
在多核快速发展的现在,利用多线程技术提高CPU设备的利用率已经成为一种趋势。然而多核计算机体系架构和单核有了很大的变化,在多线程编程中会碰到一些意想不到的问题,比如多核中非常典型的false sharing问题。下文会非常详细的揭示false sharing产生的根源,以及何如避免来提高程序的性能。
先来了解一下典型的多核架构,每个CPU都有自己的Cache,如果一个内存中的变量在多个Cache中都有副本的话,则需要保证变量的Cache一致性:变量的值为最后一次写入的值。Intel多核架构实现Cache一致性是采用的MESI (Modified/Exclusive/Shared/Invalid) 协议。
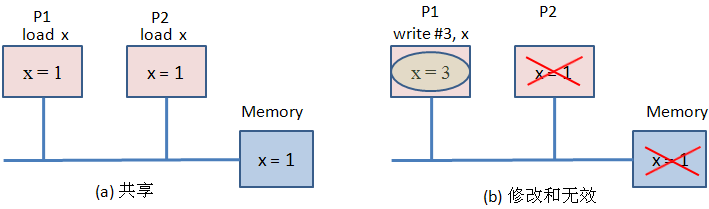
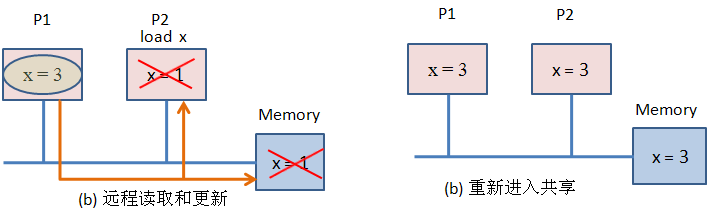
以上图为例,初始P1和P2都从Memory中加载变量x=1,这时每个CPU的Cache的x变量均处于Shared状态;当P1写入x=3时,P2中的变量成为无效状态,P1的为Modified状态。以后在P2读取变量x的值,由于P2的Cache的变量x是无效的,致使Cache命中失败,同时系统会用P1的值来更新P2的Cache和Memory,。
需要注意的是,CPU Cache的结构是按CacheLine为最小单位进行读写的。在Linux可以用命令行sudo cat /proc/cpuinfo看到Cache信息。
本人的机器信息如下:Cache Size: 3072KB, Cache_alignment:64。
下面的例子就能说明false sharing产生的原因:
- double sum=0.0, sum_local[NUM_THREADS];
- #pragma omp parallel num_threads(NUM_THREADS)
- {
- int me = omp_get_thread_num();
- sum_local[me] = 0.0;
- #pragma omp for
- for (i = 0; i < N; i++)
- sum_local[me] += x[i] * y[i]; //产生false sharing的代码行
- #pragma omp atomic
- sum += sum_local[me];
- }
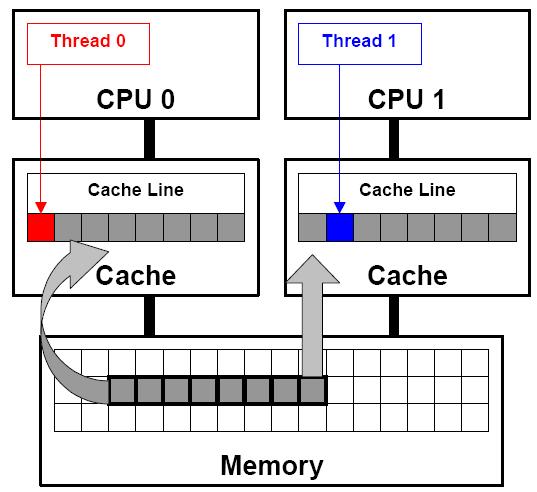
在上图中,CPU0和CPU1的sum_local数组位于同一个Cache Line中。比如某个CPU中的线程更新sum_local[]时,会使其他CPU的Cache的sum_local变成Invalid,这样其他CPU中的线程访问该变量的时候就会进行更新,导致Cache失败,这样会造成额外的内存和Cache之间的同步代价。
在实际的多线程程序中为了避免这种情况,可以采用如下几种方法:
1, 每个线程使用局部线程数据
2, 每个线程访问的全局数据尽可能分隔开至少超过一个Cache Line。
那么,false sharing对程序性能的影响到底有多大呢?下面通过一个程序来进行的粗略性能实验。
下面是一个通过蒙特卡洛法来求取pi的值。
- #include<stdio.h>
- #include<pthread.h>
- #include<stdlib.h>
- #include<sys/time.h>
- #define MaxThreadNum 32
- #define kSamplePoints 100000000
- #define kSpace 1
- void *compute_pi(void *);
- inline double WallTime();
- int total_hits, hits[MaxThreadNum][kSpace];
- int sample_points_per_thread, num_threads;
- int main(void)
- {
- int i;
- double time_start, time_end;
- pthread_t p_threads[MaxThreadNum];
- pthread_attr_t attr;
- pthread_attr_init(&attr);
- pthread_attr_setscope(&attr, PTHREAD_SCOPE_SYSTEM);
- printf("Enter num_threads\n");
- scanf("%d", &num_threads);
- time_start = WallTime();
- total_hits = 0;
- sample_points_per_thread = kSamplePoints / num_threads;
- for(i=0; i<num_threads; i++)
- {
- hits[i][0] = i;
- pthread_create(&p_threads[i], &attr, compute_pi, (void *)&hits[i]);
- }
- for(i=0; i<num_threads; i++)
- {
- pthread_join(p_threads[i], NULL);
- total_hits += hits[i][0];
- }
- double pi = 4.0 * (double)total_hits / kSamplePoints;
- time_end = WallTime();
- printf("Elasped time: %lf, Pi: %lf\n", time_end - time_start, pi);
- return 0;
- }
- void *compute_pi(void * s)
- {
- unsigned int seed;
- int i;
- int *hit_pointer;
- double rand_no_x, rand_no_y;
- int local_hits;
- hit_pointer = (int *)s;
- seed = *hit_pointer;
- local_hits = 0;
- for(i=0; i<sample_points_per_thread; i++)
- {
- rand_no_x = (double)(rand_r(&seed))/(double)(RAND_MAX);
- rand_no_y = (double)(rand_r(&seed))/(double)(RAND_MAX);
- if((rand_no_x - 0.5)*(rand_no_x - 0.5) + (rand_no_y - 0.5) * (rand_no_y - 0.5) < 0.25)
- (*hit_pointer)++;
- // ++local_hits;
- seed *= i;
- }
- //*hit_pointer = local_hits;
- pthread_exit(0);
- }
- inline double WallTime()
- {
- struct timeval tv;
- struct timezone tz;
- gettimeofday(&tv, &tz);
- double currTime = (double)tv.tv_sec + (double)tv.tv_usec/1000000.0;
- return currTime;
- }
其中注释的代码是一种采用线程局部数据的方法,记为pi_local,改变kSpace可以改变不同的线程访问的全局数据之间的间隔,其中改变kSpace的值使不同线程访问的数据之间的间隔为4bytes, 32bytes,64bytes,并分别记为pi_4, p1_32, pi_64,测试得到的结果如下:

因为CPU的数量为2,最大的并行效率为2,以pi_local为标准(因为这种情况完全不存在false sharing问题),可以看到pi_4的false sharing最为严重,因为16个线程访问的hits数组均位于一个Cache Line,因此会导致严重的Cache Invalid现象。而pi_64就采用另外的空间间隔策略完全避免了这一问题,效果也还不错。



相关推荐
根据提供的文件信息,我们可以归纳出以下...总结以上内容,我们可以了解到`volatile`关键字在Java多线程中的重要作用以及相关的CPU缓存管理和优化技术。这些知识点对于理解并发编程中的内存模型和性能调优至关重要。
缓存行填充是为了解决CPU缓存一致性问题,如False Sharing。某些处理器有固定的缓存行大小,当多个线程共享同一缓存行中的变量时,可能会引起不必要的通信开销。Java中的`@Contended`注解可以标记字段以进行填充,...
`volatile`关键字在Java中主要用于解决多线程环境下变量的可见性和有序性问题,确保不同线程之间对共享变量的正确同步。 1. **volatile变量的可见性**:当一个线程修改了`volatile`变量的值,这个变化对于其他线程...
当多个线程共享数据时,如果这些数据分布在不同的缓存行,可能导致伪共享(false sharing),从而降低性能。题目中分析了各种情况下的线程分配和缓存行利用,强调了优化并行计算要考虑硬件层次结构。 【PA 5.1】和...
1. 伪共享(False Sharing): 伪共享是多线程系统中一个众所周知的性能问题,发生在不同处理器的上的线程对变量的修改依赖于相同的缓存行。 2. Busy Spin: Busy Spin 是一种在不释放 CPU 的基础上等待事件的技术,...
### Java多线程与并发控制知识点详解 #### 一、Volatile关键字的深入理解与应用场景 **1. 创建Volatile数组** 在Java中确实可以创建`volatile`类型的数组,但需要注意的是,`volatile`关键字仅保护对数组引用的...
- 伪共享(False Sharing)是另一个需要注意的问题,不同线程修改同一缓存行内的不同变量可能会导致性能下降,因为看似无关的变量实际上共享了同一缓存行,造成不必要的同步。 6. **wait() 和 notify() 方法的使用...
Java 面试中关于多线程、并发和线程基础的问题是常见考点,这些问题涉及到Java内存模型、并发控制和线程安全。以下是对这些知识点的详细解释: 1. **volatile关键字** - Java允许创建volatile数组,但这仅保证数组...
但这也引入了一个问题——伪共享(false sharing),即不同线程对同一Cache行的操作可能导致不必要的内存更新,影响性能。 为了优化Cache性能,内存管理需要尽可能提高Cache局部性,即让经常一起访问的数据位于连续...
多线程环境中的伪共享(False Sharing)是指,不同线程对位于同一缓存行的不同变量的修改,可能导致性能下降,因为这种修改可能会引起不必要的缓存刷新。为了解决这个问题,开发者可以使用对齐(padding)或其他优化...
面试中,Java开发者常被问及各种技术问题,包括多线程、并发、内存管理等。以下是一些Java面试中常见的知识点: 1. **volatile关键字**: - `volatile`关键字用于修饰变量,确保其值在多线程环境中保持一致性和...
在面试过程中,Java开发者经常被问及关于并发、内存管理和多线程的问题,其中volatile关键字是面试中的常见考点。volatile关键字在Java中扮演着重要的角色,确保了多线程环境中的可见性和有序性。 首先,我们可以...
如果多个不相邻的变量被映射到同一缓存行,可能导致不必要的数据传输,称为伪共享(False Sharing)。了解缓存行大小并避免伪共享,是优化CMT处理器缓存性能的重要策略。 六、并行数据访问 在CMT处理器中,不同...
这个类可能会定义数据成员的对齐方式,以确保它们落在不同的缓存行上,从而减少因伪共享(False Sharing)导致的性能损失。伪共享发生在两个或更多个线程无意中修改了同一缓存行的不同部分,即使他们各自操作的数据...