░▒Тў»СИђСИфжЋ┐т░ЙжЏєтљѕтЎе№╝їт░єСИіСИЄт«ХС║їТЅІС╣дт║ЌуџёУЌЈС╣дУ┐ъСИ║СИђСйЊ№╝їућеС┐АТЂ»уџётіЏжЄЈтюеСИђСИфтјЪТюгу╝║С╣ЈТхЂтіеТђДуџётИѓтю║СИГтѕЏжђаСИђСИфТхЂтіеТђДуџётИѓтю║сђѓжЏєтљѕтЎетЇ░У»ЂС║єжЋ┐т░ЙуџёуггС║їтцДтіЏжЄЈРђћРђћТЎ«тЈіС╝аТњГтиЦтЁисђѓ
тЋєСИџжЏєтљѕтЎеСИ╗УдЂтѕєСИ║С║ћтцДу▒╗№╝џ
- ТюЅтйбС║ДтЊЂ(тдѓС║џжЕгжђі№╝їeBay)
- ТЋ░тГЌС║ДтЊЂ(тдѓiTunes, iFilm)
- т╣┐тЉі/ТюЇтіА(тдѓgoogle, Craigslist)
- С┐АТЂ»(тдѓgoogle, у╗┤тЪ║уЎЙуДЉ)
- уйЉСИіуцЙтї║/ућеТѕиУЄфтѕЏтєЁт«╣(тдѓMySpace, Bloglines)
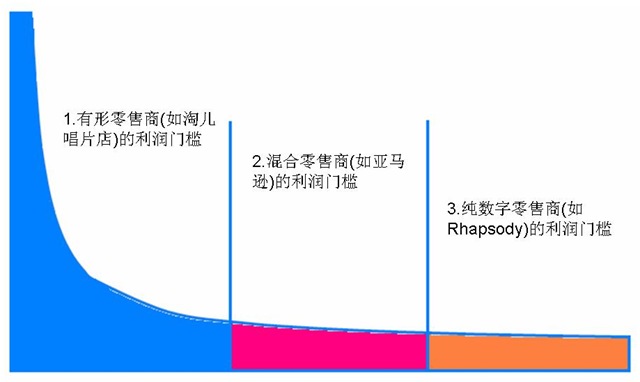
уггСИђу▒╗С╝ЂСИџуД░СИ║ТиитљѕжЏХтћ«тЋє№╝їТў»жѓ«У┤Гу╗ЈТхјтГдтњїуйЉу╗юу╗ЈТхјтГдуџёТиитљѕСйЊ№╝їС║ДтЊЂТў»жђџУ┐Єжѓ«т»ёТѕќУЂћжѓдт┐ФжђњУ┐љжђЂуџё№╝їтЁХТЋѕујЄСИђТќ╣жЮбућежЏєСИГтїќС╗ЊтѓеТќ╣Т│ЋжЎЇСйјСЙЏт║ћжЊЙТѕљТюг№╝їСИђТќ╣жЮбтѕЕућеуйЉуФЎуџёТљюу┤бтіЪУЃйтњїтЁХС╗ќС┐АТЂ»С╝ўті┐ТЈљСЙЏТЌажЎљуџёС║ДтЊЂжђЅТІЕсђѓ
С║џжЕгжђіуџёCDу╗ЈУљЦТеАт╝ЈУ┐юУЃюС║јСИђУѕгуџётћ▒уЅЄт║Ќ№╝їТ▓┐уЮђжЪ│С╣љжЋ┐т░ЙтЅЇУ┐Џ1/4уџёУи»уеІ№╝їСйєт╣ХТ▓АТюЅУ┐ЏУАїтѕ░т║Ћ№╝їтЏаСИ║Т»ЈСИђт╝аCDжЃйТюЅтГўУ┤ДжБјжЎЕ№╝їТ»ЈСИђТгАжћђтћ«жЃйТюЅУ┐љУЙЊТѕљТюг№╝їСИђт╝аCDСИіуџёТГїТЏ▓СИЇУЃйтЇЋуІгтЄ║тћ«№╝їжћђтћ«уџёCDСИЇтїЁТІгCDТЌХС╗БС╣ІтЅЇуџёжЪ│С╣љти▓у╗ЈС╗јТюфтЈЉУАїУ┐ЄуџёУйдт║ЊС╣љжўЪуџёжЪ│С╣љсђѓ
УдЂТЃ│СИђУи»Ух░тѕ░жЋ┐т░ЙС╣ІТюФ№╝їтћ»СИђуџёТќ╣т╝Јт░▒Тў»ТіЏт╝Ѓ"тјЪтГљ"№╝їт░єТЅђТюЅуџёС║цТўЊжЃйт╗║уФІтюе"тГЌУіѓ"уџётЪ║уАђСИісђѓ
уггС║їуДЇуД░СИ║у║»ТЋ░тГЌжЏХтћ«тЋє№╝їтЁХС║ДтЊЂтЄаС╣јТ▓АТюЅС╗╗СйЋуџётГўтѓеТѕљТюг№╝їС╝аУЙЊТѕљТюгт░▒Тў»т«йтИдтГЌУіѓ№╝їС║ДтЊЂтЈ»С╗ЦуІгуФІтЄ║тћ«сђѓ

┬а
ТиитљѕжЏХтћ«тЋєС║џжЕгжђітдѓСйЋт╝ђТІЊжЋ┐т░Й№╝Ъ
ждќтЁѕ№╝їтюеу║┐тјѓтЋєТЌбтЈ»С╗ЦТІЦТюЅжѓ«У┤ГтЋєт«ХуџёжЏєСИГтїќжЁЇжђЂ№╝їС╣ЪТІЦТюЅуЏ«тйЋжЏХтћ«тЋєуџёуЏ┤жћђС╝ўті┐сђѓ
тЁХТгА№╝їу╗Ду╗ГжЎЇСйјтЁгтЈИуџётГўУ┤ДжБјжЎЕ№╝їСИЇтєЇТ»ФТЌат┐ЁУдЂуџёСИ║тГўтюеУЄфт«ХС╗Њт║ЊСИГуџёС║ДтЊЂС╗ўтЄ║ТѕљТюгсђѓС║џжЕгжђіућет»ётћ«тиЦуеІ№╝їСИђСИфСйюУђЁТћ»С╗ў29.95уЙјтЁЃуџёт╣┤У┤╣№╝їТііС╣дт»ётѕ░С║џжЕгжђі№╝їтдѓТъюС╣дтЇќТјЅС║є№╝їт░єУјитЙЌ45%уџёжћђтћ«жбЮсђѓУ┐ЎТаиТЌбтЈ»С╗ЦуА«С┐ЮСИђСИфСйюУђЁуџёС╣дтЈ»С╗ЦУй╗ТЮЙтЈ»тЙЌ№╝їС╣ЪтЈ»С╗Цућет╣┤У┤╣ТЮЦт╝ЦУАЦСИђСИІтГўУ┤ДТѕљТюгсђѓ
уггСИЅ№╝їт░єУЎџТІЪтГўУ┤ДТеАт╝ЈтіаС╗ЦТЅЕт▒Ћ№╝їт╝ЋтЁЦтЁХС╗ќтцДжЏХтћ«тЋє№╝їтѕЕућеС╗ќС╗гСИјућЪС║ДтЋєтњїтѕєжћђтЋєуџёуј░ТюЅтЁ│у│╗сђѓС║џжЕгжђітѕЕућетИѓжЏєтиЦуеІ№╝їСИ║тцДтцДт░Јт░ЈуџётЋєт«ХТЈљСЙЏТюЇтіА№╝їС╗╗СйЋуџёжЏХтћ«тЋєтњїтѕєжћђтЋєжЃйтЈ»С╗ЦТііУЄфти▒уџёС║ДтЊЂтѕЌтюеС║џжЕгжђіСИі№╝їС║јС║џжЕгжђіУЄфт«ХС╗Њт║ЊСИГуџётГўУ┤ДТ▓АТюЅСИцТаи№╝їУђїСИћжАЙт«бС╗гУ┤ГС╣░У┐ЎС║ЏС║ДтЊЂСИјУ┤ГС╣░С║џжЕгжђіуџёС║ДтЊЂтљїТаиУй╗ТЮЙсђѓУ┐ЎТаитЁежЃетГўУ┤ДжБјжЎЕжЃйУйгтФЂу╗ЎС║єуггСИЅТќ╣тЇќт«Хсђѓ
уггтЏЏ№╝їтЇ│жюђтЇ│тЇ░сђѓтюеуљєТЃ│тїќТЃЁтєхСИІ№╝їСИђТюгС╣дтюетЄ║тћ«С╣ІтЅЇСИђуЏ┤тЈфТў»ТЋ░тГЌТќЄС╗Х№╝їСИђТЌдТюЅС║║У«бУ┤Г№╝їТ┐ђтЁЅТЅЊтЇ░Тю║жЕгСИіТЅЊтЇ░тЄ║ТЮЦсђѓТюђтѕЮС║џжЕгжђітюеС╗Њт║ЊжЄїТюЅУЄфти▒уџётиЦСИџТЅЊтЇ░Тю║№╝їжџЈтљјТћХУ┤ГС║єтЇ│жюђтЇ│тЇ░уџёС╝ЂСИџBookSurgeсђѓСйєТў»уј░тюеСИђуЏ┤тЈЌТіђТю»тњїу╗ЈТхјСИіуџёжЎљтѕХ№╝їтїЁТІгТѕљТюгУЙЃжФў№╝їуЅѕт╝Јтњїу║Ит╝аСИЇтї╣жЁЇ№╝їуЅѕТЮЃжЌ«жбўуГЅсђѓ
жЎЇСйјТѕљТюгуџёу╗ѕТъЂТќ╣Т│Ћт░▒Тў»т«їтЁеТХѕуЂГтјЪтГљ№╝їућетГЌУіѓтцёуљєСИђтѕЄсђѓу║»ТЋ░тГЌжЏєтљѕтЎеС╝ЂСИџтЈфжюђТііС║ДтЊЂтГўтѓетюеуАгуЏўСИі№╝їжђџУ┐Єт«йтИдУ┐љжђЂт«ЃС╗гсђѓућЪС║Д№╝їтГўтѓе№╝їжћђтћ«ТѕљТюгТјЦУ┐ЉС║јжЏХ№╝їтЇ│жюђтЇ│тѕХсђѓ

- тцДт░Ј: 33.9 KB
тѕєС║Фтѕ░№╝џ






{kind=link}
уЏИтЁ│ТјеУЇљ
### сђіУиЪТѕЉтГдSEOС╗јтЁЦжЌетѕ░у▓Йжђџ-т╝аТќ░ТўЪсђІу▓ЙтЇјУ»╗С╣дугћУ«░уггтЇЂСИђуФа #### 11.2 тЂџуйЉуФЎуџётЄєтцЄтиЦСйютњїт╗║У«ЙтєЁт«╣ - **жђЅТІЕуєЪТѓЅжбєтЪЪ**№╝џжђЅТІЕУЄфти▒уєЪТѓЅуџёУАїСИџТЮЦтѕЏт╗║уйЉуФЎ№╝їУ┐ЎТюЅтіЕС║јТЏ┤тЦйтю░уљєУДБуЏ«ТаЄтЈЌС╝ЌуџёжюђТ▒ѓ№╝їт╣ХУЃйтцЪТЈљСЙЏТЏ┤жФўУ┤ежЄЈуџё...
### 2021-2025т╣┤СИГтЏйWi-Fi 6УАїСИџУ░ЃуаћтЈітѕЕтЪ║тИѓтю║ТѕўуЋЦтњеУ»бТіЦтЉі #### уггСИђжЃетѕє№╝џWi-Fi 6ТіђТю»у╗╝У┐░ **Wi-Fi 6ТдѓУ┐░** Wi-Fi 6№╝ѕС╣ЪуД░СИ║802.11ax№╝ЅТў»СИђжА╣ТюђТќ░уџёWi-FiТаЄтЄє№╝їТЌетюеТЈљжФўуйЉу╗юТЋѕујЄтњїжђЪт║д№╝їуЅ╣тѕФТў»тюет»єжЏєуј»тбЃСИГуџё...
жЊЁугћтц┤У»єтѕФТЋ░ТЇ«жЏє№╝ї1692т╝атјЪтДІУ«Гу╗ЃтЏЙ№╝ї640*640тѕєУЙеујЄ№╝ї91.1%уџёТГБуА«У»єтѕФујЄ№╝їТаЄТ│еТћ»ТїЂcoco jsonТа╝т╝Ј
жФўТаАуйЉу╗юТЋЎтГдуџёСйЊу│╗УДётѕњСИјтѕЏт╗║.docx
SpringBootуџётГдућЪт┐ЃуљєтњеУ»бУ»ёС╝░у│╗у╗Ъ№╝їСйауюІУ┐Ўу»Єт░▒тцЪС║є(жЎёТ║љуаЂ)
тєЁт«╣ТдѓУдЂ№╝џТюгТќЄУ»ду╗єС╗Іу╗ЇС║єтдѓСйЋСй┐ућежЂЌС╝ау«ЌТ│ЋС╝ўтїќBPуЦъу╗ЈуйЉу╗ю№╝їС╗ЦТЈљжФўС║цжђџТхЂжЄЈжбёТхІуџётЄєуА«ТђДсђѓТќЄСИГждќтЁѕУДБжЄіС║єBPуЦъу╗ЈуйЉу╗юуџётЪ║Тюгу╗ЊТъётЈітЁХт▒ђжЎљТђД№╝їтЇ│т«╣ТўЊжЎитЁЦт▒ђжЃеТюђС╝ўУДБуџёжЌ«жбўсђѓжџЈтљј№╝їСйюУђЁт▒Ћуц║С║єжЂЌС╝ау«ЌТ│ЋуџётиЦСйютјЪуљє№╝їт╣Хт░єтЁХт║ћућеС║јС╝ўтїќBPуЦъу╗ЈуйЉу╗юуџёТЮЃжЄЇтњїтЂЈуй«сђѓжђџУ┐Єт«џС╣Ѕжђѓт║ћт║дтЄйТЋ░сђЂжђЅТІЕсђЂС║цтЈЅтњїтЈўт╝ѓуГЅТГЦжфц№╝їт«ъуј░С║єт»╣BPуЦъу╗ЈуйЉу╗юуџёТюЅТЋѕТћ╣У┐Џсђѓт«ъжфїу╗ЊТъюТўЙуц║№╝їС╝ўтїќтљјуџёBPуЦъу╗ЈуйЉу╗ютюеС║цжђџТхЂжЄЈжбёТхІСИГуџёу▓Йт║дТўЙУЉЌжФўС║јС╝ау╗ЪуџёBPуЦъу╗ЈуйЉу╗ю№╝їуЅ╣тѕФТў»тюетцёуљєтцЇТЮѓуџёжЮъу║┐ТђДжЌ«жбўТЌХУАеуј░тЄ║УЅ▓сђѓ жђѓућеС║║уЙц№╝џт»╣Тю║тЎетГдС╣асђЂТи▒т║дтГдС╣аС╗ЦтЈіС║цжђџТхЂжЄЈжбёТхІТёЪтЁ┤УХБуџёуДЉуаћС║║тЉўтњїТіђТю»т╝ђтЈЉУђЁсђѓ Сй┐ућетю║ТЎ»тЈіуЏ«ТаЄ№╝џжђѓућеС║јжюђУдЂУ┐ЏУАїу▓ЙуА«С║цжђџТхЂжЄЈжбёТхІуџёт║ћућетю║ТЎ»№╝їтдѓТЎ║УЃйС║цжђџу│╗у╗ЪсђЂтЪјтИѓУДётѕњуГЅжбєтЪЪсђѓСИ╗УдЂуЏ«ТаЄТў»жђџУ┐ЄжЂЌС╝ау«ЌТ│ЋС╝ўтїќBPуЦъу╗ЈуйЉу╗ю№╝їУДБтє│тЁХТўЊжЎитЁЦт▒ђжЃеТюђС╝ўуџёжЌ«жбў№╝їС╗јУђїТЈљжФўжбёТхІу▓Йт║дтњїуе│т«џТђДсђѓ тЁХС╗ќУ»┤Тўј№╝џТќЄСИГТЈљСЙЏС║єУ»ду╗єуџёPythonС╗БуаЂт«ъуј░№╝їтИ«тіЕУ»╗УђЁТЏ┤тЦйтю░уљєУДБтњїт«ъУихУ┐ЎСИђС╝ўтїќТќ╣Т│ЋсђѓтљїТЌХ№╝їт╝║У░ЃС║єжЂЌС╝ау«ЌТ│ЋтюетЁет▒ђТљюу┤бТќ╣жЮбуџёС╝ўті┐№╝їС╗ЦтЈітЁХСИјBPуЦъу╗ЈуйЉу╗юу╗ЊтљѕТЅђтИдТЮЦуџёТђДУЃйТЈљтЇЄсђѓТГцтцќ№╝їУ┐ўУ«еУ«║С║єСИђС║ЏтЁиСйЊуџёт«ъТќйТіђтиД№╝їтдѓжђѓт║ћт║дтЄйТЋ░уџёУ«ЙУ«АсђЂС║цтЈЅтњїтЈўт╝ѓТЊЇСйюуџёжђЅТІЕуГЅсђѓ ТаЄуГЙ1,ТаЄуГЙ2,ТаЄуГЙ3,ТаЄуГЙ4,ТаЄуГЙ5
тєЁт«╣ТдѓУдЂ№╝џТюгТќЄУ»ду╗єС╗Іу╗ЇС║єH5UТАєТъХтюеPLCСИјУДдТЉИт▒ЈжЏєТѕљТќ╣жЮбуџёт║ћуће№╝їуЅ╣тѕФТў»тюеТђ╗у║┐С╝║ТюЇТјДтѕХтњїУиет╣│тЈ░уД╗ТцЇТќ╣жЮбсђѓТќЄуФаждќтЁѕУДБТъљС║єС╝║ТюЇТјДтѕХуџёТаИт┐ЃС╗БуаЂ№╝їтдѓСй┐УЃйТеАтЮЌтњїу╗Ют»╣т«џСйЇТїЄС╗ц№╝їт╝║У░ЃС║єТаЄтЄєтїќТјДтѕХТхЂуеІуџёС╝ўті┐сђѓТјЦуЮђУ«еУ«║С║єУДдТЉИт▒ЈС║цС║њ№╝їжђџУ┐ЄуЏ┤ТјЦТўат░ёPLCуџёDBтЮЌтю░тЮђу«ђтїќС║єТЋ░ТЇ«тцёуљєсђѓуёХтљјС╗Іу╗ЇС║єТђ╗у║┐жЁЇуй«№╝їт░цтЁХТў»EtherCATТђ╗у║┐тѕЮтДІтїќтЈітЁХт«╣жћЎУ«ЙУ«АсђѓТГцтцќ№╝їТќЄуФаУ┐ўТјбУ«еС║єТАєТъХуџёуД╗ТцЇТђДтњїТіЦУГдтцёуљєУ«ЙУ«А№╝їт▒Ћуц║С║єтЁХтюеСИЇтљїPLCтЊЂуЅїжЌ┤уџёТўЊућеТђДтњїжФўТЋѕуџёТЋЁжџюТЂбтцЇУЃйтіЏсђѓ жђѓтљѕС║║уЙц№╝џС╗јС║ІтиЦСИџУЄфтіетїќжбєтЪЪуџётиЦуеІтИѕтњїТіђТю»С║║тЉў№╝їуЅ╣тѕФТў»ТюЅPLCу╝ќуеІу╗ЈжфїтњїжюђУдЂУ┐ЏУАїС╝║ТюЇТјДтѕХу│╗у╗Ът╝ђтЈЉуџёС║║уЙцсђѓ Сй┐ућетю║ТЎ»тЈіуЏ«ТаЄ№╝џРЉат┐ФжђЪТљГт╗║тњїУ░ЃУ»ЋтЪ║С║јPLCтњїУДдТЉИт▒ЈуџёУЄфтіетїќТјДтѕХу│╗у╗Ъ№╝ЏРЉАТЈљжФўтцџУй┤У«ЙтцЄуџёУ░ЃУ»ЋТЋѕујЄ№╝ЏРЉбт«ъуј░Уиет╣│тЈ░уџёТЌау╝ЮуД╗ТцЇ№╝ЏРЉБС╝ўтїќТіЦУГду«АуљєтњїТЋЁжџюТЂбтцЇТю║тѕХсђѓ тЁХС╗ќУ»┤Тўј№╝џУ»ЦТАєТъХСИЇС╗ЁТЈљСЙЏС║єУ»ду╗єуџёС╗БуаЂуц║СЙІтњїТ│ежЄі№╝їУ┐ўтїЁтљФС║єСИ░т»їуџёт«ъТѕўу╗ЈжфїтњїТюђСй│т«ъУих№╝їСй┐тЙЌТќ░ТЅІУЃйтцЪт┐ФжђЪСИіТЅІ№╝їУђїУхёТи▒тиЦуеІтИѕтЈ»С╗ЦтюеТГцтЪ║уАђСИіУ┐ЏСИђТГЦтѕЏТќ░сђѓ
тєЁт«╣ТдѓУдЂ№╝џТюгТќЄТАБсђіUE5т╝ђтЈЉ.txtсђІтЁежЮбС╗Іу╗ЇС║єUnreal Engine 5№╝ѕUE5№╝ЅуџётЪ║ТюгТдѓт┐хсђЂт«ЅУБЁжЁЇуй«сђЂжА╣уЏ«тѕЏт╗║сђЂТќЄС╗Ху╗ЊТъётЈітИИућетіЪУЃйсђѓUE5Тў»СИђТгЙт╝║тцДуџёТИИТѕЈт╝ЋТЊј№╝їТћ»ТїЂт«ъТЌХТИ▓ТЪЊсђЂУЊЮтЏЙтѕЏСйюсђЂC++у╝ќуеІуГЅтіЪУЃйсђѓТќЄТАБУ»ду╗єТЈЈУ┐░С║єUE5уџёт«ЅУБЁТГЦжфц№╝їтїЁТІгуАгС╗ХУдЂТ▒ѓтњїуј»тбЃжЁЇуй«№╝ЏжА╣уЏ«тѕЏт╗║У┐ЄуеІ№╝їТХхуЏќжА╣уЏ«ТеАТЮ┐жђЅТІЕсђЂУ┤ежЄЈжбёУ«ЙсђЂтЁЅу║┐У┐йУИфуГЅУ«Йуй«№╝ЏТќЄС╗Ху╗ЊТъёУДБТъљ№╝їжЄЇуѓ╣С╗Іу╗ЇС║єConfigсђЂContentтњї.uprojectТќЄС╗ХуџёжЄЇУдЂТђДсђѓТГцтцќ№╝їТќЄТАБТи▒тЁЦУ«▓УДБС║єУЊЮтЏЙу╝ќУЙЉтЎеуџёСй┐уће№╝їтїЁТІгтЈўжЄЈсђЂТЋ░у╗ёсђЂжЏєтљѕсђЂтГЌтЁИуГЅТЋ░ТЇ«у▒╗тъІуџёТЊЇСйю№╝їС╗ЦтЈіС║ІС╗ХсђЂтЄйТЋ░сђЂт«ЈтњїС║ІС╗ХтѕєтЈЉтЎеуџёт║ћућесђѓУЊЮтЏЙСйюСИ║СИђуДЇтЈ»УДєтїќУёџТюгтиЦтЁи№╝їСй┐т╝ђтЈЉУђЁТЌажюђу╝ќтєЎC++С╗БуаЂтЇ│тЈ»т┐ФжђЪтѕЏт╗║жђ╗УЙЉ№╝їжђѓућеС║јт┐ФжђЪт╝ђтЈЉтњїУ┐ГС╗Бсђѓ жђѓтљѕС║║уЙц№╝џтЁитцЄСИђт«џу╝ќуеІтЪ║уАђуџёТИИТѕЈт╝ђтЈЉУђЁсђЂУ«ЙУ«АтИѕтњїт»╣ТИИТѕЈт╝ђтЈЉТёЪтЁ┤УХБуџётѕЮтГдУђЁ№╝їт░цтЁХТў»тИїТюЏТи▒тЁЦС║єУДБUE5т╝ЋТЊјтЈітЁХУЊЮтЏЙу│╗
жцљждєуѓ╣УЈюу│╗у╗ЪТдѓУдЂУ«ЙУ«АУ»┤ТўјС╣д.doc
5+1ТАБУй┐УйдТЅІтіетЈўжђЪу«▒У«ЙУ«АУ»┤ТўјС╣д.doc
1СИЄтљеУЄфТЮЦТ░┤тјѓУ»ду╗єУ«ЙУ«АУ»┤ТўјС╣д.doc
wordpressтцќУ┤ИућхтЋєС╝ЂСИџС║ДтЊЂСИ╗жбў жАхжЮбт▒Ћуц║тЏЙhttps://i-blink.csdnimg.cn/direct/e45b2e2e8e27423eb79bda5f4c1216d7.png
СйјТЋѕТъЌТћ╣жђаСйюСИџУ«ЙУ«АУ»┤ТўјС╣д.doc
УЦ┐жЌетГљ200smartу╝ќуеІУй»С╗ХV2.8.2.1
135У░ЃжђЪтЎеТЊЇу║хТЅІТЪё У«ЙУ«АУ»┤ТўјС╣д.doc
тєЁт«╣ТдѓУдЂ№╝џТюгТќЄТАБСИ║УЊЮТАЦТЮ»тЁетЏйУй»С╗ХтњїС┐АТЂ»ТіђТю»СИЊСИџС║║ТЅЇуФъУхЏТЈљСЙЏС║єтЁежЮбуџёТїЄт»╝№╝їТХхуЏќуФъУхЏТдѓУ┐░сђЂТхЂуеІСИјУДётѕЎсђЂТаИт┐ЃУђЃуѓ╣СИјтцЄУхЏуГќуЋЦсђЂт«ъТѕўТіђтиДСИјжЂ┐тЮЉТїЄтЇЌС╗ЦтЈітцЄУхЏУхёТ║љТјеУЇљсђѓУЊЮТАЦТЮ»уФъУхЏућ▒тиЦС┐АжЃеС║║ТЅЇС║цТхЂСИГт┐ЃСИ╗тіъ№╝їТХЅтЈіу«ЌТ│ЋУ«ЙУ«АсђЂУй»С╗Хт╝ђтЈЉсђЂтхїтЁЦт╝Ју│╗у╗ЪсђЂућхтГљУ«ЙУ«АуГЅжбєтЪЪсђѓТќЄТАБУ»ду╗єС╗Іу╗ЇС║єтЈѓУхЏТхЂуеІ№╝ѕТіЦтљЇсђЂуюЂУхЏсђЂтЏйУхЏсђЂтЏйжЎЁУхЏ№╝Ѕ№╝їт╣Хжњѕт»╣Уй»С╗Ху▒╗тњїућхтГљу▒╗уФъУхЏтѕєтѕФжўљУ┐░С║єжФўжбЉУђЃуѓ╣тњїтцЄУхЏт╗║У««сђѓт»╣С║јУй»С╗Ху▒╗№╝їт╝║У░ЃС║єу«ЌТ│ЋСИјТЋ░ТЇ«у╗ЊТъёуџёжЄЇУдЂТђД№╝їтдѓТјњт║ЈсђЂтіеТђЂУДётѕњсђЂтЏЙУ«║уГЅ№╝Џт»╣С║јућхтГљу▒╗№╝їтѕЎСЙДжЄЇС║јуАгС╗ХтЪ║уАђтњїт╝ђтЈЉтиЦтЁиуџёСй┐ућесђѓТГцтцќ№╝їУ┐ўТЈљСЙЏС║єУ»ду╗єуџёуГћжбўуГќуЋЦсђЂтИИУДЂжЎижў▒УДёжЂ┐Тќ╣Т│ЋтЈітиЦтЁиУ░ЃУ»ЋТіђтиДсђѓ; жђѓтљѕС║║уЙц№╝џжФўТаАТюгСИЊуДЉућЪсђЂуаћуЕХућЪ№╝їт░цтЁХТў»т»╣у«ЌТ│ЋУ«ЙУ«АсђЂУй»С╗Хт╝ђтЈЉсђЂтхїтЁЦт╝Ју│╗у╗ЪуГЅжбєтЪЪТёЪтЁ┤УХБуџёУ«Ау«ЌТю║уДЉтГдтЈіуЏИтЁ│СИЊСИџуџётГдућЪсђѓ; Сй┐ућетю║ТЎ»тЈіуЏ«ТаЄ№╝џРЉатИ«тіЕтЈѓУхЏжђЅТЅІуєЪТѓЅуФъУхЏТхЂуеІтњїУДётѕЎ№╝їТўјуА«тљёжўХТ«хС╗╗тіА№╝ЏРЉАТЈљСЙЏу│╗у╗ЪуџётцЄУхЏуГќуЋЦ№╝їтїЁТІгжФўжбЉУђЃуѓ╣уџётГдС╣атњїСИЊжА╣уфЂуа┤№╝ЏРЉбТїЄт»╝жђЅТЅІТјїТЈАт«ъТѕўТіђтиД№╝їжЂ┐тЁЇтИИУДЂжћЎУ»»№╝їТЈљжФўуГћжбўТЋѕујЄтњїтЄєуА«ТђДсђѓ; жўЁУ»╗т╗║У««№╝џТГцТќЄТАБСИЇС╗ЁТЈљСЙЏС║єуљєУ«║уЪЦУ»є№╝їУ┐ўтїЁтљФС║єтцДжЄЈт«ъТѕўу╗ЈжфїтњїтцЄУхЏУхёТ║љТјеУЇљ№╝їт╗║У««У»╗УђЁу╗ЊтљѕУЄфУ║ФТЃЁтєхтѕХт«џСИфТђДтїќуџётцЄУхЏУ«Атѕњ№╝їтЁЁтѕєтѕЕућеТЈљСЙЏуџёУхёТ║љУ┐ЏУАїу╗ЃС╣атњїтЄєтцЄсђѓ
тЪ║С║јУАїтЮЌТійтЈќТГБТќЄтєЁт«╣уџёjavaуЅѕТюгуџёТћ╣У┐Џу«ЌТ│Ћ.zip
тєЁт«╣ТдѓУдЂ№╝џТюгТќЄУ»ду╗єС╗Іу╗ЇС║єтЪ║С║јУЦ┐жЌетГљS7-200 PLCтњїMCGSу╗ёТђЂУй»С╗Хуџёт┐ФжђњтѕєТІБу│╗у╗ЪуџёУ«ЙУ«АСИјт«ъуј░Тќ╣Т│ЋсђѓждќтЁѕжўљУ┐░С║єуАгС╗ХжЁЇуй«уџётЁ│жћ«УдЂуѓ╣№╝їтїЁТІгIOтѕєжЁЇУАеуџётЁиСйЊУ«Йуй«С╗ЦтЈіС╝аТёЪтЎетњїТЅДУАїТю║ТъёуџёУ┐ъТјЦТќ╣т╝ЈсђѓТјЦуЮђТи▒тЁЦУДБТъљС║єPLCуеІт║ЈСИГуџёТб»тйбтЏЙжђ╗УЙЉ№╝їТХхуЏќСИ╗С╝ажђЂтИдуџёУ┐ъжћЂС┐ЮТіцсђЂТю║Тб░УЄѓтіеСйюуџёУЄфС┐ЮТїЂжђ╗УЙЉтњїт«ЅтЁетцЇСйЇТю║тѕХуГЅТаИт┐ЃжЃетѕєсђѓтљїТЌХТјбУ«еС║єMCGSу╗ёТђЂућ╗жЮбуџёт║ћуће№╝їт▒Ћуц║С║єтдѓСйЋжђџУ┐ЄУёџТюгт«ъуј░тіеТђЂТЋѕТъютњїТЋ░ТЇ«у╗ЪУ«АтіЪУЃйсђѓТГцтцќ№╝їТќЄСИГУ┐ўтѕєС║ФС║єСИђС║ЏУ░ЃУ»Ћу╗ЈжфїтњїтИИУДЂжЌ«жбўуџёУДБтє│Тќ╣ТАѕ№╝їтдѓжў▓ТГбС╝аТёЪтЎеТіќтіесђЂС╝ўтїќТЋ░ТЇ«С╝аУЙЊТЋѕујЄуГЅсђѓ жђѓтљѕС║║уЙц№╝џС╗јС║ІтиЦСИџУЄфтіетїќжбєтЪЪуџётиЦуеІтИѕтњїТіђТю»С║║тЉў№╝їт░цтЁХТў»т»╣PLCу╝ќуеІтњїу╗ёТђЂУй»С╗ХТюЅСИђт«џС║єУДБуџёС║║уЙцсђѓ Сй┐ућетю║ТЎ»тЈіуЏ«ТаЄ№╝џжђѓућеС║јжюђУдЂТъёт╗║жФўТЋѕтЈ»жЮауџёт┐ФжђњтѕєТІБу│╗у╗ЪуџёуЅЕТхЂС╝ЂСИџТѕќуЏИтЁ│жА╣уЏ«т╝ђтЈЉУђЁсђѓуЏ«ТаЄТў»тИ«тіЕУ»╗УђЁТјїТЈАС╗јуАгС╗ХжђЅтъІтѕ░Уй»С╗Ху╝ќуеІуџёСИђТЋ┤тЦЌт«ъТќйТхЂуеІ№╝їуА«С┐Юу│╗у╗ЪУЃйтцЪуе│т«џУ┐љУАїт╣ХУЙЙтѕ░жбёТюЪТђДУЃйТїЄТаЄсђѓ тЁХС╗ќУ»┤Тўј№╝џТќЄуФаСИЇС╗ЁТЈљСЙЏС║єуљєУ«║ТїЄт»╝№╝їУ┐ўу╗Њтљѕт«ъжЎЁТАѕСЙІУ┐ЏУАїС║єУ»ду╗єуџёТГЦжфцУ«▓УДБ№╝їТюЅтіЕС║јУ»╗УђЁТЏ┤тЦйтю░уљєУДБтњїт║ћућеС║јт«ъУихСИГсђѓ
У»ЦУхёТ║љСИ║joblib-0.12.5-py2.py3-none-any.whl№╝їТгбУ┐јСИІУййСй┐ућетЊд№╝Ђ
тєЁт«╣ТдѓУдЂ№╝џТюгТќЄУ»ду╗єС╗Іу╗ЇС║єСИЅуДЇу╗ЈтЁИуџёТю║тЎетГдС╣атѕєу▒╗у«ЌТ│ЋРђћРђћтє│уГќТаЉсђЂжџЈТю║ТБ«ТъЌтњїKNNтѕєу▒╗тЎе№╝їтюеPythonуџёsklearnт║ЊСИГуџётЁиСйЊт«ъуј░Тќ╣Т│ЋсђѓждќтЁѕ№╝їжђџУ┐ЄтіаУййжИбт░ЙУі▒ТЋ░ТЇ«жЏєУ┐ЏУАїТЋ░ТЇ«тЄєтцЄ№╝їт╣Хт░єтЁХтѕњтѕєСИ║У«Гу╗ЃжЏєтњїТхІУ»ЋжЏєсђѓТјЦуЮђтѕєтѕФт«ъуј░С║єтє│уГќТаЉсђЂжџЈТю║ТБ«ТъЌтњїKNNтѕєу▒╗тЎе№╝їт▒Ћуц║С║єТ»ЈуДЇу«ЌТ│ЋуџётЁ│жћ«тЈѓТЋ░жЁЇуй«тЈітЁХт»╣ТеАтъІТђДУЃйуџётй▒тЊЇсђѓт»╣С║јтє│уГќТаЉ№╝їжЄЇуѓ╣У«еУ«║С║єmax_depthтЈѓТЋ░уџёСйюућеС╗ЦтЈітдѓСйЋжђџУ┐ЄтЈ»УДєтїќтиЦтЁиуљєУДБтЁХтѕєУБѓУ┐ЄуеІ№╝ЏжџЈТю║ТБ«ТъЌжЃетѕєт╝║У░ЃС║єn_estimatorsтЈѓТЋ░уџёжђЅТІЕтњїуЅ╣тЙЂжЄЇУдЂТђДуџёУ»ёС╝░№╝ЏУђїKNNтѕєу▒╗тЎетѕЎуЮђжЄЇС║јуЅ╣тЙЂТаЄтЄєтїќуџёжЄЇУдЂТђДтњїn_neighborsтЈѓТЋ░уџёС╝ўтїќсђѓТГцтцќ№╝їТќЄСИГУ┐ўТЈљСЙЏС║єтЁ│С║јТеАтъІжђЅТІЕуџёТїЄт»╝№╝їтИ«тіЕУ»╗УђЁТа╣ТЇ«СИЇтљїт║ћућетю║ТЎ»жђЅТІЕтљѕжђѓуџёу«ЌТ│Ћсђѓ жђѓтљѕС║║уЙц№╝џт»╣Тю║тЎетГдС╣аТёЪтЁ┤УХБуџётѕЮтГдУђЁтњїТюЅСИђт«џу╝ќуеІтЪ║уАђуџёуаћтЈЉС║║тЉўсђѓ Сй┐ућетю║ТЎ»тЈіуЏ«ТаЄ№╝џРЉауљєУДБт╣ХТјїТЈАтє│уГќТаЉсђЂжџЈТю║ТБ«ТъЌтњїKNNтѕєу▒╗тЎеуџётиЦСйютјЪуљє№╝ЏРЉАтГдС╝џСй┐ућеsklearnт║Њт┐ФжђЪТъёт╗║тњїУ»ёС╝░тѕєу▒╗ТеАтъІ№╝ЏРЉбУЃйтцЪТа╣ТЇ«тЁиСйЊжЌ«жбўуЅ╣уѓ╣жђЅТІЕТюђжђѓтљѕуџётѕєу▒╗у«ЌТ│Ћсђѓ тЁХС╗ќУ»┤Тўј№╝џТюгТќЄСИЇС╗ЁТЈљСЙЏС║єУ»ду╗єуџёС╗БуаЂуц║СЙІ№╝їУ┐ўтѕєС║ФС║єУ«Итцџт«ъУиху╗Јжфї№╝їтдѓтЈѓТЋ░У░ЃС╝ўТіђтиДсђЂТеАтъІУ»ёС╝░Тќ╣Т│ЋуГЅ№╝їТюЅтіЕС║јУ»╗УђЁТЏ┤тЦйтю░уљєУДБтњїт║ћућеУ┐ЎС║Џу«ЌТ│Ћсђѓ