- ŠÁĆŔžł: 451492 ŠČí
- ŠÇžňłź:

- ŠŁąŔç¬: ŠŁşňĚ×
-

Šľçšźáňłćš▒╗
- ňůĘÚâĘňŹÜň«ó (162)
- easymock (3)
- ŠĘ튣┐ň╝ĽŠôÄ (3)
- JForum (4)
- web (9)
- spring (10)
- java (20)
- struts (9)
- uml (3)
- java pattern (19)
- JQuery (14)
- ňĄÜš║┐šĘő (13)
- database (21)
- PS (3)
- ejb (6)
- šëłŠťČš«íšÉć svn , maven , ant (2)
- protocol (1)
- ŠÁőŔ»Ľ (1)
- ws (7)
- Apache (4)
- ŔäÜŠťČŔ»şŔĘÇ (1)
- guice (1)
- ňłćňŞâň╝Ć (4)
- Š×Š×ä (0)
- š╗ĆÚ¬î (1)
- šëłŠťČš«íšÉć svn (1)
- maven (1)
- ant (1)
- ń╣Žš▒Ź (1)
- Linux (1)
šĄżňî║šëłňŁŚ
- ŠłĹšÜäŔÁäŔ«» ( 0)
- ŠłĹšÜäŔ«║ňŁŤ ( 2)
- ŠłĹšÜäÚŚ«šşö ( 0)
ňşśŠíúňłćš▒╗
- 2015-01 ( 1)
- 2014-12 ( 1)
- 2014-07 ( 6)
- ŠŤ┤ňĄÜňşśŠíú...
ŠťÇŠľ░Ŕ»äŔ«║
-
Master-Gao´╝Ü
šĘŹňż«ŠśÄšÖŻń║ćšé╣´╝î´╝ëšé╣ŔÉîŔÉîňôĺ
ńŞ║ń╗Çń╣łňî┐ňÉŹňćůÚâĘš▒╗ňĆ銼░ň┐ůÚí╗ńŞ║finalš▒╗ň×ő -
waw0931´╝Ü
š╗łń║ÄŠśÄšÖŻń║ć´╝îŔ░óŔ░ó´╝ü
ńŞ║ń╗Çń╣łňî┐ňÉŹňćůÚâĘš▒╗ňĆ銼░ň┐ůÚí╗ńŞ║finalš▒╗ň×ő -
ňŹüńŞëňťćŠíîÚ¬Ĺňúź´╝Ü
ŠĆÉńżŤń║ćńŞĄńެÚôżŠÄąŔ┐śŠś»ŠťëšöĘšÜäŃÇé
ň«ëŔúůMondrian -
ŠöżŠľ╣ŔŐ│´╝Ü
[flash=200,200][/flash]
FreemarkerŠáçšşżńŻ┐šöĘ -
ŠöżŠľ╣ŔŐ│´╝Ü
[b][/b]
FreemarkerŠáçšşżńŻ┐šöĘ
šŤ«ňëŹňťĘJavańŞşňşśňťĘńŞĄšžŹÚöüŠť║ňłÂ´╝ÜsynchronizedňĺîLock´╝îLockŠÄąňĆúňĆŐňůÂň«×šÄ░š▒╗Šś»JDK5ňó×ňŐášÜäňćůň«╣´╝îňůÂńŻťŔÇůŠś»ňĄžňÉŹÚ╝ÄÚ╝ÄšÜäň╣ÂňĆĹńŞôň«ÂDoug LeaŃÇ銝Ȋľçň╣ÂńŞŹŠ»öŔżâsynchronizedńŞÄLockňş░ń╝śňş░ňŐú´╝îňƬŠś»ń╗őš╗Źń║îŔÇůšÜäň«×šÄ░ňÄčšÉćŃÇé
┬á ┬ኼ░ŠŹ«ňÉąÚťÇŔŽüńżŁŔÁľÚöü´╝îÚéúÚöüšÜäňÉąňĆłńżŁŔÁľŔ░ü´╝čsynchronizedš╗Öňç║šÜäšşöŠíłŠś»ňťĘŔŻ»ń╗Âň▒éÚŁóńżŁŔÁľJVM´╝îŔÇîLockš╗Öňç║šÜ䊾╣ŠíłŠś»ňťĘšíČń╗Âň▒éÚŁóńżŁŔÁľšë╣Š«ŐšÜäCPUŠîçń╗Ą´╝îňĄžň«ÂňĆ»ŔâŻń╝ÜŔ┐ŤńŞÇŠşąŔ┐ŻÚŚ«´╝ÜJVMň║Ľň▒éňĆłŠś»ňŽéńŻĽň«×šÄ░synchronizedšÜä´╝č
┬á ┬ኝȊľçŠëÇŠîçŔ»┤šÜäJVMŠś»ŠîçHotspotšÜä6u23šëłŠťČ´╝îńŞőÚŁóÚŽľňůłń╗őš╗ŹsynchronizedšÜäň«×šÄ░´╝Ü
┬á ┬ásynrhronizedňů│Úö«ňşŚš«ÇŠ┤üŃÇüŠŞůŠÖ░ŃÇüŔ»şń╣ëŠśÄší«´╝îňŤáŠşĄňŹ│ńŻ┐Šťëń║ćLockŠÄąňĆú´╝îńŻ┐šöĘšÜäŔ┐śŠś»ÚŁ×ňŞŞň╣┐Š│ŤŃÇéňůÂň║öšöĘň▒éšÜäŔ»şń╣늜»ňĆ»ń╗ąŠŐŐń╗╗ńŻĽńŞÇńŞ¬ÚŁ×nullň»╣Ŕ▒íńŻťńŞ║"Úöü"´╝îňŻôsynchronizedńŻťšöĘňťĘŠľ╣Š│ĽńŞŐŠŚÂ´╝îÚöüńŻĆšÜäńż┐Šś»ň»╣Ŕ▒íň«×ńżő´╝łthis´╝ë´╝ŤňŻôńŻťšöĘňťĘÚŁÖŠÇüŠľ╣Š│ĽŠŚÂÚöüńŻĆšÜäńż┐Šś»ň»╣Ŕ▒íň»╣ň║öšÜäClassň«×ńżő´╝îňŤáńŞ║ClassŠĽ░ŠŹ«ňşśňťĘń║ÄŠ░Şń╣ůňŞŽ´╝îňŤáŠşĄÚŁÖŠÇüŠľ╣Š│ĽÚöüšŤŞňŻôń║ÄŔ»ąš▒╗šÜäńŞÇńެňůĘň▒ÇÚöü´╝ŤňŻôsynchronizedńŻťšöĘń║ÄŠčÉńŞÇńެň»╣Ŕ▒íň«×ńżőŠŚÂ´╝îÚöüńŻĆšÜäńż┐Šś»ň»╣ň║öšÜäń╗úšáüňŁŚŃÇéňťĘHotSpot JVMň«×šÄ░ńŞş´╝îÚöüŠťëńެńŞôÚŚĘšÜäňÉŹňşŚ´╝Üň»╣Ŕ▒획ĹŔžćňÖĘŃÇé┬á 1. š║┐šĘőšŐŠÇüňĆŐšŐŠÇüŔŻČŠŹó
┬á ┬á ňŻôňĄÜńެš║┐šĘőňÉÂŔ»ĚŠ▒éŠčÉńެň»╣Ŕ▒획ĹŔžćňÖĘŠŚÂ´╝îň»╣Ŕ▒획ĹŔžćňÖĘń╝ÜŔ«żšŻ«ňçášžŹšŐŠÇüšöĘŠŁąňî║ňłćŔ»ĚŠ▒éšÜäš║┐šĘő´╝Ü
 
- Contention List´╝ÜŠëÇŠťëŔ»ĚŠ▒éÚöüšÜäš║┐šĘőň░ćŔóźÚŽľňůłŠöżšŻ«ňł░Ŕ»ąšź×ń║ëÚśčňłŚ
- Entry List´╝ÜContention ListńŞşÚéúń║ŤŠťëŔÁäŠá╝ŠłÉńŞ║ňÇÖÚÇëń║║šÜäš║┐šĘőŔóźšž╗ňł░Entry List
- Wait Set´╝ÜÚéúń║ŤŔ░âšöĘwaitŠľ╣Š│ĽŔóźÚś╗ňíךÜäš║┐šĘőŔóźŠöżšŻ«ňł░Wait Set
- OnDeck´╝Üń╗╗ńŻĽŠŚÂňł╗ŠťÇňĄÜňƬŔ⯊ťëńŞÇńެš║┐šĘőŠşúňťĘšź×ń║ëÚöü´╝îŔ»ąš║┐šĘőšž░ńŞ║OnDeck
- Owner´╝ÜŔÄĚňżŚÚöüšÜäš║┐šĘőšž░ńŞ║Owner
- !Owner´╝ÜÚçŐŠöżÚöüšÜäš║┐šĘő
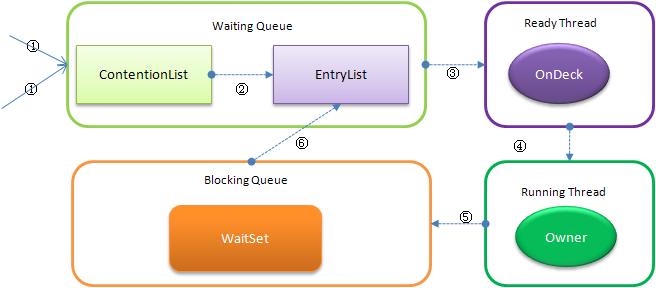
1.1 ContentionListŔÖÜŠőčÚśčňłŚ
ContentionListň╣ÂńŞŹŠś»ńŞÇńެšťčŠşúšÜäQueue´╝îŔÇîňƬŠś»ńŞÇńެŔÖÜŠőčÚśčňłŚ´╝îňÄčňŤáňťĘń║ÄContentionListŠś»šö▒NodeňĆŐňůÂnextŠîçÚĺłÚÇ╗ŔżĹŠ×䊳ɴ╝îň╣ÂńŞŹňşśňťĘńŞÇńެQueuešÜ䊼░ŠŹ«š╗ôŠ×äŃÇéContentionListŠś»ńŞÇńެňÉÄŔ┐Ťňůłňç║´╝łLIFO´╝ëšÜäÚśčňłŚ´╝ƊČ튾░ňŐáňůąNodeŠŚÂÚâŻń╝ÜňťĘÚśčňĄ┤Ŕ┐ŤŔíî´╝îÚÇÜŔ┐çCASŠö╣ňĆśšČČńŞÇńެŔŐéšé╣šÜäšÜäŠîçÚĺłńŞ║Šľ░ňó×ŔŐéšé╣´╝îňÉÂŔ«żšŻ«Šľ░ňó×ŔŐéšé╣šÜänextŠîçňÉĹňÉÄš╗şŔŐéšé╣´╝îŔÇîňĆľňżŚŠôŹńŻťňłÖňĆĹšöčňťĘÚśčň░żŃÇ銜żšä´╝îŔ»ąš╗ôŠ×äňůÂň«×Šś»ńެLock-FreešÜäÚśčňłŚŃÇé
ňŤáńŞ║ňƬŠťëOwnerš║┐šĘőŠëŹŔâŻń╗ÄÚśčň░żňĆľňůâš┤á´╝îń╣čňŹ│š║┐šĘőňç║ňłŚŠôŹńŻťŠŚáń║ëšöĘ´╝îňŻôšäÂń╣čň░▒Úü┐ňůŹń║ćCASšÜäABAÚŚ«ÚóśŃÇé
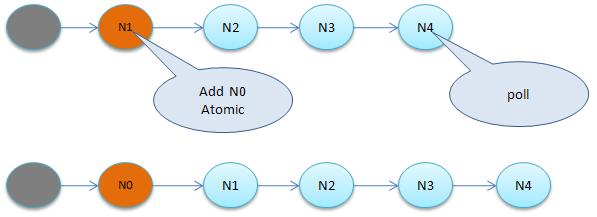
1.2 EntryList
2. Ŕ笊ŚőÚöü
- ňŽéŠ×ťň╣│ňŁçŔ┤čŔŻŻň░Ćń║ÄCPUsňłÖńŞÇšŤ┤Ŕ笊Śő
- ňŽéŠ×ťŠťëŔÂůŔ┐ç(CPUs/2)ńެš║┐šĘőŠşúňťĘŔ笊Śő´╝îňłÖňÉÄŠŁąš║┐šĘőšŤ┤ŠÄąÚś╗ňí×
- ňŽéŠ×ťŠşúňťĘŔ笊ŚőšÜäš║┐šĘőňĆĹšÄ░OwnerňĆĹšöčń║ćňĆśňîľňłÖň╗ÂŔ┐čŔ笊ŚőŠŚÂÚŚ┤´╝łŔ笊ŚőŔ«íŠĽ░´╝늳ľŔ┐ŤňůąÚś╗ňí×
- ňŽéŠ×ťCPUňĄäń║ÄŔŐéšöÁŠĘíň╝ĆňłÖňüťŠşóŔ笊Śő
- Ŕ笊ŚőŠŚÂÚŚ┤šÜ䊝ÇňŁĆŠâůňćÁŠś»CPUšÜäňşśňéĘň╗ÂŔ┐č´╝łCPU AňşśňéĘń║ćńŞÇńެŠĽ░ŠŹ«´╝îňł░CPU BňżŚščąŔ┐ÖńެŠĽ░ŠŹ«šŤ┤ŠÄąšÜ䊌ÂÚŚ┤ňĚ«´╝ë
- Ŕ笊ŚőŠŚÂń╝ÜÚÇéňŻôŠöżň╝âš║┐šĘőń╝śňůłš║žń╣őÚŚ┤šÜäňĚ«ň╝é
3. ňüĆňÉĹÚöü
3.1 CASňĆŐSMPŠ×Š×ä
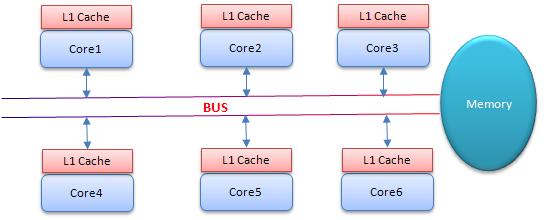
3.2 ňüĆňÉĹŔžúÚÖĄ
4. ŠÇ╗š╗ô


- 2013-01-03 10:25
- ŠÁĆŔžł 1415
- Ŕ»äŔ«║(0)
- ňłćš▒╗:š╝ľšĘőŔ»şŔĘÇ
- ŠčąšťőŠŤ┤ňĄÜ
ňĆĹŔíĘŔ»äŔ«║

-
ŠĚ▒ňůąŠÁůňç║Javaň╣ÂňĆĹňîůÔÇöÚöüŠť║ňłÂ´╝łŔŻČ´╝ë
2014-07-30 13:11 1097ňëŹÚŁóŠłĹń╗Čšťőňł░ń║ćLockňĺîsynchronizedÚâŻŔ⯊şúňŞŞšÜäń┐Ł ... -
Ŕ笊ŚőÚöüŃÇüŠÄĺÚśčŔ笊ŚőÚöüŃÇüMCSÚöüŃÇüCLHÚöü(ŔŻČ)
2014-07-30 12:42 1070Ŕ笊ŚőÚöü´╝łSpin lock´╝ë Ŕ笊ŚőÚöüŠś»ŠîçňŻôńŞÇńެš║┐šĘőň░ŁŔ»ĽŔÄĚňĆľ ... -
javaš║┐šĘőŠ▒á
2014-07-28 10:05 525ńŞÇ┬áš«Çń╗ő š║┐šĘőšÜäńŻ┐šöĘňť ... -
ňĄÜš║┐šĘőń╣őfalse sharingÚŚ«Úóś(ŔŻČ)
2014-07-22 14:17 1158ňťĘňĄÜŠáŞň┐źÚÇčňĆĹň▒ĽšÜäšÄ░ňťĘ´╝îňłęšöĘňĄÜš║┐šĘőŠŐÇŠť»ŠĆÉÚźśCPUŔ«żňĄçšÜäňłęšöĘšÄçňĚ▓ ... -
š║┐šĘőšŐŠÇü
2013-08-26 16:17 718┬á ┬á ┬áňŤżńŞşÔÇťšşëňżůÚśčňłŚÔÇŁ ňĆ»ŠŤ┐ŠŹóŠłÉ ÔÇťšşëňżůŠ▒ášŐŠÇü ... -
ňŽéńŻĽńŞşŠľşš║┐šĘő
2013-01-03 14:13 1019package cn.com.york.concurrency ... -
ÚöüŠť║ňłÂ´╝łńŞë´╝ë´╝łŔŻČ´╝ë
2013-01-03 10:32 2795ńŞŹňÉîšÜäŔžĺň║ŽšÉćŔžú´╝ł^_^´╝ë ňťĘšÉćŔžúJ.U.CňÄčšÉćń╗ąňĆŐÚöüŠť║ňłÂń╣őňëŹ ... -
ÚöüŠť║ňłÂ(ń║î)-lock´╝łŔŻČ´╝ë
2013-01-03 10:27 1129ň돊ľç´╝łŠĚ▒ňůąJVMÚöüŠť║ňłÂ-synchronized´╝ëňłćŠ×Éń║ć ... -
ňŽéńŻĽňůůňłćňłęšöĘňĄÜŠáŞCPU´╝îŔ«íš«ŚňżłňĄžšÜäListńŞşŠëÇŠťëŠĽ┤ŠĽ░šÜäňĺî
2012-10-11 12:45 1193ň╝ĽšöĘ ňëŹňçáňĄęňťĘšŻĹńŞŐšťőňł░ńŞÇńެŠĚśň«ŁšÜäÚŁóŔ»ĽÚóś´╝ÜŠťëńŞÇńެňżłňĄžšÜ䊼┤ ... -
JAVA ňĄÜš║┐šĘő
2012-04-26 17:52 1146JDK5ńŞşšÜäńŞÇńެń║«šé╣ň░▒Šś»ň░ćDoug LeašÜäň╣ÂňĆĹň║ôň╝Ľňůąňł░Jav ... -
ConcurrentHashMapňÄčšÉćňłćŠ×É
2012-02-13 18:50 1338ÚŤćňÉłŠś»š╝ľšĘőńŞşŠťÇňŞŞšöĘšÜäŠ ... -
ŠĚ▒ňůąšáöšęÂjava.lang.ThreadLocalš▒╗´╝łŔŻČ´╝ë
2011-05-26 21:19 922ŠĚ▒ňůąšáöšęÂjava.lang.ThreadLocalš▒╗ ┬á ...
šŤŞňů│ŠÄĘŔŹÉ
Java ÚöüŠť║ňłÂ Synchronized Šś» Java Ŕ»şŔĘÇńŞşšÜäńŞÇšžŹňÉąŠť║ňłÂ´╝îšöĘń║ÄŔžúňć│ňĄÜš║┐šĘőň╣ÂňĆĹŔ«┐ÚŚ«ňů▒ń║źŔÁäŠ║ÉŠŚÂňĆ»ŔâŻňç║šÄ░šÜäńŞÇń║ŤÚŚ«ÚóśŃÇé Java ÚöüŠť║ňłÂ Synchronized šÜ䊎éň┐Á ňťĘ Java ńŞş´╝Ćńެň»╣Ŕ▒íÚâŻňĆ»ń╗ąŔóźšťőńŻťŠś»ńŞÇńެňĄžŠł┐ňşÉ´╝îňůÂńŞşŠťëňĄÜńެ...
ňťĘňşŽń╣áJavaŔ┐çšĘőńŞş´╝îŔç¬ňĚ▒ŠöÂÚŤćń║ćňżłňĄÜšÜäJavašÜäňşŽń╣áŔÁ䊾ִ╝îňłćń║źš╗ÖňĄžň«Â´╝ëÚťÇŔŽüšÜäŠČóŔ┐ÄńŞőŔŻŻ´╝îňŞîŠťŤň»╣ňĄžň«ÂŠťëšöĘ´╝îńŞÇŔÁĚňşŽń╣á´╝îńŞÇŔÁĚŔ┐ŤŠşąŃÇé
ňťĘňşŽń╣áJavaŔ┐çšĘőńŞş´╝îŔç¬ňĚ▒ŠöÂÚŤćń║ćňżłňĄÜšÜäJavašÜäňşŽń╣áŔÁ䊾ִ╝îňłćń║źš╗ÖňĄžň«Â´╝ëÚťÇŔŽüšÜäŠČóŔ┐ÄńŞőŔŻŻ´╝îňŞîŠťŤň»╣ňĄžň«ÂŠťëšöĘ´╝îńŞÇŔÁĚňşŽń╣á´╝îńŞÇŔÁĚŔ┐ŤŠşąŃÇé
ňťĘňşŽń╣áJavaŔ┐çšĘőńŞş´╝îŔç¬ňĚ▒ŠöÂÚŤćń║ćňżłňĄÜšÜäJavašÜäňşŽń╣áŔÁ䊾ִ╝îňłćń║źš╗ÖňĄžň«Â´╝ëÚťÇŔŽüšÜäŠČóŔ┐ÄńŞőŔŻŻ´╝îňŞîŠťŤň»╣ňĄžň«ÂŠťëšöĘ´╝îńŞÇŔÁĚňşŽń╣á´╝îńŞÇŔÁĚŔ┐ŤŠşąŃÇé
* synchronized ňů│Úö«ňşŚňƬŔâŻŔóźńŞÇńެš║┐šĘőŔÄĚňĆľ´╝îŠ▓튝ëŔÄĚňżŚÚöüšÜäš║┐šĘőňƬŔ⯚şëňżůŃÇé * Š»Ćńެň«×ńżőÚâŻň»╣ň║öŠťëŔç¬ňĚ▒šÜäÚöü´╝łthis´╝ë´╝îńŞŹňÉîň«×ńżőń╣őÚŚ┤ń║ĺńŞŹňŻ▒ňôŹŃÇé * synchronized ń┐«Úą░šÜ䊾╣Š│Ľ´╝áŔ«║Šľ╣Š│ĽŠşúňŞŞŠëžŔíîň«îŠ»ĽŔ┐śŠś»ŠŐŤňç║ň╝éňŞŞ´╝îÚâŻń╝ÜÚçŐŠöżÚöüŃÇé...
ňťĘňşŽń╣áJavaŔ┐çšĘőńŞş´╝îŔç¬ňĚ▒ŠöÂÚŤćń║ćňżłňĄÜšÜäJavašÜäňşŽń╣áŔÁ䊾ִ╝îňłćń║źš╗ÖňĄžň«Â´╝ëÚťÇŔŽüšÜäŠČóŔ┐ÄńŞőŔŻŻ´╝îňŞîŠťŤň»╣ňĄžň«ÂŠťëšöĘ´╝îńŞÇŔÁĚňşŽń╣á´╝îńŞÇŔÁĚŔ┐ŤŠşąŃÇé
ňťĘňşŽń╣áJavaŔ┐çšĘőńŞş´╝îŔç¬ňĚ▒ŠöÂÚŤćń║ćňżłňĄÜšÜäJavašÜäňşŽń╣áŔÁ䊾ִ╝îňłćń║źš╗ÖňĄžň«Â´╝ëÚťÇŔŽüšÜäŠČóŔ┐ÄńŞőŔŻŻ´╝îňŞîŠťŤň»╣ňĄžň«ÂŠťëšöĘ´╝îńŞÇŔÁĚňşŽń╣á´╝îńŞÇŔÁĚŔ┐ŤŠşąŃÇé
javaÚöüŠť║ňłÂSynchronized.pdf
2. ÚöüšÜ䊎éň┐Á´╝ÜŠ»Ćńެň»╣Ŕ▒íÚ⯊ťëńŞÇńެńŞÄń╣őňů│ŔüöšÜäÚöü´╝îňŻôš║┐šĘőŠëžŔíî`synchronized`ń╗úšáüŠŚÂ´╝îń╝ÜŔç¬ňŐĘŔÄĚňĆľň»╣Ŕ▒íšÜäÚöü´╝îŠëžŔíîň«îŠłÉňÉÄÚçŐŠöżÚöüŃÇéňŽéŠ×ťňĄÜńެš║┐šĘőňÉÂň░ŁŔ»ĽŔ┐ŤňůąňÉîńŞÇň»╣Ŕ▒íšÜä`synchronized`ń╗úšáü´╝îňƬŠťëńŞÇńެš║┐šĘőŔ⯊łÉňŐčŔÄĚňĆľÚöü´╝îňůÂń╗ľ...
ňťĘ Java ńŞş´╝îsynchronized Šť║ňłÂŠś»ňĄÜš║┐šĘőš╝ľšĘőńŞşŠťÇÚçŹŔŽüšÜ䊎éň┐Áń╣őńŞÇŃÇéň«âňůüŔ«Şň╝ÇňĆĹŔÇůŠÄžňłÂňĄÜńެš║┐šĘőň»╣ňů▒ń║źŔÁäŠ║ÉšÜäŔ«┐ÚŚ«´╝îń╗ąÚü┐ňůŹŠĽ░ŠŹ«ńŞŹńŞÇŔç┤ňĺî race conditionŃÇéÚÇÜŔ┐çńŻ┐šöĘ synchronized´╝îňĆ»ń╗ąší«ń┐ŁňťĘňÉîńŞÇŠŚÂÚŚ┤ňƬŠťëńŞÇńެš║┐šĘőňĆ»ń╗ąŔ«┐ÚŚ«...
ňťĘňşŽń╣áJavaŔ┐çšĘőńŞş´╝îŔç¬ňĚ▒ŠöÂÚŤćń║ćňżłňĄÜšÜäJavašÜäňşŽń╣áŔÁ䊾ִ╝îňłćń║źš╗ÖňĄžň«Â´╝ëÚťÇŔŽüšÜäŠČóŔ┐ÄńŞőŔŻŻ´╝îňŞîŠťŤň»╣ňĄžň«ÂŠťëšöĘ´╝îńŞÇŔÁĚňşŽń╣á´╝îńŞÇŔÁĚŔ┐ŤŠşąŃÇé
ňťĘňşŽń╣áJavaŔ┐çšĘőńŞş´╝îŔç¬ňĚ▒ŠöÂÚŤćń║ćňżłňĄÜšÜäJavašÜäňşŽń╣áŔÁ䊾ִ╝îňłćń║źš╗ÖňĄžň«Â´╝ëÚťÇŔŽüšÜäŠČóŔ┐ÄńŞőŔŻŻ´╝îňŞîŠťŤň»╣ňĄžň«ÂŠťëšöĘ´╝îńŞÇŔÁĚňşŽń╣á´╝îńŞÇŔÁĚŔ┐ŤŠşąŃÇé
ŠÇ╗š╗ôŠŁąŔ»┤´╝î`synchronized`ňťĘJavaň╣ÂňĆĹš╝ľšĘőńŞşŠë«Š╝öšŁÇŠáŞň┐âŔžĺŔë▓´╝îň«âÚÇÜŔ┐çÚöüŠť║ňłÂší«ń┐Łń║ćňů▒ń║źŔÁäŠ║ÉšÜäň«ëňůĘŔ«┐ÚŚ«´╝îŔžúňć│ń║ćňĄÜš║┐šĘőšÄ»ňóâńŞőšÜ䊼░ŠŹ«ńŞÇŔç┤ŠÇžÚŚ«ÚóśŃÇ銺úší«šÉćŔžúňĺîńŻ┐šöĘ`synchronized`ň»╣ń║Äš╝ľňćÖÚźśŠĽłŃÇüš║┐šĘőň«ëňůĘšÜäJavań╗úšáüŔç│ňů│ÚçŹŔŽüŃÇé
ńŞ║ń║ćŔžúňć│Ŕ┐Öš▒╗ÚŚ«Úóś´╝îJavaŠĆÉńżŤń║ć`synchronized`ňů│Úö«ňşŚ´╝îň«âŠĆÉńżŤń║ćńŞÇšžŹÚöüŠť║ňłÂ´╝îší«ń┐Łňů▒ń║źŠĽ░ŠŹ«ňťĘňÉîńŞÇŠŚÂÚŚ┤ňƬŔâŻŔóźńŞÇńެš║┐šĘőŔ«┐ÚŚ«ŃÇéňťĘšČČńŞÇńެšĄ║ńżőńŞş´╝îŠ▓튝ëńŻ┐šöĘ`synchronized`´╝îňŤáŠşĄŠëÇŠťëš║┐šĘőÚâŻňĆ»ń╗ąň╣ÂňĆĹňť░ň»╣`count`Ŕ┐ŤŔíîń┐«Šö╣´╝îň»╝Ŕç┤...
šö▒ŠÁůňůąŠĚ▒ŔžúŠ×ÉsynchronizedÚöüšÜ䊝║ňłÂ´╝îňÉäšžŹÚöüšÜ䊎éň┐ÁšÜäń╗őš╗Ź´╝îŔćĘŔâÇŔ┐çšĘő´╝îňč║ń║ÄredisšÜäňłćňŞâň╝ĆÚöüdemoŃÇé
java-synchronized ňÁîňąŚńŻ┐šöĘŠś» Java š╝ľšĘőŔ»şŔĘÇńŞşšÜäńŞÇšžŹňÉąŠť║ňłÂ´╝îšöĘń║ÄŔžúňć│ňĄÜš║┐šĘőň╣ÂňĆĹŠëžŔíšÜäš║┐šĘőň«ëňůĘÚŚ«ÚóśŃÇéÚÇÜŔ┐çńŻ┐šöĘ synchronized ňů│Úö«ňşŚ´╝îňĆ»ń╗ąň░ćŠčÉńެň»╣Ŕ▒튳ľń╗úšáüňŁŚÚöüň«Ü´╝îńŻ┐ňżŚňůÂń╗ľš║┐šĘőŠŚáŠ│ĽŔ«┐ÚŚ«Ŕ»ąň»╣Ŕ▒튳ľń╗úšáüňŁŚ´╝îń╗ÄŔÇî...
ń║ćŔžú JVM ÚöüŠť║ňłÂńŞşšÜä synchronized ňĺî Lock ň«×šÄ░ňÄčšÉć ňťĘ Java ńŞş´╝îÚöüŠť║ňłÂŠś»ŠĽ░ŠŹ«ňÉąšÜäňů│Úö«´╝îňşśňťĘńŞĄšžŹÚöüŠť║ňłÂ´╝Üsynchronized ňĺî LockŃÇéń║ćŔžúŔ┐ÖńŞĄšžŹÚöüŠť║ňłÂšÜäň«×šÄ░ňÄčšÉćň»╣ń║ÄšÉćŔžú Java ň╣ÂňĆĹš╝ľšĘőÚŁ×ňŞŞÚçŹŔŽüŃÇé synchronized Úöü...
javaÚöüŠť║ňłÂSynchronized[ňŻĺš║│].pdf