
Hive 的元数据信息通常存储在关系型数据库中,常用MySQL数据库作为元数据库管理。
1. 版本表
i) VERSION -- 查询版本信息
2. 数据库、文件存储相关
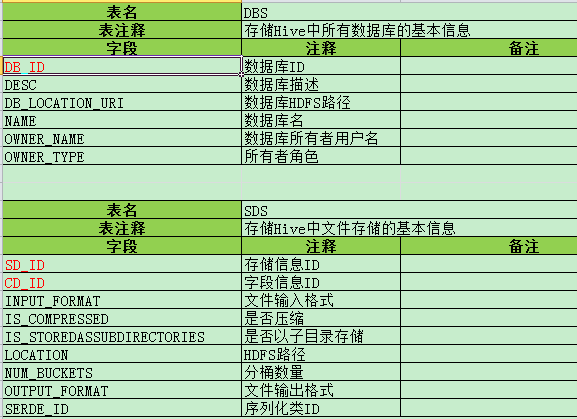
i) DBS -- 存储Hive中所有数据库的基本信息
ii) SDS -- 存储Hive中文件存储的基本信息
3. 表、视图相关
i) TBLS -- 存储Hive表、视图、索引表的基本信息
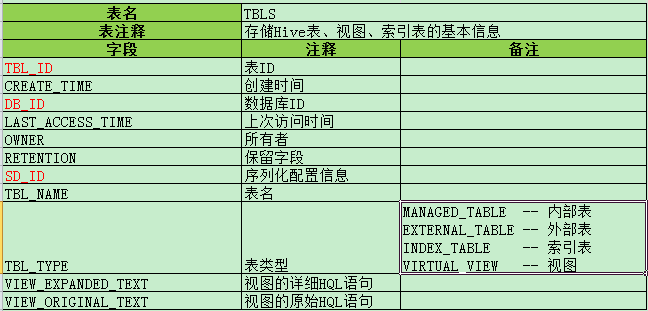
简要说明:1. 内部表与外部表的区别, 外部表 drop table 后,只删除元数据信息,数据文件还在。但是内部表 drop table 后,元数据和数据文件都会删除。
2. INDEX_TABLE : 创建索引后,Hive会单独生成一个物理表,存储索引信息和数据。
4. 列、分区相关
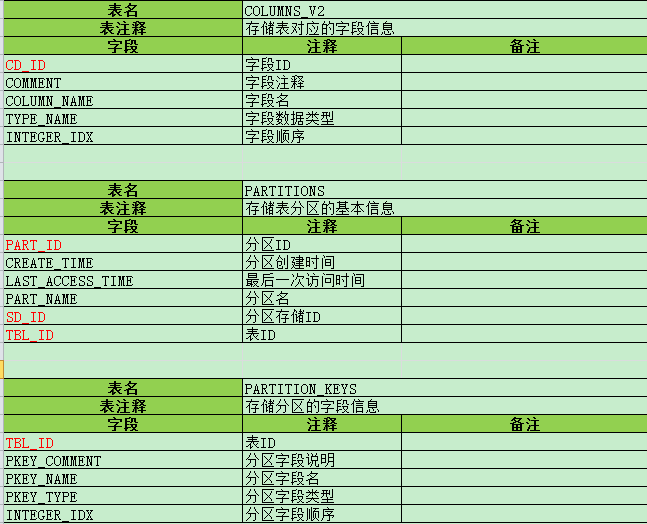
i) COLUMNS_V2 -- 存储表对应的字段信息
ii) PARTITIONS -- 存储表分区的基本信息
iii) PARTITION_KEYS -- 存储分区的字段信息
-- 收集统计信息
---====================
Impala 仅仅能部分利用Hive的统计信息, 要想得到好的执行效率, impala需要收集统计信息.
1. 检查统计信息
show table stats table_name; --显示表和分区级别的统计信息.
如果返回第一列 #Rows 值-1, 表名还没有收集过统计信息.
show column stats table_name ; --显示列级别的统计信息.
2. 收集统计信息
Impala 的compute stats 一条命令同时采集表和字段两种信息, 使用起来非常方便.
它增量和全量两种写法, 在从未收集过统计信息的前提下, 并且数量一致的情况下, 使用COMPUTE STATS命令要比COMPUTE INCREMENTAL STATS速度更快. 所以对于非分区表, 推荐使用COMPUTE STATS.
COMPUTE STATS table_name ; -- 对于非分区表, 推荐使用COMPUTE STATS, 速度更快
COMPUTE INCREMENTAL STATS table_name ;--对于分区表, 推荐使用COMPUTE INCREMENTAL STATS, 速度更快一些.
如果table通过Hive增加了分区, 需要先进行refresh, 然后增量收集统计信息.
REFRESH table_name;
COMPUTE INCREMENTAL STATS table_name;
3. 删除统计信息
DROP STATS table_name
DROP INCREMENTAL STATS table_name PARTITION (key_col1=val1 [, key_col2=val2...])]
hive里如何快速查看表中有多少记录数
直接从Mysql里查询
mysql> use hive
select * from TBLS where TBL_NAME='call_center';
mysql> select a.TBL_ID, a.TBL_NAME, b.PARAM_KEY, b.PARAM_VALUE from TBLS as a join TABLE_PARAMS as b where a.TBL_ID = b.TBL_ID and TBL_NAME="web_sales" and PARAM_KEY="numRows";
+--------+-----------+-----------+-------------+
| TBL_ID | TBL_NAME | PARAM_KEY | PARAM_VALUE |
+--------+-----------+-----------+-------------+
| 382 | web_sales | numRows | -1 |
| 406 | web_sales | numRows | 144002668 |
+--------+-----------+-----------+-------------+



相关推荐
在 Hive 中,元数据是指对数据的描述信息,如表名、表路径、分区信息、列信息等。下面将对 Hive 元数据库操作的常用 SQL 语句进行逐一解释。 查看表名及其对应的路径 查看表名及其对应的路径可以使用以下 SQL 语句...
元数据库存储了关于Hive表、列、分区等对象的所有元数据信息,使得Hive能够理解数据的结构和位置,从而执行查询。 元数据库通常存储在关系数据库管理系统(RDBMS)中,例如MySQL或Derby。在本例中,我们以Derby为例...
完成上述配置后,需要进行元数据初始化,以便Hive能识别达梦数据库中的表和列等信息。在Hive安装目录的`bin`目录下运行`schematool`命令,指定数据库类型为`dm`并执行初始化脚本。成功执行后,你会看到...
其中,元数据库在Hive系统中扮演着核心角色,它存储了关于Hive对象的所有元信息,如表结构、分区、列信息等。本文将深入探讨Hive元数据库的原理和功能,以及与传统关系数据库的异同。 首先,Hive的元数据存储在...
本文档将详细介绍如何配置 Hive 以便能够利用 Oracle 数据库来管理其元数据信息。 #### 二、安装与配置流程 **1. 下载并安装 Hive** 首先从 Apache 官方网站下载 Hive 的安装包,本文档使用的版本为 apache-hive-...
Hive元数据是Hive操作的核心部分,它包含了数据库、表、列、分区等信息,这些信息用于定义数据的结构和组织方式。本资源“hive元数据生成建表语句”主要关注如何从已有的Hive元数据中自动生成创建表的SQL语句,以...
另外,使用DBeaver等工具时,还需要了解一些额外的特性,例如元数据浏览、表数据查看、作业监控等。这些功能依赖于JDBC驱动提供的API,使用户能更直观地管理和理解Hadoop集群上的Hive数据。 在实际应用中,可能还会...
元数据库存储了关于Hive表、分区、列等对象的元数据,这些元数据是执行Hive查询的关键。通常,Hive默认使用Derby数据库作为元数据库,但当面对大规模数据处理时,Derby可能无法满足高并发和稳定性需求,因此选择更...
Hive使用MySQL作为元数据存储数据库(元数据库)是一个常见的做法,这有利于管理Hive中表的结构和属性等信息。元数据库主要存储了表结构、分区信息、表属性等元数据。 在安装Hive时,一般情况下仅需要在单个节点...
在IT行业中,HIVE数据库通常指的是Apache Hadoop的Hive组件,它是一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,使得大数据处理变得更加简单。而对于VC(Visual C++...
此外,Hive JDBC还支持事务管理和元数据查询,为Java应用提供了全面的Hive数据库访问能力。在大数据分析场景下,Hive JDBC驱动是连接Java应用和Hadoop生态系统的桥梁,使得数据分析工作变得更加便捷高效。
查数据库单个表大小 查数据库所有表大小
环境启动 hadoop hive2元数据库 sql导入 导入hivesql脚本,修改application.yml 启动主程序 HadoopApplication 基于Hadoop Hive健身馆可视化分析平台项目源码+数据库文件.zip启动方式 环境启动 hadoop hive2元数据库...
Idea连接Hive,Idea连接Hive,Idea连接Hive,Idea连接Hive,Idea连接Hive
本文档主要关注如何将Hive数据库集成到SpagoBI中,以便利用Hive的数据处理能力进行报表生成和分析。 集成SpagoBI和Hive数据库的步骤如下: 1. **安装Hive**:首先,你需要在你的服务器上安装Hive,包括设置Hadoop...
通过shell脚本,批量把一个库下面的表结构全部导出,在开发环境执行过。
### Kettle 从 Oracle 数据库导数据到 Hive 表 #### 背景与目的 在企业级数据处理场景中,随着大数据技术的发展,越来越多的企业选择将原有的关系型数据库(如 Oracle)中的数据迁移到基于 Hadoop 生态系统的数据...
在Java编程环境中,访问Hive数据库通常涉及到一系列的依赖库,这些库提供了与Hive通信所需的接口和功能。由于在你的场景中不使用Maven这样的项目管理工具,你需要手动收集和管理这些jar包。以下是对标题和描述中涉及...
使用`CREATE DATABASE`语句可以创建新的Hive数据库。例如,`CREATE DATABASE DB`将创建一个名为DB的新数据库。如果希望避免因数据库已存在而引发的错误,可以使用`IF NOT EXISTS`关键字,如`CREATE DATABASE IF NOT...
首先,确保在添加Hive数据库前,系统中不存在先前安装的MySQL版本。使用命令rpm -qa | grep mysql查询已安装的MySQL包,然后使用rpm -e --nodeps mysql-libs-5.1.71-1.el6.x86_64移除它。 接下来,利用yum工具安装...