
kafka安装
http://blog.csdn.net/weijonathan/article/details/18075967
这篇文章将介绍如何搭建kafka环境,我们会从单机版开始,然后逐渐往分布式扩展。单机版的搭建官网上就有,比较容易实现,这里我就简单介绍下即可,而分布式的搭建官网却没有描述,我们最终的目的还是用分布式来解决问题,所以这部分会是重点。
Kafka的中文文档并不多,所以我们尽量详细点儿写。要交会你搭建分布式其实很简单,手把手的教程大不了我录个视频就好了,可我觉得那不是走这条路的方式。只有真正了解原理,并且理解的透彻了才能最大限度的发挥一个框架的作用。所以,如果你不了解什么事kafka,请先看:《kafka初步》
我们从搭建单机版的环境开始说起,如果你喜欢看英文版:这里有官方的《quick start》
单机版的部署很简单,我就讲几点比较重要的,首先kafka是用scala编写的,可以跑在JVM上,所以我们并不需要单独去搭建scala的环境,后面会涉及到编程的时候我们再说如何去配置scala的问题,这里用不到,当然你要知道这个是跑在linux上的。第二,我用的是最新版0.7.2的版本,你下载完kafka你可以打开它的目录浏览一下:
我就不介绍每个包里的内容是干嘛的,我就着重说一点,你在这个文件夹里只能找到3个jar包,并且这3个还不能用于后面的编程,而且你也没法在里面找到pom这样用于构建的xml。也别急,也别满世界找,这些依赖库得等你把它放到linux上才会出现(当然需要命令)。
搭建单机版环境,简单的说有那么几步:
1. 安装java环境,我用的是最新的版本jdk7的
2. 将下载下来的kafka扔到linux上,并解压。我用的red het server的linux。
3. 接下来就是下载kafka的依赖包和构建kafka的环境。注意,这一步需要电脑联网。具体命令就是官网介绍的./sbt update 和 ./sbt package。
4. 执行完上面这步大概会花个10多分钟吧,我在自己家里ubuntu没有成功,报了下载不到jline的错。单位里用虚拟机ubuntu成功了,我深刻怀疑是网的问题。上面这不执行完了有两点要注意,一是sbt帮你下载完了所有依赖库,但是这些jar都是分散在各个目录下的,注意区分。二是,这些jar一部分是kafka的编程包,一部分是scala的环境包,上面说了没必要自己去搭scala的环境道理就在这边,你自己去下一个2.9的scala,但人家kafka只支持2.8、2.7。所以编程的时候就用sbt给你下好的包即可。后面讲到编程的时候,会写怎么搭编程环境,很简单的。
上面的步骤都执行完了,环境算是好了,下面我们要测试下是否能成功运行kafka:
1. 启动zookeeper server :bin/zookeeper-server-start.sh ../config/zookeeper.properties & (用&是为了能退出命令行)
2. 启动kafka server: bin/kafka-server-start.sh ../config/server.properties &
3. Kafka为我们提供了一个console来做连通性测试,下面我们先运行producer:bin/kafka-console-producer.sh --zookeeper localhost:2181 --topic test 这是相当于开启了一个producer的命令行。命令行的参数我们一会儿再解释。
4. 接下来运行consumer,新启一个terminal:bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
5. 执行完consumer的命令后,你可以在producer的terminal中输入信息,马上在consumer的terminal中就会出现你输的信息。有点儿像一个通信客户端。
具体可看《quick start》
如果你能看到5执行了,说明你单机版部署成功了。下面解释下两条命令中参数的意思。--zookeeper localhost:2181这个说明了去连本机2181端口的zookeeper server,--topic test,在kafka里,消息按topic来区分,我们这里的topic叫test,所以不管是consumer还是producer都指向了test。其他的参数,我就截图了,首先是producer的参数:
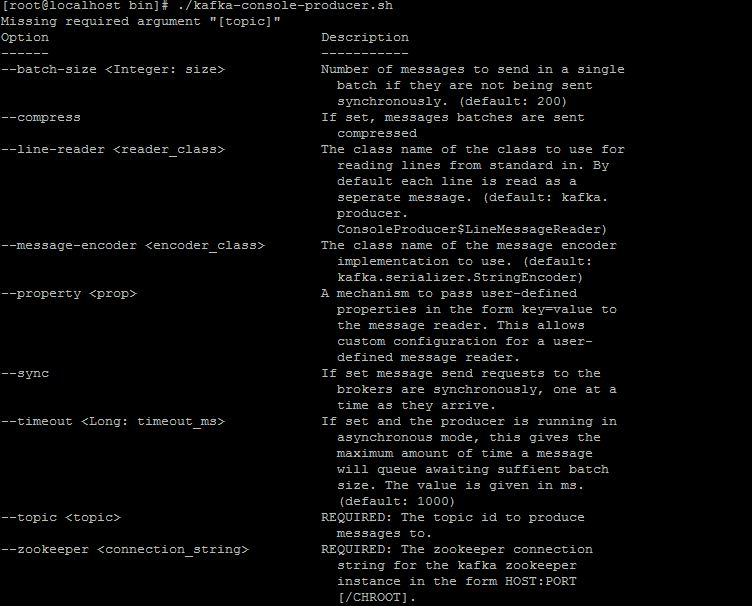
Consumer的参数:
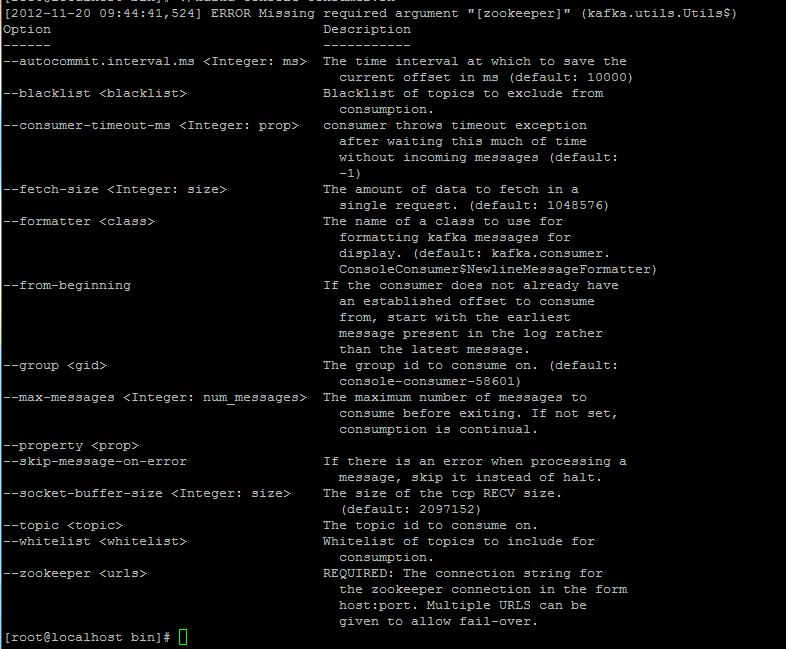
这些参数你可以先看个大概,之后会在编程中使用到,都可以动态的配置。
好了单机版就部署完了,那是不是我把consumer的放到另一台机器上就算分布式了呢。是的,前提是,你还能运行到上面的第5步。在讲配置之前,我们还是将上篇写的分布式来回顾一下,当然我们简化一下情况,按照实际部署的分析:

假设我只有两台机器,server1和server2。我现在想把zookeeper server和kafka server 和producer都放在一台机器上server1,把consumer放在server2上。这当然也叫分布式了,虽然机子不多,但是这个部署成功了,扩展是相当的容易。
我们还是按照那5个步骤来做,当然你肯定能知道,3、4两步的参数要改了,我们假设server1的IP是192.168.10.11 server2的IP是192.168.10.10:
1. 启动zookeeper server :bin/zookeeper-server-start.sh ../config/zookeeper.properties & (用&是为了能退出命令行)
2. 启动kafka server: bin/kafka-server-start.sh ../config/server.properties &
3. Kafka为我们提供了一个console来做连通性测试,下面我们先运行producer:bin/kafka-console-producer.sh --zookeeper 192.168.10.11:2181 --topic test 这是相当于开启了一个producer的命令行。
4. 接下来运行consumer,新启一个terminal:bin/kafka-console-consumer.sh --zookeeper 192.168.10.11:2181 --topic test --from-beginning
5. 执行完consumer的命令后,你可以在producer的terminal中输入信息,马上在consumer的terminal中就会出现你输的信息。
这个时候你能执行出第5步的效果么,是不是报了下面的错了:

我来说原因,在这之前想请你再回去看看《kafka初步》,看看里面讲分布式的内容:
这里的kafka server就是broker,broker是存数据的,producer把数据给broker,consumer从broker取数据。那zookeeper是干嘛的,说的肤浅点儿,zookeeper就是他们之间的选择分发器,所有的连接都要先注册到zookeeper上。你可以把它想象成NIO,zookeeper就是selector,producer、consumer和broker都要注册到selector上,并且留下了相应的key。
所以问题就出在了kafka server的配置server.properties上。Kafka注册到zookeeper上的信息不对,才导致了上面的错误。我们看config中server.properties的配置就可以知道:
1 |
# Hostname the broker will advertise to consumers. If not set, kafka will use the value returned |
2 |
# from InetAddress.getLocalHost(). If there are multiple interfaces getLocalHost |
3 |
# may not be what you want. |
4 |
#hostname= |
默认的hostname如果你不设置,就是127.0.0.1,所以你把这个hostname设置成192.168.10.11即可,这样你重启下kafka server端,就能执行第5步了。
成功配置的话,你能看到下面的效果,左边的是producer,右边的是consumer,看最下面两行好了,前面的是我之前测试用过的:

如果你还是云里雾里的,建议你回头去看看上篇文章,将kafka分布式基本原理的,kafka实际操作是要建立在对原理熟悉的情况下的。
搭建完了环境,后面就要开始写程序去处理实际问题了。当然再写程序之前,下一篇我会先写一点kafka为什么会有如此高的性能,它是怎么保障这些性能的。



相关推荐
**Kafka安装与部署指南** Apache Kafka是一款分布式流处理平台,由LinkedIn开发并贡献给了Apache软件基金会。它被广泛用于构建实时数据管道和流应用程序,能够处理大量的实时数据。Kafka以其高吞吐量、持久化、容错...
### Kafka安装手册(Linux) #### 一、Kafka简介与安装背景 Apache Kafka是一个开源的流处理平台,由LinkedIn开发并捐赠给Apache软件基金会。它主要用于构建实时数据管道和流应用,具有高吞吐量、低延迟的特点。...
**Kafka安装与配置指南** Kafka是一款分布式流处理平台,由LinkedIn开发并贡献给了Apache软件基金会。它被广泛用于实时数据管道和流处理任务,能够处理大量的实时数据。在这个指南中,我们将深入探讨Kafka的安装...
Kafka 安装及详细介绍 Kafka 是一个高吞吐的分布式消息队列系统,具有生产者消费者模式,先进先出(FIFO)保证顺序,不丢失数据,默认每隔 7 天清理数据。事件记录了一个事实,即世界或企业中发生的“某些事情”。...
### Kafka安装与配置详解 #### 一、Kafka简介 Apache Kafka是一种分布式流处理平台,主要功能包括发布和订阅记录流、存储记录流并可靠地处理这些记录流。Kafka适用于离线和在线的消息消费,如常规的消息收集、网站...
KafKa 安装 环境搭建
kafka安装教程 kafka安装教程 kafka安装教程 kafka安装教程 kafka安装教程
Linux是Kafka最常用的运行环境,因此掌握Linux下的Kafka安装与配置对于运维工程师来说是非常重要的基础技能。 首先,安装Kafka的第一步是上传Kafka的压缩包到Linux服务器的某个目录下,例如`/home/work/_src`。然后...
### Kafka安装与部署详解 #### 一、Kafka简介 Apache Kafka是一款开源的消息队列中间件,主要用于构建实时数据管道以及流式应用。它能够处理大量实时数据,并且具有高吞吐量、低延迟等特点。Kafka的核心概念包括...
### Kafka安装部署 #### 单机版安装 1. **下载**: 首先,你需要从Apache Kafka的官方网站下载最新版本的Kafka。确保下载与你的操作系统兼容的版本。 2. **解压**: 解压缩下载的文件到你选择的目录。 3. **配置**: ...
Kafka 安装使用手册 Kafka 是一种高吞吐量、可扩展的分布式消息队列系统,广泛应用于大数据、流式计算、实时数据处理等领域。本文档将详细介绍 Kafka 的安装、配置和使用。 一、Kafka 安装 1. 下载 Kafka Kafka ...
在这个“kafka安装相关文件以及java调用kafka示例项目”中,我们包含了几个关键组件和示例,以便于理解和实践Kafka的使用。 首先,我们有Kafka的安装包,这通常包含服务器端的二进制文件,配置文件,以及必要的脚本...
【Kafka安装实验手册】 本实验手册主要针对大数据采集技术中的关键组件——Apache Kafka进行详细的安装和配置指导,旨在帮助用户掌握Kafka的部署过程,从而更好地理解和运用大数据采集技术。 **Kafka简介** Kafka...
总结来说,解决Zookeeper Kafka安装过程中的错误主要涉及以下几个方面: 1. 正确配置Zookeeper和Kafka的连接参数。 2. 确保网络可达性和通信稳定性。 3. 调整Kafka的配置参数,如请求超时时间和监听器设置。 4. 在...
Kafka安装与部署指南详细介绍了如何在Linux环境下安装和部署Apache Kafka。Apache Kafka是一个分布式流处理平台,主要用于构建实时数据管道和流应用程序。它具有高吞吐量、可扩展性和容错性的特点。下面将根据指南...
**Kafka安装配置教程完整版** Kafka是一种分布式流处理平台,由Apache软件基金会开发,广泛应用于大数据实时处理、消息传递以及日志收集系统。它以其高吞吐量、低延迟和可扩展性而闻名。在本文中,我们将详细介绍...
【Kafka安装指导手册1】 Kafka是一款分布式流处理平台,常用于实时数据处理和大数据管道构建。在本文中,我们将详细介绍如何在CentOS 7系统上安装和配置Kafka,以及与其紧密关联的Zookeeper。 **一、环境准备** ...
kafka安装配置详解 Kafka是一种高吞吐量、基于发布-订阅模式的消息队列系统,广泛应用于大数据处理、实时数据处理和流处理等领域。下面将详细介绍Kafka的安装配置过程。 JDK1.8安装 Kafka依赖JDK1.8,故首先需要...
《Kafka安装部署详解》 Kafka是一款分布式流处理平台,广泛应用于大数据处理领域,它提供了高吞吐量的消息发布和订阅功能。本教程将详细阐述如何在Linux环境下,基于Scala和ZooKeeper安装部署Kafka。 首先,Kafka...
kafka安装手册 Kafka 是一种流行的分布式流处理平台,由 Apache 软件基金会开发和维护。Kafka 通过提供高吞吐量、持久化、多订阅者支持等特性,满足了大数据处理和实时数据处理的需求。 Kafka 集群安装 Kafka ...