õĖĆõĖ¬Õ║öńö©ÕŹĀńö©CPUÕŠłķ½ś’╝īķÖżõ║åńĪ«Õ«×µś»Ķ«Īń«ŚÕ»åķøåÕ×ŗÕ║öńö©õ╣ŗÕż¢’╝īķĆÜÕĖĖÕĤÕøĀķāĮµś»Õć║ńÄ░õ║åµŁ╗ÕŠ¬ńÄ»ŃĆé
õ╗źµłæõ╗¼µ£ĆĶ┐æÕć║ńÄ░ńÜäõĖĆõĖ¬Õ«×ķÖģµĢģķÜ£õĖ║õŠŗ’╝īõ╗ŗń╗ŹµĆÄõ╣łÕ«ÜõĮŹÕÆīĶ¦ŻÕå│Ķ┐Öń▒╗ķŚ«ķóśŃĆé
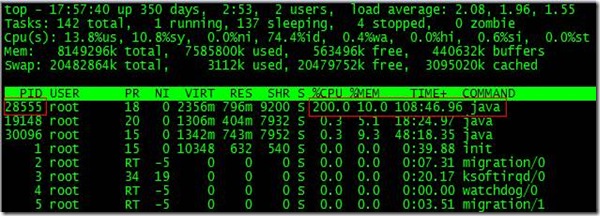
µĀ╣µŹ«topÕæĮõ╗ż’╝īÕÅæńÄ░PIDõĖ║28555ńÜäJavaĶ┐øń©ŗÕŹĀńö©CPUķ½śĶŠŠ200%’╝īÕć║ńÄ░µĢģķÜ£ŃĆé
ķĆÜĶ┐ćps aux | grep PIDÕæĮõ╗ż’╝īÕÅ»õ╗źĶ┐øõĖƵŁźńĪ«Õ«Üµś»tomcatĶ┐øń©ŗÕć║ńÄ░õ║åķŚ«ķóśŃĆéõĮåµś»’╝īµĆÄõ╣łÕ«ÜõĮŹÕł░ÕģĘõĮōń║┐ń©ŗµł¢ĶĆģõ╗ŻńĀüÕæó’╝¤
ķ”¢ÕģłµśŠńż║ń║┐ń©ŗÕłŚĶĪ©:
ps -mp pid -o THREAD,tid,time
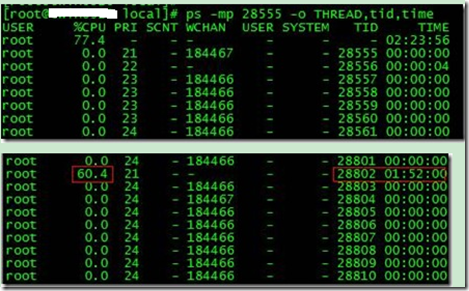
µēŠÕł░õ║åĶĆŚµŚČµ£Ćķ½śńÜäń║┐ń©ŗ28802’╝īÕŹĀńö©CPUµŚČķŚ┤Õ┐½õĖżõĖ¬Õ░ŵŚČõ║å’╝ü
Õģȵ¼ĪÕ░åķ£ĆĶ”üńÜäń║┐ń©ŗIDĶĮ¼µŹóõĖ║16Ķ┐øÕłČµĀ╝Õ╝Å’╝Ü
printf "%x\n" tid

µ£ĆÕÉĵēōÕŹ░ń║┐ń©ŗńÜäÕĀåµĀłõ┐Īµü»’╝Ü
jstack pid |grep tid -A 30
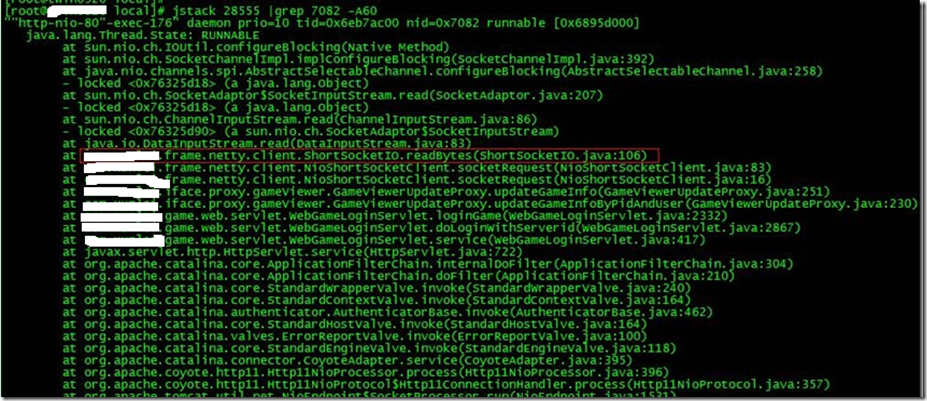
µēŠÕł░Õć║ńÄ░ķŚ«ķóśńÜäõ╗ŻńĀüõ║å’╝ü
ńÄ░Õ£©µØźÕłåµ×ÉõĖŗÕģĘõĮōńÜäõ╗ŻńĀü’╝ÜShortSocketIO.readBytes(ShortSocketIO.java:106)
ShortSocketIOµś»Õ║öńö©Õ░üĶŻģńÜäõĖĆõĖ¬ńö©ń¤ŁĶ┐׵ğSocketķĆÜõ┐ĪńÜäÕĘźÕģĘń▒╗ŃĆéreadBytesÕćĮµĢ░ńÜäõ╗ŻńĀüÕ”éõĖŗ’╝Ü
public byte[] readBytes(int length) throws IOException {
if ((this.socket == null) || (!this.socket.isConnected())) {
throw new IOException("++++ attempting to read from closed socket");
}
byte[] result = null;
ByteArrayOutputStream bos = new ByteArrayOutputStream();
if (this.recIndex >= length) {
bos.write(this.recBuf, 0, length);
byte[] newBuf = new byte[this.recBufSize];
if (this.recIndex > length) {
System.arraycopy(this.recBuf, length, newBuf, 0, this.recIndex - length);
}
this.recBuf = newBuf;
this.recIndex -= length;
} else {
int totalread = length;
if (this.recIndex > 0) {
totalread -= this.recIndex;
bos.write(this.recBuf, 0, this.recIndex);
this.recBuf = new byte[this.recBufSize];
this.recIndex = 0;
}
int readCount = 0;
while (totalread > 0) {
if ((readCount = this.in.read(this.recBuf)) > 0) {
if (totalread > readCount) {
bos.write(this.recBuf, 0, readCount);
this.recBuf = new byte[this.recBufSize];
this.recIndex = 0;
} else {
bos.write(this.recBuf, 0, totalread);
byte[] newBuf = new byte[this.recBufSize];
System.arraycopy(this.recBuf, totalread, newBuf, 0, readCount - totalread);
this.recBuf = newBuf;
this.recIndex = (readCount - totalread);
}
totalread -= readCount;
}
}
}
ķŚ«ķóśÕ░▒Õć║Õ£©µĀćń║óńÜäõ╗ŻńĀüķā©ÕłåŃĆéÕ”éµ×£this.in.read()Ķ┐öÕø×ńÜäµĢ░µŹ«Õ░Åõ║ÄńŁēõ║Ä0µŚČ’╝īÕŠ¬ńÄ»Õ░▒õĖĆńø┤Ķ┐øĶĪīõĖŗÕÄ╗õ║åŃĆéĶĆīĶ┐Öń¦ŹµāģÕåĄÕ£©ńĮæń╗£µŗźÕĪ×ńÜ䵌ČÕĆÖµś»ÕÅ»ĶāĮÕÅæńö¤ńÜäŃĆé
Ķć│õ║ÄÕģĘõĮōµĆÄõ╣łõ┐«µö╣Õ░▒ń£ŗõĖÜÕŖĪķĆ╗ĶŠæÕ║öĶ»źµĆÄõ╣łÕ»╣ÕŠģĶ┐Öń¦Źńē╣µ«ŖµāģÕåĄõ║åŃĆé
µ£ĆÕÉÄ’╝īµĆ╗ń╗ōõĖŗµÄƵ¤źCPUµĢģķÜ£ńÜäµ¢╣µ│ĢÕÆīµŖĆÕʦµ£ēÕō¬õ║ø’╝Ü
1ŃĆütopÕæĮõ╗ż’╝ÜLinuxÕæĮõ╗żŃĆéÕÅ»õ╗źµ¤źń£ŗÕ«×µŚČńÜäCPUõĮ┐ńö©µāģÕåĄŃĆéõ╣¤ÕÅ»õ╗źµ¤źń£ŗµ£ĆĶ┐æõĖƵ«ĄµŚČķŚ┤ńÜäCPUõĮ┐ńö©µāģÕåĄŃĆé
2ŃĆüPSÕæĮõ╗ż’╝ÜLinuxÕæĮõ╗żŃĆéÕ╝║Õż¦ńÜäĶ┐øń©ŗńŖȵĆüńøæµÄ¦ÕæĮõ╗żŃĆéÕÅ»õ╗źµ¤źń£ŗĶ┐øń©ŗõ╗źÕÅŖĶ┐øń©ŗõĖŁń║┐ń©ŗńÜäÕĮōÕēŹCPUõĮ┐ńö©µāģÕåĄŃĆéÕ▒×õ║ÄÕĮōÕēŹńŖȵĆüńÜäķććµĀʵĢ░µŹ«ŃĆé
3ŃĆüjstack’╝ÜJavaµÅÉõŠøńÜäÕæĮõ╗żŃĆéÕÅ»õ╗źµ¤źń£ŗµ¤ÉõĖ¬Ķ┐øń©ŗńÜäÕĮōÕēŹń║┐ń©ŗµĀłĶ┐ÉĶĪīµāģÕåĄŃĆéµĀ╣µŹ«Ķ┐ÖõĖ¬ÕæĮõ╗żńÜäĶŠōÕć║ÕÅ»õ╗źÕ«ÜõĮŹµ¤ÉõĖ¬Ķ┐øń©ŗńÜäµēƵ£ēń║┐ń©ŗńÜäÕĮōÕēŹĶ┐ÉĶĪīńŖȵĆüŃĆüĶ┐ÉĶĪīõ╗ŻńĀü’╝īõ╗źÕÅŖµś»ÕÉ”µŁ╗ķöüńŁēńŁēŃĆé
4ŃĆüpstack’╝ÜLinuxÕæĮõ╗żŃĆéÕÅ»õ╗źµ¤źń£ŗµ¤ÉõĖ¬Ķ┐øń©ŗńÜäÕĮōÕēŹń║┐ń©ŗµĀłĶ┐ÉĶĪīµāģÕåĄŃĆé
’╝łÕÅŗµāģµÅÉńż║’╝ܵ£¼ÕŹÜµ¢ćń½Āµ¼óĶ┐ÄĶĮ¼ĶĮĮ’╝īõĮåĶ»Ęµ│©µśÄÕć║Õżä’╝Ühankchen’╝ī
pidõĖ║javaĶ┐øń©ŗid
ńö©top -H -p pidÕæĮõ╗żµ¤źń£ŗĶ┐øń©ŗÕåģÕÉäõĖ¬ń║┐ń©ŗÕŹĀńö©ńÜäCPUńÖŠÕłåµ»ö

top -H -p 4076

http://www.blogjava.net/hankchen’╝ē

- Õż¦Õ░Å: 65.6 KB

- Õż¦Õ░Å: 133.1 KB
Õłåõ║½Õł░’╝Ü




ńøĖÕģ│µÄ©ĶŹÉ
µ£¼ń»ćµ¢ćń½ĀÕ░åµÄóĶ«©õĖĆõĖ¬ÕĖĖĶ¦üńÜäķŚ«ķóśŌĆöŌĆö"ń║┐õĖŖÕ║öńö©µĢģķÜ£µÄƵ¤źõ╣ŗõĖĆ’╝Üķ½śCPUÕŹĀńö©"ŃĆéķ½śCPUÕŹĀńö©ÕÅ»ĶāĮÕ»╝Ķć┤ń│╗ń╗¤ÕōŹÕ║öÕÅśµģó’╝īÕĮ▒ÕōŹńö©µłĘõĮōķ¬ī’╝īńöÜĶć│ÕÅ»ĶāĮÕ»╝Ķć┤µ£ŹÕŖĪÕ┤®µ║āŃĆéĶ¦ŻÕå│Ķ┐ÖõĖ¬ķŚ«ķóśķ£ĆĶ”üµĘ▒ÕģźńÉåĶ¦ŻÕ║öńö©ń©ŗÕ║ÅńÜäĶ┐ÉĶĪīµ£║ÕłČõ╗źÕÅŖń│╗ń╗¤ĶĄäµ║ÉńÜäń«ĪńÉåŃĆé ...
┬ĀCPUÕŹĀńö©Ķ┐ćķ½śµś»LINUXµ£ŹÕŖĪÕÖ©Õć║ńÄ░ÕĖĖĶ¦üńÜäõĖĆń¦ŹµĢģķÜ£’╝īõ╣¤µś»ń©ŗÕ║ÅÕæśń║┐õĖŖµÄƵ¤źķöÖĶ»»Õ┐ģķĪ╗µÄīµÅĪńÜäµŖĆĶāĮ’╝īµłæõ╗¼ń╗ÅÕĖĖķ£ĆĶ”üµēŠÕć║ńøĖÕ║öńÜäÕ║öńö©ń©ŗÕ║ÅÕ╣ČÕ┐½ķĆ¤Õ£░Õ«ÜõĮŹń©ŗÕ║ÅõĖŁńÜäÕģĘõĮōõ╗ŻńĀüĶĪīµĢ░’╝īµ£¼µ¢ćÕ░åõ╗ŗń╗ŹõĖĆń¦ŹCPUÕŹĀńö©Ķ┐ćķ½śńÜäõĖĆń¦ŹÕżäńÉåµĆØĶĘ»’╝īµ¢ćõĖŁķććńö©Õøø...
ń│╗ń╗¤Õ╝éÕĖĖķĆÜÕĖĖµīćńÜ䵜»CPUÕŹĀńö©ńÄćĶ┐ćķ½śŃĆüńŻüńøśõĮ┐ńö©ńÄć100%ŃĆüń│╗ń╗¤ÕÅ»ńö©ÕåģÕŁśõĮÄńŁēµāģÕåĄ’╝øĶĆīõĖÜÕŖĪÕ╝éÕĖĖÕłÖÕÅ»ĶāĮÕīģµŗ¼µ£ŹÕŖĪĶ┐ÉĶĪīõĖƵ«ĄµŚČķŚ┤Ķć¬ÕŖ©ķĆĆÕć║ŃĆüµ£ŹÕŖĪķŚ┤Ķ░āńö©µŚČķŚ┤Ķ┐ćķĢ┐ŃĆüÕżÜń║┐ń©ŗÕ╣ČÕÅæÕ╝éÕĖĖŃĆüµŁ╗ķöüńŁēķŚ«ķóśŃĆéÕ£©Ķ┐øĶĪīµĢģķÜ£µÄƵ¤źµŚČ’╝īń¼¼õĖƵŁźõŠ┐µś»ķŚ«ķóśńÜä...
1. CPUÕłåµ×É’╝ÜõĮ┐ńö©jstackÕłåµ×Éń║┐ń©ŗńŖȵĆü’╝īµēŠÕć║CPUÕŹĀńö©ķ½śńÜäÕĤÕøĀŃĆé 2. ÕåģÕŁśÕłåµ×É’╝ÜõĮ┐ńö©jmapŃĆüjhatµł¢MAT’╝łMemory Analyzer Tool’╝ēĶ┐øĶĪīÕĀåÕåģÕŁśÕłåµ×É’╝īÕ«ÜõĮŹÕåģÕŁśµ│äµ╝ÅŃĆé 3. ÕōŹÕ║öµŚČķŚ┤’╝ÜńøæµÄ¦Ķ»Ęµ▒éÕōŹÕ║öµŚČķŚ┤’╝īń╗ōÕÉłĶ░āńö©ķōŠĶĘ»Õłåµ×É’╝īµēŠÕć║...
1. **ń│╗ń╗¤Õ╝éÕĖĖ**’╝ÜõŠŗÕ”éCPUÕŹĀńö©ńÄćĶ┐ćķ½śŃĆüńŻüńøśń®║ķŚ┤100%µ╗ĪŃĆüń│╗ń╗¤ÕÅ»ńö©ÕåģÕŁśĶ┐ćõĮÄńŁēŃĆé 2. **õĖÜÕŖĪÕ╝éÕĖĖ**’╝ÜՔ鵣ŹÕŖĪĶ┐ÉĶĪīõĖƵ«ĄµŚČķŚ┤ÕÉÄĶć¬ÕŖ©ķĆĆÕć║ŃĆüµ£ŹÕŖĪķŚ┤Ķ░āńö©ĶĆŚµŚČĶ┐ćķĢ┐ŃĆüÕżÜń║┐ń©ŗÕ╣ČÕÅæÕżäńÉåµŚČÕć║ńÄ░ķŚ«ķóśŃĆüń║┐ń©ŗµŁ╗ķöüńŁēŃĆé #### õĖēŃĆüÕ”éõĮĢÕ«ÜõĮŹ...
ÕÅ»õ╗źõĮ┐ńö©`ps`µēŠÕł░ńø«µĀćĶ┐øń©ŗńÜäPID’╝īńäČÕÉÄõĮ┐ńö©`top -H -p pid`µēŠÕć║CPUÕŹĀńö©ķ½śńÜäń║┐ń©ŗŃĆéÕ░åPIDĶĮ¼µŹóõĖ║16Ķ┐øÕłČÕÉÄ’╝īķĆÜĶ┐ć`jstack pid | grep 'nid' -C5 --color`µ¤źń£ŗÕĀåµĀłĶ»”µāģŃĆéķćŹńé╣Õģ│µ│©`WAITING`ÕÆī`TIMED_WAITING`ńŖȵĆüńÜäń║┐ń©ŗ’╝ī...
µ£¼µ¢ćÕ░åĶ»”ń╗åõ╗ŗń╗ŹõĖĆÕźŚń║┐õĖŖµĢģķÜ£µÄƵ¤źńÜäÕģ©ķØóµ¢╣µĪł’╝īµČĄńø¢CPUŃĆüńŻüńøśŃĆüÕåģÕŁśÕÆīńĮæń╗£ÕøøõĖ¬Õģ│ķö«Õ▒éķØóŃĆé ķ”¢Õģł’╝īCPUÕ╝éÕĖĖµś»ÕĖĖĶ¦üńÜäµĢģķÜ£ń▒╗Õ×ŗŃĆéCPUõĮ┐ńö©ńÄćĶ┐ćķ½śÕÅ»ĶāĮµś»ńö▒õ║ÄõĖÜÕŖĪķĆ╗ĶŠæõĖŁńÜ䵣╗ÕŠ¬ńÄ»ŃĆüķóæń╣üńÜäÕ×āÕ£ŠÕø×µöČ’╝łGC’╝ēµł¢ĶĆģõĖŖõĖŗµ¢ćÕłćµŹóĶ┐ćõ║Äķóæń╣ü...
### MySQLń║┐õĖŖÕĖĖĶ¦üµĢģķÜ£Õē¢µ×É #### õĖĆŃĆüµĢģķÜ£µ”éĶ┐░õĖÄÕłåń▒╗ Õ£©MySQLńÜ䵌źÕĖĖĶ┐Éń╗┤õĖŁ’╝īń╗ÅÕĖĖõ╝ÜÕć║ńÄ░ÕÉäń¦ŹÕÉäµĀĘńÜäµĢģķÜ£’╝īĶ┐Öõ║øµĢģķÜ£ÕÅ»ĶāĮµ║ÉĶć¬õ║ÄõĖŹÕÉīńÜäÕ▒éķØó’╝īÕīģµŗ¼õĮåõĖŹķÖÉõ║ÄÕ║öńö©Õ▒éŃĆüµĢ░µŹ«Õ║ōÕ▒éŃĆüµōŹõĮ£ń│╗ń╗¤Õ▒éńŁēŃĆéķĆÜĶ┐ćÕ»╣Ķ┐Öõ║øµĢģķÜ£ńÜäµĘ▒ÕģźÕłåµ×É’╝ī...
Arthas’╝īÕģ©ÕÉŹ Alibaba Arthas’╝īµś»õĖĆõĖ¬Õ╝║Õż¦ńÜäÕ╝Ƶ║ÉJavaĶ»Ŗµ¢ŁÕĘźÕģĘ’╝īńö▒ķś┐ķćīÕĘ┤ÕĘ┤Õ╝ĆÕÅæÕ╣Čń╗┤µŖżŃĆéĶ┐ÖõĖ¬ÕĘźÕģĘńÜäõĖ╗Ķ”üńø«ńÜ䵜»ÕĖ«ÕŖ®...ķĆÜĶ┐ćńå¤ń╗āµÄīµÅĪArthas’╝īÕ╝ĆÕÅæĶĆģÕÅ»õ╗źÕ£©ķØóÕ»╣ÕżŹµØéķŚ«ķ󜵌ȵø┤ÕŖĀõ╗ÄÕ«╣’╝īÕÅŖµŚČĶ¦ŻÕå│ń║┐õĖŖµĢģķÜ£’╝īõ┐ØķÜ£µ£ŹÕŖĪńÜäķ½śÕÅ»ńö©µĆ¦ŃĆé
Õ¤║µ£¼ńÜäń¢æķÜŠµÄƵ¤źµŁźķ¬żÕīģµŗ¼’╝ܵē¦ĶĪī top ÕæĮõ╗żĶ«░ÕĮĢ CPU õĮ┐ńö©ńÄć’╝īµē¦ĶĪī free ÕæĮõ╗żĶ«░ÕĮĢÕåģÕŁśõĮ┐ńö©ńÄć’╝īõĮ┐ńö© ps ÕæĮõ╗żĶ«░ÕĮĢĶ┐øń©ŗõ┐Īµü»’╝īõĮ┐ńö© jstack µöČķøåń║┐ń©ŗõ┐Īµü»’╝īõĮ┐ńö© jstat Ķ¦åÕøŠ Old Õī║ÕŹĀńö©ńÄć’╝īõĮ┐ńö© jmap õ┐ØńĢÖÕåģÕŁśõ┐Īµü»ńŁēŃĆé...
ń║┐õĖŖµĢģķÜ£õĖ╗Ķ”üõ╝ÜÕīģµŗ¼ CPUŃĆüÕåģÕŁśŃĆüńŻüńøśõ╗źÕÅŖńĮæń╗£ķŚ«ķóś’╝īĶĆīÕż¦ÕżÜµĢ░µĢģķÜ£ÕÅ»ĶāĮõ╝ÜÕīģÕɽõĖŹµŁóõĖĆõĖ¬Õ▒éķØóńÜäķŚ«ķóś’╝īµēĆõ╗źĶ┐øĶĪīµÄƵ¤źµŚČÕĆÖÕ░ĮķćÅÕøøõĖ¬µ¢╣ķØóõŠØµ¼ĪµÄƵ¤źõĖĆķüŹŃĆéÕ¤║µ£¼õĖŖÕć║ķŚ«ķóśÕ░▒µś» dfŃĆüfreeŃĆütop’╝īńäČÕÉÄõŠØµ¼Ī õĮ┐ńö©jstackŃĆüjmap’╝īÕģĘõĮōķŚ«ķóś...
µŖźÕæŖķĆÜÕĖĖÕīģµŗ¼Õ╝éÕĖĖń▒╗Õ×ŗŃĆüÕĀåµĀłĶʤĶĖ¬ŃĆüĶ«ŠÕżćõ┐Īµü»ńŁēÕģ│ķö«µĢ░µŹ«’╝īĶ┐ÖõĮ┐ÕŠŚÕ╝ĆÕÅæĶĆģĶāĮĶ┐ģķĆ¤Õ«ÜõĮŹķŚ«ķóśµ║ÉÕż┤’╝īń╝®ń¤ŁµĢģķÜ£µÄƵ¤źµŚČķŚ┤ŃĆéÕ»╣õ║Äń║┐õĖŖÕ║öńö©’╝īĶ┐Öń¦ŹÕŹ│µŚČńÜäÕ┤®µ║āµŖźÕæŖÕ░żÕģČķćŹĶ”ü’╝īÕøĀõĖ║Õ«āÕÅ»õ╗źÕĖ«ÕŖ®Õ╝ĆÕÅæĶĆģĶ┐ģķƤÕōŹÕ║öńö©µłĘÕÅŹķ”ł’╝īõ┐«ÕżŹķŚ«ķóś’╝īµÅÉķ½śÕ║öńö©...
7. **CPUĶ┐ćķ½śµÄƵ¤ź**’╝ÜArthasµÅÉõŠøCPUÕ┐½ńģ¦Õłåµ×É’╝īÕŹÅÕŖ®Õ«ÜõĮŹCPUÕŹĀńö©ķ½śńÜäÕĤÕøĀŃĆé 8. **µŚźÕ┐Śń║¦Õł½ÕŖ©µĆüĶ░āµĢ┤**’╝ÜÕ£©ń║┐µø┤µ¢░µŚźÕ┐ŚńŁēń║¦õĖ║debug’╝īĶÄĘÕÅ¢µø┤Ķ»”ń╗åńÜäķŚ«ķóśµÄƵ¤źõ┐Īµü»ŃĆé ŃĆÉArthasÕĖĖńö©ÕæĮõ╗żĶ»”Ķ¦ŻŃĆæ - **jadÕæĮõ╗ż**’╝ÜÕÅŹń╝¢Ķ»æJVMõĖŁńÜä...
3. **CPUõĮ┐ńö©ńÄćńøæµÄ¦**’╝ÜVJTopÕÅ»õ╗źÕ«×µŚČńøæµÄ¦JavaÕ║öńö©ńÜäCPUõĮ┐ńö©ńÄć’╝īÕĖ«ÕŖ®µēŠÕć║CPUÕŹĀńö©Ķ┐ćķ½śńÜäń║┐ń©ŗ’╝īÕłåµ×ÉÕģȵē¦ĶĪīńÜäõ╗ŻńĀü’╝īõ╗ÄĶĆīõ╝śÕī¢µĆ¦ĶāĮŃĆé 4. **µ¢╣µ│ĢĶĆŚµŚČń╗¤Ķ«Ī**’╝ÜķĆÜĶ┐ćĶ┐ĮĶĖ¬µ¢╣µ│ĢĶ░āńö©ĶĆŚµŚČ’╝īVJTopĶāĮÕĖ«ÕŖ®Õ╝ĆÕÅæĶĆģĶ»åÕł½Õć║µĆ¦ĶāĮńōČķół’╝ī...
µ£¼µ¢ćÕ░åõ╗źõĖĆõĖ¬ÕģĘõĮōńÜäń║┐õĖŖÕ«×õŠŗõĖ║ĶāīµÖ»’╝īõ╗ŗń╗ŹÕ”éõĮĢķĆɵŁźµÄƵ¤źÕ╣ČĶ¦ŻÕå│ÕåģÕŁśµ│äµ╝ÅķŚ«ķóśŃĆéķĆÜĶ┐ćÕøŠµ¢ćÕ╣ČĶīéńÜäµ¢╣Õ╝Å’╝īÕĖ«ÕŖ®Ķ»╗ĶĆģµø┤ÕźĮÕ£░ńÉåĶ¦ŻÕåģÕŁśµ│äµ╝ÅńÜäĶ»Ŗµ¢Łµ¢╣µ│ĢŃĆé #### õ║īŃĆüķŚ«ķóśĶāīµÖ» Õ£©õĖĆõĖ¬ķĪ╣ńø«õĖŁ’╝īÕ╝ĆÕÅæÕøóķś¤µ¢░õĖŖń║┐õ║åõĖĆõĖ¬APIµÄźÕÅŻ’╝īÕ╣ČķĆēµŗ®õ║å...
ķĆÜĶ┐ćµöČķøåCPUõĮ┐ńö©ńÄćŃĆüÕåģÕŁśÕŹĀńö©ŃĆüńŻüńøśI/OŃĆüńĮæń╗£µĄüķćÅńŁēń│╗ń╗¤ĶĄäµ║ÉńøæµÄ¦µĢ░µŹ«’╝īń╗ōÕÉłµĢ░µŹ«Õ║ōµŚźÕ┐Ś’╝łÕ”éµģ󵤟Ķ»óµŚźÕ┐Ś’╝ē’╝īµēŠÕć║µĆ¦ĶāĮµ│óÕŖ©ńÜ䵌ČķŚ┤ńé╣ÕÆīÕģ│ĶüöµōŹõĮ£ŃĆé 2. **SQLµ¤źĶ»óõ╝śÕī¢**’╝ܵŻĆµ¤źµģ󵤟Ķ»óµŚźÕ┐Ś’╝īµēŠÕć║Õ»╝Ķć┤µĆ¦ĶāĮõĖŗķÖŹńÜäSQLĶ»ŁÕÅźŃĆéÕłåµ×É...
- **µĆ¦ĶāĮõ╝śÕī¢**’╝ÜÕ»╣Õ║öńö©Ķ┐øĶĪīµĆ¦ĶāĮÕłåµ×É’╝īÕ”éÕåģÕŁśµ│äµ╝ŵŻĆµĄŗŃĆüCPUÕŹĀńö©ńÄćńøæµÄ¦’╝īµÅÉķ½śÕ║öńö©ÕōŹÕ║öķƤÕ║”ÕÆīĶ┐ÉĶĪīµĢłńÄćŃĆé - **µ©ĪÕØŚÕī¢Õ╝ĆÕÅæ**’╝ÜÕ«×ńÄ░µ©ĪÕØŚÕī¢ńÜäõ╗ŻńĀüń╗ōµ×ä’╝īõŠ┐õ║Äõ╗ŻńĀüÕżŹńö©ÕÆīÕÉĵ£¤ń╗┤µŖżŃĆé - **ķøåµłÉń¼¼õĖēµ¢╣Õ║ō**’╝ÜķøåµłÉÕ╣ČķģŹńĮ«ÕÉäń¦Źń¼¼...
- **ELK (Elasticsearch, Logstash, Kibana)** µł¢ **Prometheus + Grafana**’╝ÜĶ┐Öõ║øńÄ░õ╗ŻµŚźÕ┐ŚÕÆīńøæµÄ¦Ķ¦ŻÕå│µ¢╣µĪłĶāĮÕ«×µŚČµöČķøåŃĆüÕłåµ×ÉÕÆīÕÅ»Ķ¦åÕī¢µŚźÕ┐ŚµĢ░µŹ«’╝īµÅÉķ½śµĢģķÜ£µÄƵ¤źµĢłńÄćŃĆé 6. **Õ║öńö©µ£ŹÕŖĪÕÖ©ńøæµÄ¦** - **TomcatŃĆüJettyńŁēÕ║öńö©...