flynewton
- 浏览: 62548 次
- 性别:

- 来自: 杭州
-

最新评论
-
xuhang1128:
http://www.ihacklog.com/linux/m ...
Linux下安装memcached -
greatghoul:
常用的功能挺全面的。
vim使用技巧两篇



相关推荐
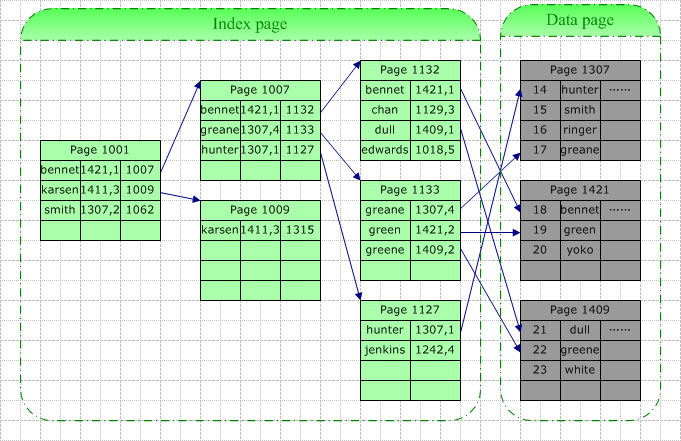
数据库索引设计与优化是数据库管理系统中至关重要的一个环节,它直接影响到数据查询的效率、存储空间的使用以及系统的整体性能。在这个主题中,我们将深入探讨数据库索引的基础概念、设计原则、优化策略以及实际应用...
《数据库索引设计与优化》提供了一种简单、高效、通用的关系型数据库索引设计方法。作者通过系统的讲解及大量的案例清晰地阐释了关系型数据库的访问路径选择原理,以及表和索引的扫描方式,详尽地讲解了如何快速地...
数据库索引重建及修复语句
高清完整版 数据库索引设计与优化 高清完整版 数据库索引设计与优化
数据库索引设计原则 数据库索引设计原则是 Oracle 数据库管理系统中的一项重要技术,旨在提高数据库的查询效率和性能。以下是数据库索引设计原则的详细解释。 一、基本原则 数据库索引设计原则的基本原则是确保...
《数据库索引设计与优化》提供了一种简单、高效、通用的关系型数据库索引设计方法。作者通过系统的讲解及大量的案例清晰地阐释了关系型数据库的访问路径选择原理,以及表和索引的扫描方式,详尽地讲解了如何快速地...
数据库索引技术是数据库管理系统中的核心组成部分,它极大地提高了数据查询效率,使得在海量数据中查找特定信息变得迅速。下面将分别对标题和描述中提到的各个知识点进行详细阐述。 首先,我们来看“文件记录的组织...
### 数据库索引及优化详解 #### 一、数据库索引的重要性 数据库索引就像是图书中的目录,能够显著提升查询速度。例如,在执行查询 `SELECT * FROM table1 WHERE id = 44` 时,如果没有索引,系统需要逐行扫描整个...
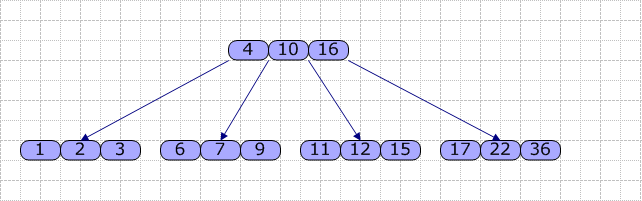
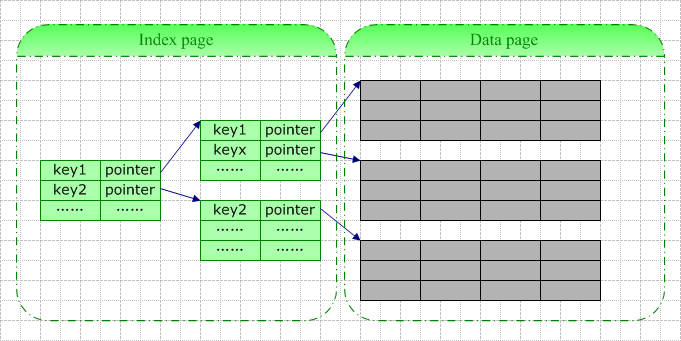
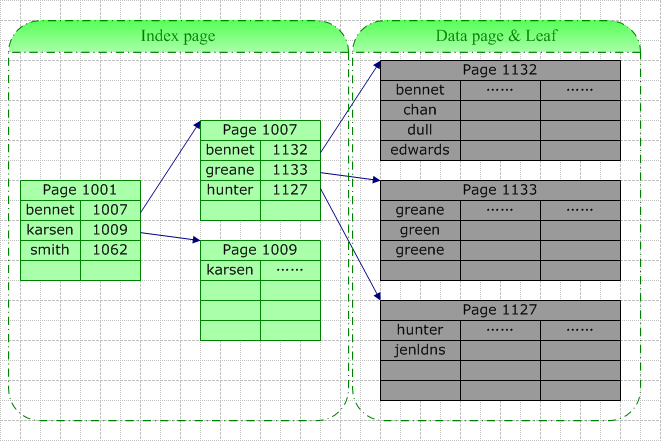
数据库索引是数据库管理系统中用于加速数据检索的一种数据结构,它的设计目的是为了提高查询效率,减少数据访问的时间。本文将深入探讨数据库索引的概念、B-Tree数据结构以及索引的分类和作用。 首先,B-Tree是...
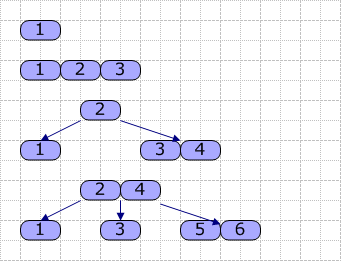
【数据库索引】是数据库管理系统中用于加速数据检索的一种数据结构。索引好比书籍的目录,能够快速定位到所需的数据行。根据物理存储方式,索引分为【聚簇索引】和【非聚簇索引】。聚簇索引是按照数据的实际存储顺序...
《Oracle与MySQL数据库索引设计与优化》这本书深入探讨了两个主流关系型数据库管理系统——Oracle和MySQL中的索引设计和优化策略。索引是数据库性能的关键因素,它们能够加速数据检索,提高系统效率,尤其在大数据量...
数据库索引作为数据库管理系统(DBMS)中的关键技术之一,其作用在于优化数据的检索速度和确保数据的唯一性。本文将深入探讨数据库索引的优缺点,以及如何在实际操作中合理地运用索引来提升数据库性能。 ### 数据库...
### 空间数据库索引技术的深度剖析 #### 核心知识点提炼: - **空间数据库索引技术的重要性**:空间数据库索引技术是提升空间数据库存储效率与空间检索性能的关键,尤其在处理大规模空间数据时更为显著。传统索引...
### Oracle数据库索引的维护 在Oracle数据库管理与优化的过程中,索引的维护是非常关键的一环。合理地创建、管理和优化索引能够显著提高查询性能,降低系统的响应时间,从而提升整个应用程序的效率。本文将从Oracle...